Paper Review: Long-Short Transformer: Efficient Transformers for Language and Vision
Code not available yet.

This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. Long-Short Transformer (Transformer-LR) has a linear complexity for both vision and language tasks. It uses both short- and long-range attention to capture local and distant correlations, respectively. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms.
The approach shows great results on the Long Range Arena benchmark, autoregressive language modeling, and ImageNet classification. For example, it reaches 84.1% on ImageNet!
The approach
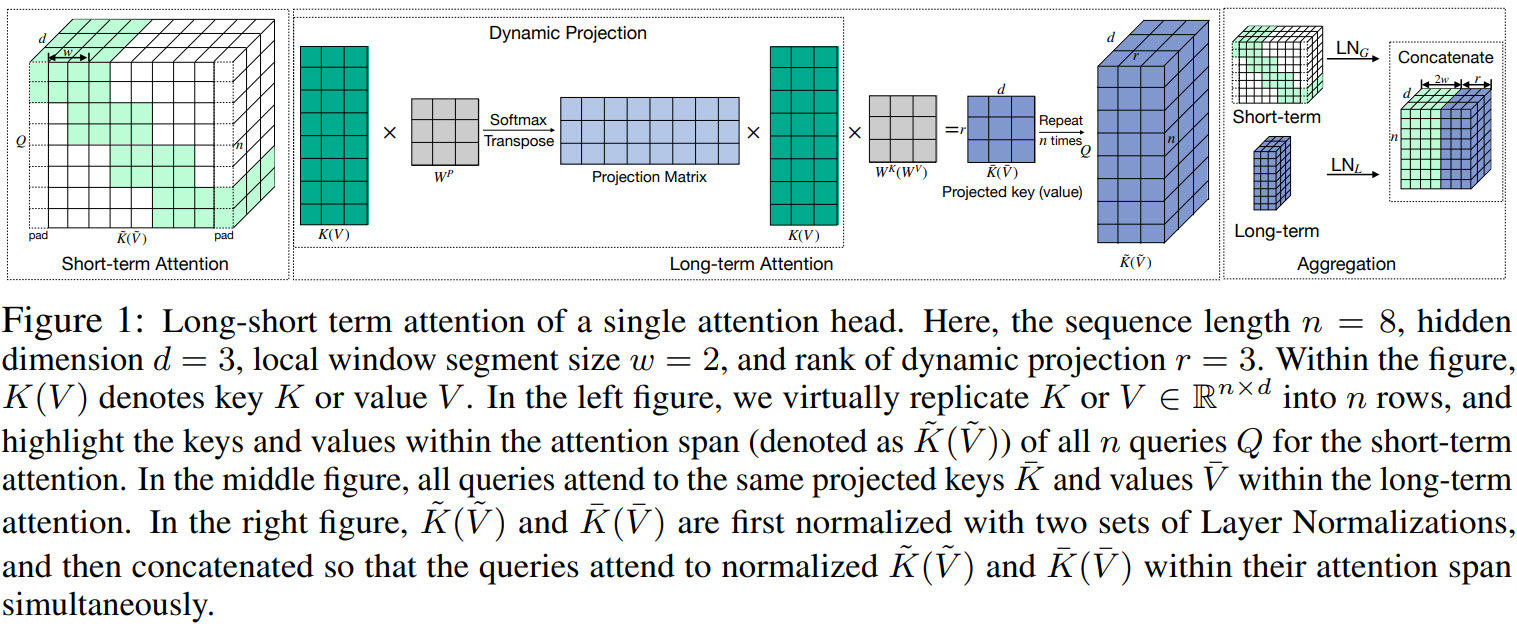
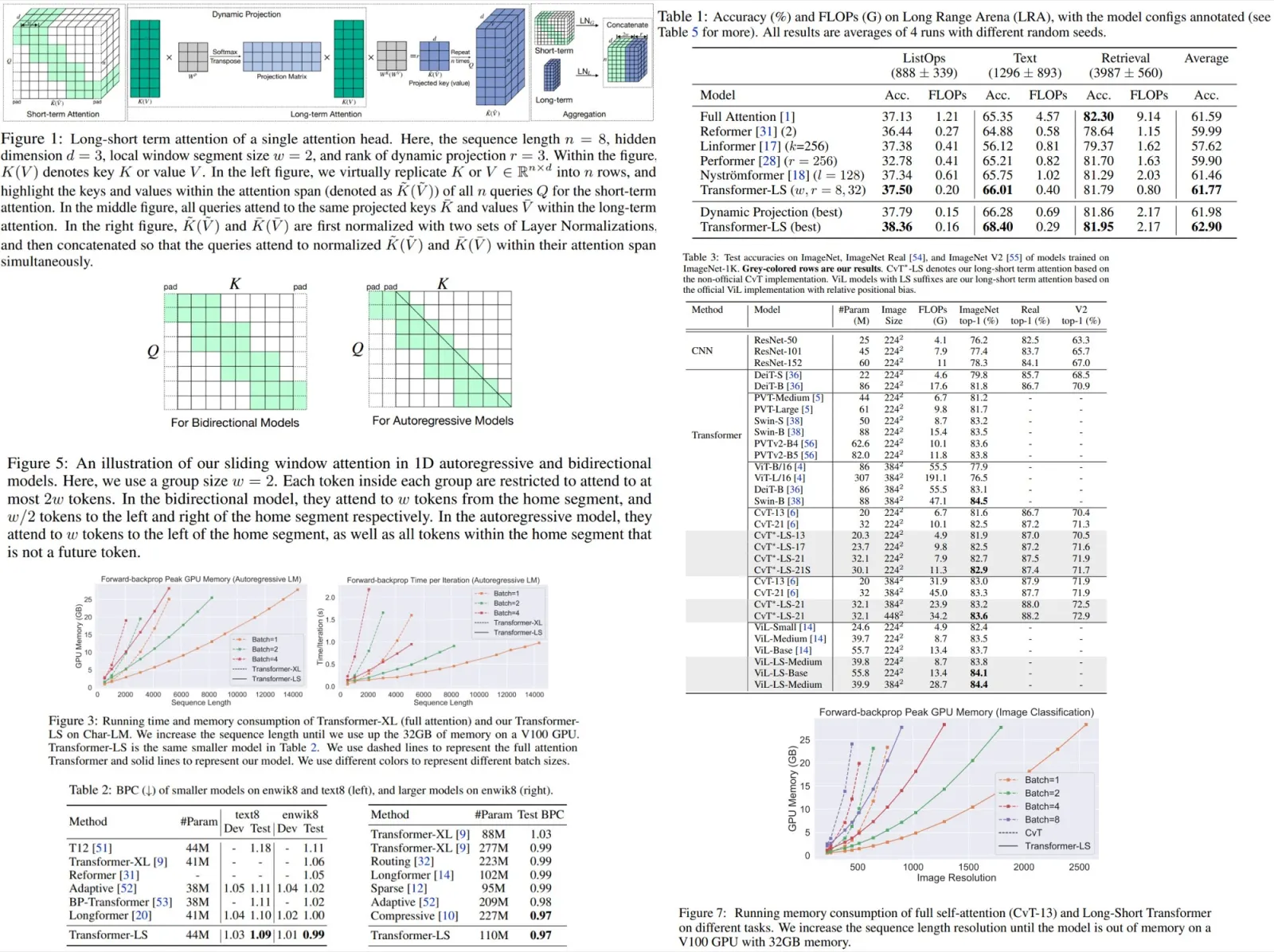
Short-term Attention via Segment-wise Sliding Window
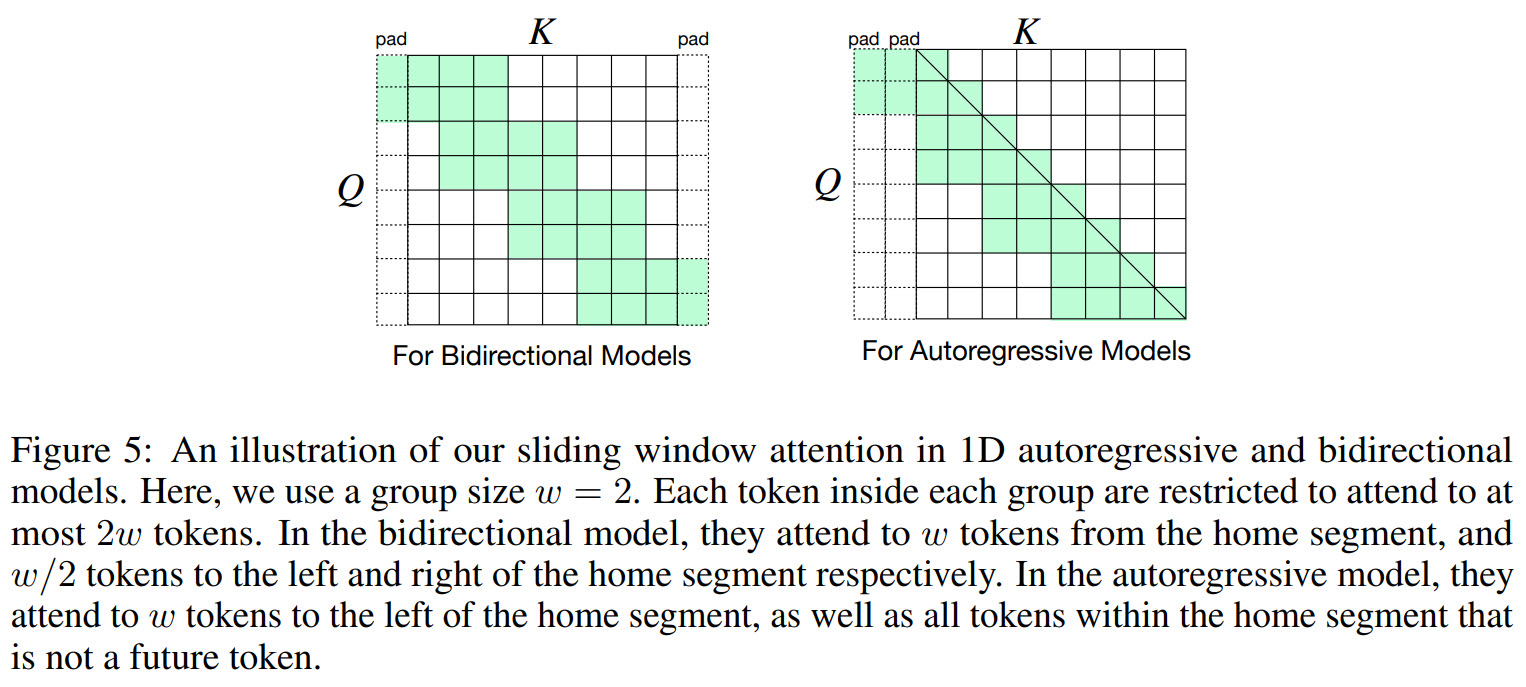
- The input sequence is divided into disjoint segments with length
l; - All tokens within a given segment attend to all tokens within that segment and to
w/2consecutive tokens on the left and on the right side of that segment;
It is possible to augment this sliding window attention to capture long-range correlations, for example, by using different dilations in different heads. But this would require more tuning, and it will be difficult to implement multi-head attention with different dilations efficiently.
Long-range Attention via Dynamic Projection
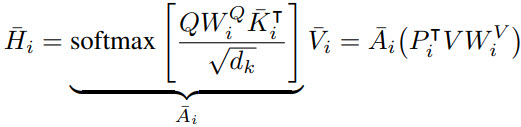
- Each head is projected into a lower-rank matrix;
- Unlike Linformer, the dimensions of this matrix is dynamic depending on the input sequence. As a result, it should be more flexible and robust;
- Query embeddings are kept at the same length;
- The the effective attention weights of a query on all tokens sum to 1;
- This global attention allows each query to attend to all token embeddings within the same self-attention layer;
Application to Autoregressive Model
In autoregressive models, each token can only attend to the previous tokens; thus, long-range attention has a different range for different tokens.
- The input sequence is divided into disjoint segments with length
l; - Dynamic projection extracts keys and values from each segment;
- Each token can attend only to keys and values of segments that don’t contain its future tokens;
As a result, the dynamic low-rank projection is applied to each segment only once in parallel.
Aggregating Long-range and Short-term Attention
Each query at i-th head attends to the union of keys and values from the local window and global low-rank projection. But there is a problem: there is a scale mismatch between the local and the global embeddings. Therefore, the authors introduce a normalization strategy (DualLN) to align the norms and improve the effectiveness of the aggregation in the following: two sets of Layer Normalization are added after the key and value projections for the local window and global low-rank attentions.
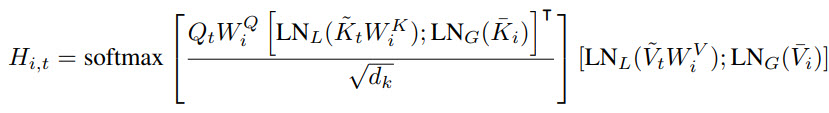
The experiments
Long Range Arena
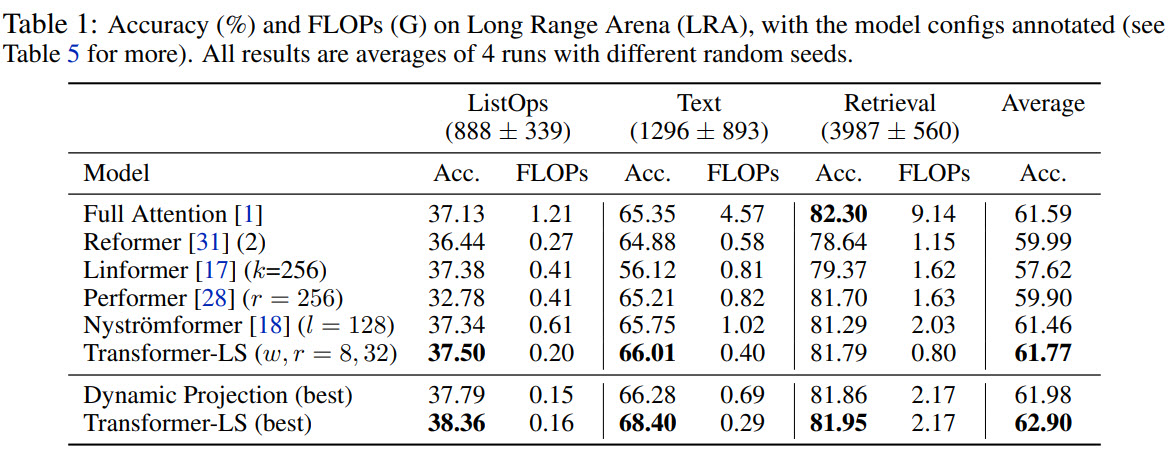
Three tasks from the LRA benchmark are used:
- ListOps measures a parsing ability of the models in hierarchically structured data. Each instance contains 500-2000 tokens;
- Text is a binary sentiment classification on movie reviews with a maximum sequence length of 4k;
- Retrieval: models should find whether there is a common citation between papers. Max length of each byte-level document is 4k;
Transformer-LS not only reaches a better score than most approaches but also uses fewer computations.
Autoregressive Language Modeling
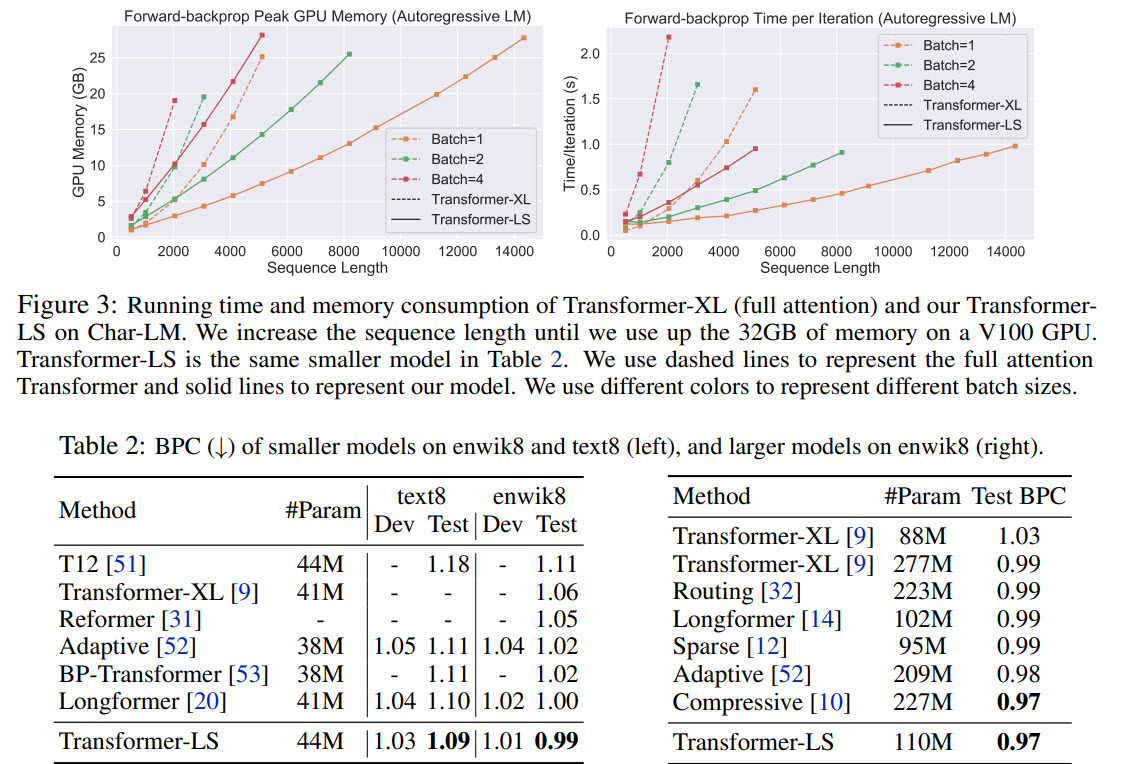
Imagenet Classification
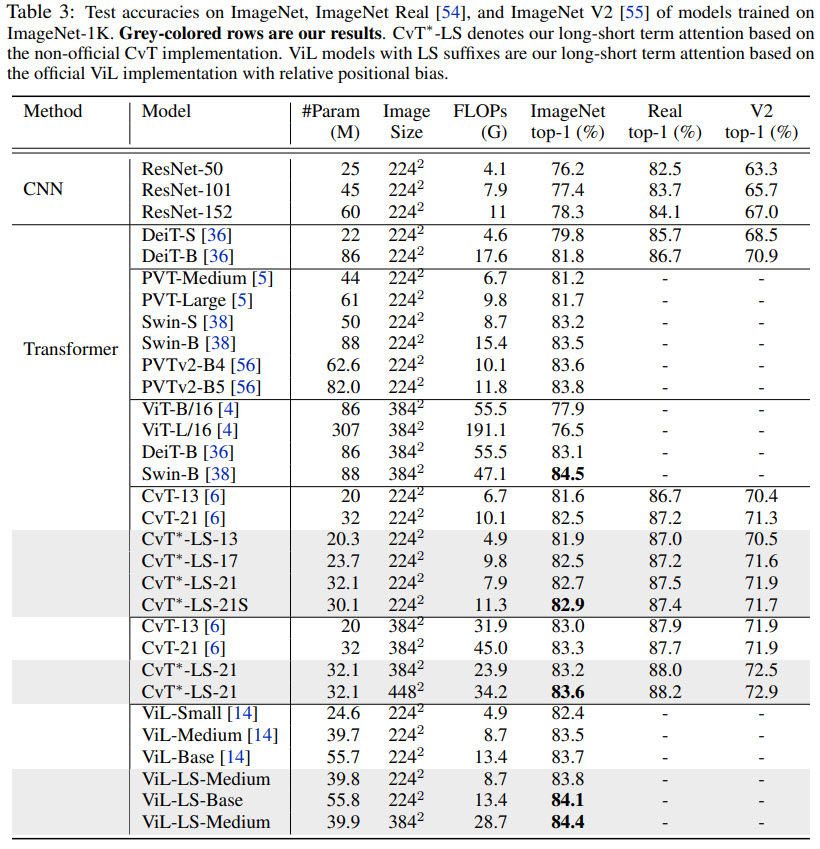
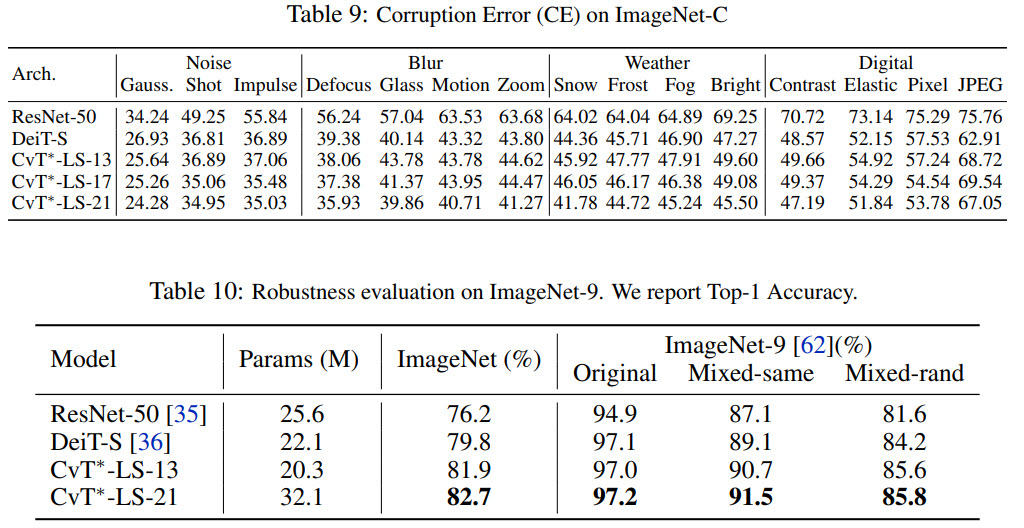
- The authors use ViL and CvT as backbones and replace their attention with their long-short term attention. These modified architectures get getter results and lower FLOPs;
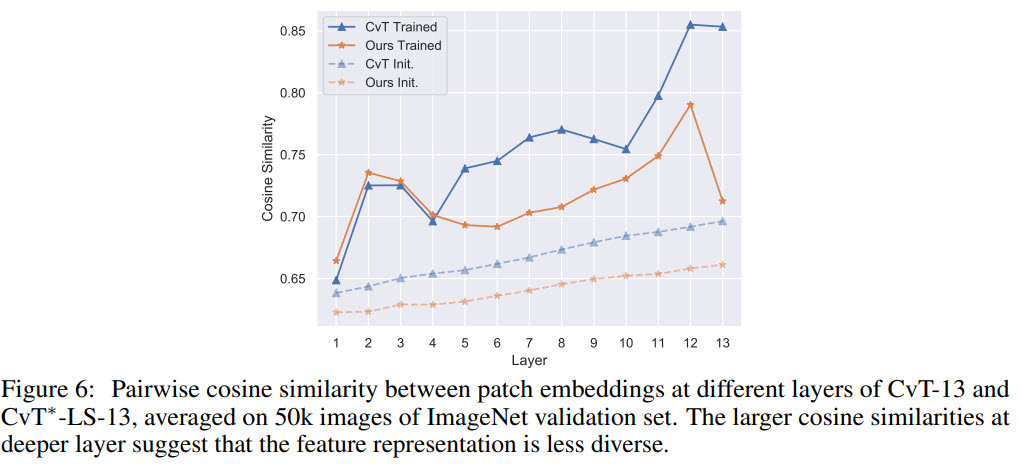
- Short-term Attention Suppresses Oversmoothing. Oversmoothing is a situation when all queries extract similar information in deeper layers, and the attention mechanism is less important). This problem is solved or at least alleviated by restricting tokens from different segments to attend to different windows;
- The approach also shows good results on Diverse ImageNet Datasets;
This was a fascinating paper, but I feel that it would be valuable to have more comparisons with other approaches:
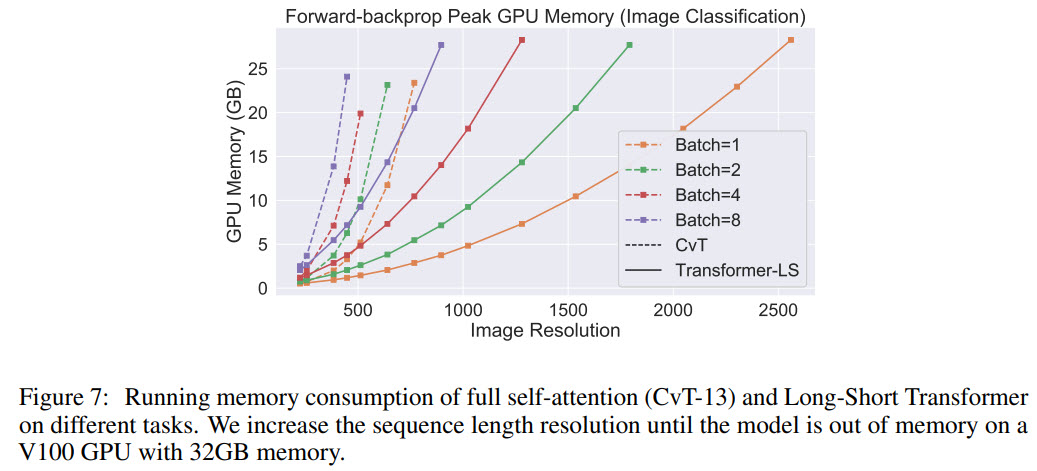
- plots of running time and memory consumption compare only full attention and Transformer-LS. It would be nice to see Longformer and other models on these plots;
- I think when measuring the performance on ImageNet, it is important to compare not only to basic models like ResNets, but with more modern architectures like EfficientNets;