Paper Review: SwinIR: Image Restoration Using Swin Transformer
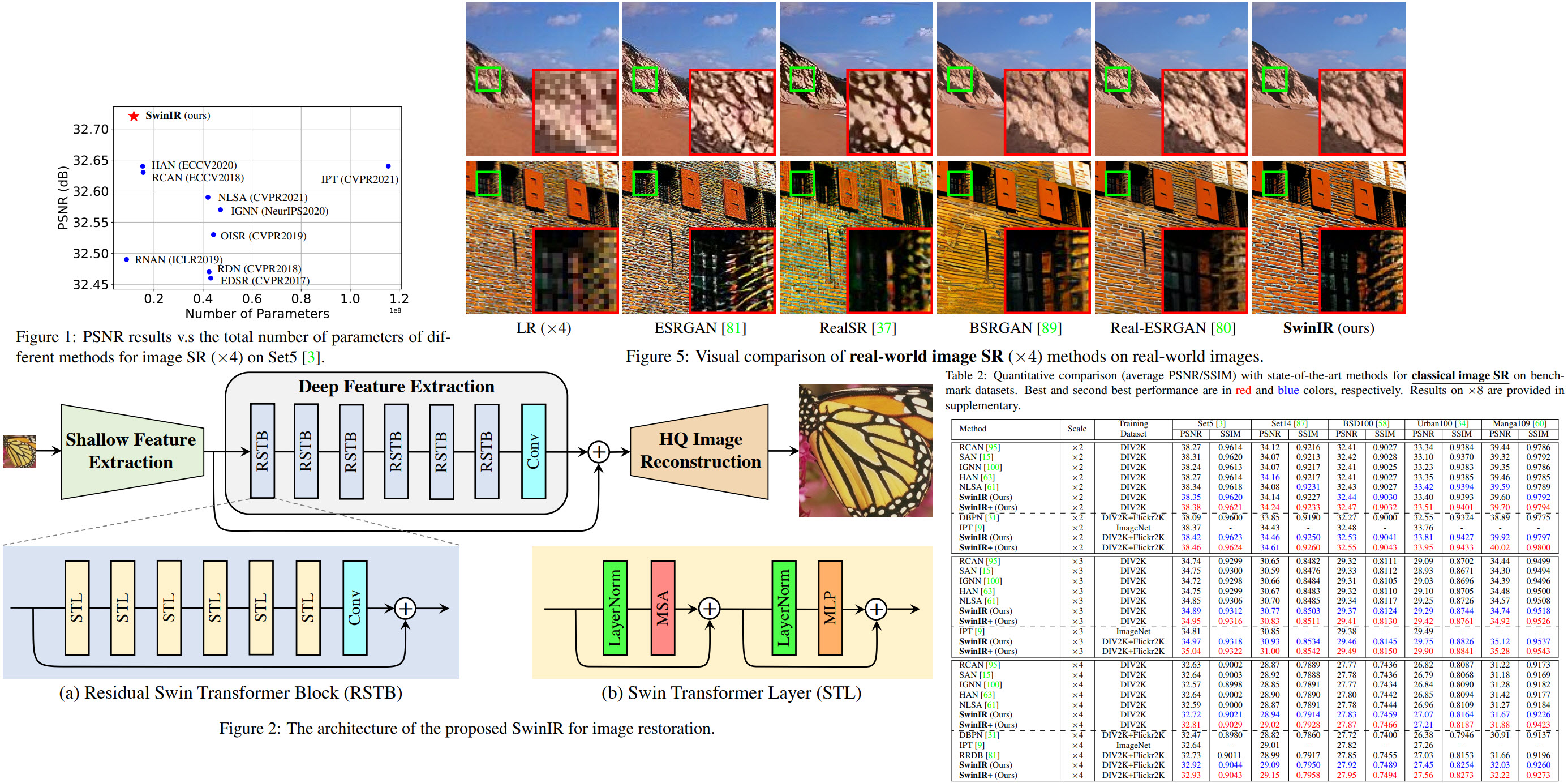
Image restoration is a vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images).
The authors use a model based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14∼0.45dB, while the total number of parameters can be reduced by up to 67%.
The approach
Compared with widely used CNN-based image restoration models, transformer-based SwinIR has several benefits:
- content-based interactions between image content and attention weights, which can be interpreted as spatially varying convolution;
- long-range dependency modeling is enabled by the shifted window mechanism;
- better performance with fewer parameters;
The architecture
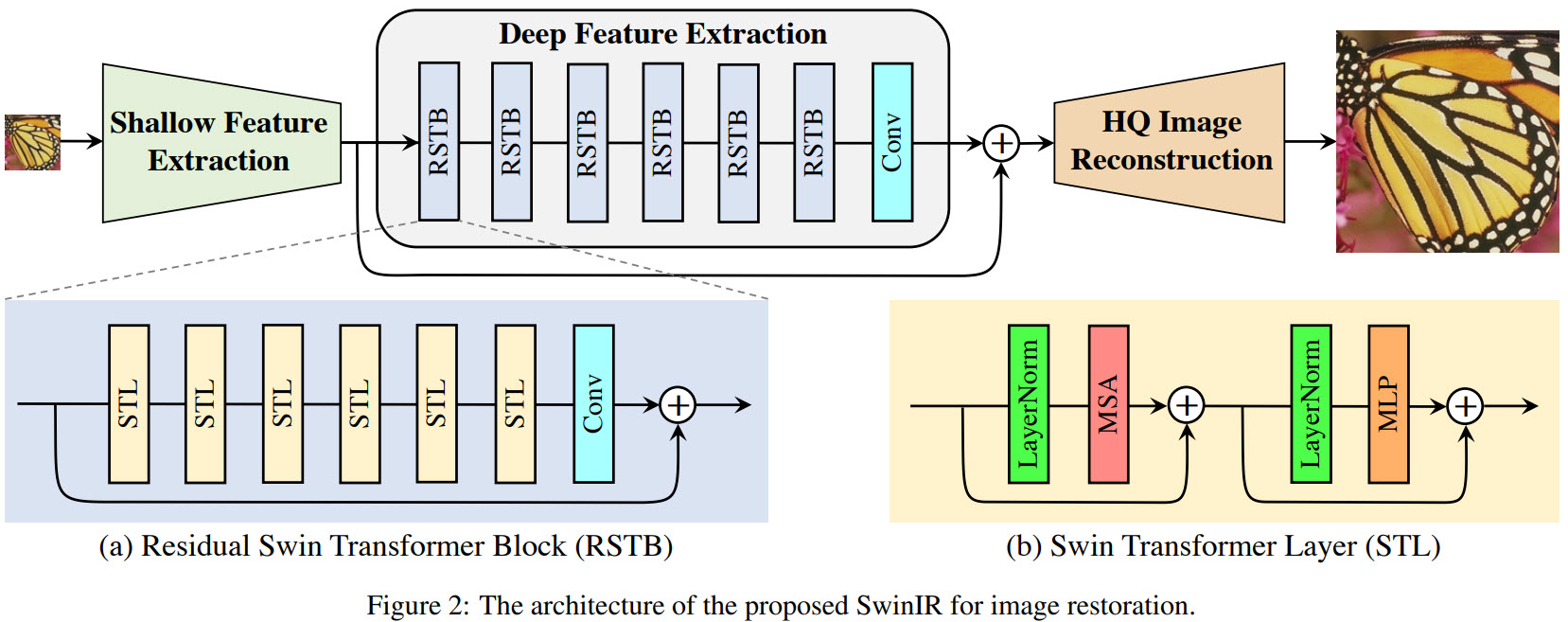
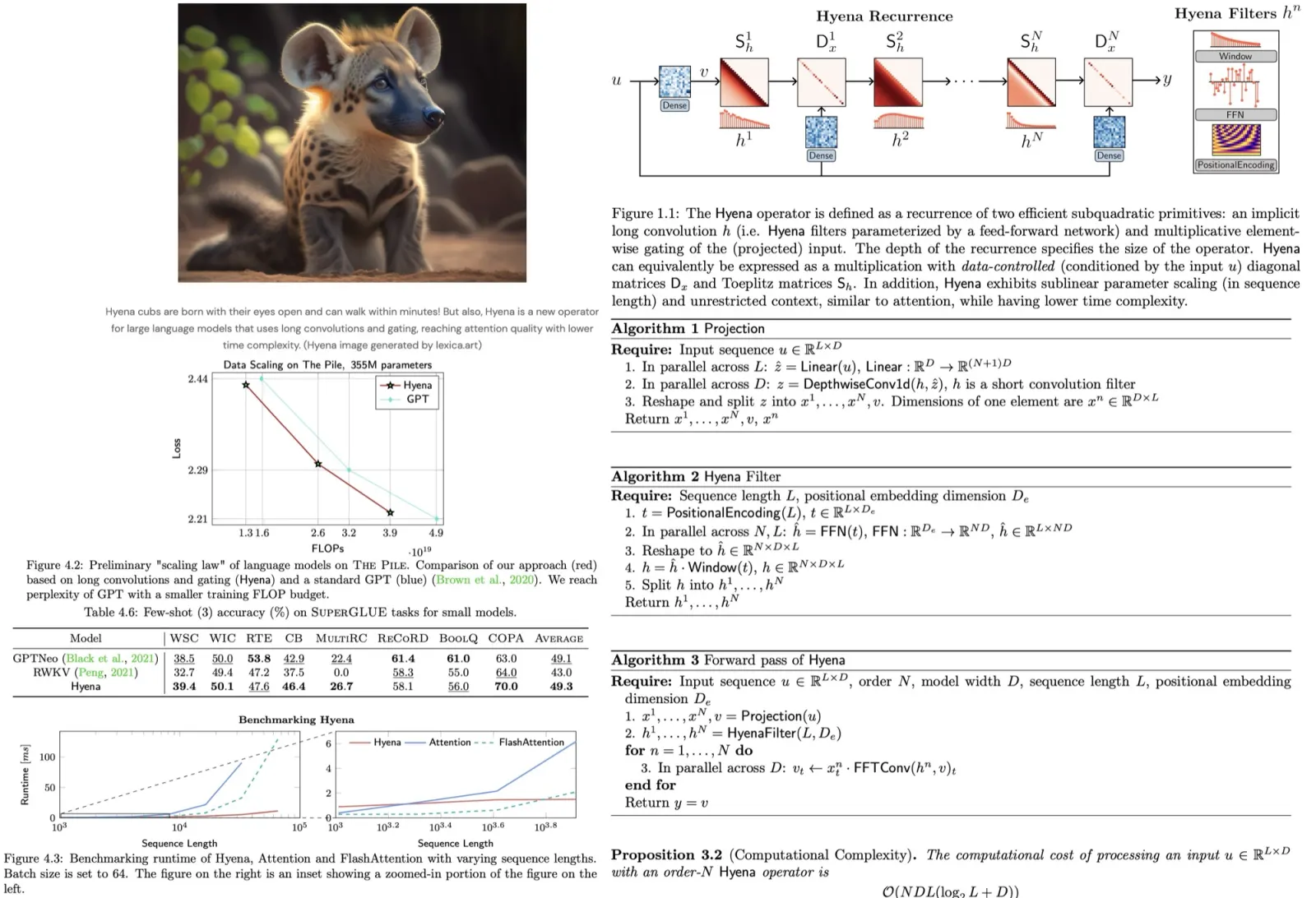
SwinIR consists of three modules: shallow feature extraction, deep feature extraction, and high-quality image reconstruction modules:
- Shallow feature extraction module uses a convolution layer (3x3) to extract shallow features that are fed into both following layers;
- Deep feature extraction module is composed of K residual Swin Transformer blocks (RSTB), each of which utilizes several Swin Transformer layers for local attention and cross-window interaction. The authors add a convolutional layer at the end of the block for feature enhancement and use a residual connection to provide a shortcut for feature aggregation;
- Both shallow and deep features are fused in the reconstruction module for high-quality image reconstruction. Different tasks use different reconstruction modules. For super-resolution, a sub-pixel convolutional layer is used. For other tasks, they use a single convolutional layer. Besides, they use residual learning to reconstruct a residual between LQ and HQ images instead of the HQ image;
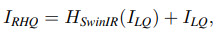
Losses
- For classical and lightweight image SR the loss is a simple L1;
- For real-world SR, they use a combination of pixel loss, GAN loss, and perceptual loss;
- For image denoising and JPEG compression artifact reduction, they use the Charbonnier loss;
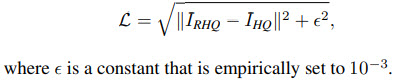
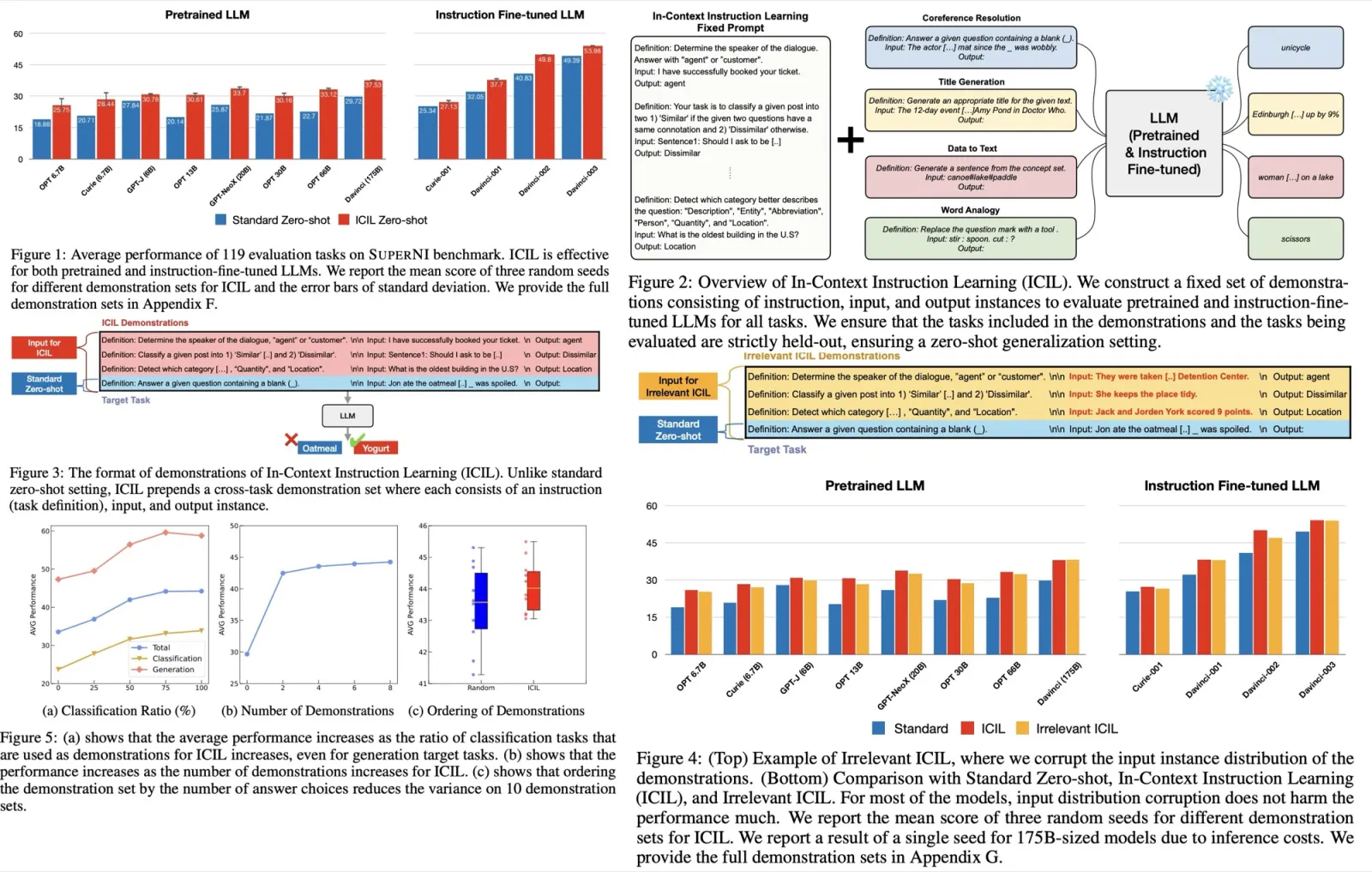
Results
Better and smaller models for all tasks.
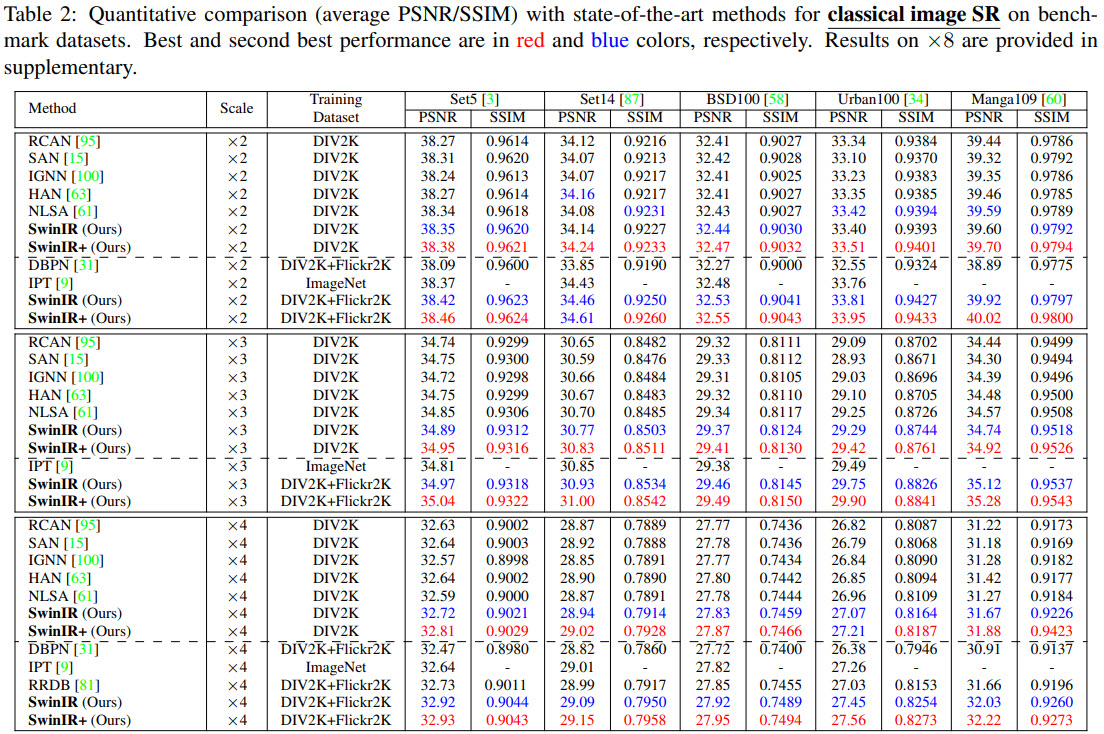

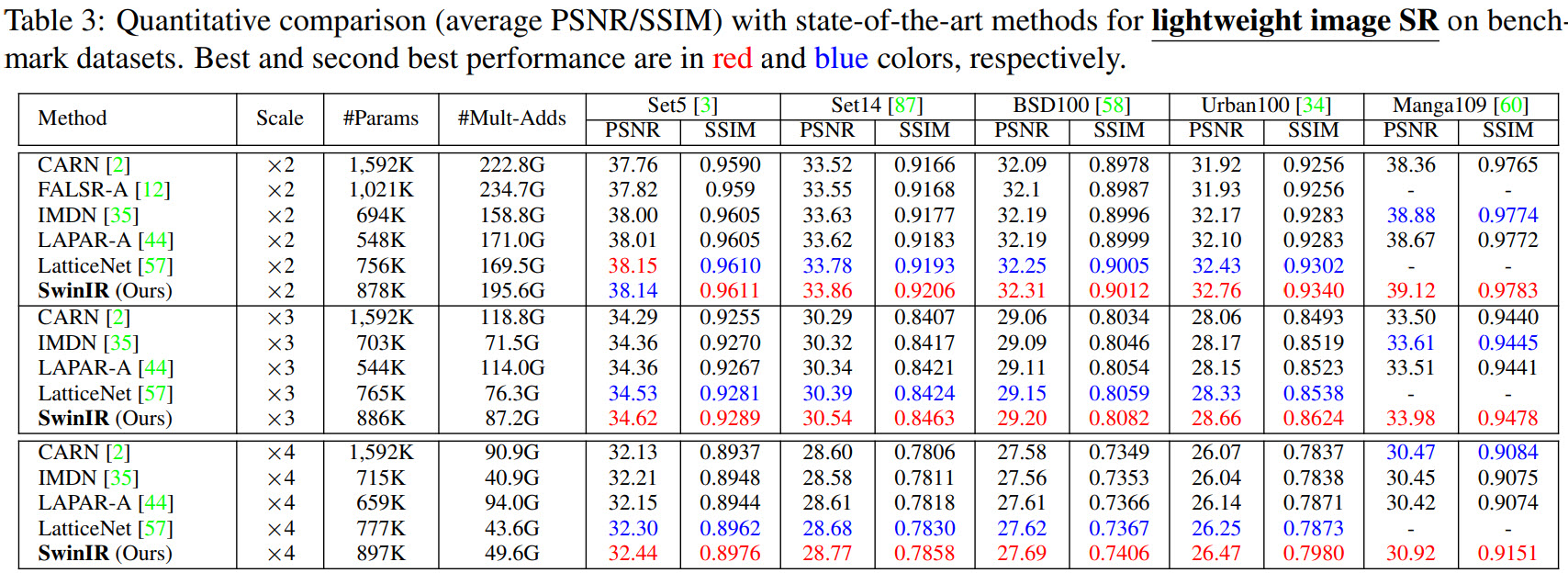

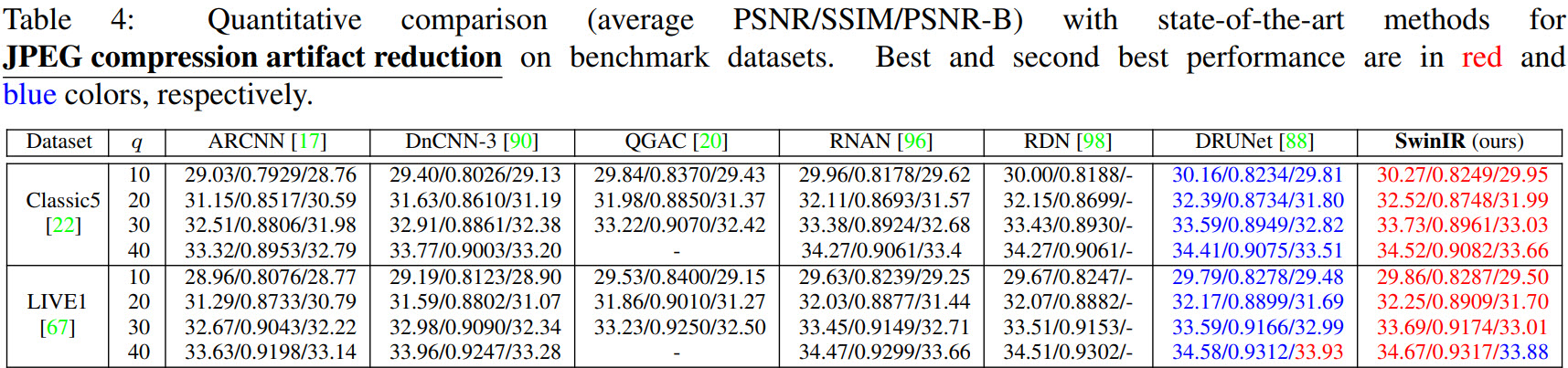
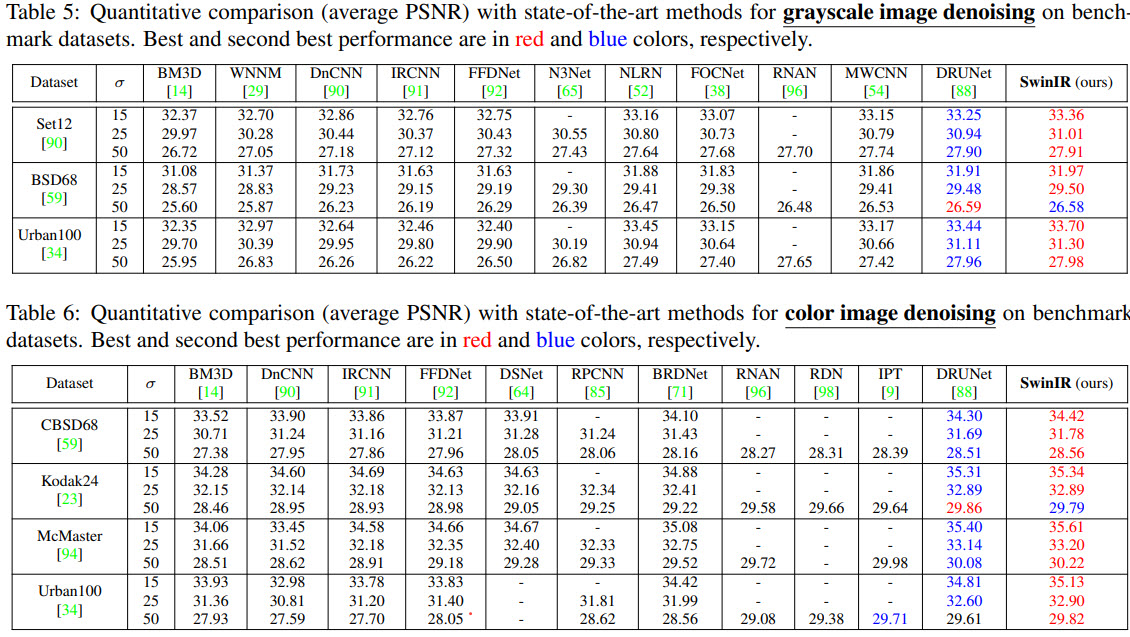
Ablations
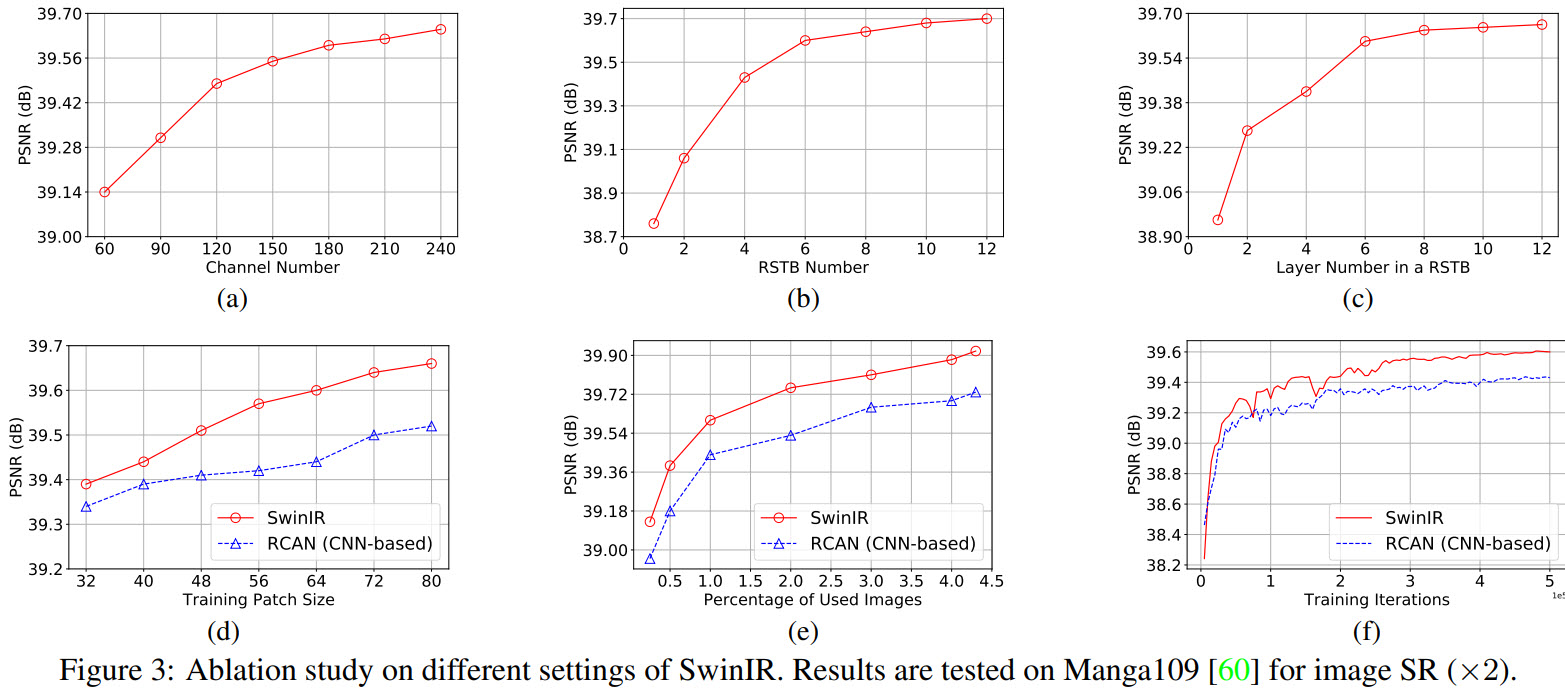

- The higher the channel number, RSTB number, and STL number in a RSTB, the better;
- The bigger the image patches, the better;
- Converges better and faster than CNN models;