

Project description
This is my training pipeline for training neural nets in PyTorch. It is based on PyTorch-lightning as a wrapper over PyTorch code and hydra for managing configuration files. The main concepts of the pipeline are:
- the pipeline consists of several flexible modules, which should be easily replaceable
- all used parameters and modules are defined in configs, which are prepared beforehand
- thanks to the
load_objfunction, it is possible to define classes in configuration files and to load them without writing explicit imports - parameters and modules can be changed through the command line commands using hydra
- the pipeline can be used for different deep learning tasks without changing the main code
Currently supported tasks: image classification, named entity recognition.
Hydra configuration
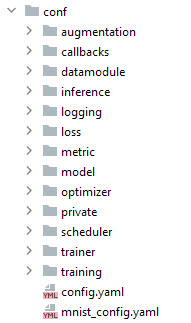
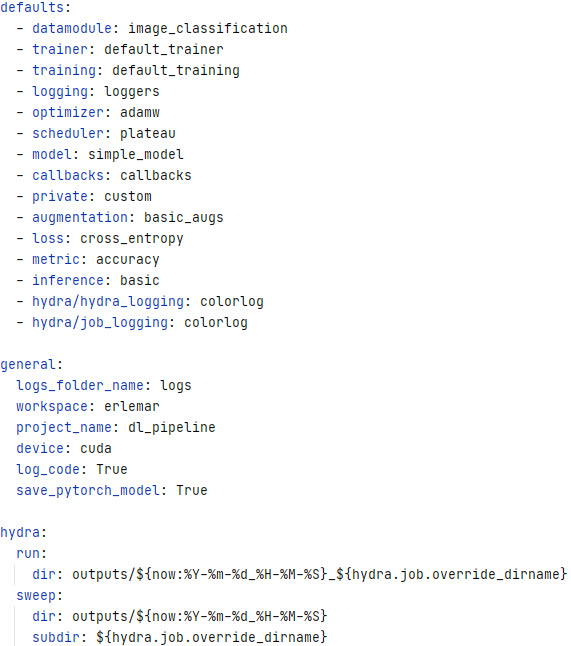
- the folder with hydra configuration files has separate folders for each logical part of the pipeline
- each folder has one or several small configuration files. For example, the
optimizerfolder has configuration files describing different optimizers - main configuration file -
config.yamlhas the definition of default configuration files in each folder as well as general configuration for the project and hydra itself - next, you can see an example of a configuration file for a
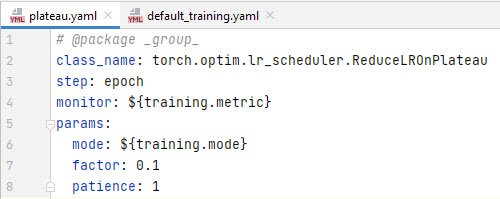
scheduler# @package _group_ class_name: torch.optim.lr_scheduler.ReduceLROnPlateau step: epoch monitor: ${training.metric} params: mode: ${training.mode} factor: 0.1 patience: 1The first line is technical information for Hydra
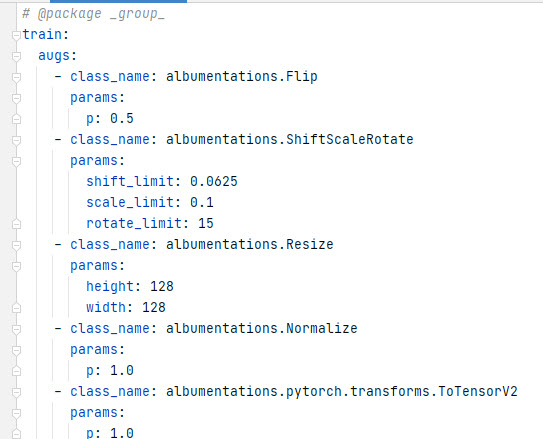
class_name- the full path to the class for import. functionload_objis used in the code to instantiate classes.${training.metric}- this syntax means interpolation; this means that the value is taken from another configuration file. - it is even possible to define augmentations using configuration files.
Running the pipeline
>>> python train.py
>>> python train.py optimizer=sgd
>>> python train.py model=efficientnet_model
>>> python train.py model.encoder.params.arch=resnet34
>>> python train.py datamodule.fold_n=0,1,2 -m
The basic way to run the training pipeline is to run the train.py script.
If we want to change some parameters, we can do it through the command line. It works even if the parameter is deeply nested.
It is also possible to run multiple experiments using -m (multirun). In this case, all combinations of the passed parameters’ values will be used to run the script one after another.
Logging
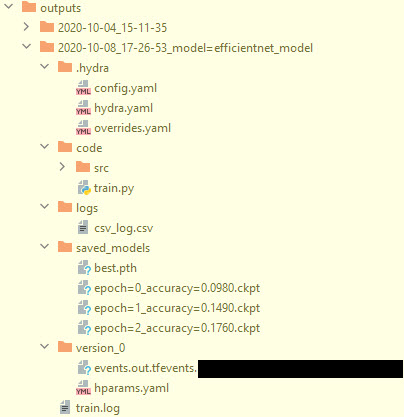
Logging in this pipeline is performed using two approaches.
It is possible to log the experiment into a predefined experiment tracking tool - comet_ml, W&B, and so on.
Also, logging can be done locally:
- a folder with the timestamp is created. Optionally, the name of the folder can show overridden values, but this could cause errors when the path of the folder becomec too long for the OS to process correctly
hydrafolder is created automatically and has the original configuration file, the overridden, and the resulting configuration filecodefolder can copy the code of the project, which could be useful in cases when you change the code rapidly without committing the changeslogsfolder hascsvfile with logssaved_modelshas PyTorch-lightning checkpoints and some other possible artifactsversion_0has tensorboard logs if it is enabled