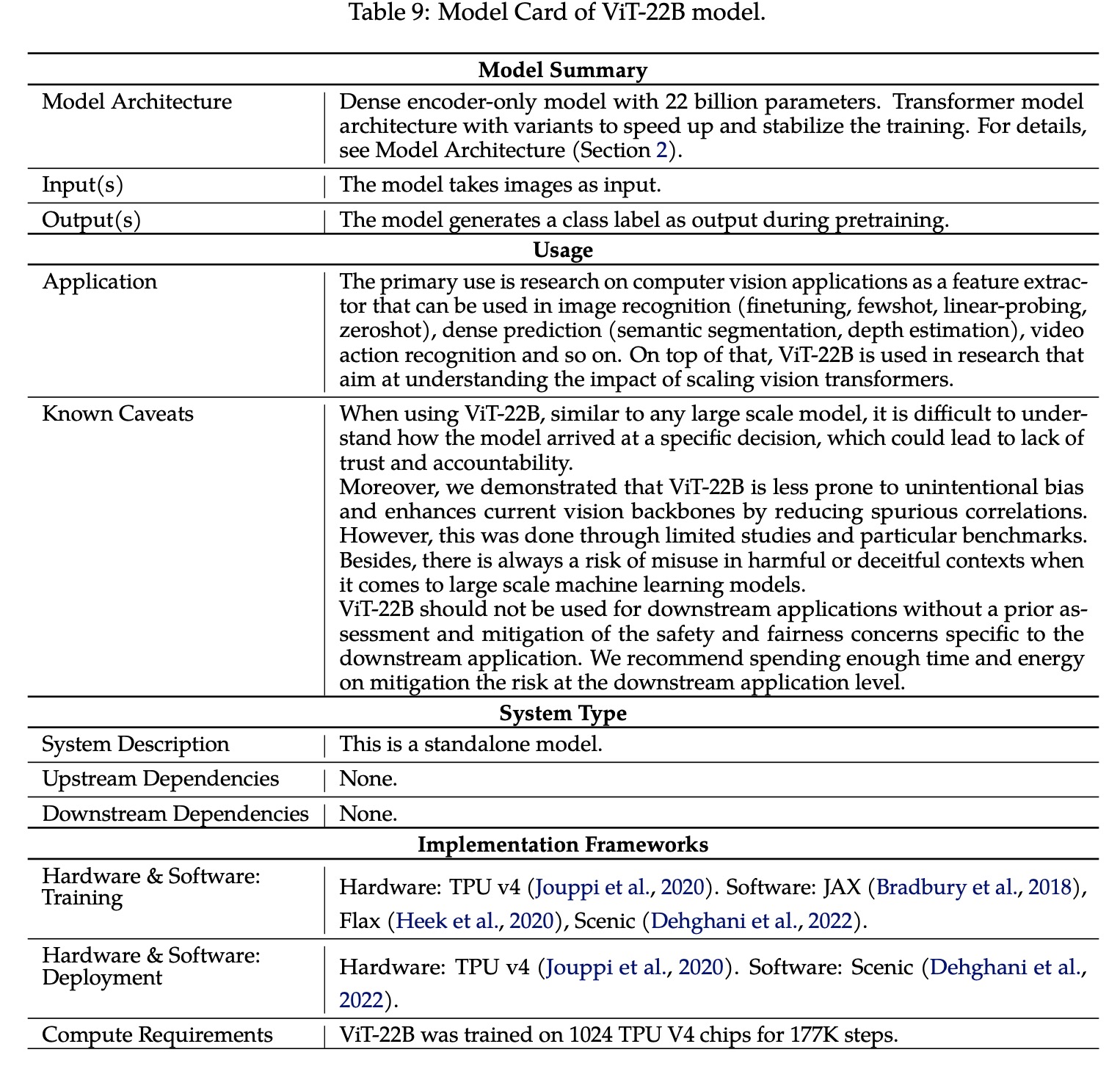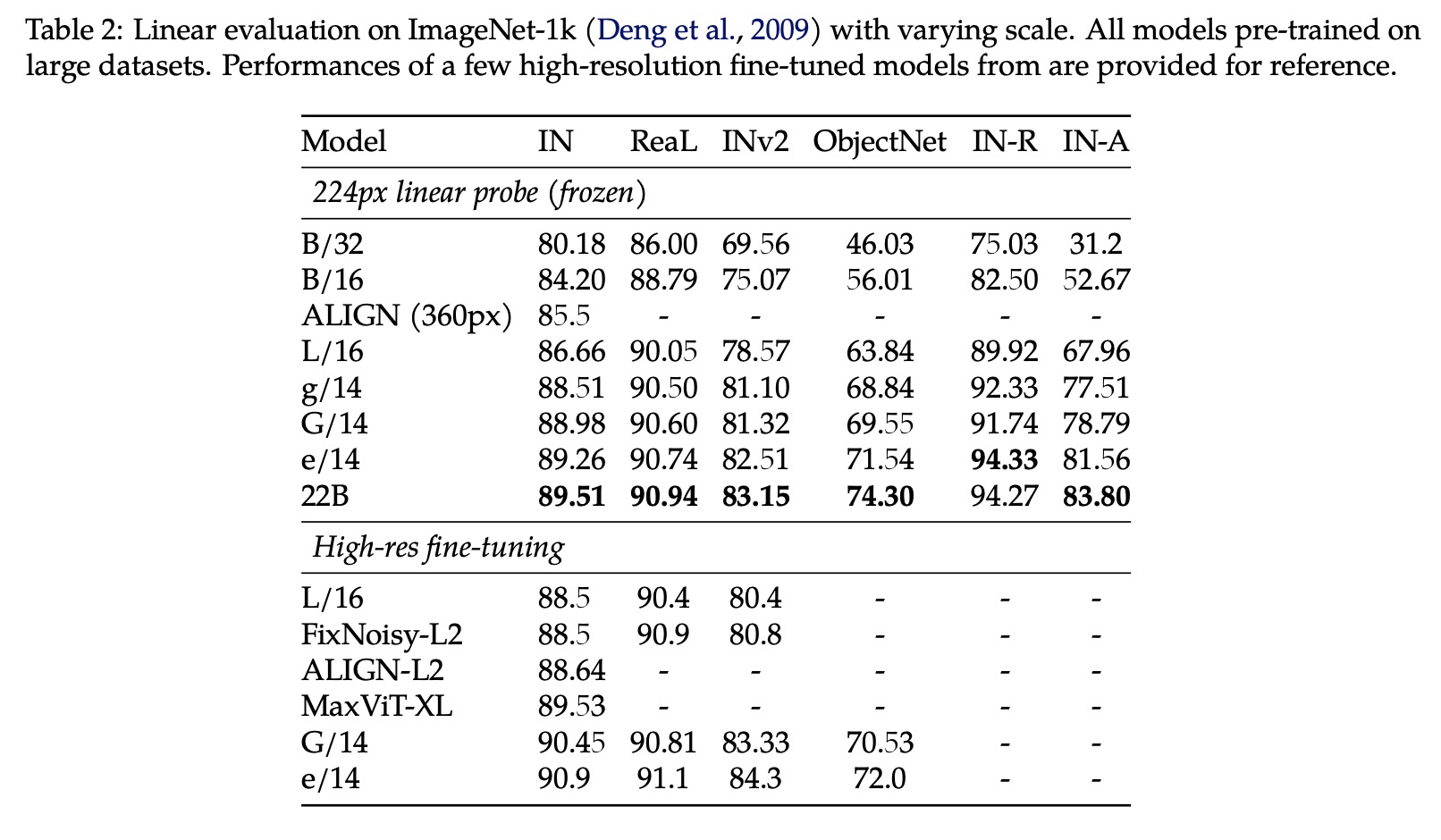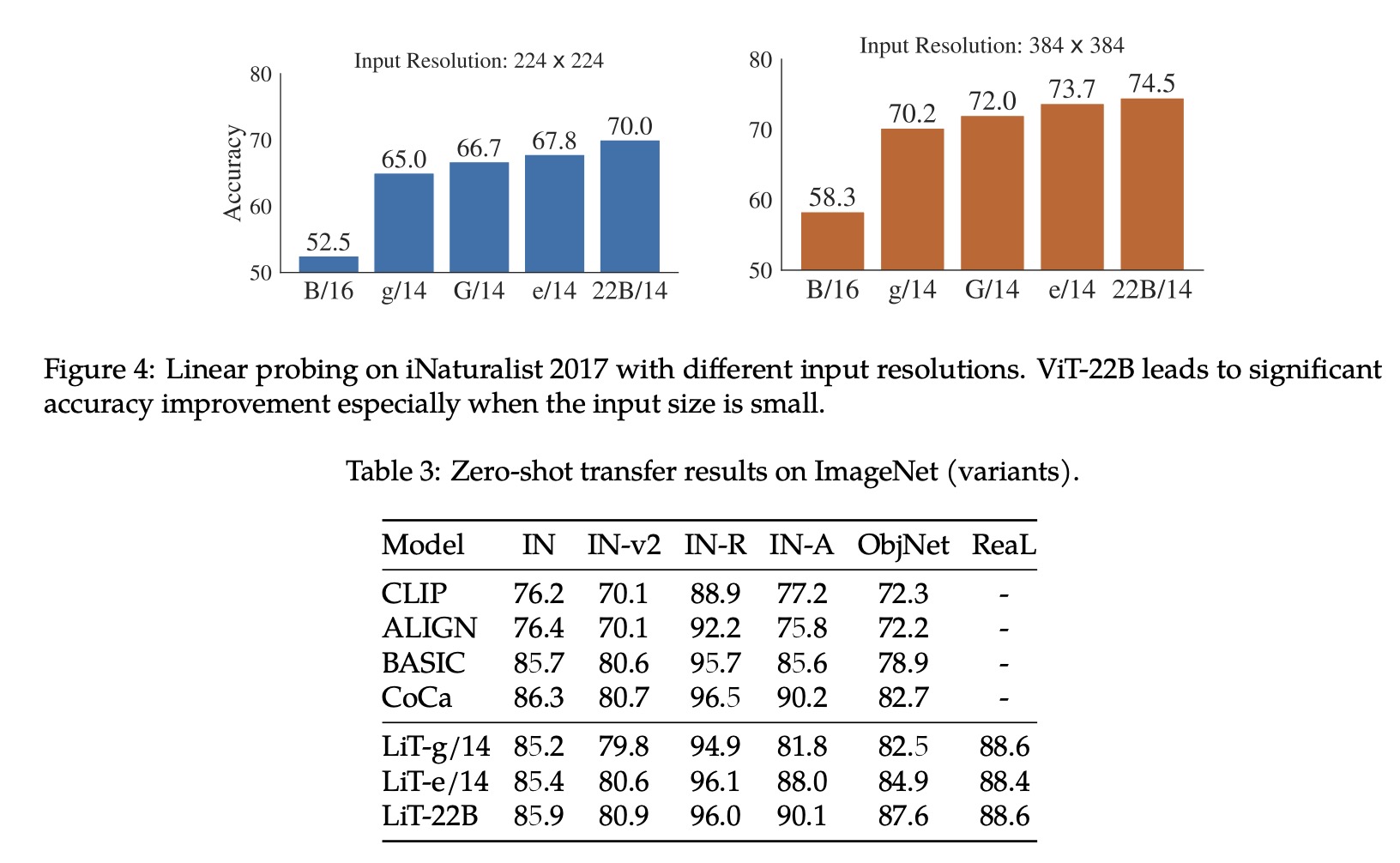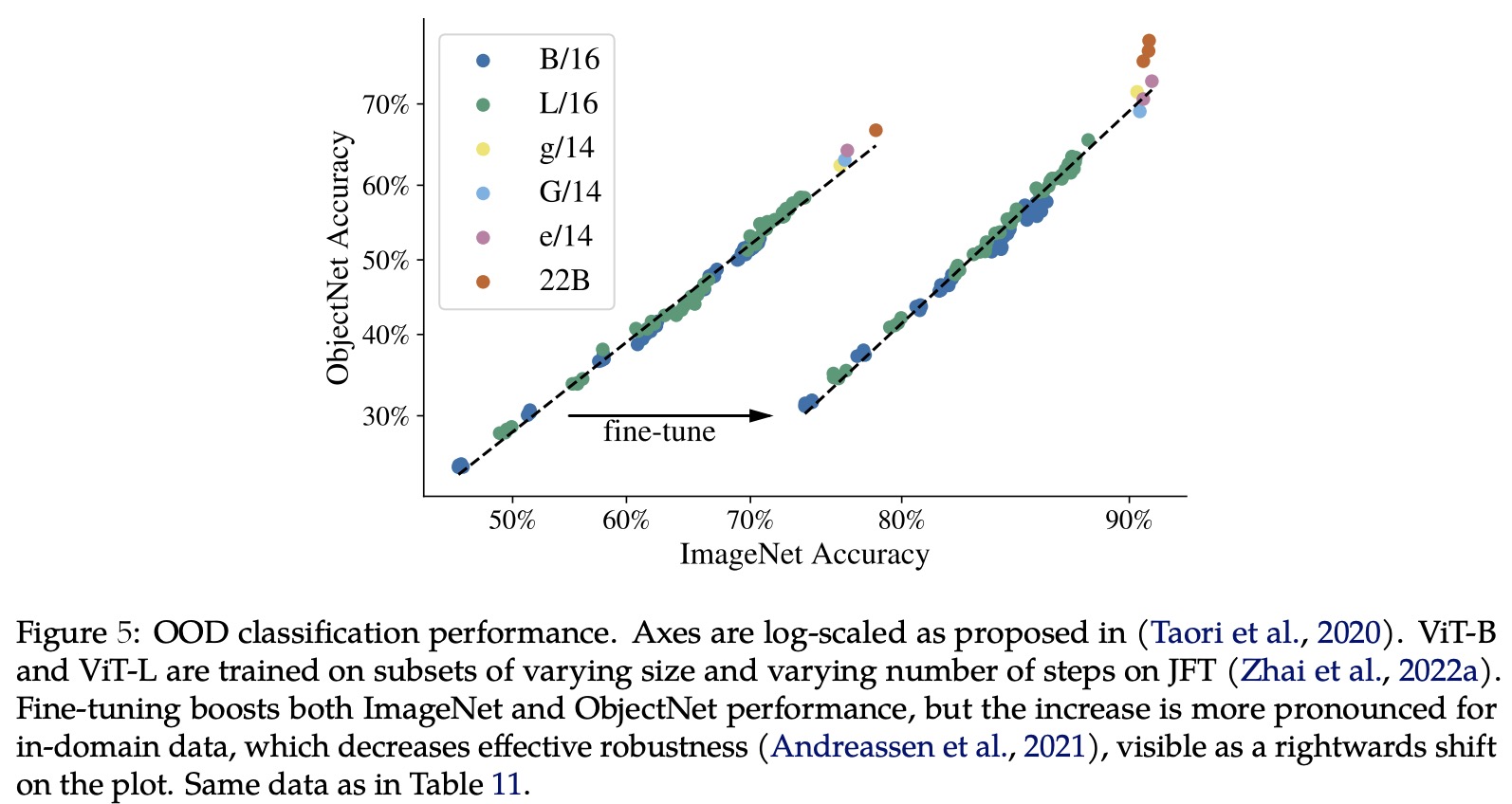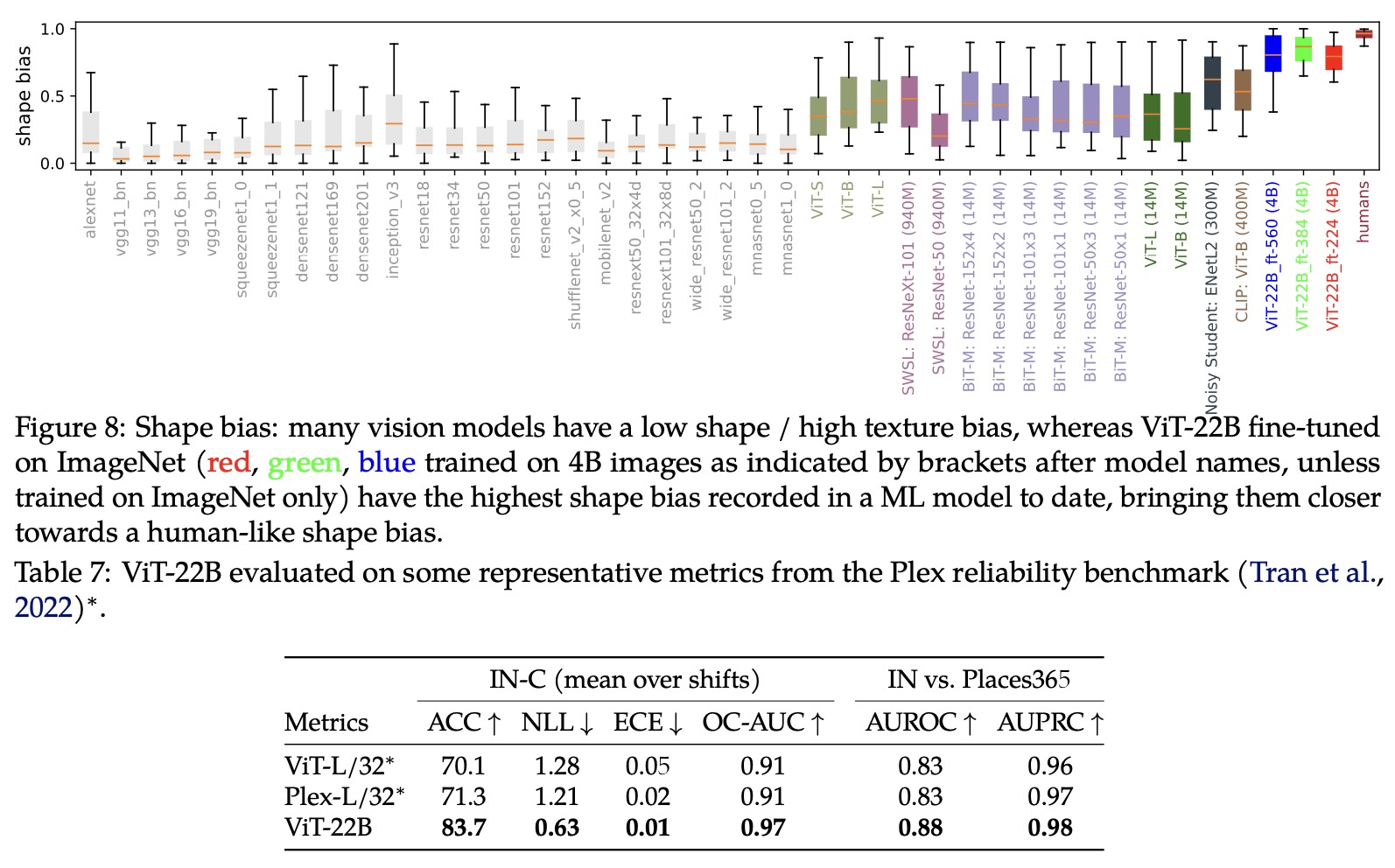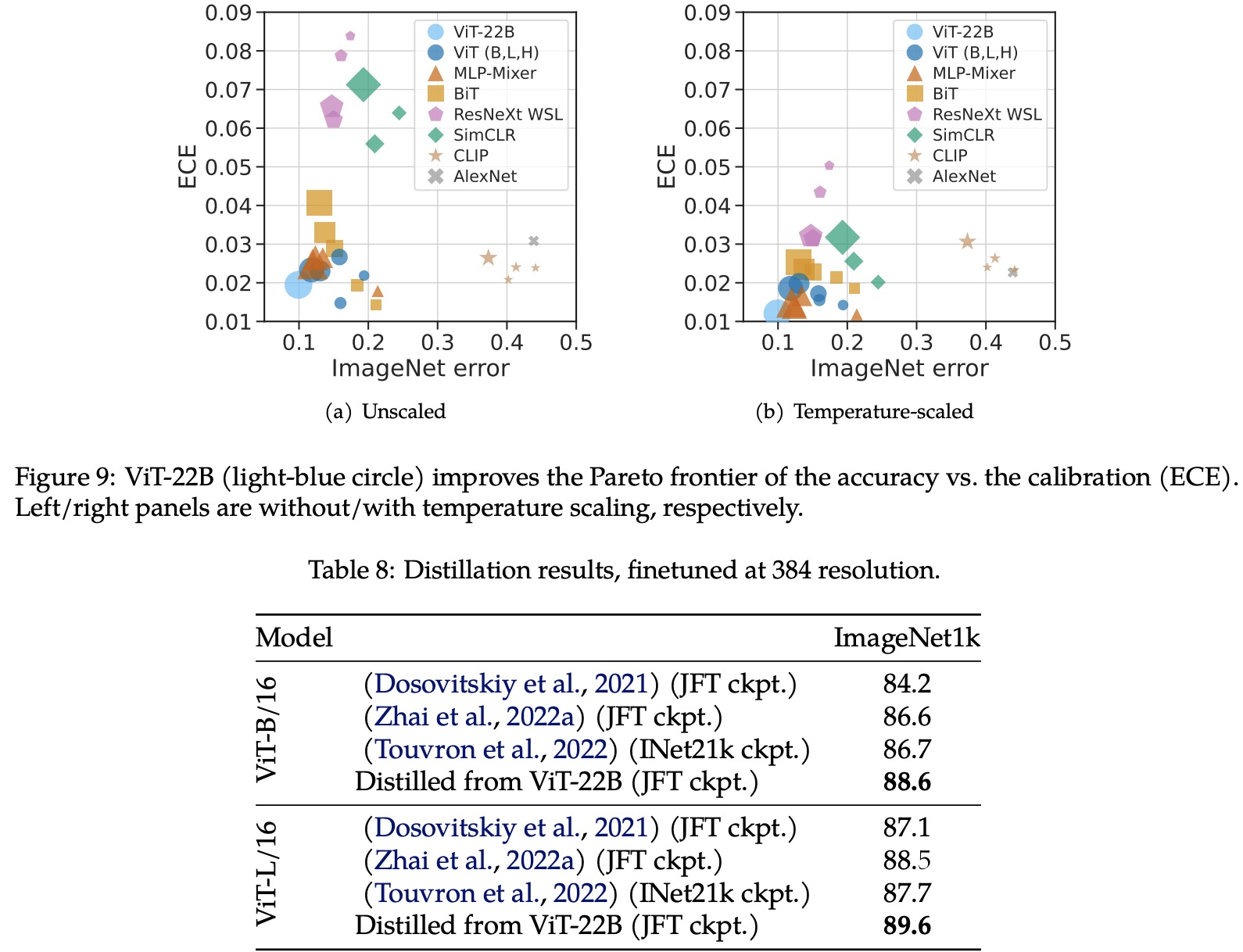
Paper Review: Scaling Vision Transformers to 22 Billion Parameters
The authors from Google Research present a recipe for training a highly efficient and stable 22B-parameter Vision Transformer (ViT-22B), which is currently the largest dense ViT model. They perform various experiments on ViT-22B and find that as the model’s scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and provides important steps toward achieving this goal.
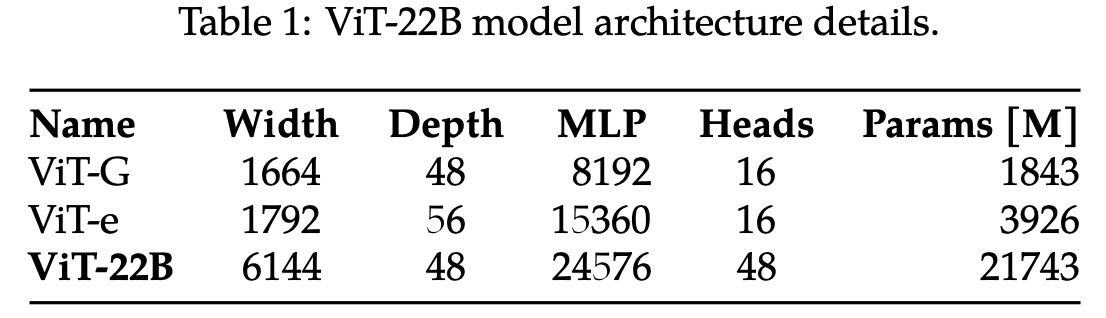
Model Architecture
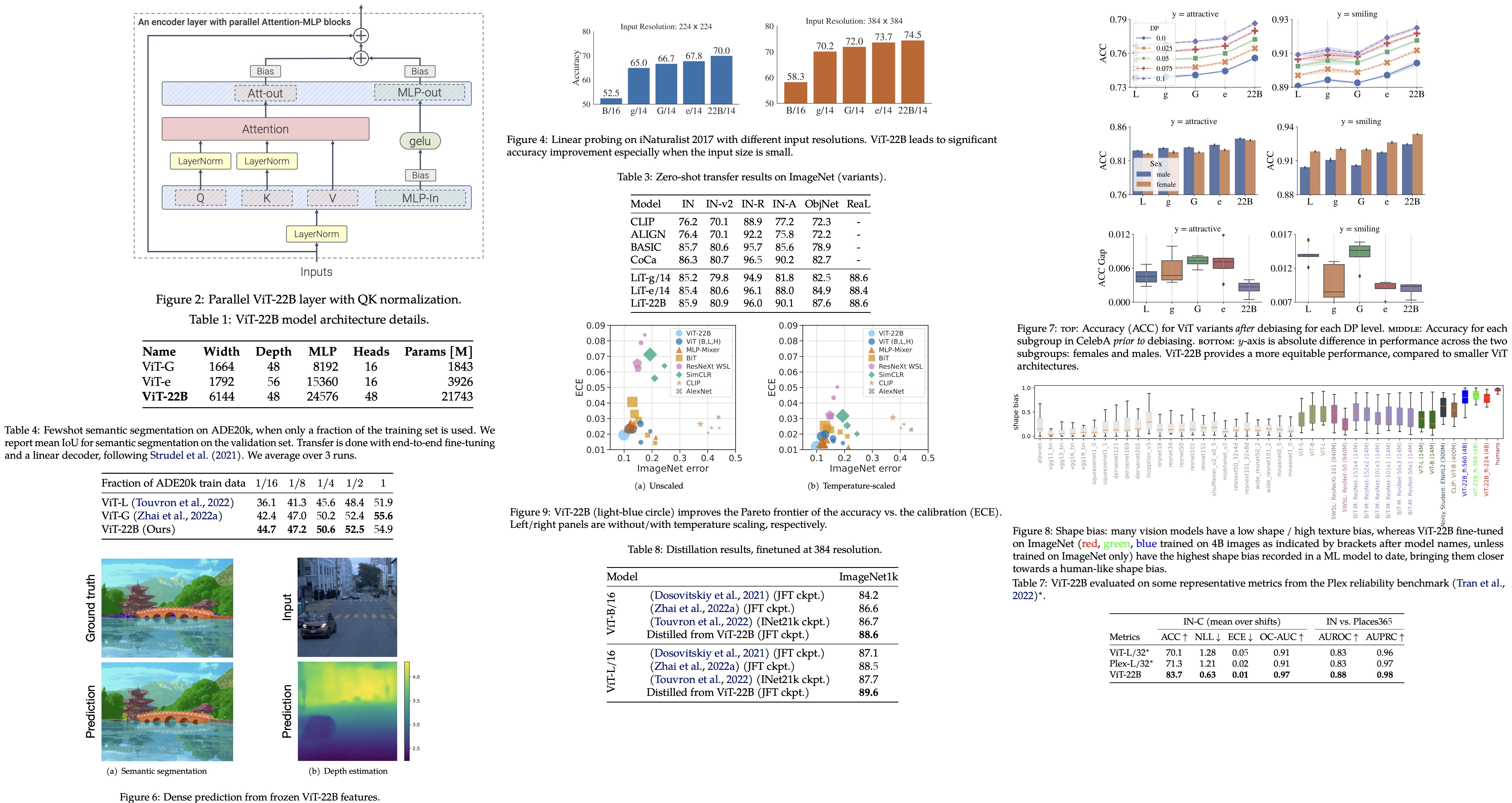
Parallel layers
The authors describe a modification to the standard Transformer architecture used in ViT-22B, which involves applying the Attention and MLP (multi-layer perceptron) blocks in parallel rather than sequentially. This enables further parallelization through linear projections from the MLP and attention blocks. Specifically, the matrix multiplication for query/key/value-projections and the first linear layer of the MLP are combined, as well as the attention out-projection and the second linear layer of the MLP. This technique was also used in the PaLM model and resulted in a 15% speed-up during training without performance degradation.
QK Normalization
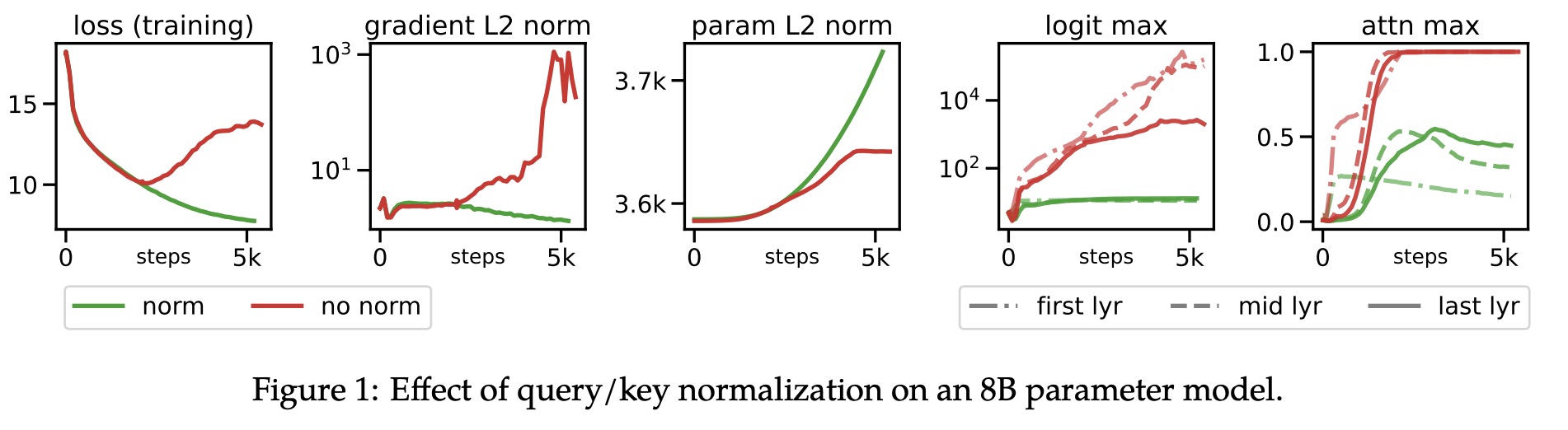
The authors observed divergent training loss in ViT models with around 8B parameters, caused by extremely large values in attention logits, which lead to near-zero entropy attention weights. To solve this, they applied LayerNorm to the queries and keys before the dot-product attention computation. This involves computing attention weights using a formula that includes layer normalization of the input, query weight matrix, and key weight matrix.
Omitting biases on QKV projections and LayerNorms
The authors removed bias terms from the QKV projections and applied all LayerNorms without bias, centering on improving accelerator utilization without quality degradation.
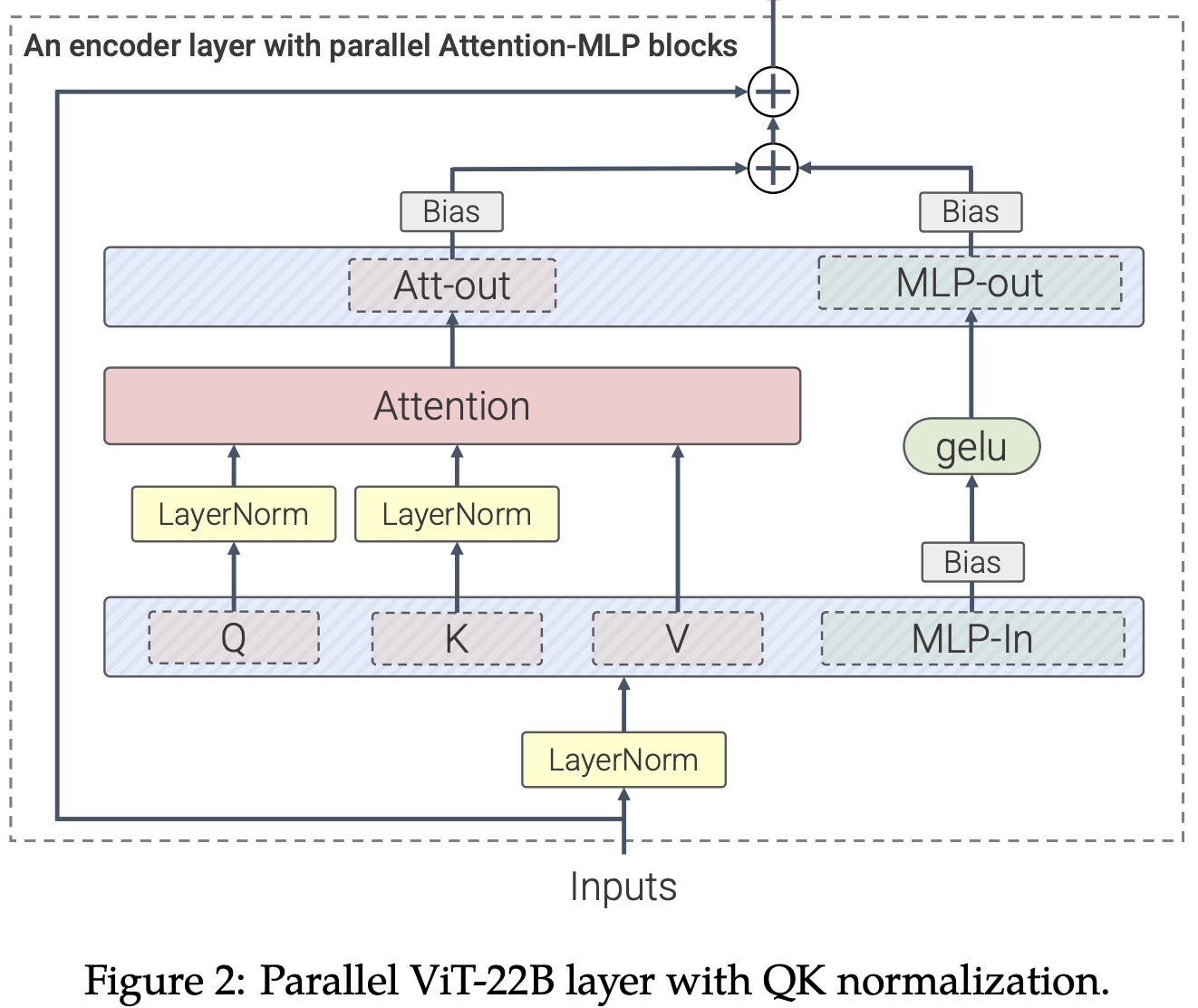
They used multi-head attention pooling to aggregate per-token representations in the head, and their embedding layer followed the original ViT with patch size 14x14 and images at resolution 224x224. They used a learned 1D positional embedding and performed 2D interpolation of the pre-trained position embeddings during fine-tuning on high-resolution images. Unlike PaLM, they used bias terms for the MLP dense layers as they observed improved quality without speed reduction.
Training Infrastructure and Efficiency

The authors implemented ViT-22B in JAX using the FLAX library and organized the chips into a 2D logical mesh of size t x k to leverage both model and data parallelism. They used the jax.xmap API to shard all intermediates, and built a wrapper around the dense layers in FLAX that adapts them to the setting where their inputs are split across k devices. They used asynchronous parallel linear operations and parameter sharding to maximize throughput, minimize communication, and overlap computation and communication. Using these techniques, ViT-22B achieved 1.15k tokens per second per core during training on TPUv4, and had a model flops utilization (MFU) of 54.9%, indicating efficient use of hardware. These results were better than PaLM and ViT-e on the same hardware.
Experiments
ViT-22B is trained on a version of the JFT dataset, which has been extended to around 4B images and semi-automatically annotated with a class-hierarchy of 30k labels. The model is trained using 256 visual tokens per image, with a peak learning rate of 10^-3 and a reciprocal square-root learning rate schedule. The model is trained for 177k steps with a batch size of 65k, approximately 3 epochs, and employs a sigmoid cross-entropy loss for multi-label classification. A linear warmup and cooldown are used, and a higher weight decay of 3.0 is used for the head and 0.03 for the body for better few-shot adaptation during upstream training.