Paper Review: StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
Text-to-image synthesis has come a long way in recent years, thanks to the combination of large pretrained language models, ample training data, and the emergence of scalable model families such as diffusion and autoregressive models. However, these models come with a significant drawback: they require iterative evaluations to generate a single image. Unlike their counterparts, GANs can generate a single image in just one forward pass, making them much faster. However, they have yet to catch up to the state-of-the-art in large-scale text-to-image synthesis.
In this paper, the authors propose StyleGAN-T, a model designed specifically for large-scale text-to-image synthesis. With its large capacity, stable training on diverse datasets, strong text alignment, and controllable variation-text alignment tradeoff, StyleGAN-T outperforms previous GANs and even surpasses distilled diffusion models, the previous frontrunners in fast text-to-image synthesis in terms of sample quality and speed.
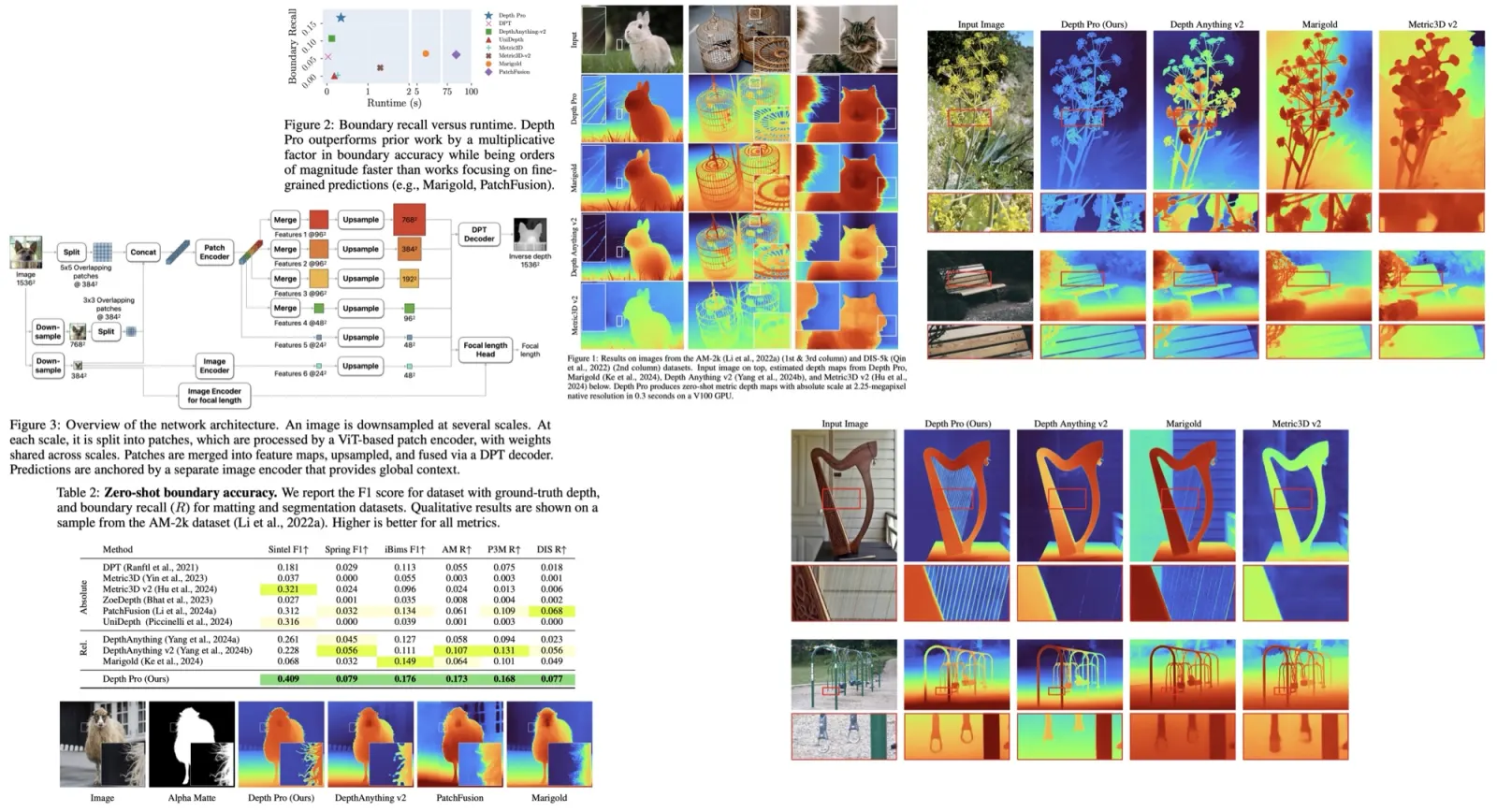
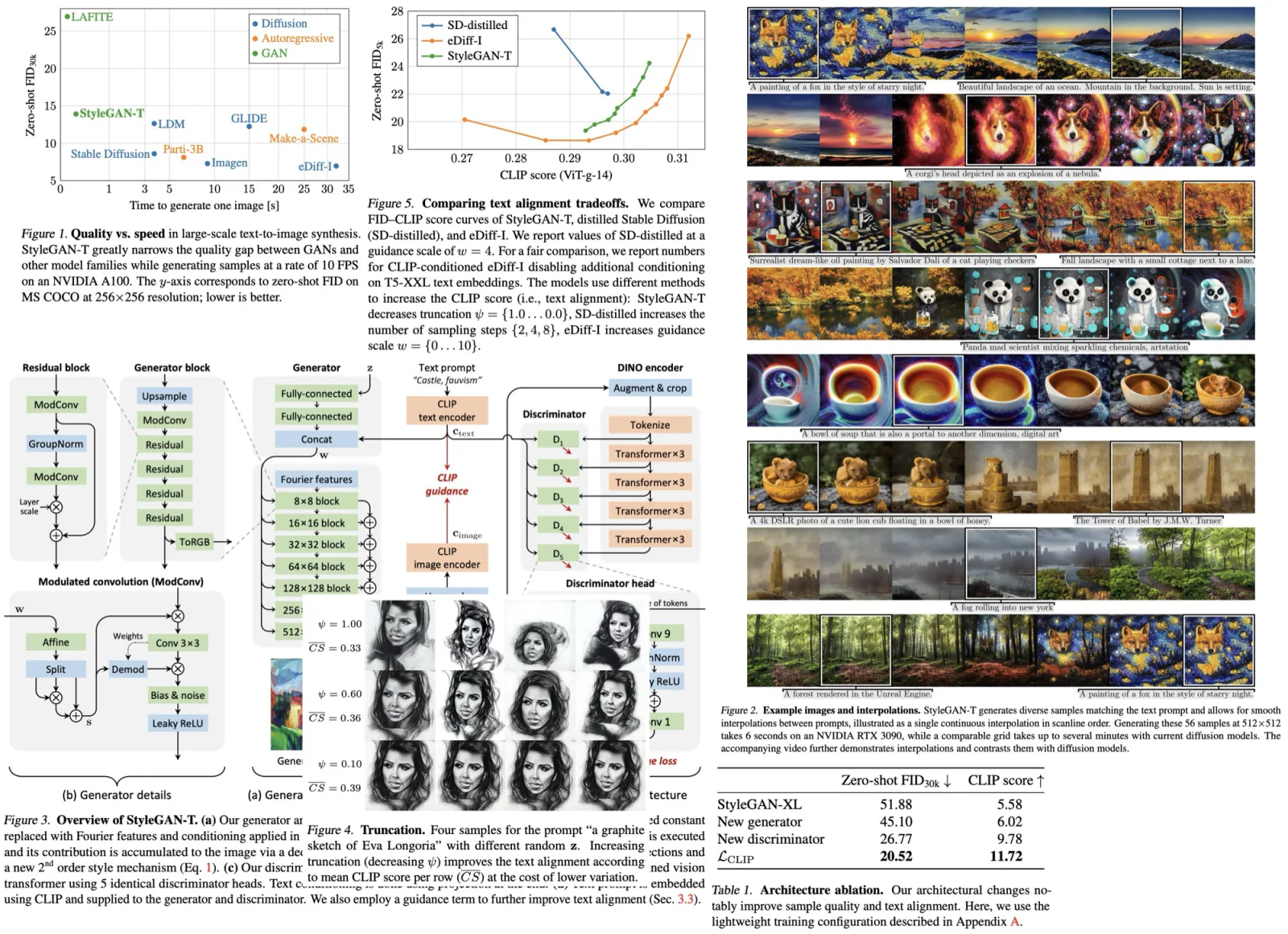
StyleGAN-T achieves a better zero-shot MS COCO FID than current state of-the-art diffusion models at a resolution of 64×64. At 256×256, StyleGAN-T halves the zero-shot FID previously achieved by a GAN but continues to trail SOTA diffusion models.
StyleGAN-XL
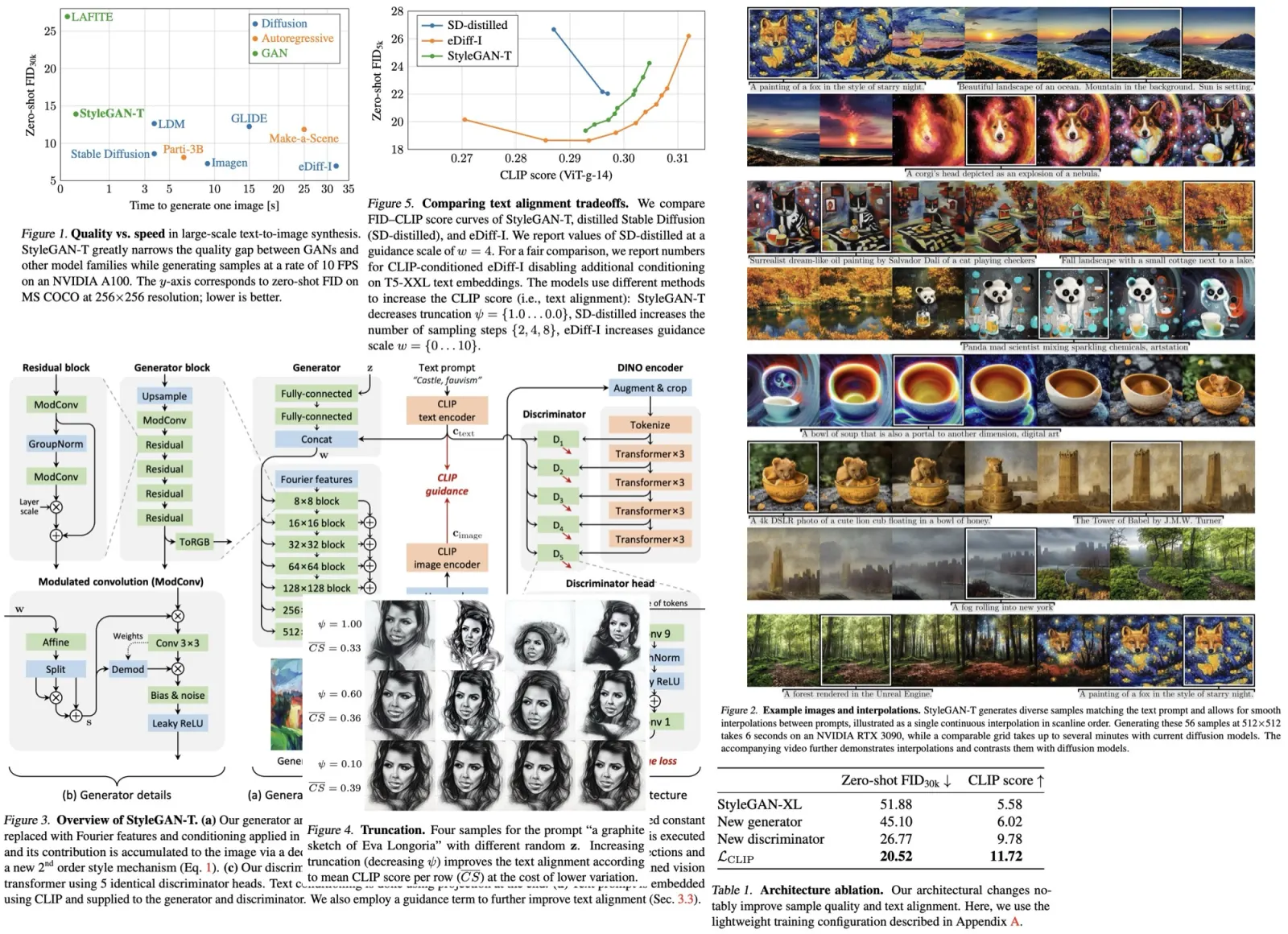
This new architecture is based on the successful StyleGAN-XL. It processes a normally distributed input latent code z using a mapping network to produce an intermediate latent code w. This intermediate latent is then used to modulate the convolution layers in a synthesis network, using the weight demodulation technique from StyleGAN2. The synthesis network of StyleGAN-XL uses the alias-free primitive operations of StyleGAN3 to achieve translation equivariance, meaning it has no preferred positions for the generated features.
What sets StyleGAN-XL apart is its unique discriminator design. It uses multiple discriminator heads that operate on feature projections from two pretrained frozen feature extraction networks: DeiT-M and EfficientNet. These outputs are fed through randomized cross-channel and cross-scale mixing modules, resulting in two feature pyramids with four resolution levels each that are processed by eight discriminator heads. An additional pretrained classifier network provides guidance during training.
The synthesis network of StyleGAN-XL is trained progressively, increasing the output resolution over time by introducing new synthesis layers once the current resolution stops improving. Unlike previous progressive growing approaches, the discriminator structure does not change during training. The early low-resolution images are upsampled as necessary to suit the discriminator, and the already trained synthesis layers are frozen as further layers are added.
For class-conditional synthesis, StyleGAN-XL concatenates a one-hot class label to z and uses a projection discriminator.
StyleGAN-T
The authors modify baseline focusing on the generator, discriminator, and variation vs. text alignment tradeoff mechanisms in turn.
To measure the effectiveness of their modifications, the authors use the FID (Fréchet Inception Distance) and CLIP (Contrastive Language-Image Pretraining) score metrics. The CLIP score measures text alignment by using a ViT-g-14 model trained on LAION-2B dataset. The tests use a limited compute budget, smaller models, and a smaller dataset than the final large-scale experiments.
The authors change class conditioning to text conditioning in the baseline model by embedding text prompts using a pretrained CLIP ViT-L/14 text encoder, which is used in place of the class embedding. They remove the classifier guidance during training as well. This simple conditioning mechanism is similar to early text-to-image models.
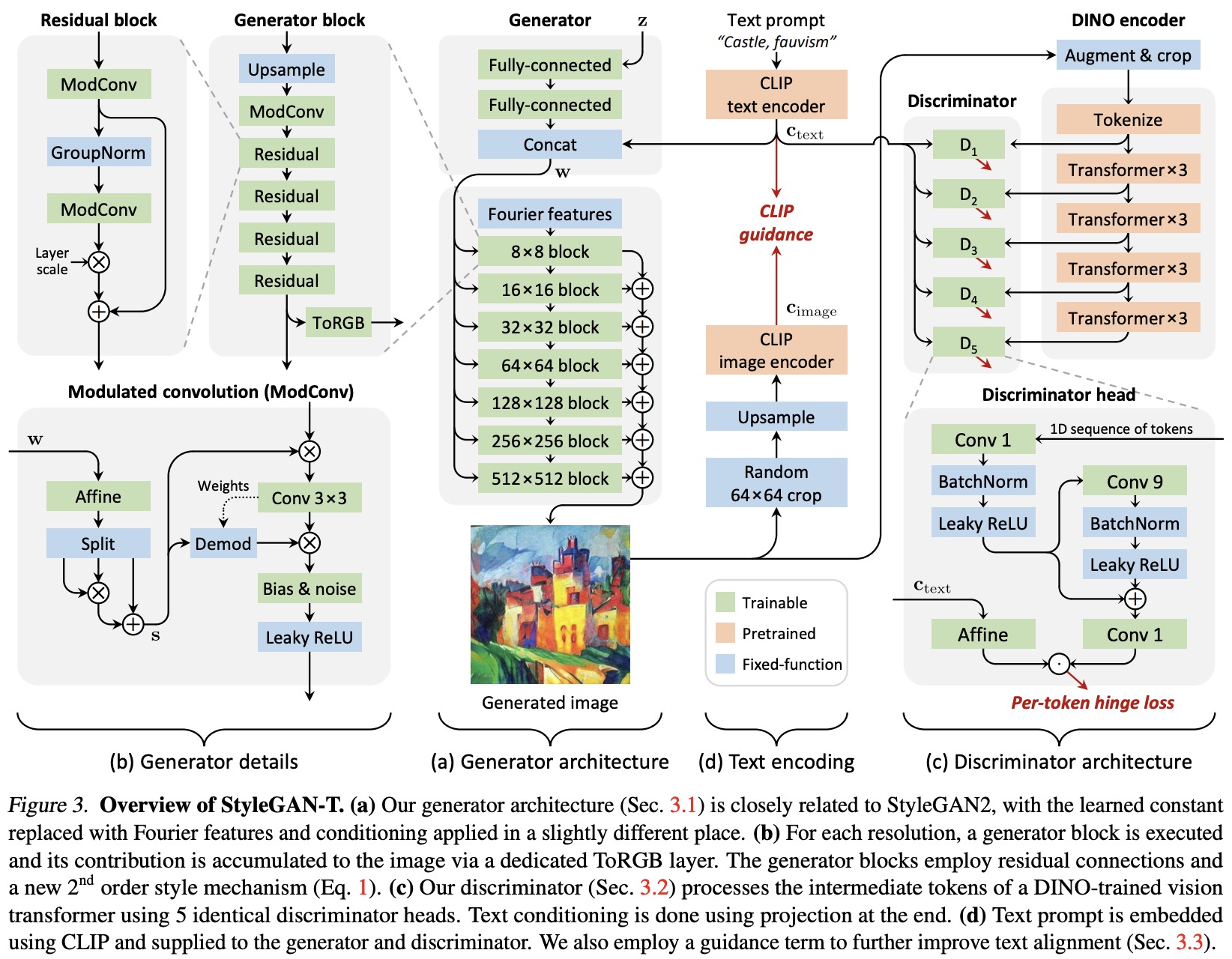
The results of the lightweight training configuration show that the baseline model achieved a zero-shot FID of 51.88 and a CLIP score of 5.58. It’s worth noting that the authors used a different CLIP model for generator conditioning and CLIP score computation to reduce the risk of artificially inflating the results.
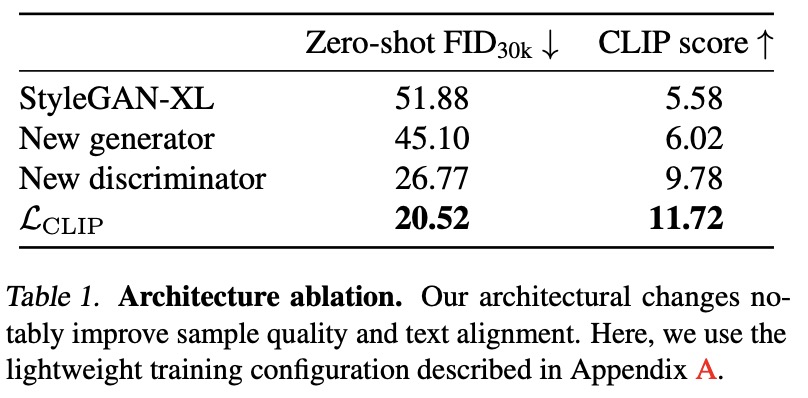
Redesigning the Generator
The authors switch from using StyleGAN3 layers to achieve translational equivariance in StyleGAN-XL to using StyleGAN2 backbone for the synthesis layers. This change was made because equivariance is not necessary for text-to-image synthesis and also adds computational cost. The authors also propose two changes to the details of the generator architecture.
In order to increase the capacity of the generator, residual convolutions are used as a building block. This allows the generator to scale in both width and depth without experiencing early mode collapse in training. Half of the convolution layers are made residual and are wrapped in normalization and scaling techniques for better optimization. This design allows for a significant increase in the total number of layers (2.3× in the lightweight configuration and 4.5× in the final model) and stabilizes early training iterations. The parameter count is matched to the StyleGAN-XL baseline for fairness.
The authors also made changes to the text-to-image synthesis architecture to improve the role of text embeddings in the final image output. The changes include bypassing the mapping network with the text embeddings, splitting the text-based styles into three vectors, and computing the final style vector using element-wise multiplication, increasing the expressive power of the network. These changes improved the FID and CLIP score by about 10%.
Redesigning the Discriminator
- ViT-S trained with the self-supervised DINO objective as a feature network. It is lightweight, fast to evaluate, and encodes semantic information at high spatial resolution;
- The discriminator architecture consists of five heads spaced evenly between the transformer layers and uses a hinge loss to evaluate independently for each token in each head. ViTs are isotropic, i.e., the representation size (tokens × channels) and receptive field (global) are the same throughout the network; this allows to use the same architecture for all discriminator heads. The heads use 1D residual convolutions applied on the token sequence, found to perform as well as 2D convolutions. The authors use virtual batch statistics instead of synchronous BatchNorm to avoid communication overhead between nodes and GPUs.
- The authors apply differentiable data augmentation with default parameters before the feature network in the discriminator. They use random crops when training at a resolution larger than 224×224 pixels (ViT-S training resolution);
Variation vs. Text Alignment Tradeoffs
The use of guidance is crucial in text-to-image models to achieve better image quality aligned with the text. The authors aim to incorporate this concept in their GAN model.
Guiding the generator. In the context of text-to-image generation, the authors use a pre-trained CLIP image encoder as a part of the generator loss function to guide the generator towards images that are captioned similarly to the input text encoding. The weight of the CLIP guidance in the overall loss must balance image quality, text conditioning, and distribution diversity. The CLIP guidance is found to improve the FID and CLIP scores by about 20%, but it is only helpful up to 64x64 pixel resolution. The authors also apply the CLIP guidance to random 64x64 pixel crops for higher resolutions.
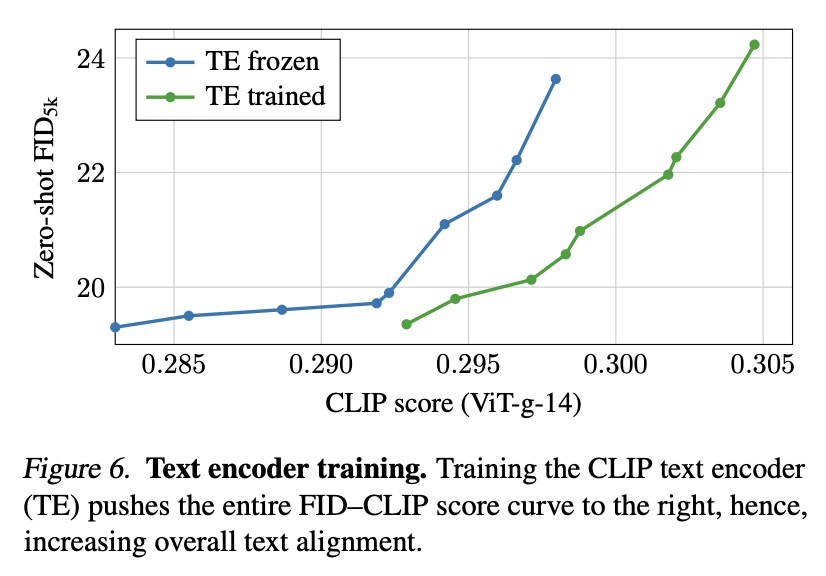
The authors propose a two-phase training approach for guiding the text encoder. In the primary phase, the generator is trainable and the text encoder is frozen. In the secondary phase, the generator is frozen and the text encoder becomes trainable. The text encoder is trained with a high weight of the CLIP guidance term to improve text alignment without introducing artifacts, which was not reported in earlier methods. The secondary phase can be much shorter than the primary phase, and after convergence, the authors continue with the primary phase.
The authors describe the use of explicit truncation to trade variation for higher quality in GANs. They track the mean of the mapping network’s output and interpolate the mapping network’s output with the mean during inference time using a scaling parameter. The combination of CLIP guidance and truncation improves the text alignment and quality of the generated images.

Results
The final model consists of ∼1 billion parameters; the authors did not observe any instabilities when increasing the model size. They train on a union of several datasets amounting to 250M text-image pairs in total.
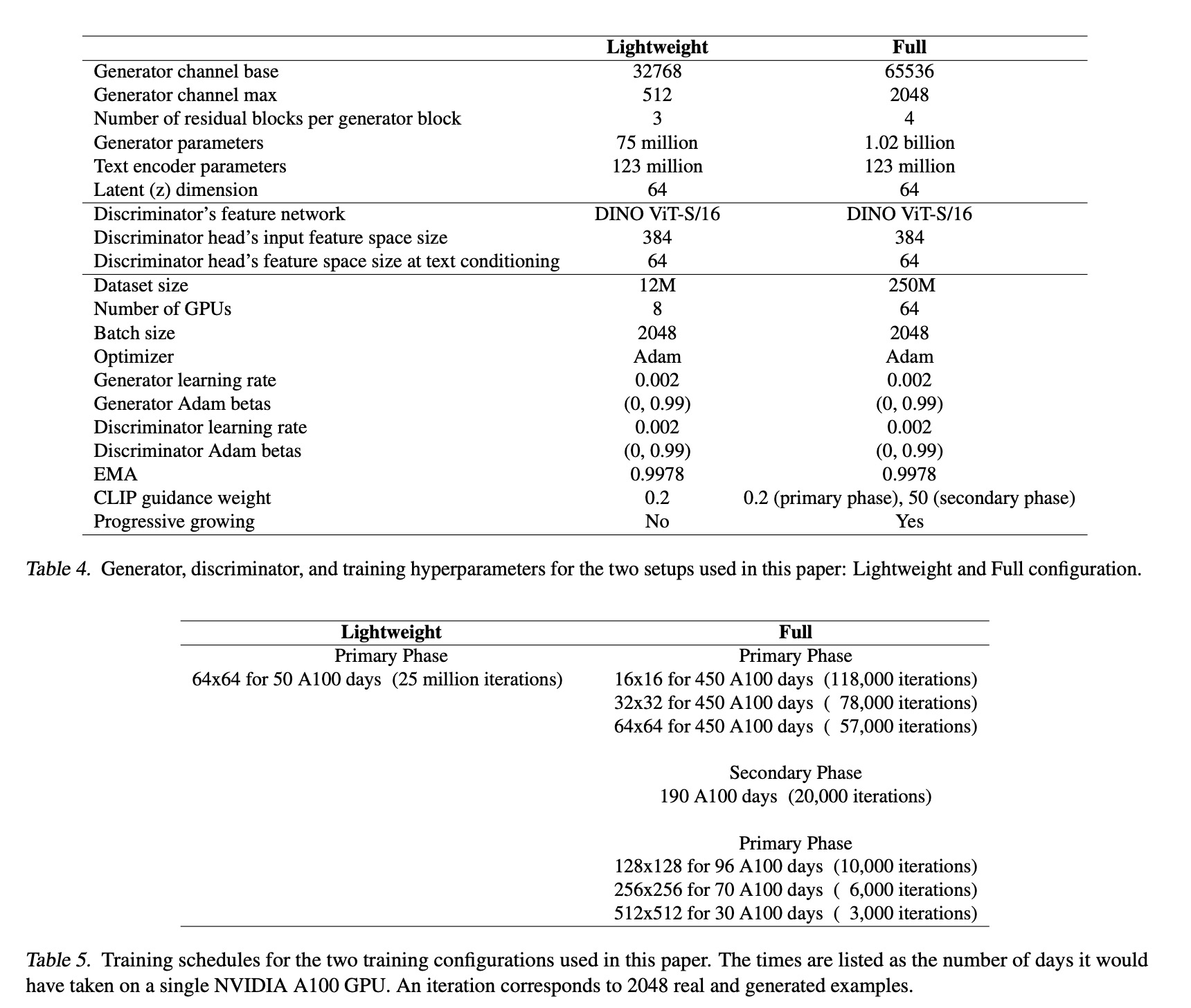
The total training time was four weeks on 64 A100 GPUs using a batch size of 2048. The primary phase was 3 weeks (resolutions up to 64×64), then the secondary phase was 2 days (text embedding), and finally, the primary phase was 5 days (resolutions up to 512×512). The total compute budget is about a quarter of Stable Diffusion’s.
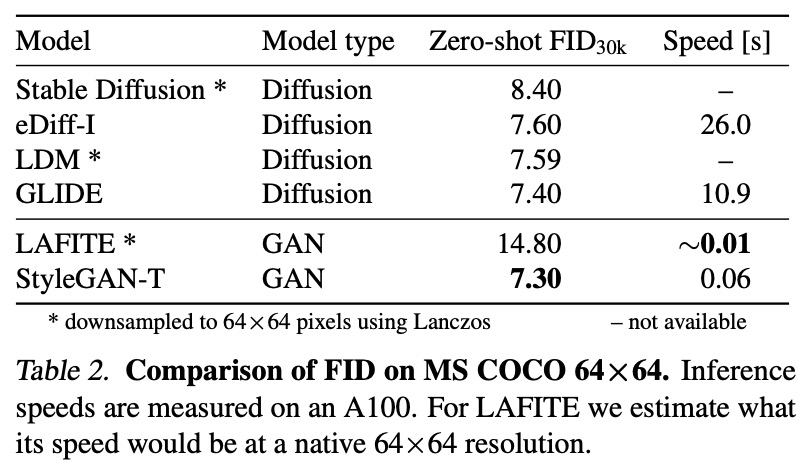
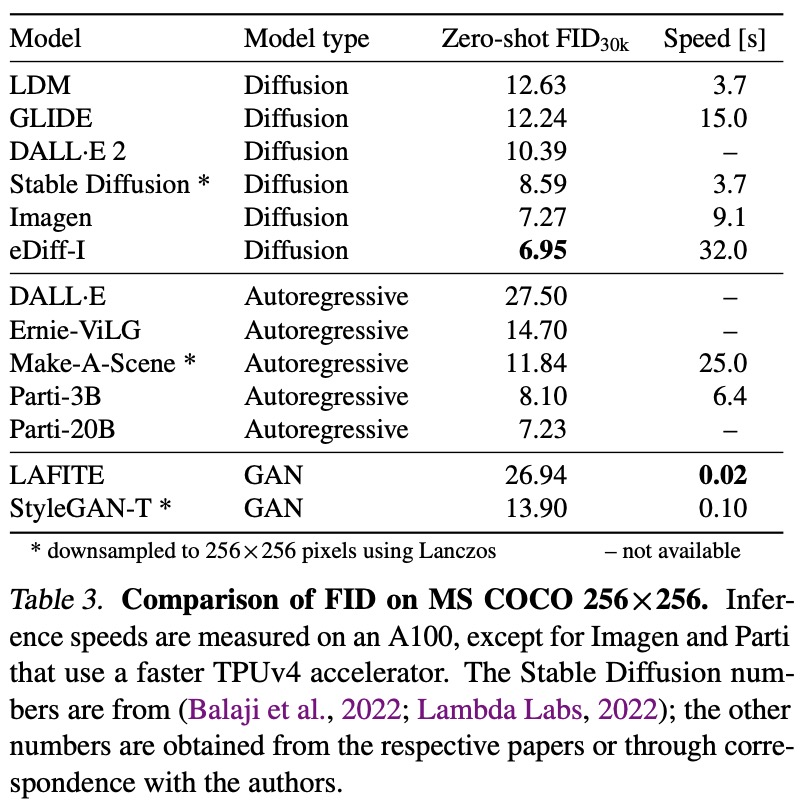


At low resolution, StyleGAN-T outperforms all other approaches in terms of output quality, while being very fast to evaluate. The authors notice that powerful superresolution model is crucial.
StyleGAN-T sometimes struggles in terms of binding attributes to objects as well as producing coherent text in images. This could be solved by using a bigger language model at the cost of slower runtime.
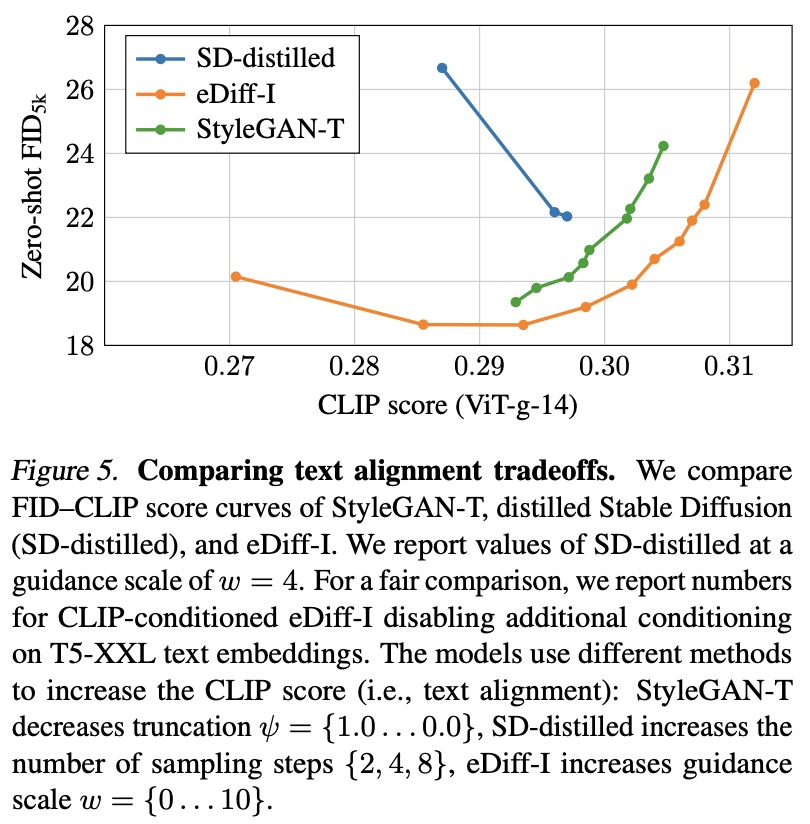
Guidance via CLIP loss is vital for good text alignment, but high guidance strength results in image artifacts. Possible solutions include retraining CLIP on higher-resolution data or revisiting the conditioning mechanism in the discriminator. Truncation is also mentioned as a way to improve text alignment, but alternative methods to truncation might further improve the results. The authors suggest future avenues for improvement, including improved super-resolution stages, personalizing diffusion models, and applying these methods to GANs.
paperreview deeplearning cv gan styletransfer