Paper Review: Wolf: Captioning Everything with a World Summarization Framework

Wolf (WOrLd summarization Framework) is a video captioning framework that combines different VLMs to improve accuracy. It uses both image and video models to capture various levels of information, enhancing video understanding, auto-labeling, and captioning. To evaluate caption quality, the authors introduce a new LLM-based metric called CapScore, which assesses the similarity and quality of generated captions against ground truth. They also create four human-annotated datasets across three domains - autonomous driving, general scenes, and robotics - for comprehensive evaluation. Wolf outperforms existing state-of-the-art research (VILA1.5, CogAgent) and commercial (Gemini-Pro-1.5, GPT-4V) solutions, significantly improving caption quality and similarity, particularly in challenging driving videos. The authors also establish a benchmark and a leaderboard to promote further advancements in the field.
Wolf: Captioning Everything with a World Summarization Framework
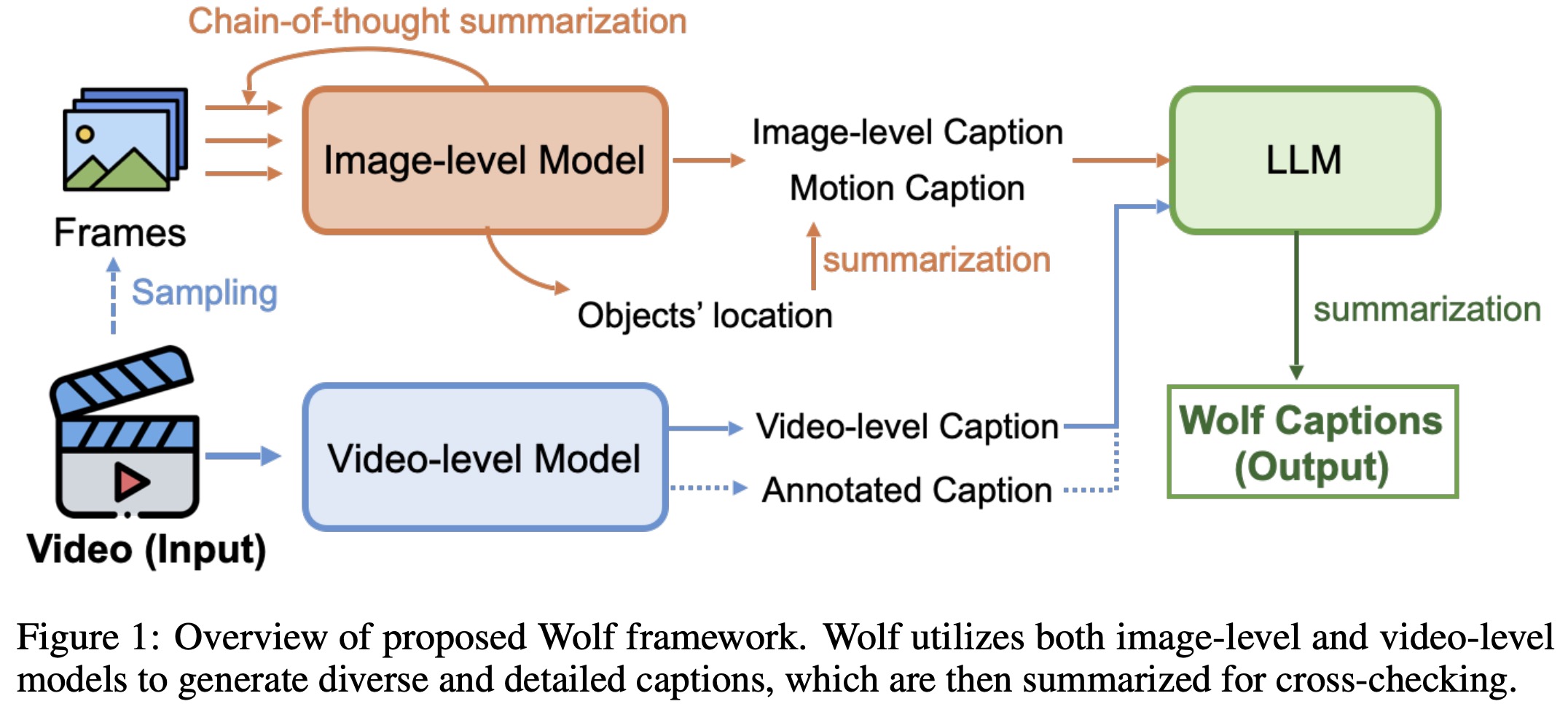
First, image-based VLMs, which are pre-trained on larger datasets, generate captions for sequential key frames of the video (two key-frames per second) using Chain-of-thought. These captions provide detailed scene-level information and object locations. Then, GPT-4 summarizes all the captions to produce a cohesive description of the video, capturing both visual and temporal information. A separate process uses the video-level VLM to generate captions for the entire video, providing a high-level overview of the content. Then, Wolf uses an LLM to summarize and refine the captions from both image-level and video-level models, reducing hallucinations and redundancy. This approach allows Wolf to capture a rich variety of details and accurately describe motion behavior in videos.
Wolf Benchmark: Benchmarking Video Captioning

- Autonomous Driving: 500 intensely interactive video-caption pairs and 4785 normal driving scene video-caption pairs
- Robot Manipulation: 100 robot manipulation videos
- Pexels: 473 high-quality videos
CapScore addresses the challenge in video captioning of lacking a standard evaluation metric. Inspired by BERTScore and CLIPScore, CapScore uses GPT-4 to assess captions on two criteria: Caption Similarity and Caption Quality.
- Caption Similarity measures how closely a predicted caption aligns with the ground truth, focusing on content and context.
- Caption Quality evaluates the accuracy of the caption, checking for reduced hallucinations (incorrect or extraneous details) compared to the ground truth.
GPT-4 is used to provide scores for these metrics on a scale from 0 to 1.
Experiments

Wolf excels in capturing detailed motion behaviors in videos, such as vehicles moving in different directions and reacting to traffic signals, which other models struggle with.
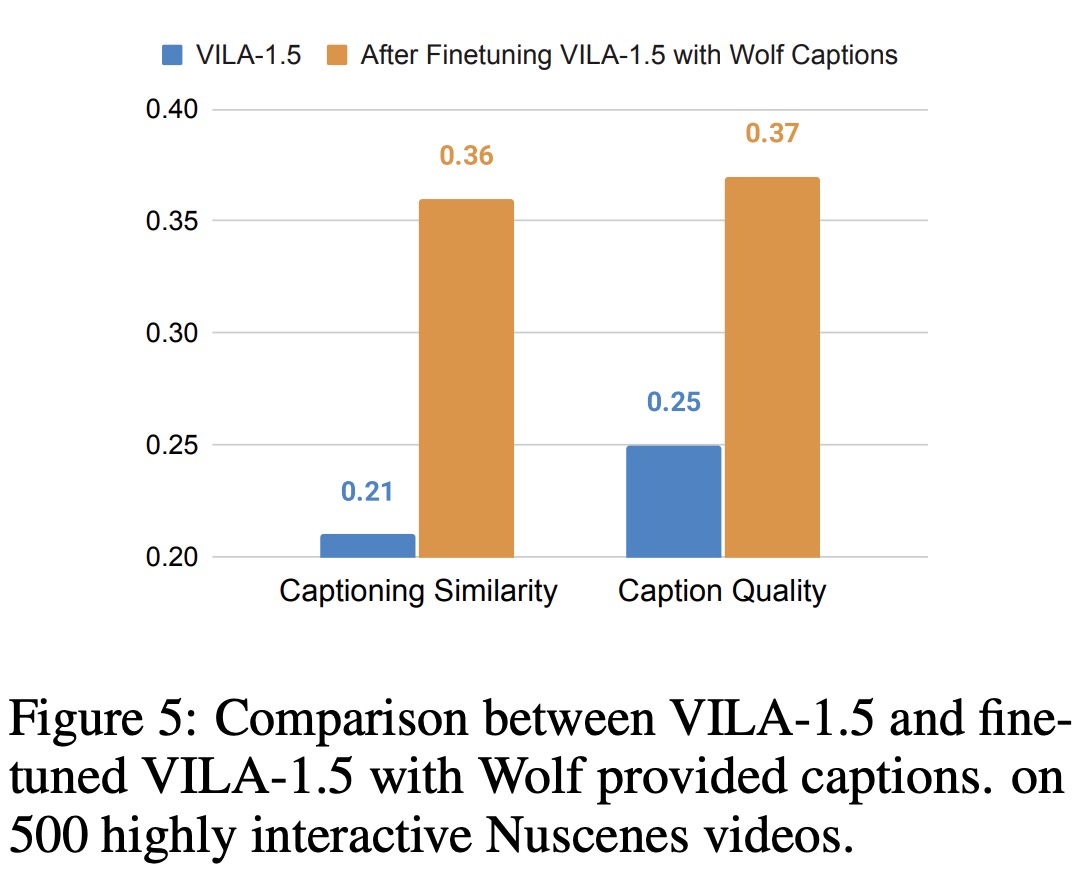
To further validate Wolf’s effectiveness, the authors fine-tuned the VILA-1.5 model using captions generated by Wolf on the Nuscenes dataset. This fine-tuning significantly improved the model’s performance, particularly in caption similarity and quality, outperforming GPT-4V and approaching the performance of Gemini-Pro-1.5. The results suggest that Wolf-generated captions can enhance the performance of VLMs, pushing them to achieve higher accuracy and detail in video captioning.
The ablation study shows that the chain-of-thought approach in Wolf significantly improves video understanding in models like CogAgent. Wolf consistently achieves higher CapScores by incorporating additional video captions from various models.
In evaluating token efficiency, it’s observed that longer captions initially improve similarity scores but eventually plateau or decline. Caption quality varies, with GPT-4V maintaining consistency, while Wolf and Gemini-Pro-1.5 perform better with shorter captions. This indicates that concise captions may be more effective in certain contexts, balancing similarity and quality.
Limitations and Optimization
Wolf is more cost-effective for auto-labeling and captioning than human labels, but its ensemble method raises efficiency concerns, particularly regarding GPU resource usage. To optimize Wolf, the focus is on three areas: Low-Hanging Fruit, Batched Inference, and Model Quantization. For, example, quantizing models to 4 bits improves efficiency by reducing memory usage and increasing batch sizes, allowing more videos to be processed in parallel.
For safety, Wolf reduces the risk of missing crucial information or including hallucinations in captions, which is vital for autonomous systems. However, there are unresolved safety issues, such as aligning captions with the task at hand, measuring caption alignment, and quantifying confidence in captions.
paperreview deeplearning llm vlm summarization captioning multimodal