Paper Review: Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities

Audio Flamingo 2 is an Audio-Language Model with advanced audio understanding and reasoning capabilities. AF2 achieves state-of-the-art performance with a compact 3B parameter model, surpassing larger open-source and proprietary models across 20+ benchmarks. Key components include a custom CLAP model, synthetic Audio QA data, and a multi-stage curriculum learning strategy. AF2 extends audio understanding to long segments (30 secs to 5 mins) and introduces LongAudio, a dataset for long audio captioning and question-answering, as well as LongAudioBench, an expert-annotated benchmark for long-audio understanding.
The architecture

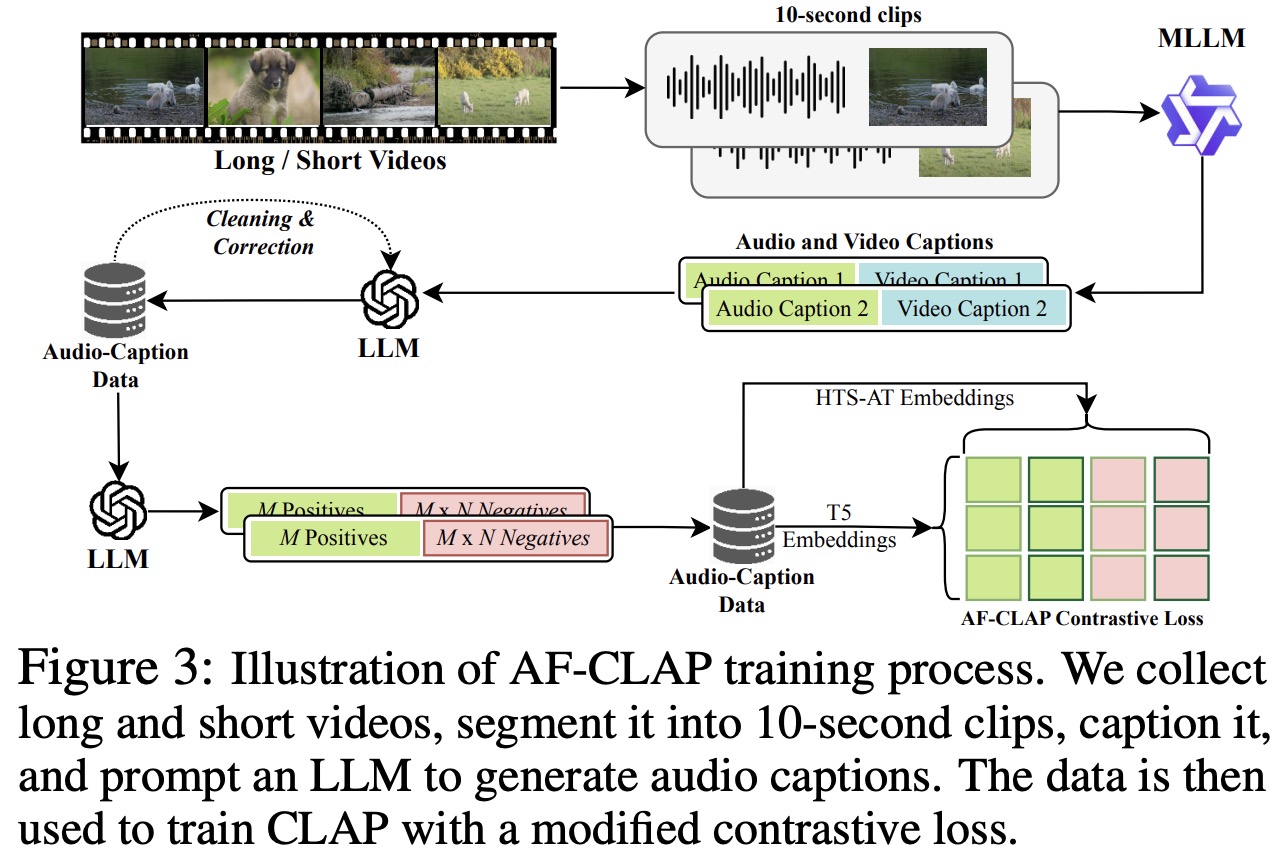
AF-CLAP is an improved version of the CLAP audio encoder, designed to enhance linguistic robustness and compositional reasoning in Audio-Language Models. Standard CLAP models struggle with limited high-quality training data and inconsistencies in linguistic variations and sound relationships. AF-CLAP addresses these issues through:

- Expanded Training Dataset: over 8M high-quality audio-caption pairs collected from open-source long-video datasets and short audios. Automated captioning with GPT-4o generates 5.5M new pairs, ensuring greater diversity and domain coverage.
- Enhanced Training Objective – improves linguistic invariance by generating multiple semantically identical captions and enhances compositional reasoning using composition-aware negatives to capture relationships between sound events.
- Contrastive Learning with Hard Negatives – incorporates M positive and M x N negative samples in each batch to improve alignment between text and audio embeddings.
AF2 extracts dense audio features from the penultimate layer of AF-CLAP, generating higher-quality representations compared to mean pooling. For longer audio, a non-overlapping sliding window approach is used, with RoPE encoding to encode temporal information.
To enhance model capacity, AF2 applies three self-attention layers. Gated cross-attention layers condition audio representations on the LLM, reducing quadratic attention complexity to linear complexity.
AF2 uses Qwen2.5-3B as a base model.
Training data
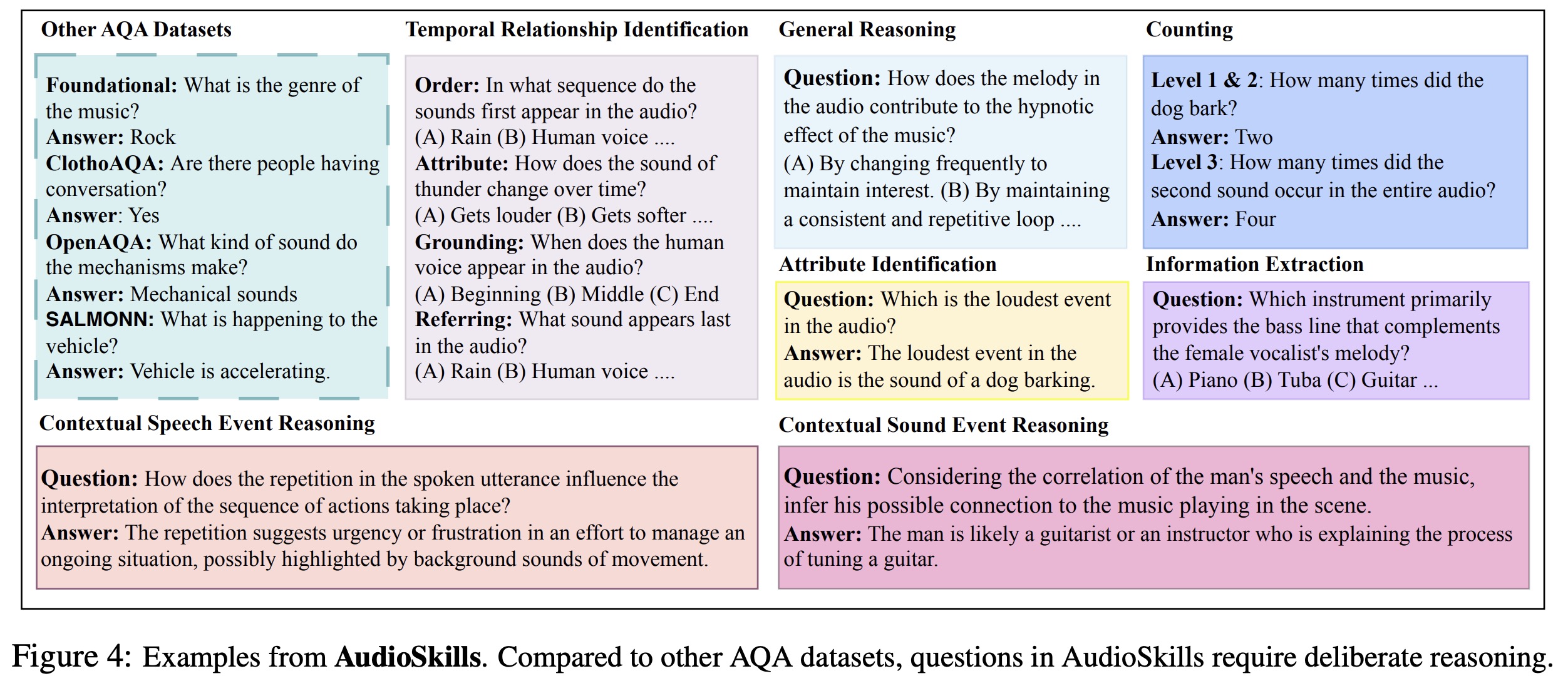
AudioSkills is a synthetic audio reasoning dataset designed to enhance problem-solving and reasoning abilities beyond basic acoustic event classification. It includes ~4.2M QA pairs generated from open-source sound and music datasets, synthetic audio, and GPT-4o-generated metadata.
The dataset covers seven key reasoning skills:
- Temporal Reasoning: understanding event order, attribute changes, and temporal grounding in audio.
- Attribute Identification: recognizing sound characteristics, such as intensity or speaker gender.
- Counting: determining the number of sound occurrences across three difficulty levels.
- Contextual Sound Event Reasoning: identifying the purpose of sounds based on their context.
- Contextual Speech Event Reasoning: understanding spoken utterances in relation to surrounding sounds.
- Information Extraction: analyzing detailed content and external world knowledge in audio.
- General Reasoning: addressing complex scenarios requiring multiple reasoning skills.

LongAudio is the first large-scale long audio understanding dataset; it has 80K+ unique audios and 263K AQA pairs. To ensure diversity, videos are clustered and selectively sampled, with captions generated using Qwen2-VL-2B-Instruct and Qwen2-Audio, while GPT-4o creates reasoning-based questions.
LongAudioBench is a high-quality benchmark subset; it consists of 2429 human-verified instances sampled from LongAudio. GPT-4o is used as a judge for evaluation, scoring responses from 1 to 10 based on correctness.
Training strategy
AF2 is trained using a 3-stage curriculum learning strategy, progressively increasing audio context length and data quality:
- Pre-training aligns audio representations with the LLM using large-scale, noisy classification and captioning datasets with some high-quality QA data. CLAP and LLM layers are frozen, only audio representation transformation and gated cross-attention layers are trained. The audio context is 30 seconds.
- Fine-tuning (instruction-tuning) enhances audio understanding and reasoning using high-quality short-audio classification, captioning, and QA datasets. LLM layers are frozen, but CLAP, audio representation transformation, and gated cross-attention layers are trained. The audio context is 1.5 minutes.
- Long Fine-tuning extends context length and trains long-audio reasoning skills using LongAudio dataset. Only audio transformation and gated cross-attention layers are trainable. The audio context is 5 minutes.
Experiments
The model is trained using 128 NVIDIA A100 80GB GPUs.

AF2 outperforms larger models despite having a smaller 3B LLM, excelling in both foundational audio understanding and expert-level reasoning across standard benchmarks.