Paper Review: UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
This paper explores a method known as targeted distillation with mission-focused instruction tuning to create smaller student models that excel in specific applications like open information extraction. Using named entity recognition as a case study, the authors demonstrate how ChatGPT can be distilled into a much smaller model called UniversalNER for open NER. In the largest NER benchmark assembled, comprising 43 datasets across 9 domains, UniversalNER significantly outperformed other instruction-tuned models like Alpaca and Vicuna by over 30 absolute F1 points on average. Surprisingly, with far fewer parameters, UniversalNER not only matched ChatGPT’s ability to recognize various entity types but exceeded its NER accuracy by 7-9 absolute F1 points on average. UniversalNER even surpassed state-of-the-art multi-task systems like InstructUIE. A series of ablation studies were conducted to evaluate the impact of various elements in the distillation approach.
Mission-Focused Instruction Tuning
Instruction tuning is a technique used to finetune pretrained autoregressive language models to follow natural language instructions and produce responses. While most research has aimed at tuning models for a variety of tasks, the authors introduce a specific method for mission-focused instruction tuning. This method is designed to optimize the model for broader application areas, like open information extraction.
Data Construction
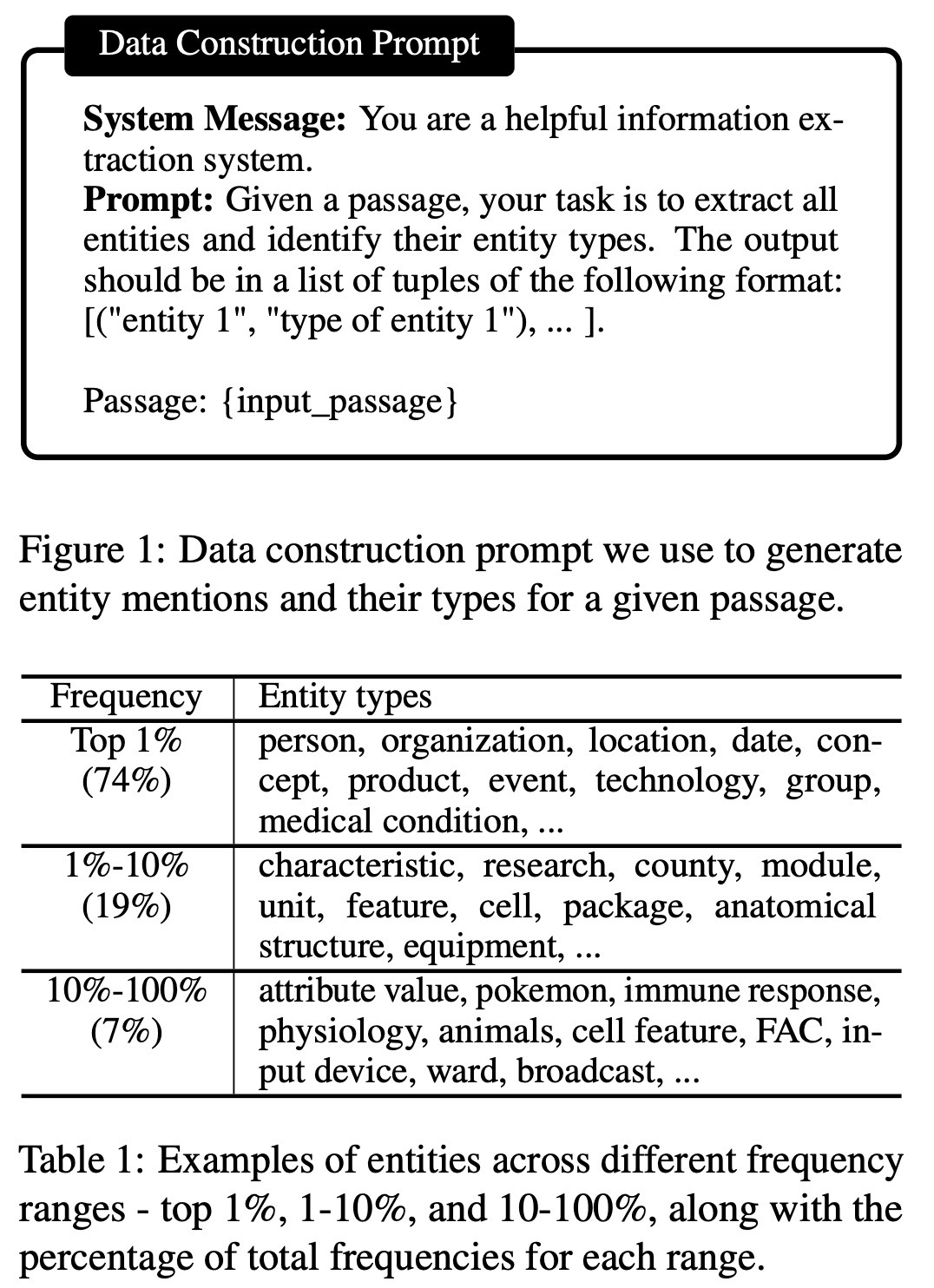
In instruction tuning, examples typically consist of instruction, input, and output. While conventional methods emphasize diverse instructions, mission-focused instruction tuning stresses diverse input, especially for broad application classes. Prior research used language models to produce inputs, assuming known test data domains, which is insufficient for distillation for expansive application areas.
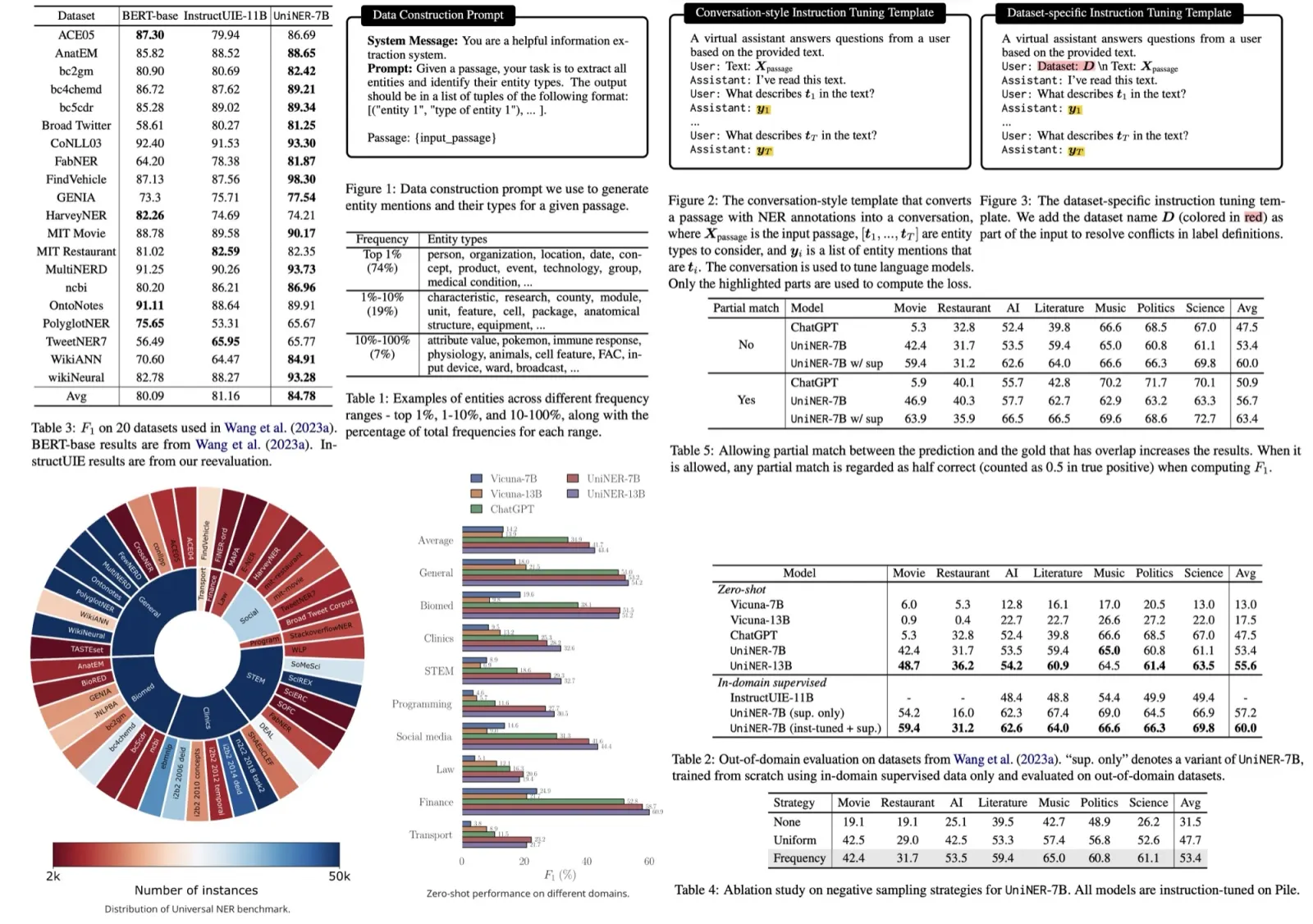
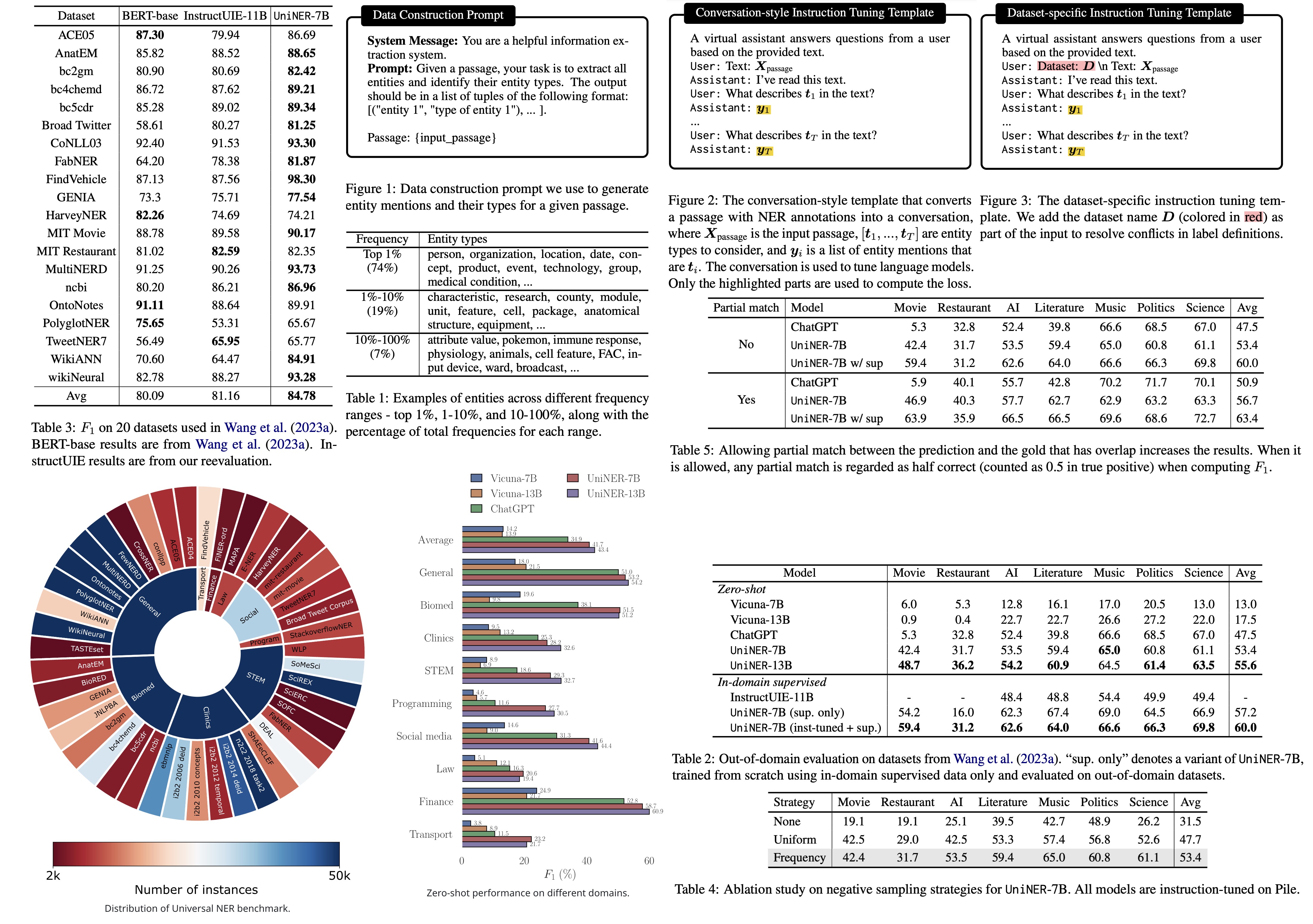
To overcome this, the authors recommend sourcing inputs directly from a comprehensive corpus of varied domains and then using a LLM for outputs. The authors extracted inputs from the Pile corpus, splitting the content into manageable chunks and using ChatGPT to derive entities and their classifications based on these chunks. Importantly, they didn’t limit the entity types, allowing the model to produce a wide range of entity categories.
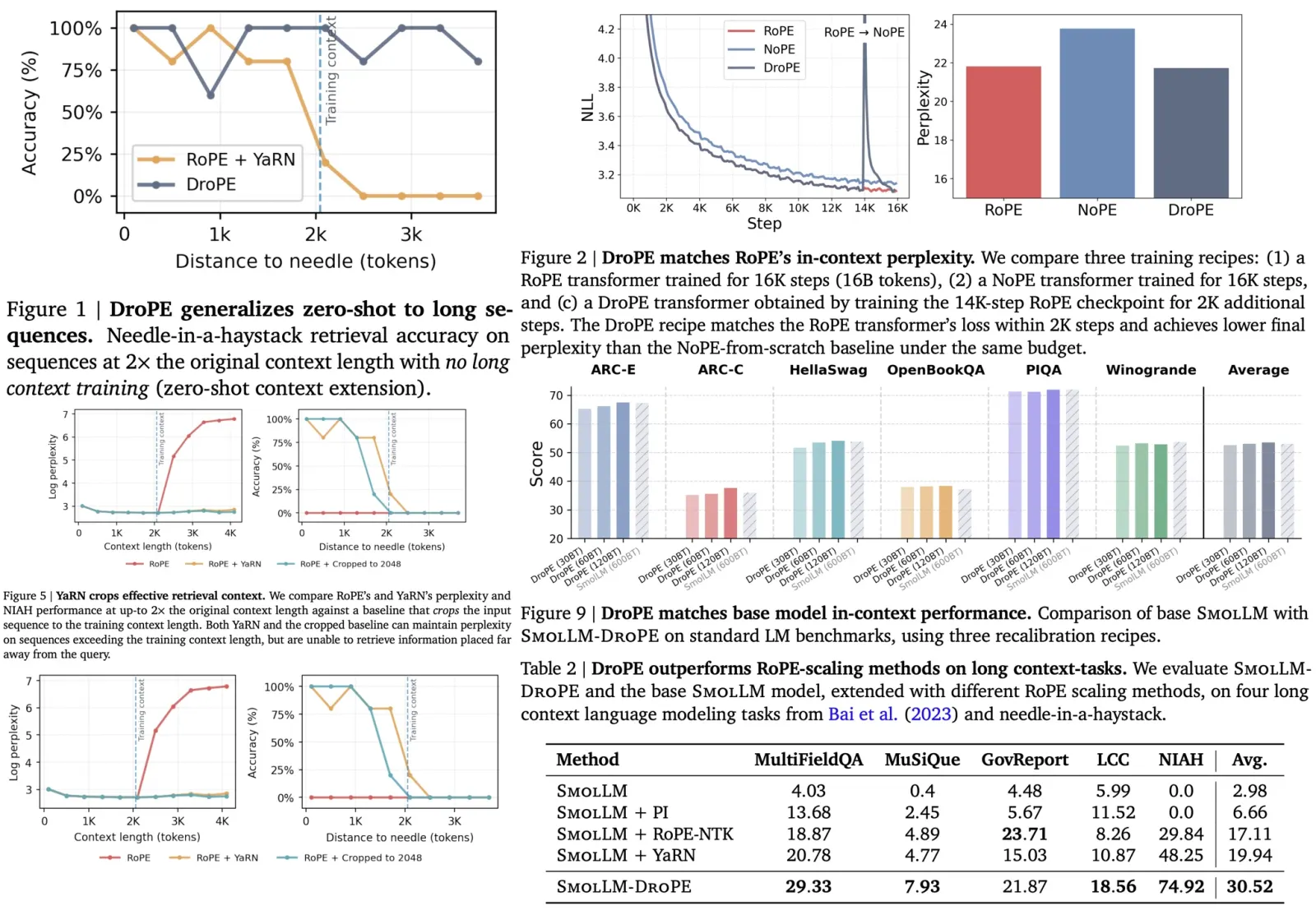
After postprocessing, they obtained 45,889 input-output combinations, covering 240,725 entities and 13,020 unique entity types. The data showed a skewed distribution with a variety of domains and levels of granularity. For instance, some entities belonged to broad categories like “PERSON,” while others were more specific, such as “MEDICAL CONDITION.”
Additionally, they employed ChatGPT not just to identify but also to define entities in brief sentences. This alternative approach produced an even more diverse set of entity types. While this method made the model more adaptable to entity type paraphrasing, it underperformed in traditional NER benchmarks.
Instruction Tuning


The authors fine-tuned smaller models using instruction tuning for recognizing diverse entity types in NER. They adopted a conversation-style tuning format, wherein a passage is presented as input to the language model. For each entity type in the output, the model is queried using natural language, prompting it to produce a structured JSON list output of all entities of that type in the passage. This method proved more effective than the traditional NER-style tuning.
Additionally, instead of focusing on one entity type per query, the authors also experimented with combining all entity types into a single query, prompting the model to provide a consolidated output.
To address the issue of “negative” entity types (those not present in a given passage), the researchers used negative sampling. This involves querying the model for entities that are absent from the passage, with the expected output being an empty JSON list. Negative entity types were sampled based on their frequency in the entire dataset.
Furthermore, when additional human-annotated data was available, supervised fine-tuning was applied to improve model performance. However, discrepancies in label definitions across datasets posed a challenge. To harmonize these differences, the authors suggested dataset-specific instruction tuning templates. These templates incorporated the dataset’s name, allowing the model to recognize and adapt to the specific semantics of labels from different datasets. This ensured that during model evaluation, the appropriate dataset context was used for supervised scenarios, while it was omitted in zero-shot settings.
Universal NER Benchmark
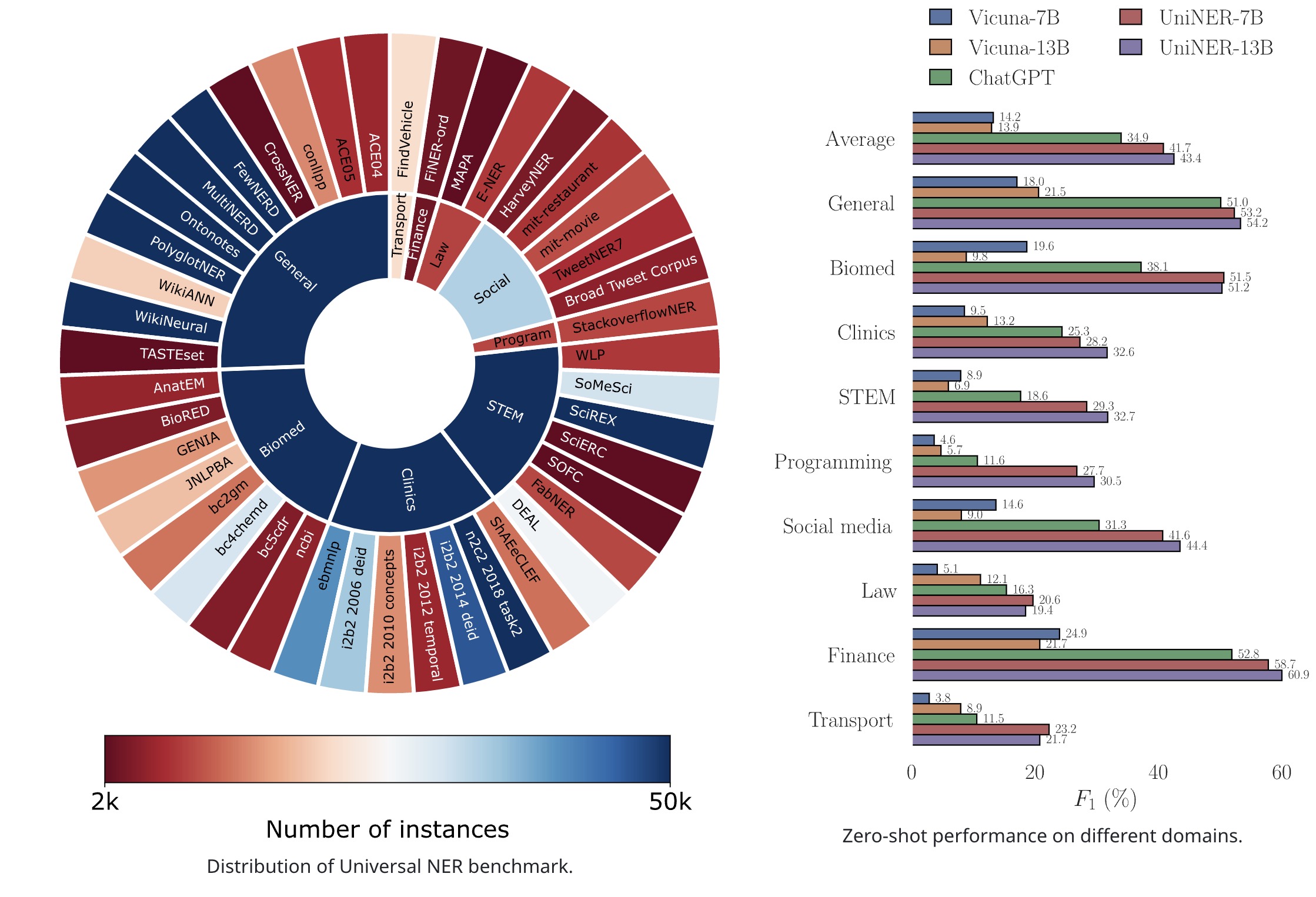
The researchers assembled the largest Named Entity Recognition (NER) benchmark to date, comprising 43 NER datasets across 9 diverse domains, including general, biomedical, clinical, STEM, programming, social media, law, finance, and transportation. To make the entity types more comprehensible to LLMs, they manually inspected the labels and converted them into natural language formats, such as replacing “PER” with “PERSON.”
However, they did not include all possible entity types in their analysis. Some were excluded because they came from inconsistent sources across different datasets and were not aligned with a universal ontology or annotation guideline. Such inconsistencies made those labels unsuitable as a “ground truth” for evaluating a universal NER model. Additionally, the team adjusted document-level datasets that contained very long contexts to fit the input length limits of models, by splitting them into sentence-level instances.
Experiments
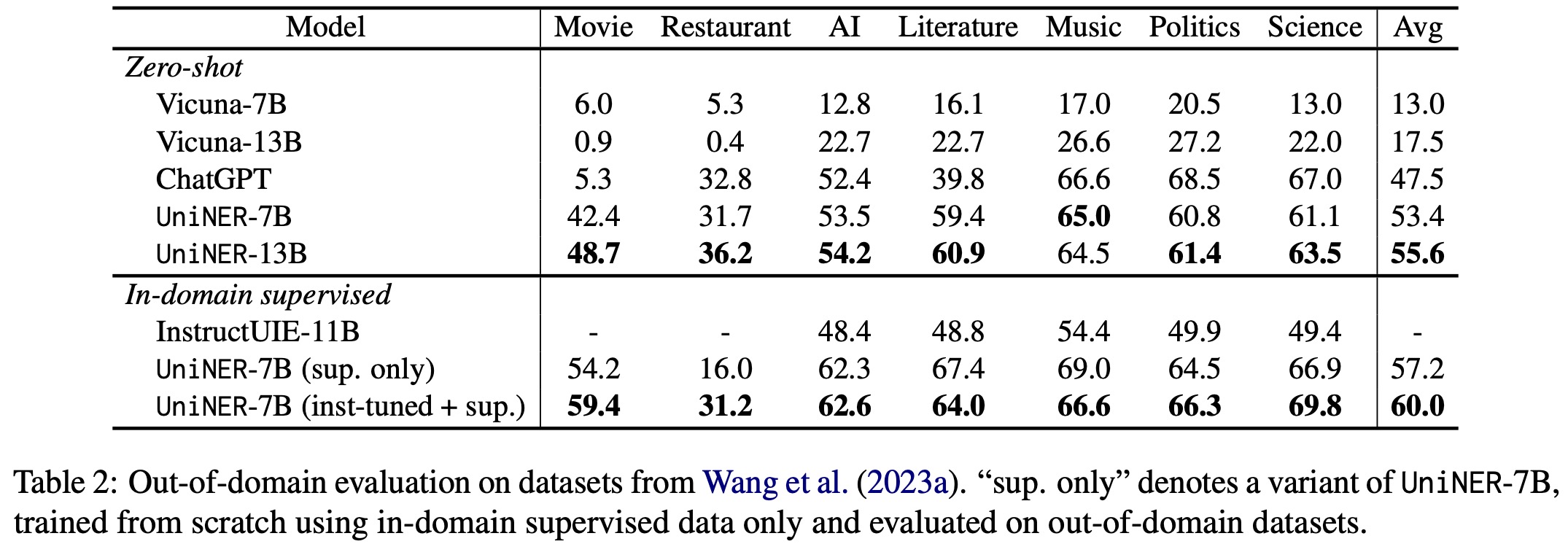
- UniNER’s 7B and 13B versions outperform ChatGPT in terms of average F1 scores, with scores of 41.7% and 43.4% compared to ChatGPT’s 34.9%. This indicates that the targeted distillation from diverse inputs yields better performance across various domains.
- Fine-tuning on larger models, such as UniNER-13B, leads to improved generalization.
- Variants of UniNER were tested, and it was found that combining all entity types into one query and response or using entity type definitions resulted in lower performance. The performance drop was attributed to factors such as lower consistency with evaluation datasets and increased task complexity.
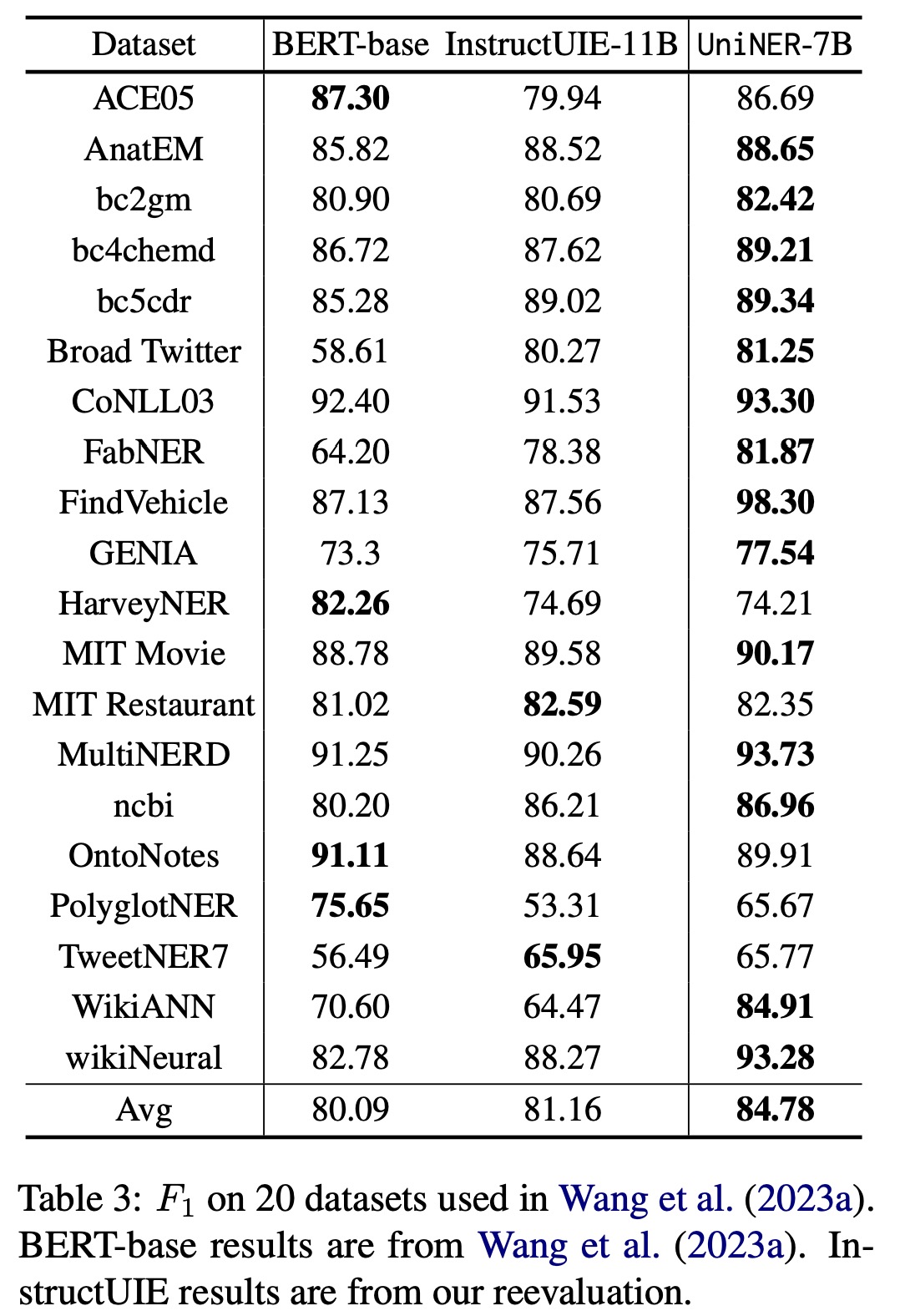
- A study of out-of-domain and in-domain evaluations revealed that UniNER surpassed other models and could be further improved with additional human annotations. The in-domain supervised setting led to an average F1 score of 84.78%, outperforming other benchmark models.
Ablations

- Negative Sampling Strategies: Three different strategies were tested: no sampling, uniform sampling (equal probability for each entity type), and frequency-based sampling (based on the entity type’s frequency in the dataset). Frequency-based sampling was found to be the most effective, significantly outperforming the other two methods.
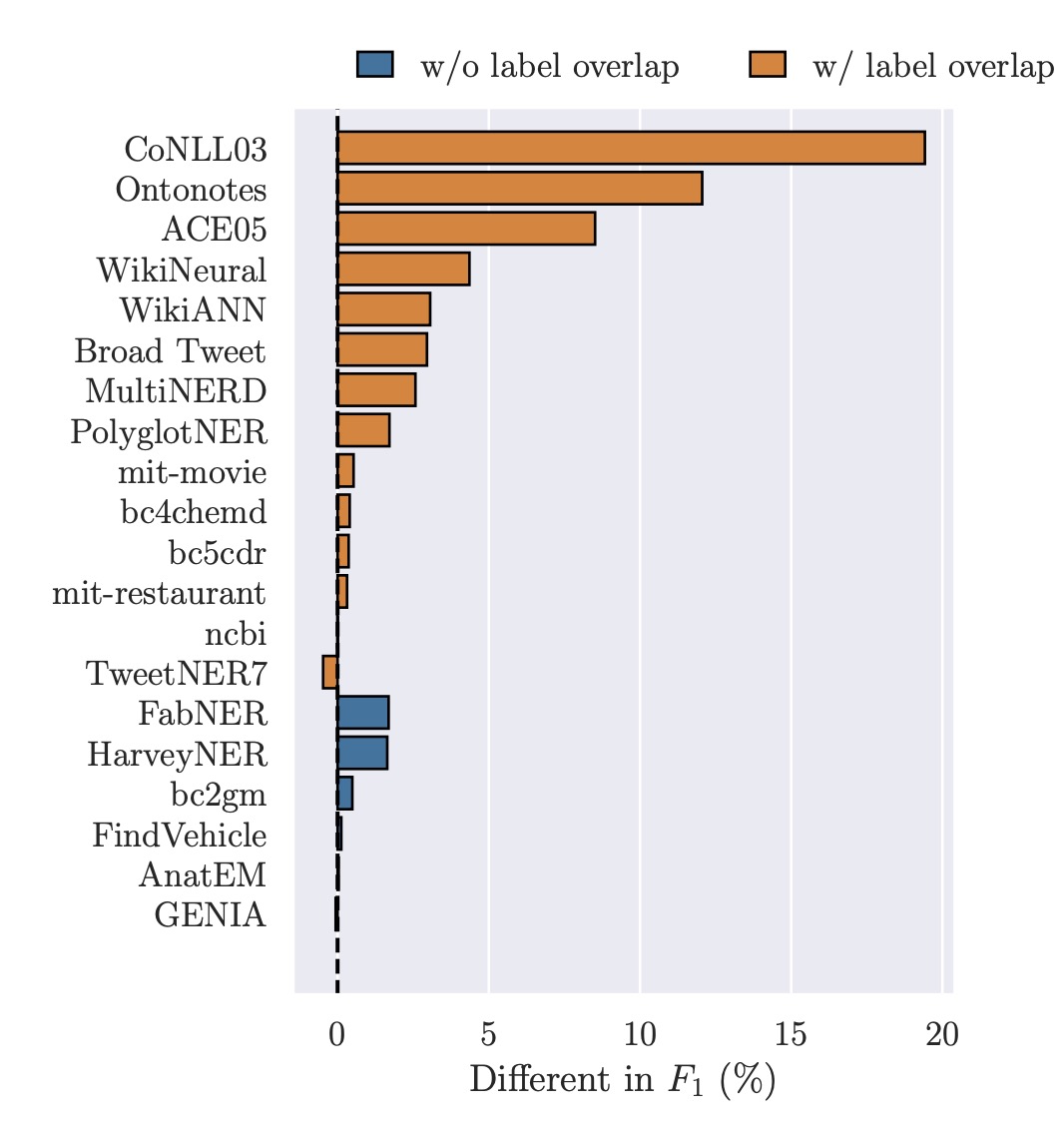
- Dataset-specific Template: Comparing a dataset-specific instruction tuning template to the original template showed that the former performed better, especially on datasets with overlapping entity type labels. Two entity types, FACILITY and TIME, were notably improved with the dataset-specific template due to inconsistencies in their definitions across different datasets.
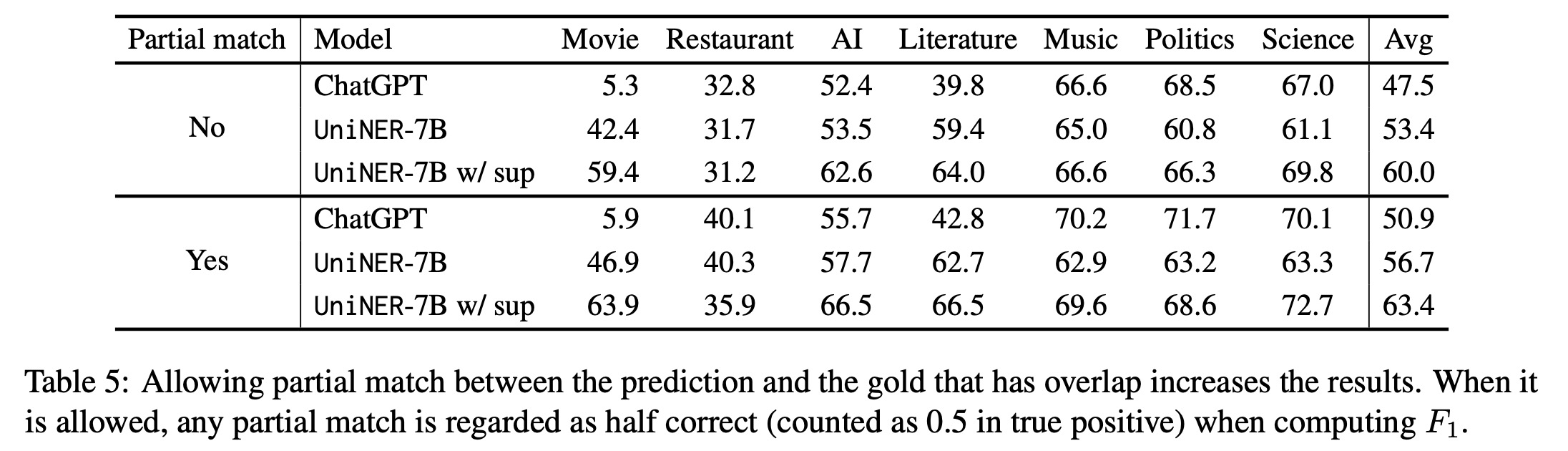
- Evaluation with Partial Match: Using strict F1 as an evaluation metric may underestimate a model’s zero-shot learning capabilities since slight misalignments in entity boundaries are penalized. Therefore, a “partial match” evaluation method was introduced, where predictions overlapping with the ground truth are considered half correct. Using this method yielded higher scores, suggesting it might be a more lenient but realistic measure of performance.