
Paper Review: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models

Visualization-of-Thought (VoT) prompting enhances spatial reasoning in LLMs by enabling them to visualize their reasoning processes. By mimicking the human mind’s ability to visualize unseen objects and scenarios, VoT prompts LLMs to generate and visualize their reasoning processes, which in turn improves their performance on complex spatial reasoning tasks. VoT improves performance in tasks like natural language navigation, visual navigation, and 2D grid visual tiling, outperforming existing MLLMs.
Spatial Reasoning
Spatial reasoning is essential for applications like navigation and robotics, involving understanding spatial relationships among objects. Although LLMs can interpret spatial terms and perform well on related benchmarks, this doesn’t necessarily reflect true spatial understanding. To evaluate LLMs’ spatial awareness more accurately, tasks such as natural language navigation, visual navigation, and visual tiling have been designed. To better assess LLMs’ spatial awareness, the authors selected the following tasks:
- Natural Language Navigation: Involves navigating a space based on verbal instructions and recognizing previously visited locations. This task tests the model’s ability to understand spatial structures and loop closures.
- Visual Navigation: Challenges the model to navigate a 2D grid world using visual cues, generating instructions for movement and route planning. This task assesses the model’s ability to visually interpret space and predict subsequent movements.
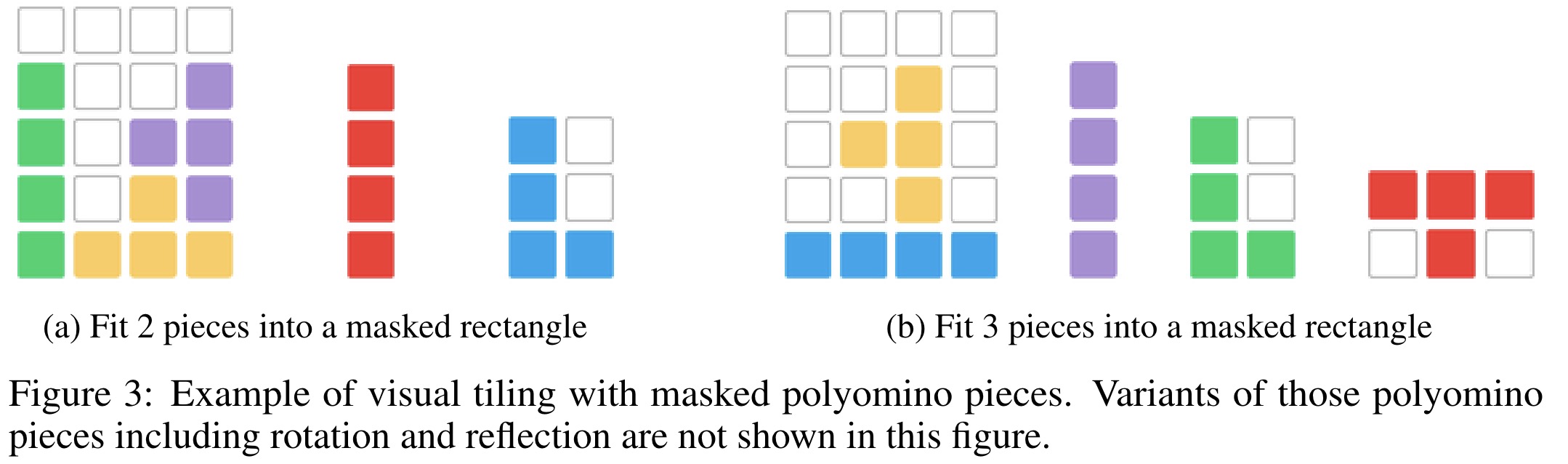
- Visual Tiling: Tasks the model with arranging various shaped tiles within a confined area, enhancing its spatial reasoning regarding geometry and spatial fit.
Visualization-of-Thought Prompting
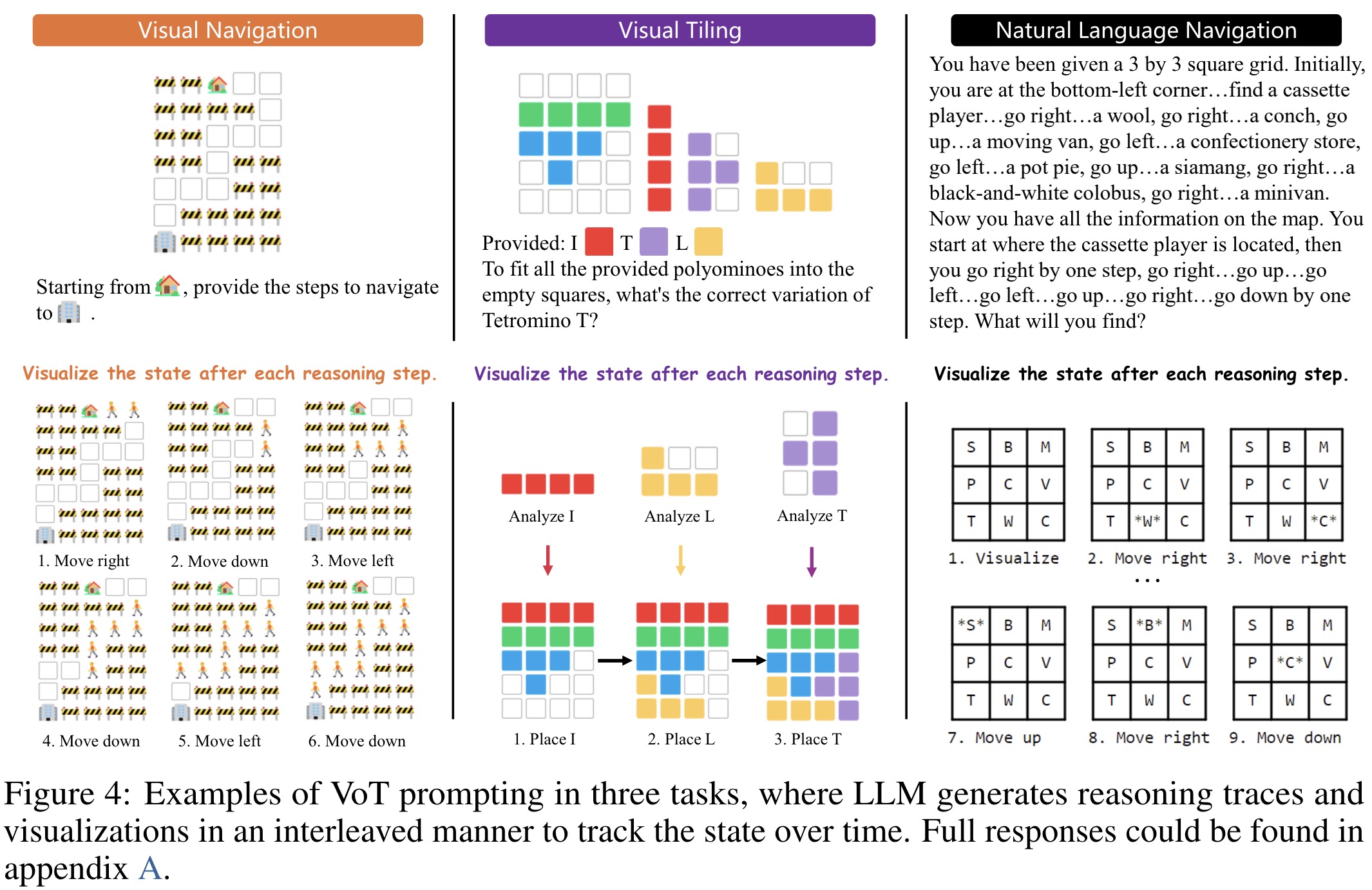
VoT prompting enhances spatial reasoning in LLMs by incorporating visualizations into their reasoning process. VoT integrates a visual aspect into each reasoning step, simulating human-like mental visualizations to improve understanding of spatial relationships and dynamics. This method, which grounds the model’s reasoning in visuospatial contexts, contrasts with traditional CoT prompting by adding visual state tracking. This allows LLMs to simulate forming mental images during tasks such as navigation, thus enhancing their spatial reasoning capabilities in a more human-like manner.
Experiments
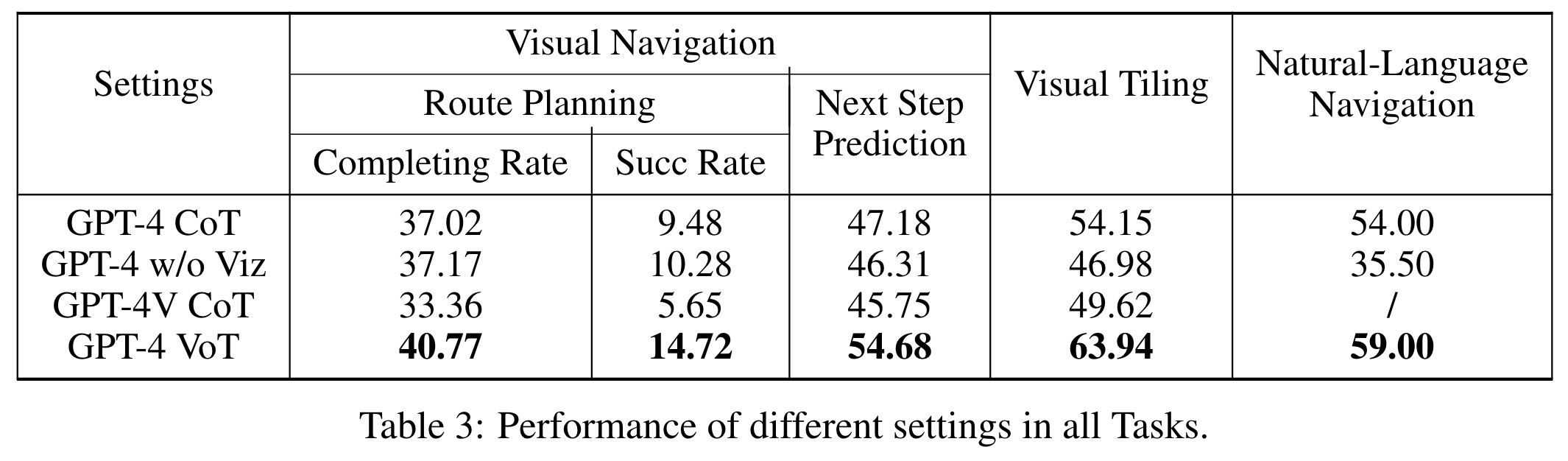
Accuracy in spatial reasoning tasks for LLMs is measured by matching model outputs against ground truths using substring matching. For route planning tasks, navigation instructions are normalized by executing each instruction and ignoring those that violate navigation rules. The effectiveness of route planning is assessed through the completing rate, which is the ratio of the length of the normalized instruction sequence to the total ground-truth instructions. Two metrics are used to evaluate performance: the average completing rate across all instruction sequences, and the success rate, which indicates the proportion of sequences where the model successfully navigates to the destination.
GPT-4 VoT shows a significant improvement over configurations without visualization, such as GPT-4V CoT and GPT-4 without visualization, with a notable 27% better performance in natural language navigation tasks. This suggests that incorporating visualizations helps LLMs better interpret actions within a grounded context. However, despite these advances, GPT-4 VoT’s performance remains imperfect, particularly in the complex route planning task, where LLM performance significantly declines with increased task complexity.
Discussions
Do visual state tracking behaviors differ among prompting methods?
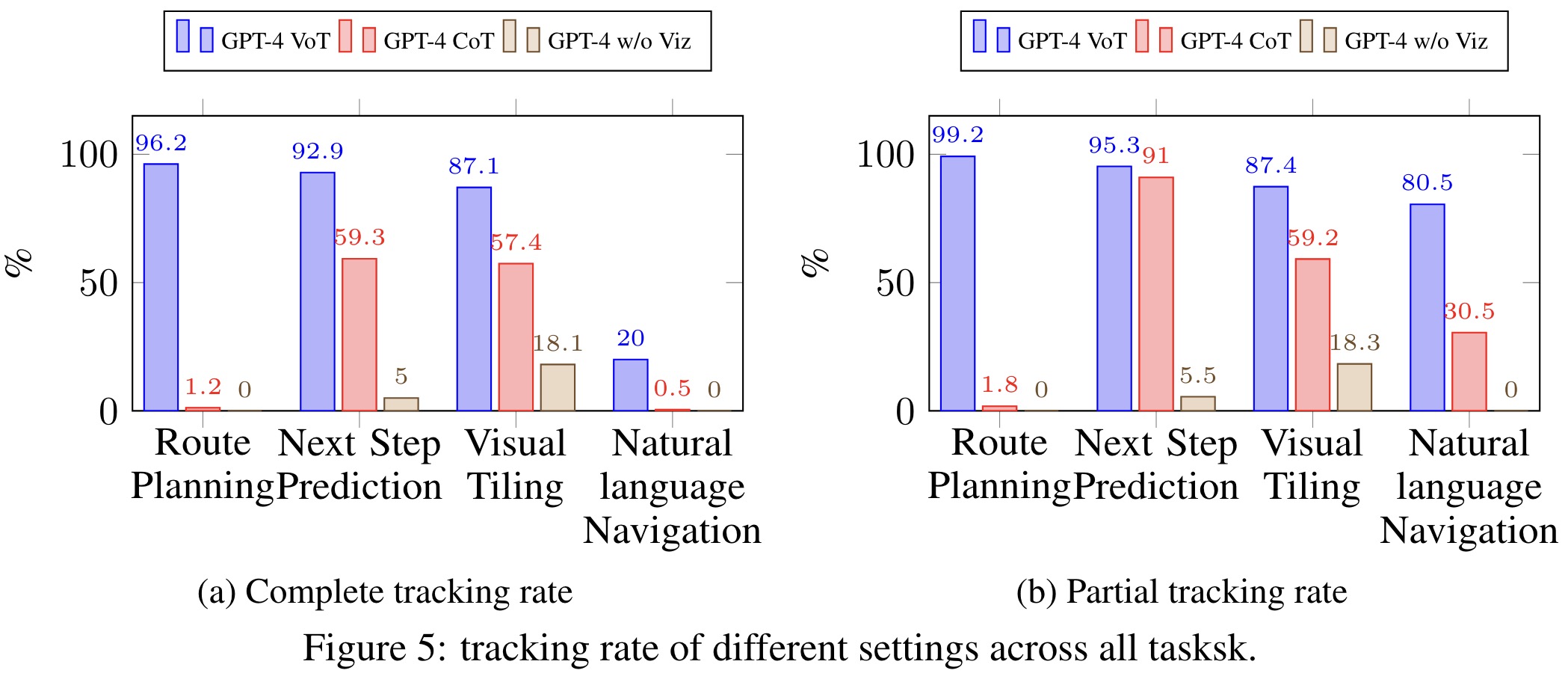
Visual state tracking in LLMs like GPT-4 is enhanced by VoT prompting, which aligns visualizations with reasoning steps to improve spatial reasoning. Models show an innate ability for visual tracking, particularly in tasks requiring spatiotemporal reasoning. 2D grid input is more likely to activate this innate capability than natural language and VoT increases the visual tracking rate noticeably. This ability may derive from exposure to tabular data, city grid navigation, and ascii-art during pre-training, which aids in spatial understanding and manipulation. Specifically, ascii-art enhances the model’s capability to generate interleaved visual and textual sequences, boosting spatial visualization and reasoning. When GPT-4 is explicitly prompted to use ascii-art for visualization in navigation tasks, it significantly improves both tracking accuracy and task performance.
How visualizations enhance final answers?
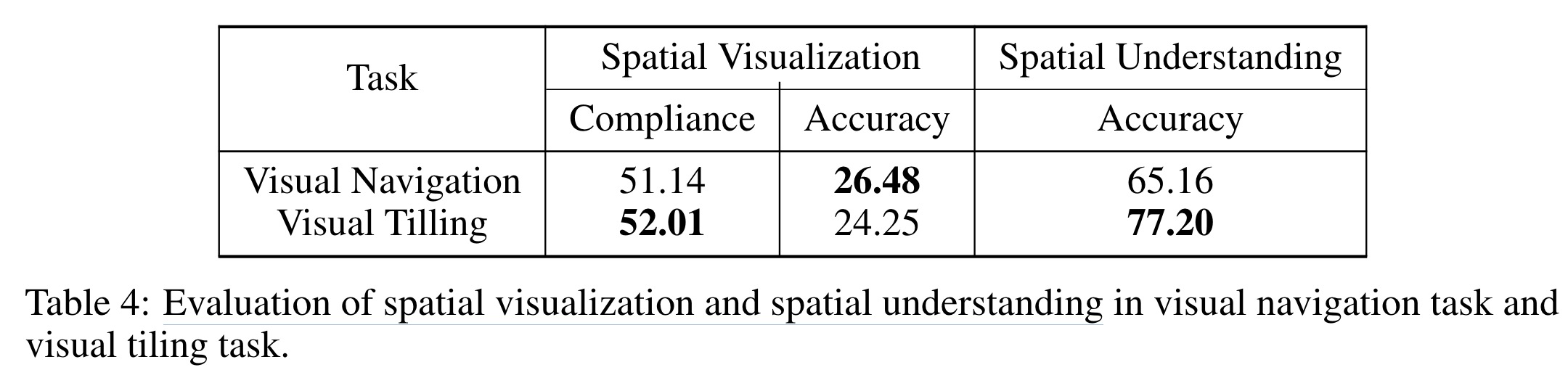
VoT prompting in GPT-4 aims to improve spatial reasoning by generating accurate visualizations at each step of a task, enhancing the model’s decision-making in subsequent steps. This is tested in tasks like visual navigation and polyomino tiling, where the last visualization produced by the model is analyzed for compliance and accuracy—key measures of the model’s spatial visualization capability. While LLMs show promising multi-hop visualization skills adhering to spatial constraints, there is still a need for significant enhancements, as indicated by the suboptimal accuracy in state visualization.
Additionally, VoT prompting might not be as effective in tasks that can be solved through logical reasoning without visual aids. In experiments involving natural language navigation within a ring, where instructions involve simple mathematical calculations, GPT-4 using CoT prompting without visualizations outperformed VoT, suggesting that in some contexts, straightforward logical reasoning may be more efficient than visual reasoning.
paperreview deeplearning mllm multimodal

