Paper Review: Zephyr: Direct Distillation of LM Alignment

While distilled supervised fine-tuning (dSFT) enhances larger models’ accuracy, they often misinterpret natural prompts. Using preference data from AI Feedback (AIF) and distilled direct preference optimization (dDPO), a chat model called Zephyr-7B is trained. This model sets a new standard in chat benchmarks for 7B parameter models, outperforming Llama2-Chat-70B, and doesn’t require human annotations.
Method
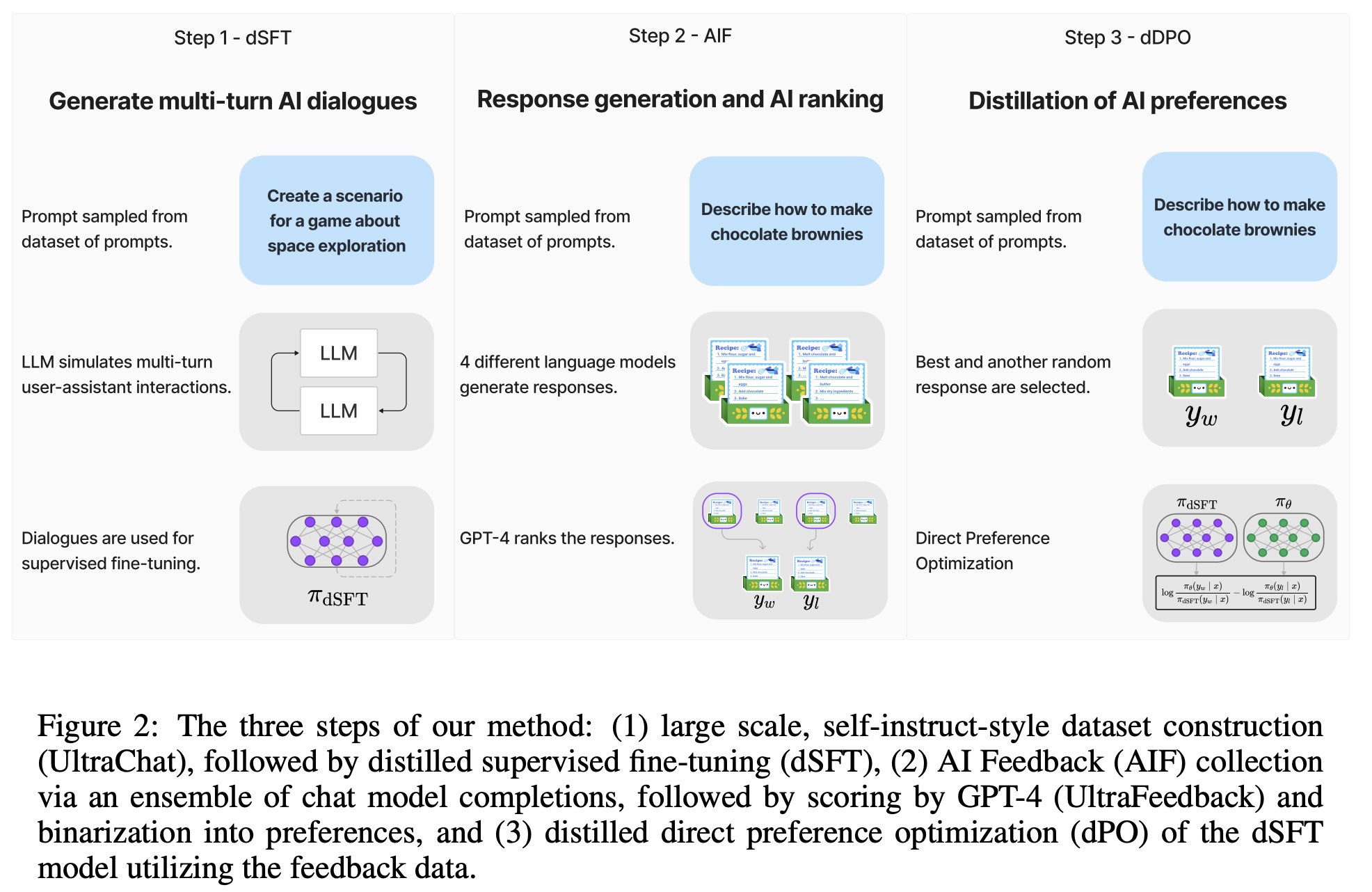
- dSFT: Instead of traditional supervised fine-tuning using high-quality instructions and responses, the teacher model generates them. Using the self-instruct protocol, a dataset is created through iterative self-prompting, where the teacher model responds and refines instructions. The resulting dataset is then used for distillation.
- AIF: Instead of human feedback, AI preferences from the teacher model evaluate outputs from various models. The method follows UltraFeedback, where responses from different models to a set of prompts are scored by the teacher model. The highest scoring and a random lower scoring response are saved, forming a feedback dataset.
- dDPO refines the dSFT model by maximizing the likelihood of ranking preferred outputs using a reward function. The optimal reward function is derived from the original LLM policy and the optimal LLM policy.
The training procedure starts with the dSFT model, iterating through each AIF dataset entry, computing probabilities from both dSFT and dDPO models, and updating based on the computed objective.
Experiments
The authors use Mistral 7B, Transformer Reinforcement Learning library, DeepSpeed ZeRO-3 and FlashAttention-2. The experiments were run on 16 A100 with bfloat16 precision.
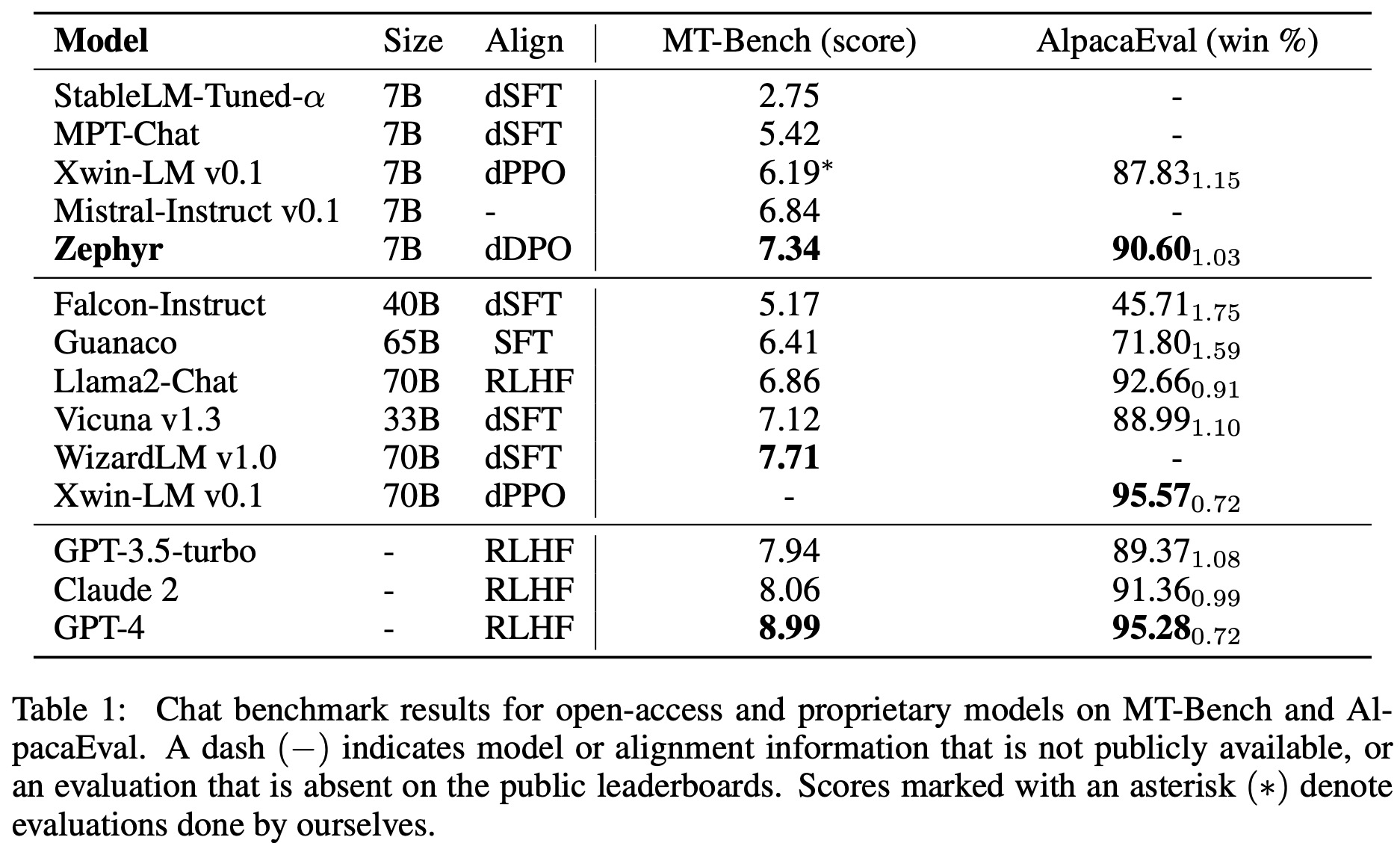
Zephyr-7B sets a new performance benchmark among 7B models, surpassing other open models on MT-Bench and AlpacaEval. Specifically, it outperforms Xwin-LM-7B, trained with distilled PPO. Zephyr-7B is competitive with the larger Llama2-Chat 70B on MT-Bench but falls short when compared to WizardLM-70B and Xwin-LM-70B, suggesting that dDPO might benefit larger models. On AlpacaEval, Zephyr-7B rivals proprietary models like GPT-3.5-turbo and Claude 2, although its performance in math and coding is subpar.
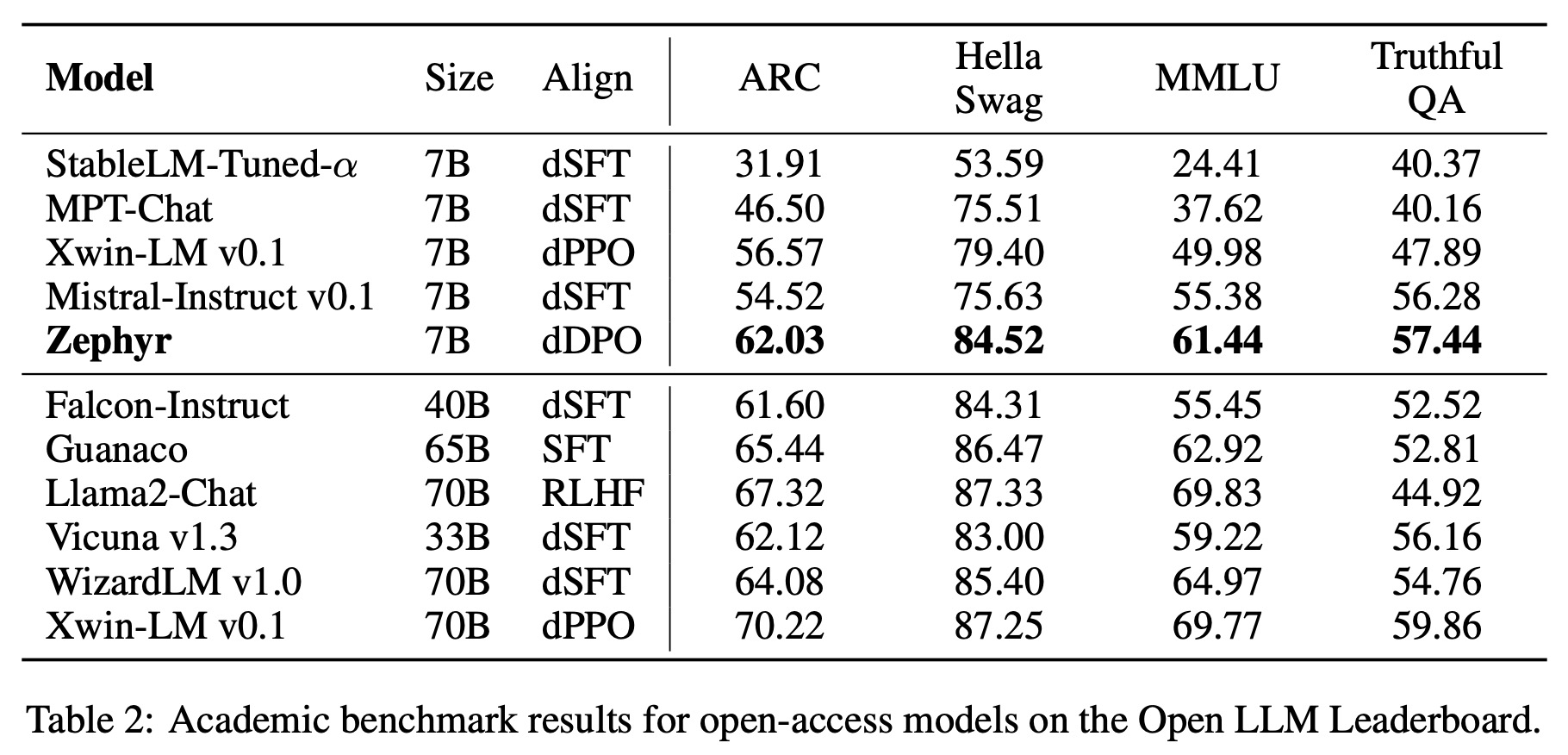
In academic tasks, dDPO-equipped Zephyr excels among 7B models, but larger models still outperform it in knowledge-intensive tasks, with Zephyr matching the performance of 40B scale models.
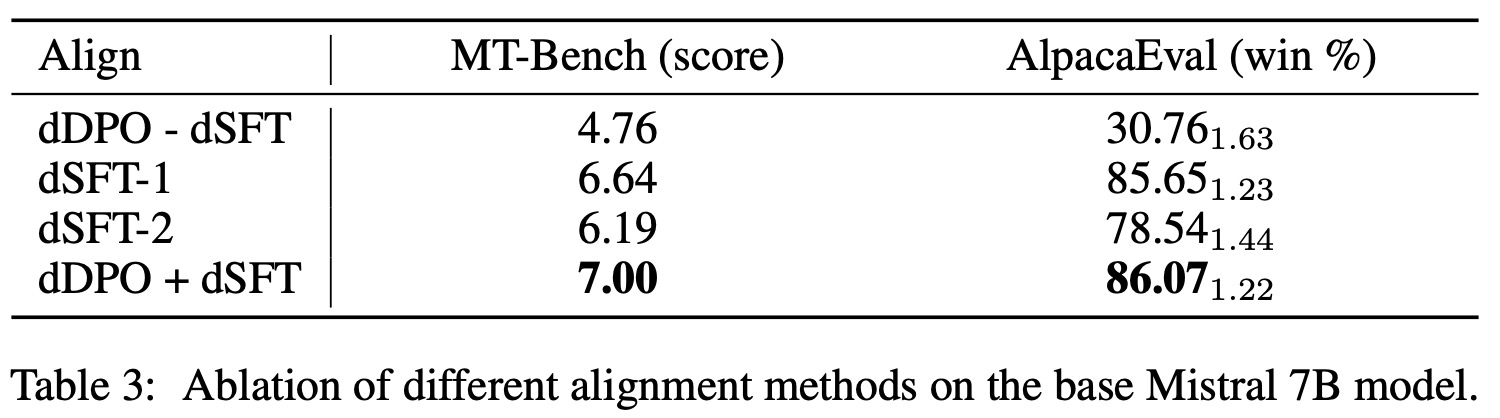
The authors examine the effects of four different alignment processes on the Mistral 7B model:
- dDPO fine-tunes the base model directly with DPO for one epoch on UltraFeedback.
- dSFT-1 uses SFT for one epoch on UltraChat.
- dSFT-2 starts with dSFT-1 and adds another epoch of SFT using top-ranked UltraFeedback completions.
- dDPO + dSFT combines dSFT-1 and one epoch of DPO on UltraFeedback.
Results show that without an initial SFT step, models struggle to learn from feedback. Using dSFT significantly enhances performance. Directly training on preferred feedback output (dSFT-2) doesn’t impact performance. The combined method (dDPO+dSFT) results in a notable performance boost.
Despite Zephyr-7B showing signs of overfitting after one epoch of DPO, it didn’t negatively affect downstream performance. The best model used one epoch of SFT and three of DPO. However, training the SFT model for more than one epoch, followed by DPO, degrades performance with prolonged training.
Limitations
The use of GPT-4 is used as an evaluator for the AlpacaEval and MT-Bench benchmarks, which is known to be biased towards models distilled from it, or those that produce verbose, but potentially incorrect responses. Another limitation is that it is necessary to examine whether the method scales to much larger models like Llama2-70B, where the performance gains are potentially larger.
paperreview deeplearning nlp llm dpo finetuning