Paper Review: YOLOX: Exceeding YOLO Series in 2021
This paper presents a new variation of YOLO - YOLOX. Now it is anchor-free, has a decoupled head, and uses the leading label assignment strategy SimOTA.
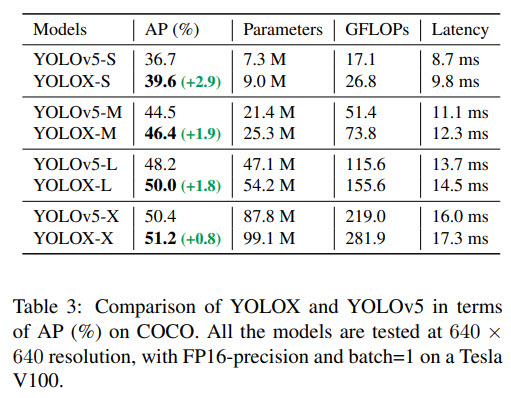
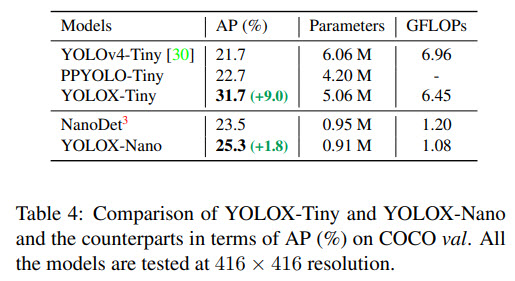
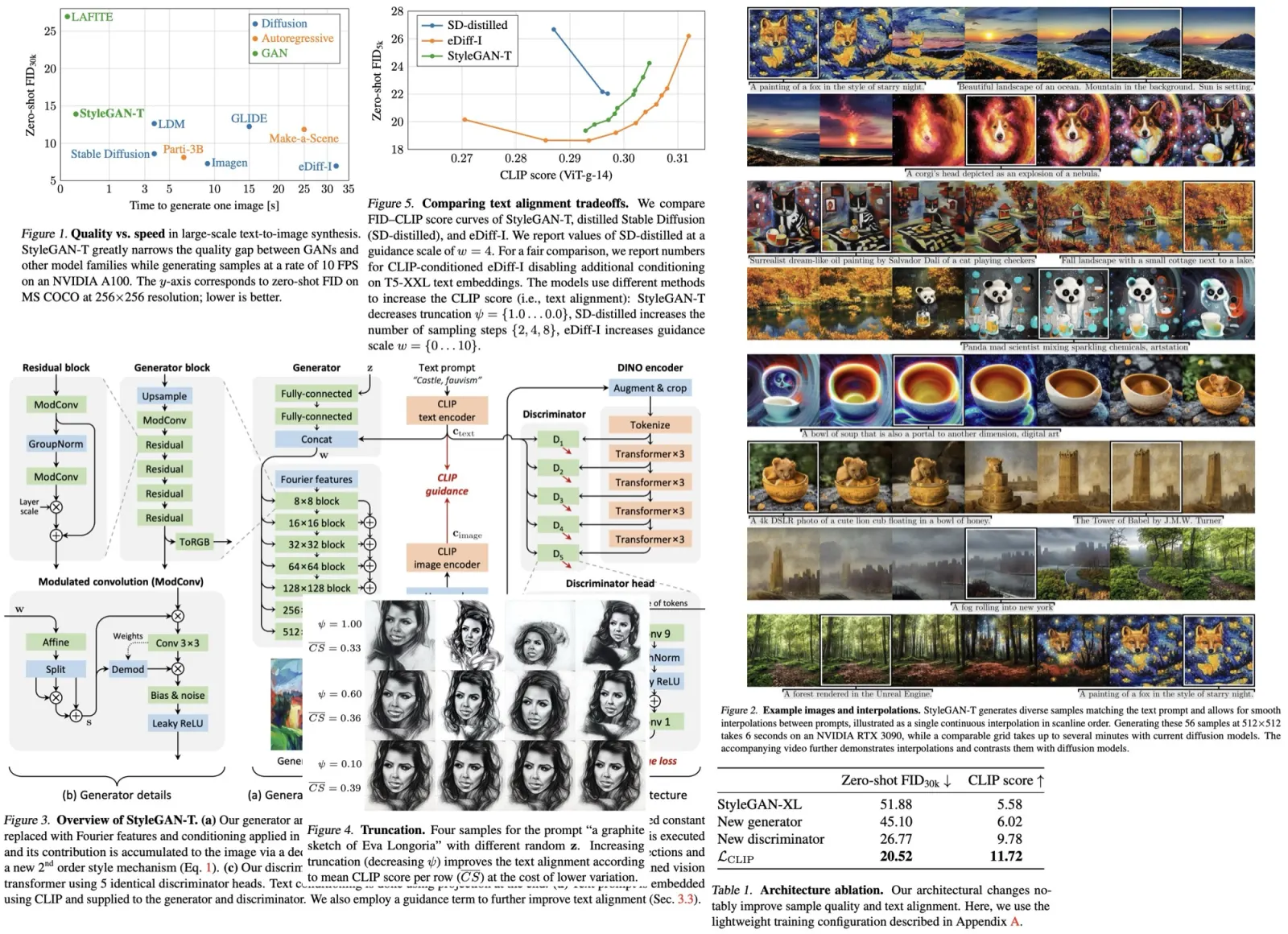
Thanks to these changes, it reaches state-of-the-art results both for small and big models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
YOLOX-DarkNet53
The baseline of the approach is YOLOv3 with Darknet53 as a baseline.
The training
- 300 epochs, 5 epochs warmup, SGD;
- lr is 0.01 * batch size (128) / 64, cosine scheduler;
- the input size is evenly drawn from 448 to 832 with 32 strides;
- EMA weight updating;
- BCE loss for cls and object branch, IoU for reg branch;
- RandomHorizontalFlip, ColorJitter and multi-scale for data augmentation;
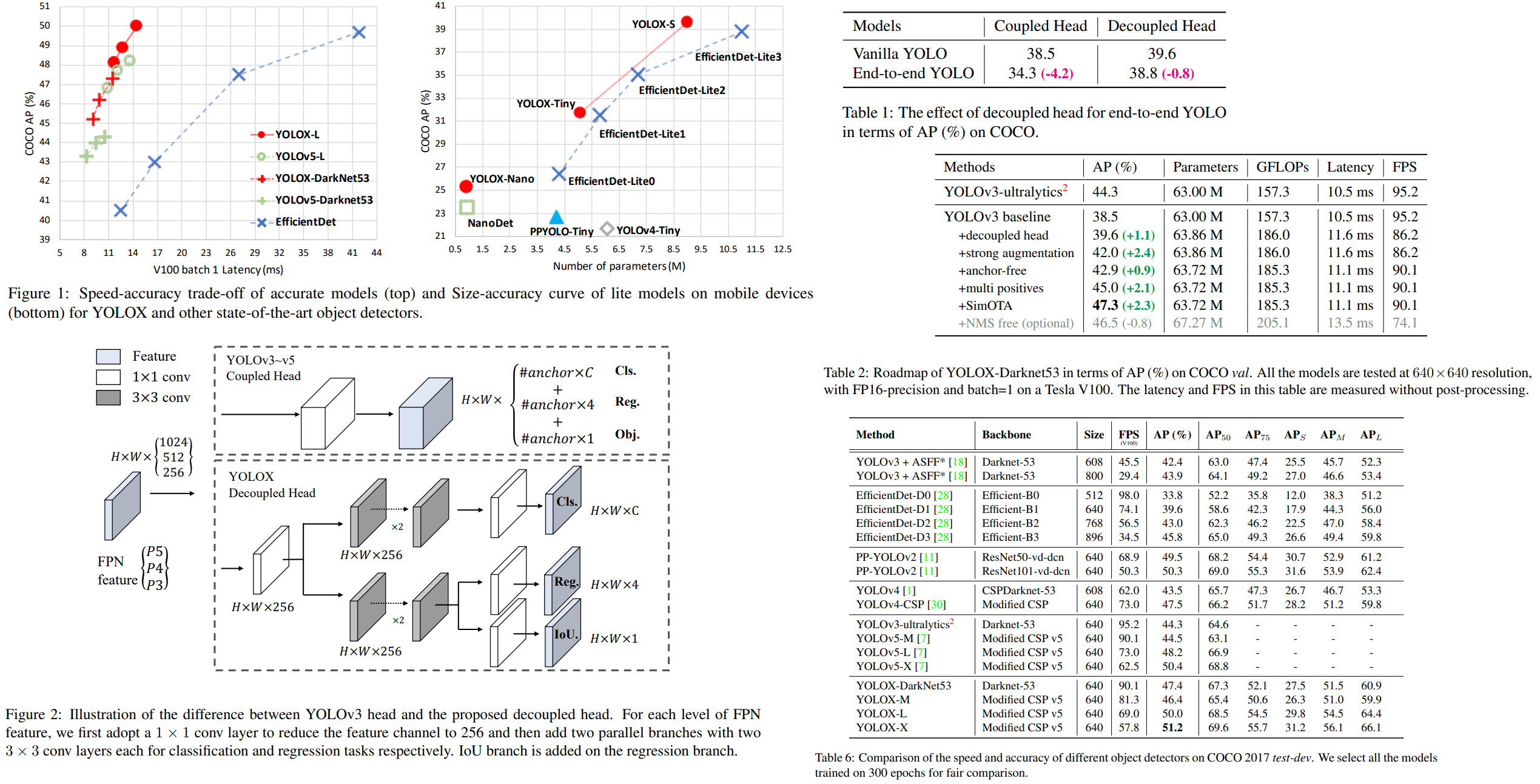
Decoupled head
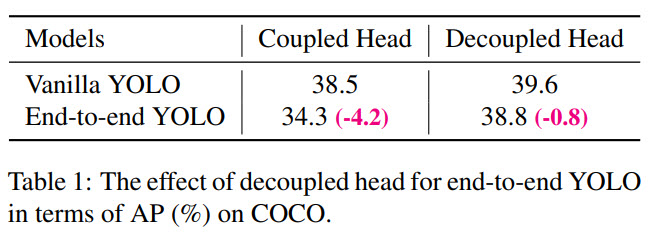
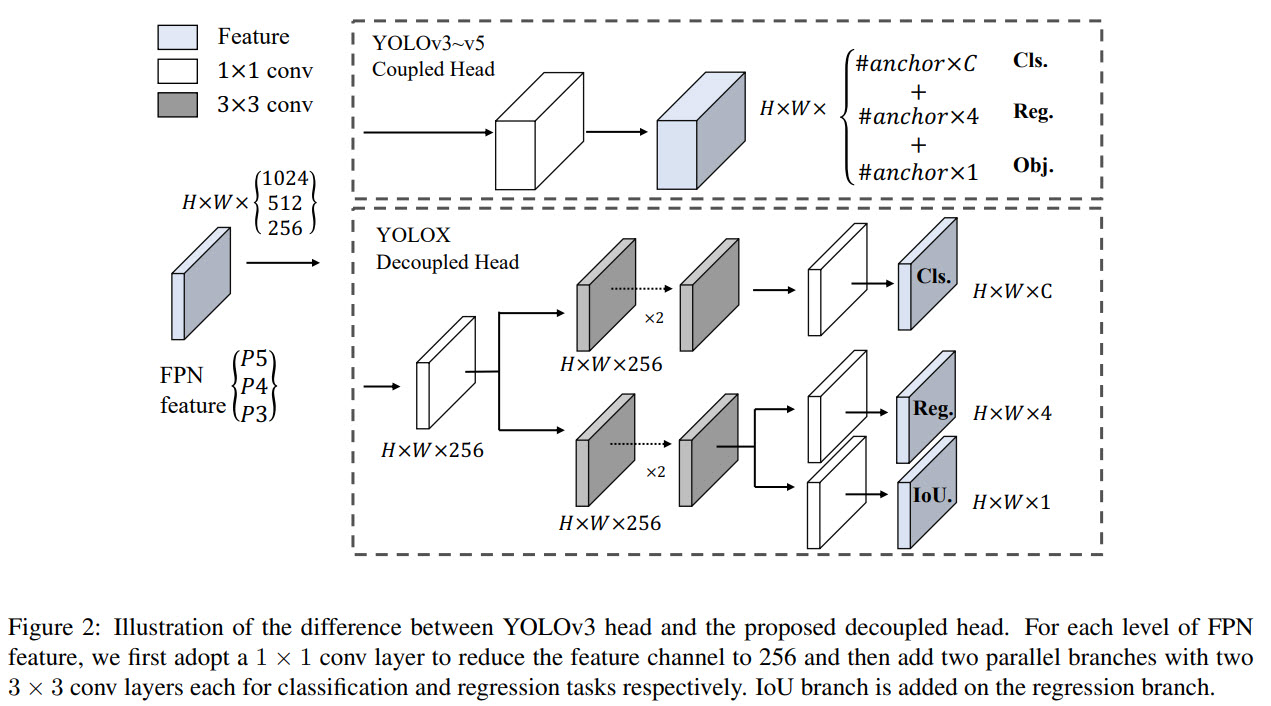
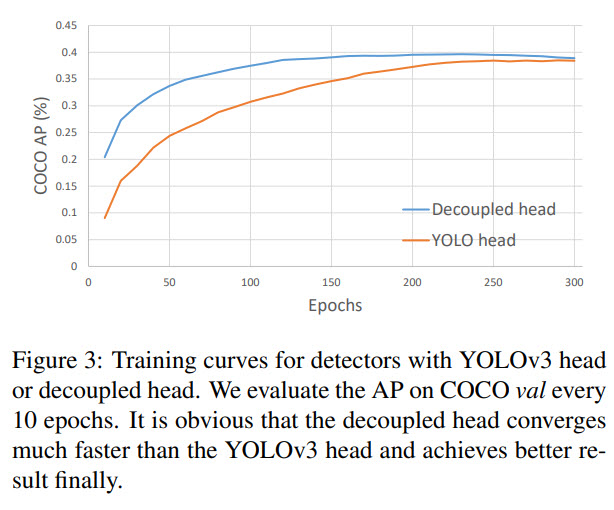
Many object detecting architectures have already started using a decoupled head (separating classification and regression), but YOLO hasn’t adopted this approach yet.
The authors think it is worth using a decoupled head for YOLO architecture: it greatly improves the converging speed and is essential to end-to-end training.
The new lite detection head has a 1 x 1 convolutional layer to reduce the channel dimension and then two parallel branches with two 3 x 3 convolutional layers, respectively.
Data Augmentation
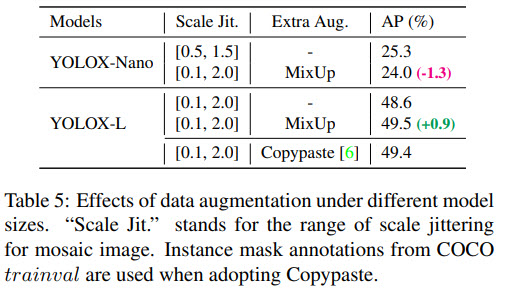
They use Mosaic (from ultralytics-YOLOv3) and MixUp. With these augmentations it is worth training the models from scratch - the ImageNet pre-training is no more beneficial!
Anchor-free and multi-positives
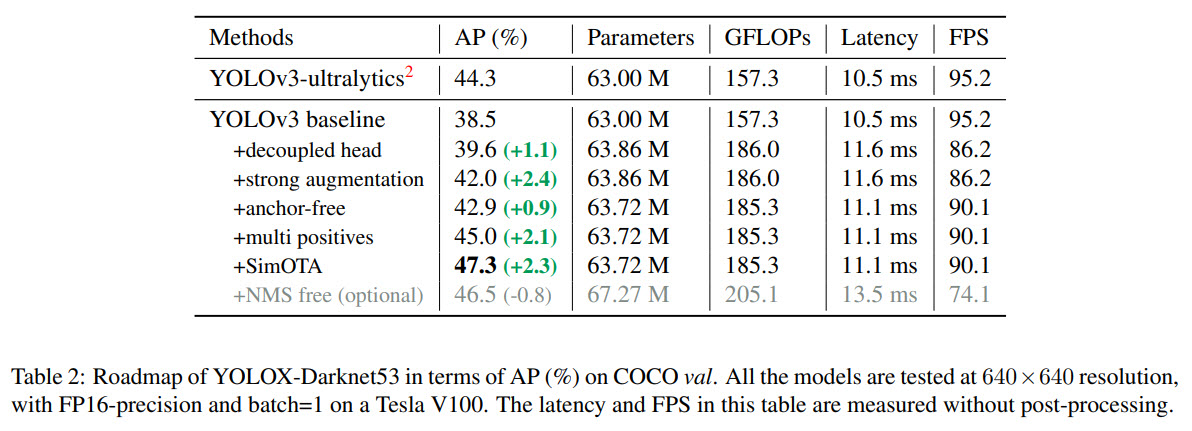
Both YOLOv4 and YOLOv5 use anchors. However, there are disadvantages of using this approach: it is necessary to use clustering analysis to find the set of optimal anchors before training, and these anchors aren’t generalized well. More than this, anchors cause the detection heads to be heavier and make more predictions per image, thus harming the performance on edge AI systems.
Anchor-free detectors can achieve similar performance and, at the same time, have fewer parameters and make the training and decoding simpler.
To make YOLO anchor-free, the authors make the following changes: they make 1 prediction for each location (instead of 3), the model predicts the top-left corner of the grid and the height and the width of the box. The center location of each object is a positive sample. They also pre-define a scale range to designate the FPN level for each object.
As there is only one positive sample for each object, we face a severe disbalance. To alleviate it, the center area of 3 x 3 is assigned as positives (center sampling).
SimOTA
Advanced label assigning approaches are important for the success of the object detection model. The authors think it should follow these rules: loss/quality aware, center prior, dynamic number of positive anchors for each ground-truth (abbreviated as dynamic top-k), global view.
OTA (Optimal Transport Assignment) meets these rules, so the authors choose it. OTA analyzes the label assignment from a global perspective and formulates the assigning procedure as an Optimal Transport (OT) problem, producing the SOTA performance. Solve OT problem via Sinkhorn-Knopp algorithm adds 25% extra training time. Therefore, the authors simplify it to dynamic top-k strategy, named SimOTA, to get an approximate solution.
SimOTA first calculates a pair-wise matching degree for each prediction-gt pair. Then, for gt, we select the top k predictions with the least cost within a fixed center region as its positive samples. Finally, the corresponding grids of those positive predictions are assigned as positives, while the rest grids are negatives.
SimOTA not only reduces the training time but also avoids additional solver hyperparameters in Sinkhorn-Knopp algorithm.
End-to-end YOLO
Adding two additional convolutional layers, one-to-one label assignment and stop gradient (stop the gradient relevant to the attached PSS head passing to the original FCOS network parameters) enables the detector to perform an end-to and manner, though slightly decreasing the performance and the inference speed.
This module is optional and isn’t used in the final models.
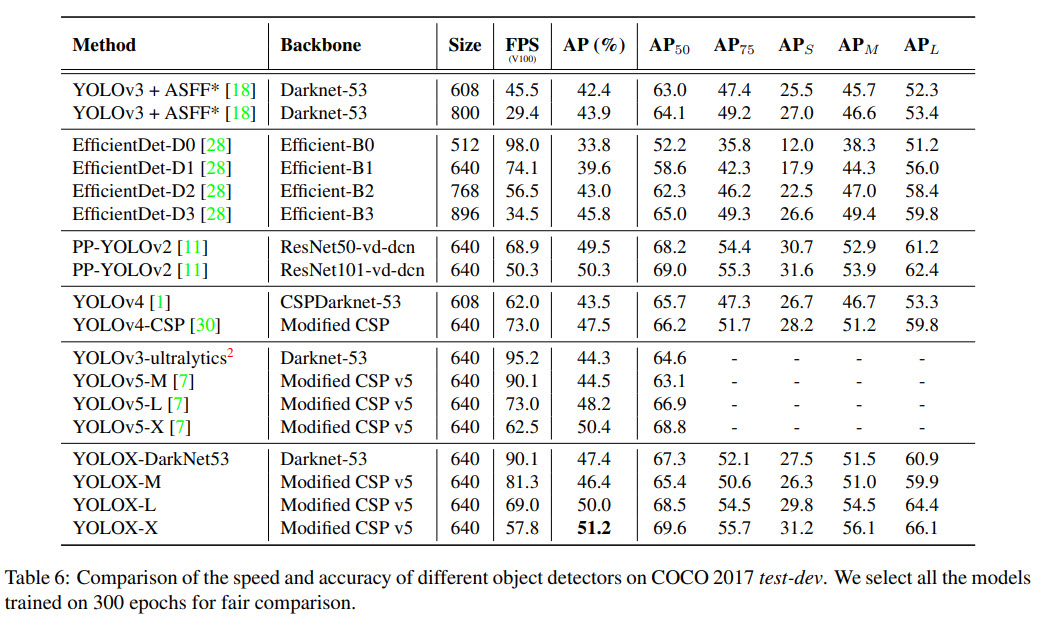
The results