Paper Review: Language-agnostic BERT Sentence Embedding
One more state-of-the-art paper from Google. They adapt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages. State-of-the-art on Tatoeba, BUCC, and UN.
General approach
Usually, masked language models don’t produce good sentence-level embeddings - they need to be fine-tuned for the specific task. And multilingual sentence embedding models use dual encoder, but don’t usually perform MLM pre-training.
So the authors decided to train multilingual sentence embeddings combining state-of-the-art for multilingual sentence embeddings with MLM and encoders from a translation language model.
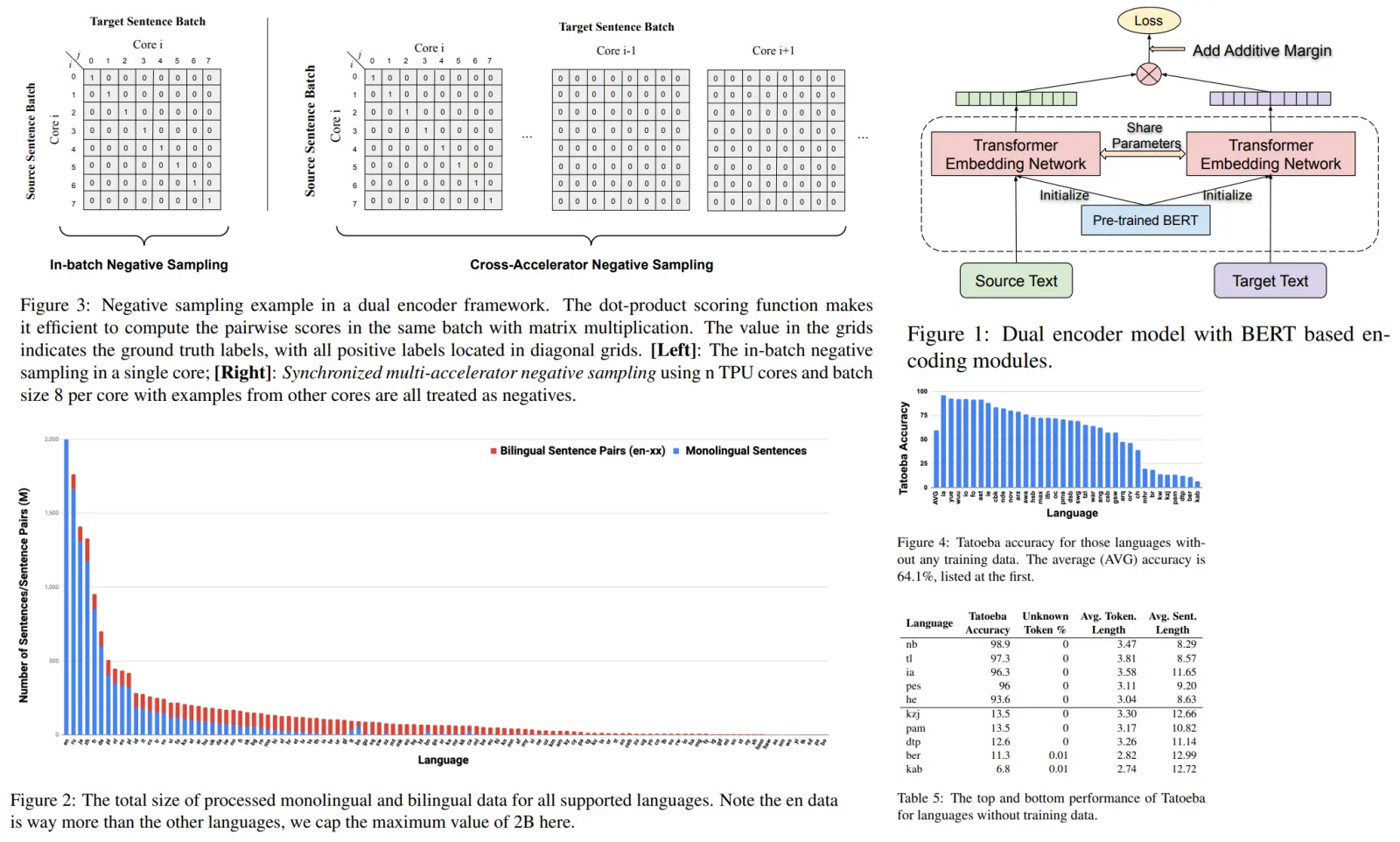
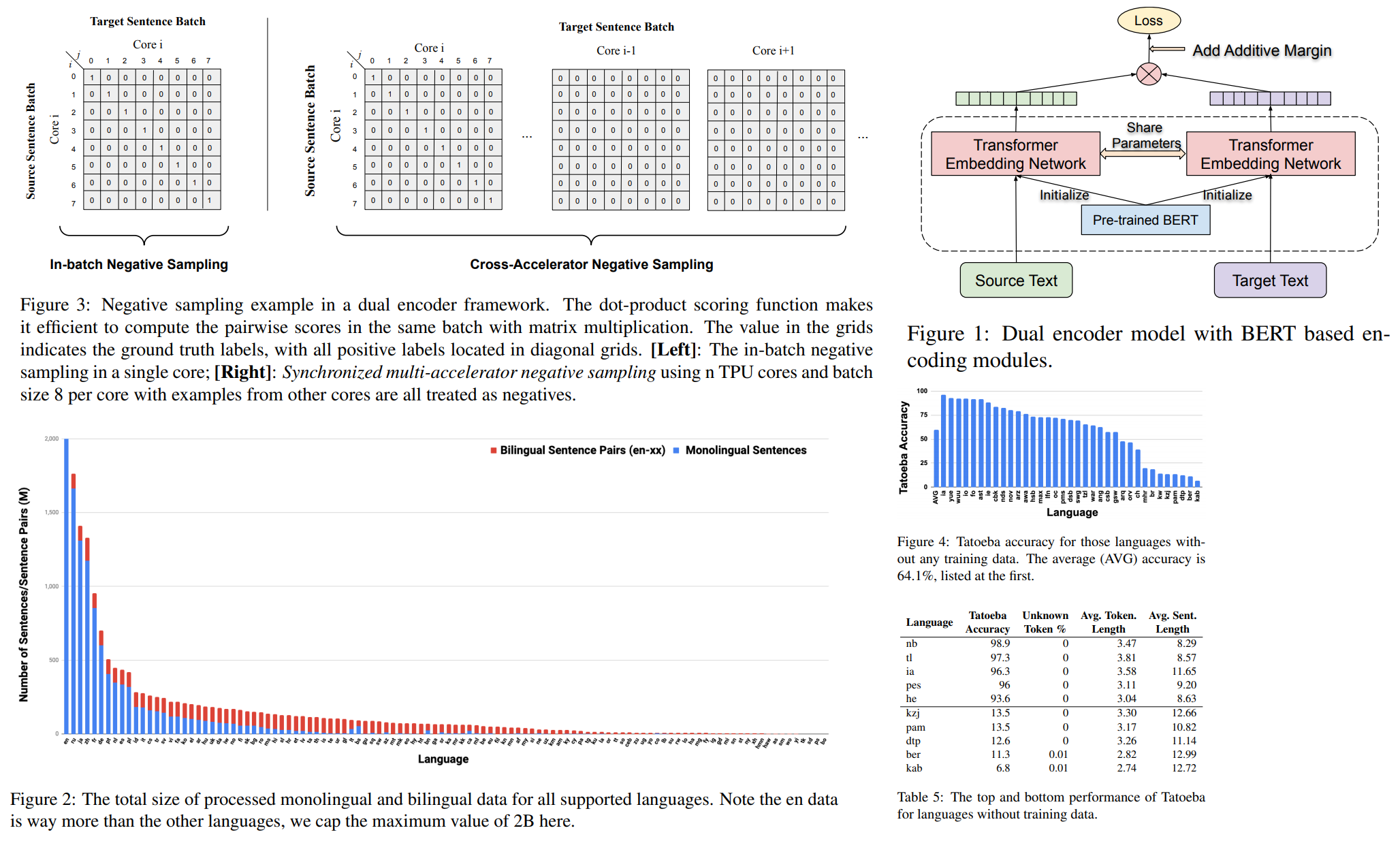
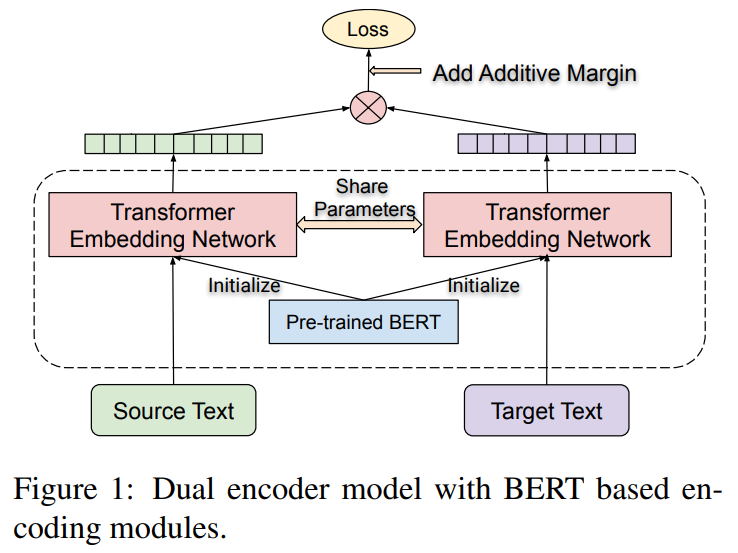
They use a dual-encoder framework with an additive margin softmax loss. Source and target sentences are encoded separately using a shared BERT-based encoder. The final layer representations are taken as the sentence embeddings for each input. The similarity between the source and target sentences is scored using cosine over the sentence embeddings produced by the BERT encoders
As a result, they reach new state-of-the-art results, especially for languages with limited data.
Corpus
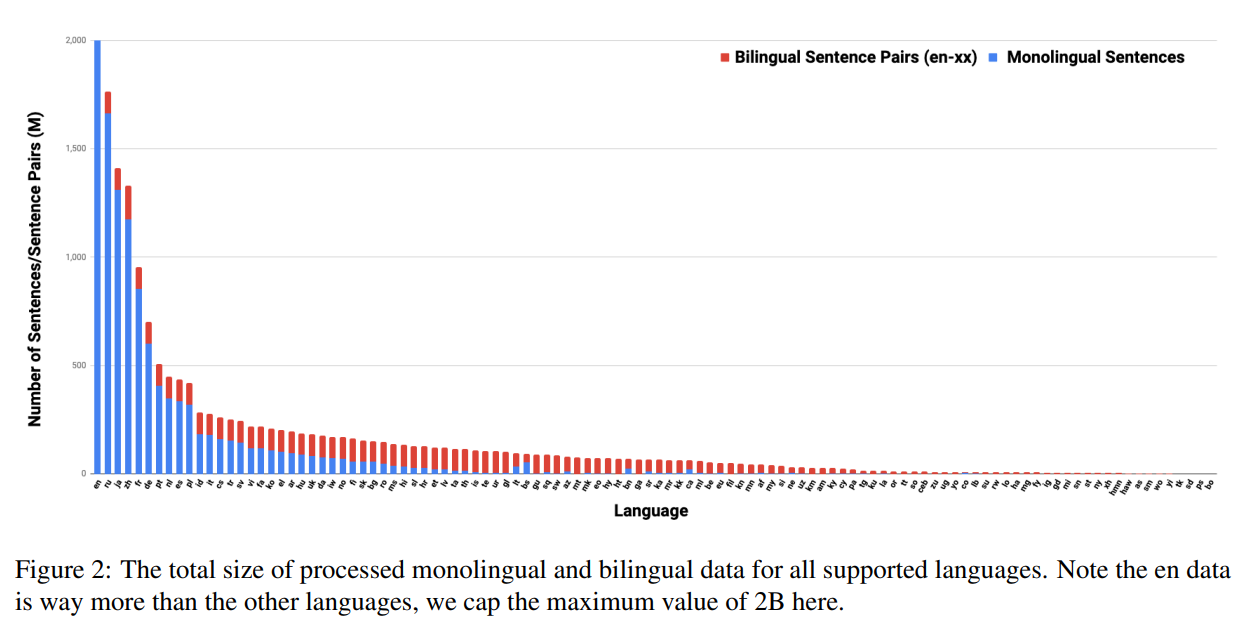
Monolingual Data from CommonCrawl and Wikipedia. 17B monolingual sentences in total. Bilingual Translation Pairs from the web pages using a bitext mining system. Then they did a lot of filtering. 6B translation pairs in total.
Model
Bidirectional Dual Encoder with Additive Margin Softmax


Cross-Accelerator Negative Sampling

Pre-training and parameter sharing
The encoder is pre-trained with Masked Language Model and Translation Language Model.
They use 3 stages progressive stacking algorithm: if there are L layers, then at first they learn a model with L/4 layers, then L/2 layers and then L layers. Parameters from earlier stages are copied into later stages.
Model training
12 layers transformer with 12 heads and 768 hidden size. Trained on 32-core slices of Cloud TPU V3 pods. batch size 2048, max sequence length 64. margin value 0.3
Model is trained on 50k steps (less than 1 epoch). AdamW, lr 1e-5, weight decay.
During training, the sentence embeddings (after normalization) are multiplied by a scaling factor of 10.
All parameters are tuned on a hold-out development set. :notbad:
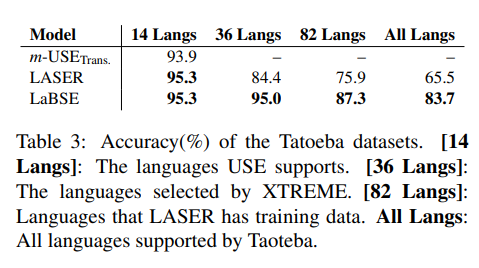
Results
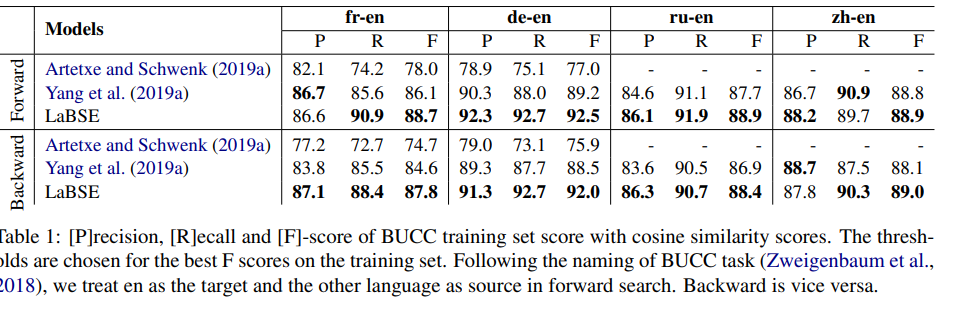
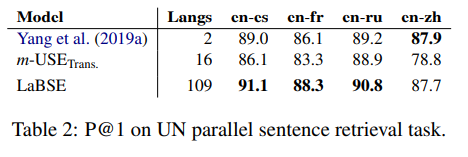
Analysis
- The additive margin is very important. With 0 value, model performance is low (60s or 70s P@1 on UN). With 0.1 the performance is much better (80+ P@1). Higher values perform better on certain tasks
- Pre-training. Very important (we could never guess this, right?)
- Comparison to Multilingual BERT. LaBERT is much better on languages that have fewer data. Possible reasons: larger vocab (500k vs 30k), TLM pre-training, pre-training not only on wiki but also on commoncrawl
- Importance of the Data Selection. The LaBSE models are trained with the data selected by a pre-trained contrastive data selection (CDS) model. The authors tried to train a model on original crawled data - the results were much worse. This means the model is sensitive to data quality (again, we could never guess this, right?)
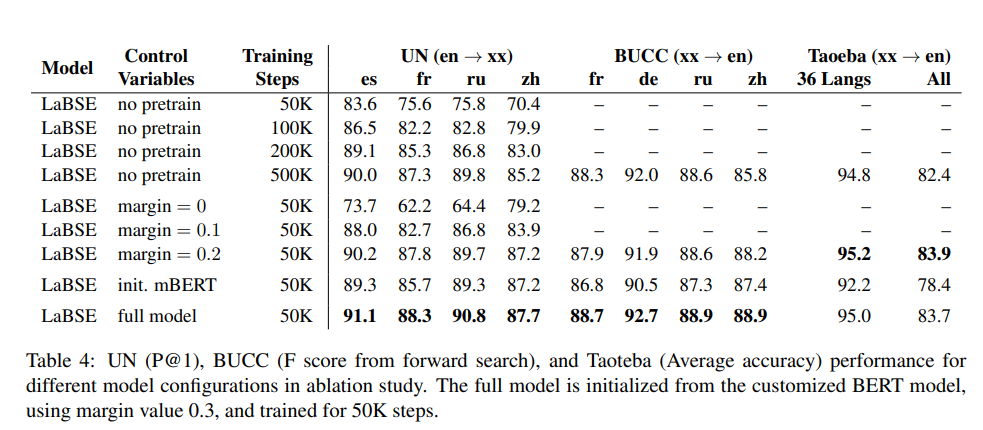
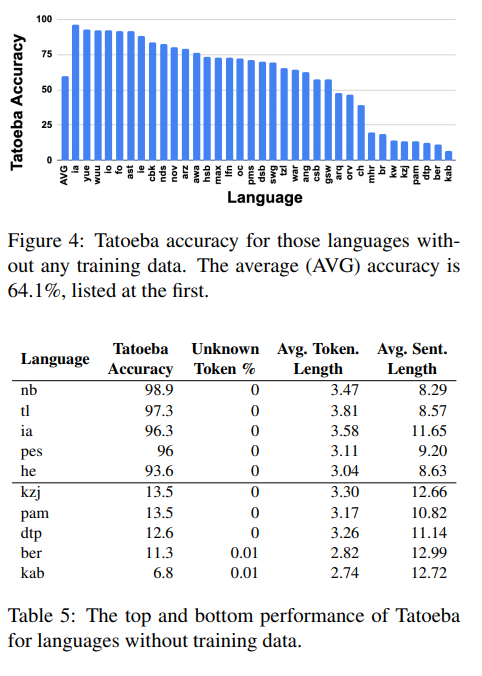
Zero-shot Transfer to Languages without Training Data