Paper Review: YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
This paper introduces a novel concept named Programmable Gradient Information to address the issue of data loss in deep learning networks as data undergoes layer-by-layer feature extraction and spatial transformation. PGI aims to provide complete input information for calculating the objective function, ensuring reliable gradient information for network weight updates. Alongside PGI, the authors present a new lightweight network architecture called Generalized Efficient Layer Aggregation Network (GELAN), which is designed based on gradient path planning. GELAN leverages conventional convolution operators to achieve better parameter utilization compared to state-of-the-art methods that use depth-wise convolution. The effectiveness of GELAN and PGI is demonstrated through object detection tasks on the MS COCO dataset, showing that this approach allows train-from-scratch models to surpass the performance of models pre-trained on large datasets.
Problem Statement
Information Bottleneck Principle
The Information Bottleneck Principle highlights the inevitable information loss data X experiences during transformation in deep neural networks; it illustrates that with each layer the data passes through, the likelihood of information loss increases, potentially leading to unreliable gradients and poor network convergence due to incomplete information about the prediction target. One proposed solution to mitigate this issue is to enlarge the model with more parameters, allowing for a more comprehensive data transformation and improving the chances of retaining sufficient information for accurate target mapping. However, this approach does not address the fundamental issue of unreliable gradients in very deep networks. The authors suggest exploring reversible functions as a potential solution to maintain information integrity throughout the network, aiming to achieve better convergence by preserving essential data through the network layers.
Reversible Functions
The concept of reversible functions means that a function and its inverse can transform data without loss of information. This principle is applied in architectures like PreAct ResNet, which ensures data is passed through layers without loss, aiding in deep network convergence but potentially compromising the depth’s advantage in solving complex problems. An analysis using the information bottleneck principle reveals that retaining critical information mapping data to targets is essential for training effectiveness, especially in lightweight models. The aim is to develop a new training method that generates reliable gradients for model updates and is feasible for both shallow and lightweight neural networks, addressing the core issue of significant information loss during data transformation.
Approach
Programmable Gradient Information
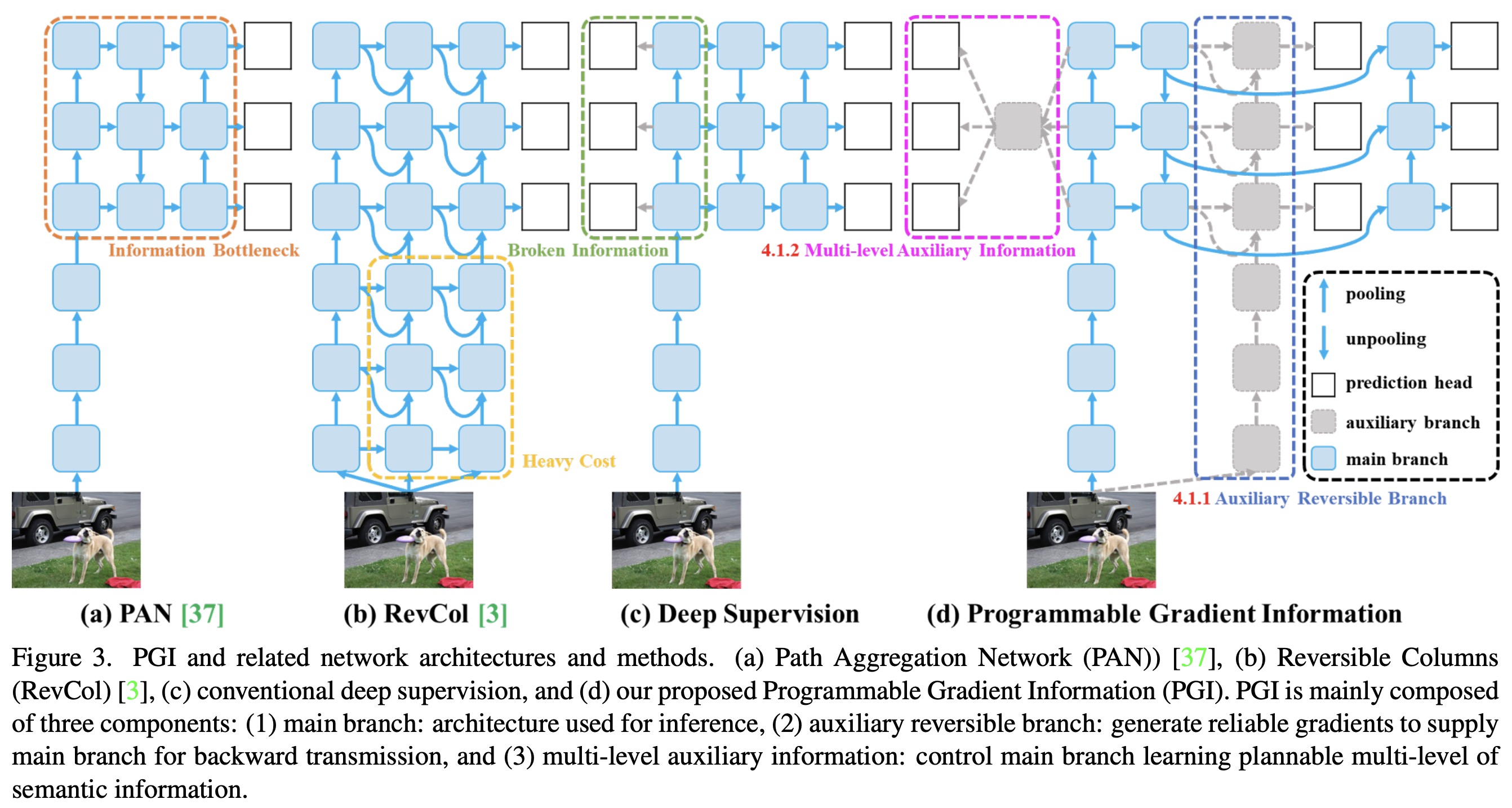
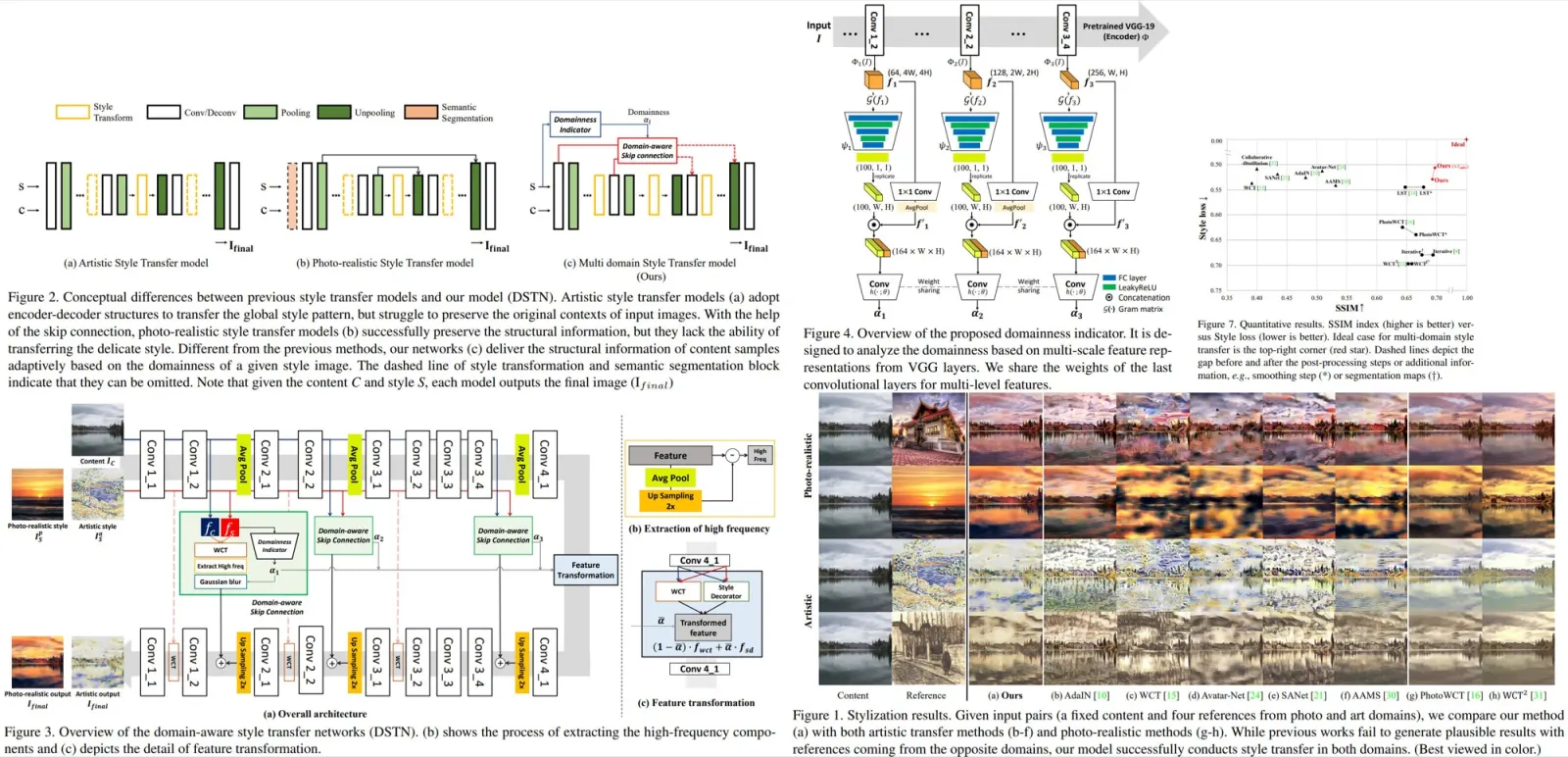
PGI consists of three components: a main branch for inference without extra cost, an auxiliary reversible branch to counteract the effects of network depth, and multi-level auxiliary information to mitigate error accumulation in deep supervision and lightweight models with multiple prediction branches.
Auxiliary Reversible Branch
Auxiliary Reversible Branch helps maintain complete information flow from data to targets, mitigating the risk of false correlations due to incomplete features. However, integrating a reversible architecture with a main branch significantly increases inference costs. To counteract this, PGI treats the reversible branch as an expansion of deep supervision, enhancing the main branch’s ability to capture relevant information without the necessity of retaining complete original data. This approach allows for effective parameter learning and application to shallower networks. Importantly, the auxiliary reversible branch can be omitted during inference, preserving the network’s original inference efficiency.
Multi-level Auxiliary Information
This component aims to address the information loss in deep supervision architectures, particularly in object detection tasks using multiple prediction branches and feature pyramids for detecting objects of various sizes. This component integrates a network between the feature pyramid layers and the main branch to merge gradient information from different prediction heads. This integration ensures that each feature pyramid receives comprehensive target object information, enabling the main branch to retain complete information for learning predictions across various targets. By aggregating gradient information containing data about all target objects, the main branch’s learning is not skewed towards specific object information, mitigating the issue of fragmented information in deep supervision.
Experiments
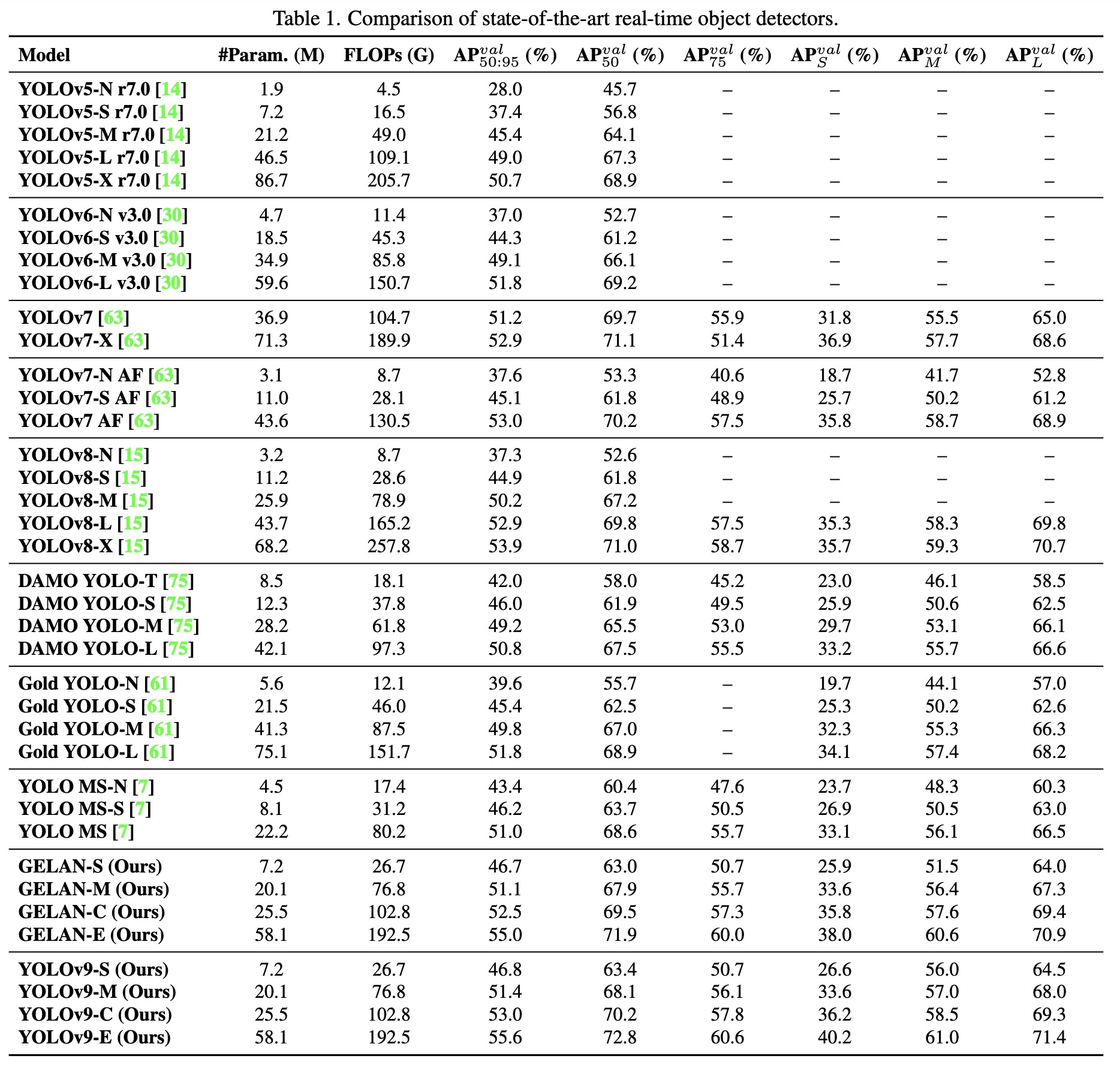
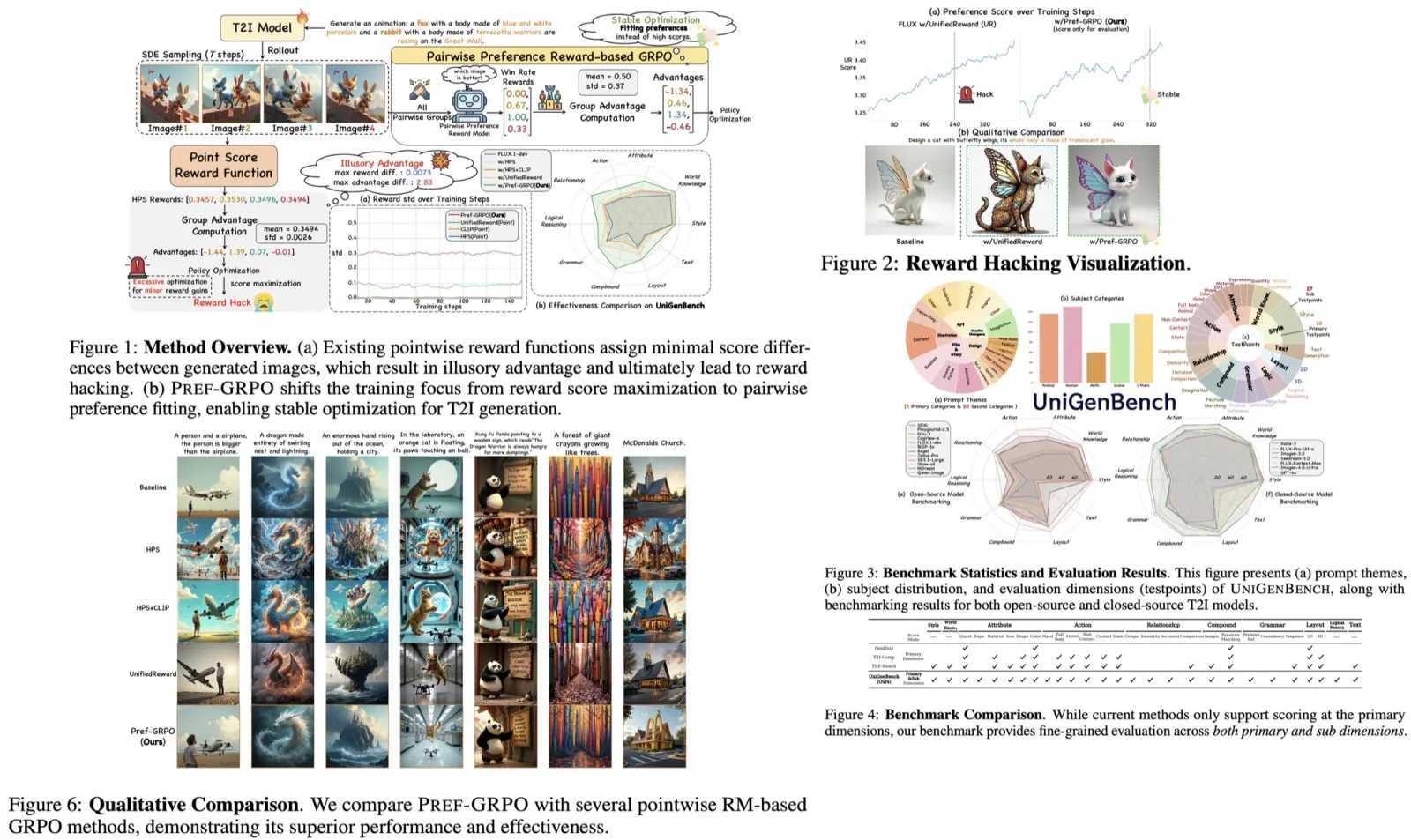
YOLOv9 outperforms existing real-time object detectors across various model sizes, achieving higher accuracy with fewer parameters and reduced computational requirements. Specifically, YOLOv9 surpasses lightweight and medium models like YOLO MS in terms of parameter efficiency and accuracy, matches the performance of general models such as YOLOv7 AF with significantly fewer parameters and calculations, and exceeds the large model YOLOv8-X in both efficiency and accuracy.
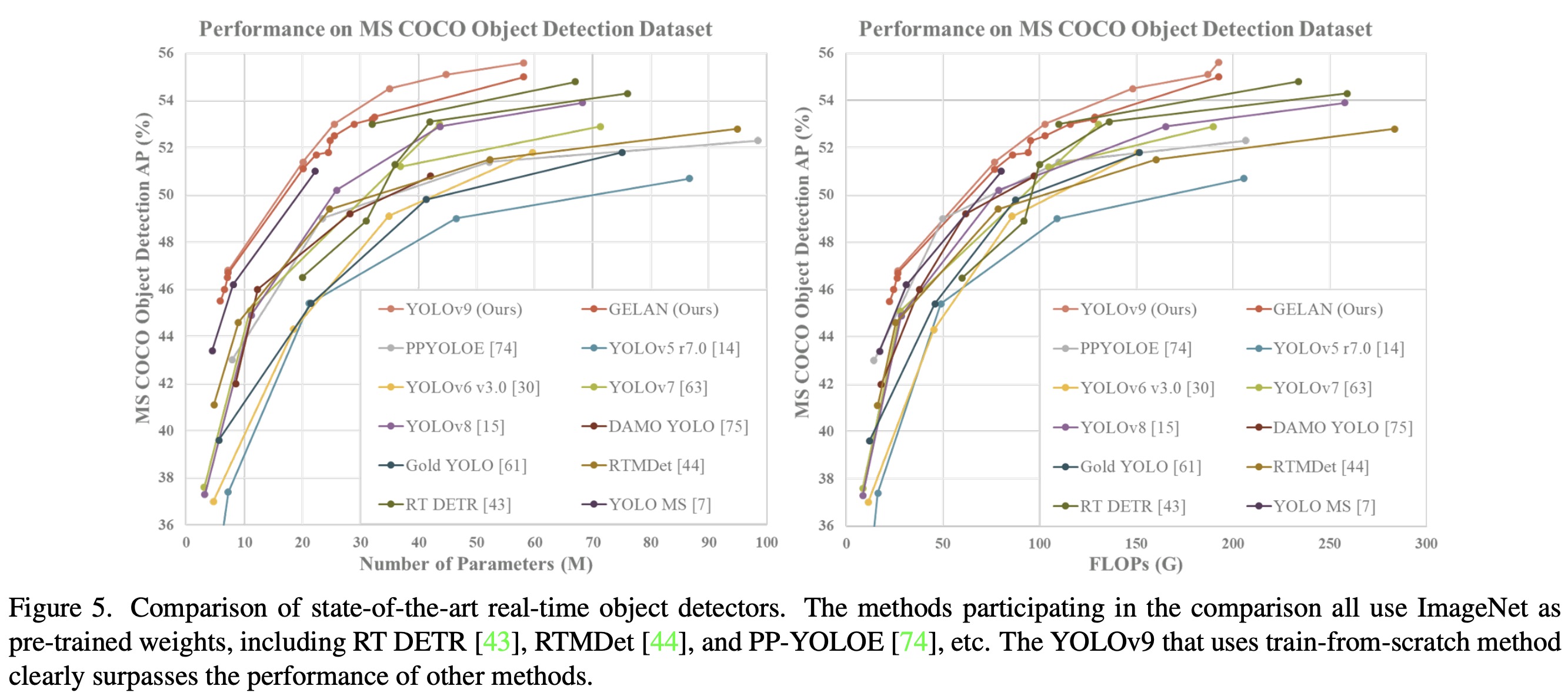
Additionally, when compared to models using depth-wise convolution or ImageNet pretraining, YOLOv9 demonstrates superior parameter utilization and computational efficiency. The success of YOLOv9, particularly in deep models, is attributed to the PGI, which enhances the ability to retain and extract crucial information for data-target mapping, leading to performance improvements while maintaining lower parameter and computation demands.
Ablations
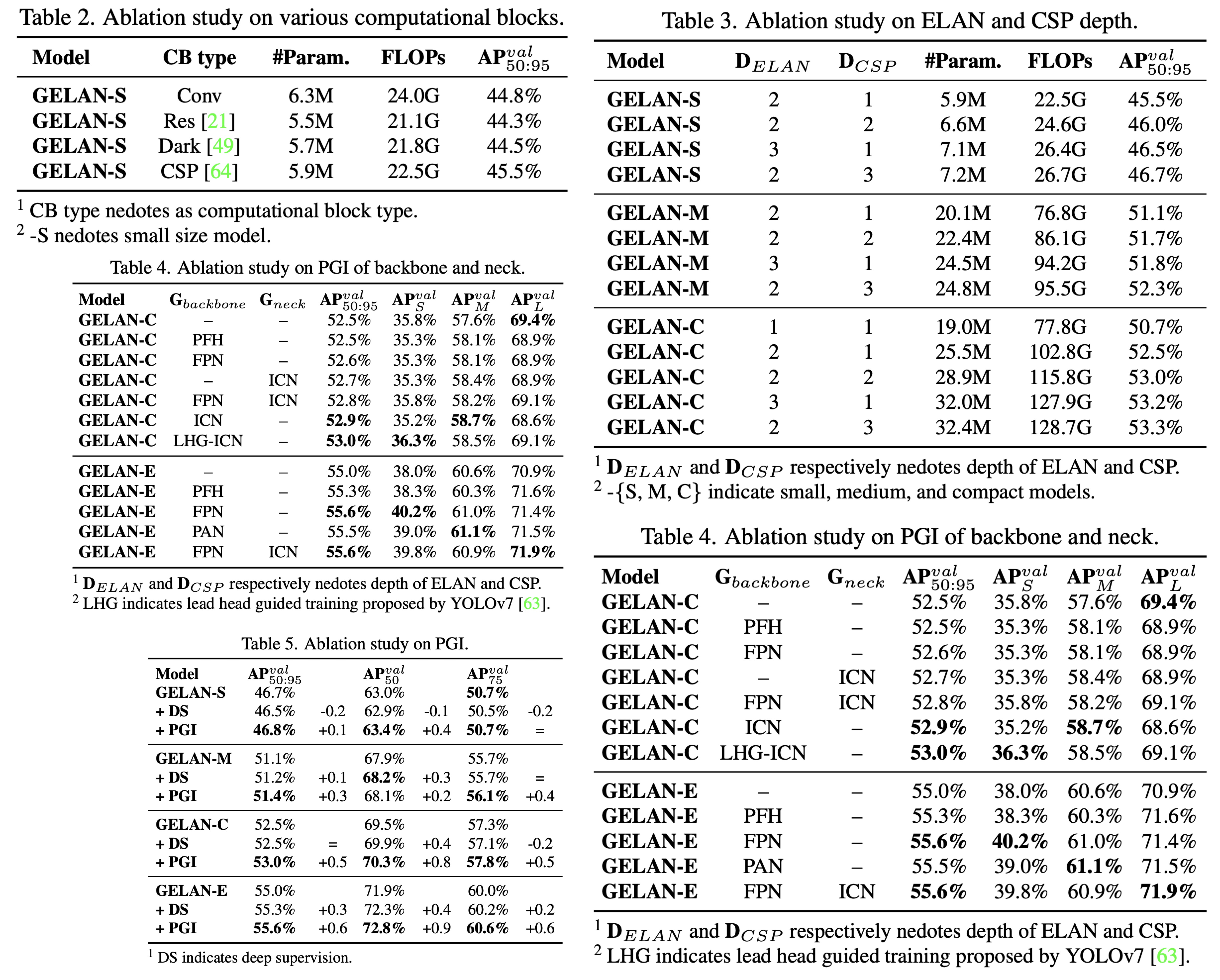
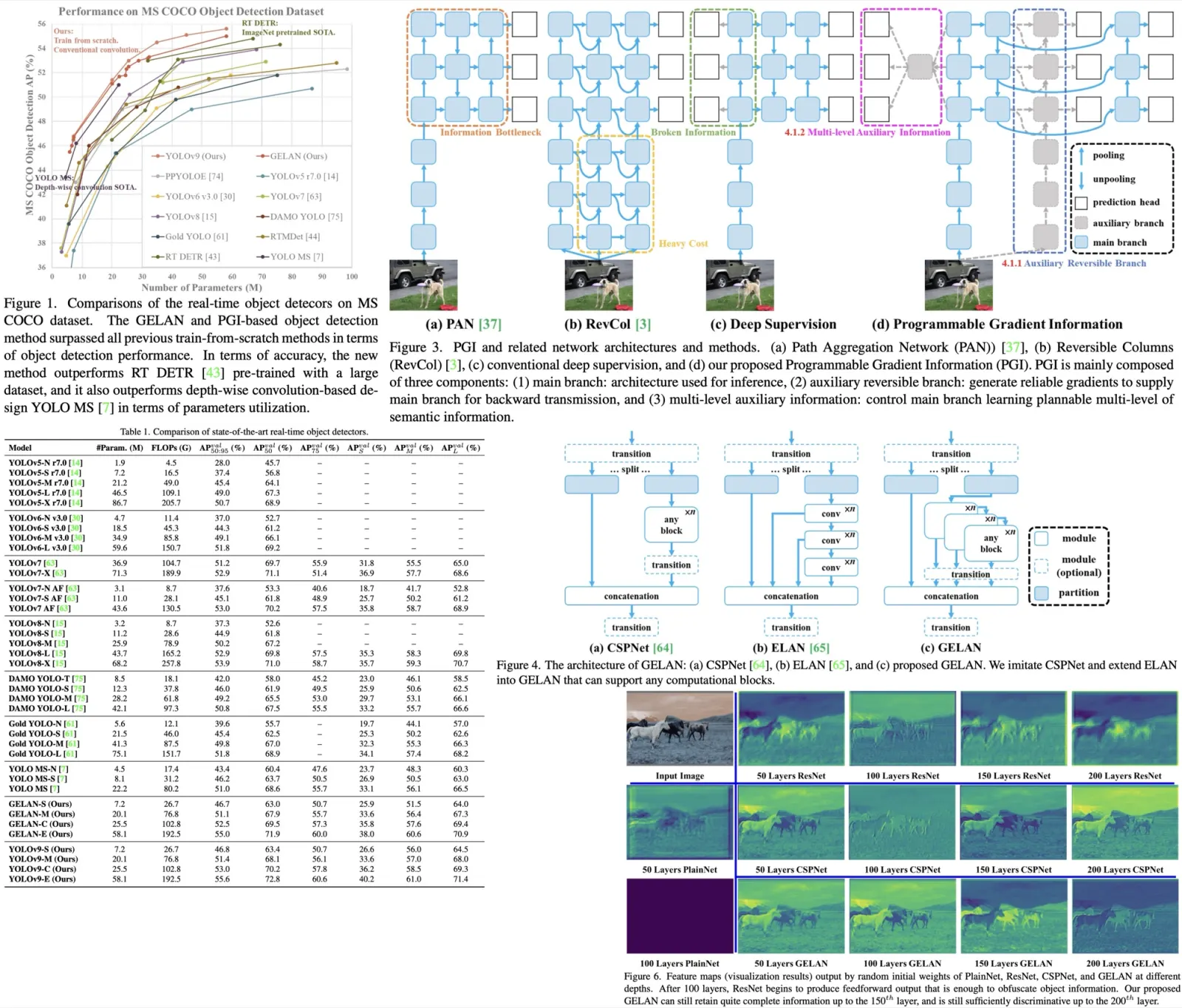
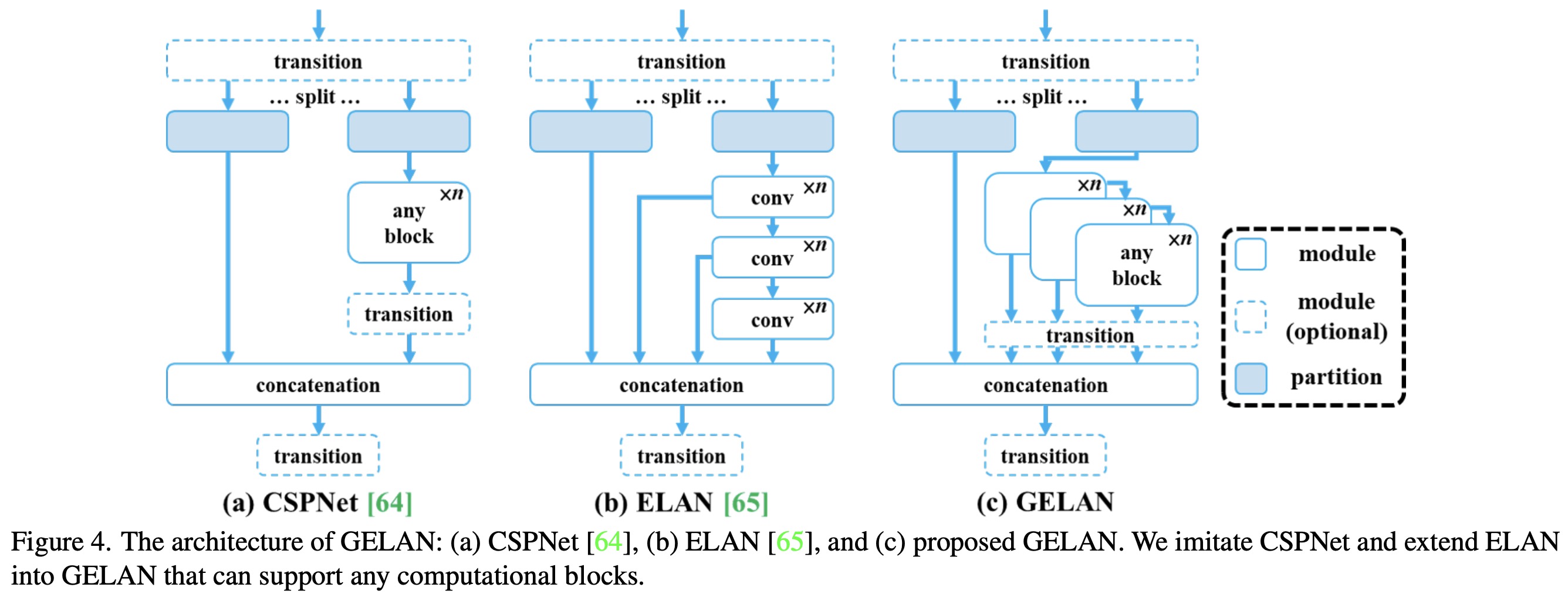
- CSP blocks were identified as particularly effective, enhancing performance with reduced parameters and improved accuracy, leading to their selection for GELAN in YOLOv9.
- GELAN’s performance is not highly sensitive to block depth, allowing for flexible architecture design without compromising stability.
- Applying PGI’s auxiliary supervision to deep supervision concepts demonstrated significant improvements, particularly in deep models.