Paper Review: Differential Transformer
The Differential Transformer introduces a new attention mechanism that improves upon the traditional Transformer by reducing irrelevant context. It achieves this by using a differential attention mechanism, where attention scores are calculated as the difference between two softmax attention maps. This helps cancel out noise and promotes sparse attention patterns, leading to better focus on relevant context. Experiments show that Diff Transformer outperforms standard Transformers, particularly in areas like long-context modeling, key information retrieval, hallucination reduction, and in-context learning. It also offers improved robustness against issues like order permutation in input sequences.
Differential Transformer
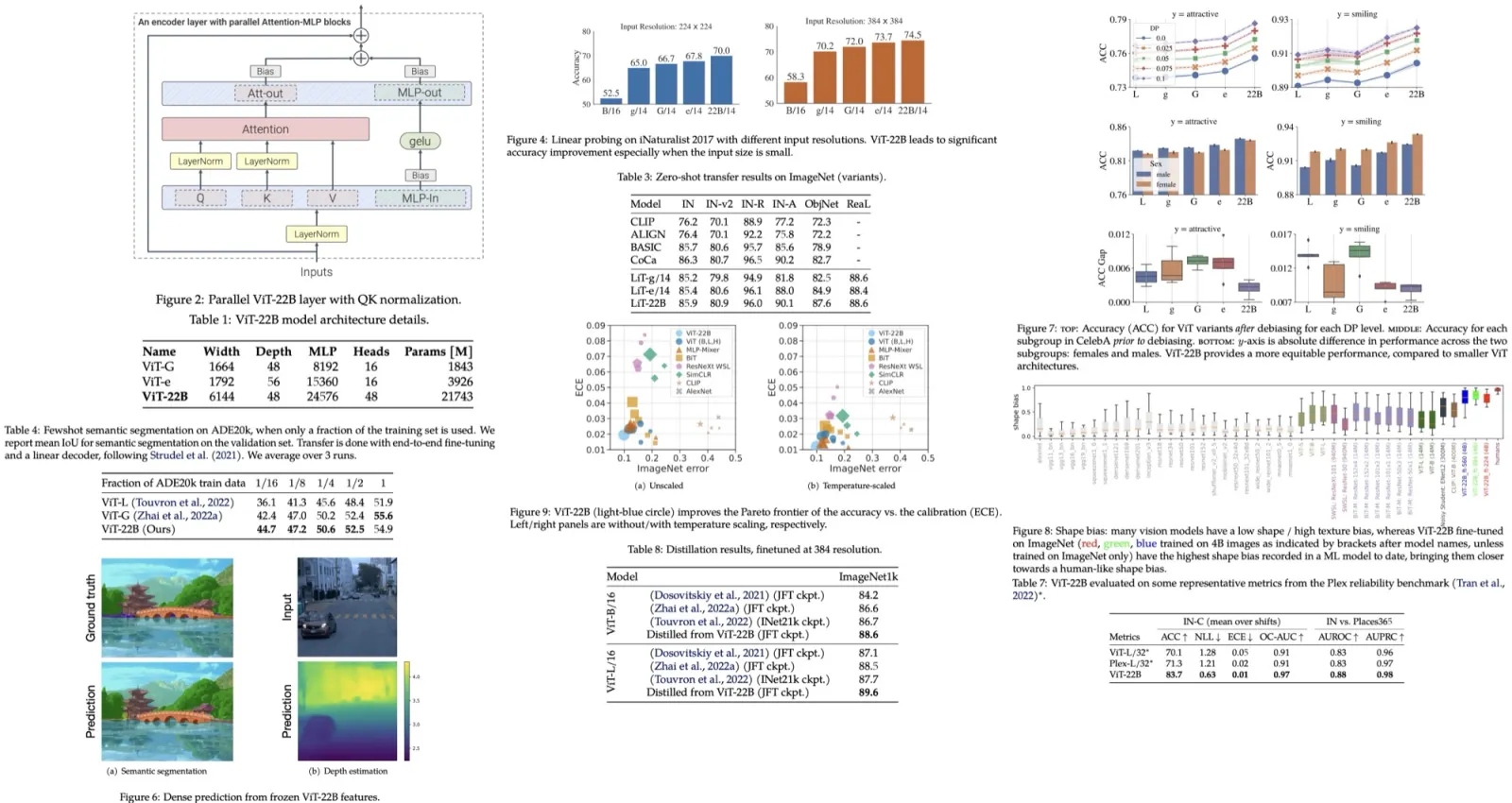
The Diff Transformer builds upon the decoder-only model structure and introduces a differential attention mechanism, which replaces traditional softmax attention with two softmax functions that cancel out noise. Each layer includes the differential attention module and a feed-forward network. Multi-head differential attention is applied, where the attention for each head is processed independently and normalized using RMSNorm and headwise normalization to maintain training stability.
The differential attention mechanism is inspired by differential amplifiers in electrical engineering, designed to eliminate common noise by subtracting attention scores from two softmax functions. FlashAttention is used to enhance efficiency, while multi-head differential attention allows for richer contextualization across different attention heads. The architecture integrates improvements from models like LLaMA, including SwiGLU activation functions and pre-RMSNorm.
Experiments
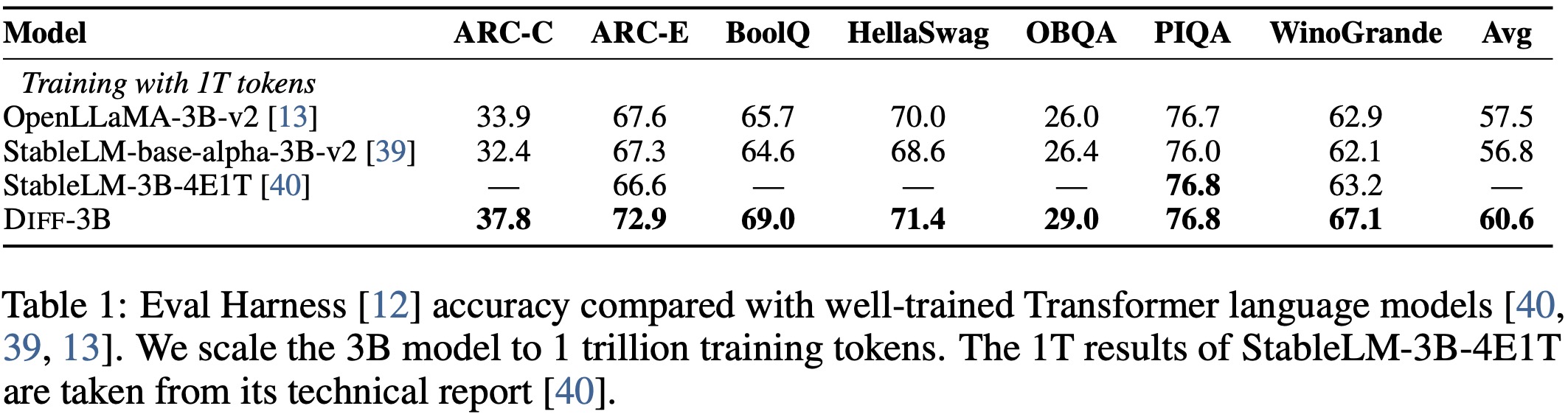
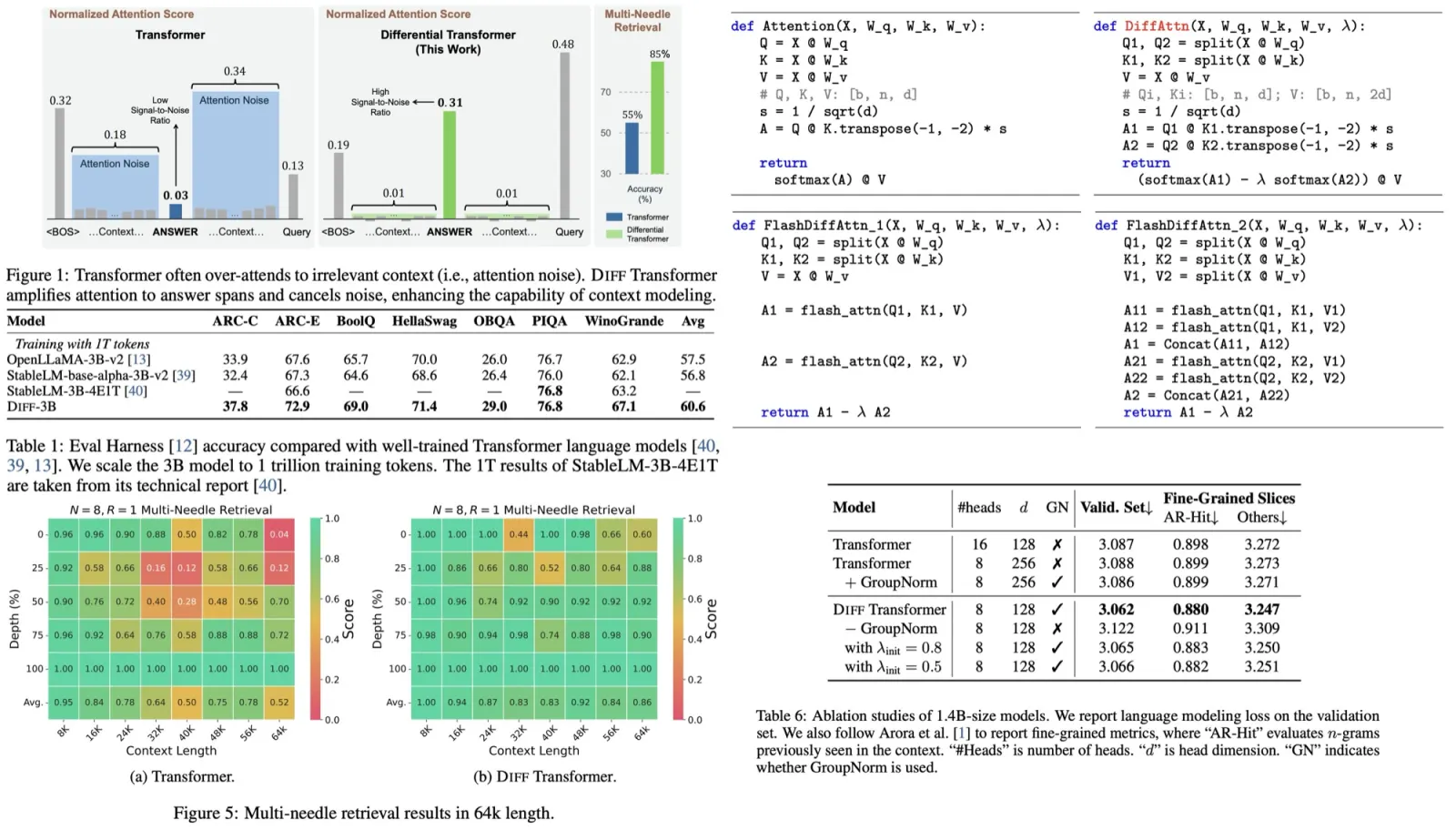
Zero-shot results from the LM Eval Harness benchmark demonstrate that Diff Transformer performs favorably compared to well-tuned models. Additionally, experiments show that DIFF Transformer consistently outperforms standard Transformers across various tasks, using comparable training setups to ensure fair comparisons.
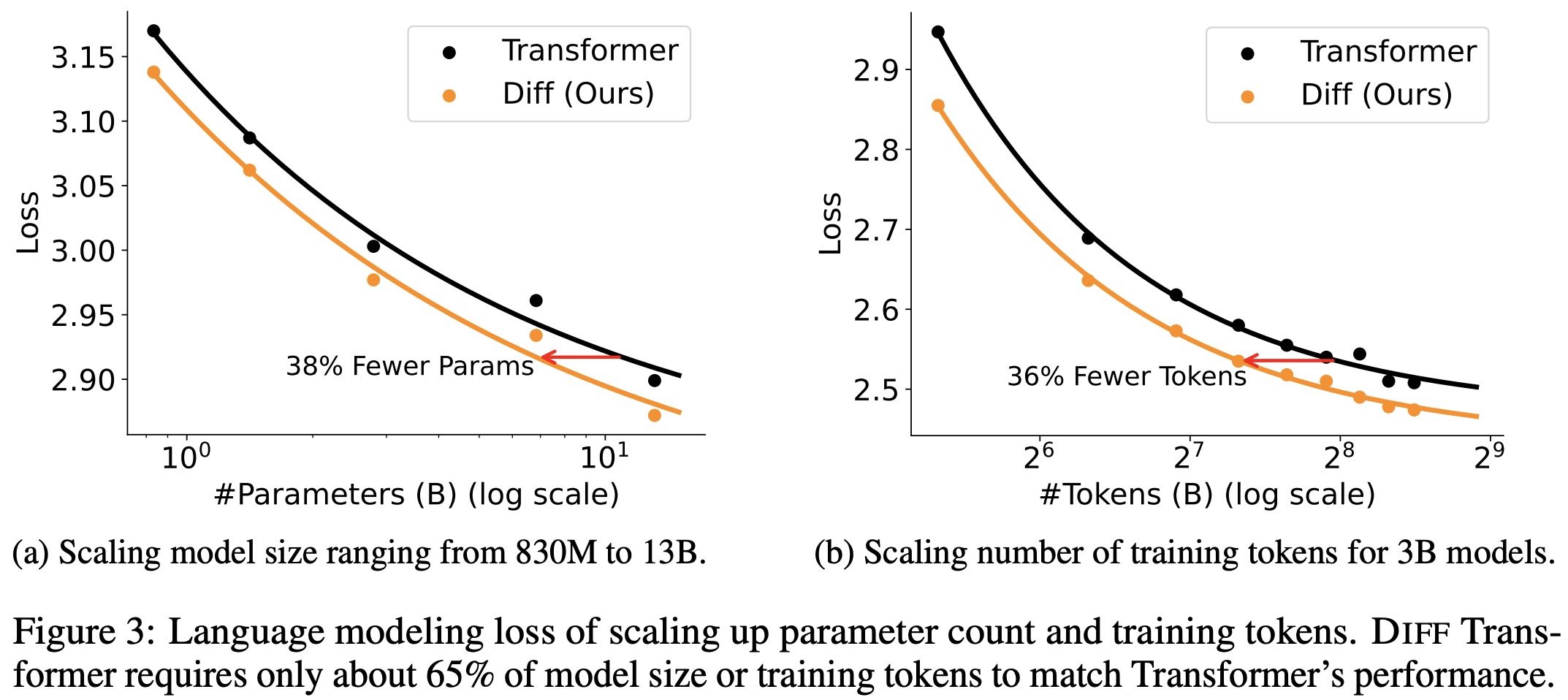
6.8B-size Diff Transformer achieves a validation loss comparable to 11B-size Transformer, requiring only 62.2% of parameters. Similarly, 7.8B-size Diff Transformer matches the performance of 13.1B-size Transformer, requiring only 59.5% of parameters. Diff Transformer trained with 160B tokens achieves comparable performance as Transformer trained with 251B tokens, consuming only 63.7% of the training tokens.
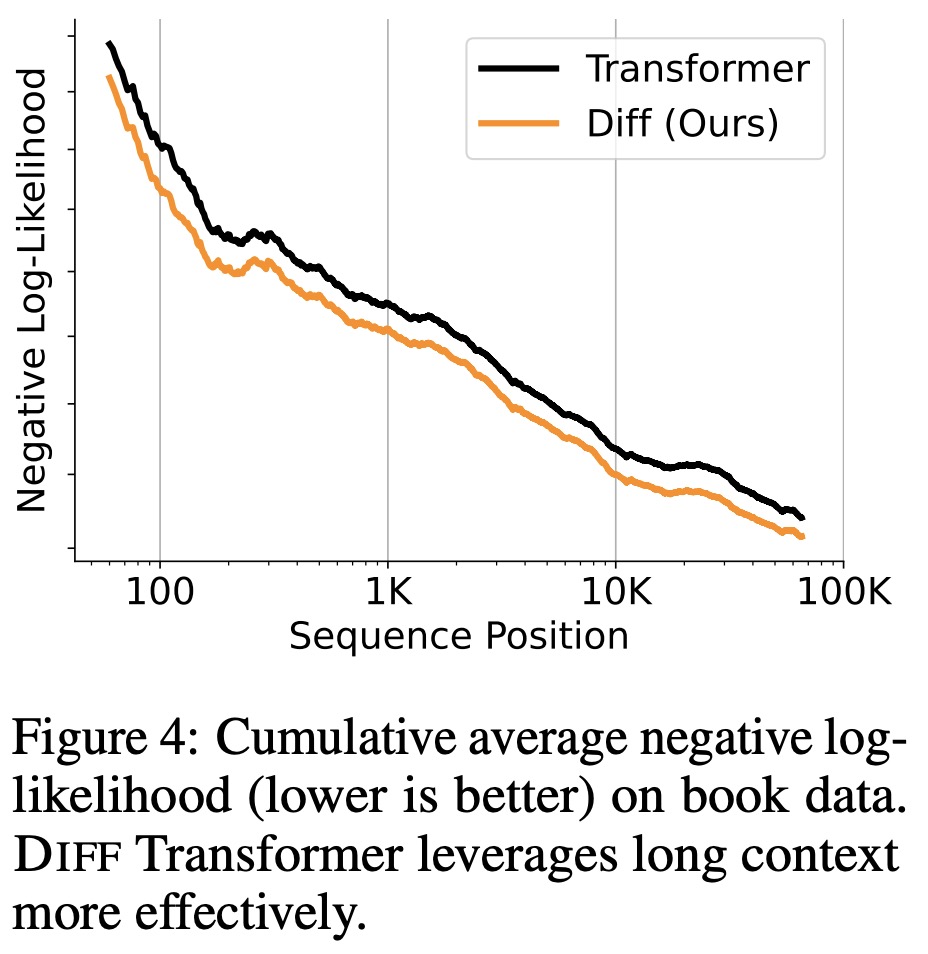
Diff Transformer can effectively leverage the increasing context.
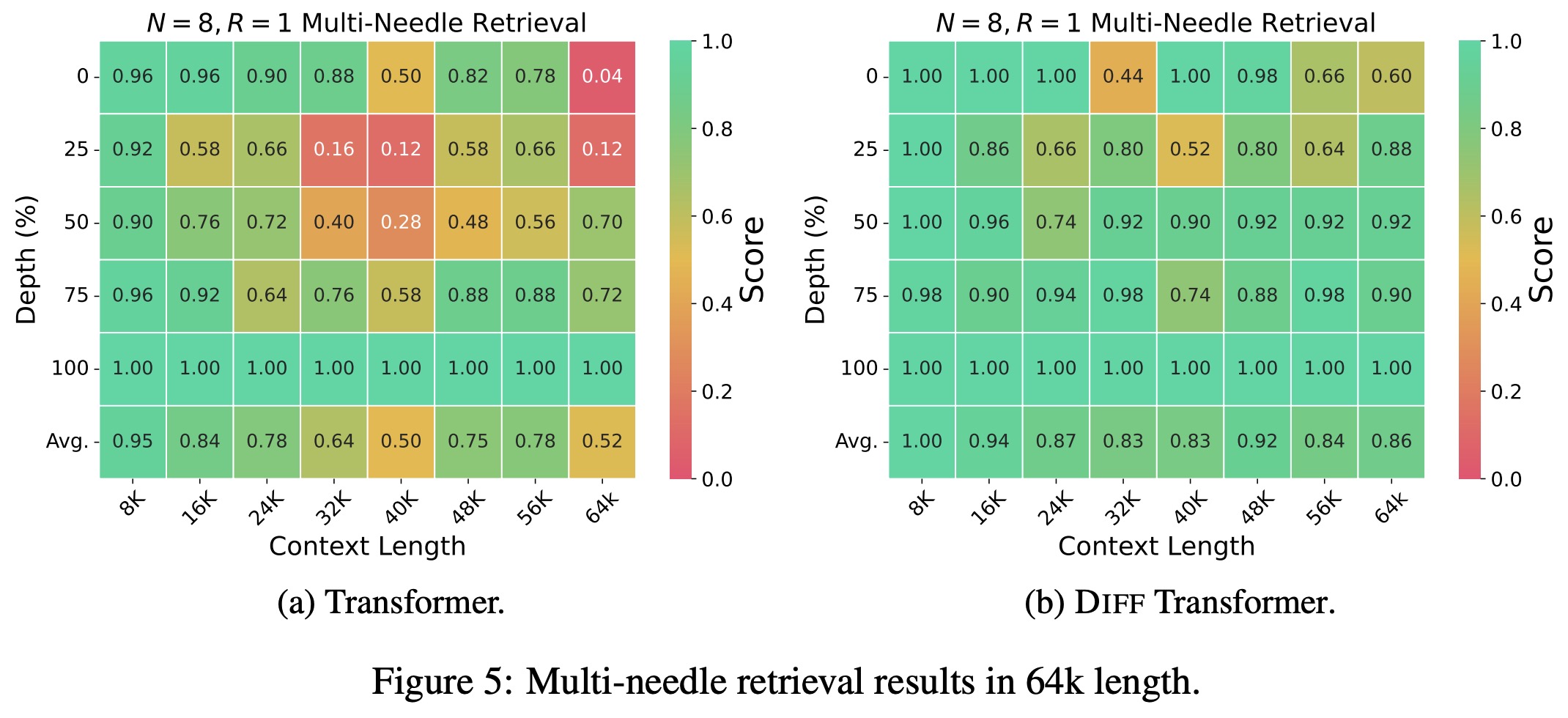
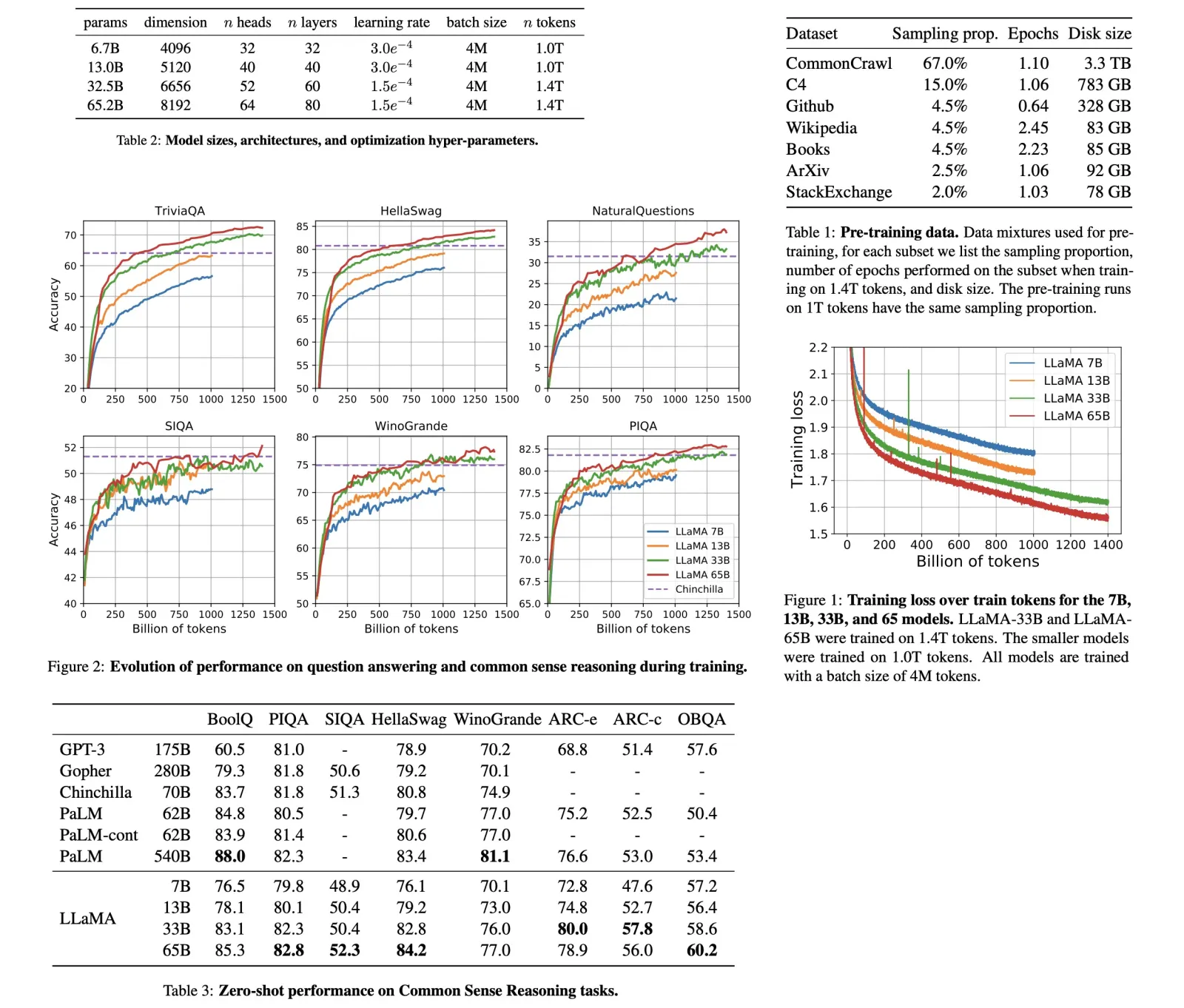
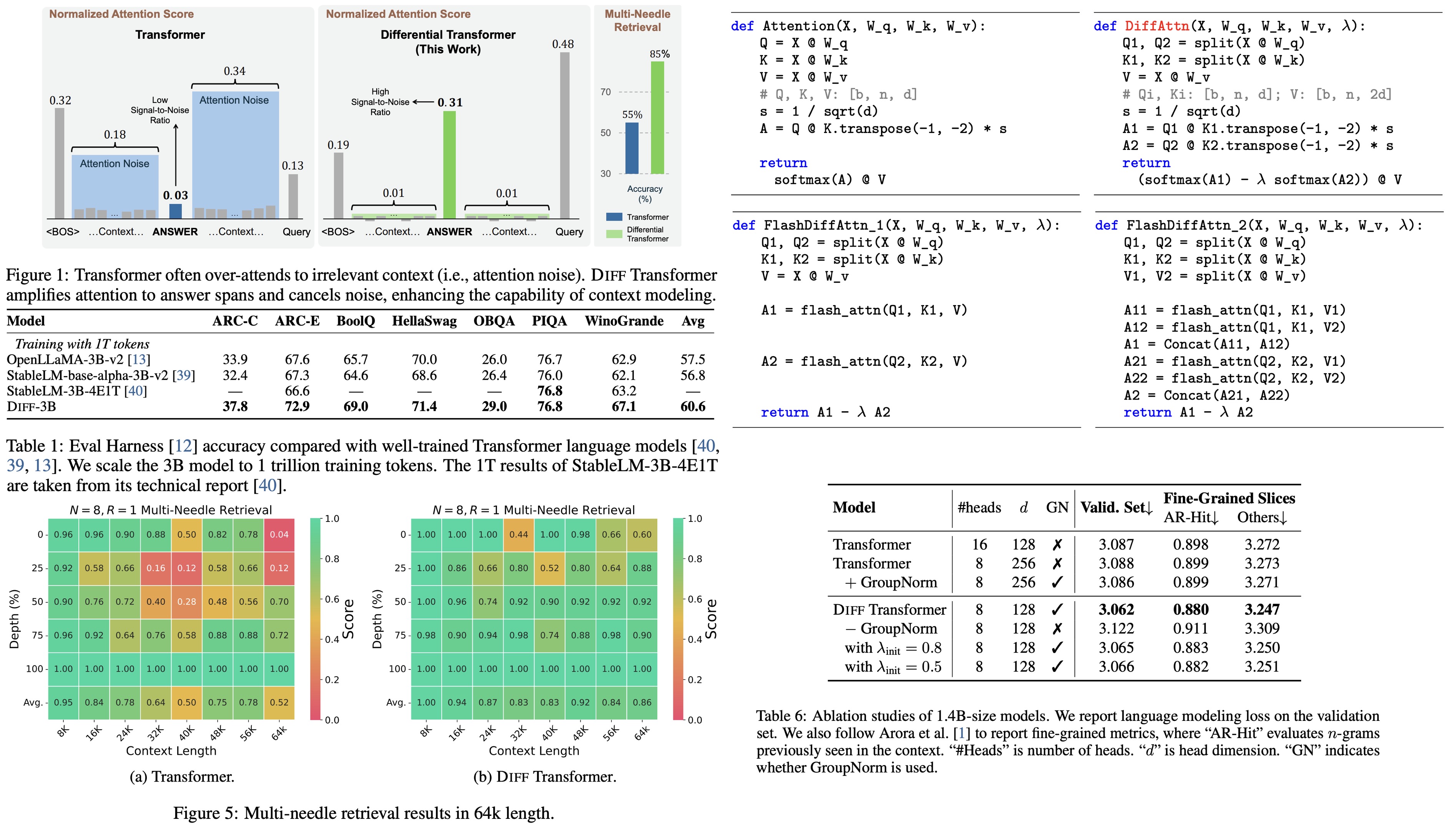
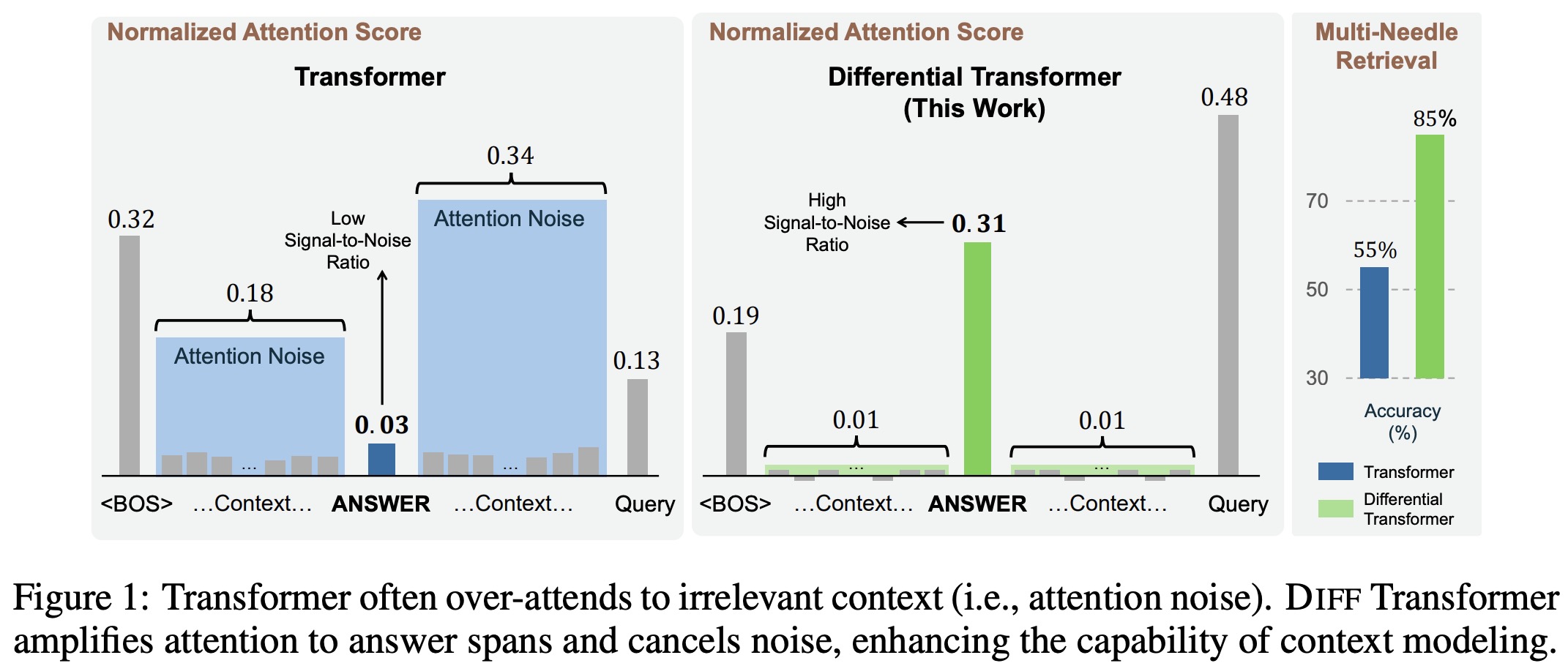
The authors evaluate the performance of Diff Transformer and standard Transformer models on a key information retrieval task with context lengths ranging from 8K to 64K tokens. The results show that Diff Transformer maintains stable accuracy across different context lengths, whereas the accuracy of standard Transformer declines as the context length increases. For example, at 25% depth in a 64K context, Diff Transformer shows a 76% accuracy improvement over Transformer.
Additionally, attention score analysis reveals that Diff Transformer allocates higher attention scores to the relevant answer span and reduces attention noise, better preserving useful information compared to the Transformer, especially when key information is placed at different positions within the context.

Compared with Transformer, Diff Transformer mitigates contextual hallucination on summarization and question answering. This improvement possibly stems from Diff Transformer’s better focus on essential information needed for the task, instead of irrelevant context.
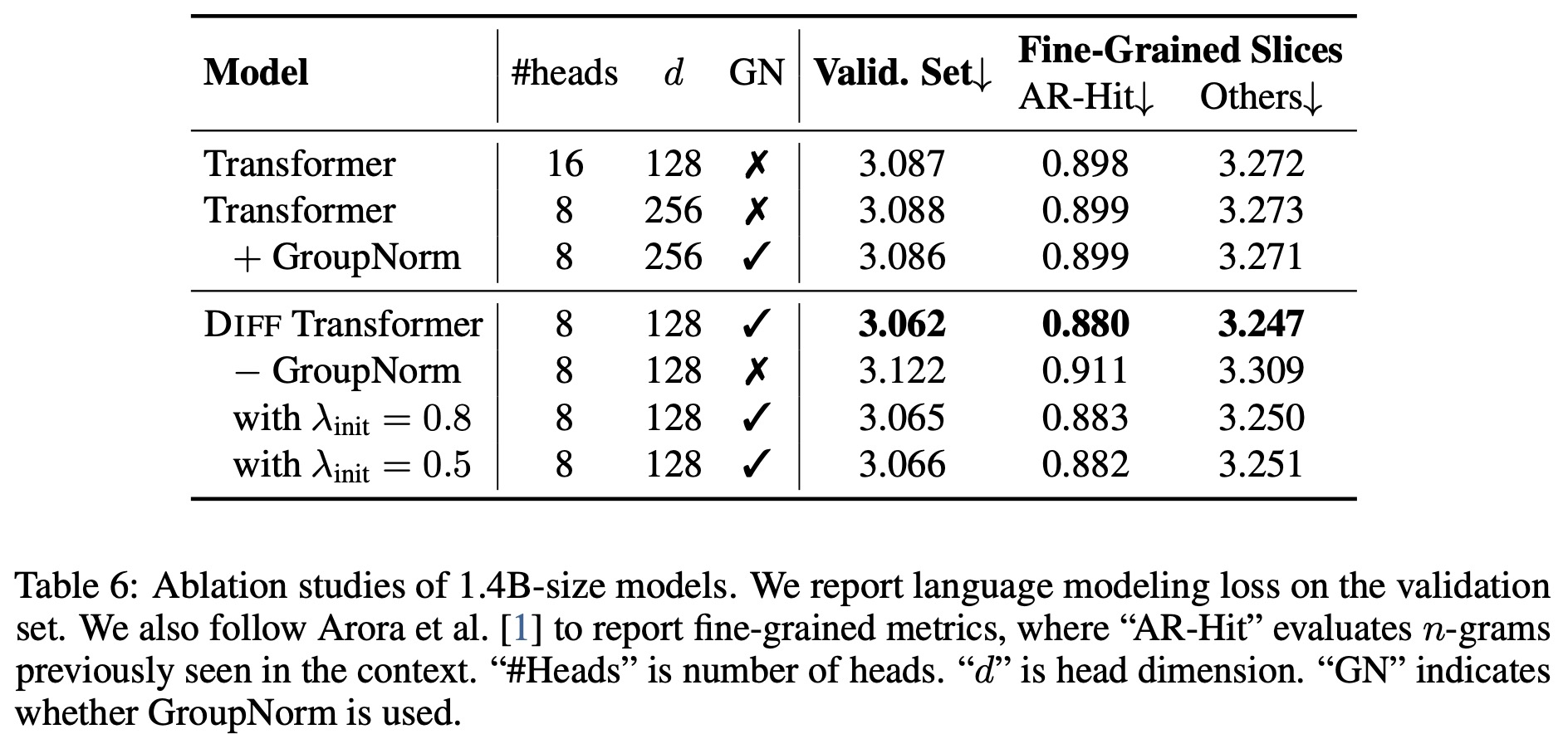
Ablation studies:
- Diff Transformer outperforms Transformer in both overall and fine-grained loss, even when halving the number of attention heads to maintain model size.
- Removing GroupNorm from Diff Transformer leads to performance degradation, as GroupNorm helps stabilize training by normalizing diverse statistics across multiple heads. In contrast, adding GroupNorm to Transformer shows little effect.
- The main improvements of Diff Transformer stem from the differential attention mechanism, rather than configuration changes or normalization methods.
- Various strategies for initializing the λ parameter (used in the differential attention) show minimal impact on validation loss, indicating that Diff Transformer is robust to different initialization choices. The default used value is
λinit = 0.8 − 0.6 × exp(−0.3 · (l − 1))