Paper Review: Swin Transformer V2: Scaling Up Capacity and Resolution
Code link (no V2 published yet)
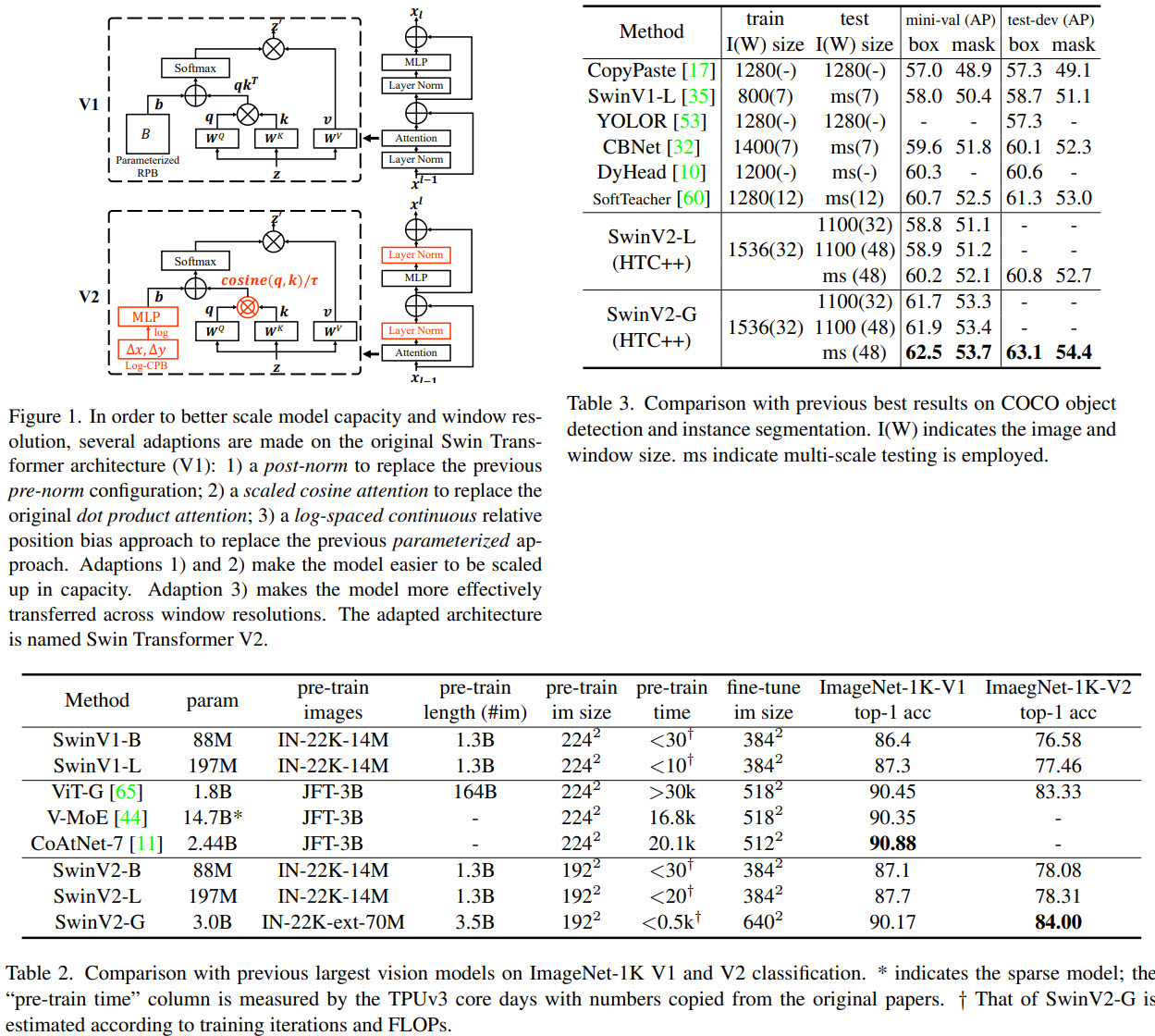
Swin Transformers was an interesting architecture that got great results on many benchmarks, and the authors present a newer version - it is scaled up to 3 billion parameters and can be trained on images up to 1536x1536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn’t always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
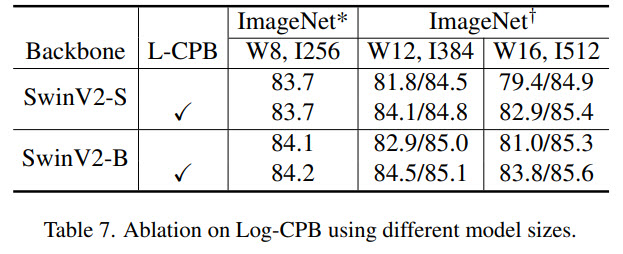
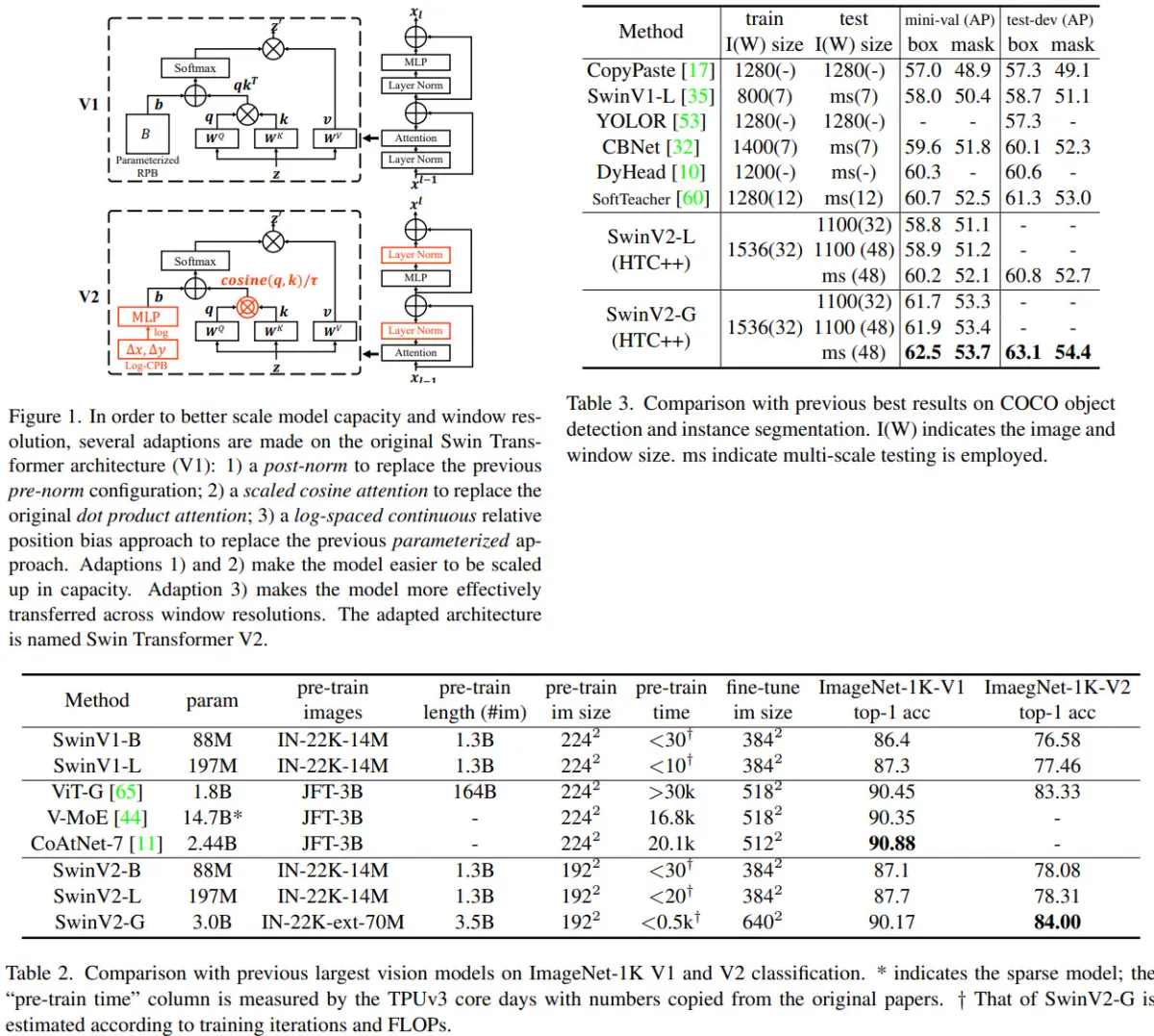
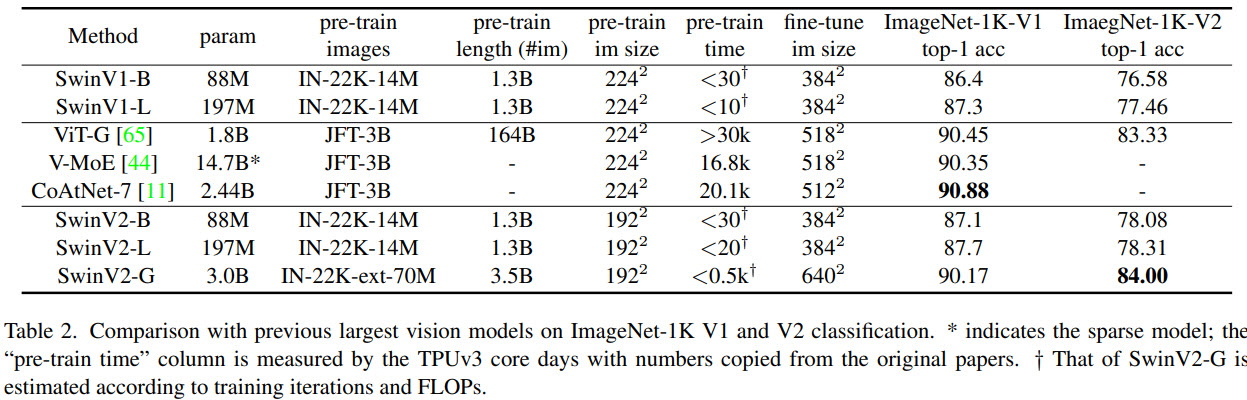
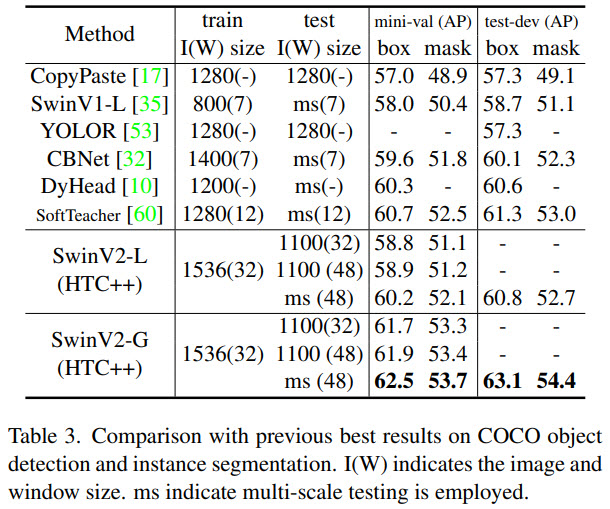
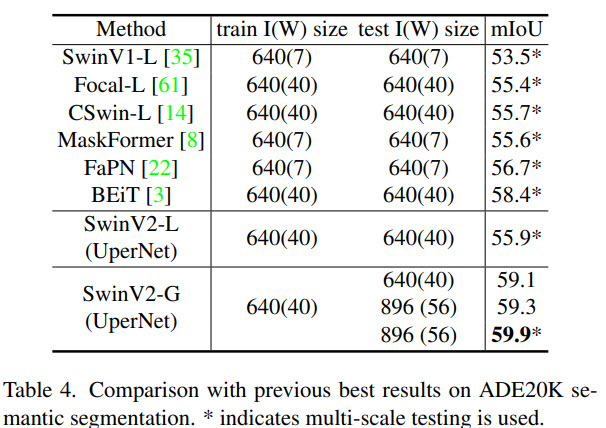
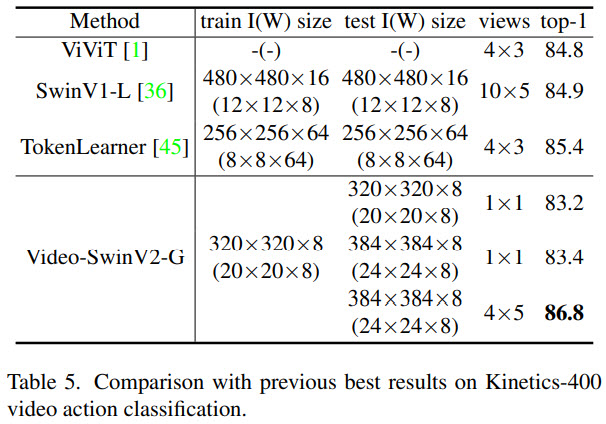
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
On the challenges of scaling up vision models
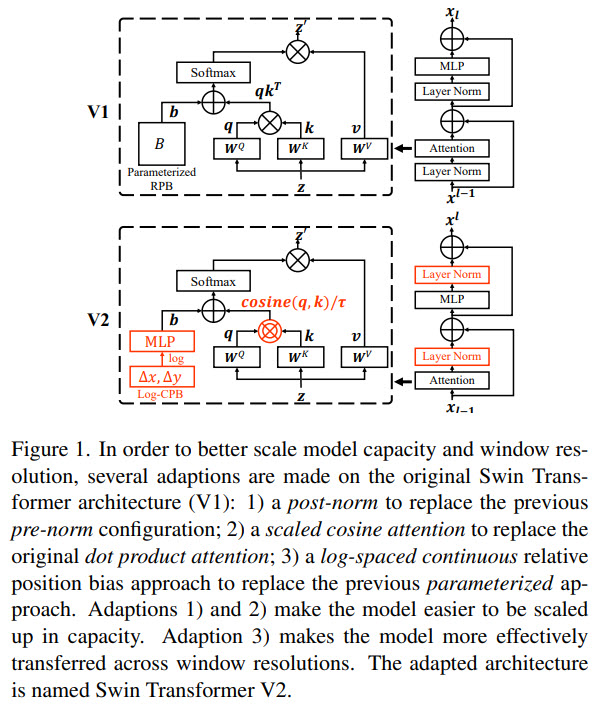
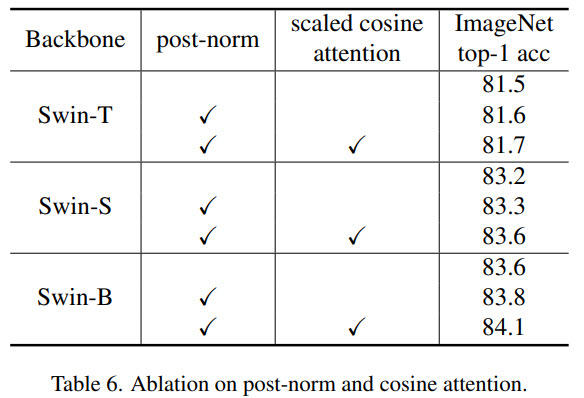
The authors say that their experiments with large vision models reveal an instability issue in training. Larger models have a larger discrepancy of activation amplitudes across layers. This is caused by residual connections and leads to the accumulation of activation values layer by layer. The authors propose a new normalization configuration (post-norm) to deal with this problem: it moves the LN layer from the beginning of each residual unit to the backend. They also use scaled cosine attention instead of a dot product attention - this makes the computation irrelevant to amplitudes of block inputs, and the attention values are less likely to fall into extremes.
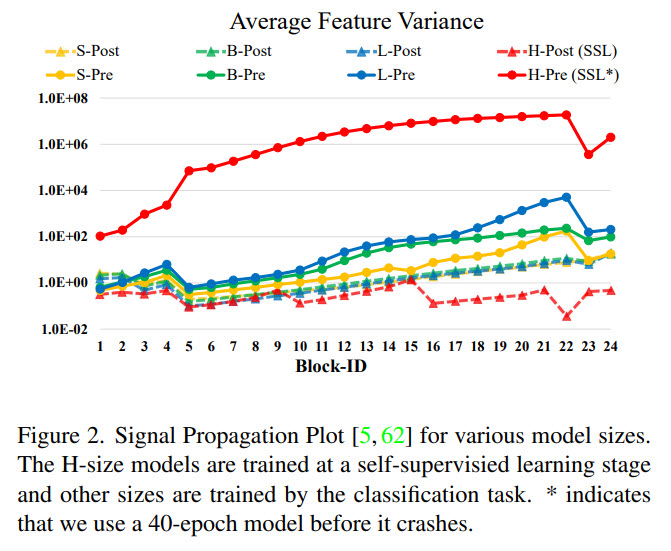
Another issue is that many downstream tasks require high-resolution input images or large attention windows, but the models are pretrained on lower-resolution images. The current common practice is to perform a bi-cubic interpolation of the position bias maps. The authors use a log-spaced continuous position bias (Log-CPB), which generates bias values for arbitrary coordinate ranges by applying a small meta-network on the log-spaced coordinate inputs. A pre-trained model will be able to freely transfer across window sizes by sharing weights of the meta-network, as the meta-network takes any coordinates. It is very important to transform the coordinates into the log-space so that the extrapolation ratio can be low even when differences between the windows sizes are large.
Yet another issue is that the scaling up of model capacity and resolution leads to high GPU memory consumption. Therefore, the authors use a number of tricks, for example, zero-optimizer, activation checkpointing, and a novel implementation of sequential self-attention computation.
An overview of Swin Transformer
The main idea of Swin Transformer is to combine the vanilla Transformer encoder architecture with several visual signal priors: hierarchy, locality, and translation invariance.
The original Swin Transformer uses a pre-normalization configuration.
Swin Transformer introduces an additional parametric bias term accounting for the geometric relationship in self-attention computation:

It accounts for relative spatial configurations of visual elements.
When transferring across different window sizes, the learned relative position bias matrix in pre-training is used to initialize the bias matrix of a different size in fine-tuning by a bi-cubic interpolation approach.
Scaling Up Model Capacity
Most of the changes were already described higher.
Post-normalization results in much lower activation amplitudes.
Scaled cosine attention:

Scaling Up Window Resolution
- The continuous position bias approach uses a small meta-network (2-layer MLP with ReLU) on the relative coordinates;
- Log-spaced coordinates instead of linear-spaced ones. For example, when transferring from 8x8 to 16x16 window, the extrapolation ratio becomes 0.33x instead of 1.14x;
Other improvements
- Zero-Redundancy Optimizer (ZeRO). Usually, optimizers in the data-parallel mode broadcast the model parameters and optimization states to every GPU or a master node. Instead, in ZeRO, the model parameters and optimization states are divided and distributed to multiple GPUs. The authors use the DeepSpeed framework and the ZeRO stage-1 option;
- Activation check-pointing reduces training speed by almost 30%;
- Sequential self-attention computation instead of using the previous batch computation approach reduces memory consumption at the cost of a small decrease of the training speed;
They train the model on ImageNet-22K, enlarging the dataset by 5 times, and use self-supervised learning to better exploit this data.
The results
Ablations