Paper Review: Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
This paper from Meta AI introduces Voicebox, a highly versatile, text-guided generative model for speech at scale. This non-autoregressive model has been trained on over 50,000 hours of unfiltered and unenhanced speech. Voicebox is capable of performing various tasks through in-context learning and can also adapt to future contexts. It can be used for tasks like mono or cross-lingual zero-shot text-to-speech synthesis, noise removal, content editing, style conversion, and diverse sample generation. Compared to the state-of-the-art zero-shot text-to-speech (TTS) model, VALL-E, Voicebox delivers superior performance in terms of intelligibility and audio similarity, and is up to 20 times faster.
Method
Background: Flow Matching with an optimal transport path
Continuous Normalizing Flows (CNFs) are generative models that transform a simple prior distribution (e.g., normal distribution) to match the data distribution by using a parameterized time-dependent vector field. This transformation process is mathematically represented as a flow governed by an ordinary differential equation (ODE).
The probability path, a time-dependent probability density function, is then derived using a change of variables formula. To sample from the probability path, an initial value problem is solved with the help of an ODE solver. The training of the vector field, parameterized by a neural network, is done using a Flow Matching objective, which minimizes the difference between the model’s vector field and the true vector field of the data. However, since the exact distribution of the data is not known, the authors adopt the Conditional Flow Matching (CFM) objective - it constructs a probability path using a mixture of simpler conditional paths, which are easier to compute.
The authors incorporate optimal transport theory by proposing a simple and intuitive Gaussian path. This optimal transport path leads to better training efficiency, faster generation, and improved model performance compared to other methods, such as diffusion paths.
Problem formulation
The authors aim to build a single model that can perform many text-guided speech generation tasks through in-context learning. They suggest training the model on a text-guided speech infilling task. This task predicts a segment of speech based on the surrounding audio and complete text transcript. They use a binary temporal mask, the same length as the audio sample, to divide the sample into two complementary masked versions. The model learns to predict the missing data, given the context of the complete text transcript and the remaining portion of the audio sample.
Model and Training
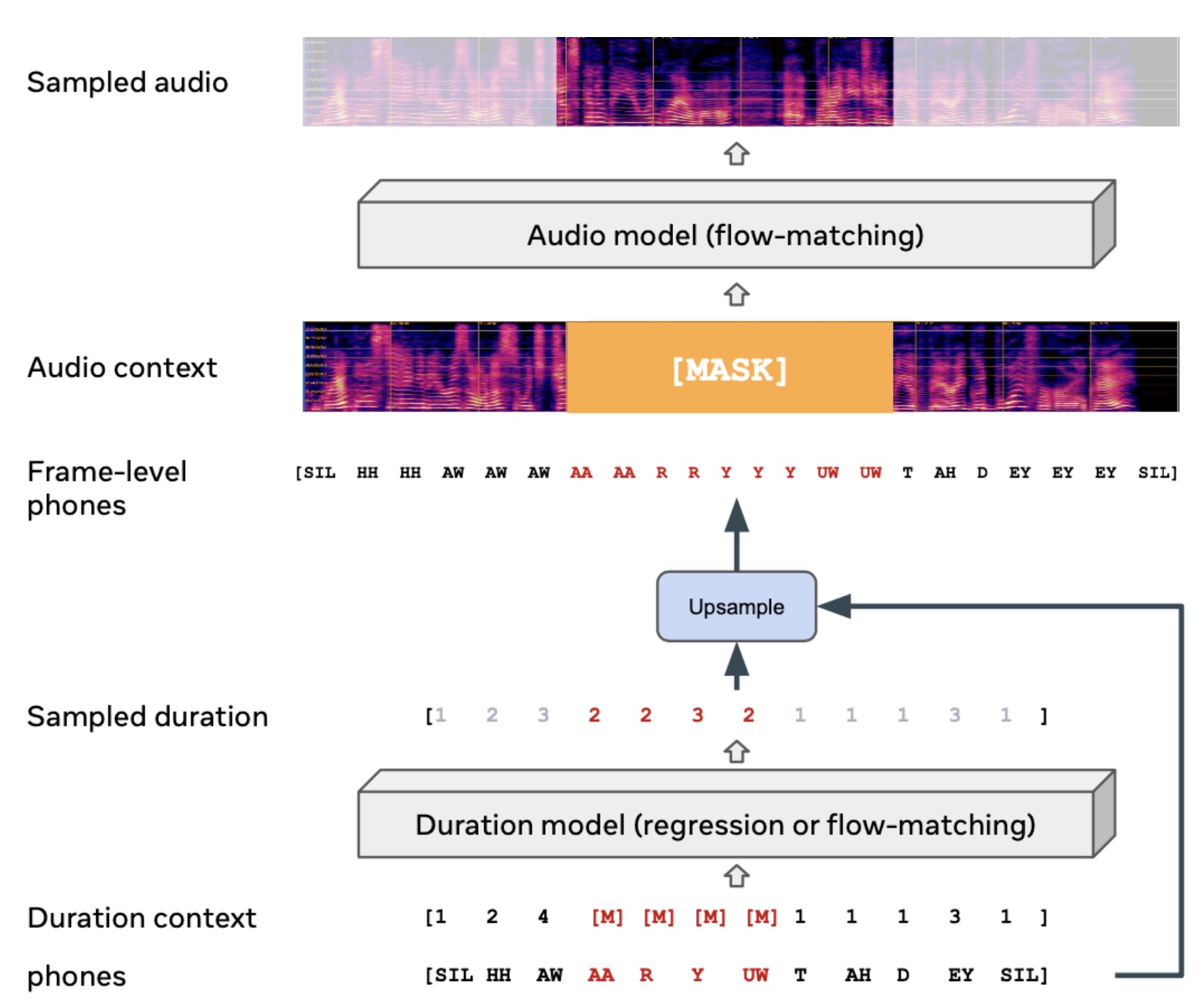
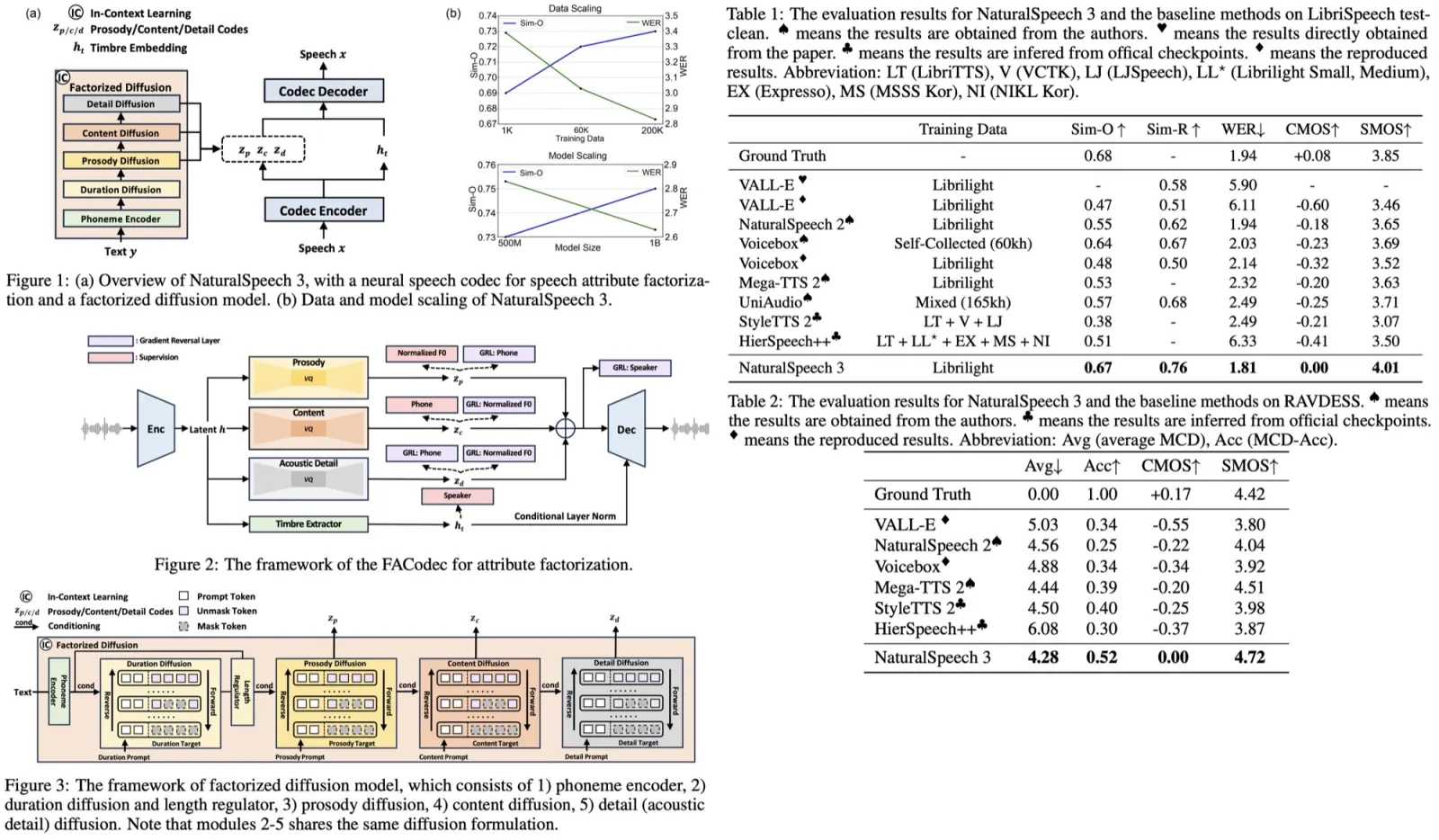
Voicebox is divided into two components: an audio model and a duration model.
The audio model is responsible for the generation of speech from the given context. This context includes a frame-level phone transcript and a complementary masked version of the audio sample. Due to the highly stochastic nature of the missing audio data the audio model is parameterized with a Continuous Normalizing Flow (CNF) and trained using the optimal transport path. This model predicts the distribution of all audio frames instead of only the masked frames, improving conditioning. The audio is represented as an 80-dimensional log Mel spectrogram extracted at a 100Hz frame rate.
The duration model regresses the masked duration given the context duration and the phonetic transcript. It is trained with an L1 regression loss on masked phones, with the regression-based duration model similar to the duration model used in FastSpeech2.
Both the audio and duration model components use a transformer model to parameterize the vector field, allowing for embedding of the flow step, frame-level phone transcript, and audio context. They both incorporate the same masked loss function to divert the model’s focus to masked frames.
Inference
To sample from the learned audio distribution in Voicebox, an initial noise is drawn from the prior distribution. Then they use an Ordinary Differential Equation (ODE) solver to evaluate the flow. A larger number of function evaluations (NFEs) typically result in a more accurate solution but take longer to compute. However, some solvers can adaptively adjust the number of evaluations, providing flexibility to users to balance between speed and accuracy. Empirically, Voicebox can generate high-quality speech with fewer than 10 NFEs, making it faster than auto-regressive models.
Classifier-Free Guidance
Classifier Guidance (CG) is a technique used post-training to balance between mode coverage and sample fidelity for diffusion models. It works by modifying the score estimate of a diffusion model to include the gradient of the log likelihood of an auxiliary classifier. In this context, the concept of Classifier-Free Guidance (CFG) is extended to flow-matching models. During training, the conditioner is dropped with a certain probability. During inference, the modified vector field of the audio model is computed using both the conditional and unconditional models. The balance between these models is controlled by a guidance strength parameter.
Applications
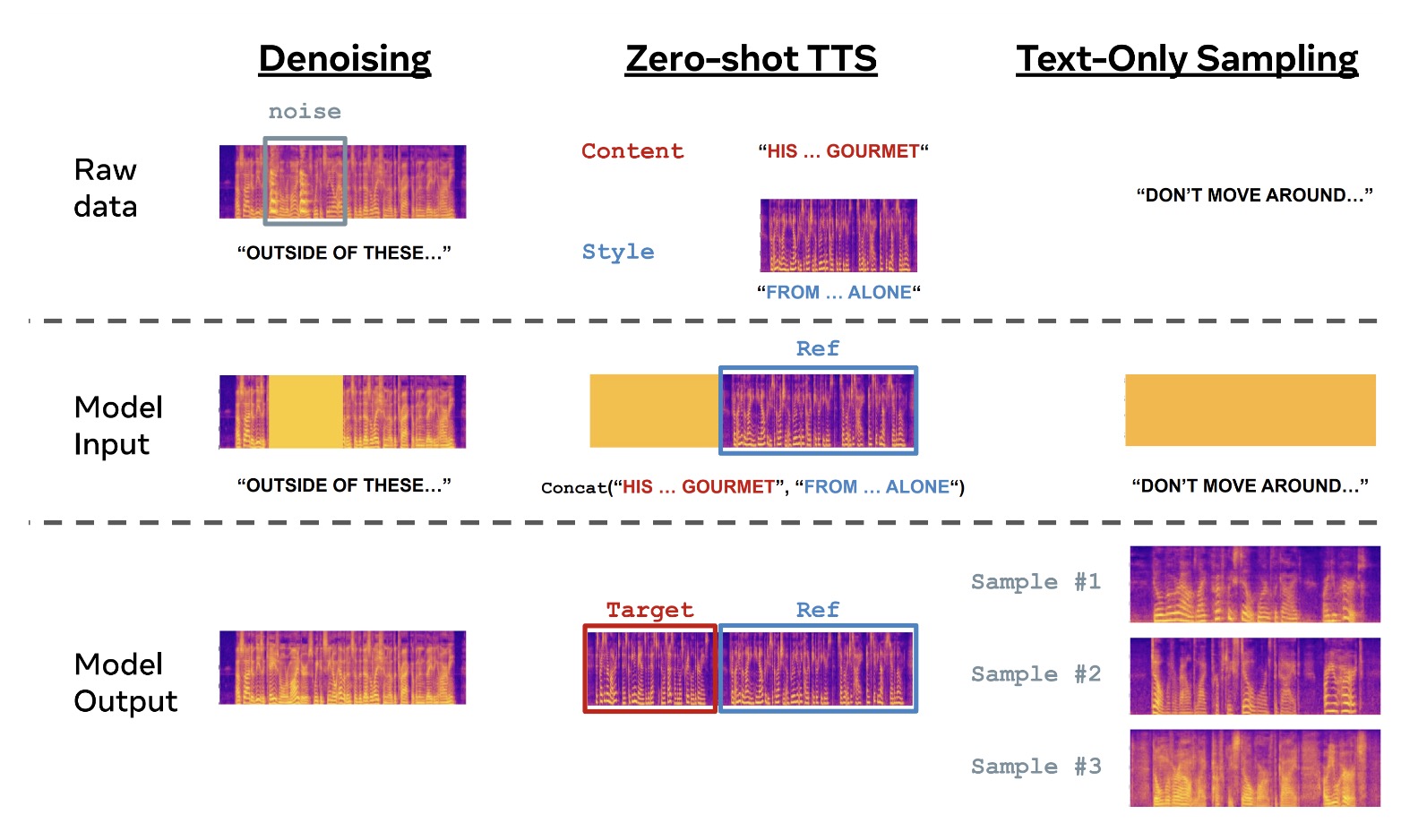
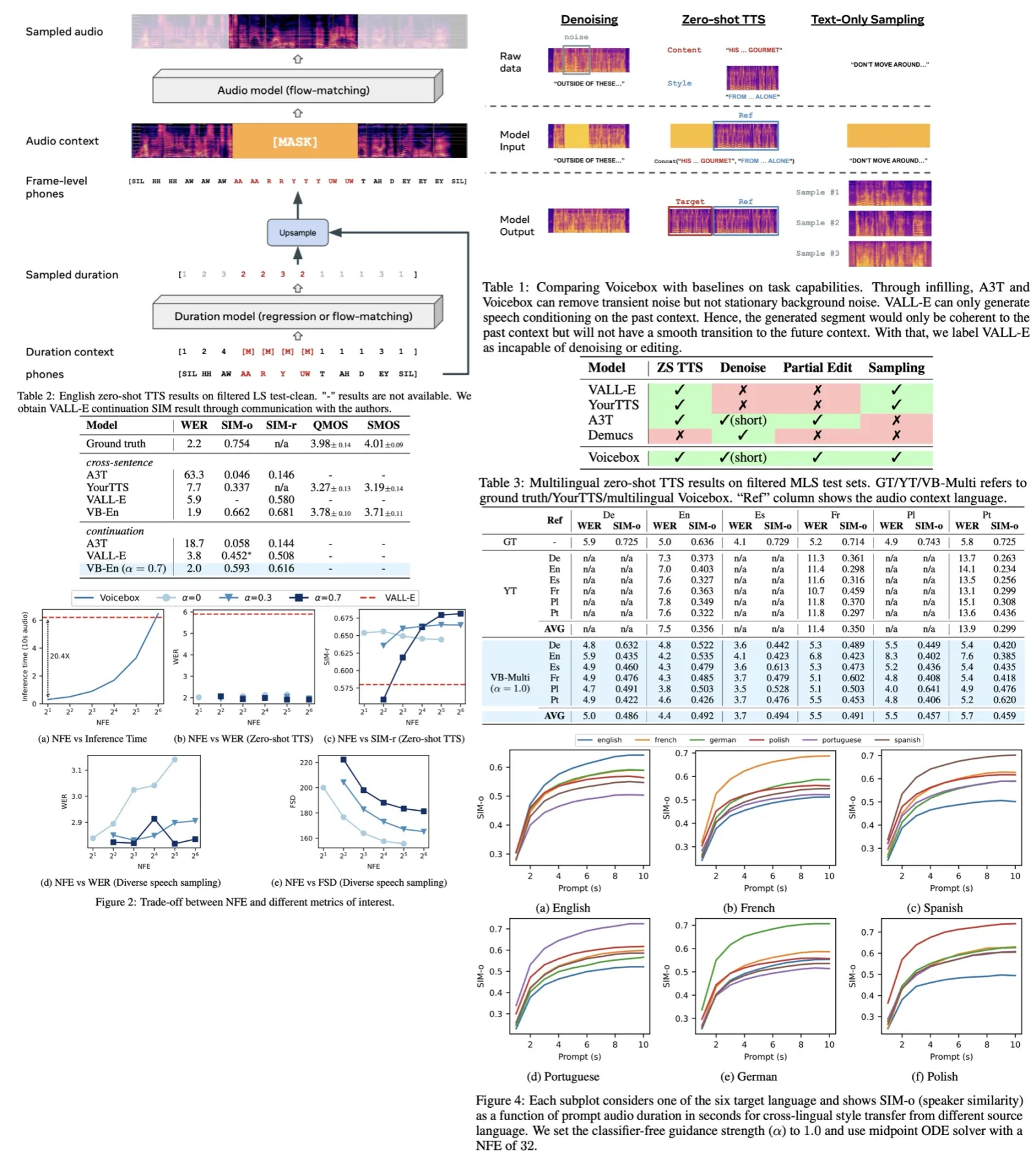
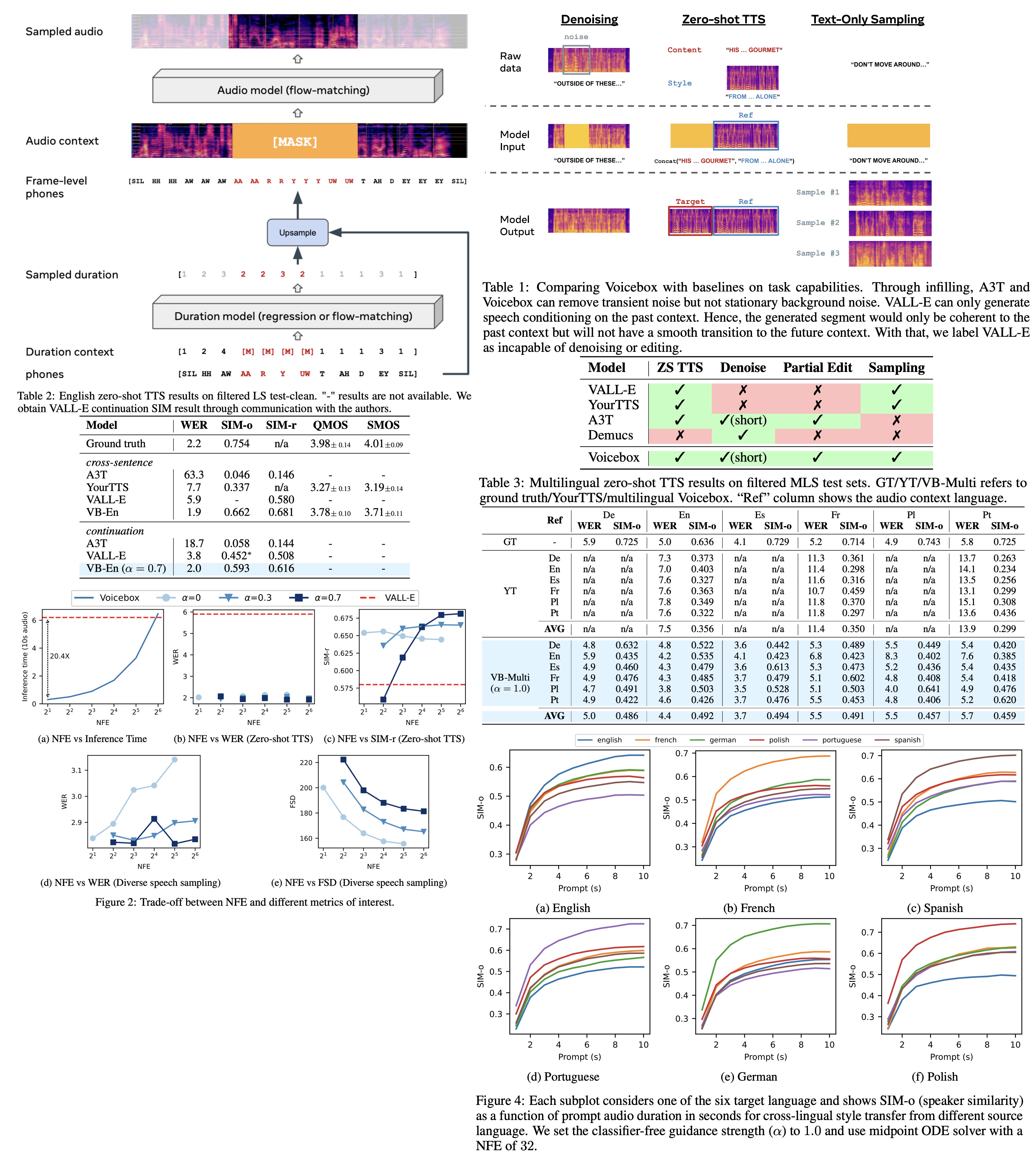
Voicebox demonstrates in-context learning abilities and can perform tasks that it was not explicitly trained on.
- Zero-shot TTS & alignment-preserved style transfer: It can synthesize speech that mirrors an unseen audio style. This is done by treating the reference audio and the target speech as one utterance, where the target speech is masked. It can also convert the audio style of a speech while preserving its alignment, which is useful for editing audio synchronized with other modalities, such as video.
- Transient noise removal & content editing: Voicebox can remove transient noise by regenerating the corrupted segment using the original frame-level transcript and the surrounding clean audio. It can also perform content editing where a new transcript replaces some words from the original transcript, generating a new audio.
- Diverse speech sampling & alignment-preserved style shuffling: Voicebox can generate diverse speech samples by infilling an entire utterance using the duration and audio model. It can also shuffle the audio style while maintaining alignment by sampling from the frame-level transcript of the target speech clip.
Metrics
The goal of Voicebox in audio-conditioned tasks is to produce realistic speech coherent with the context and has correct textual content. For tasks not conditioned on audio context, it aims to generate diverse, realistic samples with the correct content, similar to training data. The paper suggests using reproducible model-based perceptual metrics over subjective ones, such as mean opinion scores (MOS), which can be biased and aren’t always comparable across studies:
- Correctness and Intelligibility: This is measured by the word error rate (WER) of the synthesized speech’s transcription in comparison to the input text. A lower WER indicates the speech is more intelligible, but doesn’t necessarily imply better quality. Public automatic speech recognition (ASR) models are used for comparability.
- Coherence: It’s measured by the similarity between the embedding of generated speech and the audio context. Different embedding models would reflect coherence of different attributes. The paper advocates for computing similarity against the original audio context.
- Diversity and Quality: The paper adapts the Fréchet Inception Score (FID), a metric often used for image generation evaluations, to speech. It is now referred to as Fréchet Speech Distance (FSD), and reflects sample quality and diversity.
As supplementary metrics, the authors include quality MOS (QMOS) for subjective audio quality evaluation, and similarity MOS (SMOS) for subjective audio similarity evaluation. For duration models, the authors suggest using these metrics to evaluate end-to-end performance and propose several standalone metrics specific to the duration model.
Experiments

Voicebox is trained on English-only and multilingual data. The English-only model uses 60K hours of ASR-transcribed English audiobooks. The multilingual model uses 50K hours of audiobooks in six languages: English, French, German, Spanish, Polish, and Portuguese. Low-resource languages are upsampled using a certain factor to mimic a multinomial distribution.
The models use the Montreal Forced Aligner for phonemization and force alignment of the transcript. The audio is represented as an 80-dimensional log Mel spectrogram, and a HiFi-GAN vocoder is used for waveform generation. A Transformer with convolutional positional embedding and ALiBi self-attention bias is used for both audio and duration models.
Training the VB-En/VB-Multi audio models is performed for 500K/750K updates with an effective batch size of 240K frames. Duration models are trained for 600K updates with an effective batch size of 60K frames.
During inference, the torchdiffeq package is used for fixed and adaptive step ODE solvers. The resulting NFE is 64/32 with/without classifier-free guidance, and the regression duration model is used by default. Silence at both ends is trimmed to 0.1 second max.
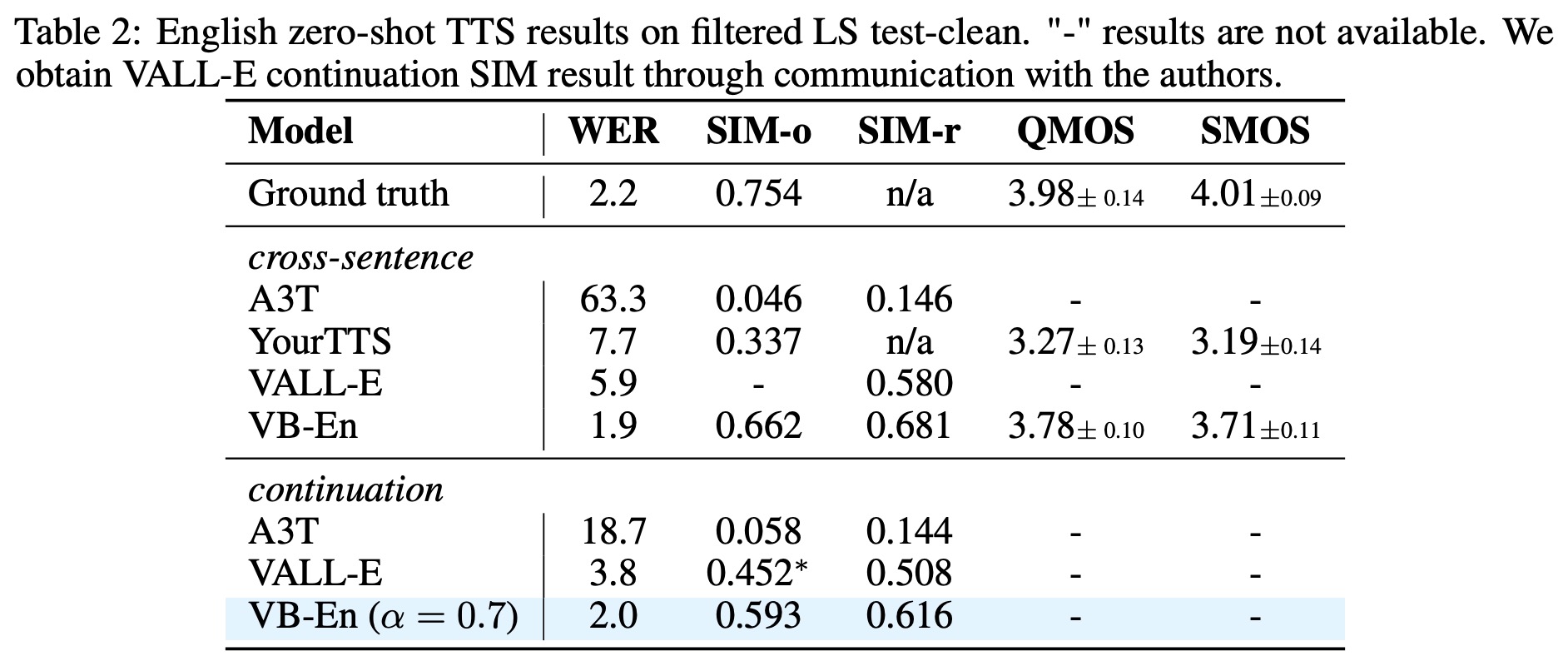
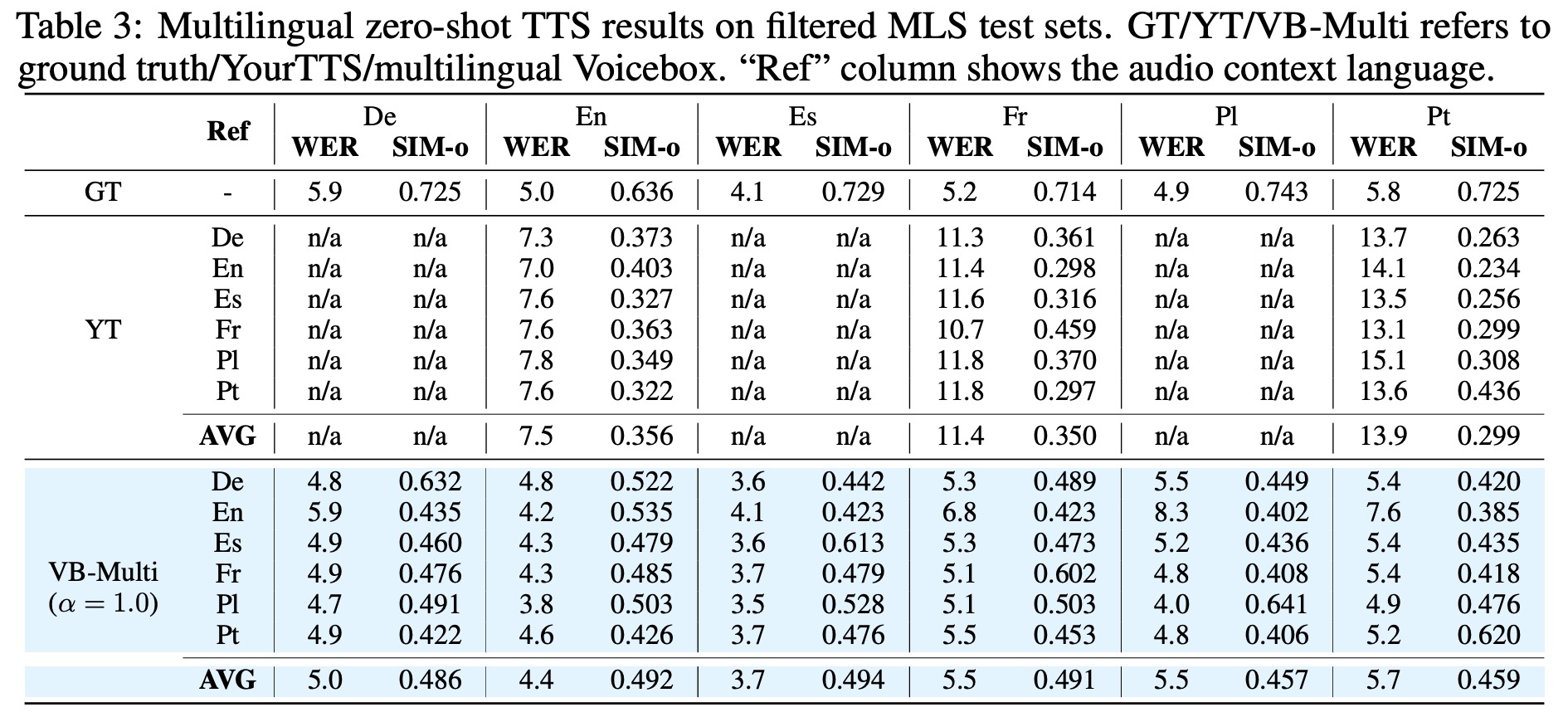
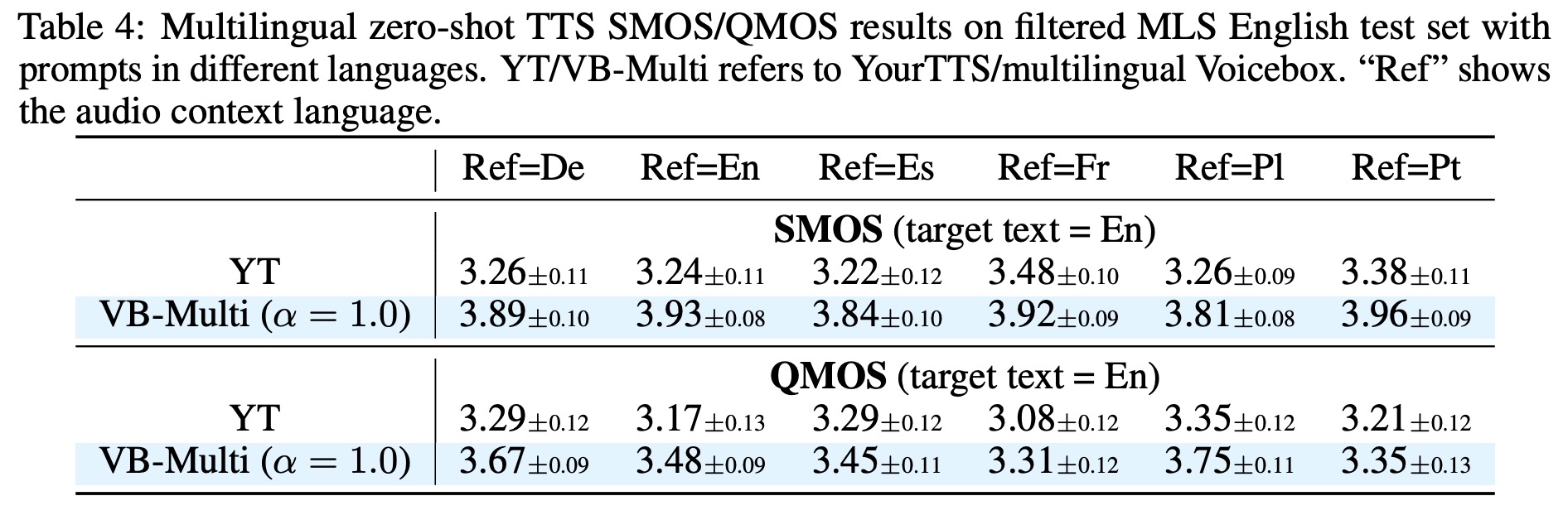
- In monolingual zero-shot TTS, the Voicebox model outperforms all other models in Mean Opinion Score (MOS) studies, offering effective style transfer and better quality than the YourTTS model.
- In cross-lingual zero-shot TTS, Voicebox also exceeds YourTTS’s performance in every area, including in languages such as English, French, and Portuguese. On average, Voicebox yielded higher MOS for audio similarity and quality.
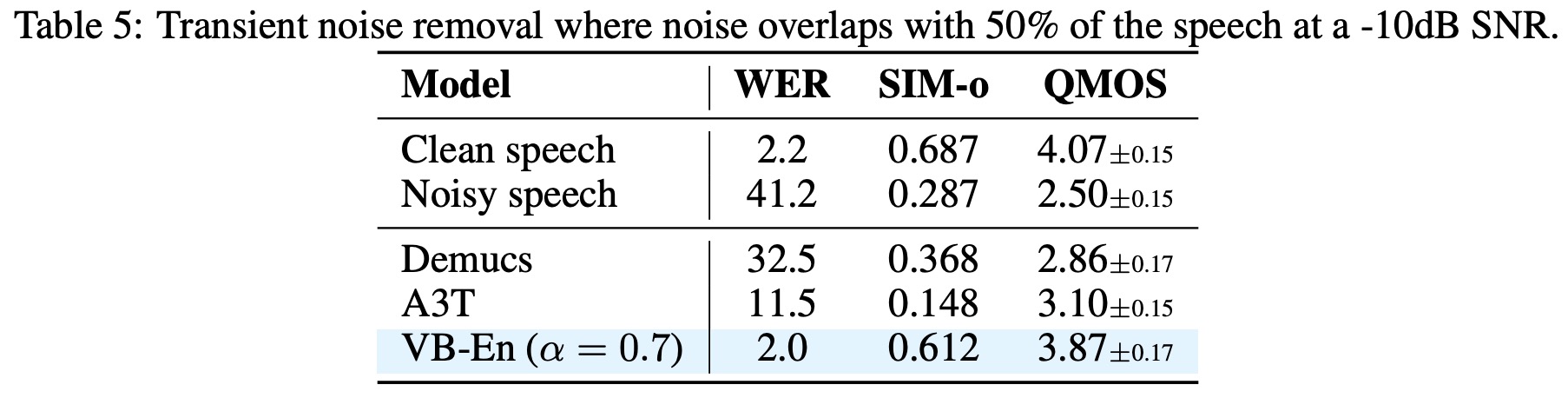
- Voicebox also performed well in transient noise removal tests, even in challenging noise conditions. It was shown to generate samples that were more intelligible, similar to clean parts of the audio, and of higher quality than the other models, A3T and Demucs.
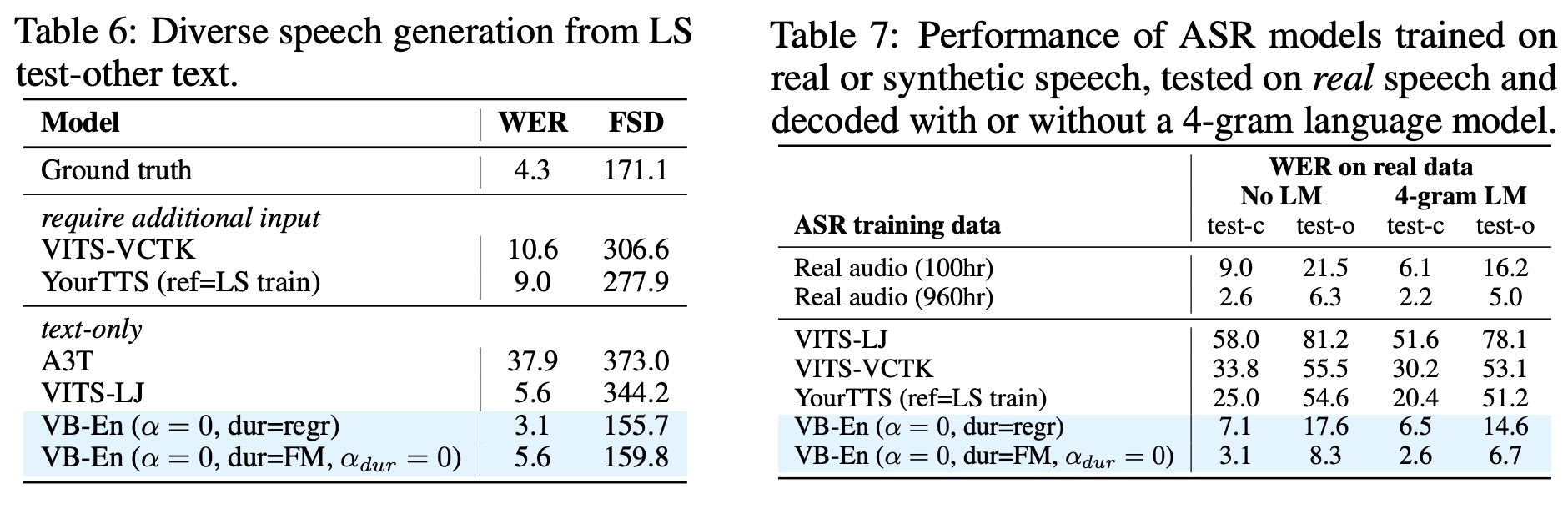
- The model’s ability to generate diverse samples was demonstrated in tests with Librispeech text. Voicebox outperformed baselines on the Frechet Speech Distance (FSD), indicating its ability to produce realistic and diverse samples. The flow-matching (FM) duration model particularly showed its ability to create varying speaking styles.
Inference efficiency versus performance
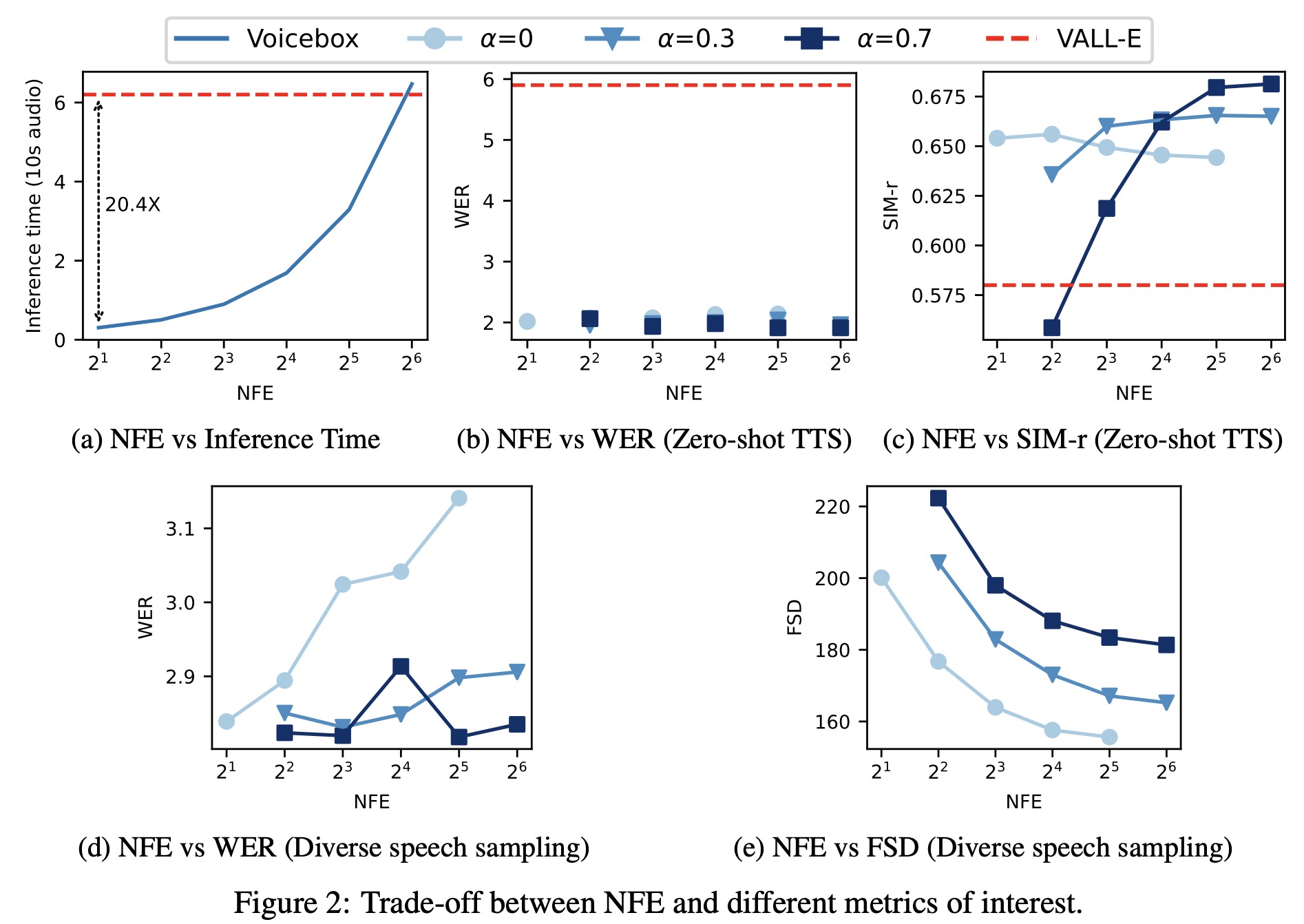
The authors discuss the trade-offs between different metrics of interest, including Word Error Rate (WER), Speaker Identity Metrics (SIM), and Fréchet Speech Distance (FSD), in the Voicebox model.
- Voicebox can generate a 10-second audio sample significantly faster than the VALL-E model, depending on the NFE setting. At NFE=2, Voicebox was found to be about 20 times faster than VALL-E.
- In the cross-sentence setup, Voicebox consistently outperformed VALL-E in terms of WER. The WER remained stable with a mean of 2.0.
- When analyzing SIM-r, lower classifier guidance strength values (α = 0 or 0.3) resulted in higher speaker similarity in a lower NFE regime. However, as NFE increased beyond 16, higher classifier guidance strength improved speaker similarity.
- Examining FSD by generating samples for Librispeech test-other text, it was found that lower classifier guidance strength resulted in more diverse samples with lower FSD scores.
- Increasing NFE improved the FSD score. WER was also examined and it was discovered that a lower NFE, especially with a lower guidance weight (α = 0 or 0.3), resulted in less diverse, lower-quality samples, which were easier for the ASR model to recognize due to the lack of extreme audio styles. As a result, WERs were lower.
How context length affects monolingual and cross-lingual zero-shot TTS
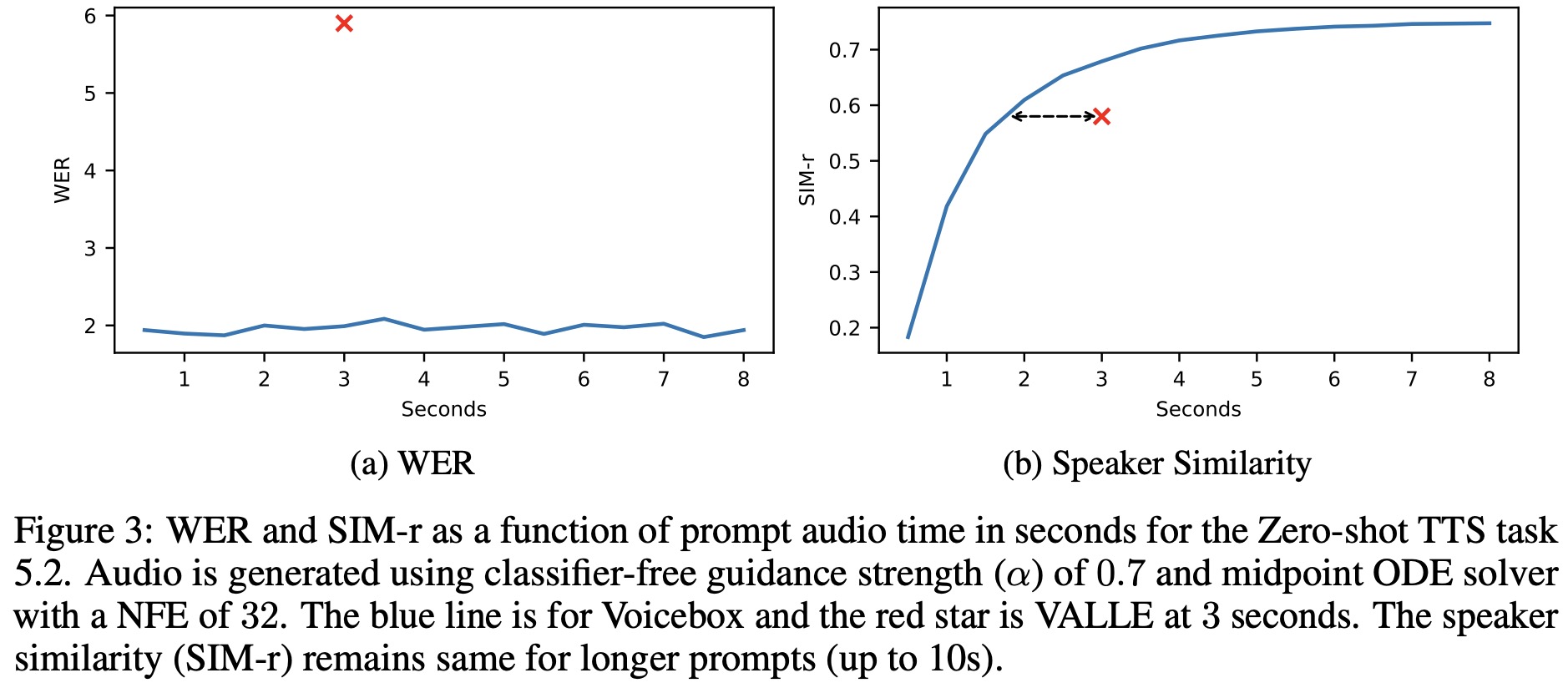
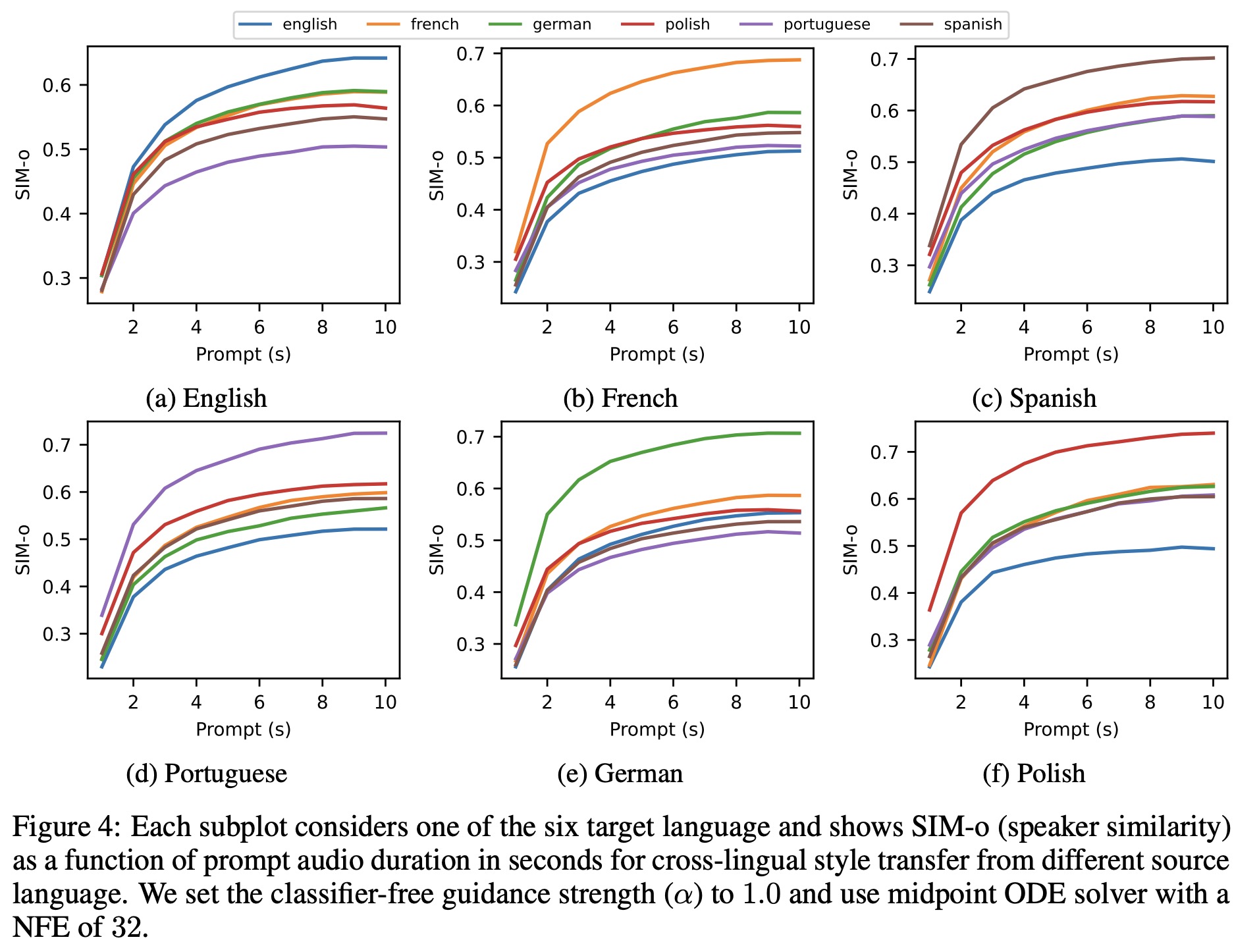
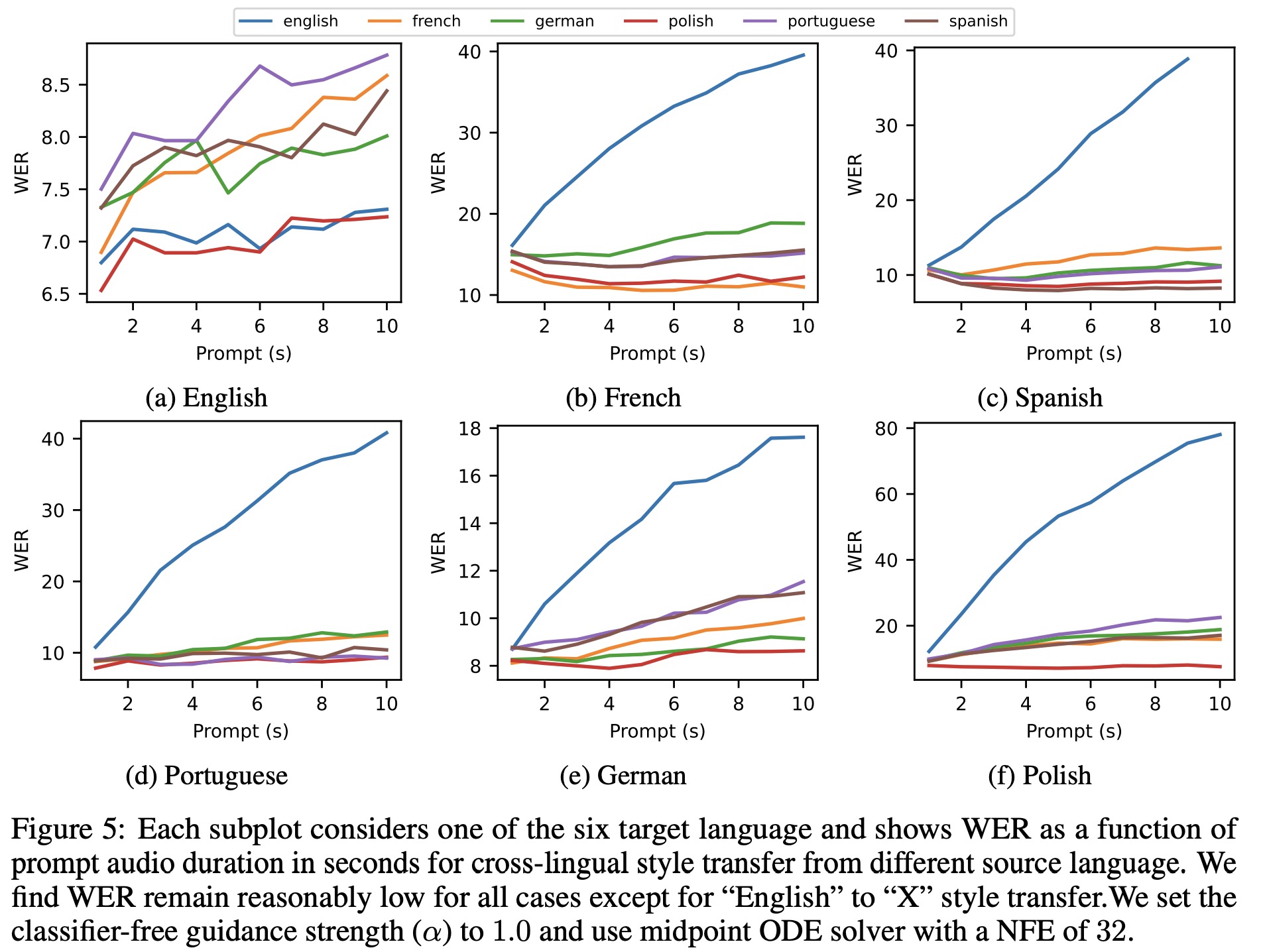
In the monolingual setting, as the length of prompt audio increases, Word Error Rate (WER) decreases mildly and Speaker Identity Metrics (SIM-r) grows quickly and then plateaus. Comparatively, Voicebox is more efficient than VALL-E at leveraging an audio prompt, achieving similar speaker similarity with about two thirds of the input audio.
For the cross-lingual setting, the speaker similarity consistently improves with a longer prompt, similar to the monolingual setting. However, WER increases as the prompt length is extended, especially for translations from English to non-English languages. This increase in WER could be attributed to the training data imbalance across languages, as English represents over 90% of the multilingual training data. Therefore, when transferring from English, the model might assume that the whole sentence is in English as the prompt length increases, leading to incorrect pronunciation for the non-English target.
Ethical Statement
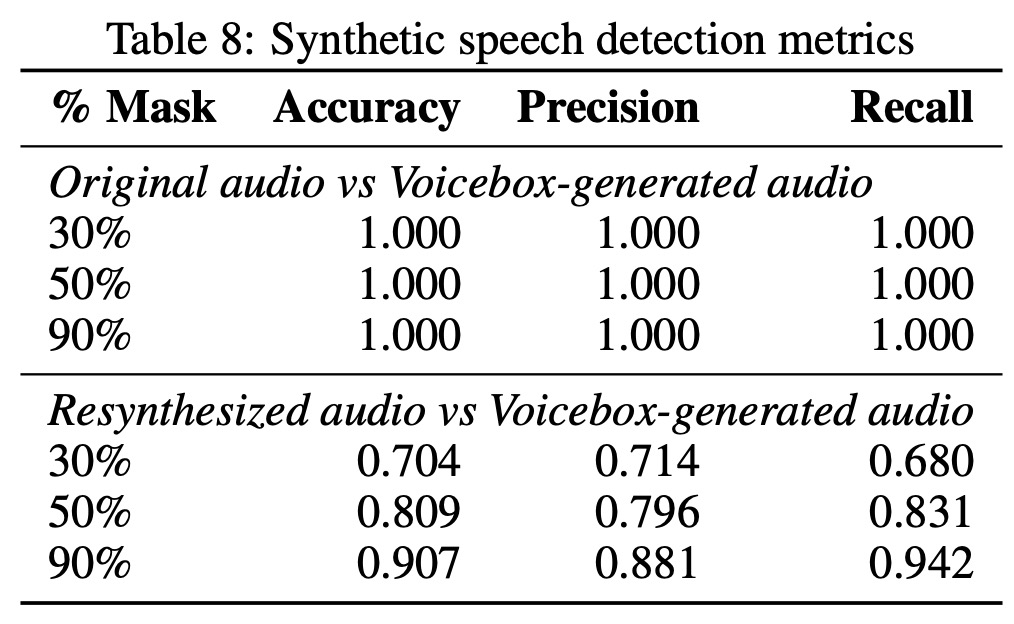
The authors discuss the potential risks of a model capable of generating speech in the style of any individual, and the measures taken to mitigate these risks. The authors introduce a binary classification model that can distinguish between real-world speech and speech generated by their Voicebox model.
The model can trivially distinguish original audio from Voicebox-generated audio, mostly by recognizing vocoder-produced artifacts. However, differentiating Voicebox-generated audio from resynthesized audio is a more challenging task. When 90% of the audio is masked, the model can reliably classify the audio as Voicebox-generated. This reliability decreases a bit in lower masking regimes, possibly due to the naive inference method of averaging the outputs of all sliding windows, as the majority of windows are non-synthetic.
Conclusion and Discussion
Voicebox exhibits strong task generalization capabilities, achieving state-of-the-art performance on monolingual and cross-lingual zero-shot Text-to-Speech (TTS), speech inpainting, and diverse speech sampling. It can also generate speech up to 20 times faster than leading autoregressive models.
However, Voicebox has limitations. It is trained on read speech from audiobooks in up to six languages, which may not translate well to more casual, conversational speech. The model also relies on a phonemizer and a forced aligner to produce frame-level phonetic transcript, and current phonemizers can’t always predict phonetic transcript accurately because pronunciation is context-dependent. Lastly, the model doesn’t allow independent control of each attribute of speech, like voice and emotion.
Looking ahead, the authors plan to incorporate more diverse speech, explore end-to-end methods that eliminate the need for phonemizers and forced aligners, and work towards disentangling control of speech attributes.
Voicebox has broader implications, such as helping people who cannot speak regain their voice through zero-shot TTS, and assisting in content creation and language translation. However, the potential for misuse exists, so a highly effective classifier has been developed to distinguish between real and synthetic speech. The authors plan future research to embed artificial fingerprints that can be easily detected, maintaining speech quality while aiding detection of synthetic speech.
paperreview deeplearning audio tts speech