Paper Review: Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
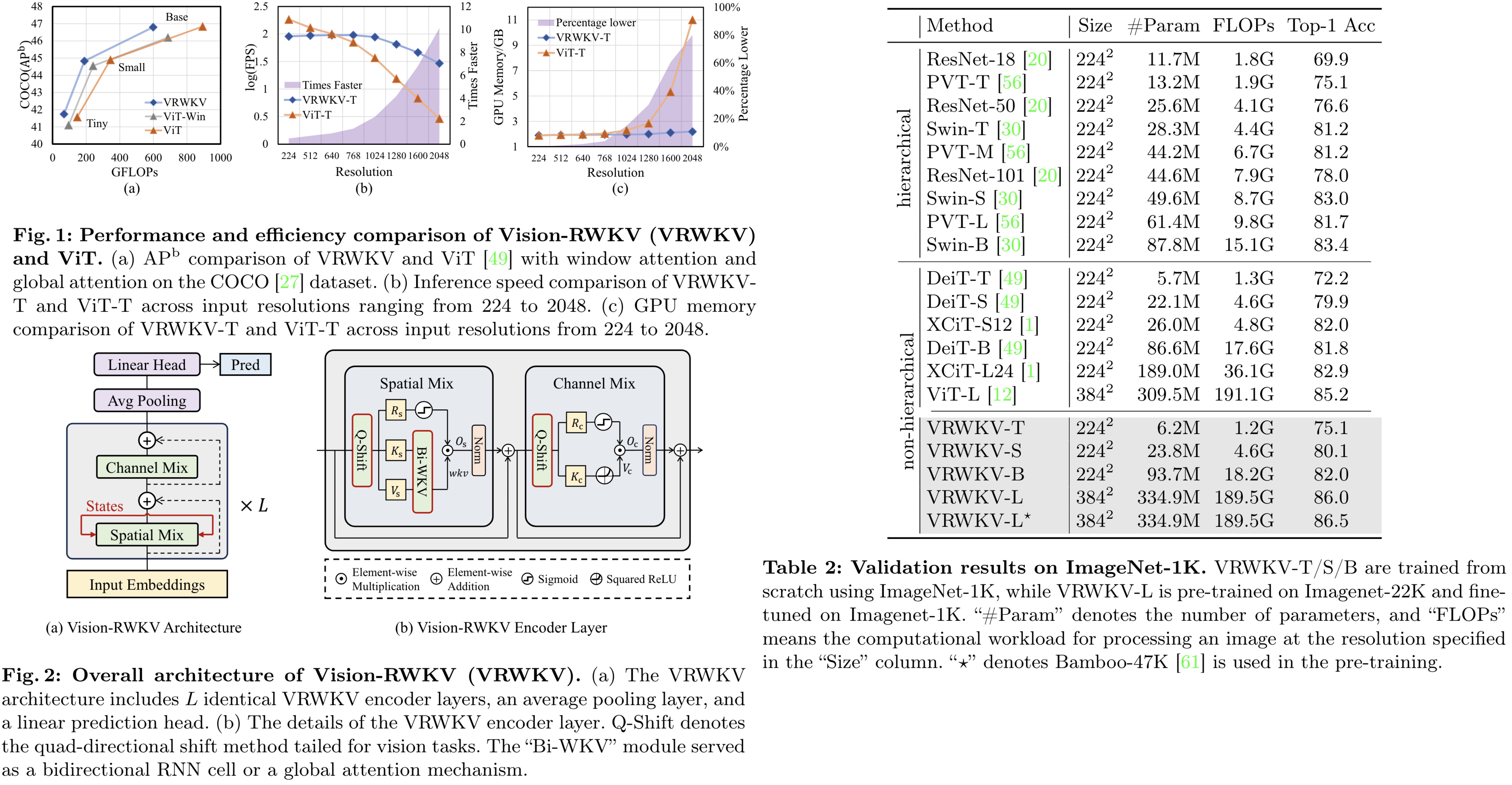
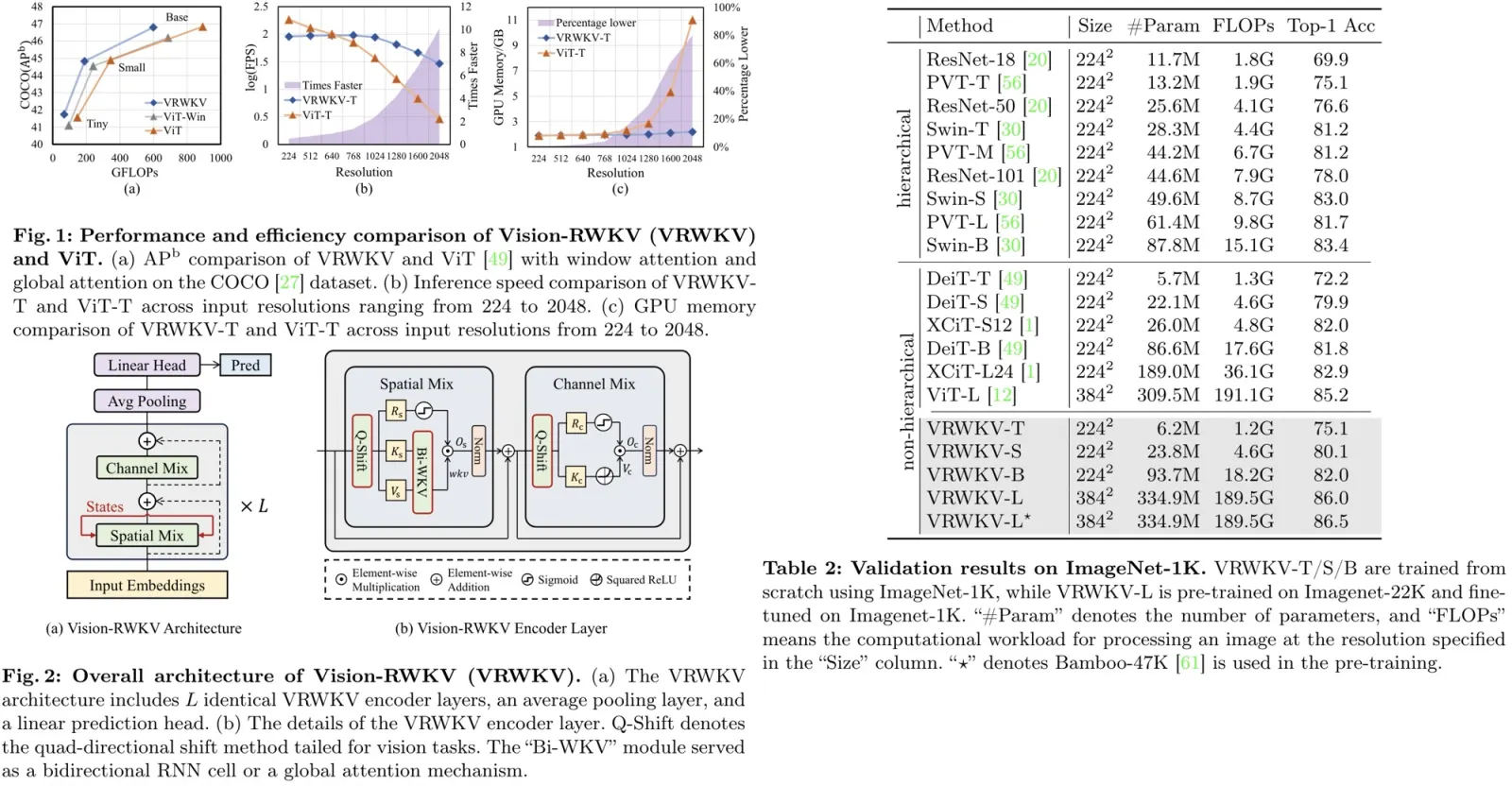
Vision-RWKV is a vision model adapted from the RWKV designed to handle sparse inputs and perform robust global processing efficiently. It scales well with large parameters and datasets, and its reduced spatial aggregation complexity allows for seamless high-resolution image processing without windowing operations. VRWKV outperforms the ViT in image classification, showing faster speeds and lower memory usage for high-resolution inputs. In dense prediction tasks, it surpasses window-based models while maintaining comparable speeds, presenting itself as a more efficient alternative for visual perception tasks.
The approach
Architecture
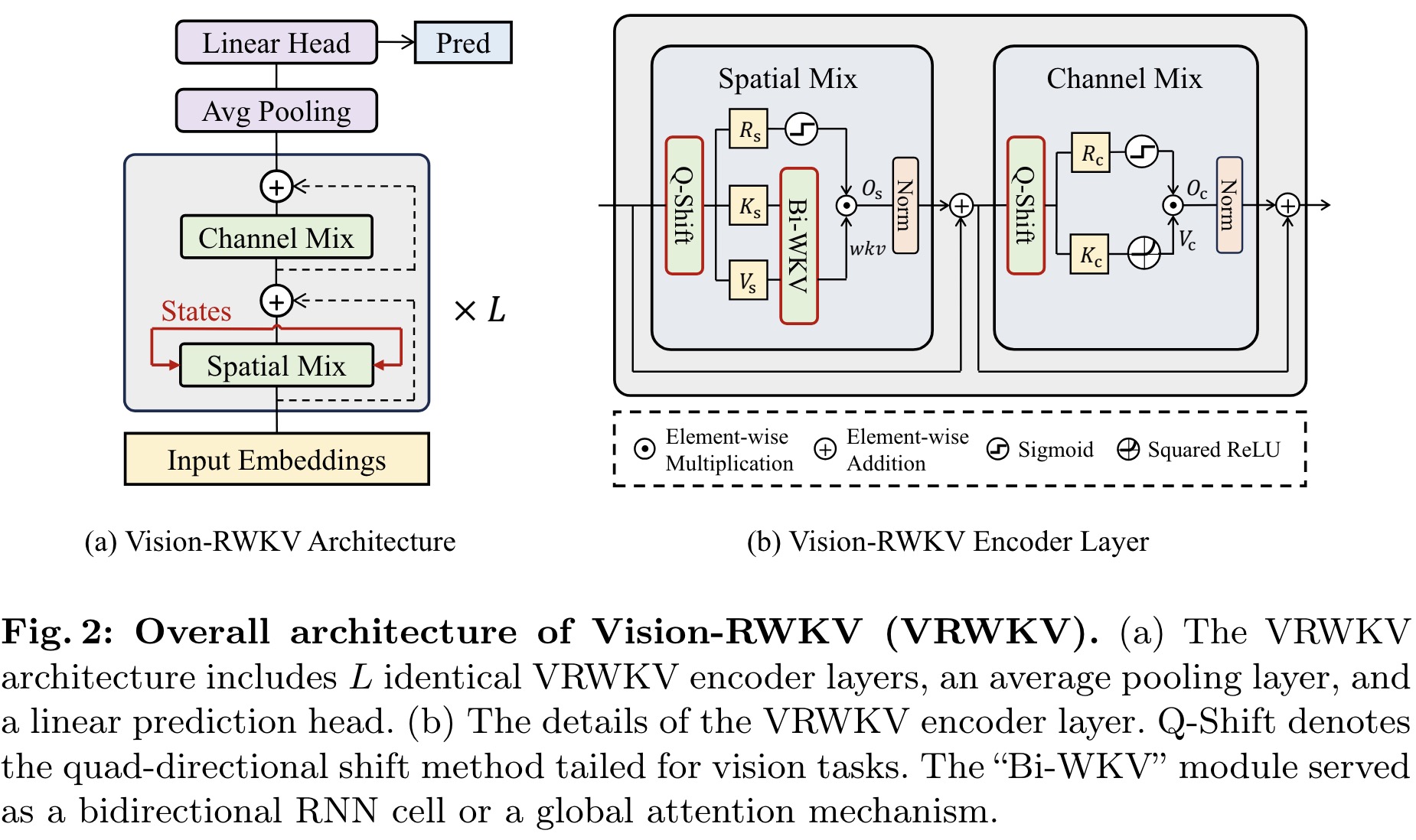
Vision-RWKV supports sparse input and stable scaling by incorporating a block-stacked image encoder design similar to the ViT, consisting of spatial-mix and channel-mix modules for attention and feature fusion, respectively. VRWKV processes images by converting them into patches, adding position embeddings to form image tokens, which then pass through L identical encoder layers maintaining the input resolution.
The spatial-mix module performs global attention computation through a linear complexity bidirectional attention mechanism, using Q-Shift functions for adapting to vision tasks and a sigmoid function for output control. The channel-mix module focuses on channel-wise feature fusion, employing a similar Q-Shift and gate mechanism for output. Additionally, the model includes layer normalization and residual connections to prevent vanishing gradients, ensuring robust training stability.
Linear Complexity Bidirectional Attention
The original RWKV attention mechanism is modified for vision tasks with three key changes:
- Introducing bidirectional attention to ensure all tokens are mutually visible by extending the attention range to the entire token set, transforming causal attention into bidirectional global attention;
- Adding a relative bias based on the time difference between tokens, normalized by the total number of tokens, to account for relative positions in differently sized images;
- Allowing a flexible decay parameter in the exponential term, enabling the model to focus on tokens further away from the current one across different channels;
Quad-Directional Token Shift
An exponential decay mechanism is used to reduce the complexity of global attention from quadratic to linear, significantly improving computational efficiency for high-resolution images. To better capture the two-dimensional relationships in images, a quad-directional token shift operation is introduced in both the spatial-mix and channel-mix modules. It linearly interpolates each token with its neighboring tokens in four directions—up, down, left, and right—across different channel segments. Q-Shift minimally increases computational demand while significantly expanding the receptive field of tokens, enhancing spatial relationship coverage in the model’s later layers.
Scale Up Stability
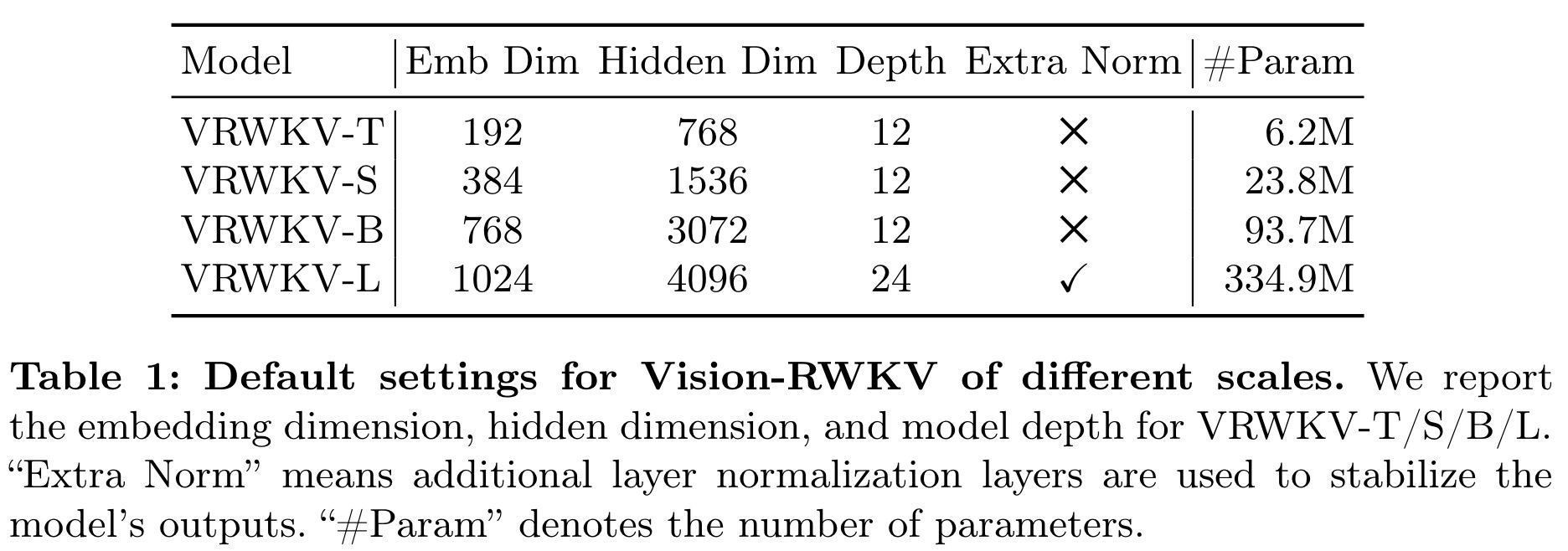
To address potential instability in model outputs and training caused by increasing the number of layers and accumulation in the exponential term during recursion, two modifications are made:
- Bounded exponential - the exponential term is divided by the number of tokens to keep decay and growth within a manageable range;
- Extra layer normalization, added after the attention mechanism and Squared ReLU operation to prevent output overflow in deeper models.
Additionally, the authors use layer scale.
Experiments
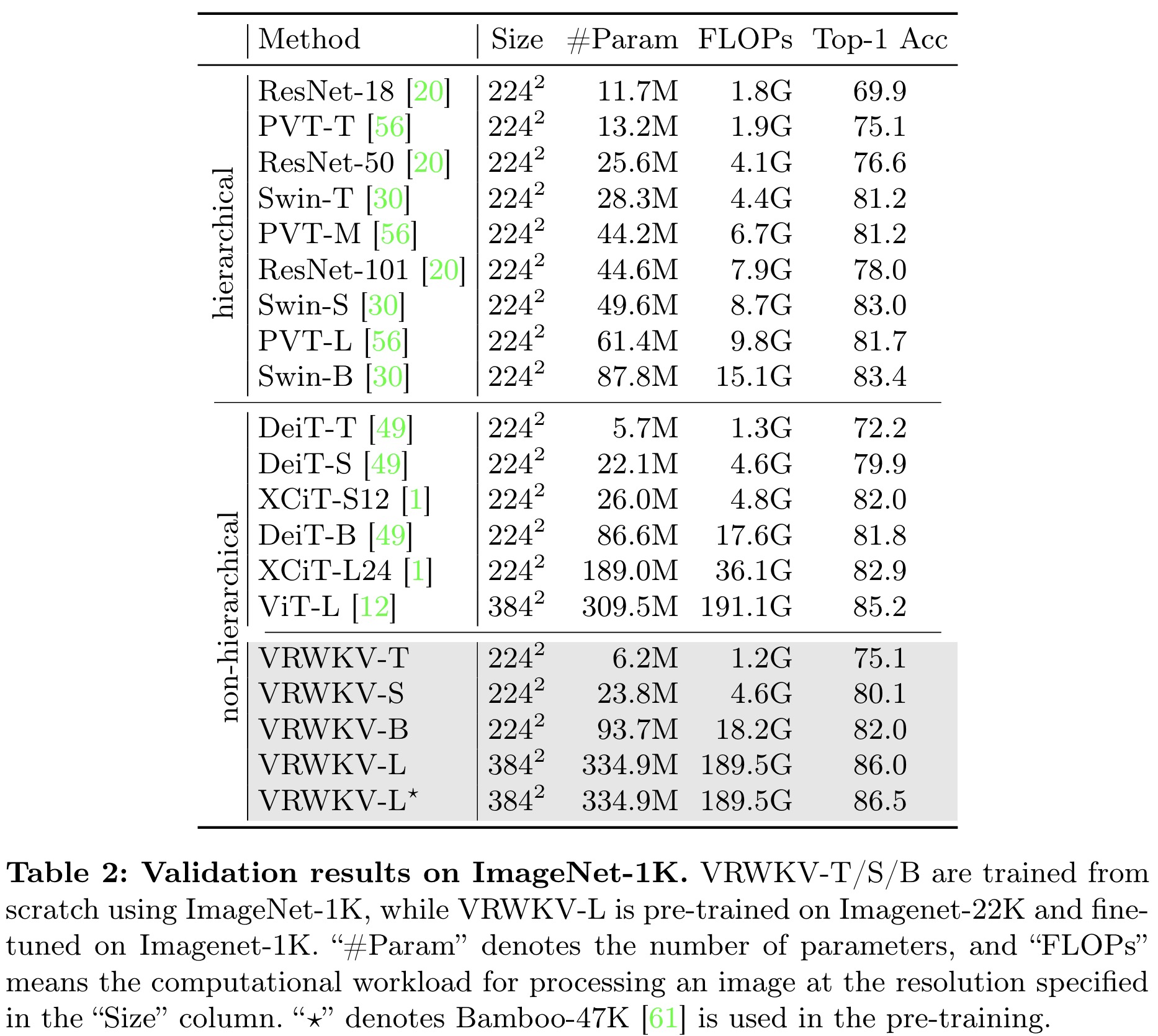
The VRWKV model demonstrates superior performance across various model sizes on the ImageNet-1K validation dataset, outperforming both hierarchical and non-hierarchical backbones like ViT, with higher top-1 accuracy and lower or comparable computational complexity. Notably, VRWKV-T surpasses DeiT-T in accuracy with lower FLOPs, and VRWKV-L achieves higher accuracy than ViT-L at a reduced computational cost. Pre-training on large-scale datasets further boosts VRWKV’s performance, indicating its scalability and potential as an alternative to traditional ViT models.
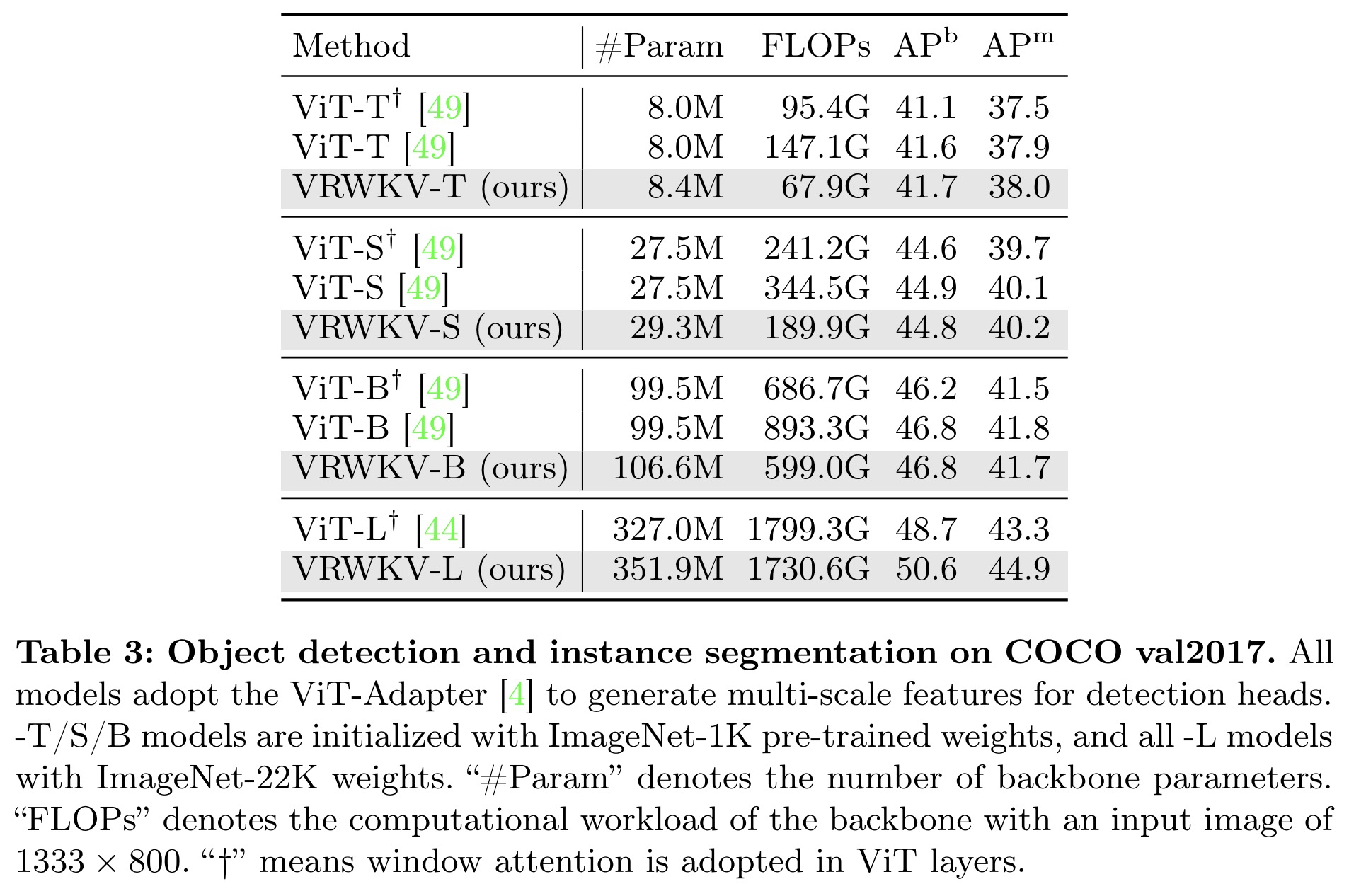
In object detection on the COCO dataset, VRWKV shows better performance than ViT with significantly lower FLOPs, benefiting from its global attention mechanism in dense prediction tasks.
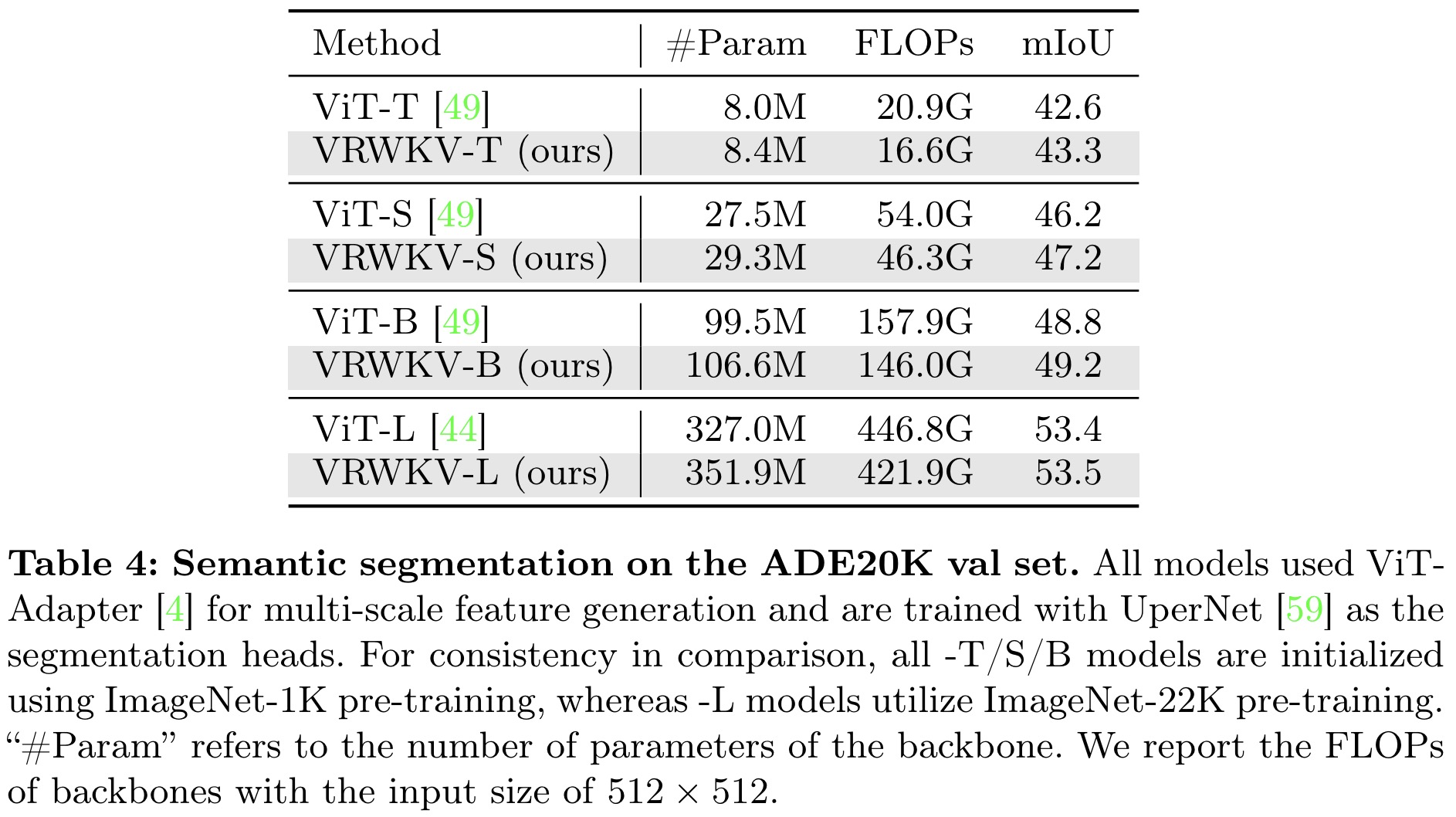
VRWKV’s advantage extends to semantic segmentation tasks, where it outperforms ViT models in efficiency and accuracy, showcasing the effectiveness of its linear complexity attention mechanism.
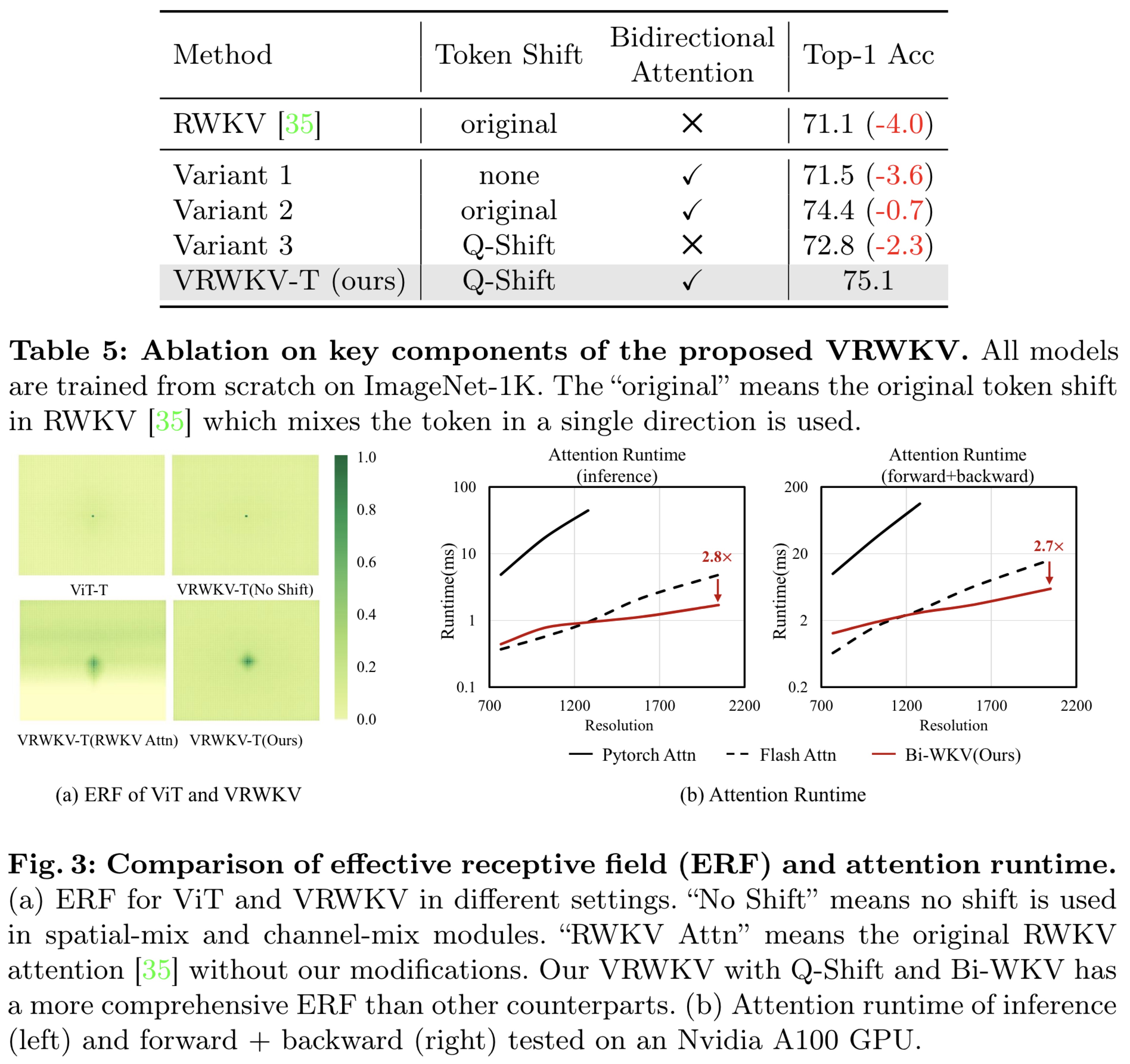
- Ablation studies on the tiny-sized VRWKV model on the ImageNet-1K dataset validate key components like Q-Shift and bidirectional attention, showing significant performance improvements. Without token shift, performance drops significantly, while the original shift method still lags behind the newly introduced Q-Shift. Implementing bidirectional attention increases top-1 accuracy by 2.3 points.
- Analysis of the effective receptive field highlights that all models except those using the original RWKV attention achieve global attention, with VRWKV-T outperforming ViT-T in global capacity. Q-Shift notably enhances the receptive field’s core range, boosting global attention inductive bias.
- Efficiency analysis demonstrates that at higher resolutions (up to 2048x2048), VRWKV-T significantly outperforms ViT-T in inference speed and memory usage on an Nvidia A100 GPU, thanks to its linear attention mechanism and RNN-like computational framework.
- MAE pre-training further enhances VRWKV’s performance, with a top-1 accuracy improvement on ImageNet-1K validation, showcasing its ability to benefit from sparse inputs and masked image modeling.