Paper Review: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

Visual AutoRegressive modeling is a new approach to autoregressive learning for images by focusing on coarse-to-fine scale prediction, moving away from the traditional raster-scan method of predicting the next token. This methodology allows autoregressive transformers to quickly learn visual distributions and exhibit better generalization capabilities. For the first time, VAR enables GPT-style autoregressive models to outperform diffusion transformers in image generation tasks.
On the ImageNet 256×256 benchmark, VAR significantly improved upon the autoregressive baseline, enhancing the FID from 18.65 to 1.80 and the IS from 80.4 to 356.4, while also achieving a 20× faster inference speed. VAR not only surpasses the Diffusion Transformer in image quality, inference speed, data efficiency, and scalability but also demonstrates power-law scaling laws similar to those seen in LLMs, with near-perfect linear correlation coefficients. Additionally, VAR exhibits zero-shot generalization capabilities in tasks like image in-painting, out-painting, and editing.
The approach
Preliminary: autoregressive modeling via next-token prediction
In traditional next-token autoregressive modeling, the probability of observing a current token depends solely on its preceding tokens, allowing the decomposition of a sequence’s likelihood into conditional probabilities. For images, which are 2D continuous signals, this involves tokenizing the image into discrete tokens and arranging them in a 1D order for modeling. A quantized autoencoder is used to convert image feature maps into discrete tokens, which are then arranged in a specific order (like raster scan or spiral) to train the autoregressive model.
However, this method faces several issues:
- Mathematical Premise Violation: The inherent bidirectional correlations among image tokens contradict the unidirectional dependency assumption of autoregressive models.
- Structural Degradation: Flattening the image tokens disrupts the spatial locality, compromising the relationships between each token and its immediate neighbors.
- Inefficiency: The process is computationally expensive, with the generation of an image token sequence incurring a significant computational cost due to the model’s self-attention mechanism.
Visual autoregressive modeling via next-scale prediction
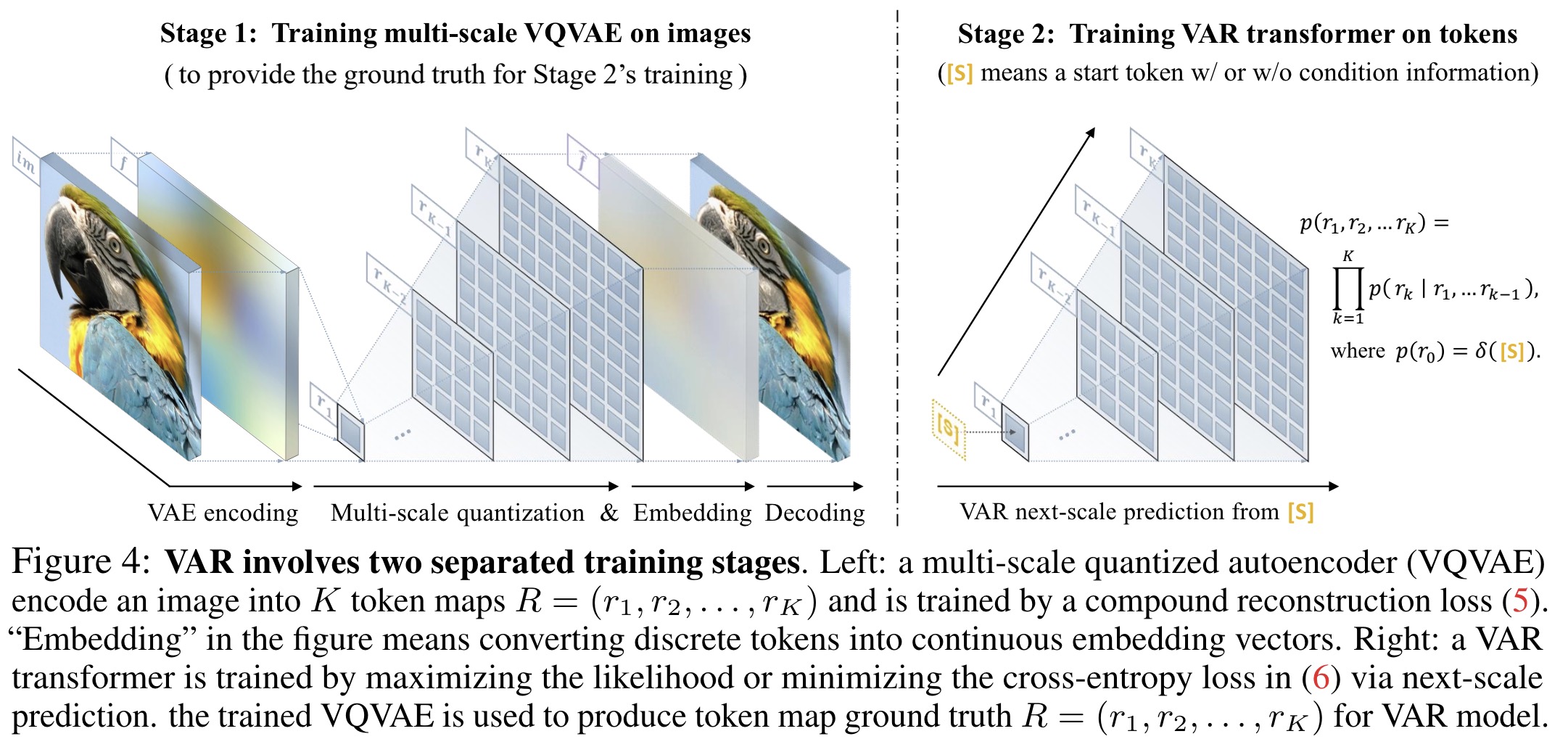
The reformulated approach, termed Visual Autoregressive modeling, shifts from traditional next-token prediction to a next-scale prediction strategy for image autoregression. Instead of predicting a single token next, VAR predicts entire token maps at progressively higher resolutions, starting from a quantized feature map and building up to the original resolution. This is done by generating each token map conditioned on all previous maps, parallelizing the generation process within each scale and addressing the limitations of traditional methods:
- Mathematical Consistency: By ensuring each scale depends only on the previous scales, VAR aligns with the natural process of human visual perception and artistic drawing, thus maintaining a logical mathematical premise.
- Spatial Locality Preservation: VAR avoids the issue of disrupting spatial locality by not flattening the token maps and ensuring full correlation within each scale, further supported by the multi-scale approach.
- Reduced Computational Complexity: The efficiency of generating images is greatly improved, with computational complexity reduced to a factor of the image’s dimensions squared, due to the parallel generation of tokens at each scale.
VAR employs a multi-scale quantization autoencoder, similar in architecture to VQGAN but modified for multi-scale quantization, to encode images into discrete token maps for each scale. This process utilizes a shared codebook across scales to ensure consistency and employs extra convolution layers to manage information loss during upscaling, without convolutions post-downsampling.

Experiments
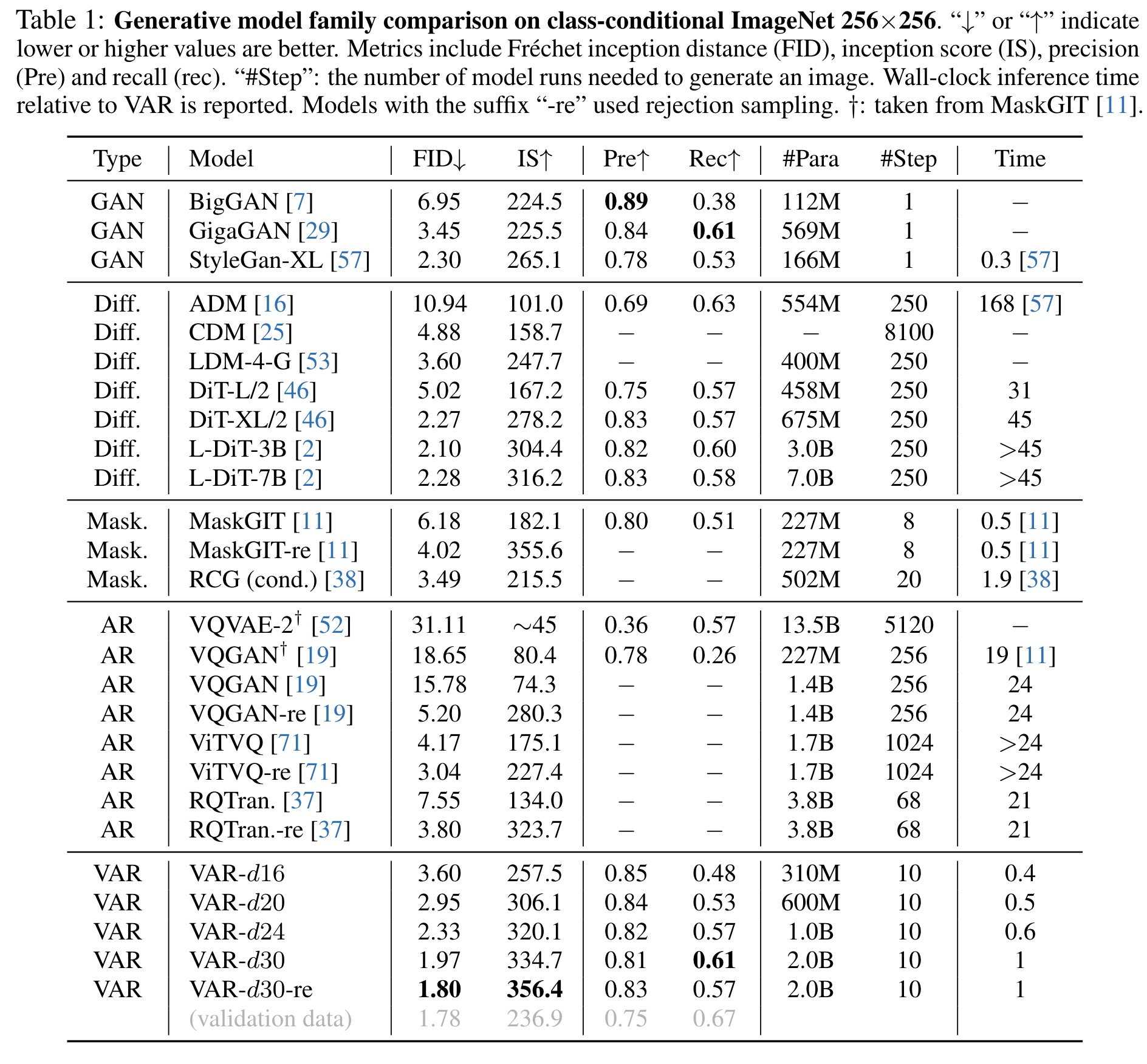
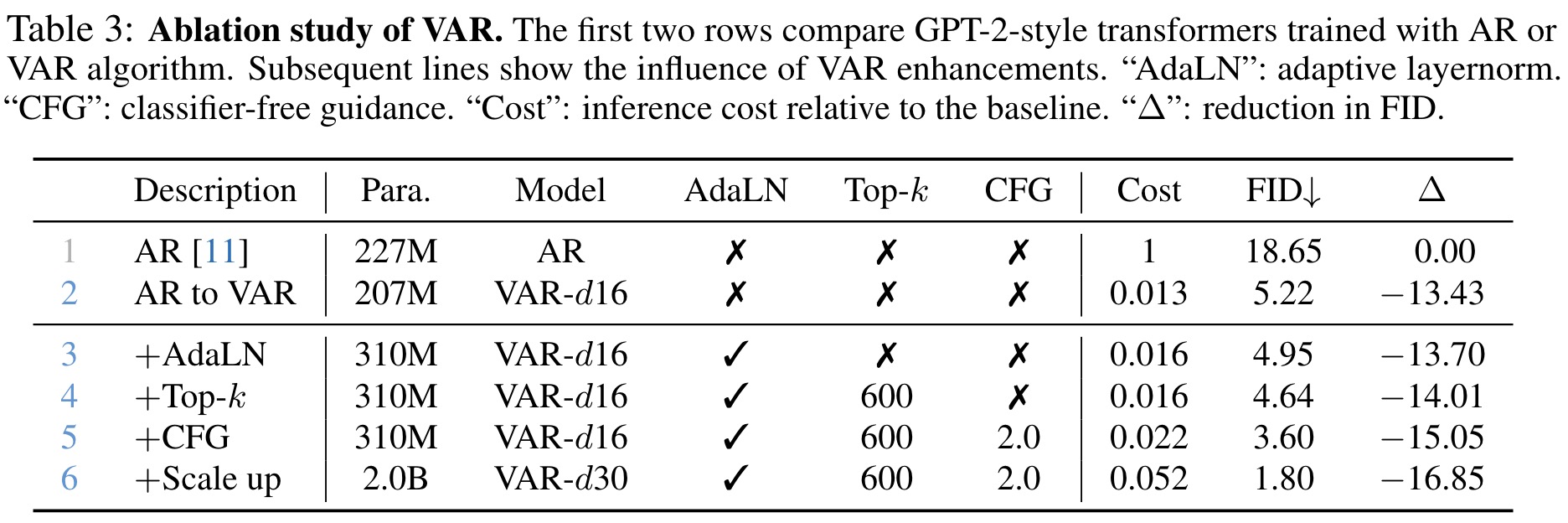
VAR model surpasses traditional generative approaches such as GANs, diffusion models, BERT-style masked-prediction models, and GPT-style autoregressive models. It achieves superior FID and IS metrics, indicating higher image generation quality and diversity. It also offers remarkable speed in image generation, being about 20 times faster than models like VQGAN and ViT-VQGAN, and reaching speeds comparable to efficient GAN models that generate images in a single step. This efficiency stems from VAR’s innovative approach that requires significantly fewer iterations and computations for image generation. Compared to popular diffusion models VAR demonstrates better performance in diversity and quality of generated images, maintains comparable precision and recall, and boasts significantly faster inference speeds. Additionally, VAR is more data-efficient, requiring fewer training epochs, and shows better scalability, with consistent improvements in FID and IS metrics as model parameters increase.
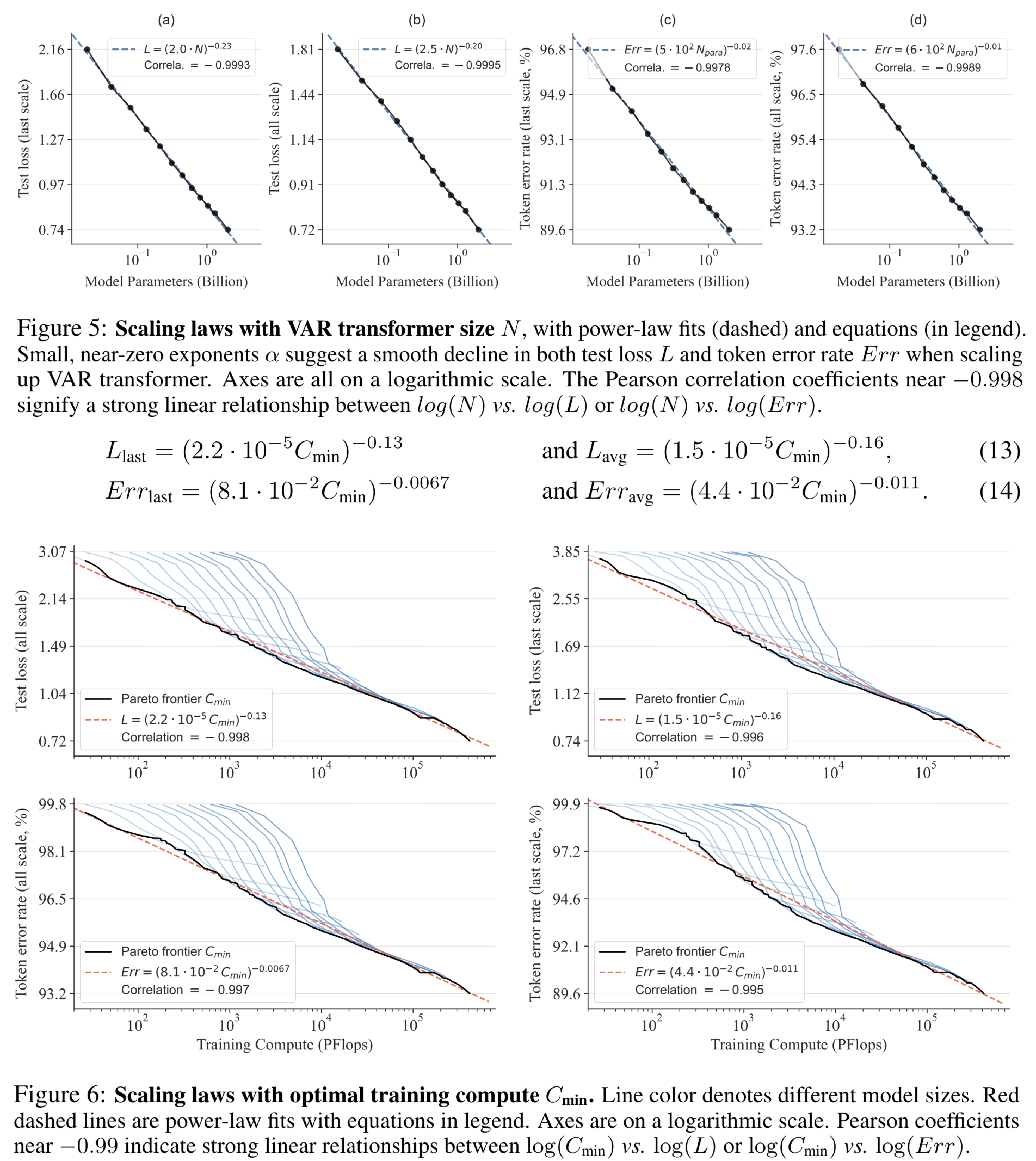
The power-law scaling laws suggest that increasing the size of autoregressive models leads to a predictable decrease in test loss, correlating with the model’s parameter counts, training tokens, and optimal training compute, all following a power-law relationship. This predictability not only confirms the scalability of LLMs but also serves as a tool for forecasting the performance of larger models, thus optimizing resource allocation.
In examining VAR models, the authors followed protocols from prior research, training models across various sizes (from 18M to 2B parameters) and observing their performance on the ImageNet dataset. The findings reveal a clear power-law scaling trend in test loss and token prediction error rates as model size increases, echoing the results found in LLMs. Moreover, the experiments show that larger VAR transformers are more compute-efficient, achieving comparable performance levels with less computational effort.
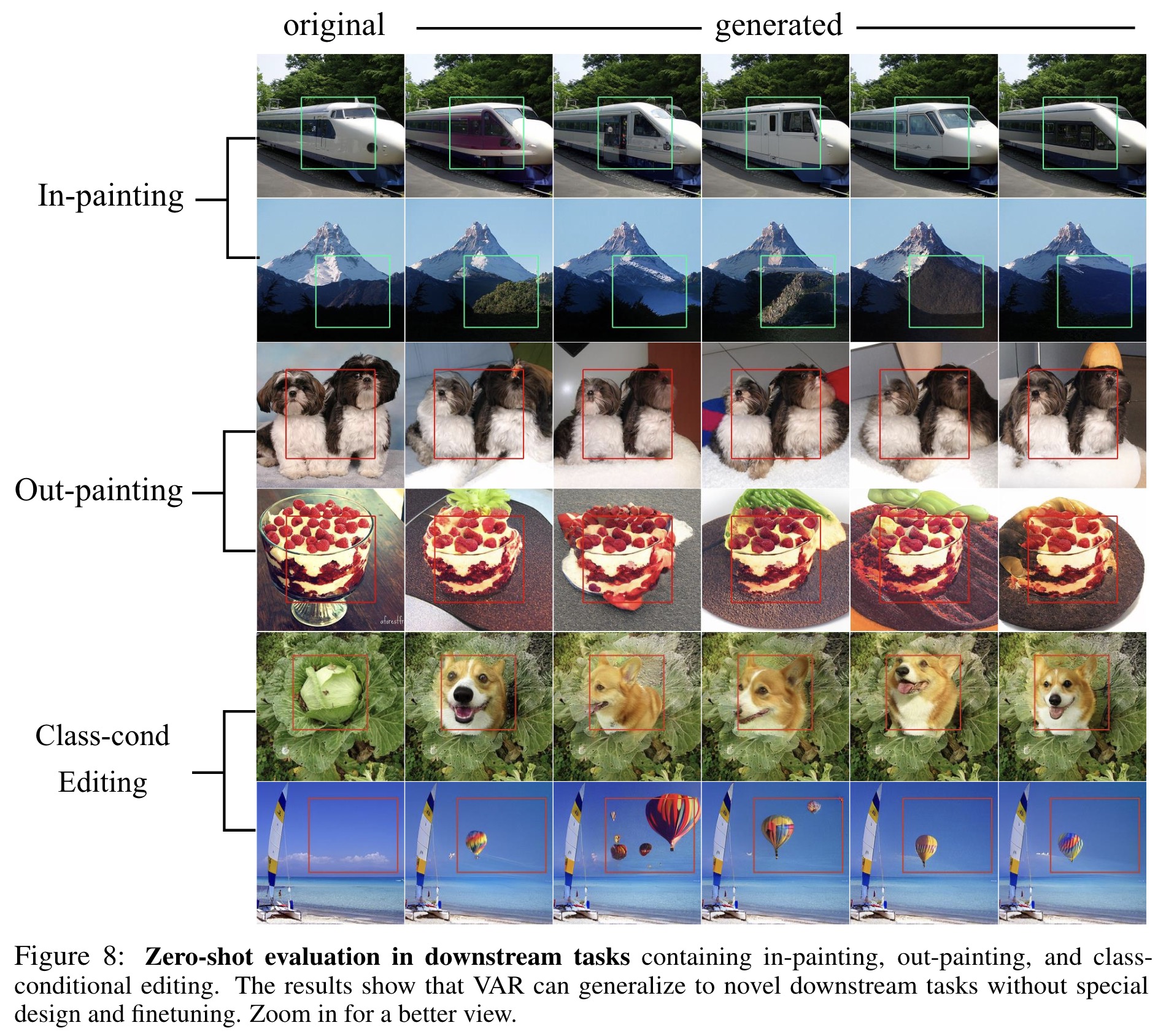
VAR was tested on image in-painting and out-painting tasks, where it successfully generated tokens within specified masks without any class label information. This demonstrates VAR’s ability to generalize and perform well on downstream tasks without requiring modifications to its architecture or parameter adjustments. Additionally, VAR was applied to class-conditional image editing tasks, following the approach of MaskGIT, by generating tokens within a bounding box based on a class label.