Paper Review: Winning Amazon KDD Cup’24
Amazon KDD Cup 2024 Multi Task Online Shopping Challenge for LLMs involved building a useful assistant for online shopping queries. The competition featured 57 tasks across 5 types and 4 tracks.
The winning solution used a single model per track, fine-tuning Qwen2-72B-Instruct on a custom training dataset. Since only 96 example questions were provided, additional data was generated using public datasets and synthetic data. The approach included wise-finetuning, ensembling LoRA adapters, and employing Logits Processors to constrain output. AWQ 4-bit Quantization and vLLM were used for efficient inference.
Amazon KDDCup 2024: Multi Task Online Shopping Challenge for LLMs
The KDD Cup 2024, hosted by Amazon, focused on developing LLMs for online shopping assistance. Participants worked with a small development dataset of 96 questions covering only 18 of 57 tasks. The test dataset, called ShopBench, contained 20000 questions. The competition was a code submission challenge where models were evaluated on Amazon’s infrastructure, using 4x NVIDIA T4 GPUs.
Participants faced several challenges: no training dataset, hidden tasks (only 18 out of 57 were visible), and time and compute constraints. The competition had five tracks: Shopping Concept Understanding, Shopping Knowledge Reasoning, User Behavior Alignment, Multi-lingual Abilities, and an Overall track that combined all others. Each track involved multiple task types: Multiple Choice, Ranking, NER, Retrieval, and Generation.
The requirement for each question was to generate text that could be parsed by Amazon’s evaluation script. If the script couldn’t parse the response, a score of 0 would be given for that question.
Datasets
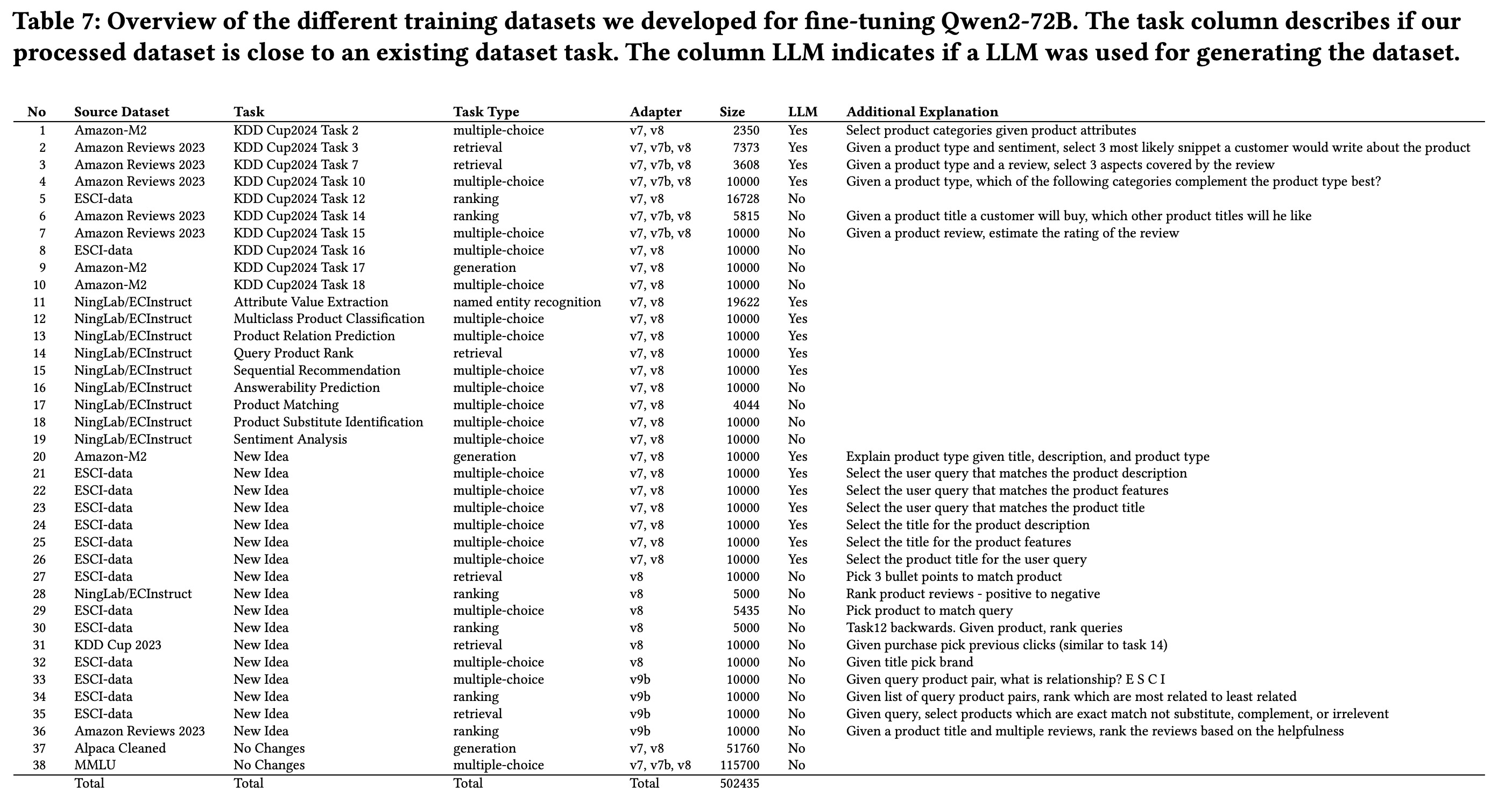
In order to create the training data, participants used a mix of real and synthetic datasets. Real datasets included non-e-commerce sources like MMLU and Alpaca-Cleaned, as well as e-commerce-specific data like Amazon-M2, Amazon Reviews 2023, NingLab/ECInstruct, and ESCI-data.
To further diversify the data, synthetic data generation pipelines were used:
- Prompting LLMs to rephrase existing tasks, combining product details into task-specific prompts.
- Extracting correct labels (e.g., product type, categories) from seed data using LLMs and constructing related questions.
- Using GPT-4 to generate instructions with varied wordings and create multiple-choice tasks from ESCI-data, with correct answers randomly selected from relevant entries.
Model
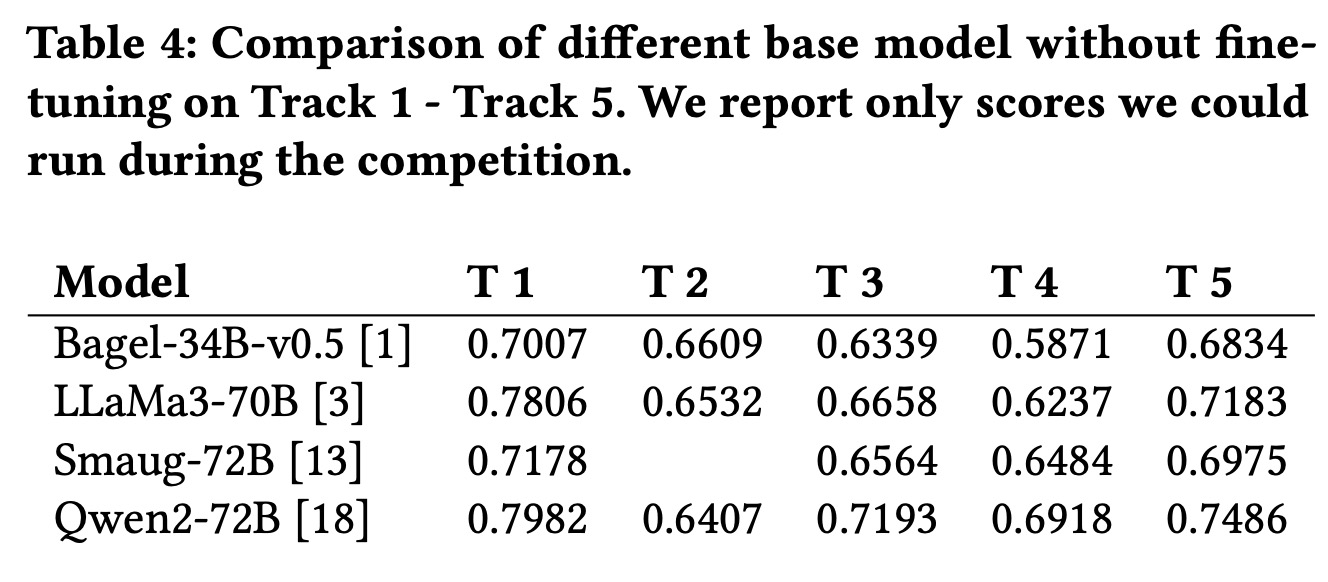
In the KDD Cup 2024 competition, the winning team explored both zero-shot and fine-tuned LLM models, ultimately finding fine-tuning to provide the best accuracy. They used a prompt template that specified the task type and incorporated a heuristic rule classifier during inference to determine the question’s task type. system_prompt = "You␣are␣a␣helpful␣online␣shopping␣ assistant.␣Your␣task␣is␣{task_type}."
For fine-tuning, they used the Qwen2-72B-Instruct model, training it on a dataset of 500,000 examples using 8x NVIDIA A100 GPUs for 24 hours. They focused on supervised fine-tuning (and not RLHF), deeming it enough - many questions have exact solutions and thus don’t require human preferences.
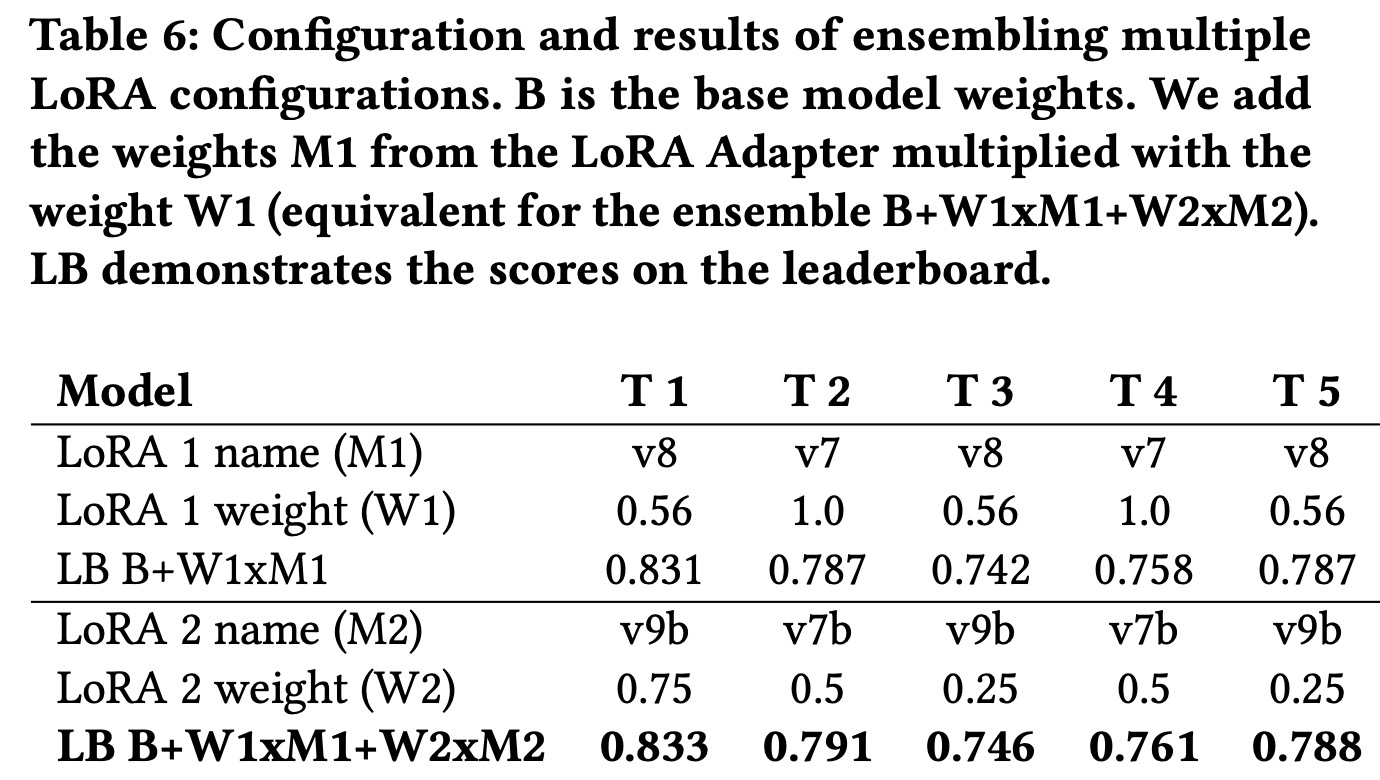
The solution also involved ensembling four fine-tuned LoRA adapters for different tracks, balancing task-specific performance with zero-shot capabilities using wise-ft, which interpolates between base model weights and fine-tuned weights
Logits processors were used to constrain model outputs to specific formats: digits and commas for multiple choice, ranking and retrieval; encouraging models to cite from the prompt for NER. When switching to larger models in Phase 2, the importance of these processors decreased.
Given the competition’s constraints (limited compute resources and time), the team employed 4-bit quantization to reduce the size of the Qwen2-72B model from 150GB to 40GB and used vLLM for faster inference. They calibrated AWQ quantization with the development questions, improving accuracy while staying within the time limits for each track.
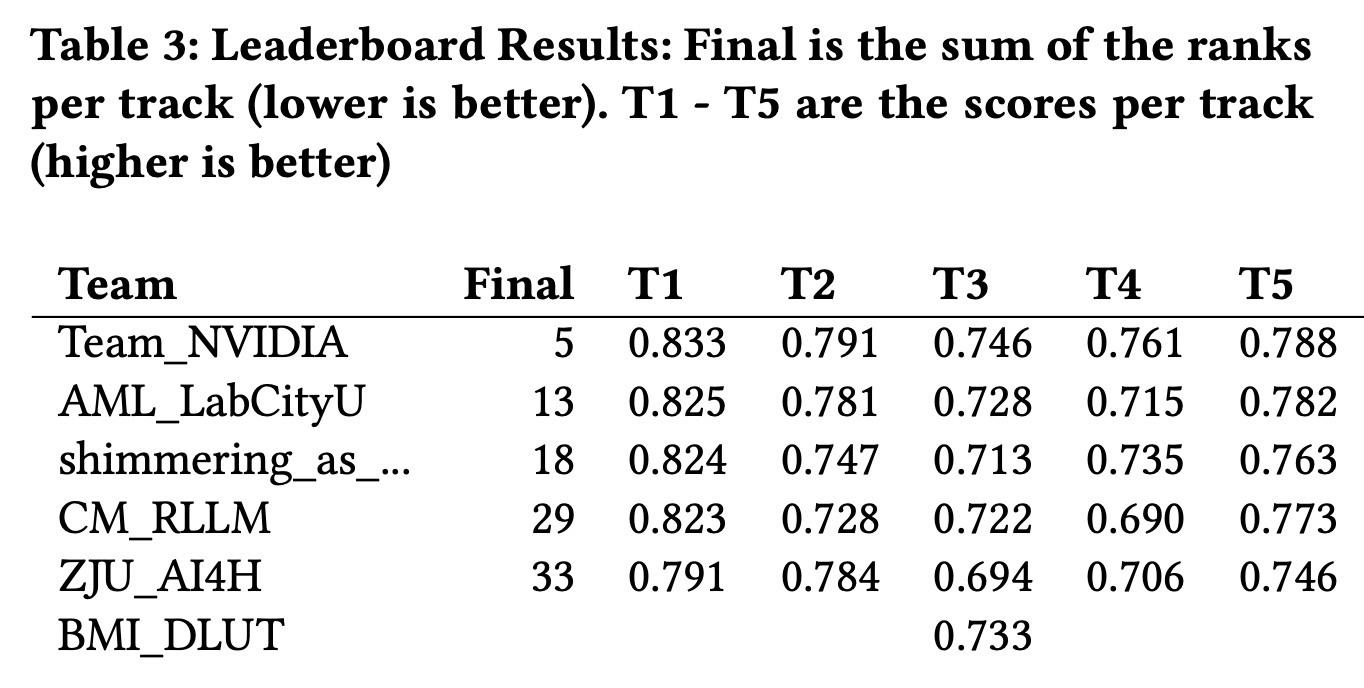
Results