DeepSeek-V4 Review: Why Million-Token Context Needs Efficient Attention, Not Just Larger Windows
Long-context LLMs usually promise a simple capability: put more tokens into the prompt and let the model reason over them. This works up to a point, but it hides a structural bottleneck: a long context window is only useful if the model can actually afford to attend over it during inference, tool use, and long reasoning trajectories.
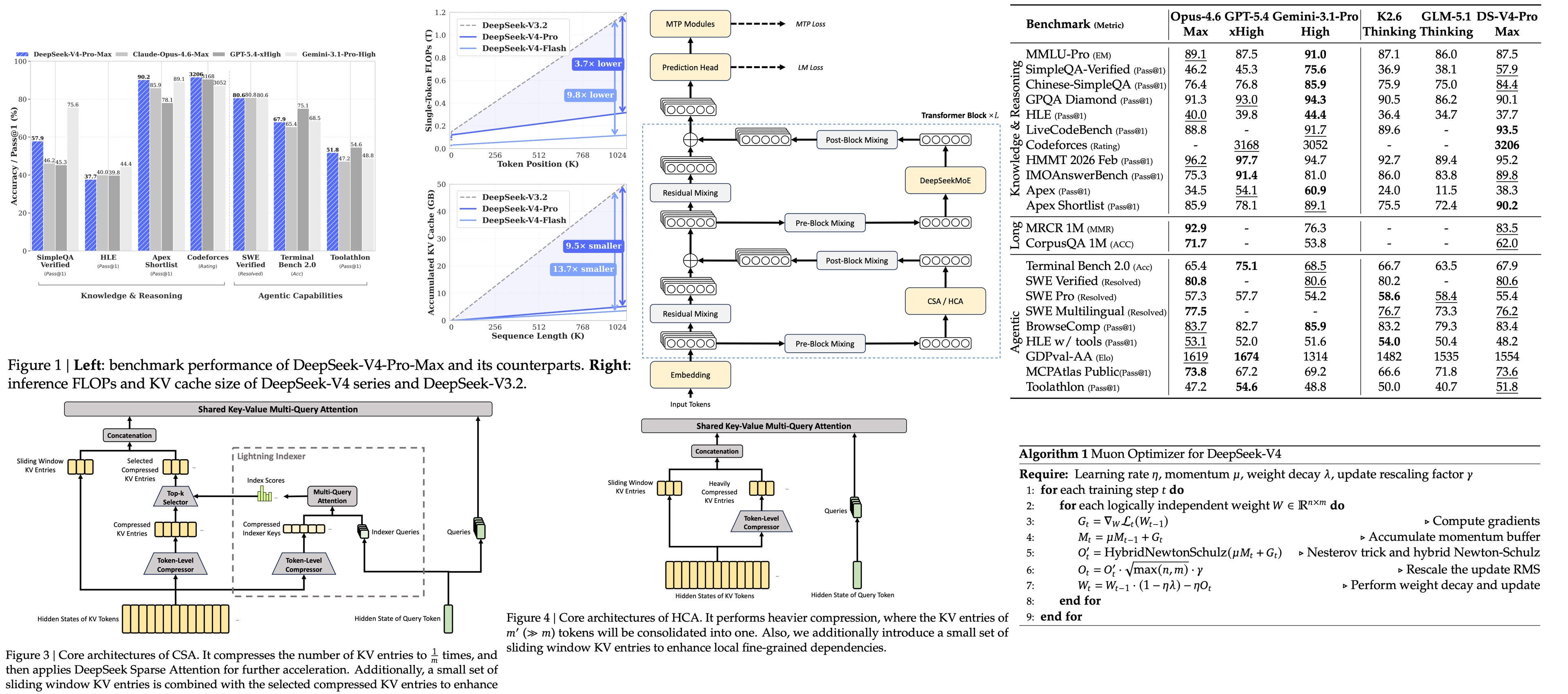
DeepSeek-V4 changes the focus from maximum context length to efficient long-horizon computation. Both available models (V4-Pro with 1.6T total / 49B active parameters and V4-Flash with 284B / 13B active) support 1M-token context windows. The whole architecture is built around making that window usable: hybrid compressed attention (Compressed Sparse, Heavily Compressed, and Sliding Window, interleaved across layers), a scaled MoE with Manifold-Constrained Hyper-Connections, Muon optimizer, reduced KV-cache cost, and a post-training recipe that replaces unified-policy RL with on-policy distillation of independently trained domain specialists
The central claim is that future reasoning and agentic systems will not be limited only by model quality, but also by whether the model can maintain useful state over very long trajectories. DeepSeek-V4 is interesting because it treats long context as an infrastructure problem inside the model itself.
Sparse MoE, mHC, and training stability
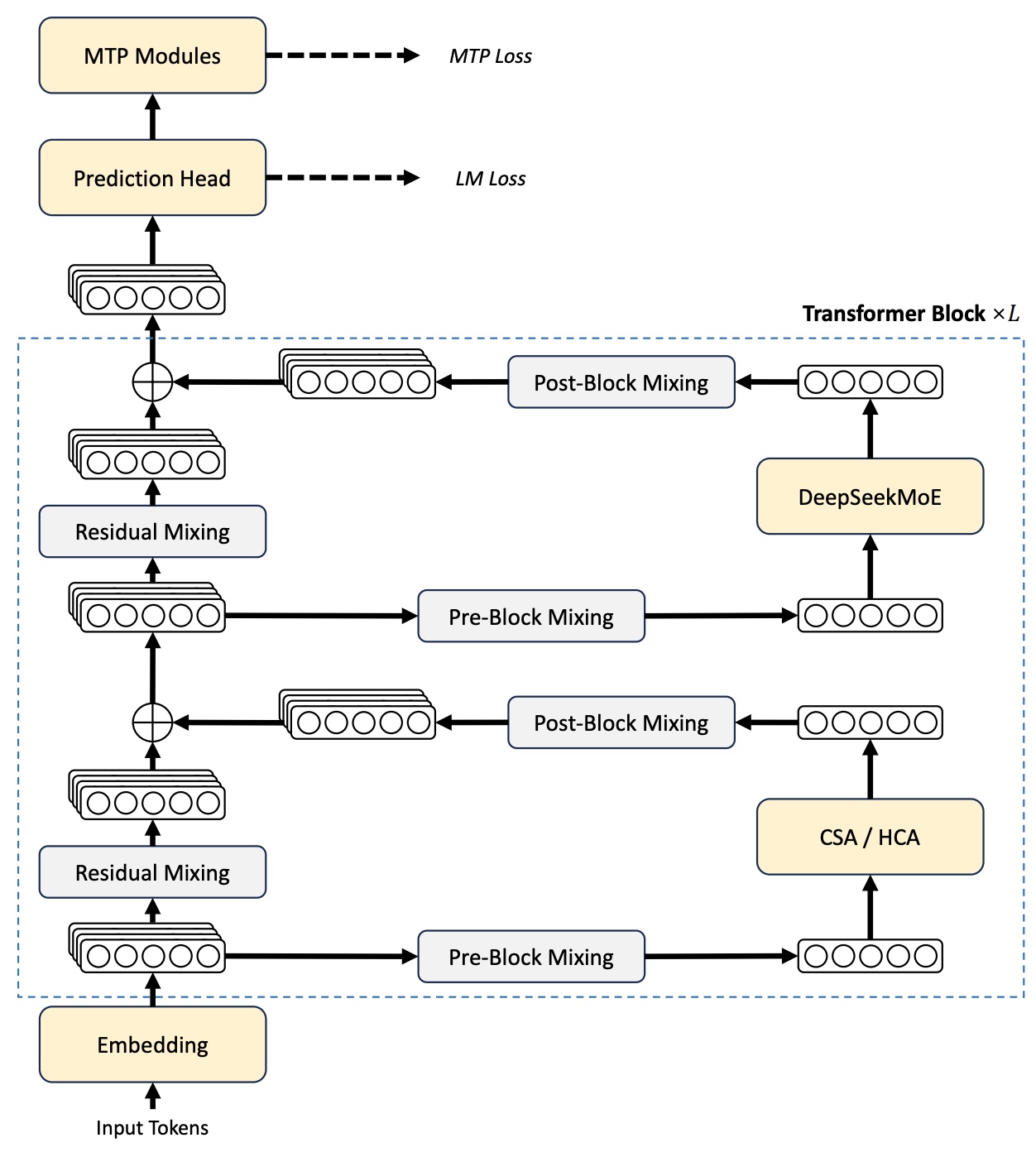
The DeepSeekMoE backbone from V3 scales up: V4-Flash has 256 routed experts + 1 shared, V4-Pro 384 + 1 shared, both activating 6 experts per token. Load balancing uses V3’s auxiliary-loss-free scheme plus a sequence-wise balance loss to prevent pathological routing on individual sequences. DeepSeek-V4 keeps multiple parts of the previous DeepSeek design: DeepSeekMoE for feed-forward layers, Multi-Token Prediction, and the broader MoE approach. The model also replaces dense FFN layers in the early transformer blocks with MoE layers using hash routing, while keeping the MTP strategy from DeepSeek-V3.
V4 integrates mHC directly into the backbone, projecting the residual mixing matrix onto the Birkhoff polytope of doubly stochastic matrices via Sinkhorn–Knopp with ~20 normalization iterations. This keeps the residual connection in the generalized identity regime that plain Hyper-Connections break. V4 is the first frontier-scale deployment of mHC, and the authors report it trains cleanly where unconstrained HC diverges.
Two stability mechanisms get added on top, both mentioned as empirical without theoretical grounding. Anticipatory Routing computes and caches routing indices Δt steps earlier, using historical router parameters, then applies them during the later main training step. SwiGLU Clamping clamps the gate’s linear component to [-10, 10] and caps the gate component above at 10, and reportedly eliminates loss spikes that emerge at trillion-parameter scale.
Hybrid attention
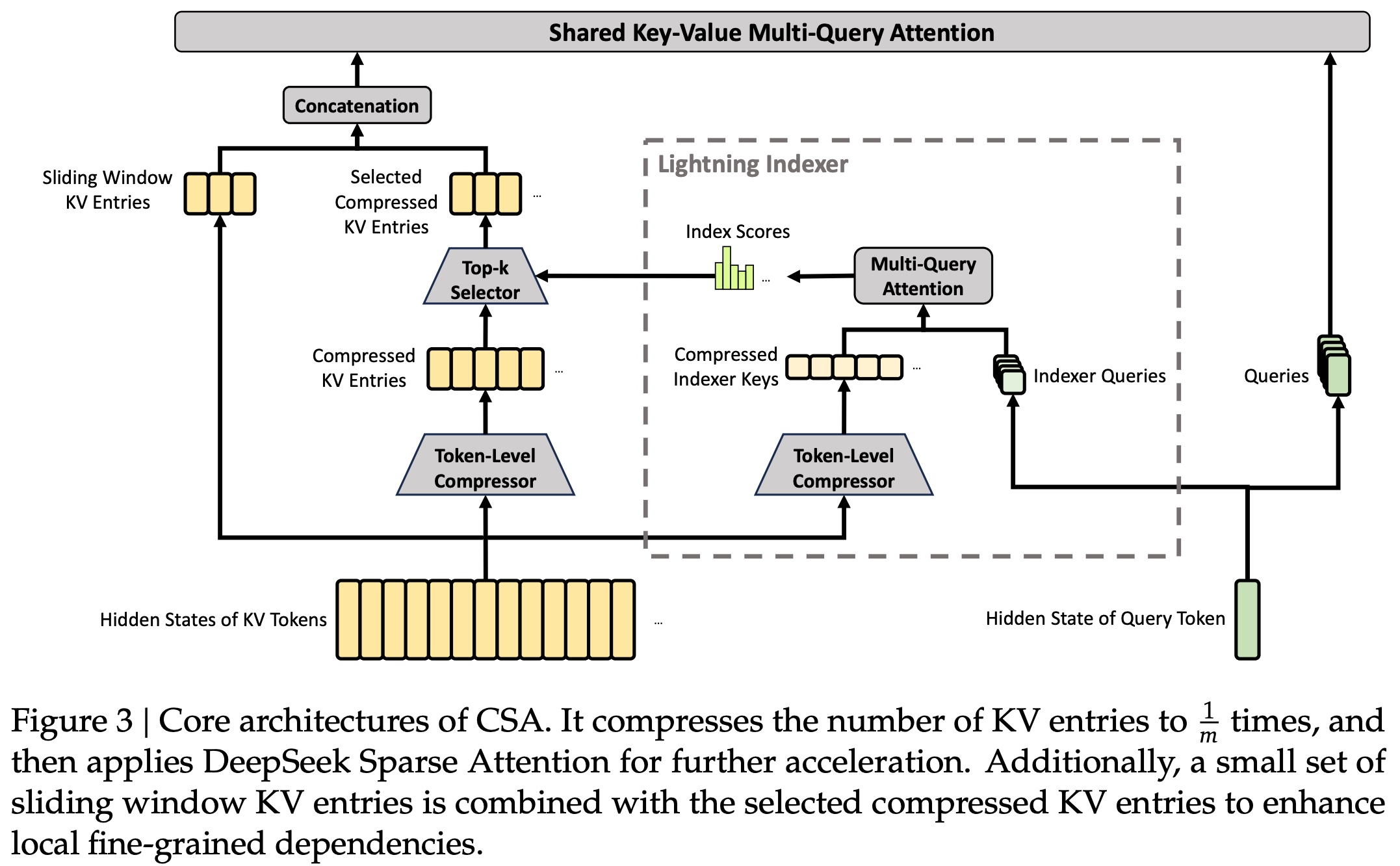
- Compressed Sparse Attention (CSA) first compresses the KV cache along the sequence dimension, then applies DeepSeek Sparse Attention over the compressed representation. Instead of allowing every query to attend densely to the full history, it compresses groups of tokens into fewer KV entries and then selects a limited number of compressed blocks for each query.
- Heavily Compressed Attention (HCA) uses a much larger compression ratio, but removes sparse selection. The compressed sequence becomes short enough that dense attention over compressed blocks is affordable. In other words, CSA preserves more selectivity, while HCA provides an aggressively compressed global view.
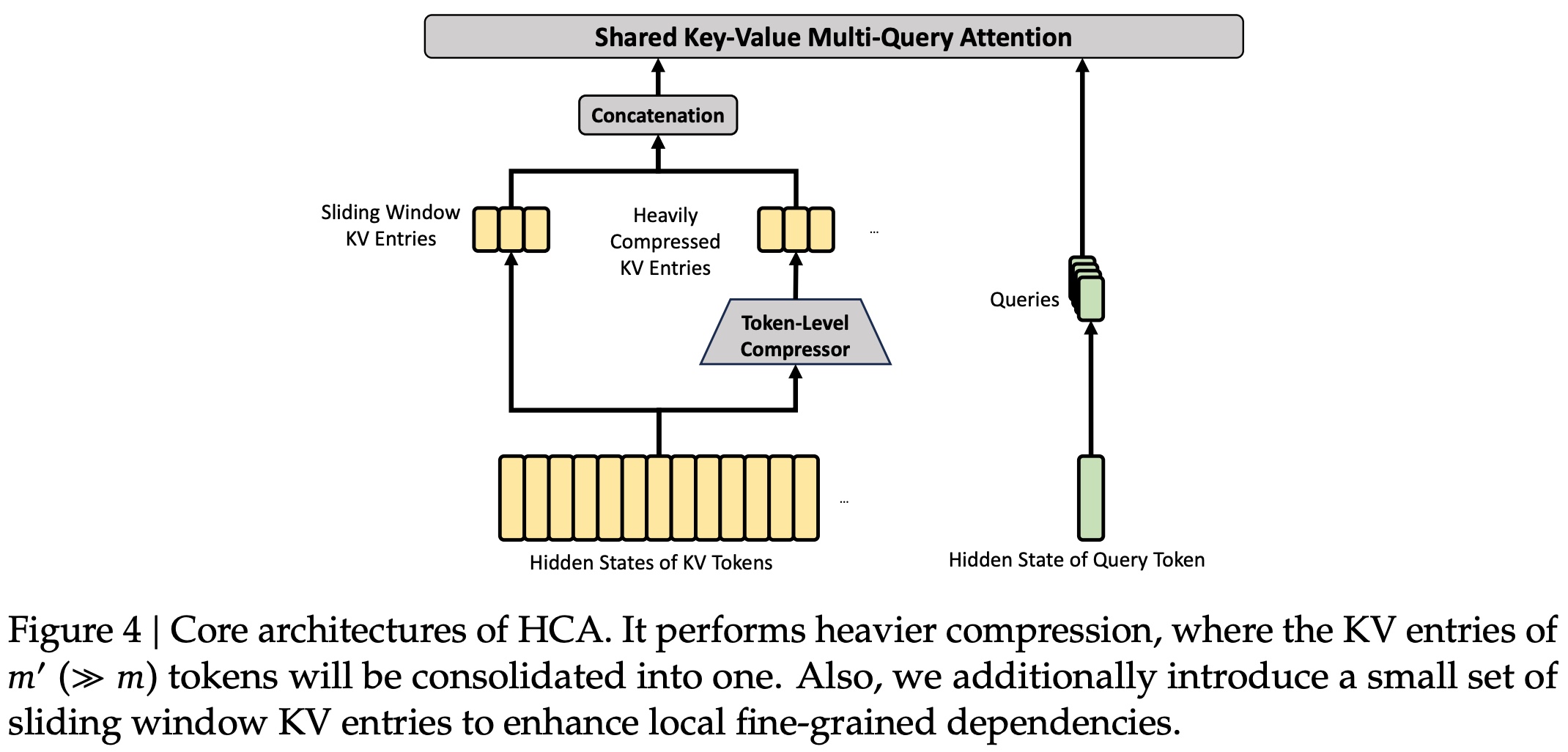
- Attention sinks add learnable sink logits to the attention denominator in CSA and HCA. This means each query head does not have to distribute all attention mass over previous tokens or compressed blocks: the total attention assigned to actual context can be less than 1, and even close to 0. This is useful in long-context attention because not every query should be forced to attend to some distant or weakly relevant context block.
Systems and precision

Pretraining uses Muon as the main optimizer (AdamW on embeddings, prediction heads, and RMSNorm weights) across 32T tokens for Flash and 33T for Pro. Sequence length is ramped 4K → 16K with dense attention; the sparse-attention path is switched on at a 64K stage. The query-key indexer path is quantized FP32 → BF16 for a 2× speedup with 99.7% recall on the top-k set.
Compared with DeepSeek-V3.2, DeepSeek-V4-Pro uses only 27% of the single-token inference FLOPs and 10% of the KV cache size at one million tokens. DeepSeek-V4-Flash reduces this further to 10% of the FLOPs and 7% of the KV cache size.
In DeepSeek-V3.2, reasoning traces were preserved across tool-result rounds but discarded when a new user message arrived. DeepSeek-V4 changes this for tool-calling scenarios. If the conversation contains tool calls, the reasoning content is preserved across the entire conversation, including across user message boundaries. A long-running coding agent needs to remember why it changed a file, which tests failed, which hypotheses were rejected, and what the next step should be.
The authors introduce Quick Instruction tokens for auxiliary tasks such as deciding whether to trigger search or recognizing intent. Instead of using a separate small model that requires redundant prefilling, these special tokens reuse the already-computed KV cache. The point is not just model quality; it is reducing orchestration overhead around the model.
Post-training: On-Policy Distillation and Generative Reward Models
The post-training recipe diverges from V3 and DeepSeek-R1. R1 ran GRPO on a single unified policy with rule-based rewards; V4 instead trains N domain specialists independently (math, competitive coding, agent use, instruction following, and others), each with its own RL loop on high-quality in-domain data. The merge happens via On-Policy Distillation (OPD): a weighted sum of full-vocabulary KL divergences from each specialist’s output distribution into a single student policy, with the student trained on its own on-policy rollouts.
The KL is computed over the full vocabulary rather than a token-level estimate, stabilizing gradients when specialists disagree. The per-specialist weighting is tunable, which means specialists explore different regions of behavior, and the final model learns how to absorb their distributions in contexts generated by itself.
This is why DeepSeek-V4 supports multiple reasoning-effort modes: the model is trained to operate under different inference budgets.
For hard-to-verify tasks, V4 also moves away from conventional scalar reward models. The authors use rubric-guided RL data and a Generative Reward Model, where the actor itself functions as the evaluator. This is less clean than rule-based verification, but it gives them a way to apply RL to tasks where correctness cannot be reduced to tests or exact answers.
Experiments
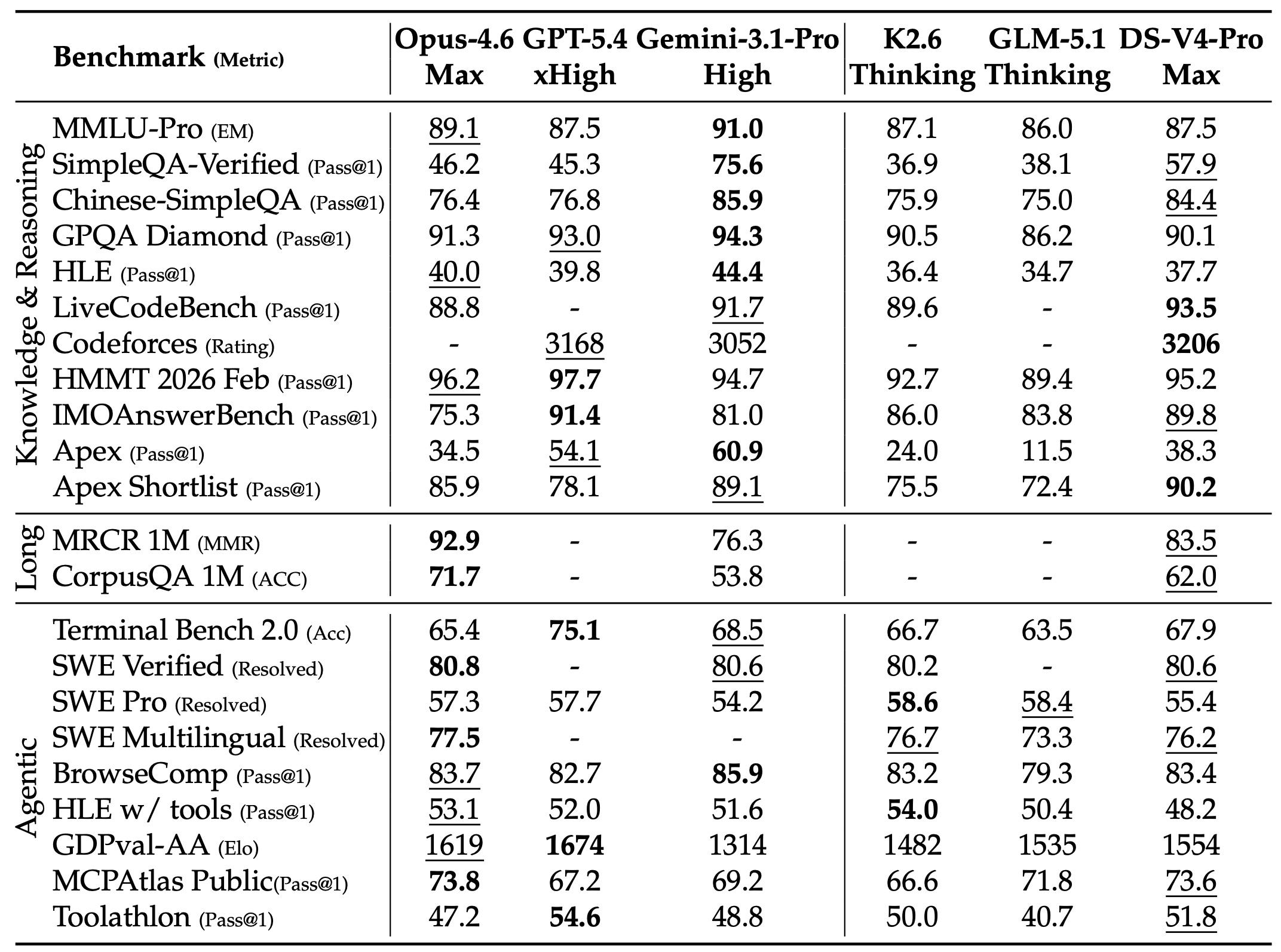
For base models, DeepSeek-V4-Pro-Base improves over DeepSeek-V3.2-Base across many knowledge, reasoning, coding, and long-context benchmarks. For long context, the MRCR results show stable retrieval up to 128K tokens, with degradation beyond that point but still meaningful performance at one million tokens. DeepSeek-V4-Pro-Max reports 0.59 average MMR on MRCR 8-needle at 1M tokens, while V4-Flash-Max reports 0.49.
Overall, the authors claim reaching open-source SOTA in agentic coding, strong world knowledge among open models, and reasoning performance that rivals top closed models.
Some evaluations are blank because APIs were too busy to return responses, and GPT-5.4 was not evaluated on some long-context tasks because its API failed to respond to many queries.
Limitations
The model is released as a preview. The technical report is detailed, but many practical questions will only be answered by external usage: how stable the one-million-token context is across real agent traces, how often compression loses critical details, and how well the tool-use thinking path generalizes outside DeepSeek’s own harness.
Second, the evaluations are strong but not fully independent. Several evaluations use internal frameworks, internal tasks, or vendor-controlled harnesses. This is normal for frontier model reports, but it means the most useful evidence will come from external SWE-bench-style, terminal, retrieval, and long-context evaluations.
Conclusions
V4 is the first DeepSeek release where the architectural part is more interesting than the RL one. Hybrid compressed attention makes 1M context servable at a fraction of V3.2’s cost, and on-policy distillation of independent domain specialists replaces the unified GRPO pipeline from DeepSeek-R1 with a compositional alternative. R1 showed that RL on a base model can elicit reasoning; V4 now claims that decomposing into specialists and merging via full-vocabulary KL is better than holding every skill in one policy. Compared to Kimi K2.5, V4 and Kimi K2.5 focus on different bottlenecks: K2.5 on native multimodality and learned agent orchestration, V4 on sparse attention and compositional post-training.
Instead of treating context length as a static model property, DeepSeek-V4 treats it as part of the runtime system for reasoning and tool use. This is the right direction. Long-horizon agents will not work just because models become smarter. They need memory that is cheap enough to keep, structured enough to retrieve from, and stable enough to support many steps of reasoning.
I like that the paper is honest about what is still open. The stability tricks are empirical without theory. Opus 4.6 retains a 13-point lead on internal R&D coding, and long-context performance degrades gradually rather than staying flat at 1M.
paperreview deeplearning llm moe rl nlp