Paper Review: Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
Ferret-v2 is an upgrade to the Ferret LLM, enhancing image processing capabilities with three key improvements:
- Flexible image resolution handling for improved detail processing;
- Integration of the DINOv2 encoder for better understanding of diverse visual contexts;
- A three-stage training process that includes image-caption alignment, high-resolution dense alignment, and instruction tuning.
These enhancements allow Ferret-v2 to significantly outperform the original model and other SOTA methods.
The approach
A Revisit of Ferret
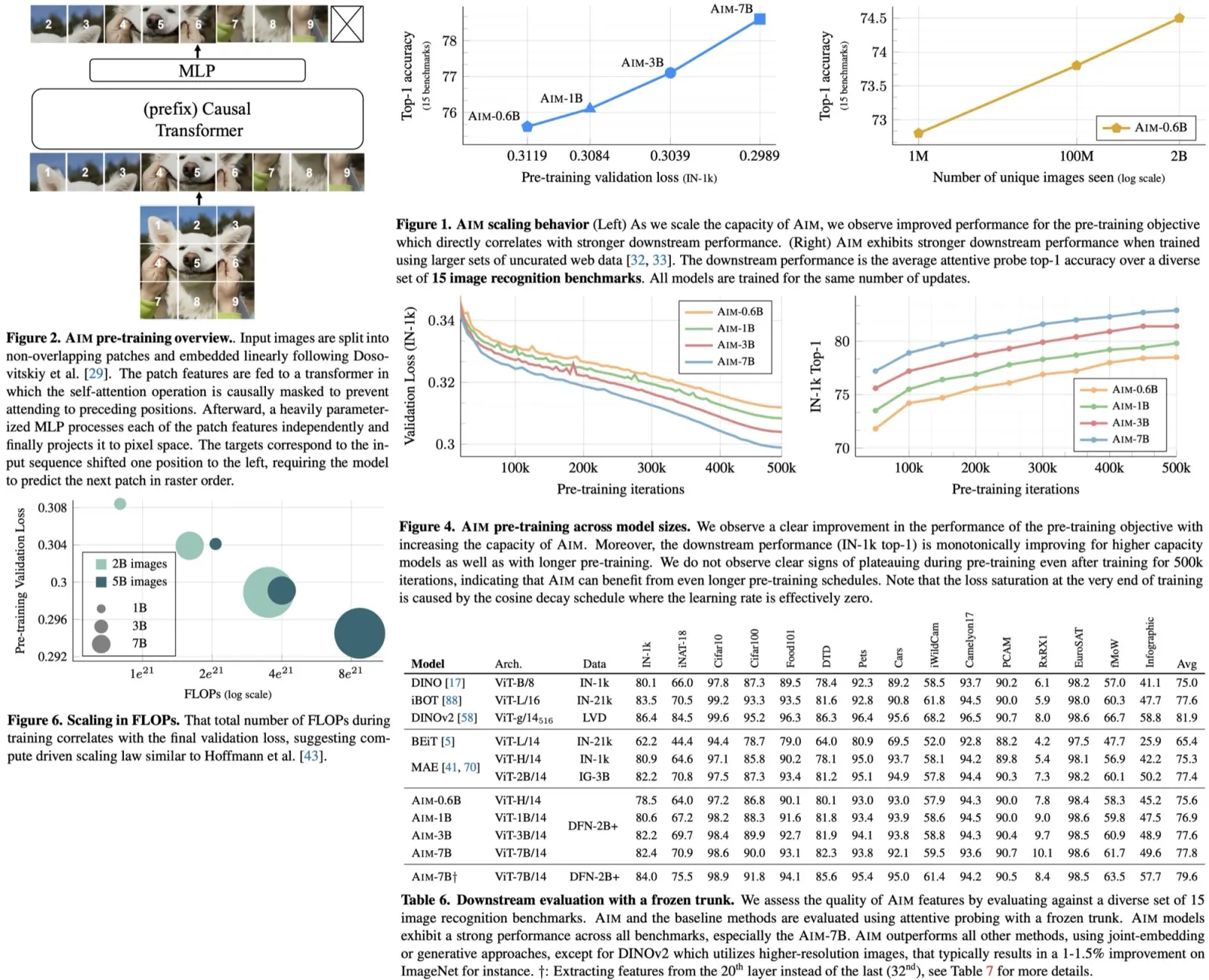
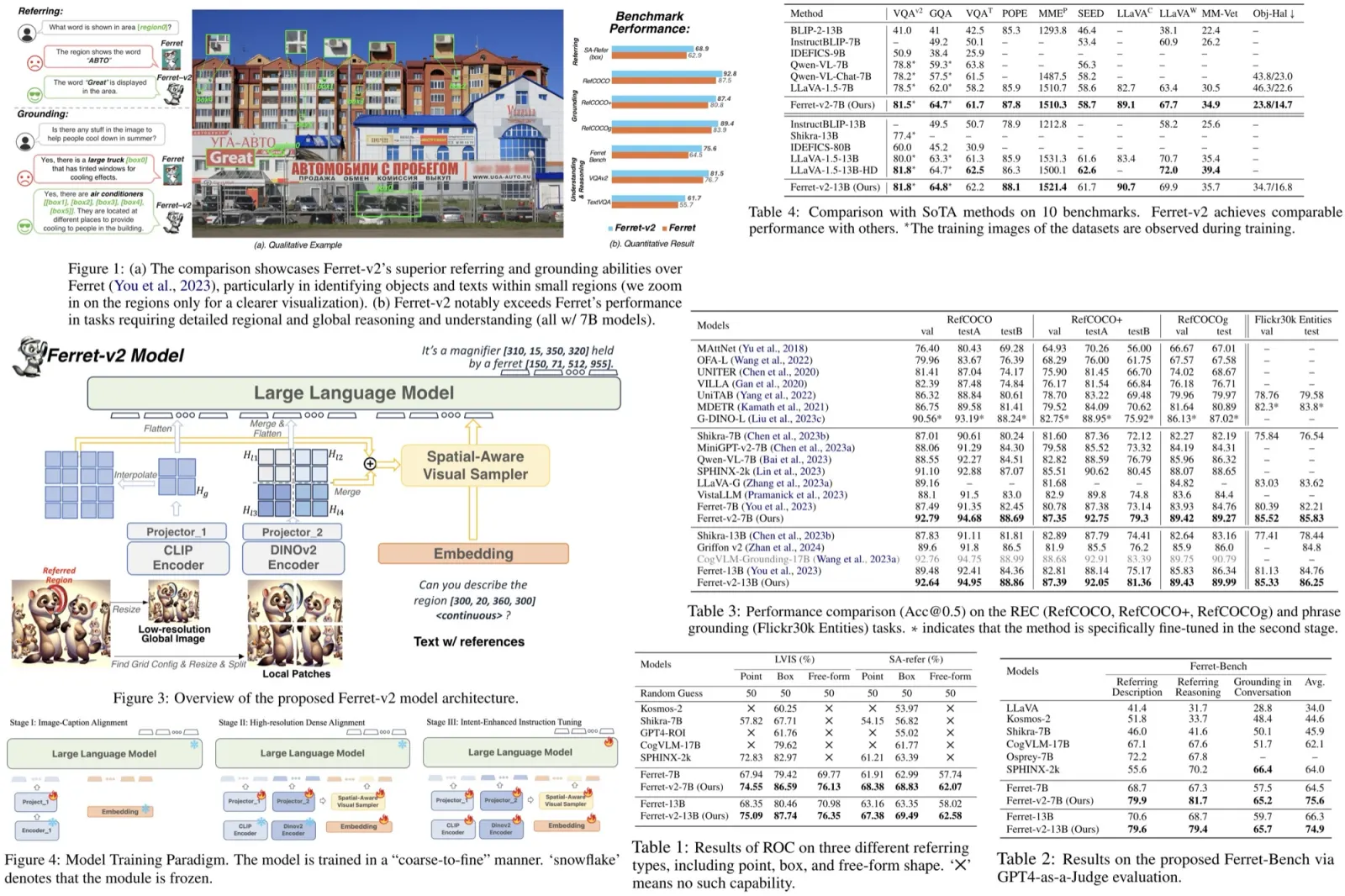
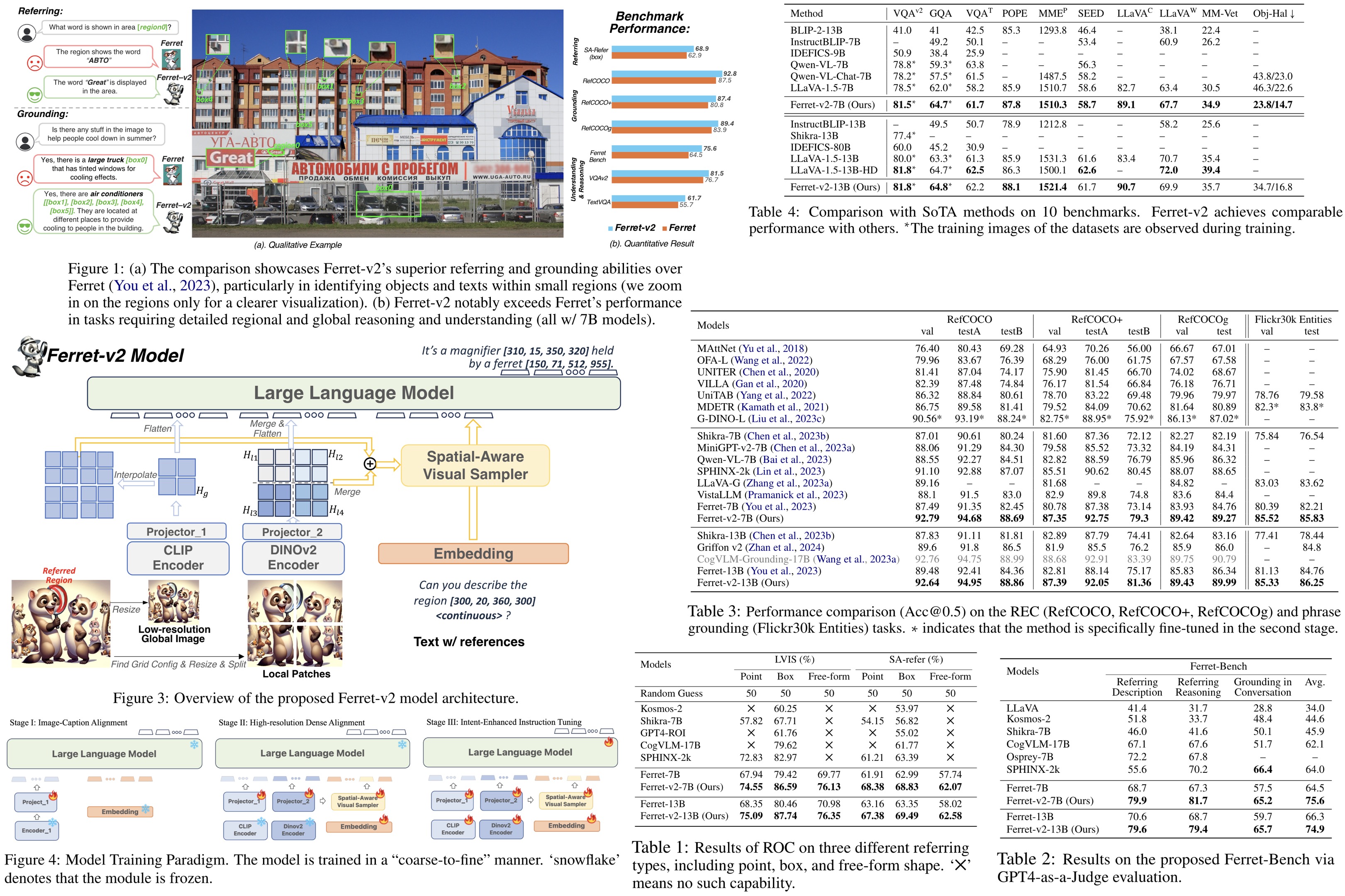
Ferret is an MLLM that excels in spatial referring and grounding within natural images, using a hybrid region representation. This representation combines discrete coordinate tokens, continuous region features, and region names when available, with coordinates normalized to a range from 0 to 999. The model uses a spatial-aware visual sampler for feature extraction and integrates these features with textual input into a decoder-only LM Vicuna. Ferret’s training consists of image-caption alignment and instruction-tuning stages. However, its performance is limited by the fixed resolution of its pre-trained encoder, leading to the development of Ferret-v2, which aims to enhance multimodal learning by addressing high-resolution scaling challenges.
Analysis of Higher Resolution Scaling
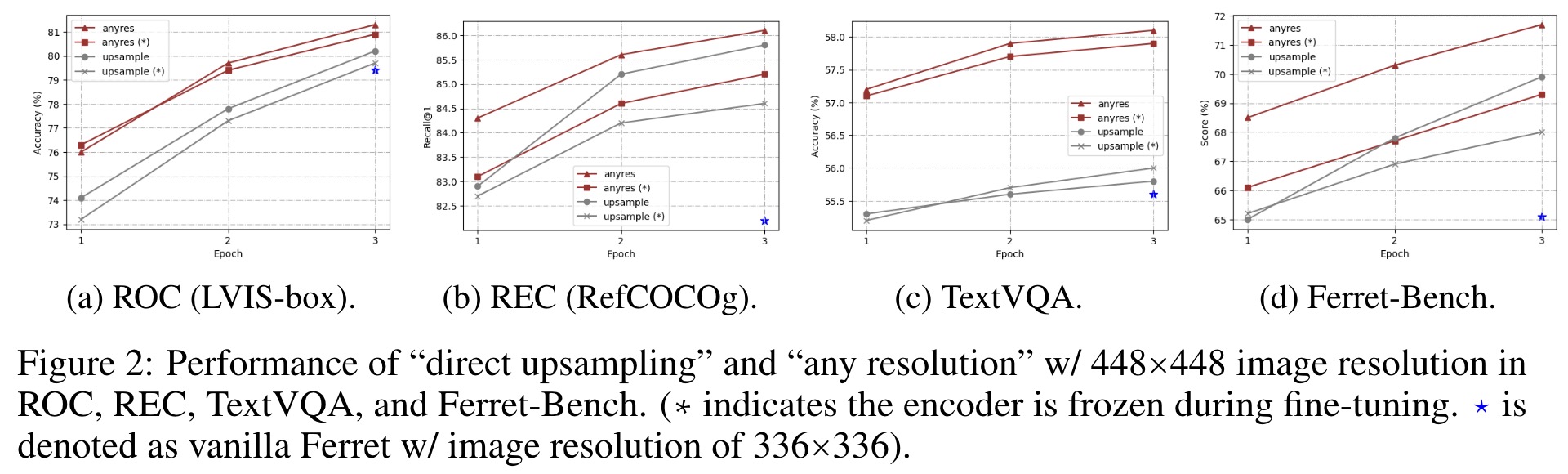
The authors compare two high-resolution scaling methods for language models: “direct upsampling,” which upscales images to a resolution of 448, and “any resolution,” which adjusts the resolution based on the image’s original aspect ratio and size. In the Ferret model, a linear layer is replaced by a two-layer MLP, and the model is trained on additional datasets for visual question answering and OCR tasks. Results indicate that “any resolution” significantly outperforms “direct upsampling.” This method preserves the encoder’s pre-training knowledge by processing image patches at similar token lengths to its original training, making it more effective for leveraging high-resolution images in language models.
Model architecture
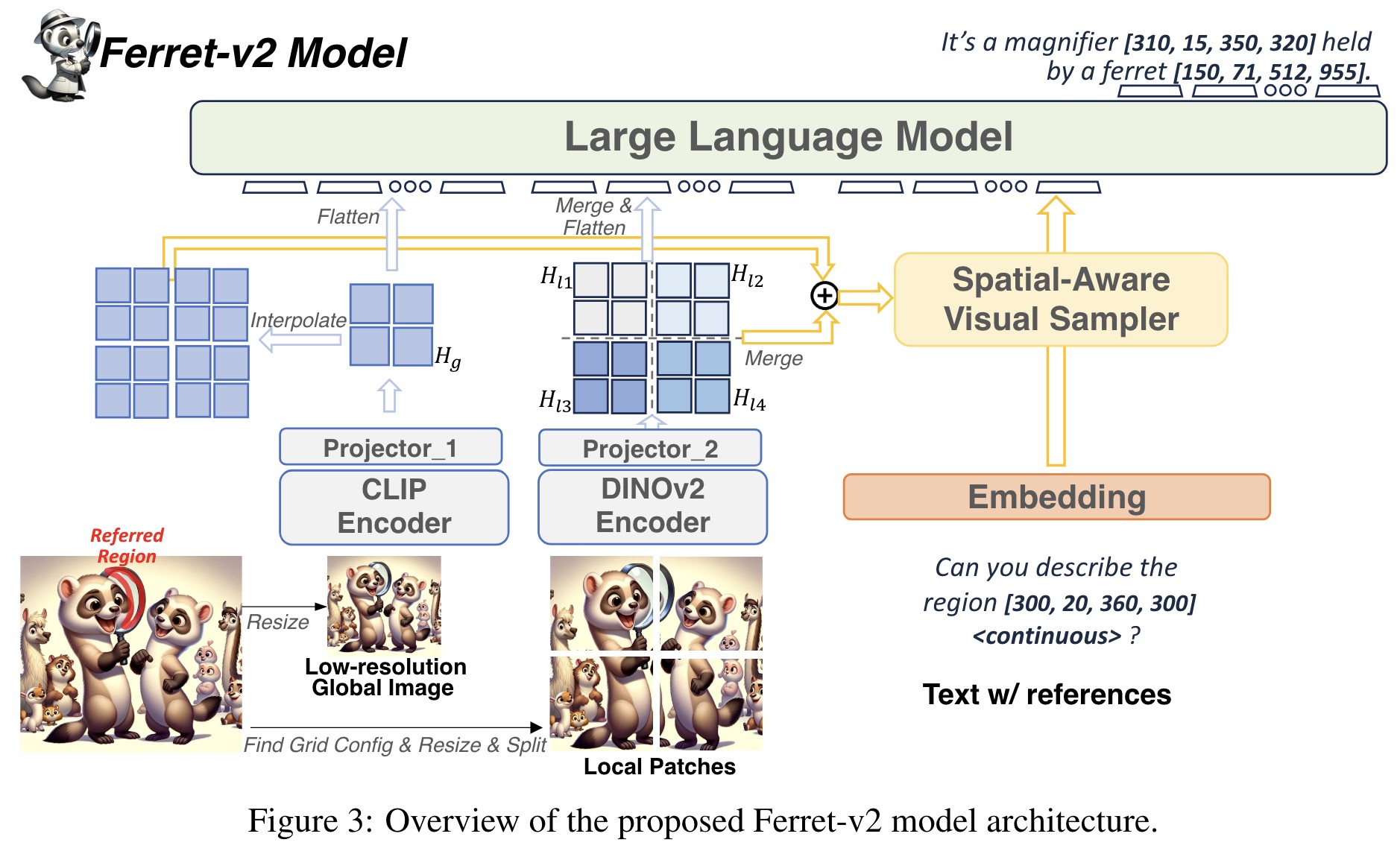
To tackle the challenge of analyzing images at multiple granularities, the authors encode global images and local patches with different encoders, CLIP and DINOv2, respectively. CLIP captures broad image semantics, while DINOv2 focuses on detailed local information. These are then integrated using separate MLP projectors, with features from local patches merged into a larger map and combined with upsampled global image features. This fusion creates a feature map rich in both detail and semantics, enhancing the model’s ability to perform referring and grounding tasks. The model effectively identifies and describes regions in images, combining detailed visuals with semantic context, thus improving its overall image analysis capabilities.
Training Paradigm
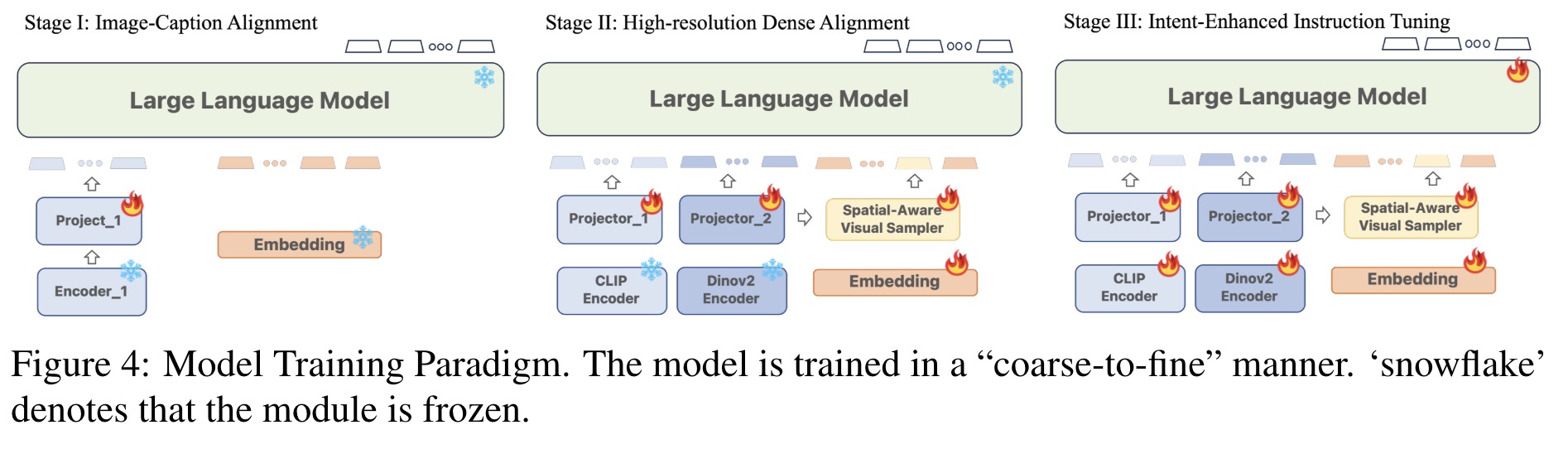
Image-Caption Alignment. At this stage the authors use uses 1.4 million image-text pairs to align the pre-trained CLIP encoder with an LLM. The visual sampler is not involved, and only the projector is trainable.
High-resolution Dense Alignment. To bridge the gap between the initial alignment and more detailed task requirements, this stage introduces dense alignment of images at a high resolution. It includes two tasks: Dense Referring, which classifies objects based on queried regions, and Dense Detection, which localizes objects in a raster scan order (from top to bottom, left to right). Data from the LVIS dataset is used; only the projectors and the visual sampler are updated in this stage.
Intent-Enhanced Instruction Tuning. The final stage aims to refine the model’s adherence to user instructions while maintaining its ability to process high-resolution images and detailed visual information. The encoders, projectors, region samplers, and LLM are set to be trainable. The model is trained on the GRIT dataset along with additional datasets for tasks like VQA and OCR. Additionally, the authors use Data Unification (use GLIPv2 to localize groundable nouns in the text on VQA datasets and a public OCR model to get text bounding boxes on OCR datasets) and Task Generalization (update the prompt to diminish ambiguity across different tasks).
Experiments
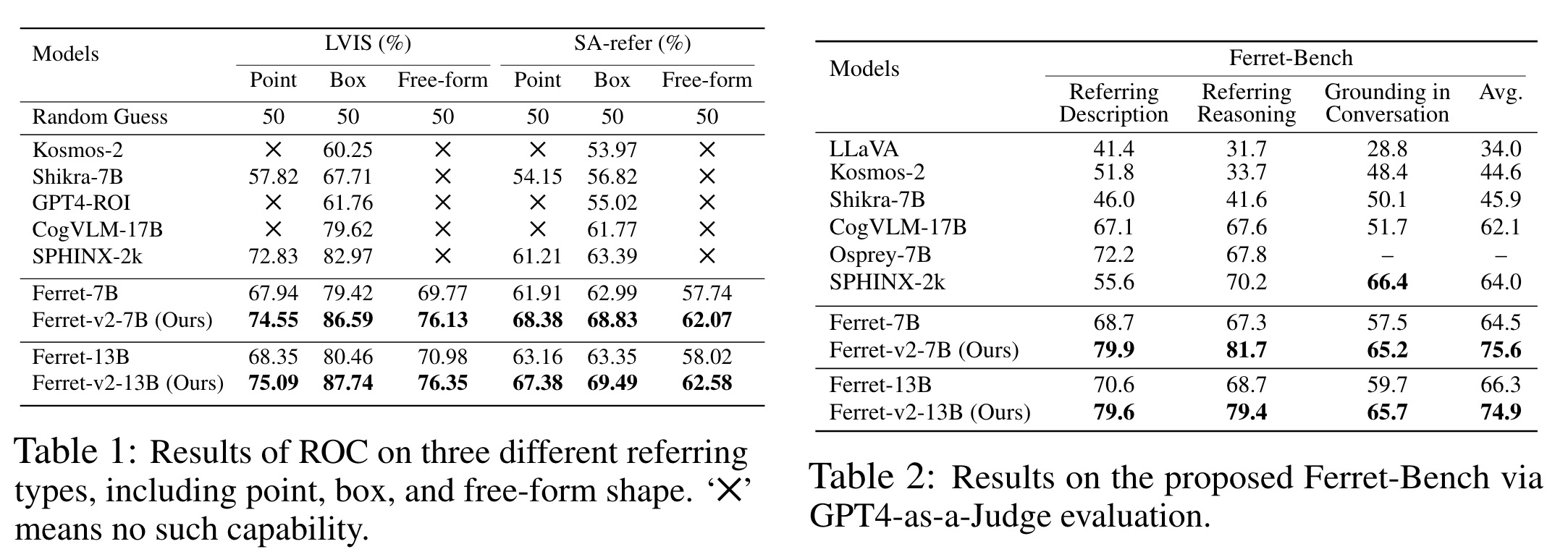
Ferret-v2 shows marked improvements in handling referential queries within images, particularly through the Referring Object Classification task. It uses the LVIS dataset and a specially compiled “in-the-wild” evaluation set, SA-refer, which includes high-resolution images and detailed object annotations, to demonstrate its superior ability to reference and classify small and detailed objects.
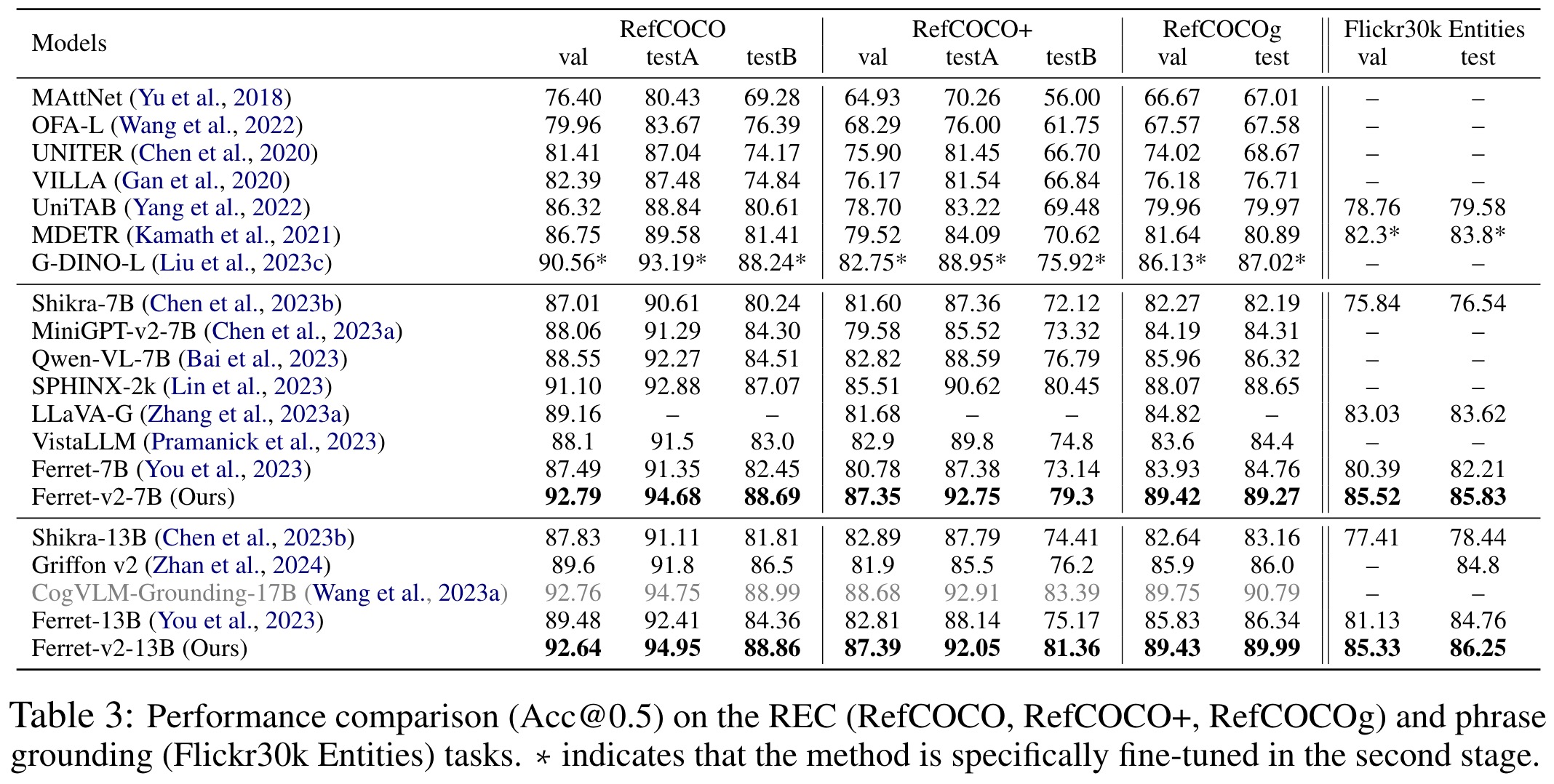
Ferret-v2’s capabilities are further highlighted in visual grounding tasks using datasets like RefCOCO, RefCOCO+, RefCOCOg, and Flickr30k Entities, where it significantly outperforms both Ferret and other state-of-the-art models by utilizing high-resolution images effectively.
Additionally, Ferret-v2’s performance in the multimodal Ferret-Bench benchmark, designed to evaluate models’ abilities to refer to and reason about specific image regions, underscores its strong spatial understanding and commonsense reasoning capabilities.
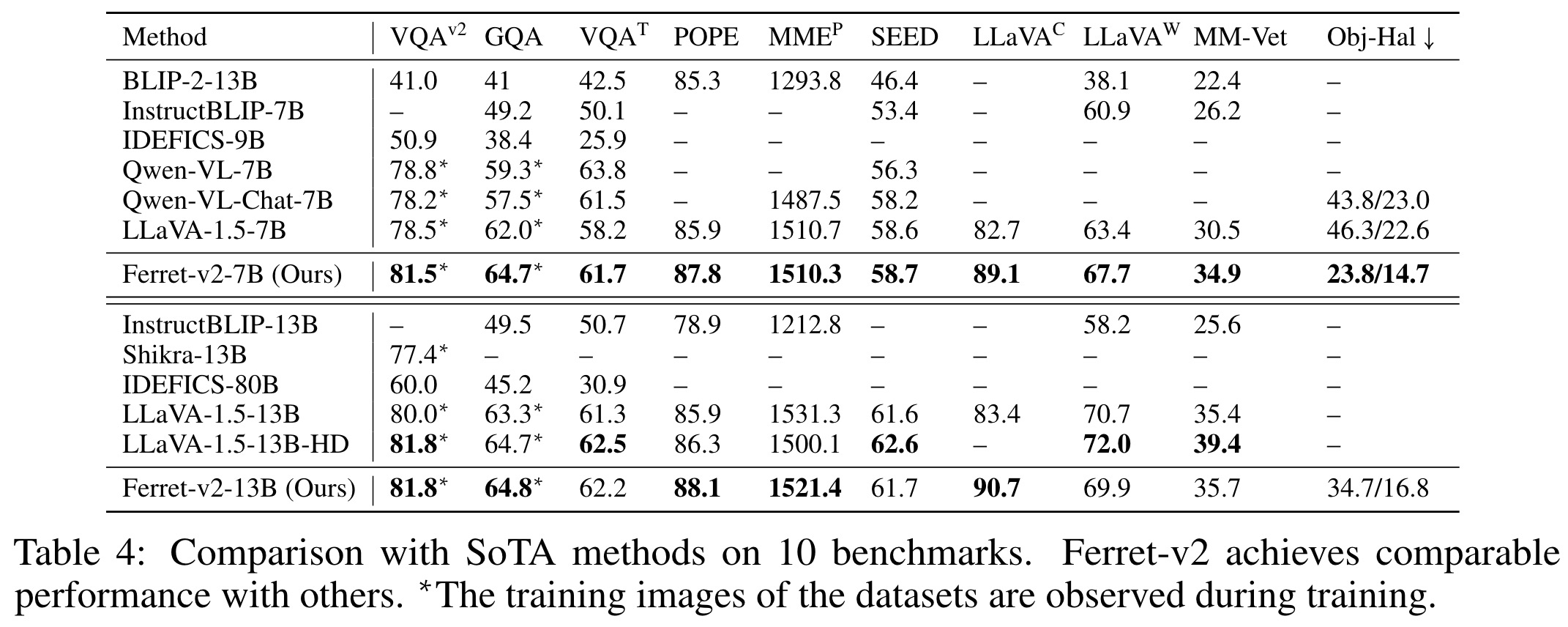
Ferret-v2 addresses the limitations of the original Ferret model by including pseudo-labeled VQA and OCR datasets and a special prompt to enhance its performance on task-specific datasets. This addition helps bridge the gap between fine-grained regional analysis and more generalized tasks, thereby broadening Ferret-v2’s applicability to both detailed and coarse-grained tasks. Benchmarked across ten different datasets, Ferret-v2 matches or exceeds the performance of current state-of-the-art MMLMs, showing particular strength in tasks like VQAv2 and GQA, which require precise spatial information for accurate responses.
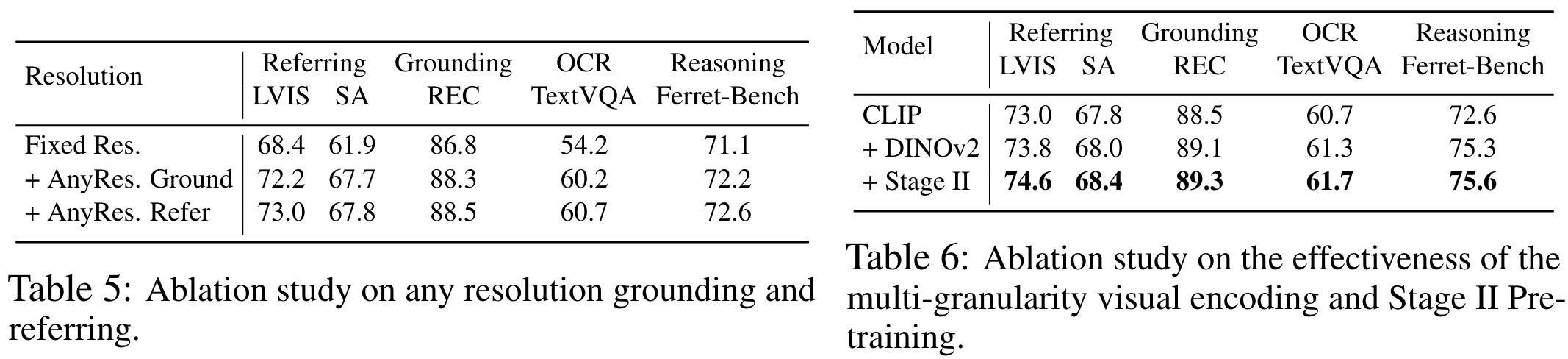
The ablation studies show that accommodating any resolution significantly boosts performance in tasks that require detailed high-resolution understanding, improving precision in referring tasks across LVIS and SA datasets while also modestly enhancing grounding capabilities. Using CLIP and DINOv2 leads to notable improvements in both referring and grounding tasks.
paperreview deeplearning llm cv mllm multimodal