Paper Review: MDETR – Modulated Detection for End-to-End Multi-Modal Understanding

The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder. Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering. Furthermore, the model is capable of handling the long tail of object categories.
MDETR is based on DETR; you can read my review on it here.
MDETR takes only free-form text and aligned boxes as input, and, as a result, it can detect nuanced concepts from the text and generalize to new combinations of categories and attributes.
The architecture
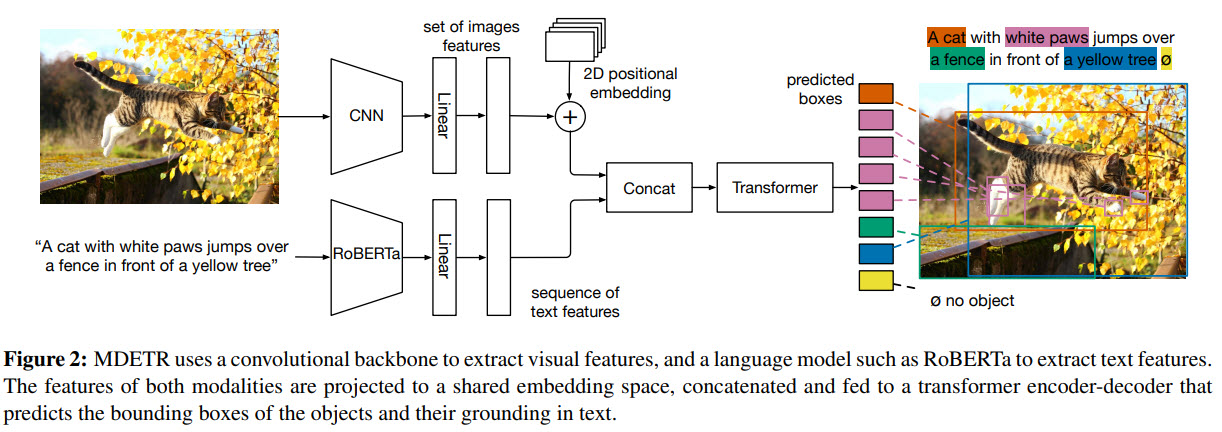
- The image is encoded by some backbone, for example, ResNet-18;
- The text is encoded with a pre-trained language model, for example, DistilRoberta from HuggingFace. The output has the same size as the input;
- There are separate linear layers on top of each embedding; their outputs are concatenated and fed into a joint transformer encoder (they call it the cross encoder);
- Transformer decoder takes not only the output of the encoder but also object queries (like DETR);
Training
The authors present two new loss functions.
Soft token prediction
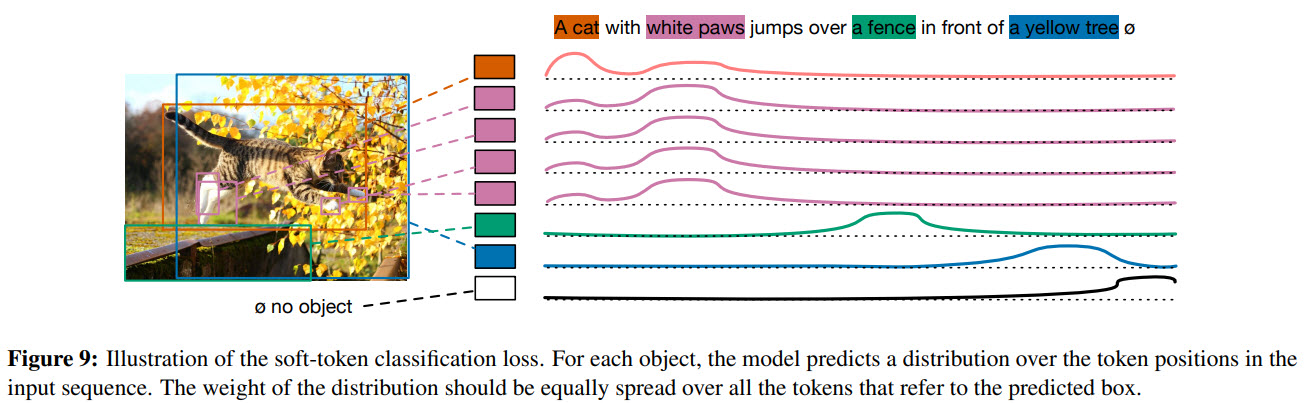
We are interested in predicting spans of texts (and not classes) for detected objects for modulated detections.
The idea is the following:
- set the maximum number of tokens in a sentence to 256;
- for each predicted box (which is matched to ground-truth boxes) model predicts a distribution over all token positions;
- several words can correspond to a single object and vice versa;
Contrastive alignment

While the previous loss used positional information to align objects to the texts, this loss uses embedded representations of objects and texts to align them.
Experiments
The authors perform two separate groups of experiments: on synthetic data from the CLEVER dataset and then on real-world images.
Synthetic data
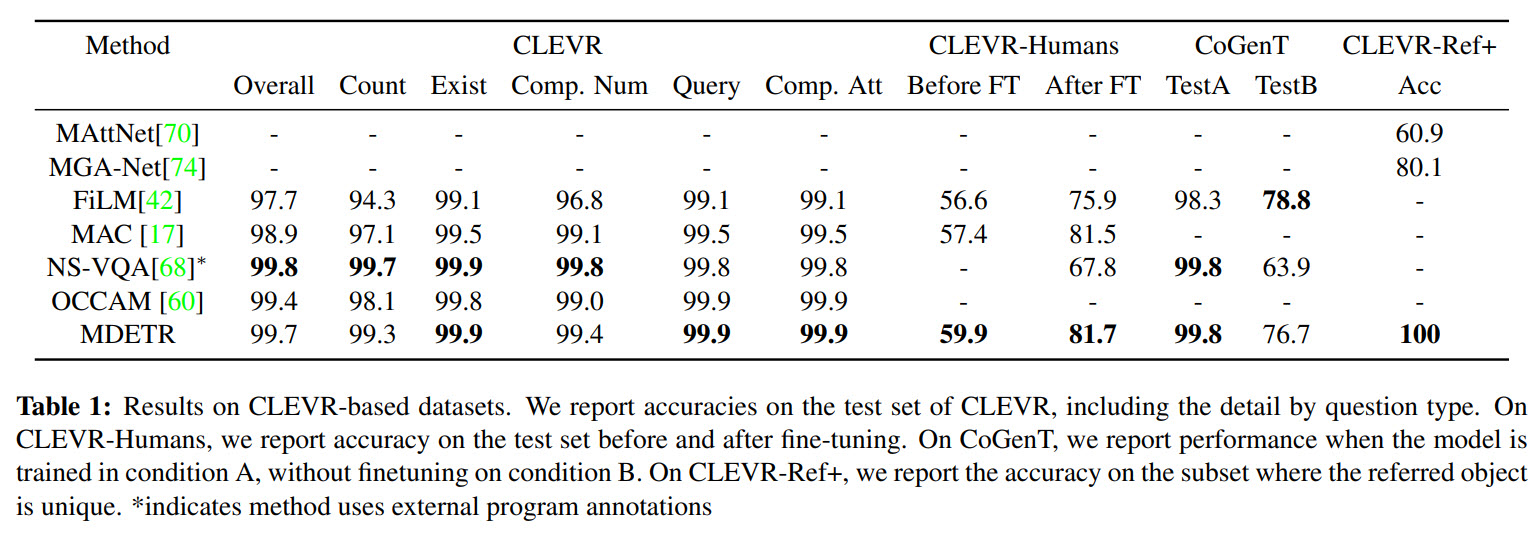
This dataset is quite simple for visual understanding, but the questions themselves can be quite complex. There are no bounding boxes in this dataset, so the authors use scene graphs to make them and utilize only the objects referred to in the question.
CLEVR-Humans - a dataset with human-generated questions, so it tests models in a zero-shot setting.
CLEVR-REF+ - a dataset for expression comprehension. Their model achieves 100% accuracy.
Natural images

The authors make their own dataset for pre-training using data from Flickr30k, MS COCO, Visual Genome. In total, the dataset has 1.3M aligned image-text pairs.
The model consists of EfficientNetB3 Noisy Student and RoBERTa-base.
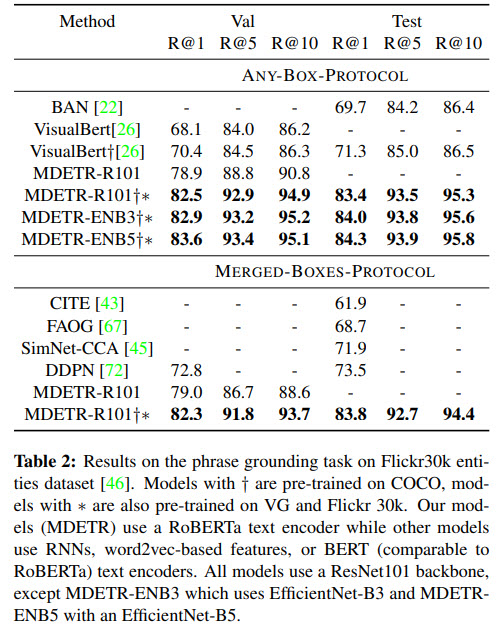
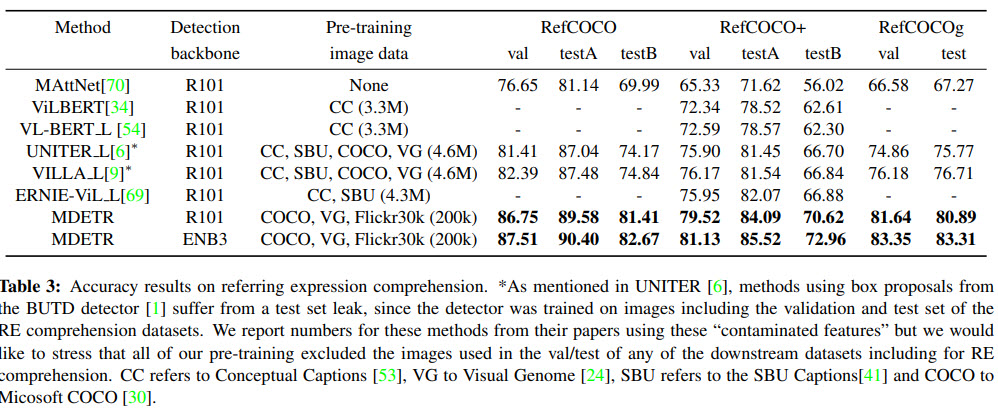
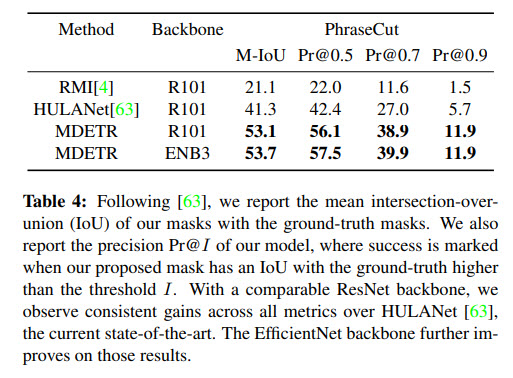
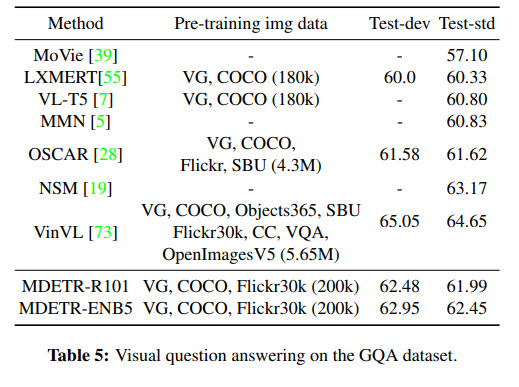
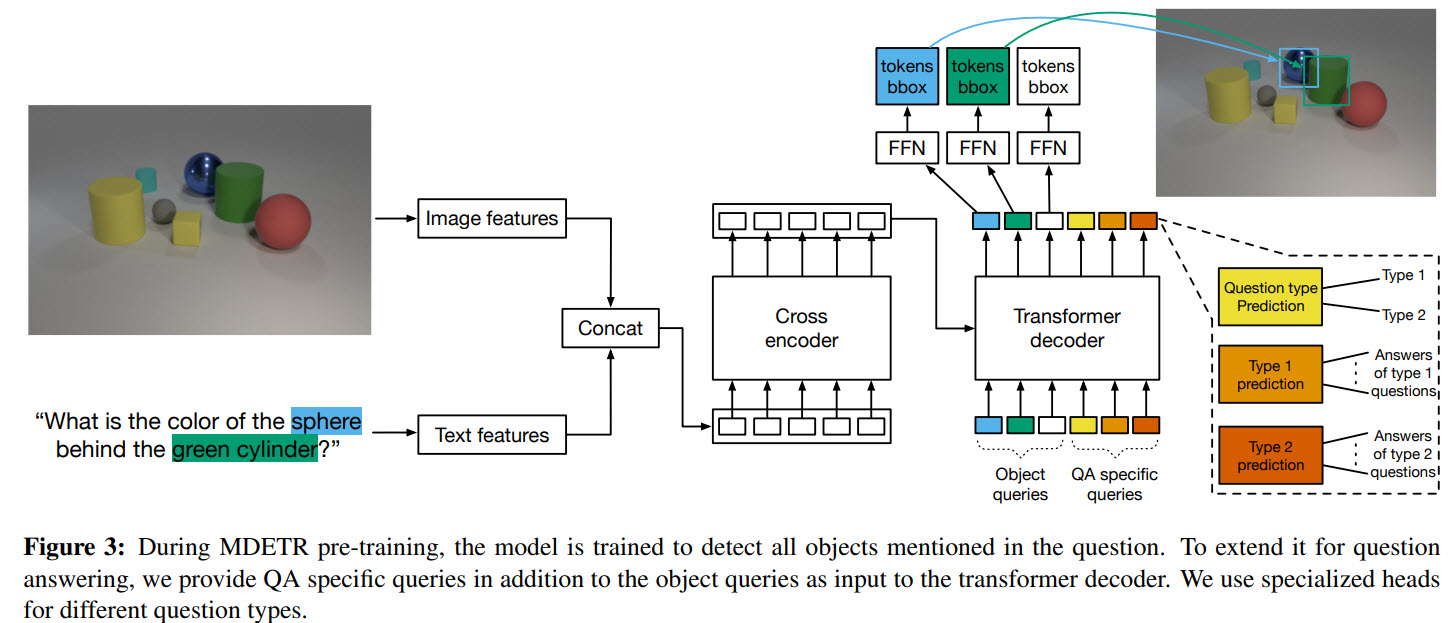
Few-shot transfer for long-tailed detection
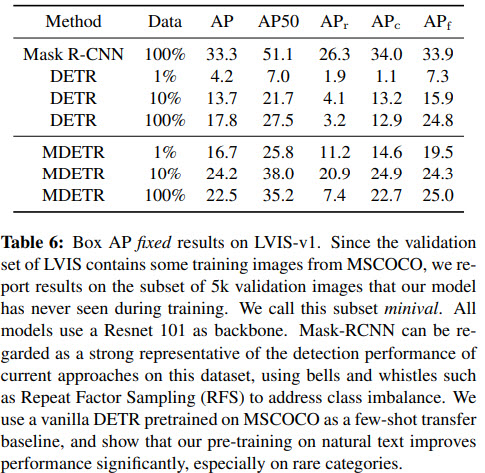
The authors try few-shot learning, where the model uses only a fraction of a dataset.
An example of the output:

The paper has appendixes with rich information on the datasets and the training.
paperreview deeplearning objectdetection multimodal