Paper Review: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture

This paper presents a new methodology for self-supervised learning from images - Image-based Joint-Embedding Predictive Architecture (I-JEPA). Instead of relying on manual data augmentation, I-JEPA predicts the features of different parts of an image based on a single context block, enabling the learning of highly semantic image representations. A key element in this process is the use of an effective masking strategy, which includes selecting large-scale target blocks for semantic learning, and utilizing a sufficiently informative and spatially distributed context block. The I-JEPA approach proves to be highly scalable, particularly when used with Vision Transformers (ViT). For example, a ViT-Huge/14 model was trained on ImageNet using 16 A100 GPUs in less than 72 hours, and demonstrated strong performance in various tasks, such as linear classification, object counting, and depth prediction.
Background
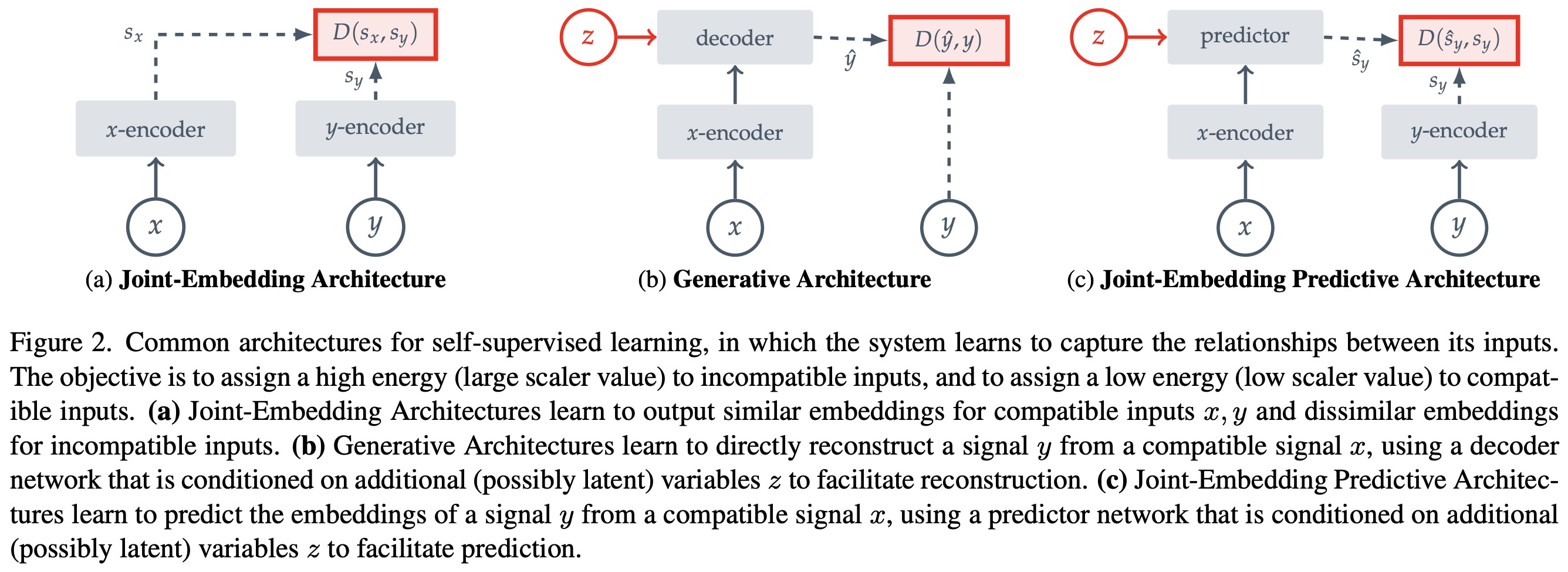
There are three architectures for self-supervised learning:
- JEAs (Joint-Embedding Architectures) aim to produce similar embeddings for compatible inputs and dissimilar ones for incompatible inputs. JEAs have historically struggled with representation collapse, where the encoder provides a constant output regardless of the input. Various strategies to counteract this include contrastive losses, non-contrastive losses, clustering-based approaches, and asymmetrical architectural designs.
- Generative Architectures learn to reconstruct a signal from a compatible signal using a decoder network that is conditioned on an additional variable. One common approach is using masking, where some patches of the image are masked. This architecture avoids representation collapse as long as the informational capacity of the additional variable is low compared to the signal.
- JEPAs (Joint-Embedding Predictive Architectures), similar to Generative Architectures, predict the embeddings of a signal from a compatible signal using a predictor network, but apply the loss function in embedding space rather than input space. The proposed I-JEPA is an instantiation of this architecture for images using masking. JEPAs aim to find representations that are predictive of each other when conditioned on additional information, but like JEAs, they also have the potential problem of representation collapse, which can be mitigated by an asymmetric architecture between the encoders.
Method
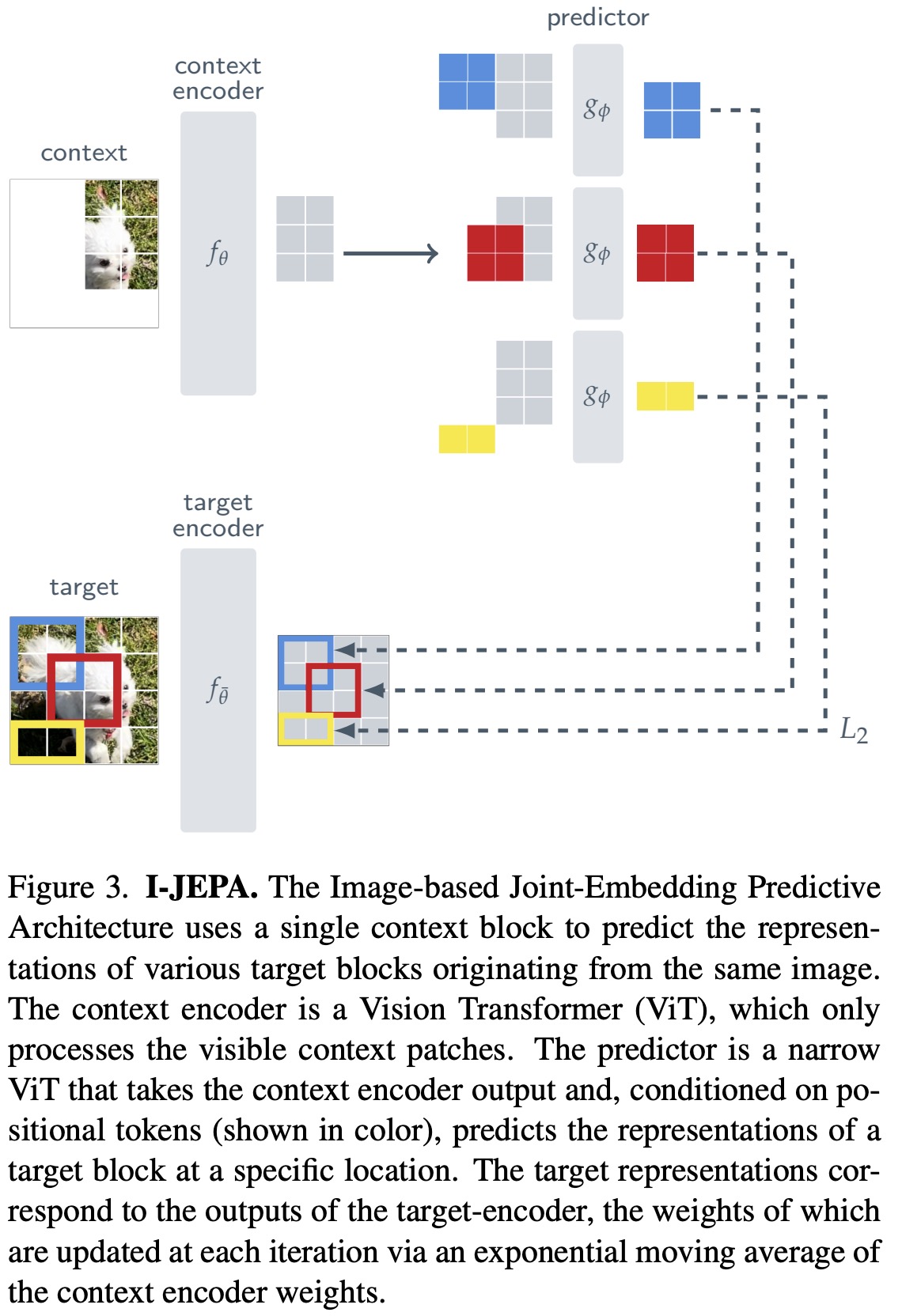
The overall objective of I-JEPA is to predict the representations of various target blocks in an image using a single context block. The model employs a Vision Transformer (ViT) for the context encoder, target encoder, and predictor. These encoders and predictors are similar to the generative masked autoencoders (MAE), but I-JEPA differs by being non-generative, predicting in the representation space.
In I-JEPA, the targets are the representations of image blocks. The image is converted into non-overlapping patches, which are then passed through the target encoder to gain patch-level representation. From this, blocks are randomly sampled to obtain the targets for loss. The target blocks are obtained by masking the output of the target encoder, not the input, which ensures high semantic target representations.

The context block in I-JEPA is a single block sampled from the image. To make the prediction task non-trivial, any overlapping regions with the target blocks are removed. The context block is then fed through the context encoder to obtain a corresponding patch-level representation.
To predict the target block representations, the predictor takes the output of the context encoder and a mask token for each patch it wishes to predict and outputs a patch-level prediction. This is done for each target block.
The loss is calculated as the average L2 distance between the predicted patch-level representations and the target patch-level representation. The parameters of the predictor and context encoder are learned through gradient-based optimization, while the parameters of the target encoder are updated via an exponential moving average of the context-encoder parameters, which is essential for training JEAs with Vision Transformers.
Image Classification
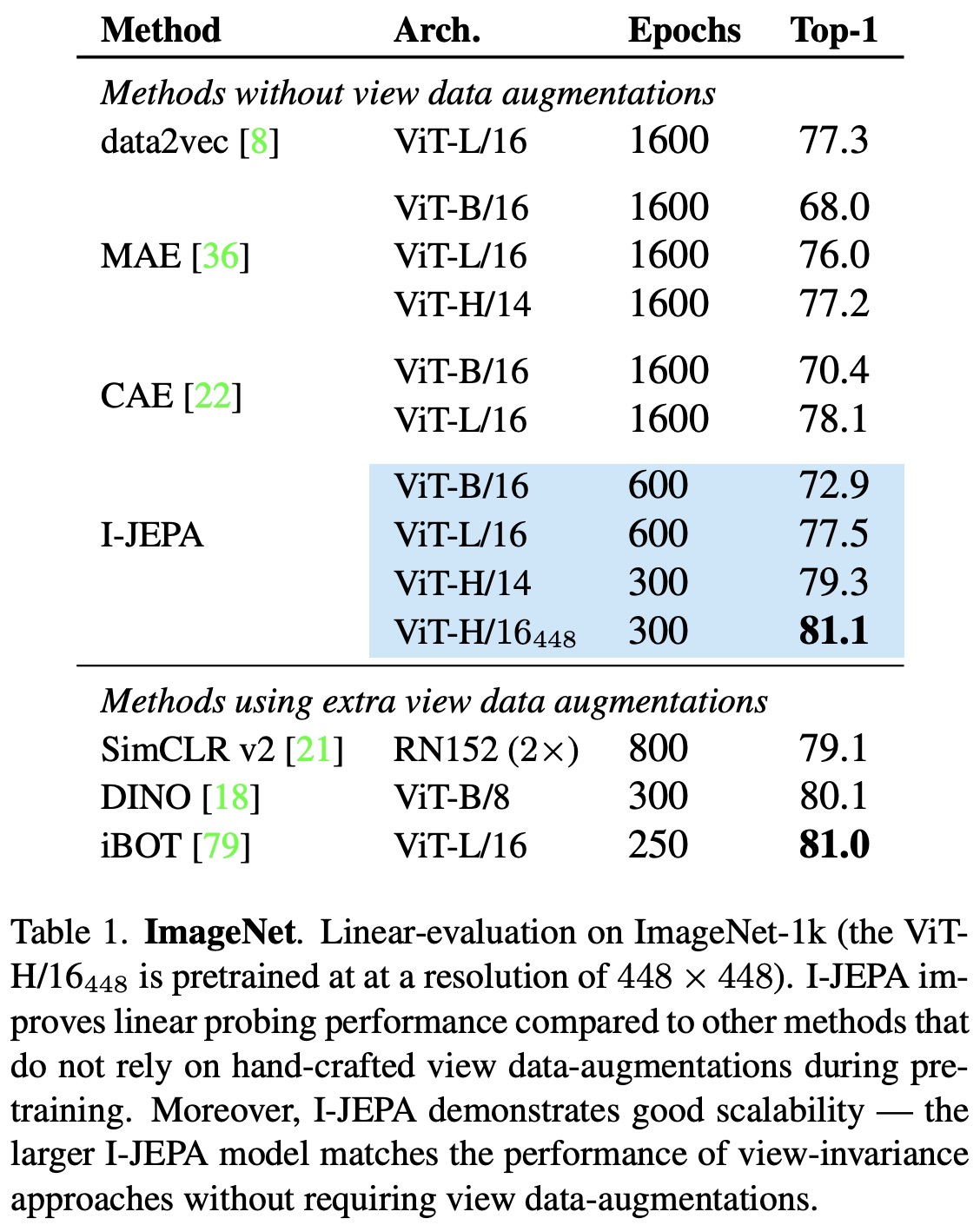
- ImageNet-1K: The results of I-JEPA performance on the ImageNet-1K linear-evaluation benchmark shows significant improvements compared to other methods such as Masked Autoencoders (MAE), Context Autoencoders (CAE), and data2vec, particularly regarding computational effort. With the improved efficiency of I-JEPA, larger models could be trained that outperformed the best CAE models using less computation. I-JEPA’s performance even matches view-invariant approaches like iBOT when trained at higher resolution, without using hand-crafted data augmentations.
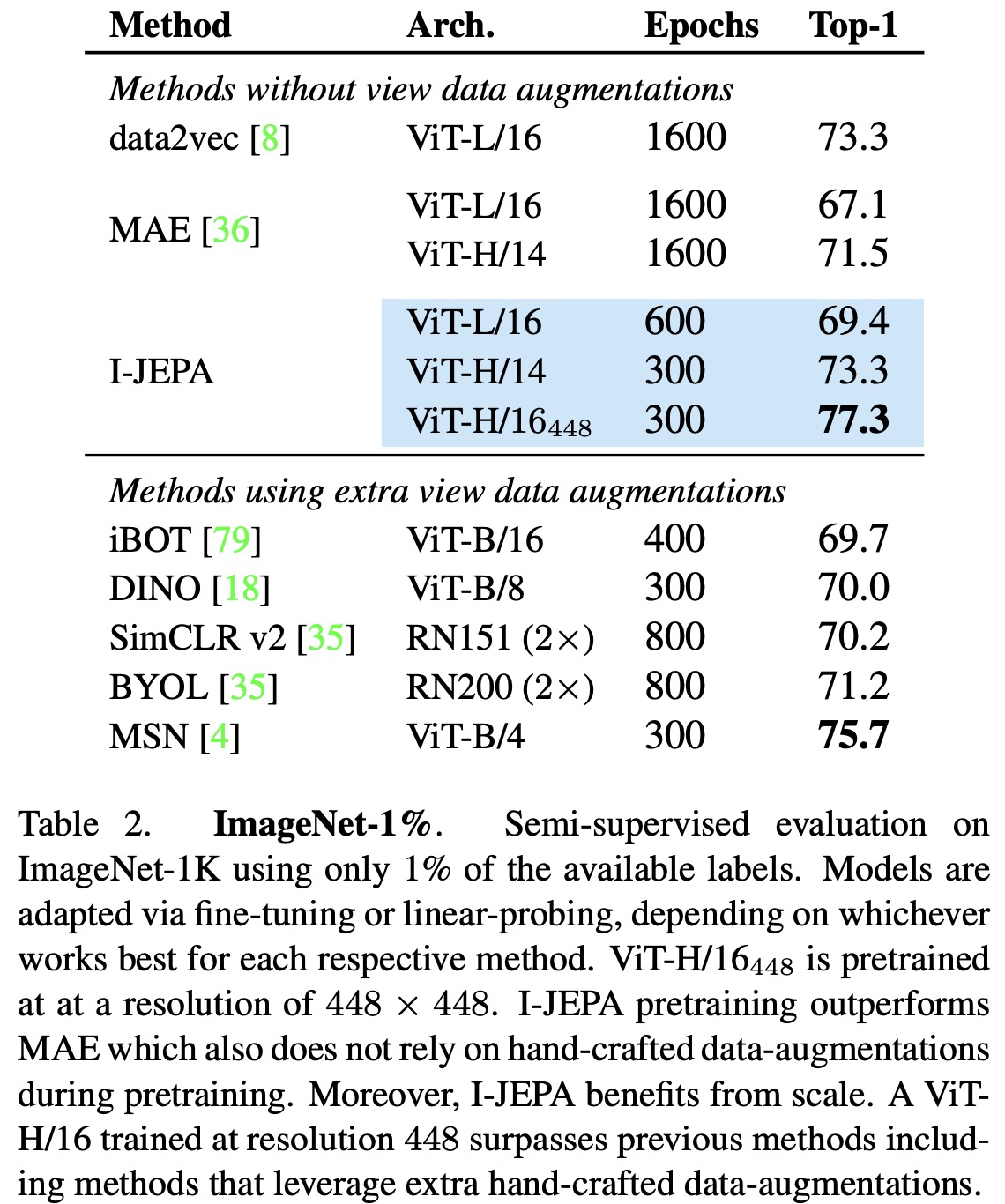
- Low-Shot ImageNet-1K: I-JEPA outperforms MAE in the 1% ImageNet benchmark, where models are adapted for ImageNet classification using only 1% of the available labels, corresponding to roughly 12 or 13 images per class. With increased image input resolution, I-JEPA also outperforms other joint-embedding methods that do leverage extra hand-crafted data augmentations during pretraining, such as MSN, DINO, and iBOT.
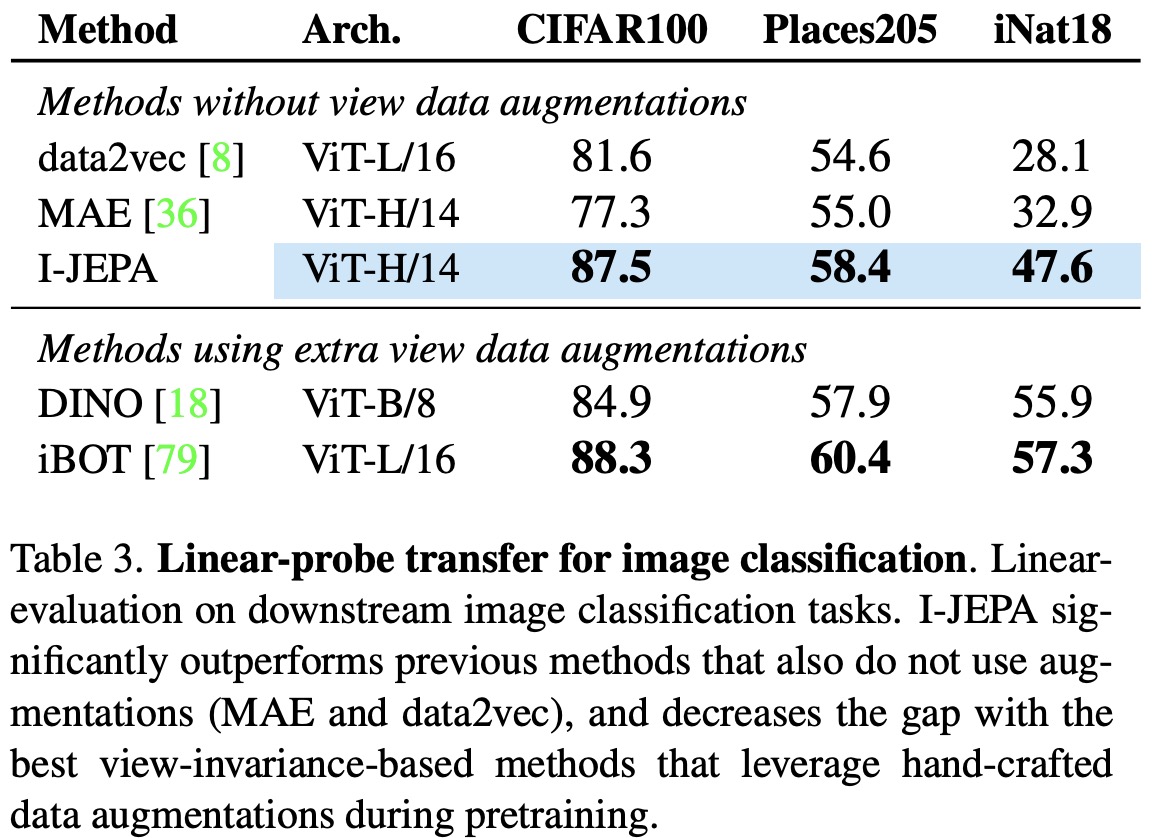
- Transfer Learning: I-JEPA’s performance on various downstream image classification tasks shows significant improvements over previous methods like MAE and data2vec that don’t use augmentations. I-JEPA decreases the gap with view-invariance-based methods that do use hand-crafted data augmentations during pretraining, and even surpasses the popular DINO method on CIFAR100 and Place205 with a linear probe.
Local Prediction Tasks
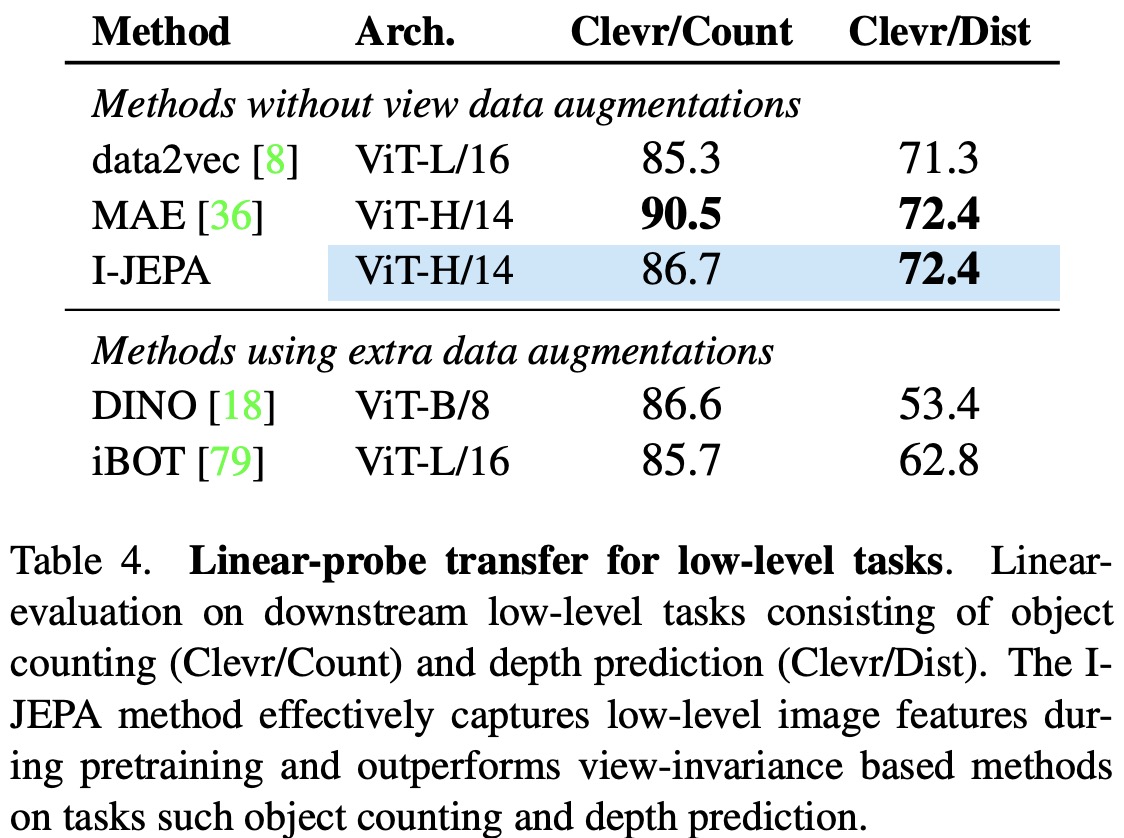
I-JEPA not only learns semantic image representations that enhance downstream image classification performance, but also effectively captures local image features. This has been demonstrated through I-JEPA’s superior performance in low-level and dense prediction tasks such as object counting and depth prediction.
In the tests, I-JEPA outperformed other view-invariance methods such as DINO and iBOT. After pretraining, the encoder weights were frozen and a linear model was trained on top to perform object counting and depth prediction on the Clevr dataset. The results indicate that I-JEPA captures low-level image features more effectively during pretraining than the other methods and significantly outperforms them, especially in the area of depth prediction.
Scalability
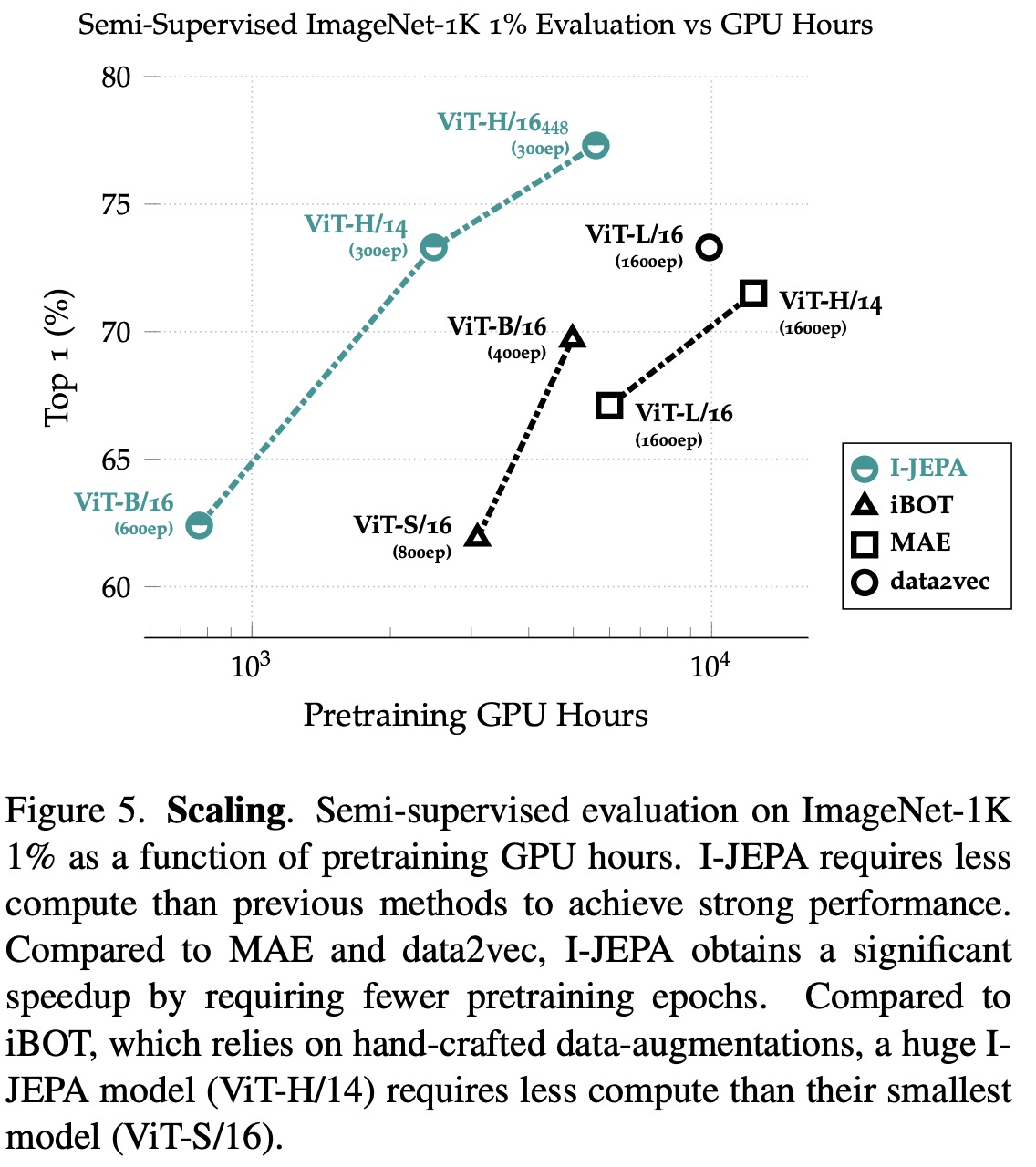
I-JEPA has been found to be highly scalable and more efficient compared to previous approaches. It requires less computational resources, achieves robust performance without needing hand-crafted data augmentations, and generally runs faster. While I-JEPA does introduce additional overhead by computing targets in representation space, it converges in approximately five times fewer iterations, offering significant computational savings.
Moreover, I-JEPA benefits from pretraining with larger datasets, showing improved transfer learning performance on semantic and low-level tasks when the size of the pretraining dataset is increased. For example, the performance improved when transitioning from training on ImageNet-1K (IN1K) to ImageNet-22K (IN22K).
The study also found that I-JEPA benefits from larger model size when pretraining on larger datasets such as IN22K. For example, pretraining a larger ViT-G/16 model improved the downstream performance on image classification tasks compared to a smaller ViT-H/14 model. However, the performance on low-level downstream tasks did not see a similar improvement as larger input patches used by ViT-G/16 could be detrimental for local prediction tasks.
Predictor Visualizations

The role of the predictor in I-JEPA is to use the output of the context encoder and, when conditioned on positional mask tokens, predict the representations of a target block at the location indicated by the mask tokens. The researchers wanted to investigate whether this predictor, when conditioned on positional mask tokens, is correctly learning to capture positional uncertainty in the target.
To do this, they visualized the outputs of the predictor after freezing the context-encoder and predictor weights. A decoder was trained using the RCDM framework to map the average-pooled predictor outputs back to pixel space, enabling visualization. The resulting images demonstrated that the I-JEPA predictor correctly captured positional uncertainty and produced high-level object parts with the correct pose. For instance, it correctly identified the back of a bird and the top of a car. The visualization approach was designed to be reproducible for the wider research community.
Ablations

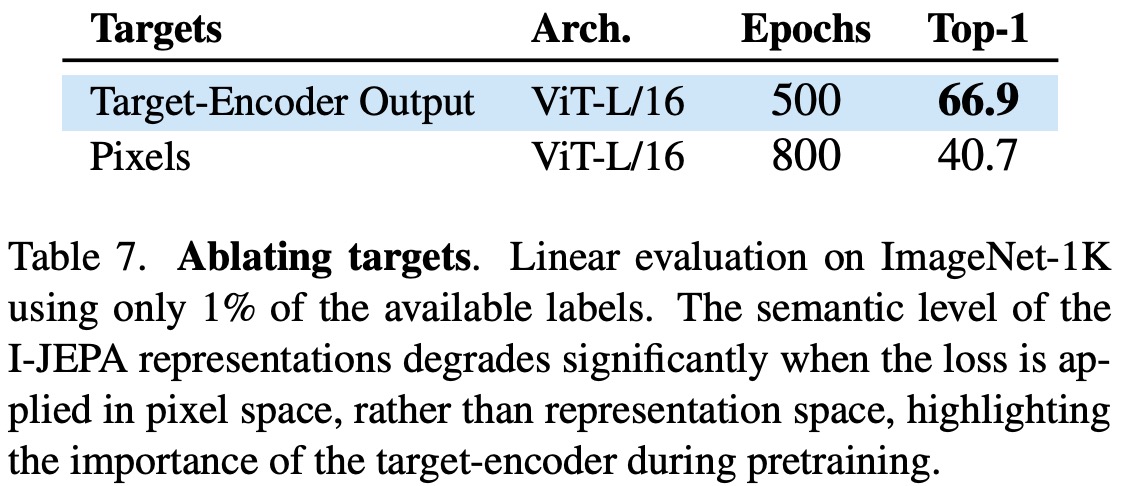
- The authors compared the low-shot performance on 1% ImageNet-1K using a linear probe when the loss is computed in pixel-space versus representation space. Their conjecture was that a crucial component of I-JEPA is that the loss is computed entirely in representation space, giving the target encoder the ability to produce abstract prediction targets, while eliminating irrelevant pixel-level details. Predicting in pixel-space led to a significant degradation in the linear probing performance.
- In addition, they compared their multi-block masking strategy with other masking strategies such as rasterized masking, block masking, and random masking. The rasterized masking splits the image into four large quadrants, using one quadrant as a context to predict the other three. In block masking, the target is a single image block and the context is the image complement. In random masking, the target is a set of random patches and the context is the image complement. In all strategies, there’s no overlap between the context and target blocks. The authors found that multi-block masking was beneficial for guiding I-JEPA to learn semantic representations.