Paper Review: TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Recent trends have seen the introduction of retrieval-augmented tabular DL models, which use related data points to make more accurate predictions. However, current implementations of this approach have shown little improvement over non-retrieval based models. The authors propose a new model, TabR, which improves on existing models by adding an attention-like retrieval component. The specifics of this attention mechanism, previously unexplored, have been found to significantly boost performance in tabular data tasks. The TabR model shows superior average performance compared to other DL models for tabular data, sets new standards on several datasets, and even surpasses GBDT models in some instances, specifically on datasets that are typically seen as GBDT-friendly.
TabR
Preliminaries
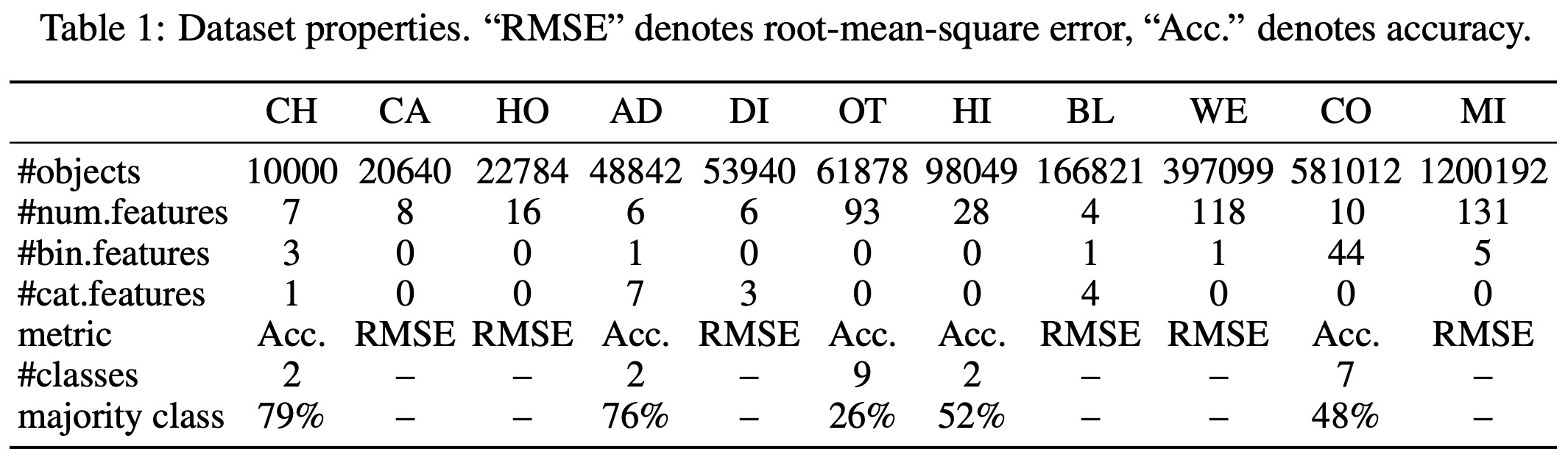
The dataset is represented as pairs of features and labels, {(xi, yi)} where xi and yi are the features and label of the i-th object, respectively. Three types of tasks are considered: binary classification, multiclass classification, and regression.
The dataset is divided into training, validation, and testing parts, and the model makes predictions for “input” or “target” objects. When a retrieval technique is used, retrieval is done within a set of “context candidates” or “candidates”, with the retrieved objects referred to as “context objects” or simply “context”. The same set of candidates is used for all input objects.
The experimental setup involves tuning and evaluation protocols which entail hyperparameter tuning and early stopping based on validation set performance. The best hyperparameters are then tested on the test set averaged over 15 random seeds, with standard deviations accounted for in comparison of algorithms.
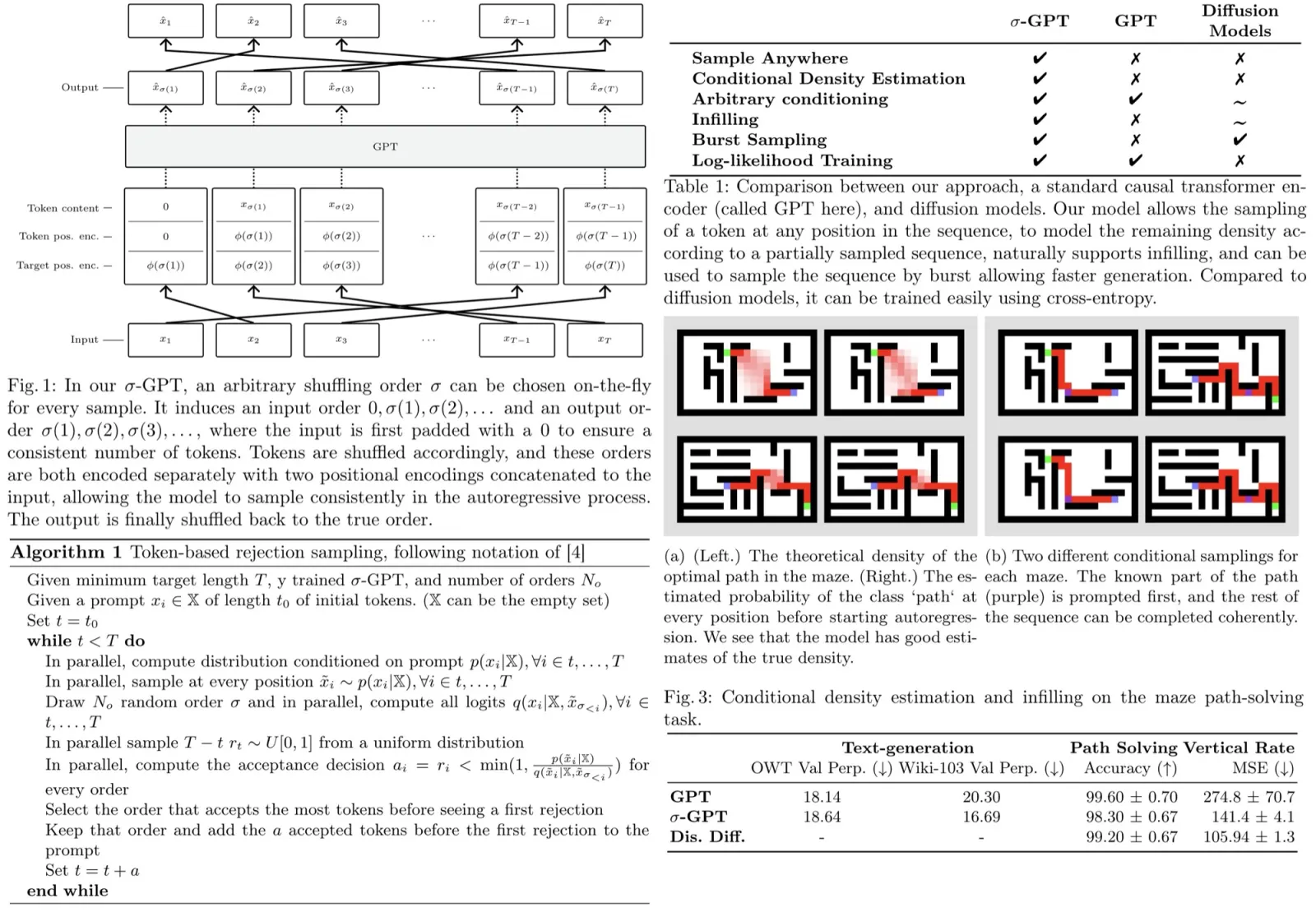
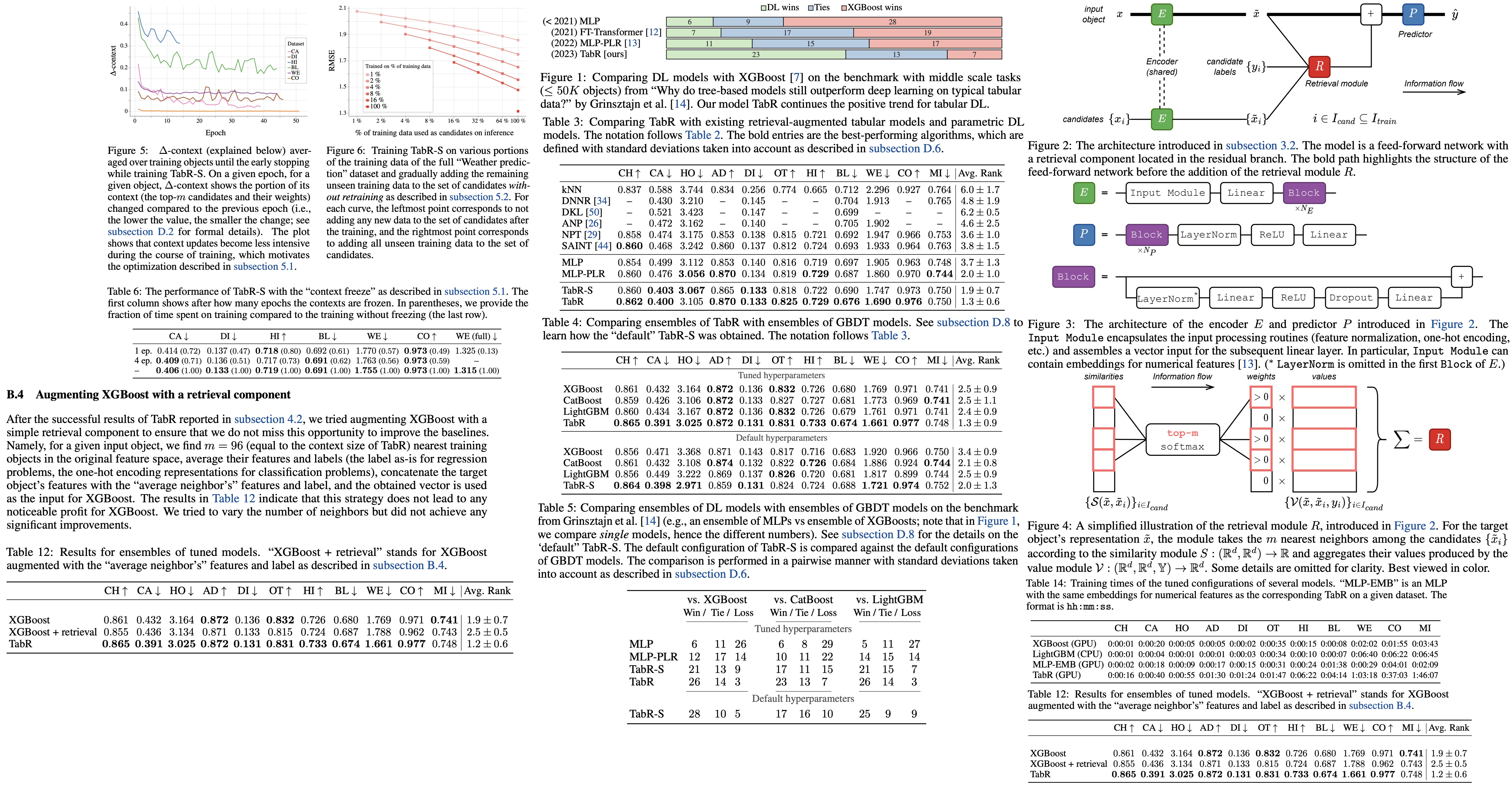
Overview of the architecture
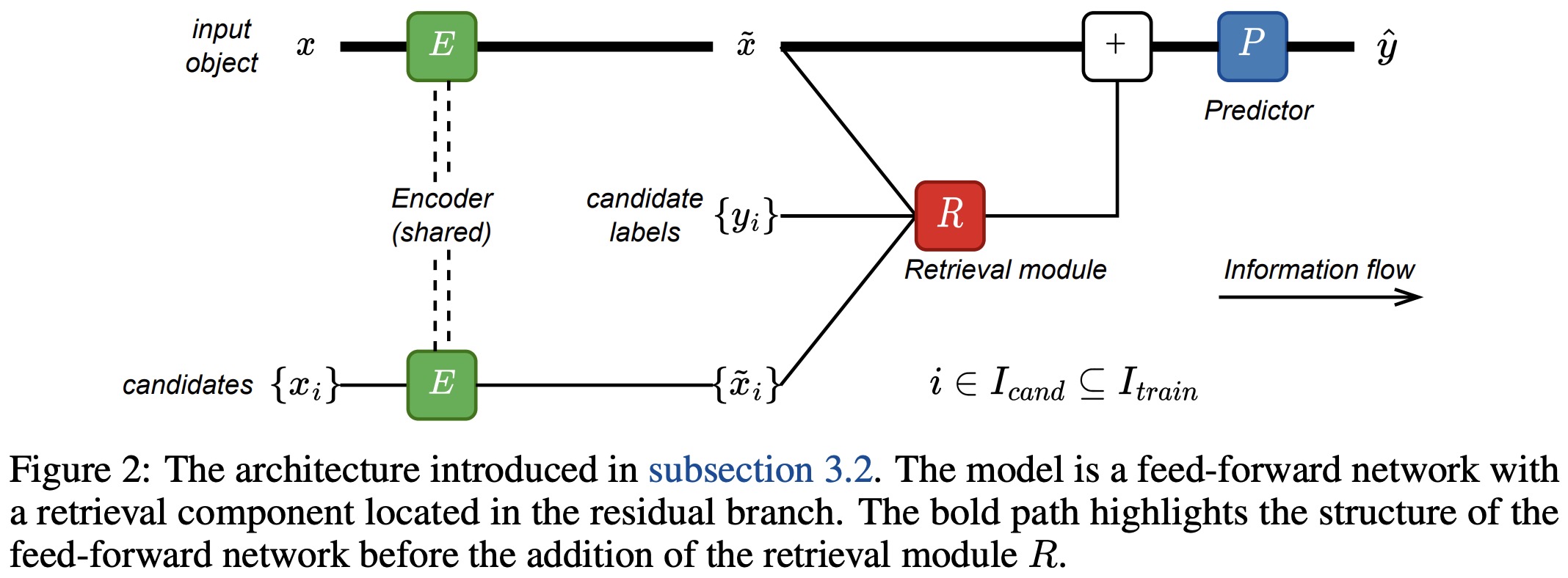
The authors aim to integrate retrieval functionality into a traditional feed-forward network for tabular data problems. This is done in the absence of established architectural blocks for creating deep retrieval-based models for such data. The process involves passing a target object and its context candidates through an encoder, then a retrieval component enriches the target object’s representation, and finally, the predictor makes the prediction.
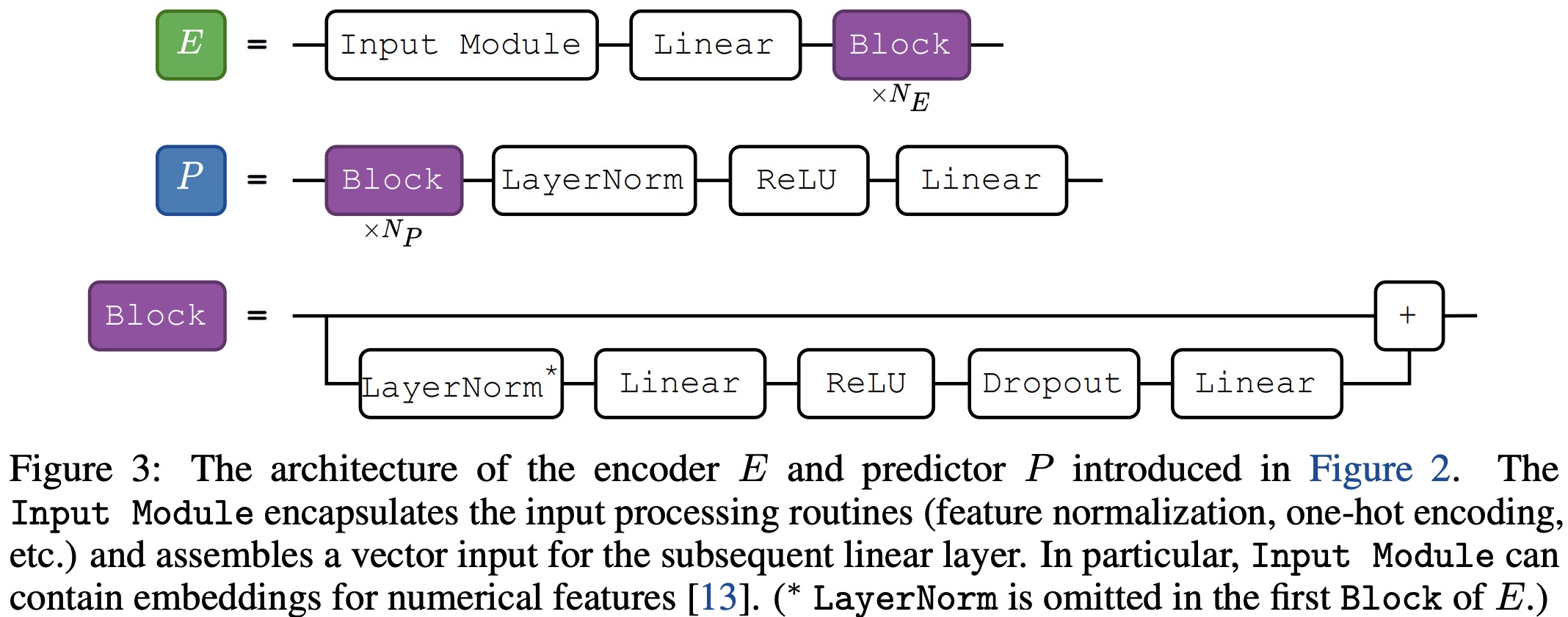
The encoder and predictor modules are kept simple as they aren’t the focus of this work. The retrieval module, on the other hand, operates over the representation of the target object and the representations and labels of the candidates. This module can be seen as a generalized version of the attention mechanism.
The process involves several steps:
- normalize the representations if the encoder contains at least one block;
- define context objects based on similarity to the target object;
- assign weights to context objects based on the softmax function over their similarities;
- define the values of the context objects;
- output the weighted aggregation using the values and weights.
The context size is set to a relatively large value of 96, with the softmax function automatically selecting the effective context size.
Implementing the retrieval module
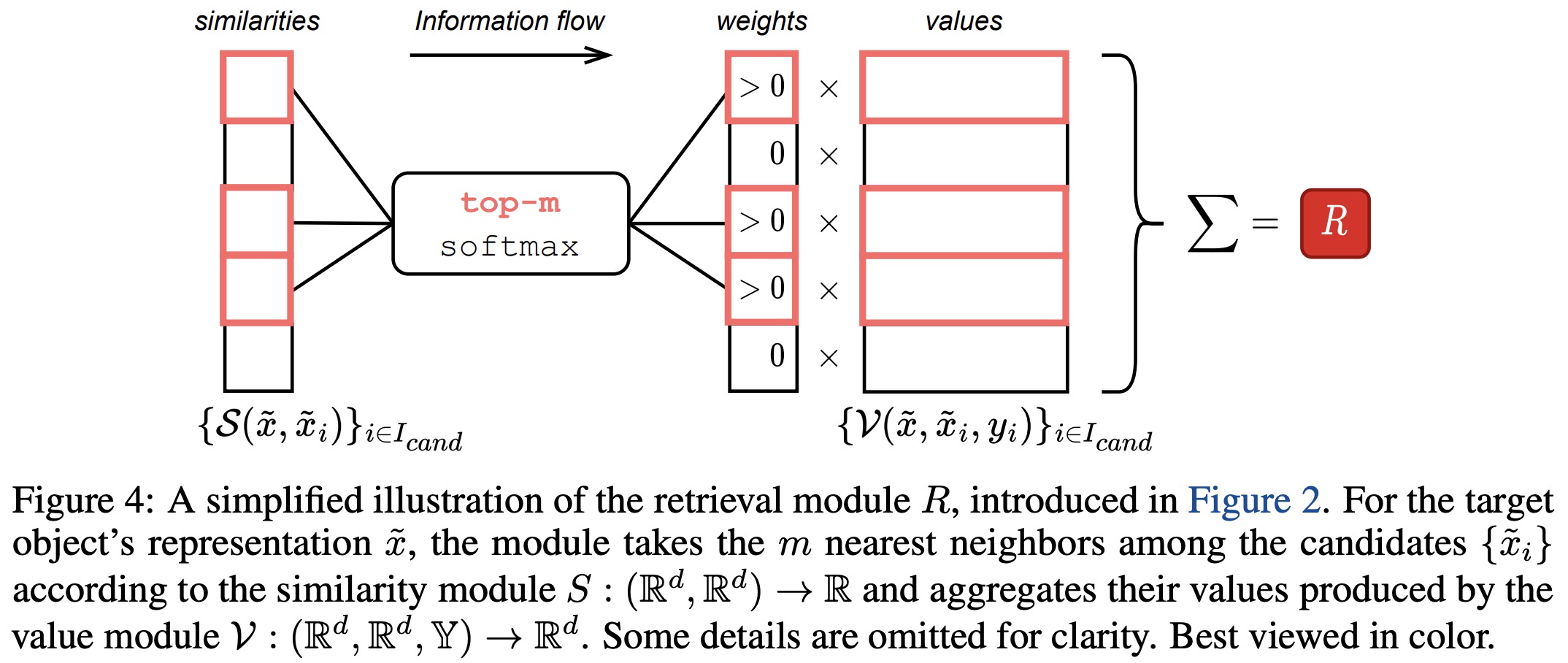
The authors explore different implementations of the retrieval module, particularly the similarity and value modules. The final model is obtained in several steps.
- Step-0: The authors evaluate the similarity and value modules of vanilla attention, finding that the configuration performs similarly to a Multi-Layer Perceptron (MLP), thus not justifying the usage of the retrieval component.
- Step-1: They then add context labels into the value module, but find that this does not result in improvements, indicating that the similarity module of vanilla attention may be the bottleneck.
- Step-2: To improve the similarity module, the authors remove the notion of queries and replace the dot product with the L2 distance. They observe that this adjustment leads to a significant jump in performance on several datasets.
- Step-3: The value module is then improved, with inspiration taken from the recently proposed DNNR (a generalized version of the kNN algorithm for regression problems). The new value module results in further performance improvements.
- Step-4: In the final step, the authors create the model TabR. They observe that omitting the scaling term in the similarity module and not including the target object to its own context (using cross-attention) leads to better results on average. The resulting model, TabR, offers a robust approach to the retrieval-based tabular deep learning problems.
Limitations.
The authors highlight two main limitations of the TabR model:
- As with all retrieval-augmented models, the usage of real training objects for predictions could pose issues from an application perspective, such as privacy and ethical concerns.
- The retrieval component of TabR, although more efficient than elements in prior works, still incurs noticeable overhead compared to fully parametric models. Consequently, it may not scale efficiently to handle truly large datasets.
Experiments
The authors compare TabR with existing retrieval-augmented solutions and state-of-the-art parametric models. Besides the fully-configured TabR, they also employ a simplified version, TabR-S, which does not use feature embeddings, has a linear encoder, and a one-block predictor.
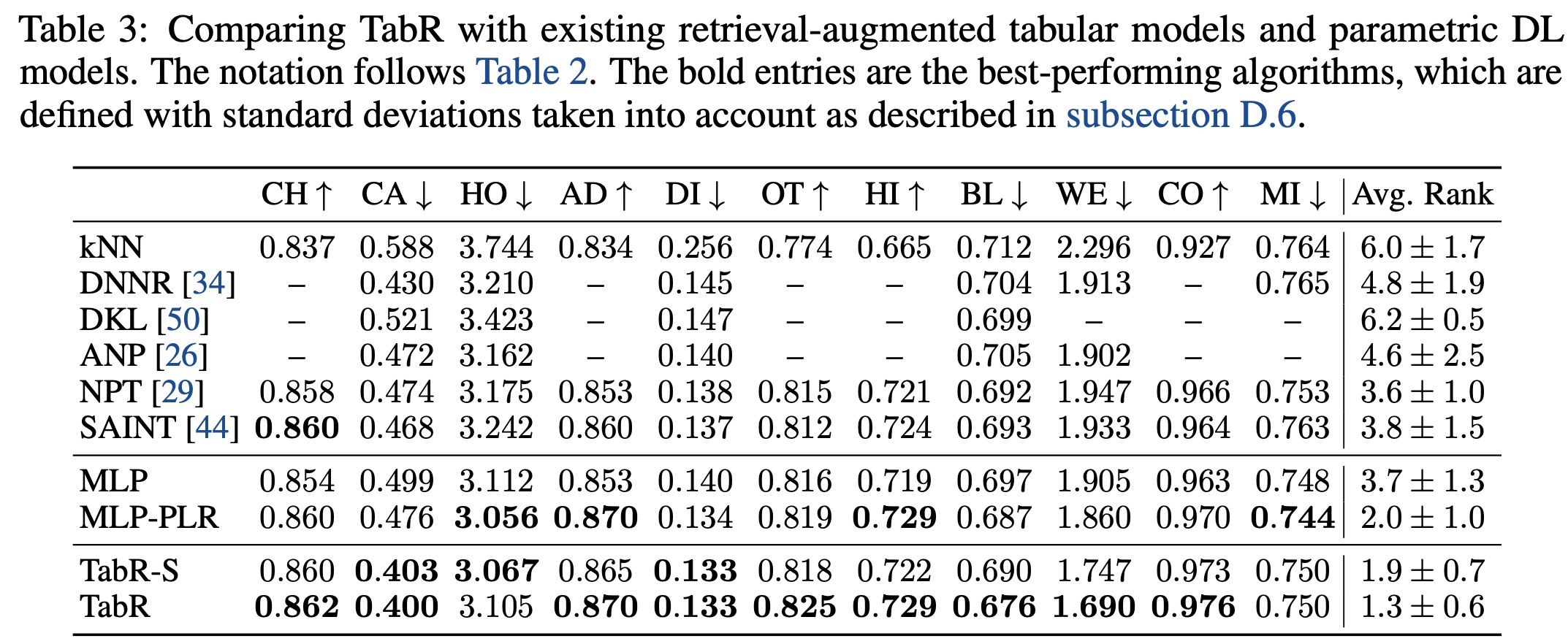
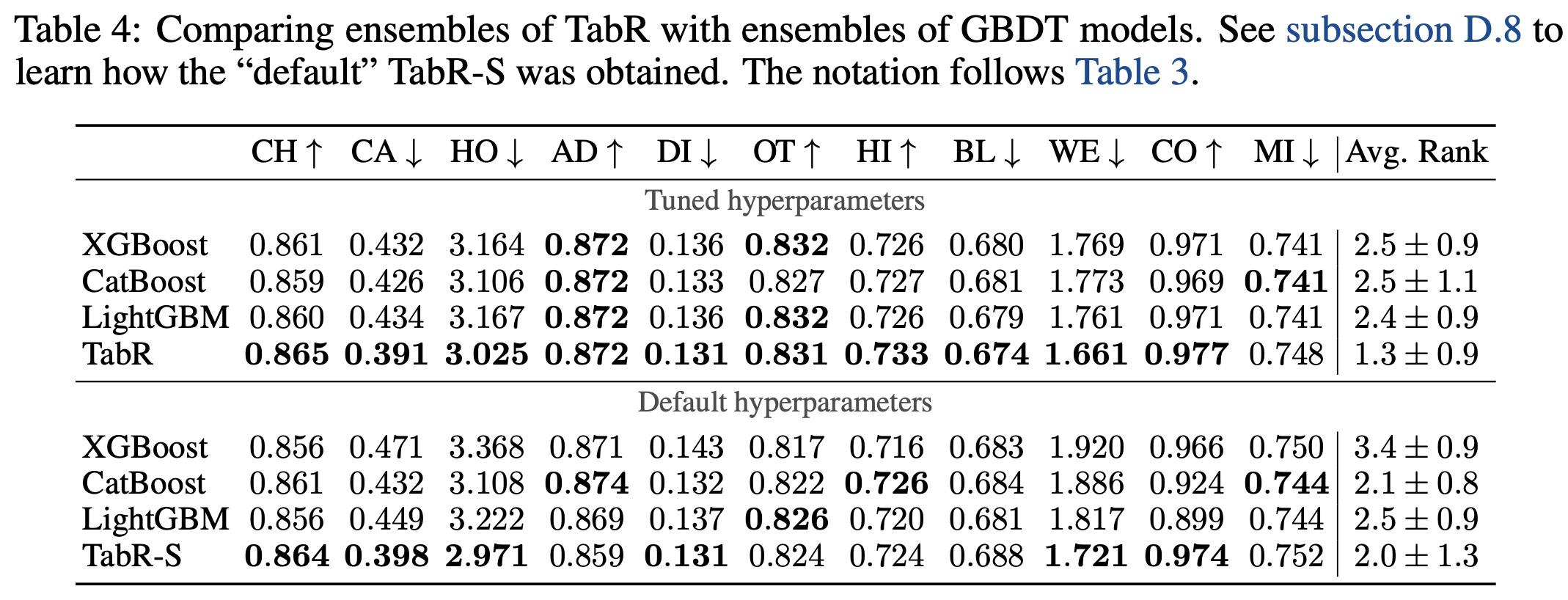
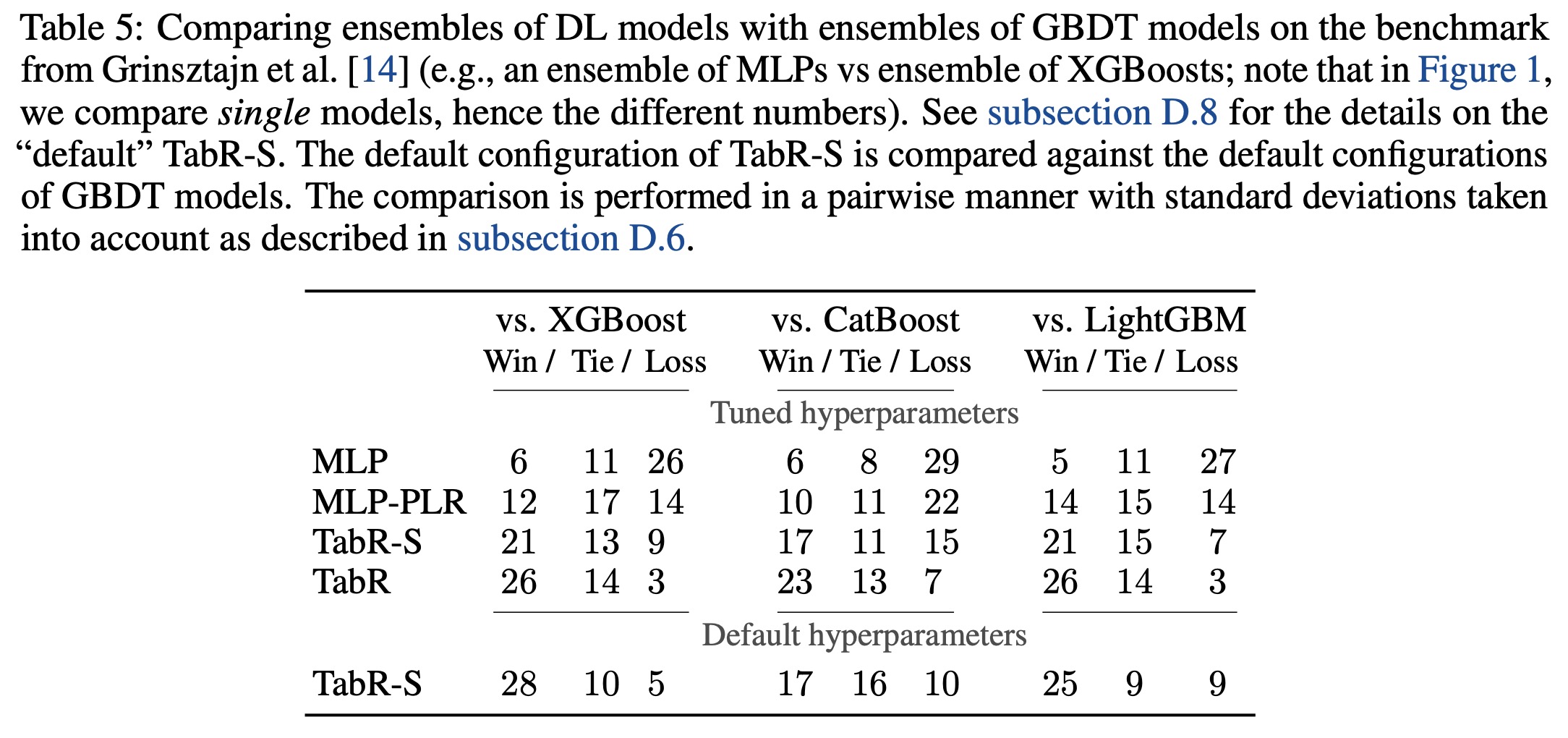
- Comparisons with fully parametric DL models showed that TabR outperformed most of them on several datasets and was competitive on the rest, except for the MI dataset. It proved to be the only retrieval-based model providing a significant boost over Multilayer Perceptron (MLP) on many datasets.
- When compared to GBDT models, tuned TabR also showed noticeable improvements on several datasets and remained competitive on the rest, except for the MI dataset. Even on a benchmark designed to illustrate the superiority of GBDT over parametric DL models, TabR outperformed the GBDT models on average.
In summary, TabR establishes itself as a robust deep learning solution for tabular data problems, demonstrating strong average performance, and setting new benchmarks on several datasets. Its retrieval-based approach holds good potential, and it can notably outperform even gradient-boosted decision trees on some datasets.
Analysis
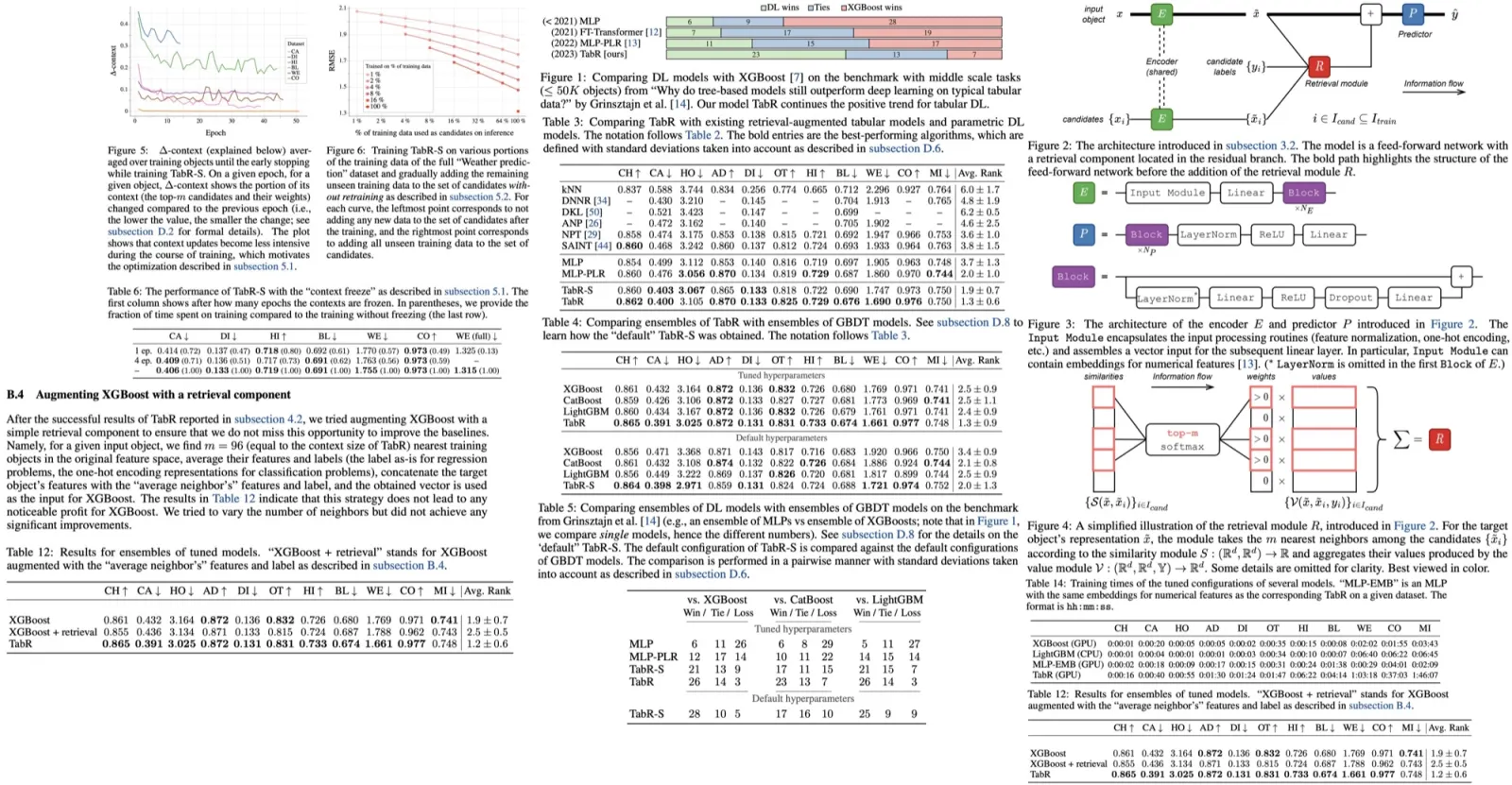
Freezing contexts for faster training of TabR
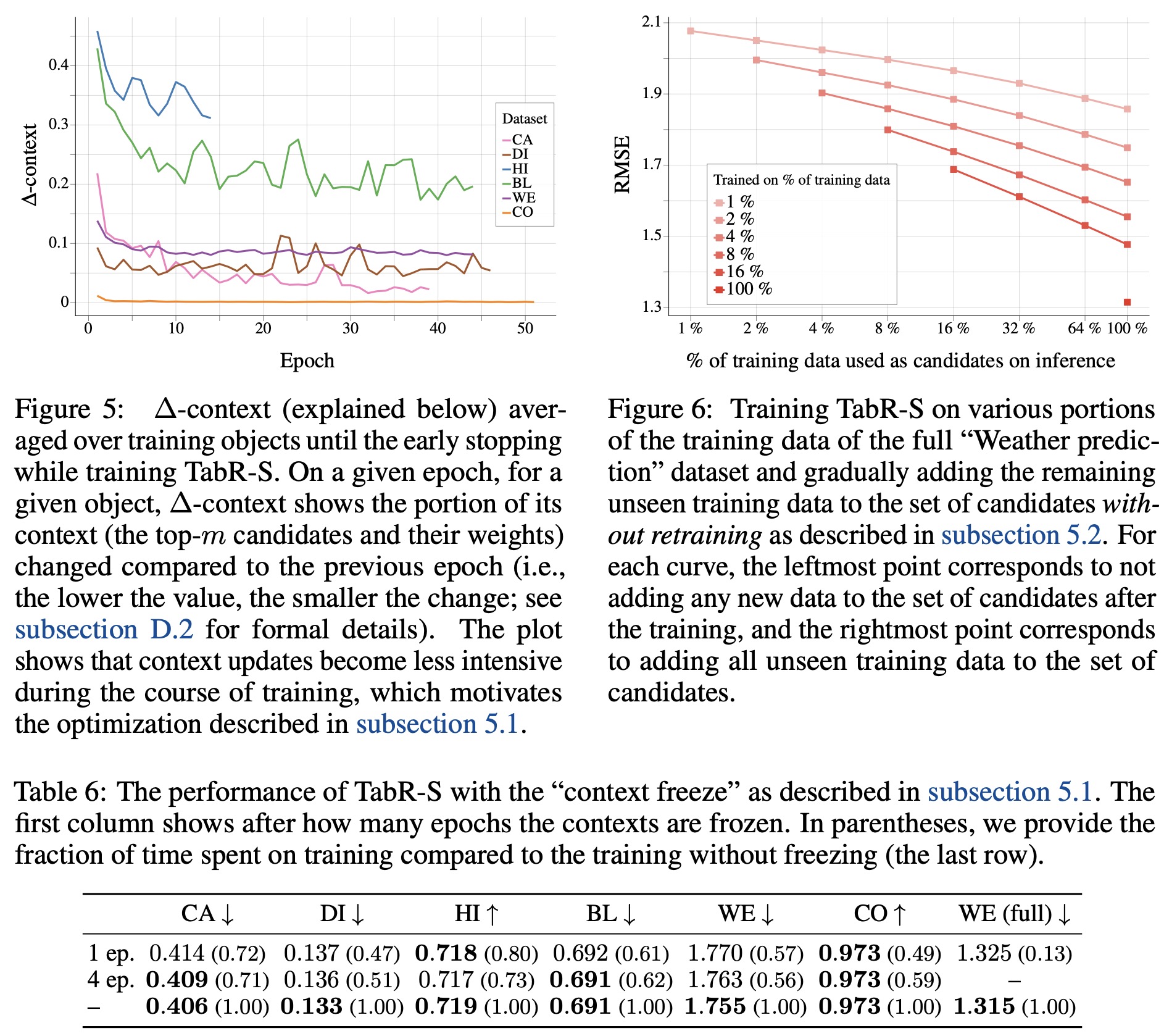
In the original implementation of TabR, training can be slow on large datasets due to the necessity of encoding all candidates and computing their similarities for each training batch. As an example, the authors mention that it takes over 18 hours to train a single TabR on the full “Weather prediction” dataset, which consists of more than 3 million objects.
However, the authors note that during the course of training, the context for an average training object (i.e., the top-m candidates and the distribution over them according to the similarity module S) tends to stabilize, which provides an opportunity for optimization. After a certain number of epochs, they propose a “context freeze” where the up-to-date contexts for all training objects are computed for the last time and then reused for the rest of the training.
This simple technique allows the acceleration of the training of TabR without significant loss in metrics, particularly on larger datasets. Specifically, on the full “Weather prediction” dataset, it led to a nearly sevenfold increase in speed (reducing the training time from 18 hours and 9 minutes to just 3 hours and 15 minutes), while still maintaining competitive Root Mean Square Error (RMSE) values.
Updating TabR with new training data without retraining (preliminary exploration)
In real-world scenarios, it’s common to receive new, unseen training data after a machine learning model has already been trained. The authors tested the ability of TabR to incorporate this new data without requiring retraining by adding the new data to the set of candidates for retrieval.
They performed this test using the full “Weather prediction” dataset, which includes over 3 million objects. The results suggest that online updates can effectively integrate new data into a trained TabR model. Additionally, this approach can be used to scale TabR to larger datasets by training the model on a subset of the data and retrieving from the full dataset.
Augmenting XGBoost with a retrieval component
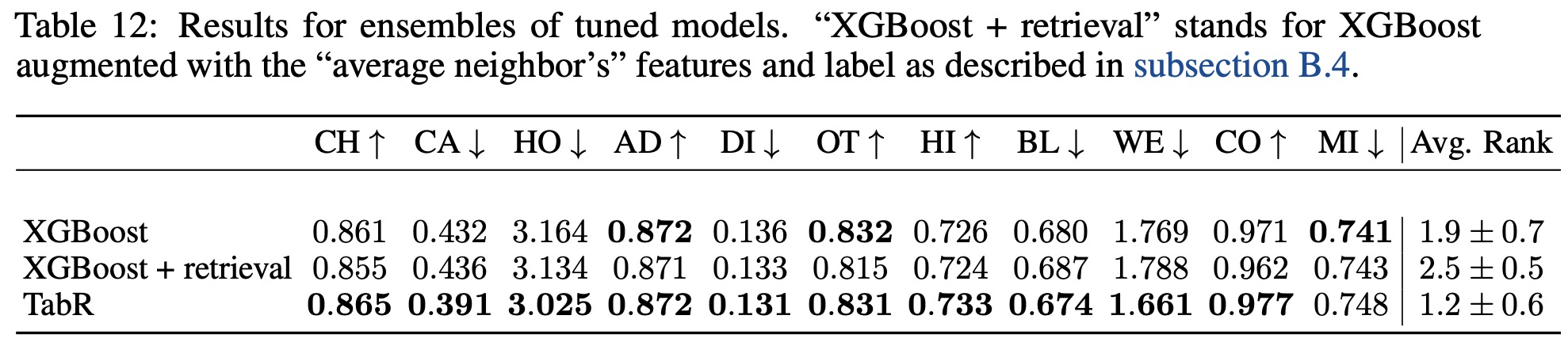
The authors attempted to improve XGBoost’s performance by incorporating a retrieval component similar to that in TabR. This approach involved finding the nearest 96 training objects (matching the context size of TabR) to a given input object in the original feature space. The features and labels of these nearest neighbors were then averaged, with the labels used as-is for regression tasks and converted to one-hot encoding for classification tasks.
This averaged data was concatenated with the features and label of the target object, forming a new input vector for XGBoost. However, the results reveal that this strategy did not noticeably enhance XGBoost’s performance. Attempts to vary the number of neighbors also failed to yield any significant improvements.
paperreview deeplearning tabular