Paper Review: Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models

ChatGPT provides a language interface with distinctive conversational competency and reasoning capabilities across many domains, but it is currently incapable of processing or generating images from the visual world. To overcome these limitations, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system can handle complex visual questions or instructions that require multiple AI models and steps, and also allows for feedback and corrections.
The general approach
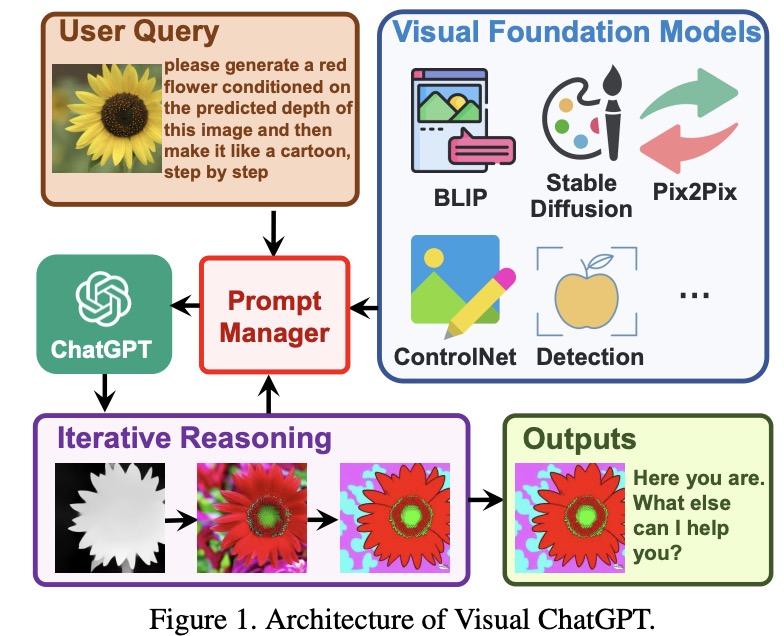
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions, including specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager’s help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users’ requirements or reaches the end condition.
Visual ChatGPT
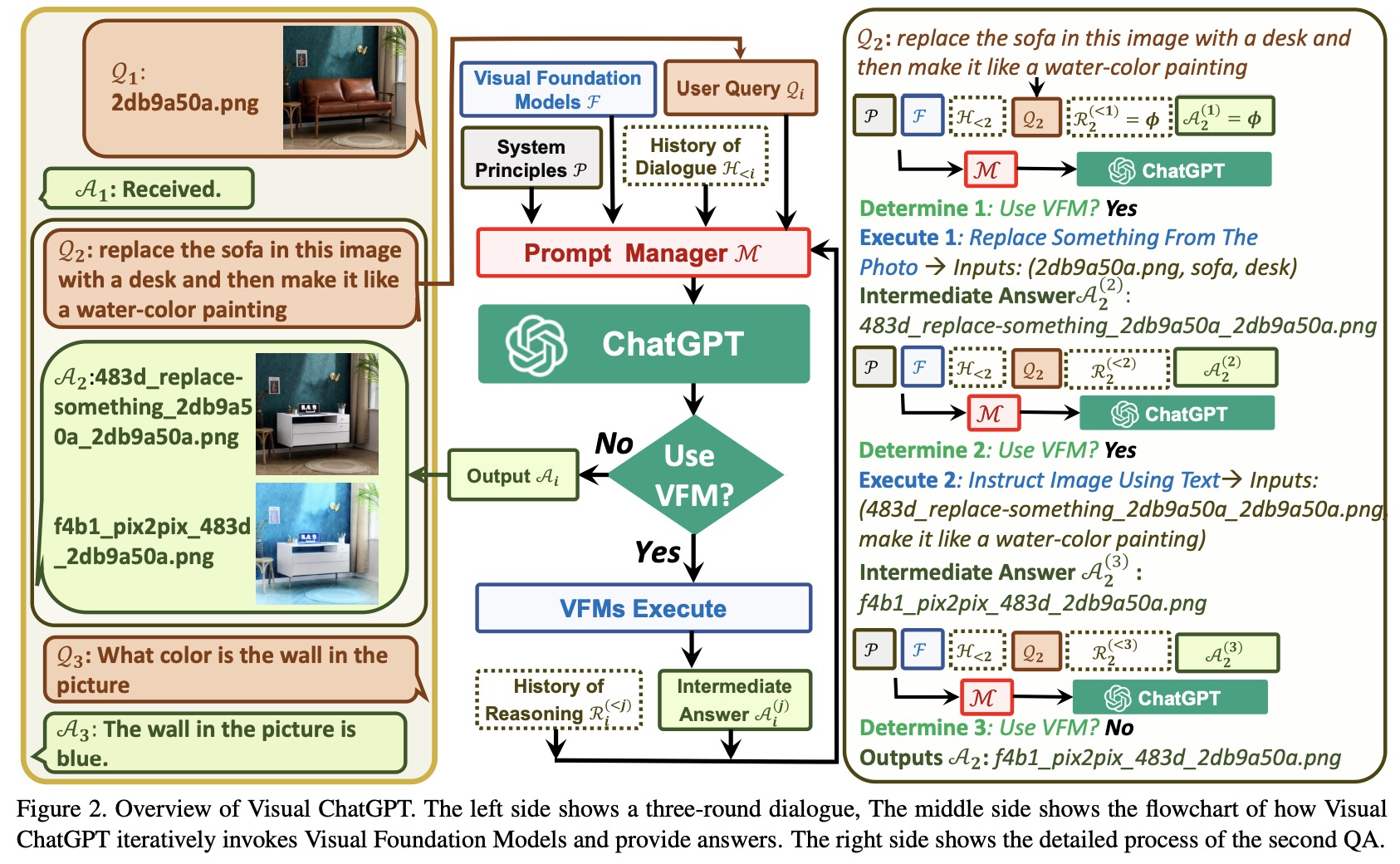
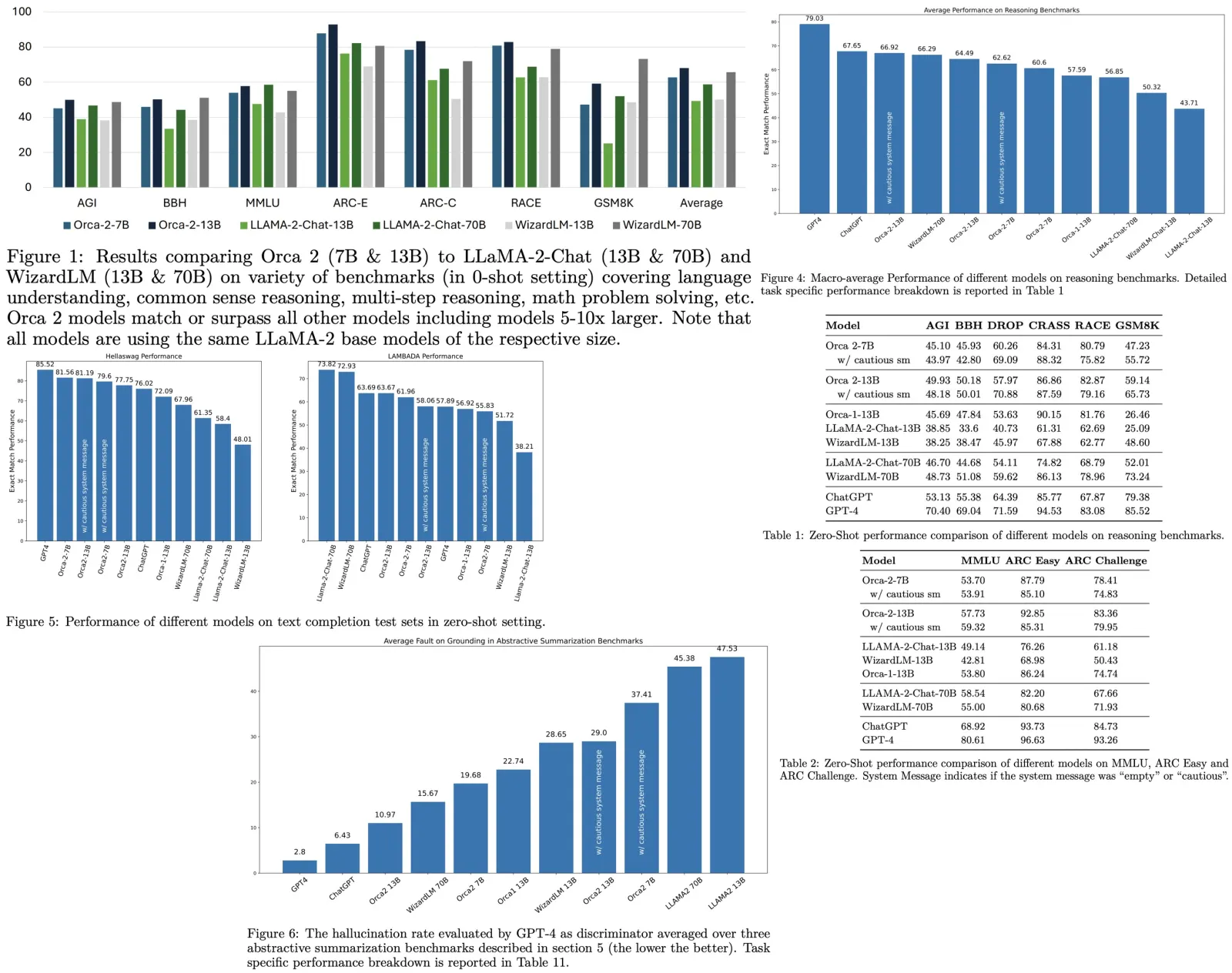
Visual ChatGPT provides output based on: rules, VFMs, history of dialogue (truncated to meet the input length of ChatGPT model), user query, history of reasoning (outputs of previously used VFMs), intermediate answer (when answering step-by-step), prompt manager.
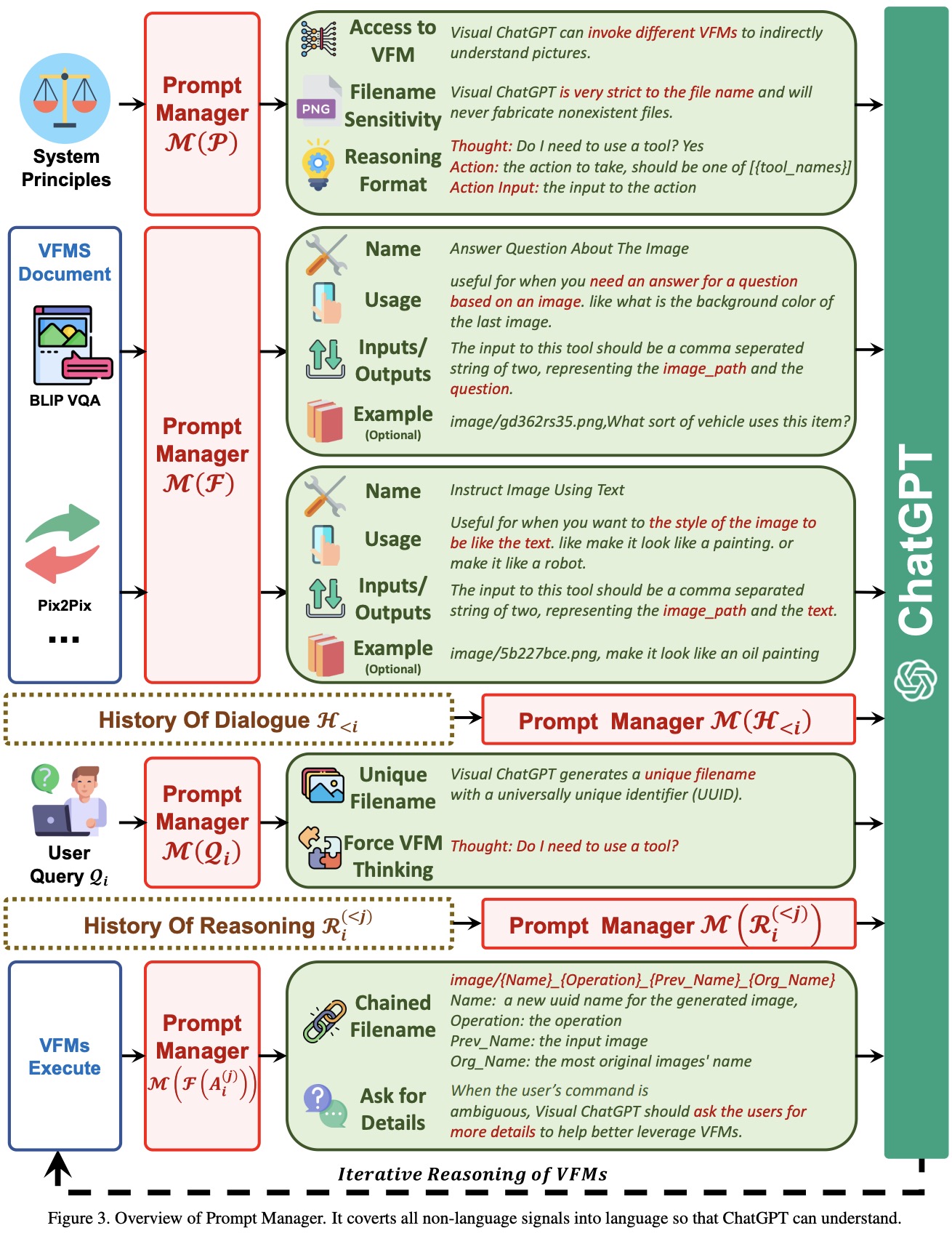
Prompt Managing of System Principles
Visual ChatGPT is a system that combines various VFMs to comprehend visual information and generate answers. To achieve this, the authors customize certain system principles and transfer them into prompts that ChatGPT can understand. These prompts serve several purposes, including:
- VFMs Accessibility. Visual ChatGPT has access to a list of VFMs and decides which ones to use;
- Filename Sensitivity - to avoid ambiguity;
- Chain-of-Thought - when a command requires several VFMs;
- Reasoning Format Strictness. Visual ChatGPT needs to follow a strict reasoning format, so the authors use regex matching algorithms to parse the intermediate reasoning results;
- Reliability. The authors design prompts in such a way that it doesn’t fabricate fake images or facts;
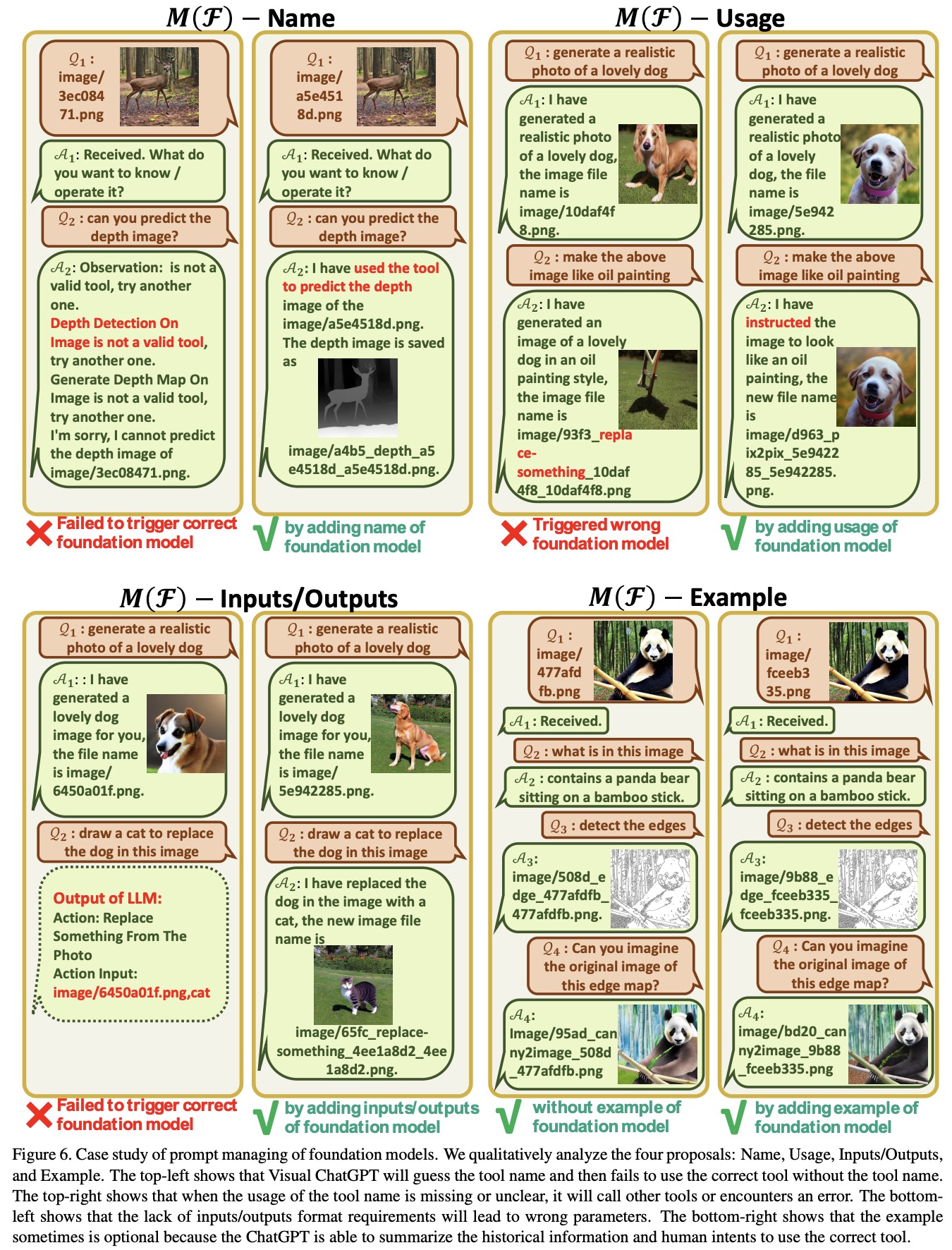
Prompt Managing of Foundation Models
Visual ChatGPT uses multiple VFMs to handle different VL tasks. However, as some VFMs may have similarities, it is crucial to distinguish between them. The Prompt Manager provides several aspects to help Visual ChatGPT understand and handle VL tasks accurately. These include:
- Name: An abstract of the overall function for each VFM, which serves as an entry to VFM and helps Visual ChatGPT understand its purpose.
- Usage: Describes the specific scenarios where the VFM should be used, helping Visual ChatGPT make informed decisions on which VFM to use for a particular task.
- Inputs/Outputs: Outlines the required input and output formats for each VFM since the format can vary significantly, providing clear guidelines for Visual ChatGPT to execute the VFMs correctly.
- Example (optional): Helps Visual ChatGPT better understand how to use a particular VFM under a specific input template and handle more complex queries.
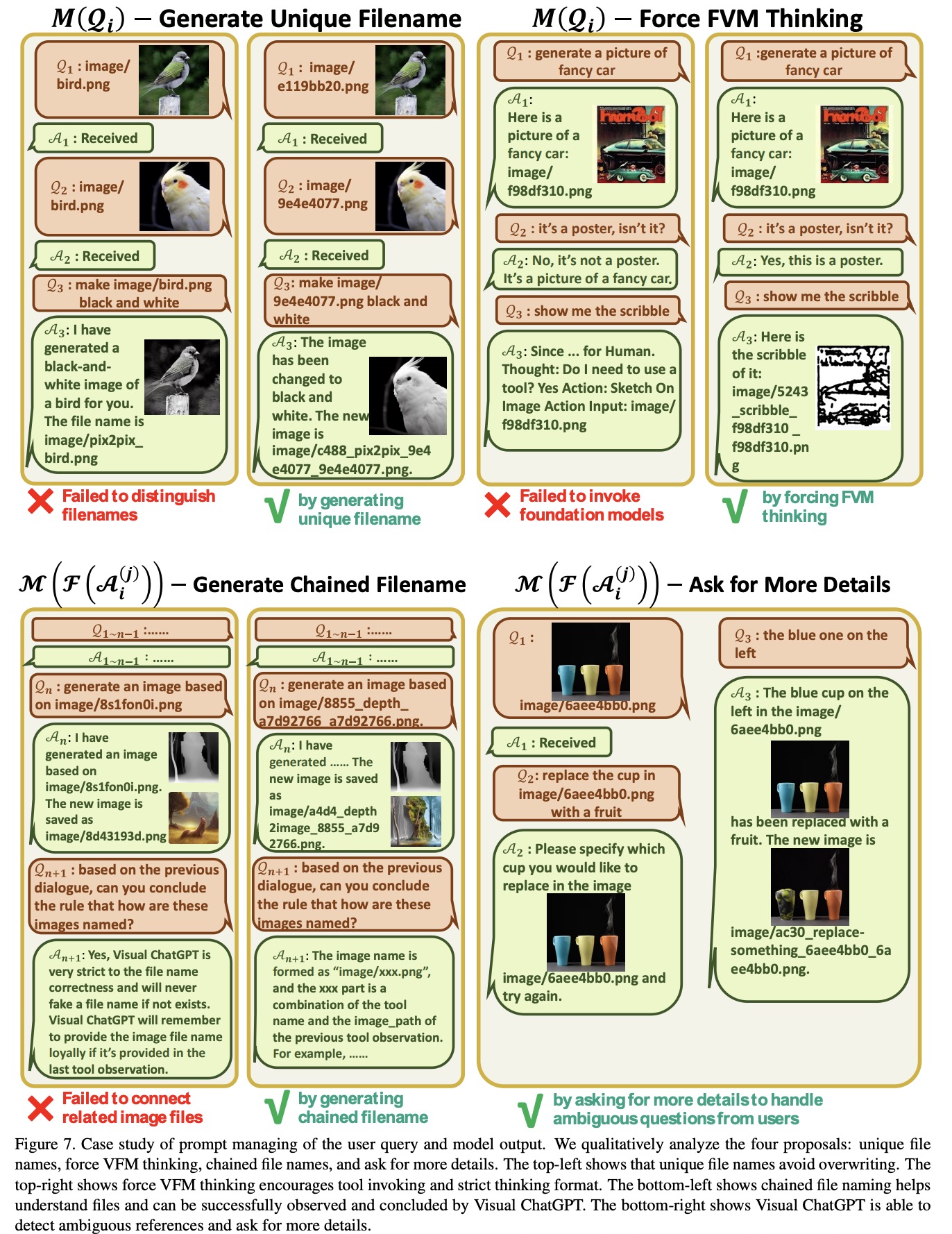
Prompt Managing of User Querie
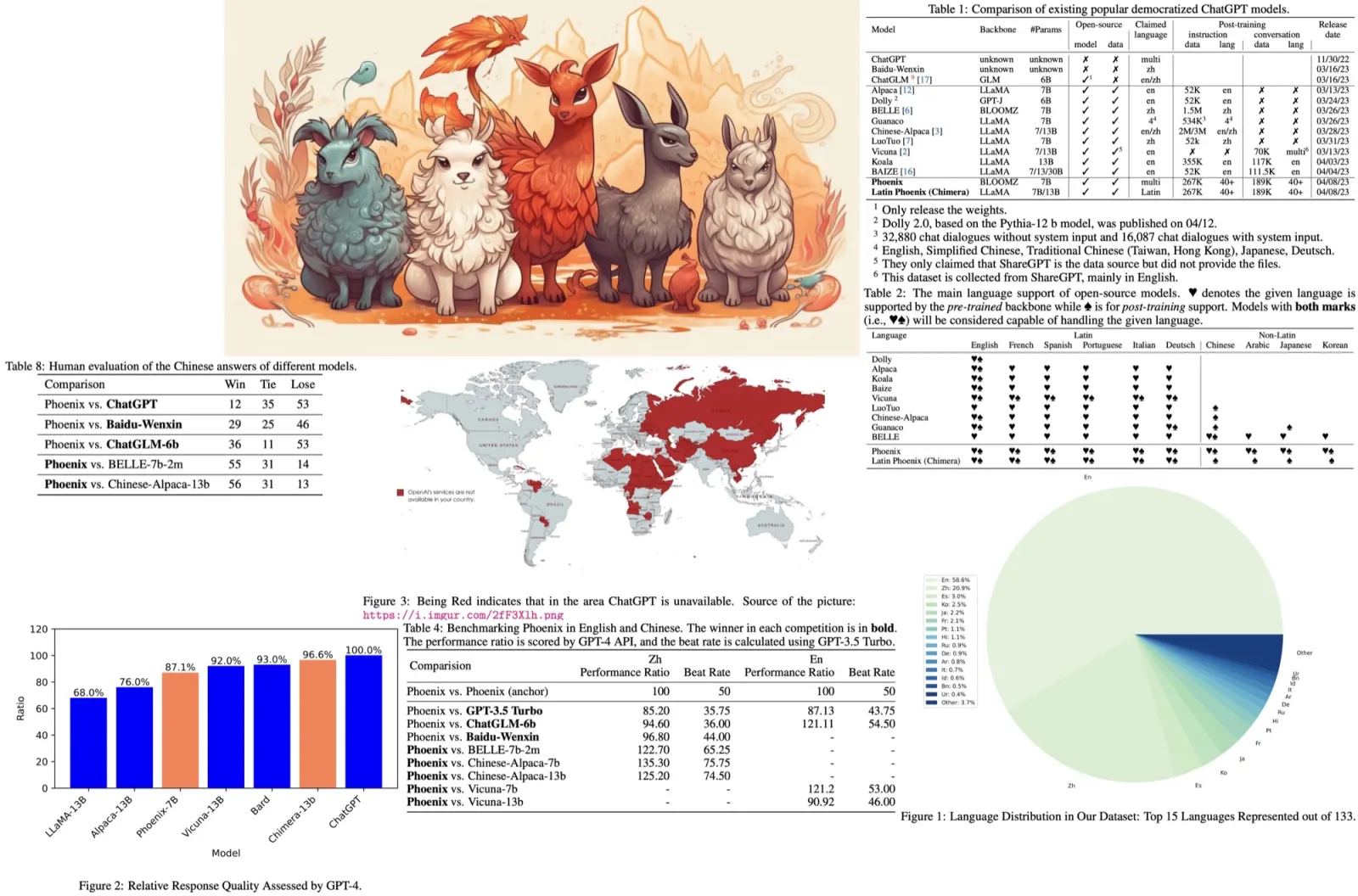
- Visual ChatGPT can handle two types of image-related queries: those that involve newly uploaded images and those that reference existing images. For newly uploaded images, Visual ChatGPT generates a unique filename with a universally unique identifier (UUID) and adds a prefix string
image/{uuid}.png. A fake dialogue history is also generated to assist in the following dialogues. For queries that involve reference to existing images, Visual ChatGPT ignores the filename check since it has the ability to understand fuzzy matching of user queries. - To ensure the successful trigger of VFMs for Visual ChatGPT, a suffix prompt is appended to the input prompt. The suffix prompt reminds Visual ChatGPT to use foundation models instead of relying solely on its imagination and encourages it to provide specific outputs generated by the foundation models.
The suffix prompt:
Since Visual ChatGPT is a text language model, Visual ChatGPT must use tools to observe images rather than imagination. The thoughts and observations are only visible for Visual ChatGPT, Visual ChatGPT should remember to repeat important information in the final response for Human. Thought: Do I need to use a tool?
Prompt Managing of Foundation Model Outputs
For intermediate outputs from different VFMs, Visual ChatGPT implicitly summarizes and feeds them to ChatGPT for subsequent interactions, calling other VFMs for further operations until reaching the ending condition or giving feedback to users. The inner steps involve:
- Generating a chained filename for intermediate outputs to help ChatGPT better understand the reasoning process. This naming rule hints ChatGPT of the intermediate result attributes and how they were generated from a series of operations. The image is named as “{Name}{Operation}{Prev Name}_{Org Name}”, where {Name} is the UUID name mentioned above, with {Operation} as the operation name, {Prev Name} as the input image unique identifier, and {Org Name} as the original name of the image uploaded by users or generated by VFMs. For instance,
image/ui3c_edge-of_o0ec_nji9dcgf.pngis a canny edge image namedui3cof inputo0ec, and the original name of this image isnji9dcgf. - Automatically calling for more VFMs to finish the user’s command by asking ChatGPT whether it needs VFMs to solve the current problem.
- Asking users for more details when the user’s command is ambiguous to help better leverage VFMs. This design is critical since LLMs are not permitted to arbitrarily tamper with or speculate about the user’s intention without a basis, especially when input information is insufficient.
Experiments
The authors use ChatGPT [29] and guide the LLM with LangChain. They collect foundation models from HuggingFace Transformers, Maskformer and ControlNet. The full deployment of all the 22 VFMs requires 4 Nvidia V100 GPUs. The maximum length of chat history is 2,000 and excessive tokens are truncated to meet the input length of ChatGPT.


Limitations
Although Visual ChatGPT is a promising approach for multi-modal dialogue, it has several limitations, including:
- Dependence on ChatGPT and VFMs, which can heavily influence performance.
- Heavy prompt engineering requirements, which can be time-consuming and require expertise in computer vision and natural language processing.
- Limited real-time capabilities when handling specific tasks that require invoking multiple VFMs.
- Token length limitation in ChatGPT, which may restrict the number of VFMs that can be used.
- Security and privacy concerns regarding the easy plug and unplug of foundation models, which can potentially compromise sensitive data. Careful consideration and automatic checks are necessary to ensure data security and privacy.
In addition to the previously mentioned limitations, Visual ChatGPT may also produce unsatisfactory generation results due to VFM failure or prompt instability. To address this, a self-correction module is necessary to check the consistency between execution results and human intentions and make corresponding edits. However, this self-correction behavior can lead to more complex thinking of the model, significantly increasing the inference time.
paperreview deeplearning nlp transformer visual llm