Paper Review: SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents

LLM-based agents face two key challenges in software engineering tasks: limited high-quality training data and outdated benchmarks due to data contamination. To overcome these, the authors have developed a scalable pipeline to extract real-world interactive Python tasks from GitHub, resulting in SWE-rebench - a dataset with over 21,000 tasks for training via reinforcement learning. This pipeline also enables a continuously updated, contamination-free benchmark. Evaluation shows that some LLMs perform worse on this new benchmark, suggesting their performance on existing benchmarks may be inflated.
The pipeline
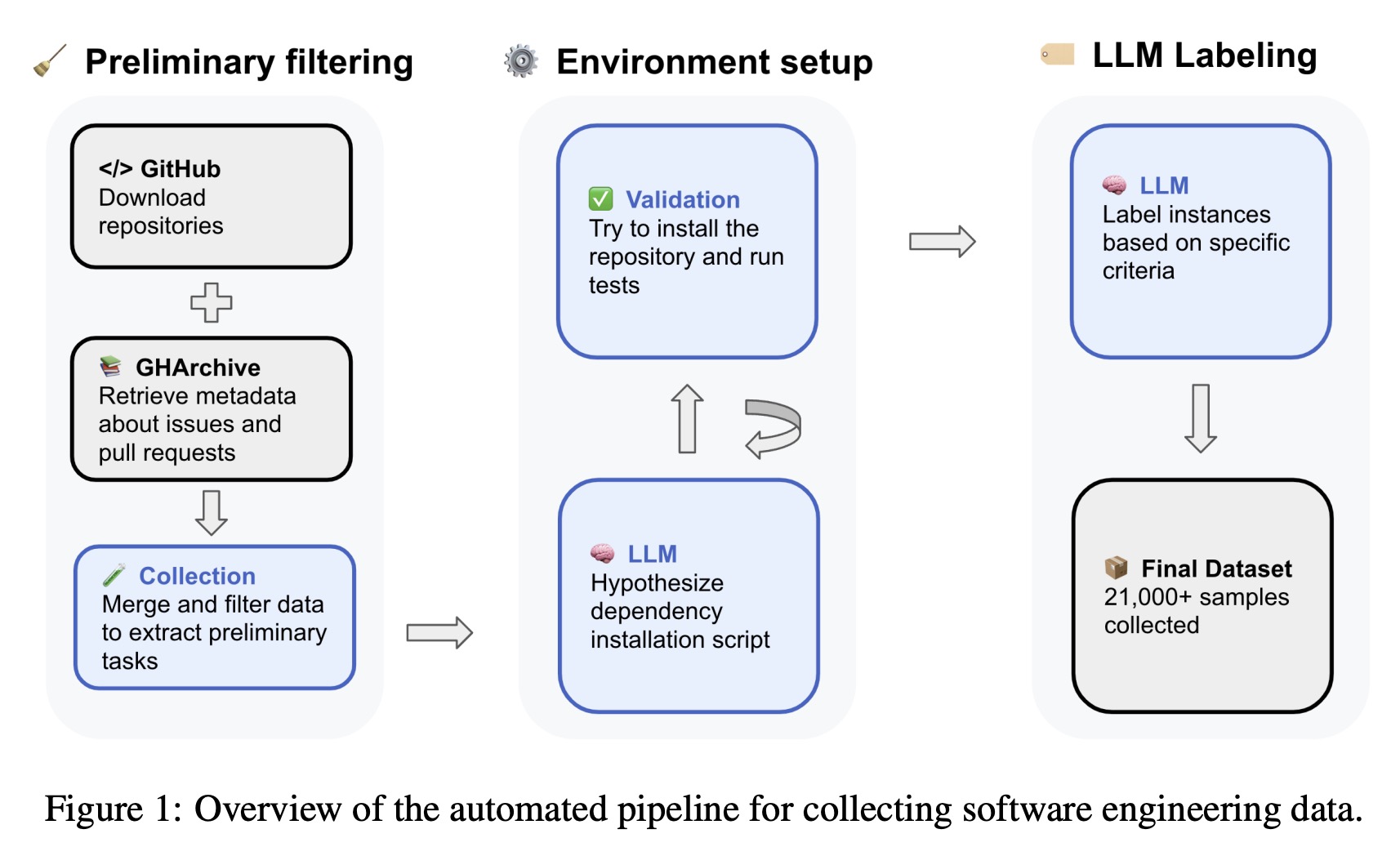
Preliminary task collection
Raw data is collected from GitHub Archive and cloned GitHub repositories. ~450k pull requests were gathered from over 30,000 Python-dominant, permissively licensed repositories. Filtering selects only those where the issue is resolved by a merged pull request affecting 1–15 files, includes non-trivial descriptions, and adds or modifies test files. The resulting 153,400 task candidates each consist of two parts: the solution patch (code changes) and the test patch (test changes).
Automated installation instructions configuration
Manual setup of environments (used in datasets like SWE-bench and SWE-Gym) limits scalability. To overcome this, the authors introduce an automated pipeline. After filtering, task instances are grouped by project versions using git tag, normalizing to major.minor format. A representative commit is chosen per group to define a shared environment. For each group or task, an agentless, LLM-driven process (using Qwen2.5-72B-Instruct) scans files like README.md and setup.py to extract installation instructions in structured JSON format. If setup or test execution fails, the LLM refines the recipe based on error logs. This method successfully configures environments for 31% of repositories.
Execution-based installation verification
To ensure task solvability and test integrity, each task undergoes execution-based verification in a containerized environment. It checks that: at least one test fails before applying the solution patch, all failing tests pass after applying the patch, tests that initially passed continue to pass. Only tasks meeting all three conditions are accepted.
Automated instance quality assessment
To ensure tasks are suitable for reinforcement learning, the dataset includes automated quality checks assessing: issue clarity (is the problem well-described), task complexity (how hard it is to solve), and test patch correctness (do tests properly validate the fix).
These labels are predicted using a fine-tuned Qwen2.5-72B-Instruct model trained on human-annotated data from SWE-bench Verified. The model achieves strong performance, especially on complexity and clarity, outperforming the base model. These labels are included as metadata, allowing users to filter tasks based on clarity, difficulty, and test quality more reliably than basic heuristics like file counts.
SWE-rebench consists of 21336 annotated Python SWE tasks.
SWE-rebench benchmark
Challenges in SWE agent benchmarking
Benchmarking SWE agents faces several issues:
- Data contamination: Public availability of SWE-bench since 2023 risks newer models being trained on its data, inflating scores.
- Scaffolding variability: Differences in prompts, agent frameworks, and evaluation strategies make it hard to compare LLMs fairly, as results often reflect engineering effort more than model capability.
- Lack of standardization: Evaluations are performed independently, with no centralized, verifiable process, leading to inconsistent or misleading reporting and reduced reproducibility.
- High performance variance: Due to stochastic behavior, results can vary widely between runs. Reporting only the best run can overstate a model’s actual performance.
Principles of SWE-rebench
SWE-rebench introduces a standardized, model-centric evaluation framework to address key issues in SWE agent benchmarking:
- Standardized scaffolding: All models are evaluated using the same minimal ReAct-style framework, fixed prompts, default generation settings, and 128K context (or max supported), ensuring fair comparison of core capabilities. Function-calling and model-specific tuning are excluded to focus on baseline ability within a shared structure.
- Transparent decontamination: Tasks are continuously updated, and evaluations are marked if they may include pre-release data for a given model.
- Stochasticity accounted for: Each model is run five times, with standard error and pass@5 reported to reflect variability.
This allows the benchmark to measure real-world SWE task-solving ability and instruction-following within a structured agent setup.
Results
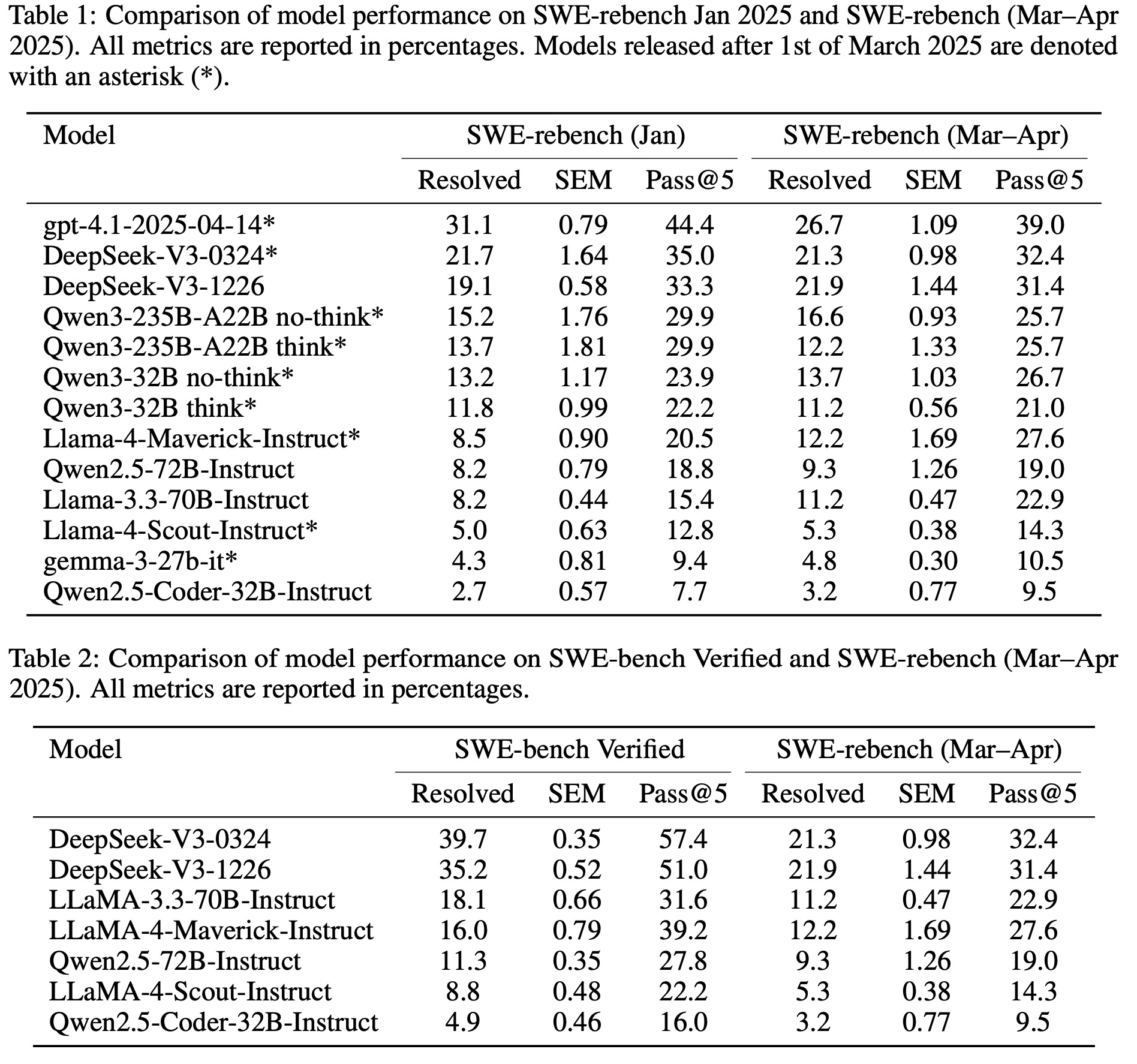
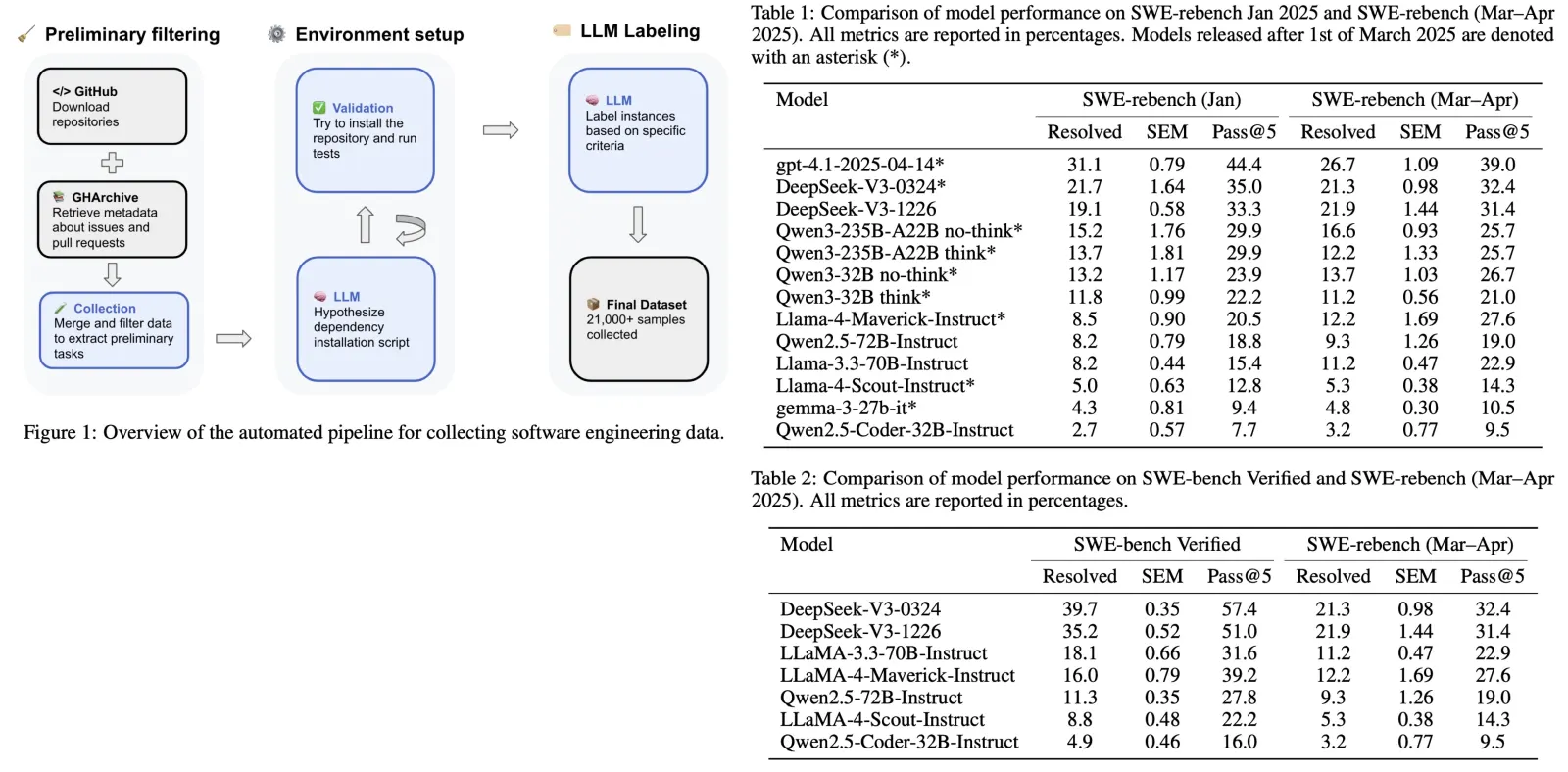
The authors use SWE-rebench to analyze model performance trends and potential data contamination effects by comparing results on tasks from January vs. March–April 2025 and against SWE-bench Verified. Key findings include:
- GPT-4.1 shows a noticeable performance drop on newer (March–April) tasks, suggesting sensitivity to task distribution changes.
- LLaMa-4-Maverick has strong pass@5 but low consistency, indicating high potential with unstable performance.
- Qwen2.5-Coder-32B-Instruct underperforms due to poor instruction following, hallucinated outputs, and formatting errors.
- Qwen3 models show similar performance with or without “think” mode, suggesting no clear benefit from explicit planning.
- DeepSeek-V3 models are the best-performing open-source models, maintaining top resolution and pass@5 scores across both SWE-rebench and SWE-bench Verified, demonstrating strong generalization.
Future work will focus on:
- Expanding beyond GitHub issues to include general pull requests,
- Refining task filtering for higher quality,
- Supporting additional programming languages (e.g., JavaScript, Java, C++),
- Continuously updating the benchmark with new tasks and broader model evaluations.
The goal is to accelerate open, reliable progress in AI for software engineering.
paperreview deeplearning llm evaluation