Paper Review: Are Pre-trained Convolutions Better than Pre-trained Transformers?
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
The authors say that previously there were no works on rigorously running experiments for pre-training and fine-tuning CNN for texts.
The possible benefits of CNNs are:
- no self-attention, so less memory required;
- they operate locally and thus don’t need positional embeddings.
On the other hand, CNNs can’t access global information; for example, they can’t do something like a cross-attention across multiple sequences.
The modeling approach
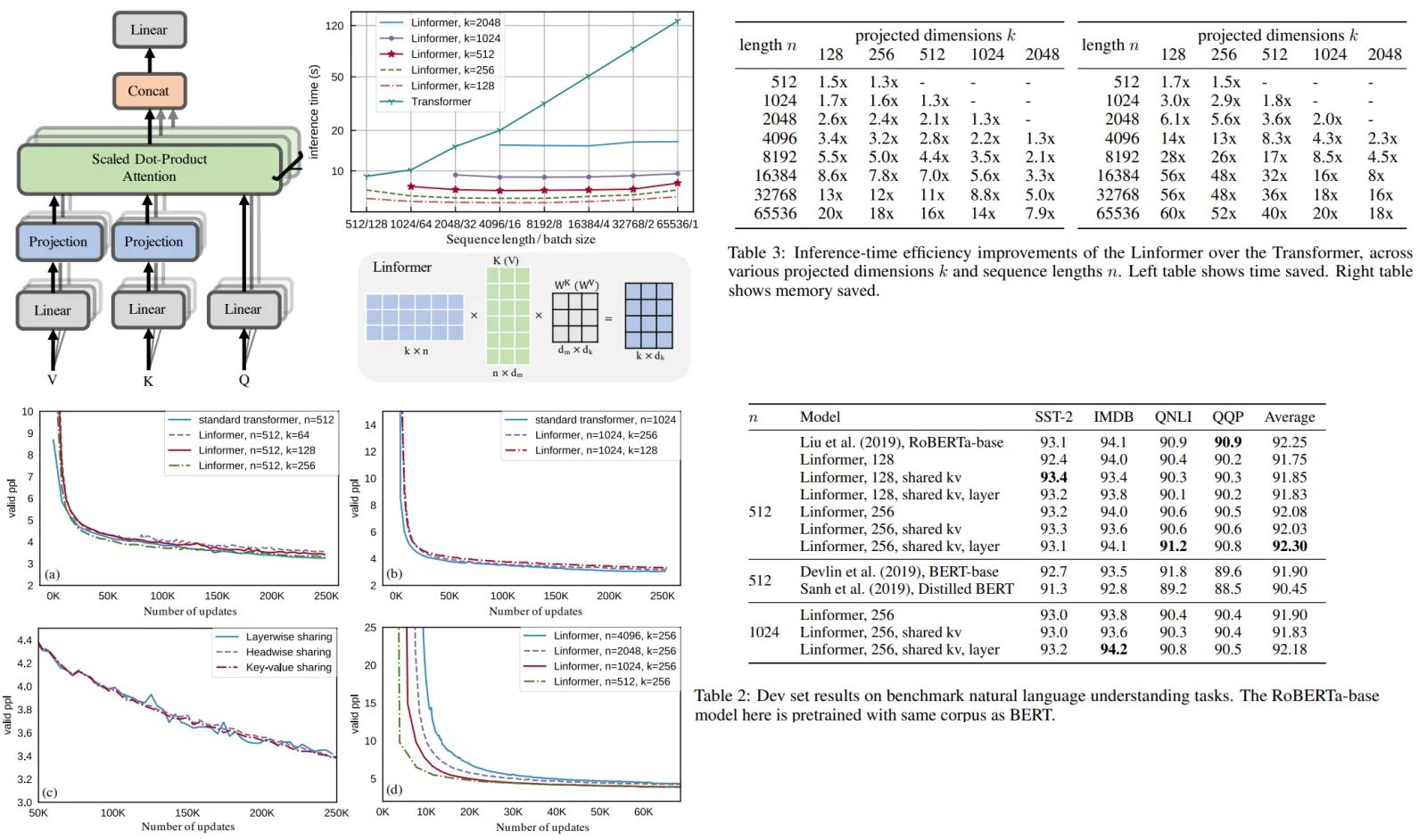
- they use depthwise separable convolutions;
- Span-based Seq2Seq pre-training: they mask a span of length L, and the model tries to predict it;
- cross-entropy loss and teacher forcing;
The architecture
The authors don’t share the exact architectures, but here is the general description:
- Seq2Seq architecture, but convolutional blocks replace multi-head attention;
- gated linear unit projections instead of query-key-value transforms;
- different experiments try lightweight convolutions, dynamic convolutions, and dilated convolutions;
- each submodule is wrapped with residual connections and layer norm;
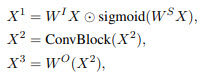
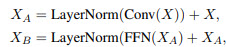
The questions
The authors poise five research questions that they hope to clarify:
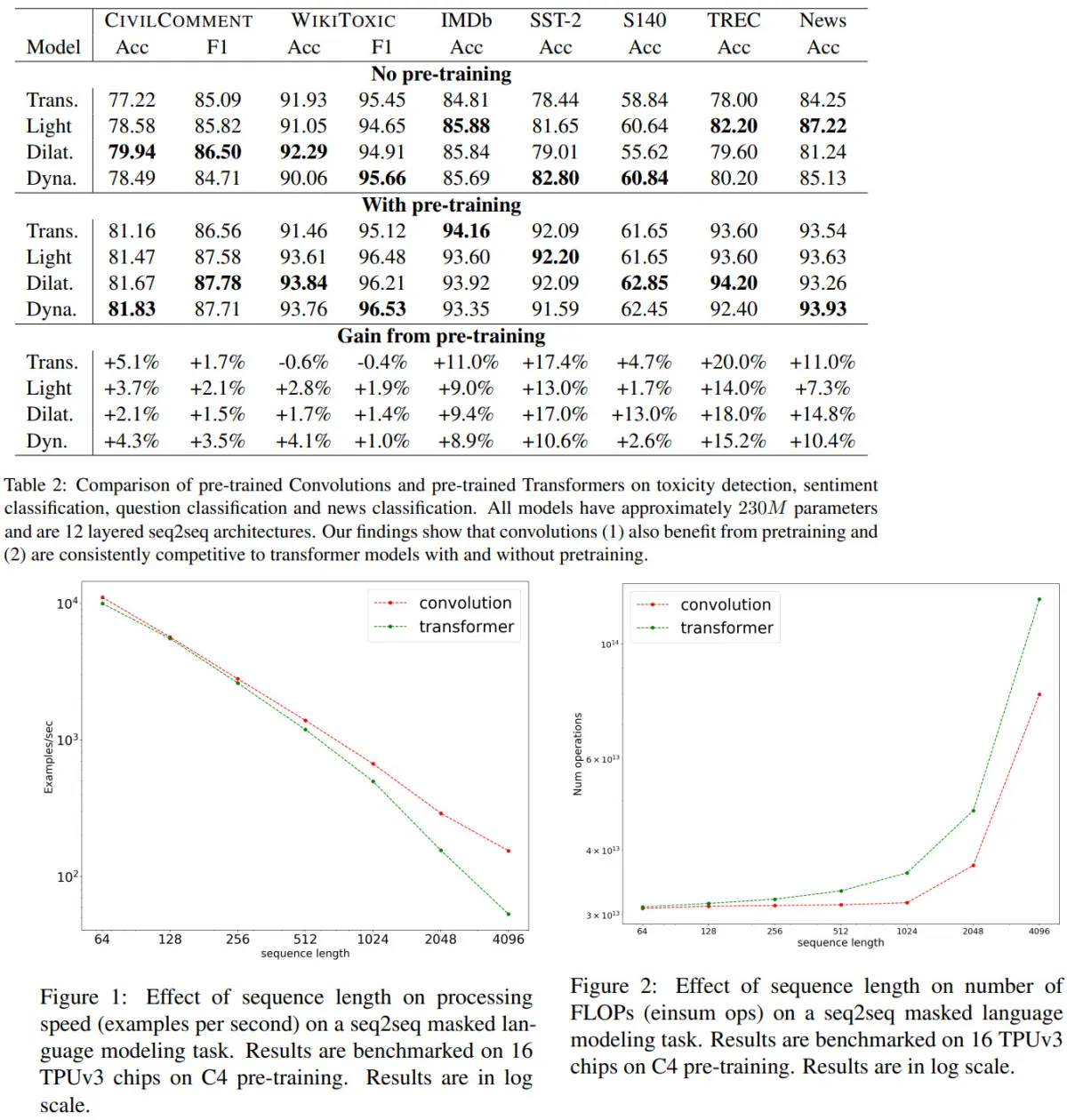
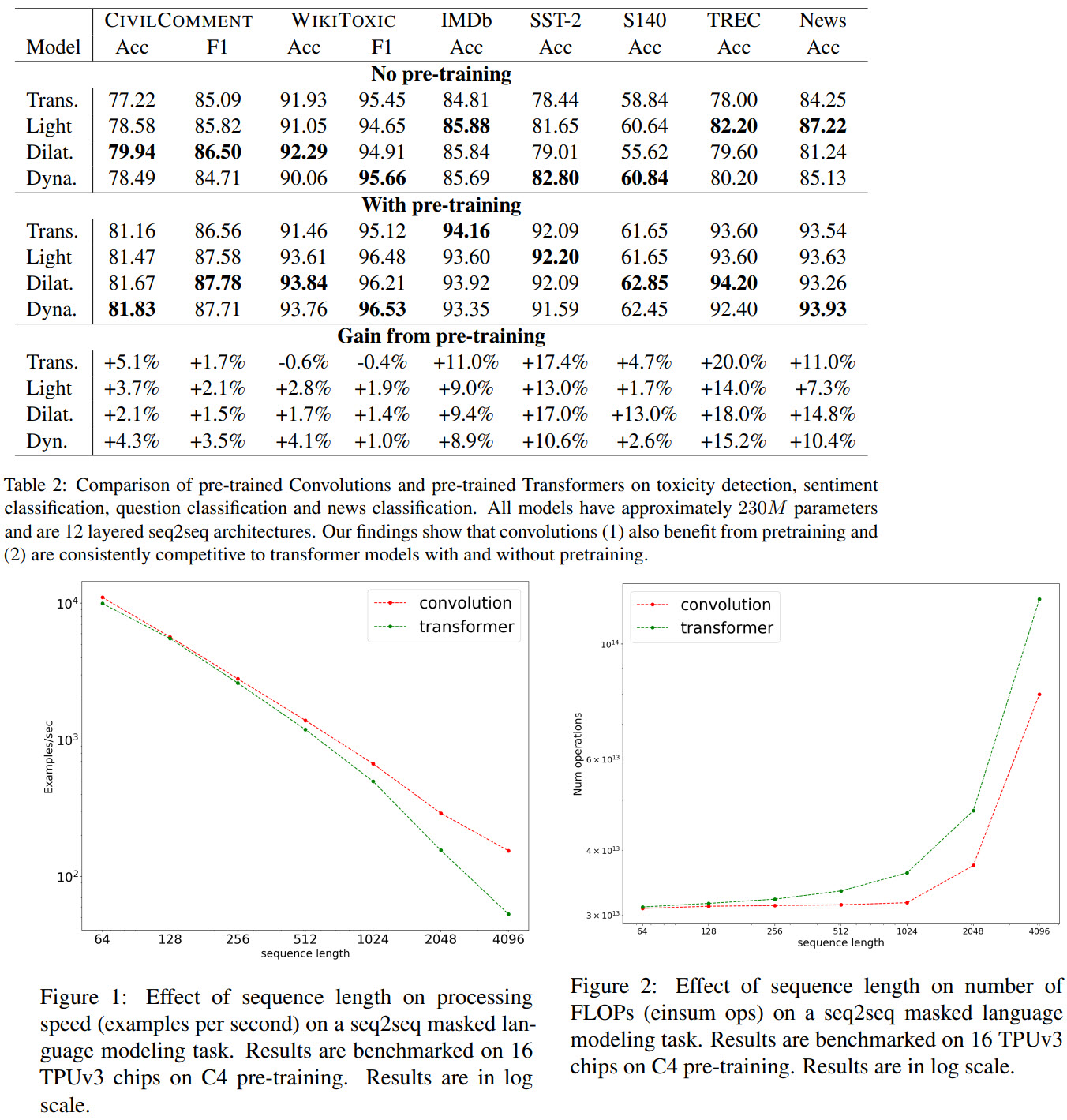
- RQ1: Do convolutions benefit from pre-training as much as Transformers? [Yes]
- RQ2: Are convolutional models, pre-trained or otherwise, competitive with Transformer models? When do they perform well? [Yes; outperform on six tasks]
- RQ3: What are the benefits (if any) of using pre-trained convolution models over pre-trained Transformers? Are convolutions faster alternatives to self-attention based Transformers? [Yes, faster]
- RQ4: What are the failure modes, caveats, and reasons to not use pre-trained convolutions?
- RQ5: Are certain convolution variants better than others? [dilated and dynamic are better than lightweight]
The experiments
They use 8 datasets with different tasks: binary and multiclass classification, generating semantic representation.
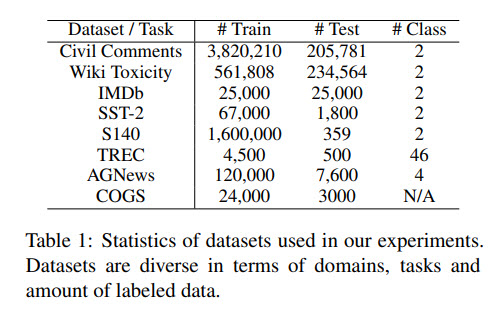
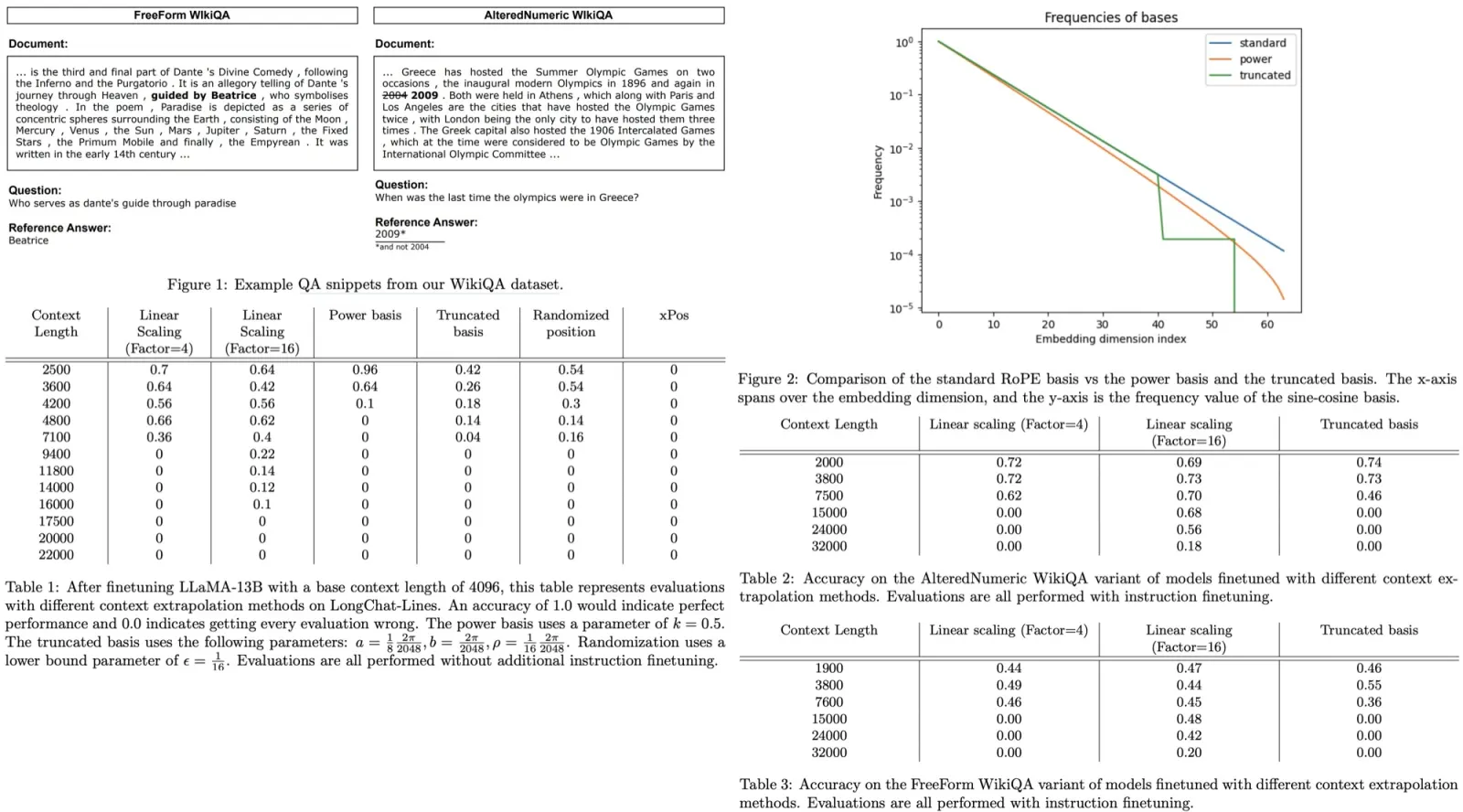
The models are similar to base BERT: 12 layers in the encoder and the decoder, 3072 dimensions in feed-forward layers, model dimensions of 768 and 12 heads. They don’t tune the parameters of the convolutional blocks; they use window size 7 and 2 depth filters. For dilated models the filter sizes are [4, 4, 7, 7, 15, 15, 15, 15, 31, 31, 31]. [I wonder how did they choose the values, if they didn’t optimize the hyperparameters]
The transformer model is similar to T5.
Pre-training
They train both convolutional and transformer models for 524K steps with the batch size 128. Pre-training objective is described above, the span size is 3, corruption rate is 15%. They use Adafactor optimizer [I have never heard about it before] with an inverse square root learning rate scheduler. The pre-training was done on 16 TPUs for 12 hours.
The results
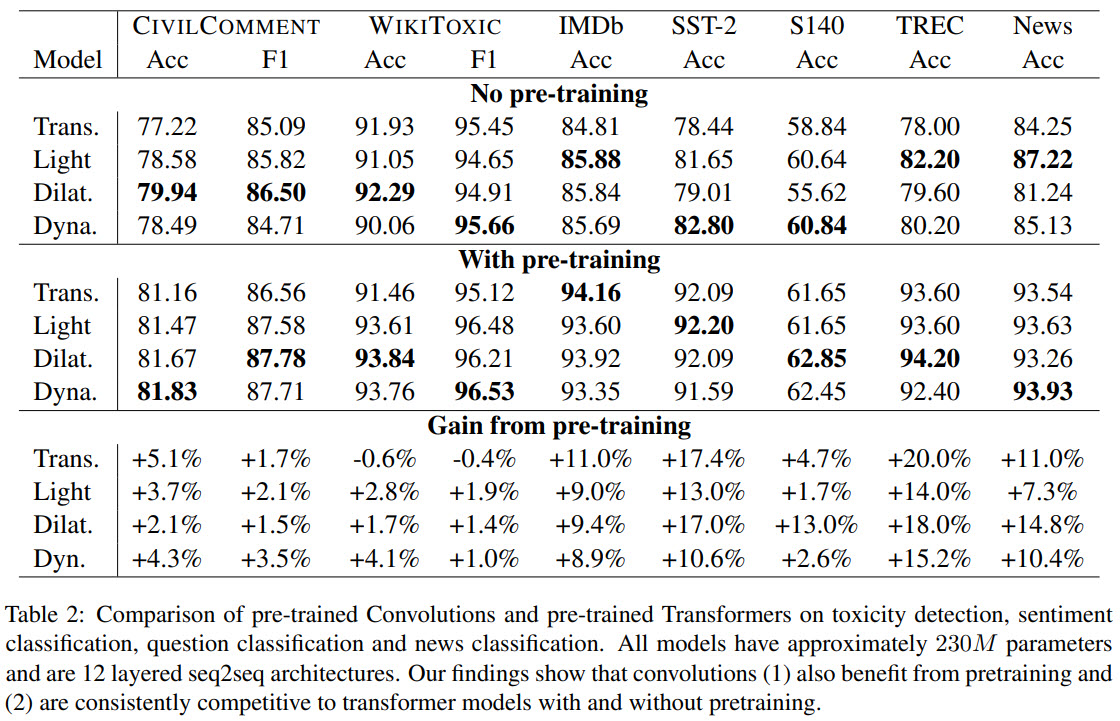
- CNN models lack cross-attention and thus work worse on tasks, which imply modeling the relationships between the sequences. Experiments on SQuAD and MultiNLI show that Transformers are much better on these tasks. But if we add cross-attention to CNN models, they reach almost the same performance as Transformer models.
- CNN models have better training speed and scale better to the longer sequences
- CNN models are more efficient in terms of FLOPs
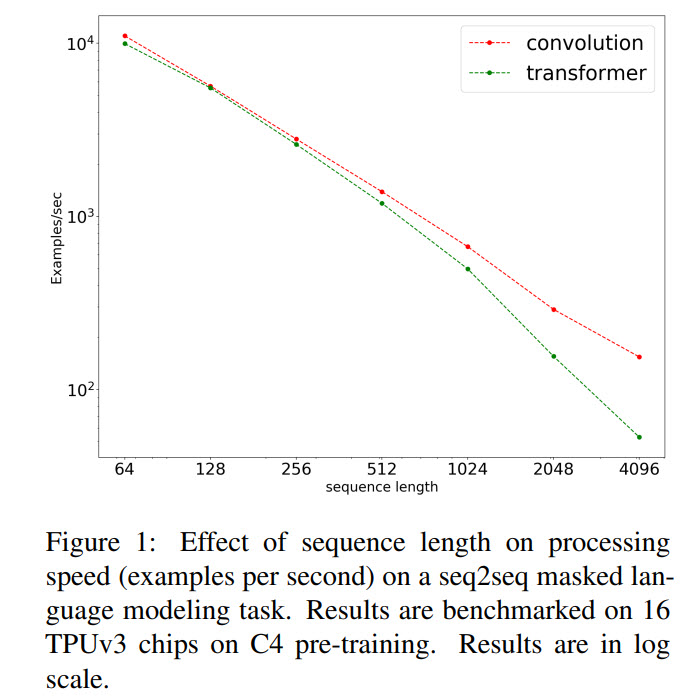
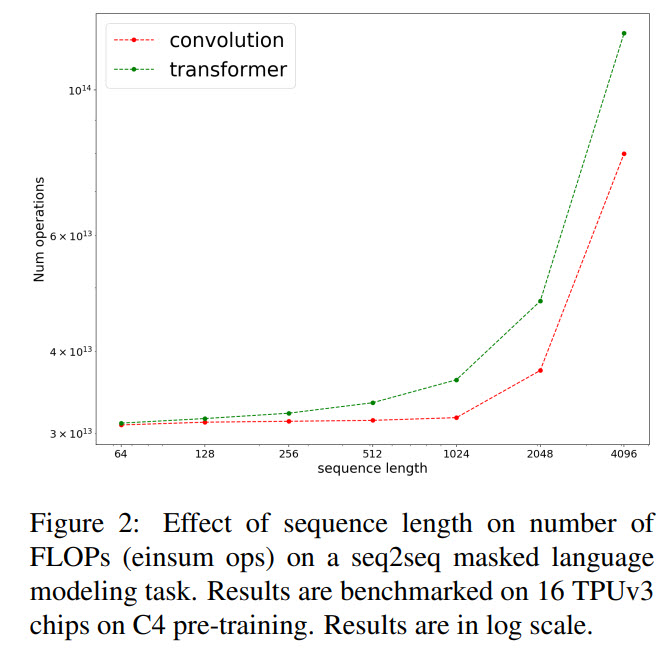
The authors additionally point out the following idea: in NLP pre-training was usually done only for transformer models, but it turns out that pre-training can work well for other architectures. They hope that this paper could open new avenues for the researchers.
paperreview deeplearning nlp cnn transformer pretraining