Paper Review: Masked Attention is All You Need for Graphs

Graph neural networks (GNNs) and message passing algorithms are widely used for learning on graphs but require significant research and handcrafted designs. Masked attention for graphs (MAG) offers a simpler alternative by using attention mechanisms exclusively. MAG represents graphs as node or edge sets and enforces connectivity by masking the attention weight matrix. This method achieves state-of-the-art performance on long-range tasks and outperforms message passing baselines and other attention-based methods in over 55 tasks. MAG also shows better transfer learning capabilities and efficient time and memory scaling compared to GNNs, making it suitable for dense graphs.
Preliminaries
Graphs are defined by a set of nodes and edges, where each node and edge has associated feature vectors. The connectivity of the graph can be represented using an adjacency matrix, though using an edge list is often more practical. GNNs use a message passing framework to update node features based on their neighbors’ features and edge information.

The Set Transformer is an attention-based architecture designed for learning on sets. It uses multihead attention blocks, self-attention blocks, and pooling by multihead attention blocks.
Recent advancements in efficient attention mechanisms, such as Flash attention, have enabled exact attention with better memory scaling and faster training times by optimizing the use of modern GPU architecture. These methods allow self-attention to scale more efficiently in terms of memory, providing comparable runtime performance to standard implementations.
Masked attention for graphs
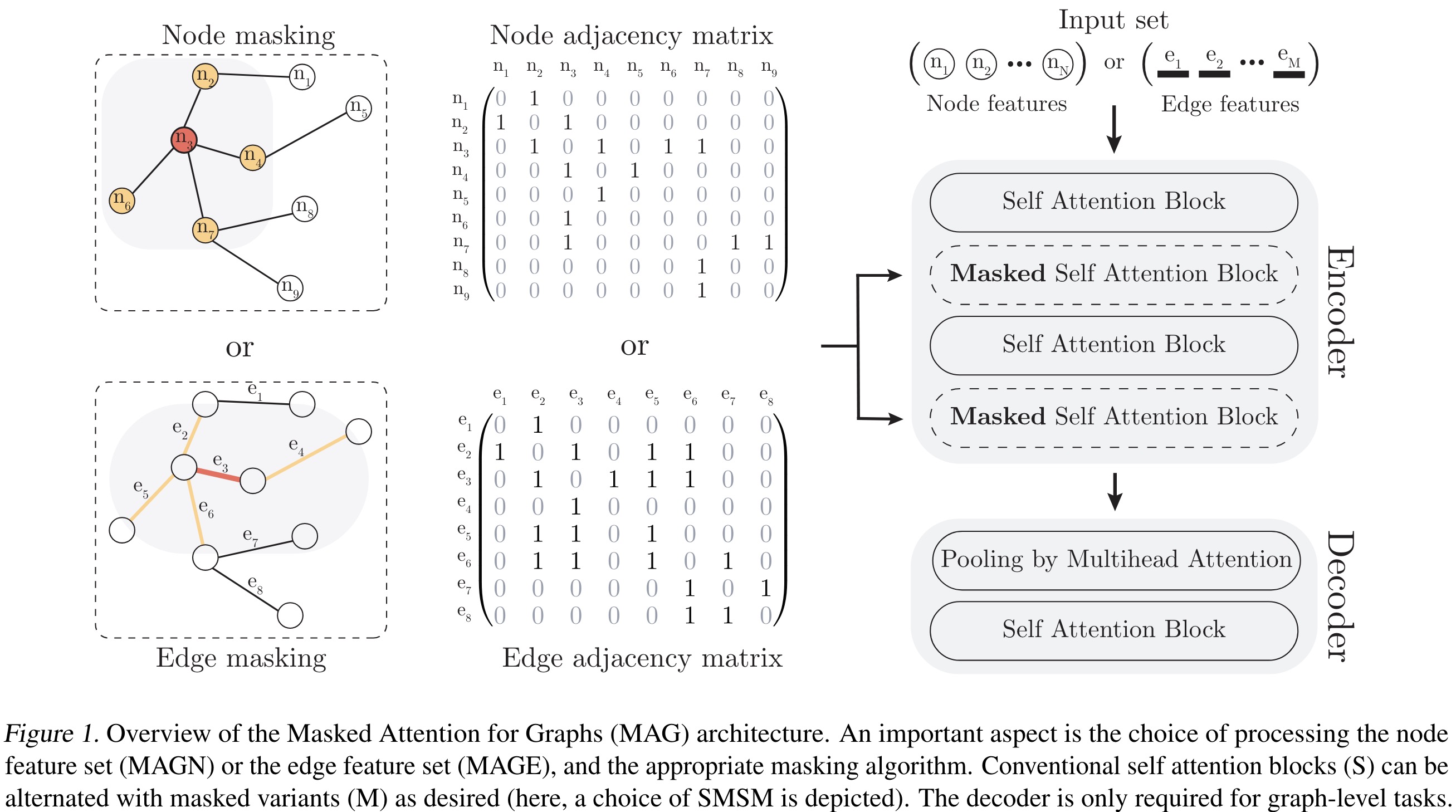
Graph learning is formulated as a learning problem on sets, applying attention directly to node or edge feature matrices using self-attention blocks. MAG incorporates graph structure by masking the pairwise attention weight matrix based on adjacency information. MAG supports two modes of information propagation: on nodes (MAGN) using the node feature matrix, and on edges (MAGE) using the edge feature matrix.

The Set Transformer is extended with masked multihead attention blocks and SABs, utilizing masks that restrict attention to adjacent nodes or edges sharing a common node. These masks are computed dynamically for each batch.

The MAG architecture consists of an encoder with alternating MSAB and SAB blocks, and a PMA-based decoder. It uses a pre-layer normalization architecture with optional MLPs after multihead attention. For graph-level tasks, the PMA module serves as the readout function, fully based on attention, while for node-level tasks, the PMA is not needed.
Experiments
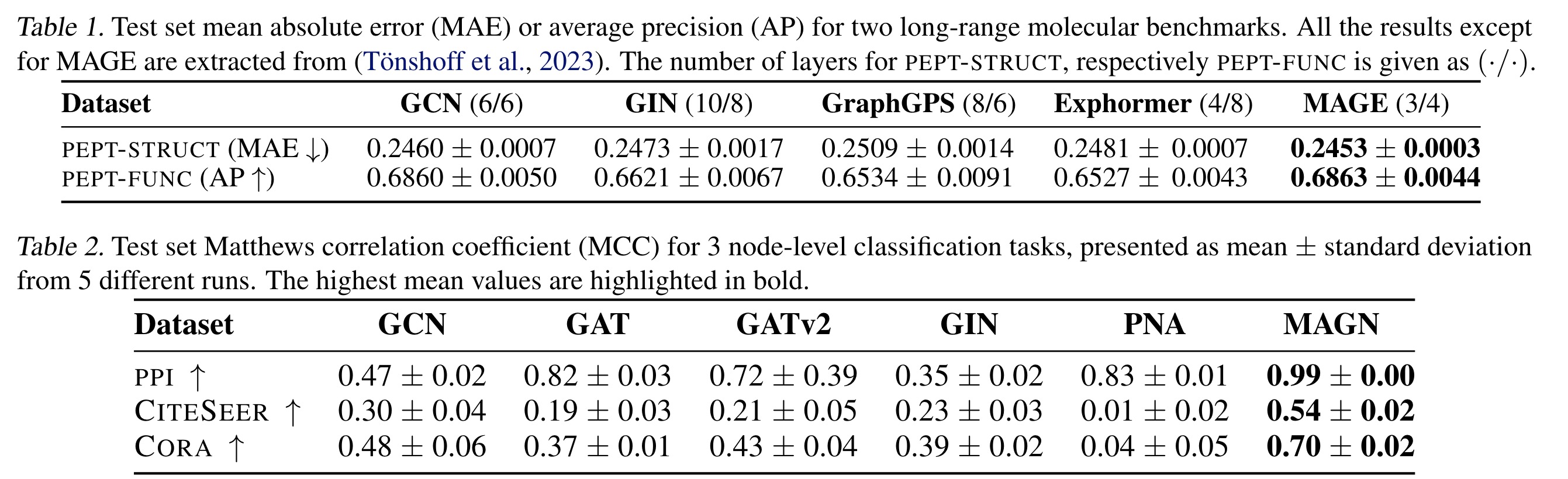
On long-range molecular tasks MAGE outperformed GraphGPS, Exphormer, GCN, and GIN. MAGE achieved top results on the PEPT-STRUCT and PEPTFUNC leaderboards, despite using fewer layers. It is notable for being exclusively based on attention without any positional encoding and is general-purpose.
For node-level tasks, typically involving citation networks, MAGN outperformed other methods significantly. Some methods like Graphormer and TokenGT were not suitable for node-level classification due to large graph sizes.
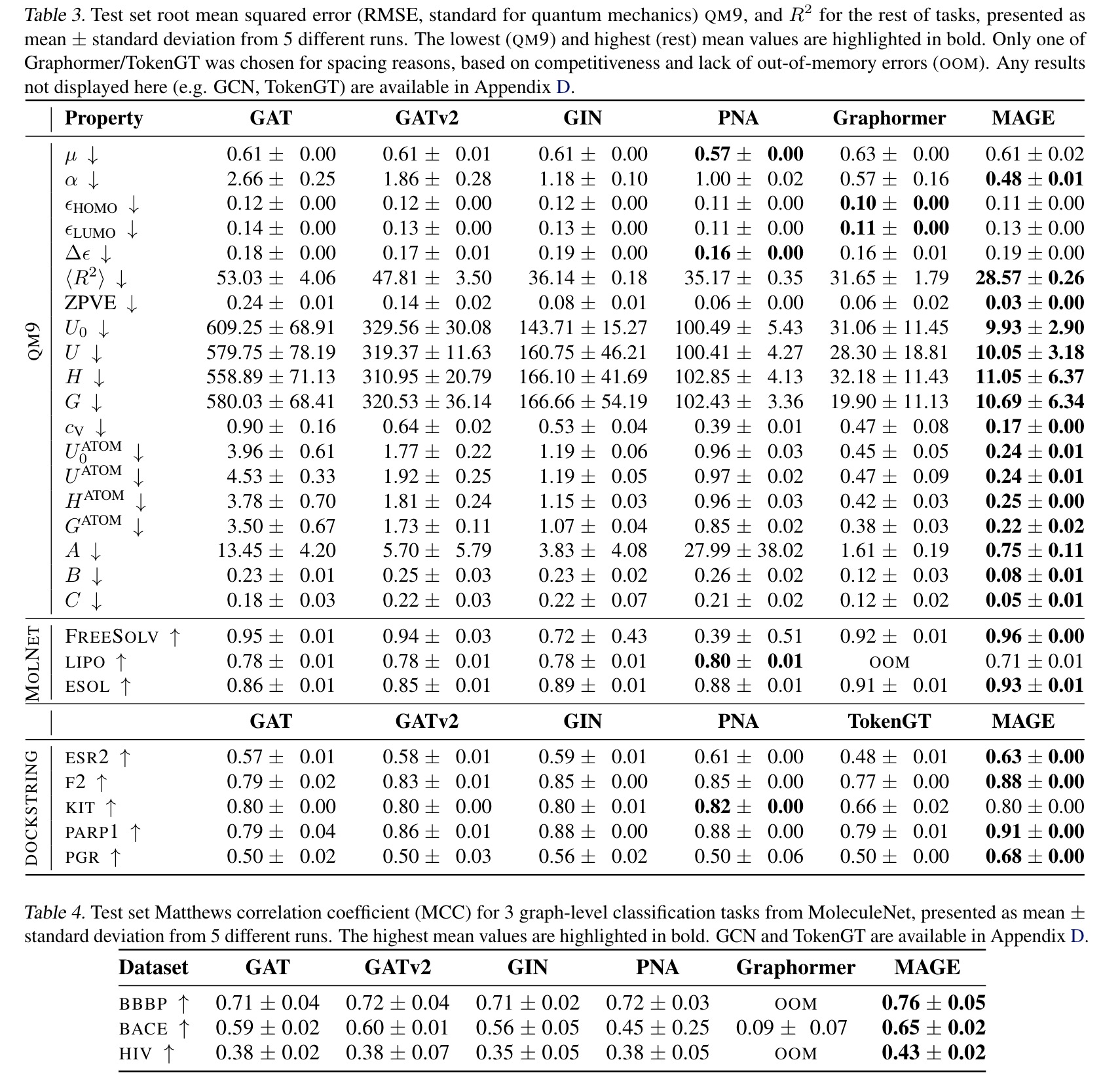
MAGE performed best on most graph-level tasks, thought it lagged on some of them due to quick convergence issues. In the DOCKSTRING benchmark, MAGE excelled on four out of five tasks, particularly on the most difficult target (PGR).
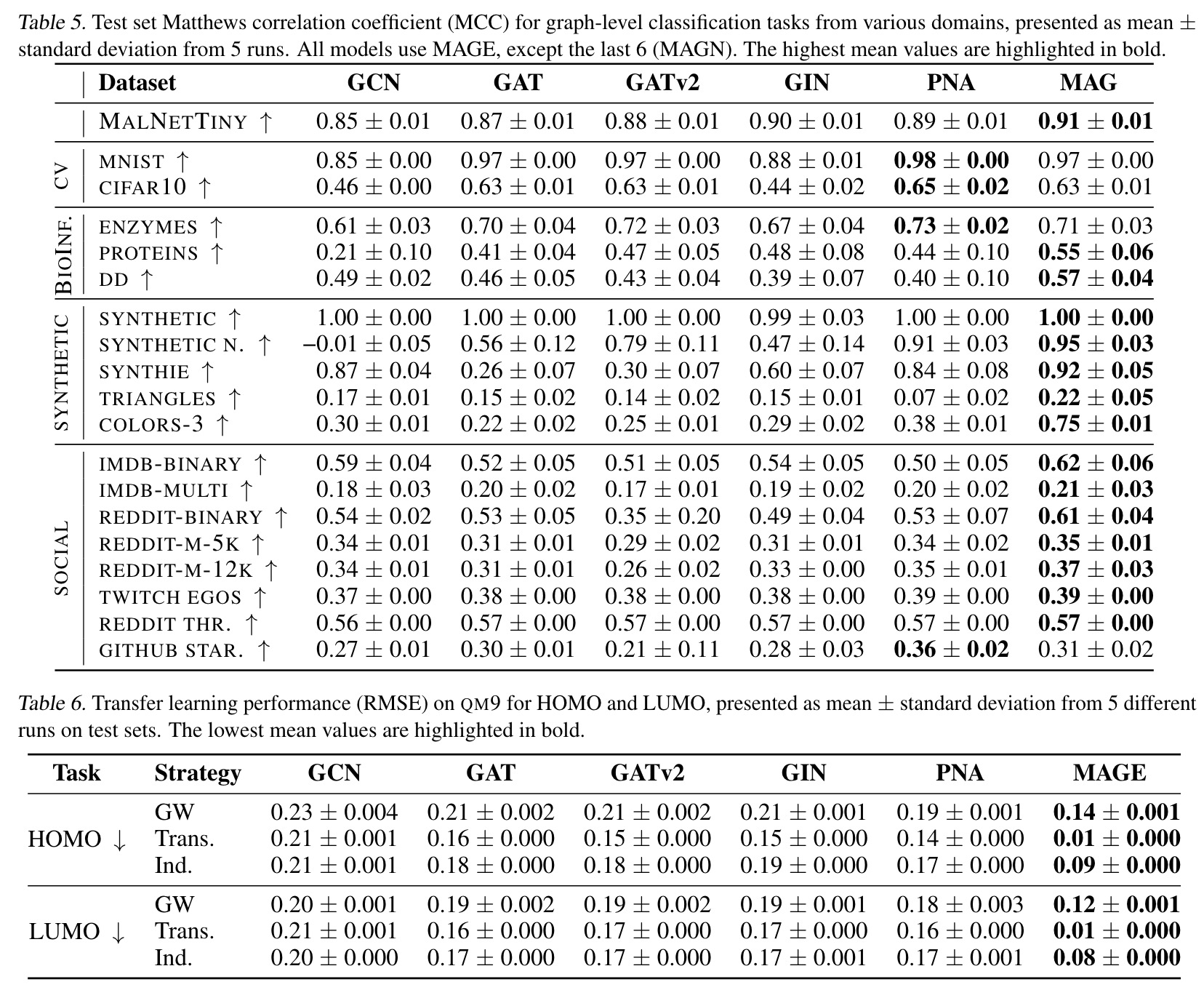
Transfer learning improved MAGE’s performance significantly, showing a 45% improvement for HOMO and 53% for LUMO in the inductive case, with even greater improvements in the transductive case. GNNs showed only modest improvements.
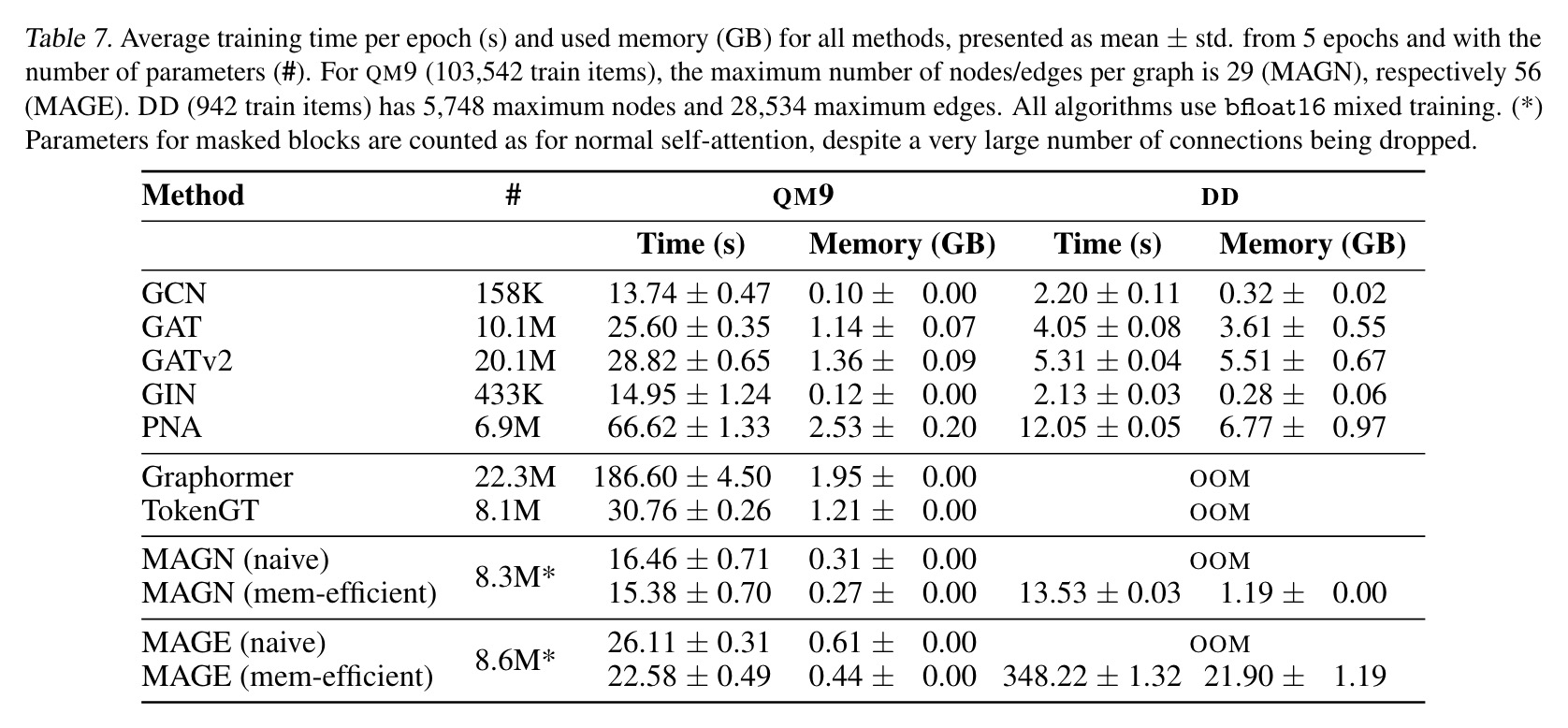
MAG’s most computation-intensive component is the encoder, which performs masked self-attention efficiently with O(N ** 0.5) memory complexity. The decoder uses cross-attention and benefits from Flash attention, resulting in efficient time and memory scaling. MAGE runs effectively with up to 30000 edges on a consumer GPU with 24GB, demonstrating competitive time and memory utilization.
paperreview deeplearning graph transformer attention gnn