Paper Review: YOLOv10: Real-Time End-to-End Object Detection

YOLO models are popular in real-time object detection for their balance between computational cost and detection performance. Over the years, researchers have improved their designs, objectives, and data strategies, but reliance on non-maximum suppression increases latency and hinders end-to-end deployment. Various YOLO components have inefficiencies that limit their capability.
YOLOv10 addresses these issues with NMS-free training for lower latency and an efficiency-accuracy driven design strategy. The authors introduced consistent dual assignments for NMS-free training, which simultaneously achieves competitive performance and low inference latency. They also proposed a holistic efficiency-accuracy driven model design strategy, optimizing various YOLO components from both efficiency and accuracy perspectives. This reduces computational overhead and enhances performance. Experiments show YOLOv10 achieves state-of-the-art performance and efficiency. For example, YOLOv10-S is 1.8 times faster than RT-DETR-R18 with similar accuracy and has fewer parameters and FLOPs. Compared to YOLOv9-C, YOLOv10-B has 46% less latency and 25% fewer parameters for the same performance.
The approach
Consistent Dual Assignments for NMS-free Training
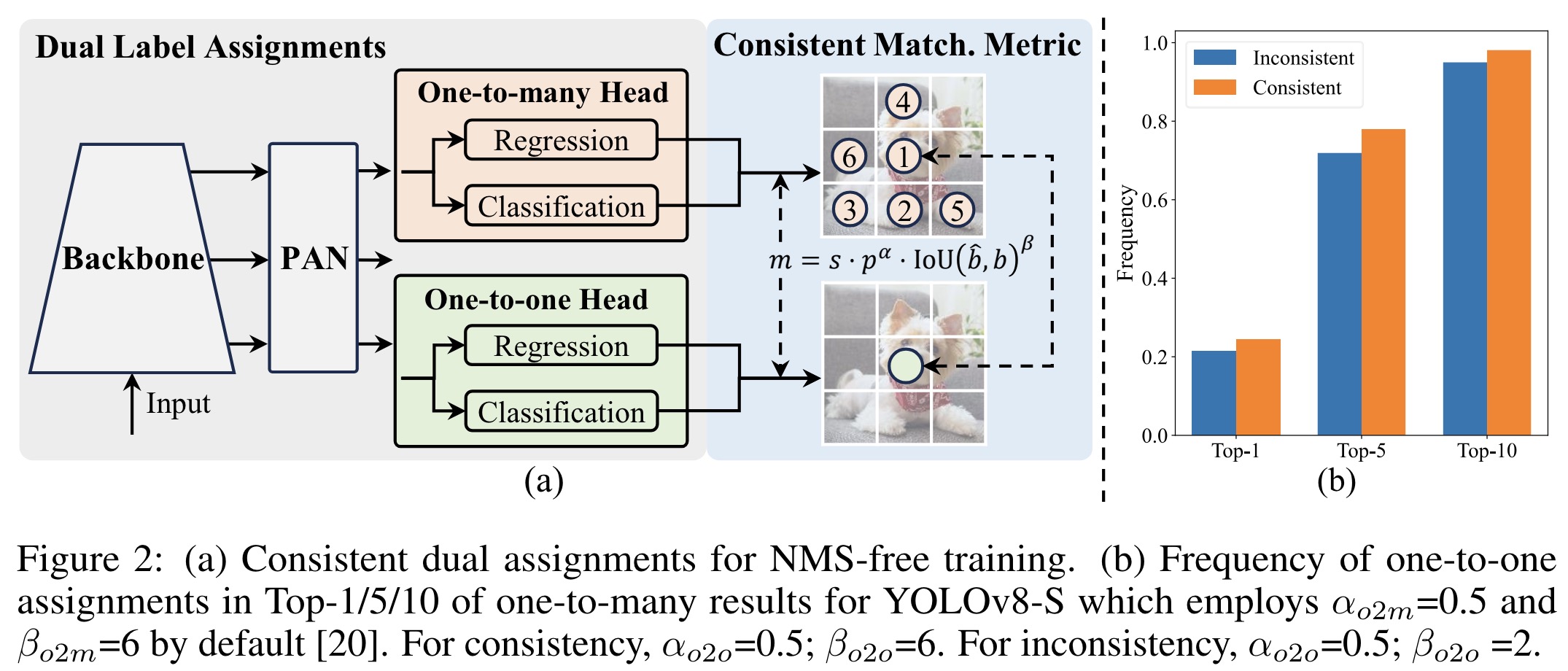
YOLO models typically use Task Alignment Learning (TAL) for training, which involves assigning multiple positive samples to each instance to enhance optimization and performance. However, this requires non-maximum suppression (NMS) post-processing, reducing inference efficiency. While one-to-one matching avoids NMS, it introduces inference overhead or suboptimal performance.
The authors introduce an NMS-free training strategy using dual label assignments and a consistent matching metric.
During training, a secondary one-to-one head is incorporated alongside the traditional one-to-many head, both sharing the same optimization objectives but utilizing different matching strategies. The one-to-many head provides rich supervisory signals, while the one-to-one head ensures efficient, NMS-free predictions during inference. Only the one-to-one head is used for inference to avoid extra costs.
To harmonize the training process, a consistent matching metric is used. This metric assesses the concordance between predictions and instances for both one-to-many and one-to-one assignments, using a uniform approach that balances semantic prediction and location regression tasks. By aligning the supervision from both heads, the model ensures that the best positive samples for one head are also the best for the other, optimizing both consistently. This approach significantly improves the alignment of one-to-one matching pairs with top results from one-to-many matching.
Holistic Efficiency-Accuracy Driven Model Design
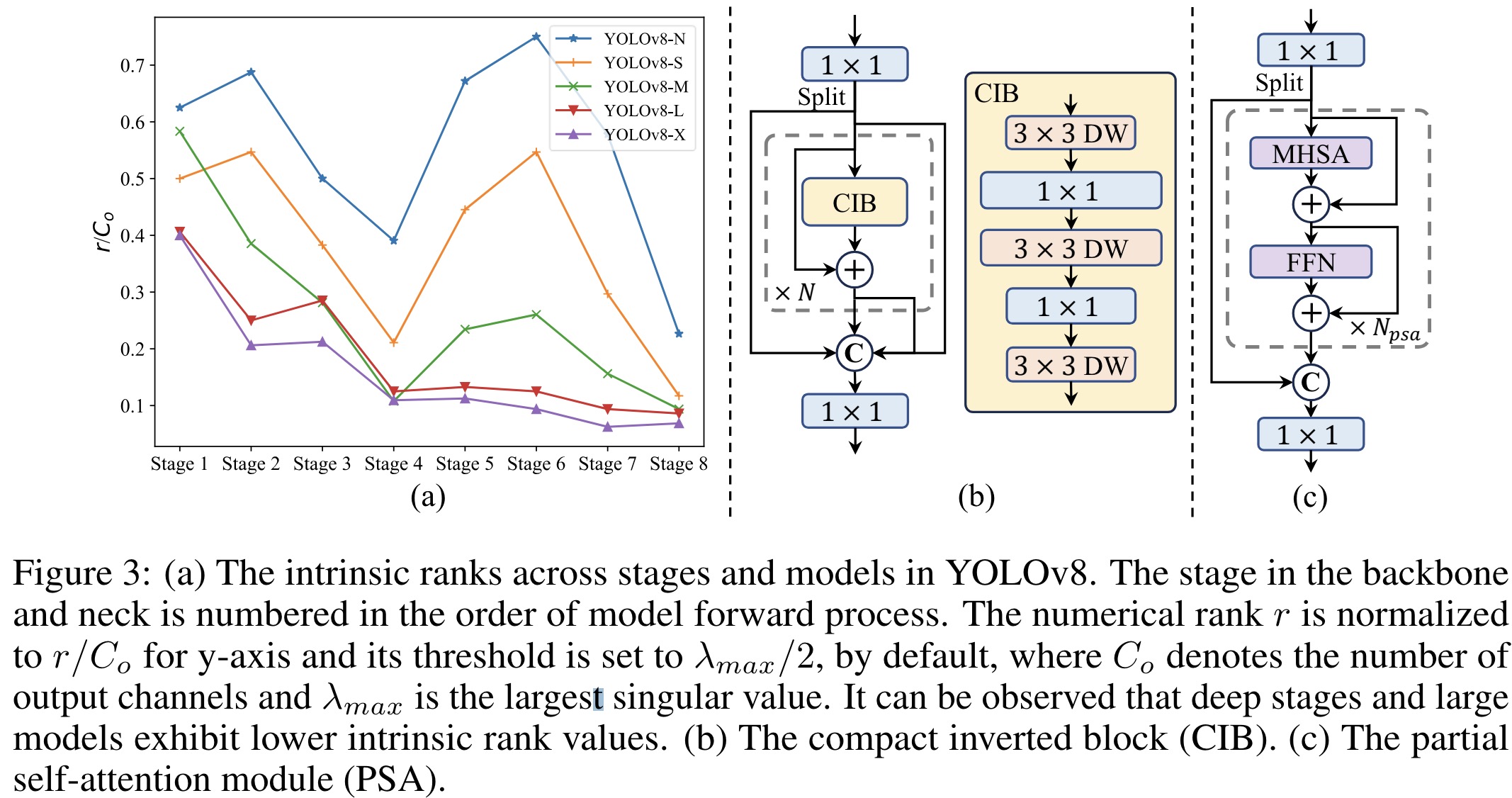
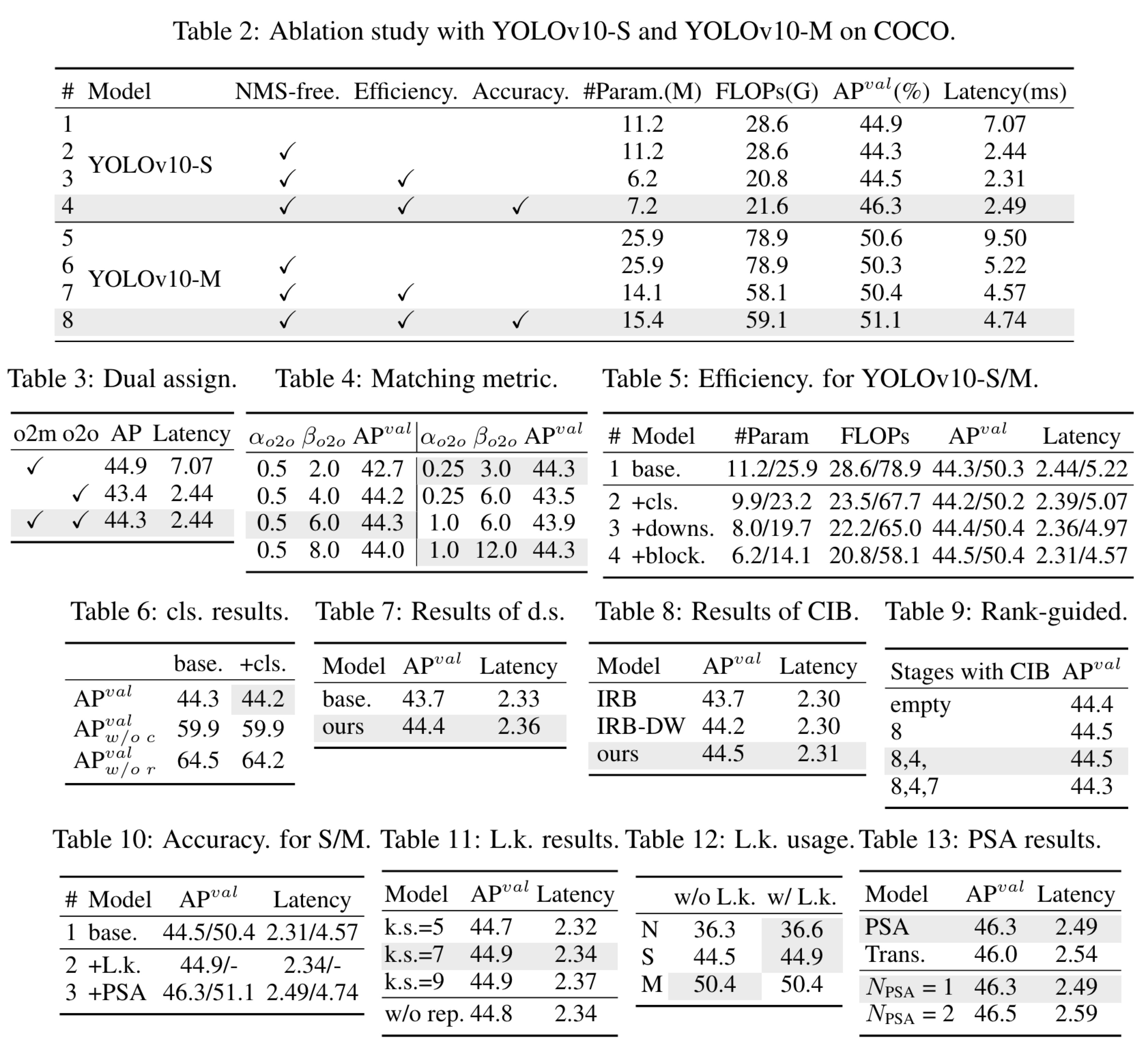
YOLO models face challenges in balancing efficiency and accuracy due to their architecture, which can be computationally redundant and limited in capability. The authors propose comprehensive model designs to address these issues, focusing on both efficiency and accuracy.
Efficiency-driven model design:
- Lightweight classification head: Reduces computational overhead by using a simplified architecture with depthwise separable convolutions.
- Spatial-channel decoupled downsampling: Separates spatial reduction and channel increase to decrease computational costs and retain information.
- Rank-guided block design: Uses intrinsic rank analysis to identify and reduce redundancy in model stages, replacing complex blocks with more efficient structures like the compact inverted block.
Accuracy-driven model design:
- Large-kernel convolution: Enhances model capability by increasing the receptive field in deep stages, using large-kernel depthwise convolutions selectively to avoid overhead in shallow stages.
- Partial self-attention (PSA): Incorporates efficient self-attention by partitioning features and applying self-attention to part of the features, reducing computational complexity and memory usage while enhancing global representation learning.
Experiments
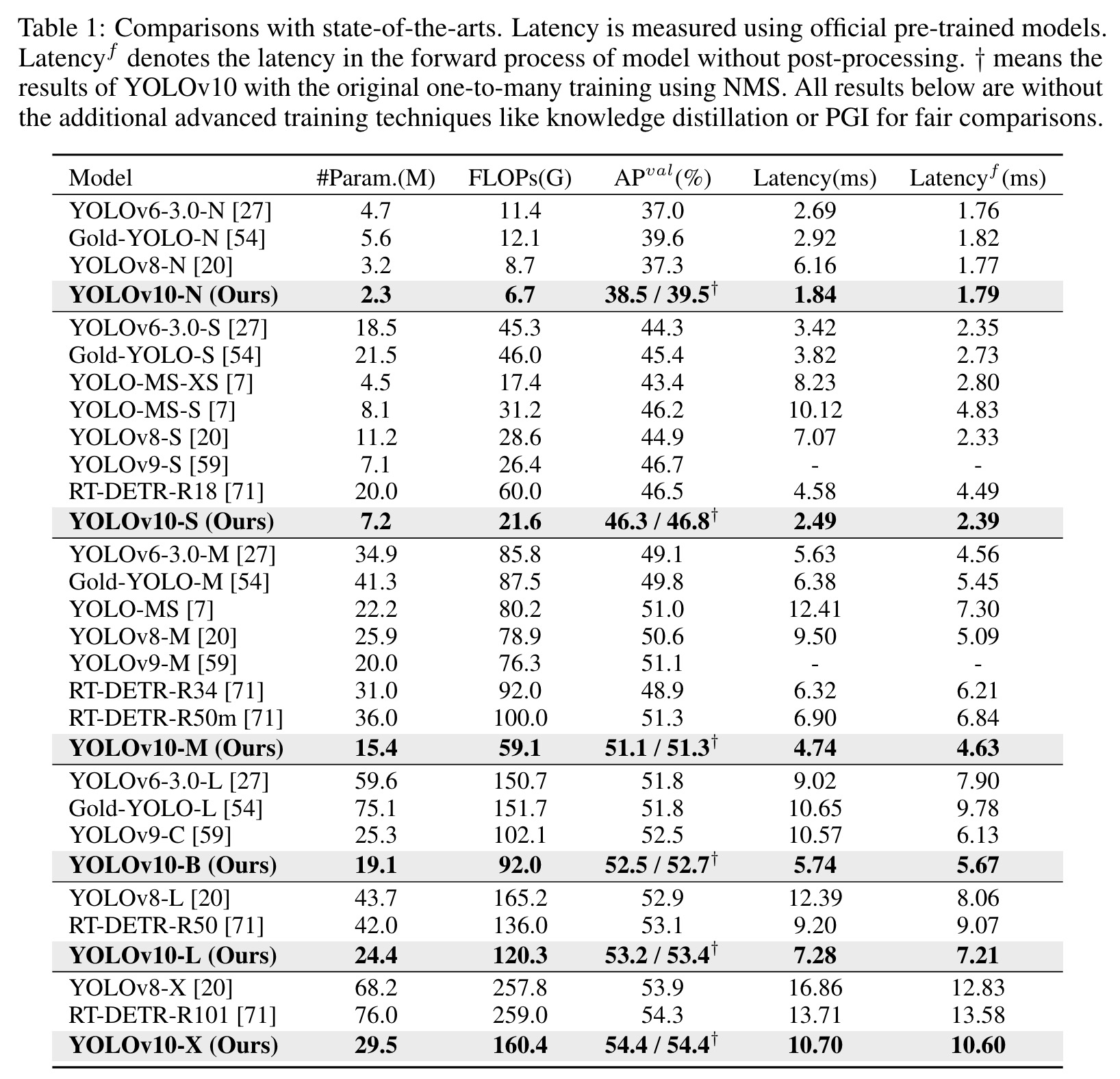
When compared to the baseline YOLOv8 models, YOLOv10 shows notable improvements in AP, with increases of 1.2% for the N variant, 1.4% for the S variant, 0.5% for the M variant, 0.3% for the L variant, and 0.5% for the X variant. Furthermore, YOLOv10 achieves significant reductions in latency, ranging from 37% to 70%.