Paper Review: Translatotron 3: Speech to Speech Translation with Monolingual Data
Translatotron 3 is a novel approach for training speech-to-speech translation models in a fully unsupervised manner using only monolingual speech-text datasets. It incorporates a masked autoencoder, unsupervised embedding mapping, and back-translation. In tests, it outperformed traditional cascade systems in Spanish-English translation tasks, achieving a significant 18.14 BLEU points improvement on a synthesized Unpaired-Conversational dataset. Notably, Translatotron 3 can retain para- and non-linguistic features like pauses, speaking rates, and speaker identity, overcoming challenges faced by supervised models that depend on real paired data or specialized modeling.
Background
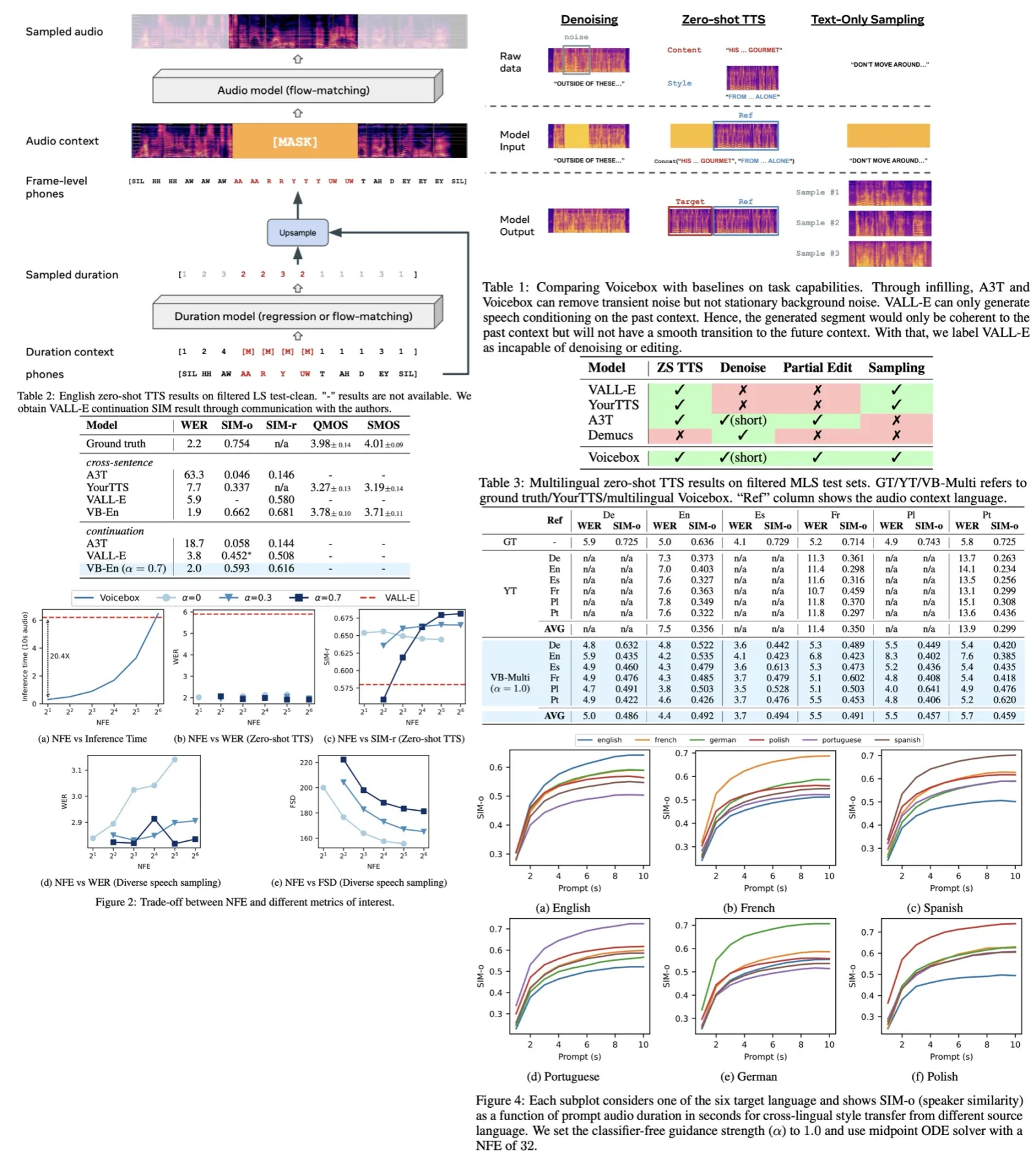
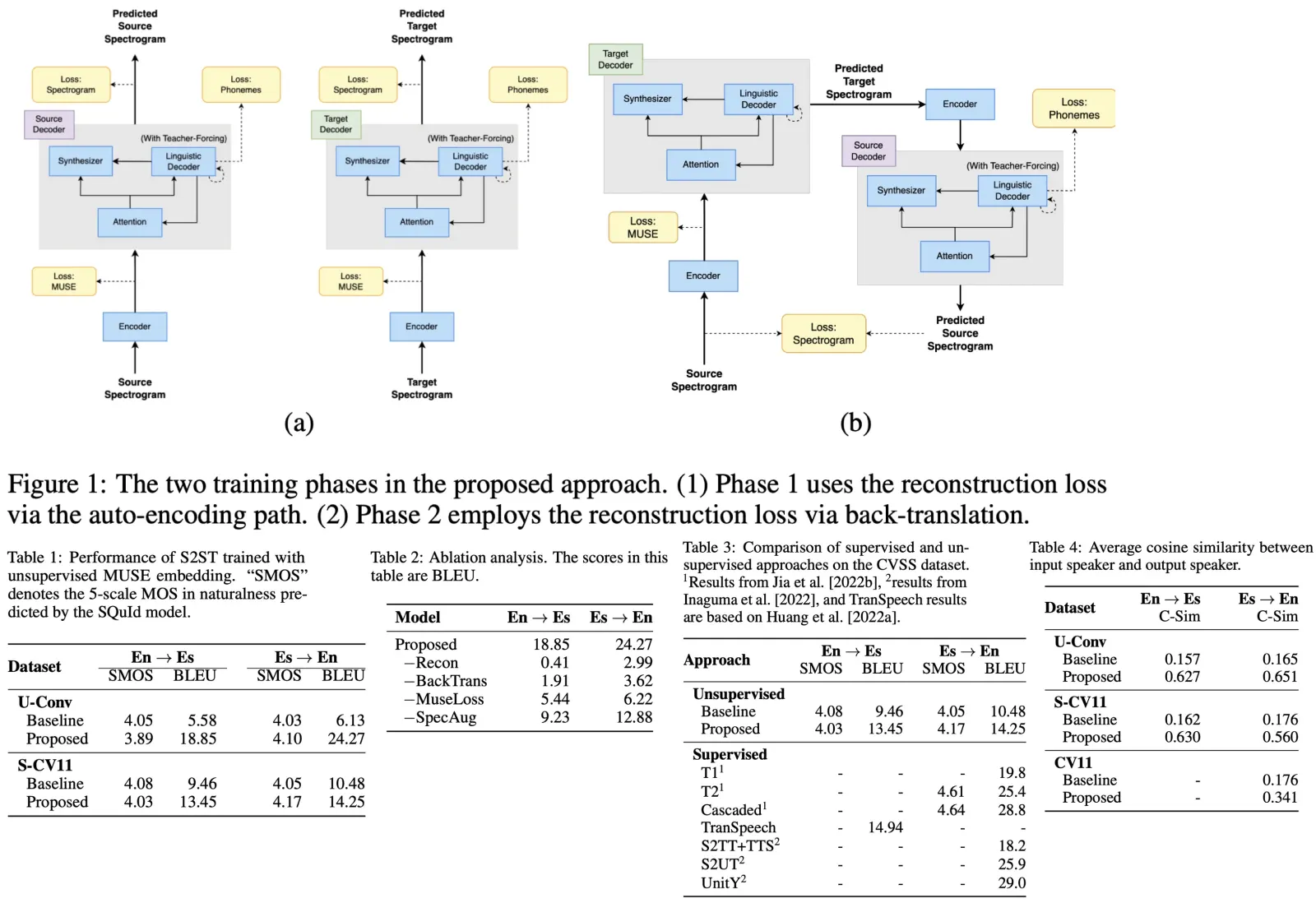
Translatotron 2 is an end-to-end speech-to-speech translation model consisting of four main components: a speech encoder, a linguistic decoder, an acoustic synthesizer, and a single attention module. This structure enables direct translation from one language’s speech to another. The model is trained using supervised methods with bilingual speech-text datasets and employs a combination of losses - spectrogram reconstruction loss, total duration loss, and auxiliary phoneme loss - to enhance speech quality and learn alignments between source speech and target text.
- Speech Encoder: Processes a source speech spectrogram sequence using a convolutional layer and Conformer blocks, producing an intermediate representation.
- Attention Module: Based on multi-head attention, it aligns the source spectrogram sequence with the target phoneme sequence and summarizes acoustic information per phoneme.
- Linguistic Decoder: Generates a phoneme sequence for the target speech using an autoregressive LSTM stack with teacher-forcing.
- Acoustic Synthesizer: Creates the spectrogram of the translated speech, integrating outputs from both the linguistic decoder and the attention module, featuring a per-phoneme duration predictor and an LSTM-based decoder.
Multilingual Unsupervised embeddings (MUSE) is a method to create multilingual word embeddings. The objective of MUSE is to find an optimal mapping that minimizes the difference between the transformed source language embeddings and the target language embeddings, measured by the Frobenius norm. This method was later improved by adding an orthogonality constraint to the weights. In an unsupervised setting, an adversarial approach is used. A discriminator classifies randomly sampled elements, and the mapping is updated to prevent the discriminator from determining the origin of its input. The discriminator, a simple classifier, is trained to predict whether an embedding came from the source or target language. The loss function for this process considers the discriminator’s ability to identify the source of each embedding.
Translatotron 3
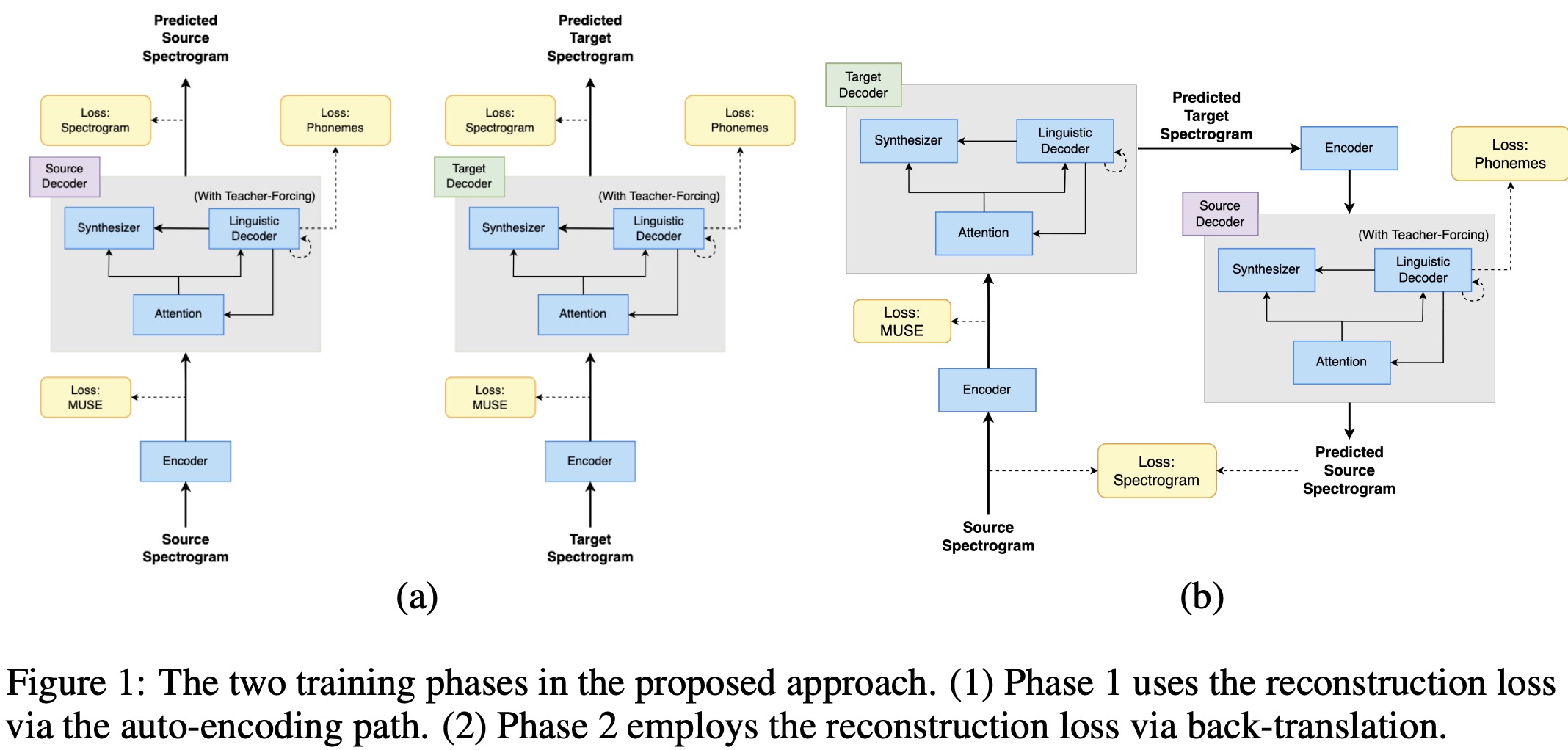
Translatotron 3 uses a shared encoder to process both source and target languages and has two separate decoders, one for each language.
The encoder in Translatotron 3 is similar to the speech encoder in Translatotron 2. It splits its output into two parts: the first half is trained to align with MUSE embeddings of the text of the input spectrogram, and the second half is updated without the MUSE loss. This shared encoder approach allows Translatotron 3 to learn a multilingual embedding space, efficiently encoding speech in both languages into a common space, rather than maintaining separate spaces for each language.
The decoder in Translatotron 3, like in Translatotron 2, consists of three components: a linguistic decoder, an acoustic synthesizer, and an attention module. To accommodate the different properties of the source and target languages, there are two separate decoders for them.
Translatotron 3’s training consists of two phases:
- Auto-encoding, Reconstruction Phase: In this phase, the network is trained to auto-encode the input into a multilingual embedding space using MUSE loss and a reconstruction loss. The goal is to ensure that the network generates meaningful multi-lingual representations. SpecAugment is applied to the encoder input to improve the generalization capabilities of the encoder by augmenting the input data.
- Back-translation Phase: This phase also includes the MUSE loss and reconstruction loss to avoid catastrophic forgetting and ensure the latent space remains multilingual. The back-translation involves encoding the source input spectrogram, decoding it into a pseudo-translation in the target language, and then re-encoding and decoding it back into the source language. This process is applied in both directions (source to target and target to source).
MUSE Loss ensures that the encoder E generates multi-lingual representations meaningful for both decoders. It minimizes the error between the pre-trained MUSE embeddings and the first output vectors of the encoder. The reconstruction loss is a combination of losses for the spectrogram, duration, and phonemes for both source and target languages.
Experiments
The model was trained on 64 TPUv4 for one week.
Data
Synthesized Speech Data:
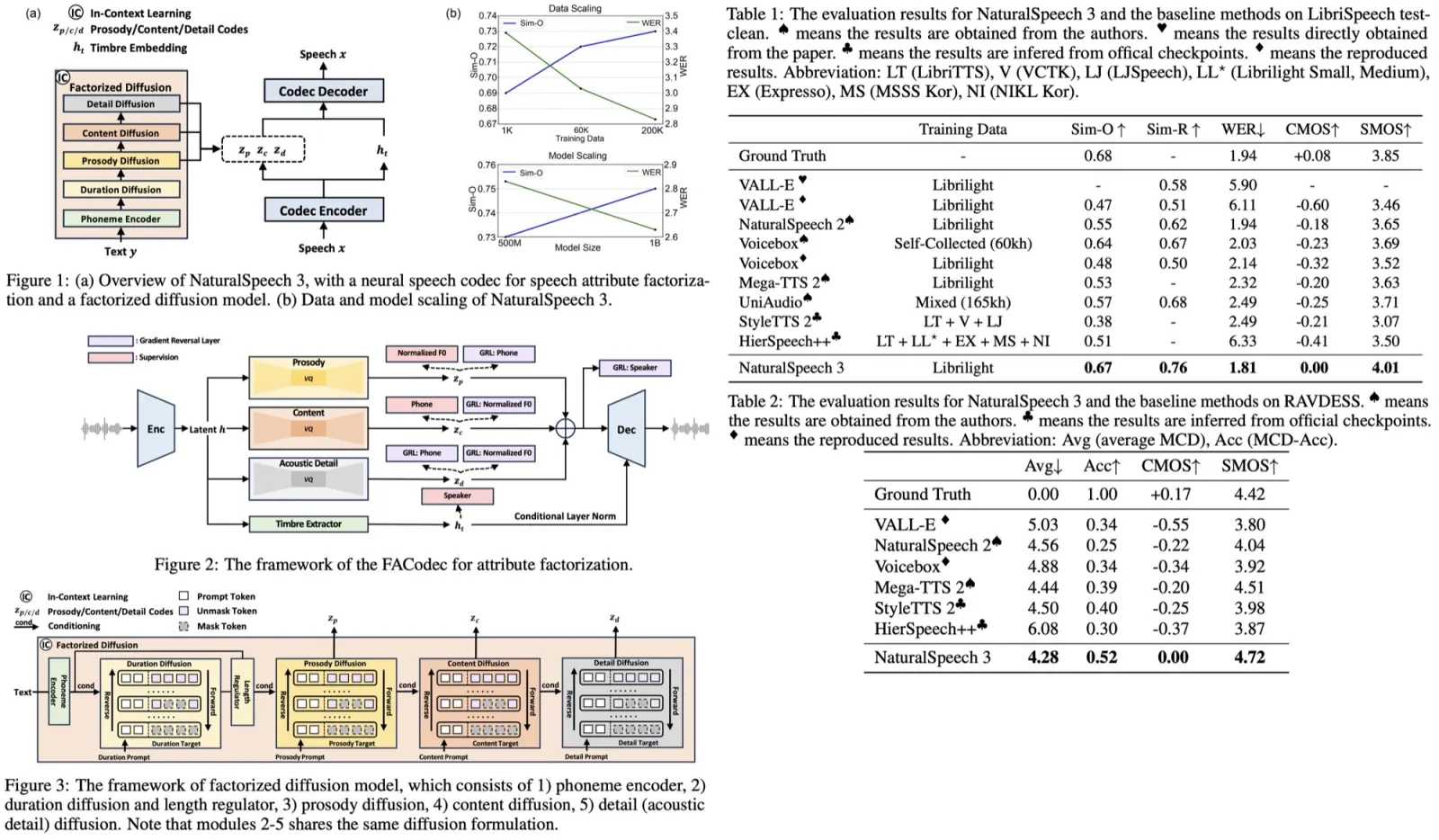
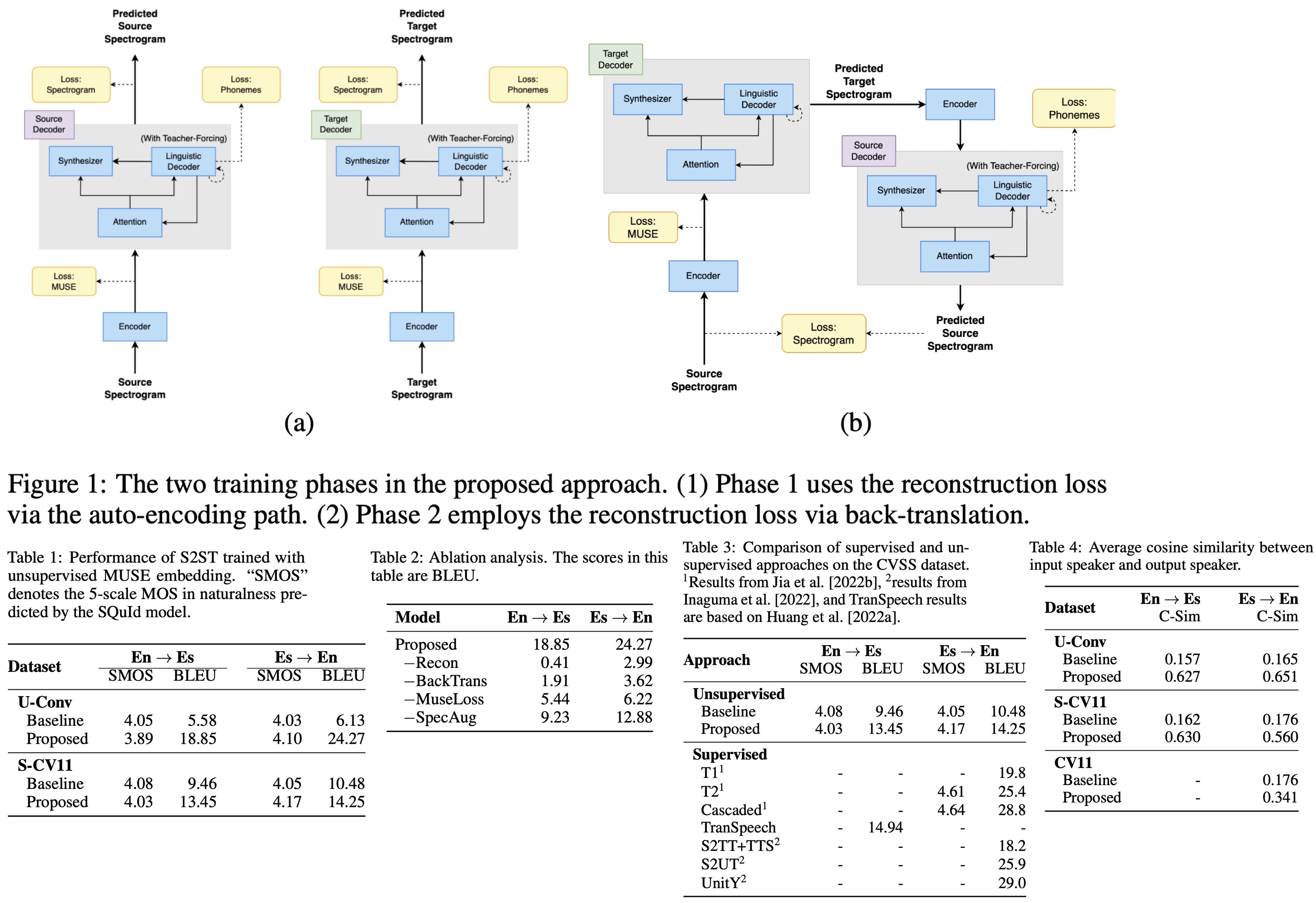
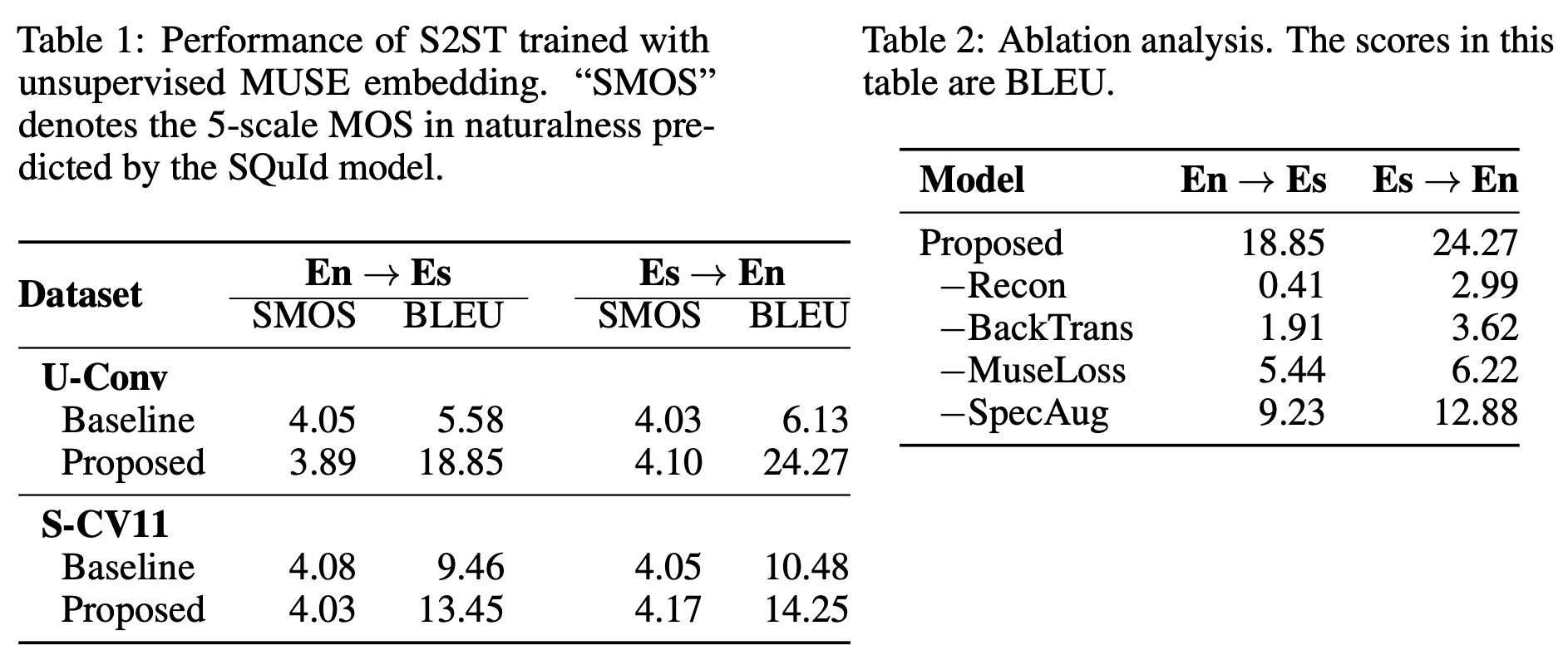
- Unpaired Conversational Dataset: The initial dataset was created by crowd-sourcing humans to read Spanish-English machine translation datasets. Both source and target speech were synthesized using a Phoneme-and-Grapheme Non-Attentive Tacotron TTS model and a WaveRNN-based neural vocoder, trained on a dataset with over 1,000 speakers. The training set included approximately 379K English and Spanish utterances each, with around 371 hours of English speech and 350 hours of Spanish speech. The test set had about 6.5K paired utterances. The approach showed substantial improvements over the baseline, with a +13.27 increase in BLEU for English→Spanish and +18.14 increase in BLEU for Spanish→English translations.
- Common Voice 11: This dataset included English and Spanish languages, with the data balanced by sampling 50% of English samples. The test set had about 13K paired utterances, and the approach demonstrated approximately 30% improvement in BLEU over the baseline, with specific improvements of +3.77 in Spanish→English and +3.99 in English→Spanish translations. The naturalness of the translations was similar to the baseline.
Real Speech Data:
- Real speech data from Common Voice 11 was used, involving natural, non-synthesized English and Spanish monolingual speech-text datasets. The evaluation of Spanish-English real speech translation used the CoVoST2 test set, a subset of the Common Voice 11 test set. The approach achieved a BLEU score of 10.67 for Spanish-English translation, which was an improvement of +0.75 over the baseline score of 9.92 BLEU.
Results
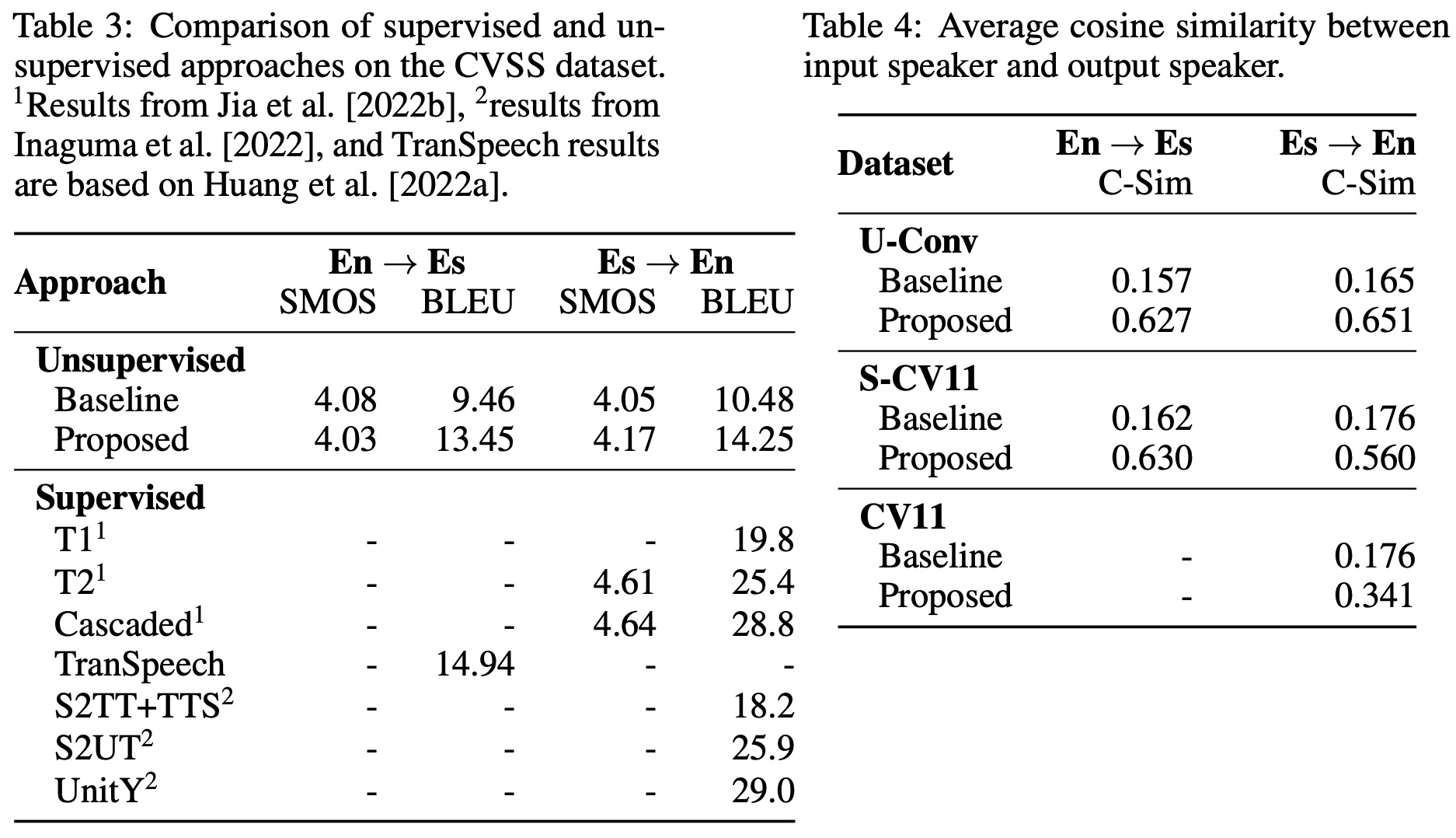
- Comparison to Supervised Approaches: The proposed approach showed performance comparable to supervised approaches in English to Spanish translation, with only a small margin of difference. This is noteworthy considering the added complexity of unsupervised translation. In contrast, for Spanish to English translation, supervised approaches outperformed the proposed method. Although the margin was significant, the complexity of the task was also a factor to consider.
- Ablation Analysis showed that all the components (SpecAugment, removing Back-Translation loss, the MUSE embedding loss, and the reconstruction loss) played a role in enhancing the overall performance. The reconstruction loss and the back-translation loss had the most substantial impact, while the inclusion of the MUSE loss also led to notable improvements.
- Para-/Non-Linguistic Feature Preservation: The approach effectively preserved paralinguistic features like the original speaker’s voice identity during translation. The test set showed an average similarity score of 0.6, indicating a good correlation between input and output speaker identities. This was a significant improvement over the baseline score of 0.16, which indicated no correlation. The model also showed promise in maintaining critical elements such as pauses and speaking rates.