Paper Review: TSMixer: An All-MLP Architecture for Time Series Forecasting

Time-series datasets in real-world scenarios often contain multiple variables with intricate patterns. While deep learning models using recurrent or attention mechanisms are commonly used to handle this complexity, recent studies show that basic linear models can sometimes outperform them on standard academic tests. This paper introduces the Time-Series Mixer (TSMixer), an innovative architecture that uses MLPs stacked together. TSMixer extracts information efficiently by blending data across time and feature dimensions.
On widely accepted academic tests, TSMixer performs on par with advanced, specialized models. Remarkably, on the large-scale M5 benchmark, which uses a real-world retail dataset, TSMixer outperforms top-tier alternative models. This highlights the significance of effectively harnessing multi-variable and supplementary data for enhancing time series forecasting.
Linear Models for Time Series Forecasting
The recent findings suggest that simple linear models can often outperform complex architectures like Transformers for time-series forecasting. Thus, the authors explore the theoretical foundations of linear models: when compared with more advanced sequential architectures like RNNs and Transformers, linear models have a unique capability to capture time dependencies for univariate time series effectively.
The authors postulate that real-world time series data are generally characterized by either periodicity or smoothness. In cases where the time series is periodic, linear models can predict future values perfectly. More generally, if the time series can be broken down into a periodic sequence and a sequence with a smooth trend, linear models can predict future values with bounded error, provided the lookback window is large enough.
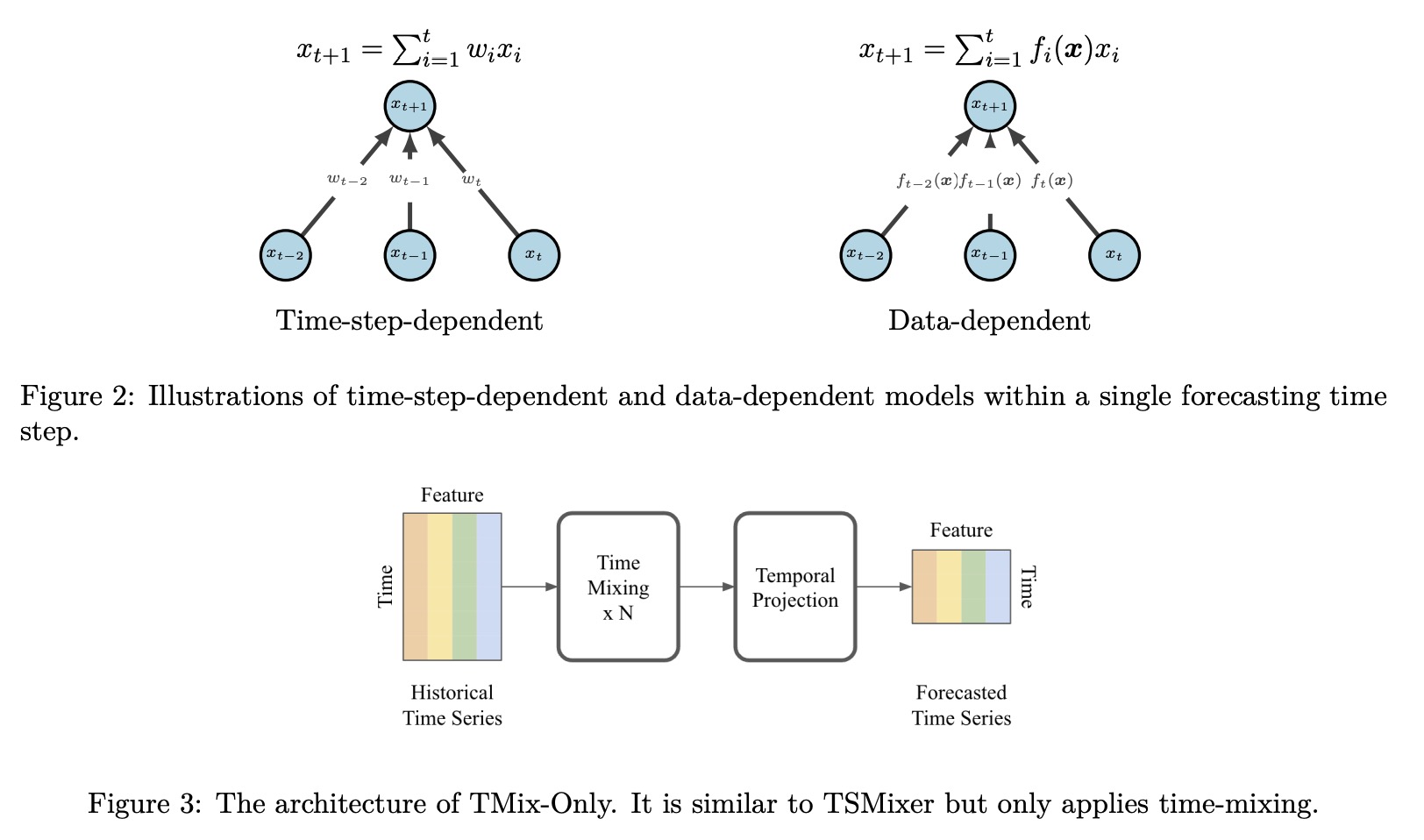
The authors also compare linear models with conventional deep learning models like RNNs or Transformers. They argue that these advanced models tend to overfit because they weigh the input sequence based on a function of the data itself, unlike linear models, which have a fixed weight for each time step. This fixed weight is a key feature that allows linear models to effectively capture time-dependent patterns, a challenge for many complex models.
However, the approach focuses only on univariate time series, and it might not hold as effectively for real-world data that are highly volatile and neither periodic nor smooth.
TSMixer Architecture
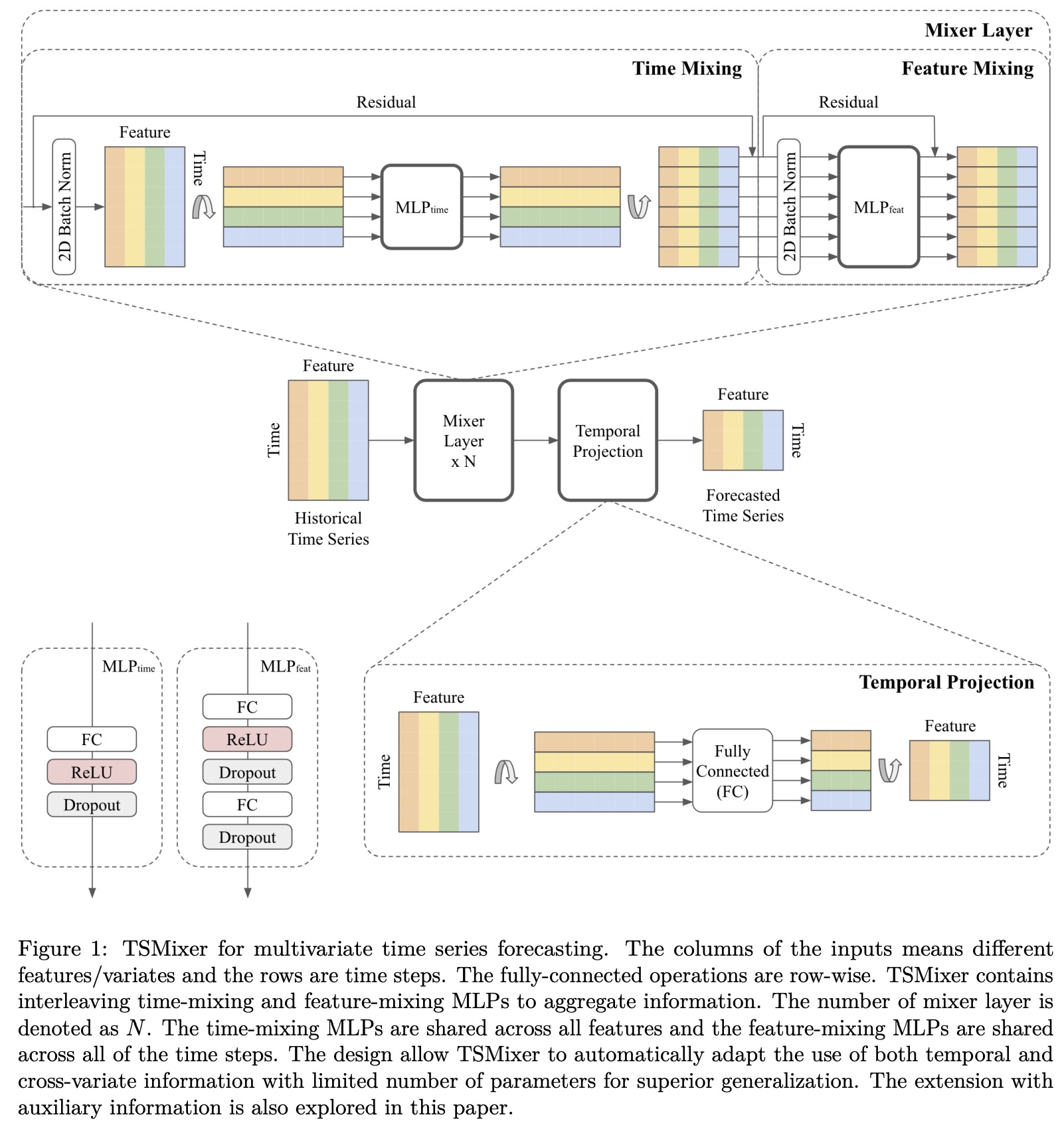
Building on the insight that linear models are effective at capturing time dependencies in time-series data, the authors introduce an enhanced architecture that incorporates non-linearities through MLPs. To facilitate efficient learning, they employ common deep learning techniques like normalization and residual connections.
To add cross-variate information to the model, the authors propose TSMixer. This model uses MLPs in both the time and feature domains alternately. Time-domain MLPs are shared across all features, and feature-domain MLPs are shared across all time steps. This design is inspired by the MLP-Mixer architecture from computer vision and aims to efficiently utilize both temporal dependencies and cross-variate information.
The interleaving of time-domain and feature-domain operations allows TSMixer to have a long lookback window without exponentially increasing the model’s size or computational complexity. Specifically, parameter growth is linear in terms of both the number of time steps and features rather than multiplicative. A simplified version of TSMixer, called TMix-Only, was also developed. This version uses only time-mixing operations and consists of a residual MLP shared across each feature.
Extended TSMixer for Time Series Forecasting with Auxiliary Information
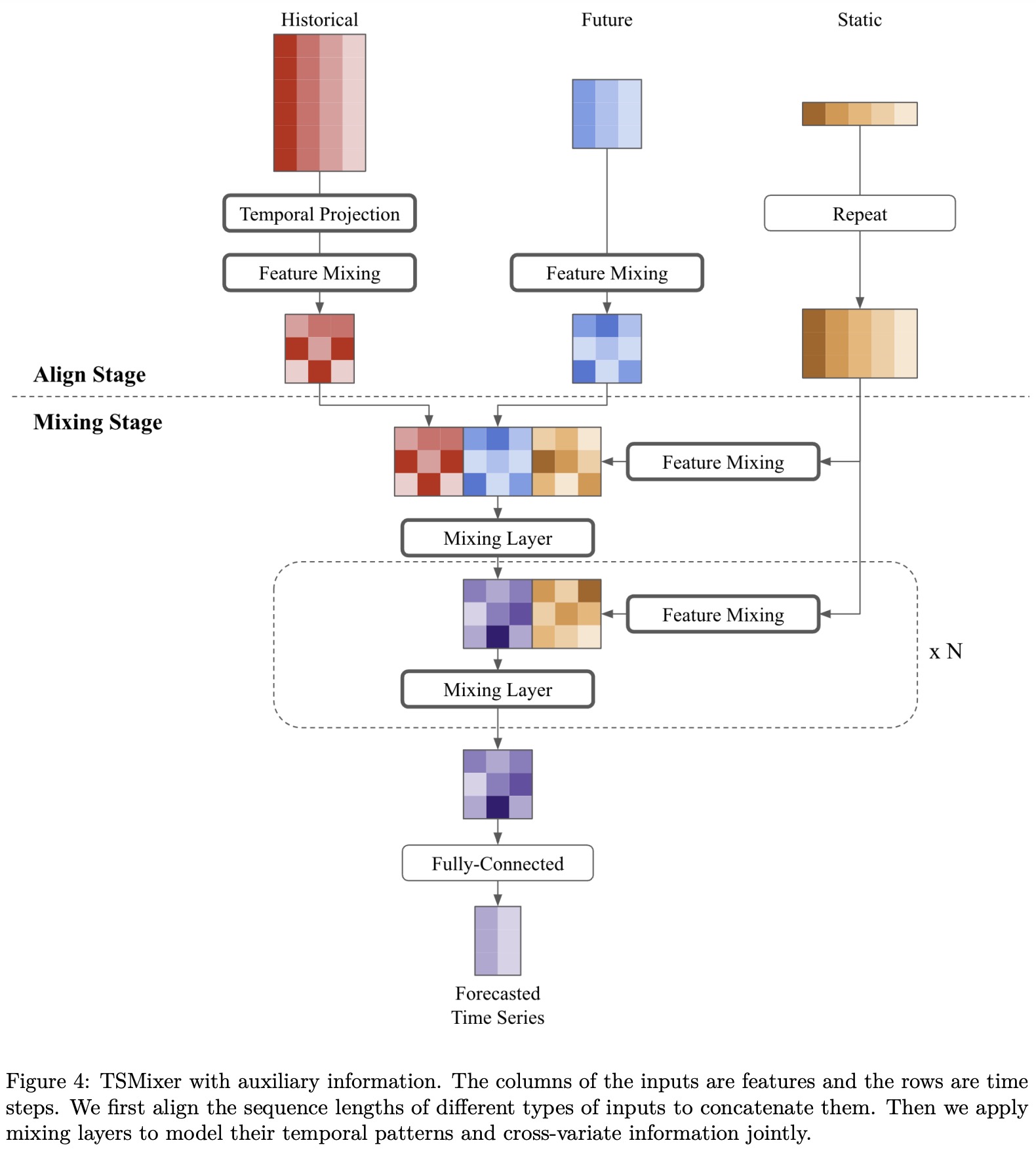
In real-world situations, besides historical data, we often have access to static features like location and future varying features, such as promotions for upcoming weeks. To effectively use these different types of features, the authors use a design that utilizes feature mixing to capture their interactions. This design involves two main stages: align and mixing.
In the align stage, the model reshapes the historical and future features to have a uniform shape. It also adjusts static features to align with the output length. Once aligned, the mixing stage uses time-mixing and feature-mixing operations to capture temporal patterns and relationships across various features. The model then uses a fully-connected layer to generate outputs for each time step, which could represent real forecasted values or parameters of a target distribution, as seen in certain tasks like retail demand forecasting.
Experiments
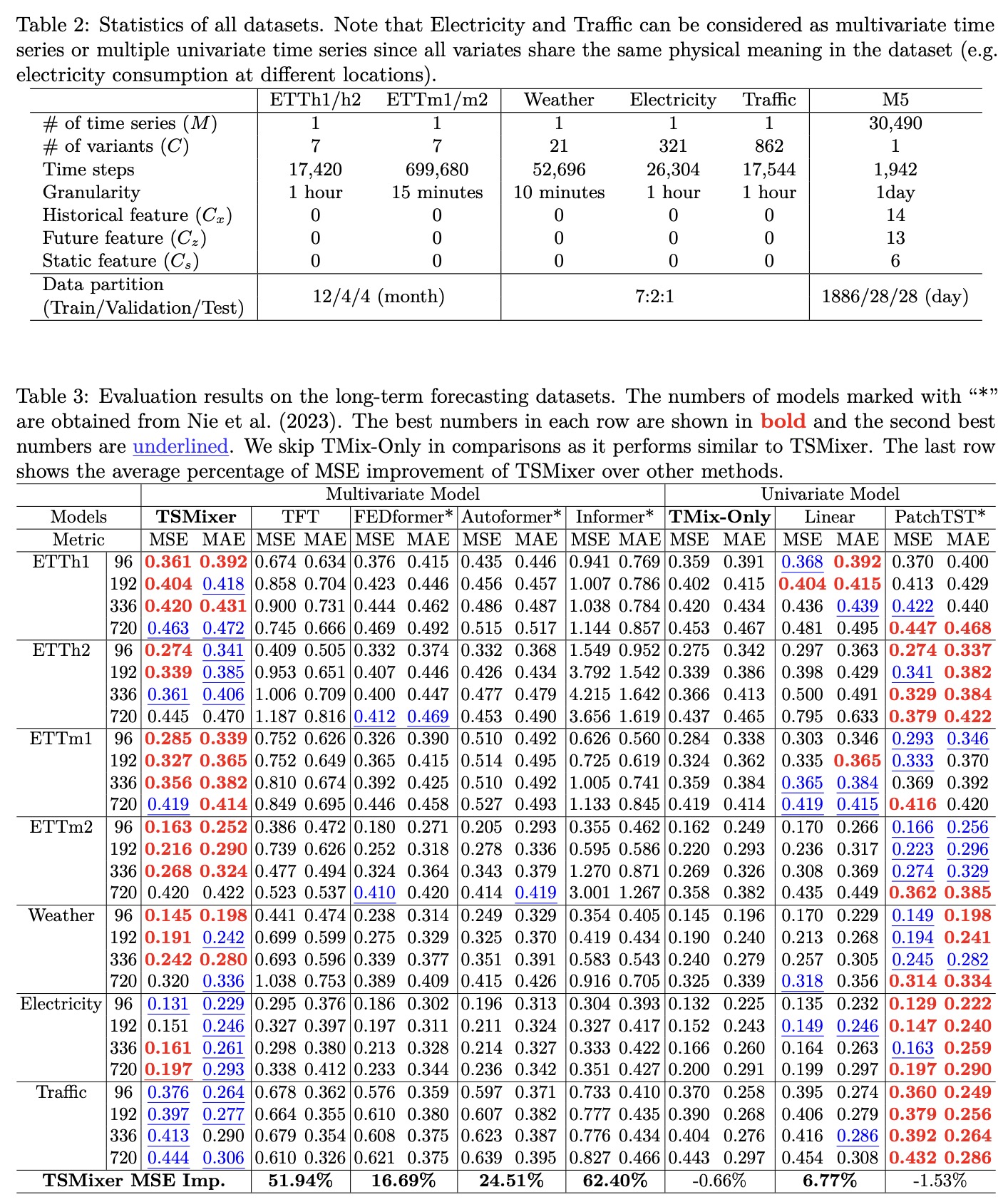
- TSMixer outperformed other multivariate models and was competitive with top-performing univariate models like PatchTST. A simplified version of TSMixer, called TMix-Only, which uses only time-mixing layers, also showed comparable performance to these state-of-the-art models. This suggested that feature-mixing might not be as crucial for the benchmarks used in the study.
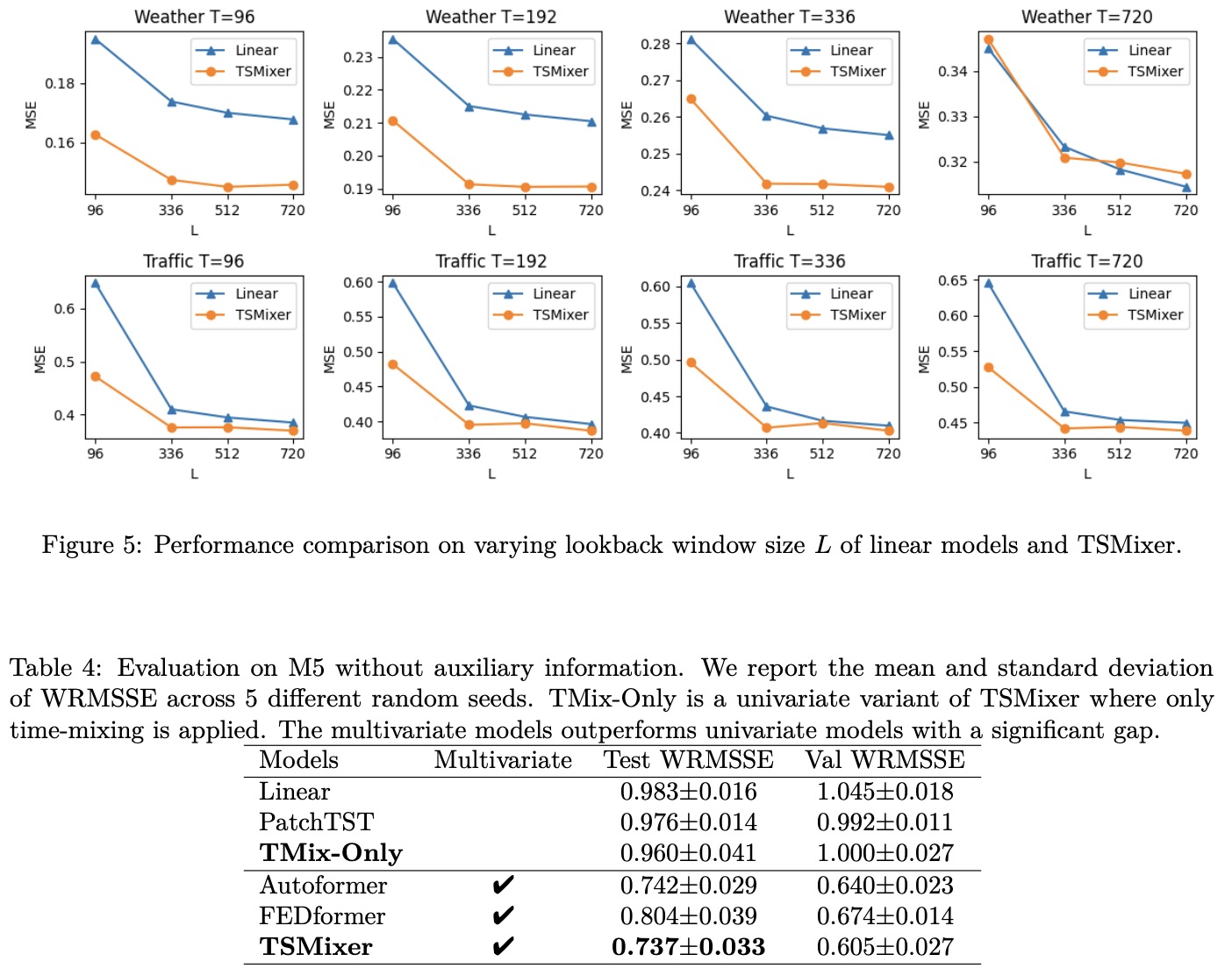
- Ablations on the lookback window sizes show that TSMixer’s performance peaked at lookback windows of 336 or 512 time units and maintained similar performance levels even when the window size was increased to 720. This suggests TSMixer has superior generalization capabilities compared to other multivariate models, which often fail to benefit from longer lookback windows and are prone to overfitting.
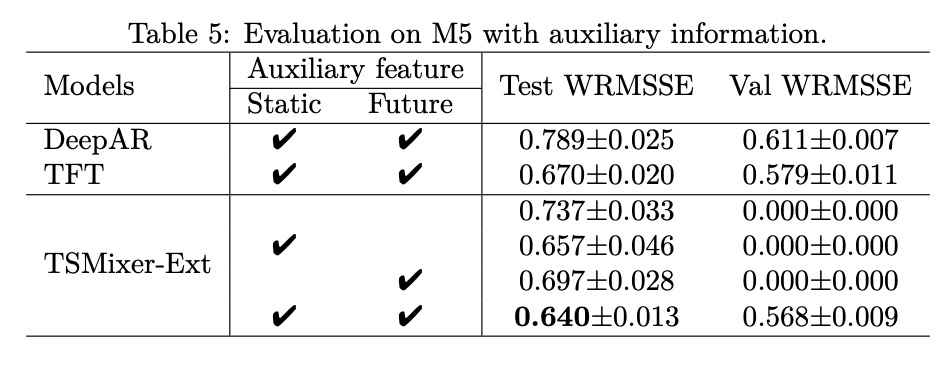
TSMixer was also evaluated on the large-scale retail dataset M5 to assess its ability to leverage complex cross-variate information and auxiliary features. The M5 dataset is more challenging than typical long-term forecasting benchmarks, comprising thousands of multivariate time series with varying historical, future, and static features.
- Forecast with Historical Features Only: When only using historical features, TSMixer significantly outperformed other models, including the state-of-the-art multivariate model FEDformer. TSMixer demonstrated its flexibility by performing well both when cross-variate information is and is not useful.
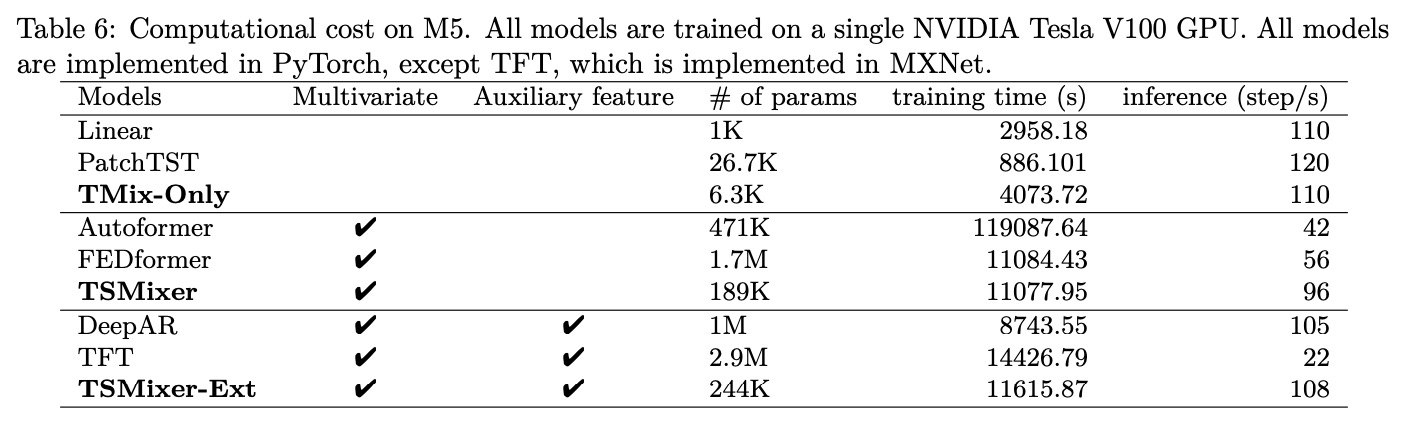
- Forecast with Auxiliary Information: TSMixer outperformed all other models by a significant margin when auxiliary features were included. Ablation studies confirmed that both static and future time-varying features contribute to TSMixer’s superior performance.
- Computational Cost: TSMixer was more computationally efficient compared to RNN- and Transformer-based models. It had similar training times to other multivariate models but much faster inference times, almost on par with simple linear models.