Paper Review: NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
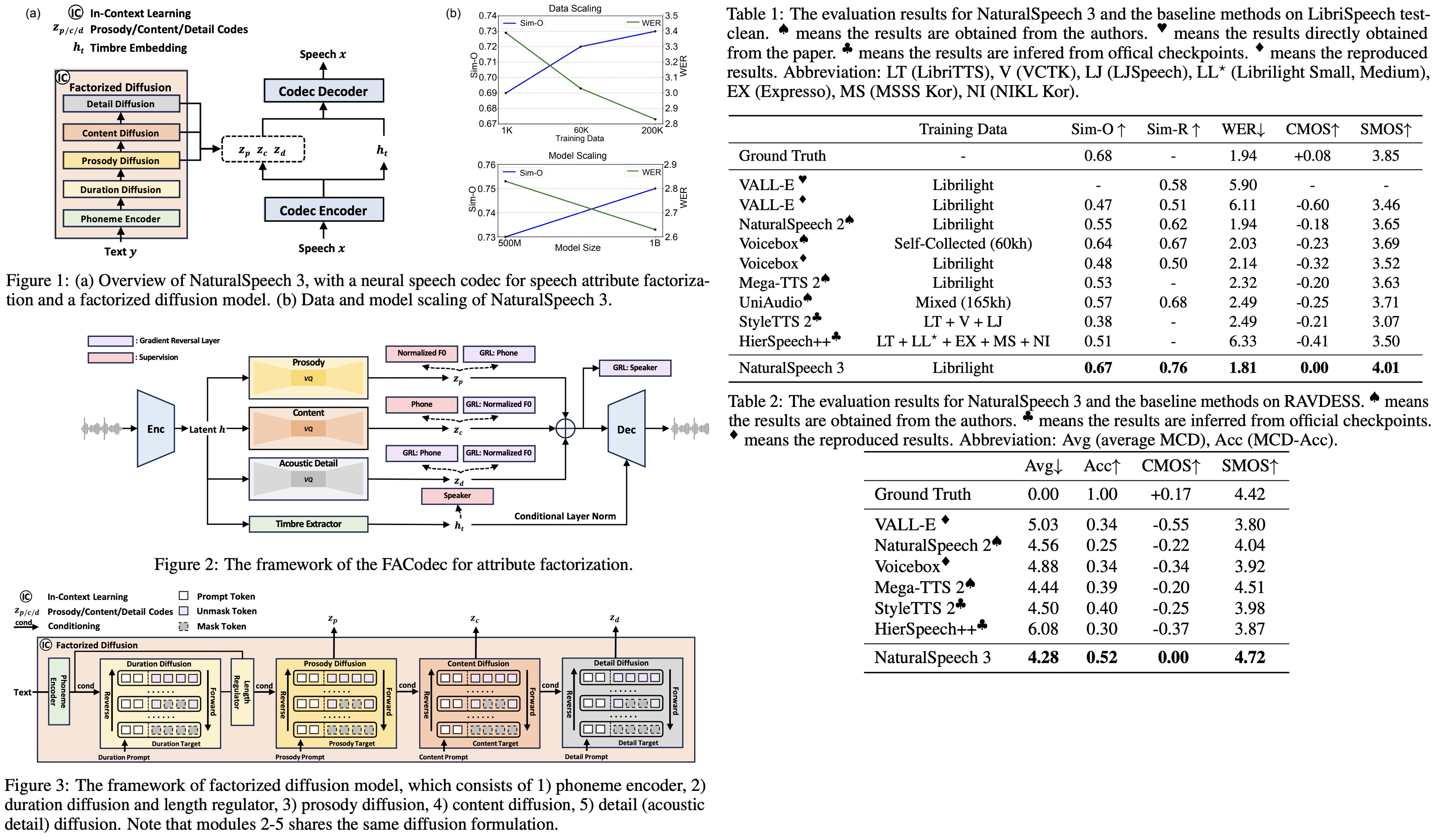
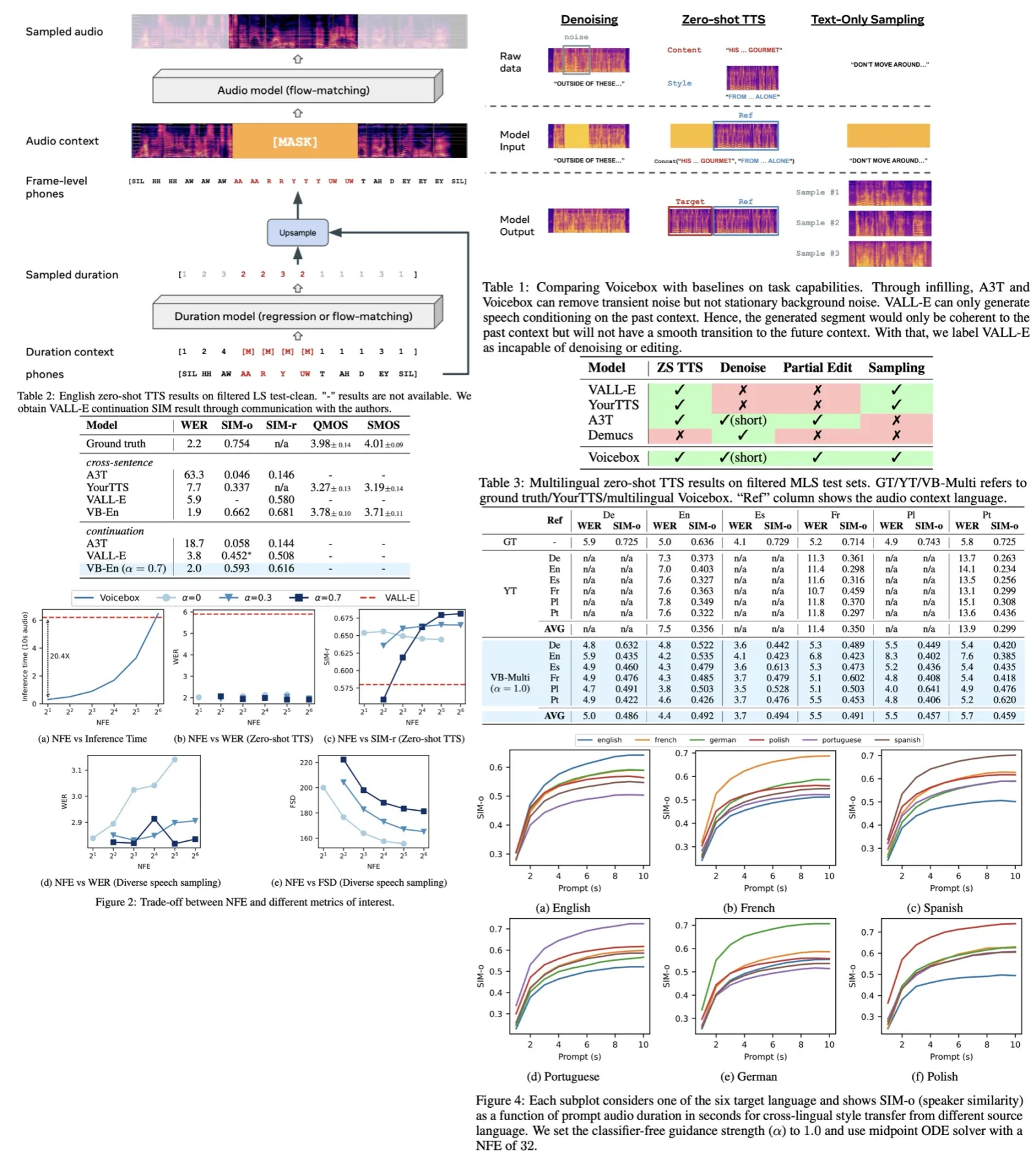
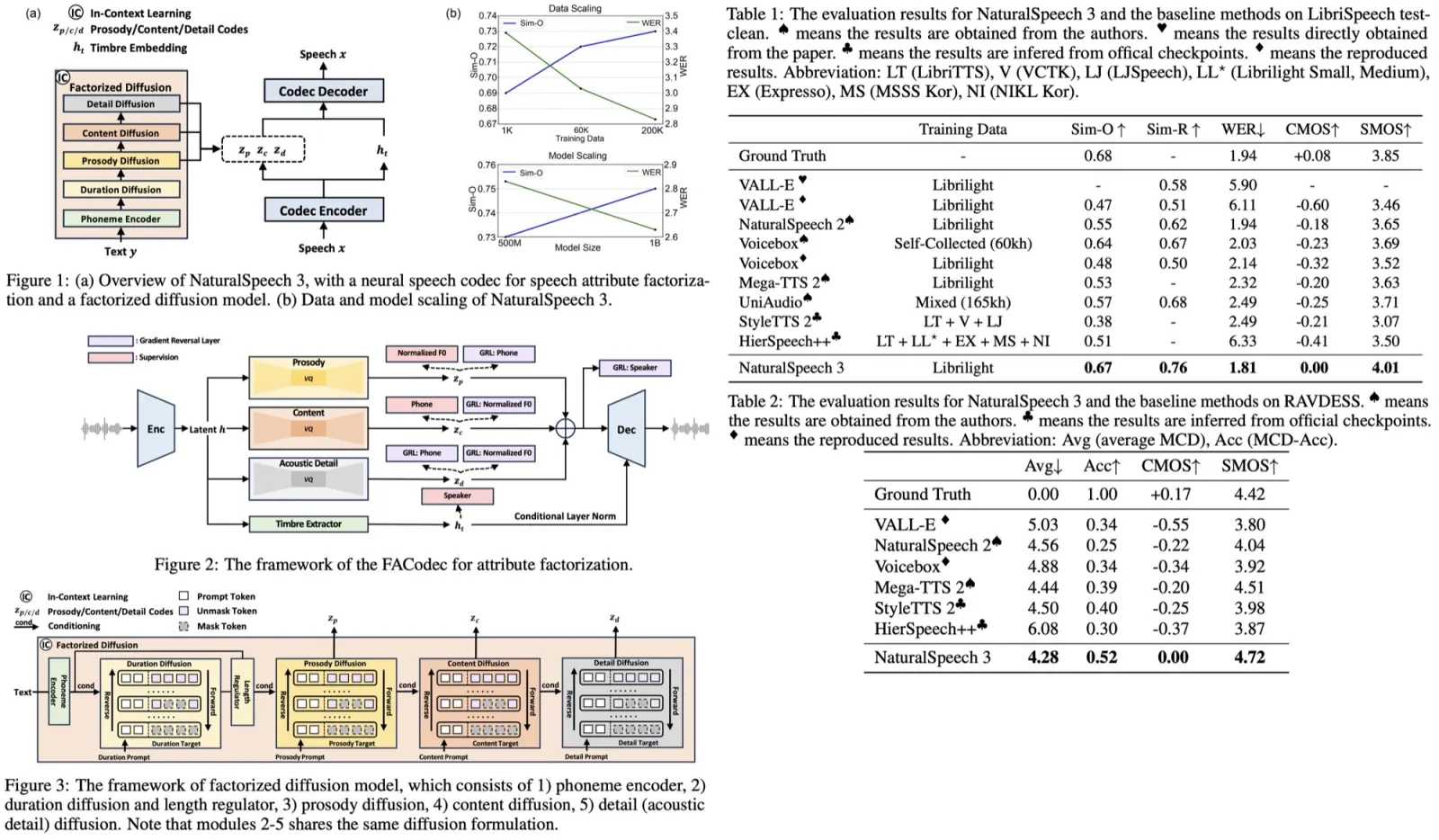
NaturalSpeech 3 is a new text-to-speech system that efficiently models intricate speech with disentangled subspaces using factorized diffusion models and a neural codec with factorized vector quantization. It generates attributes for each subspace based on prompts, leading to high-quality, natural speech generation. It outperforms current TTS systems in quality, similarity, prosody, and intelligibility and can be scaled up to 1 billion parameters and 200,000 hours of training data.
The approach
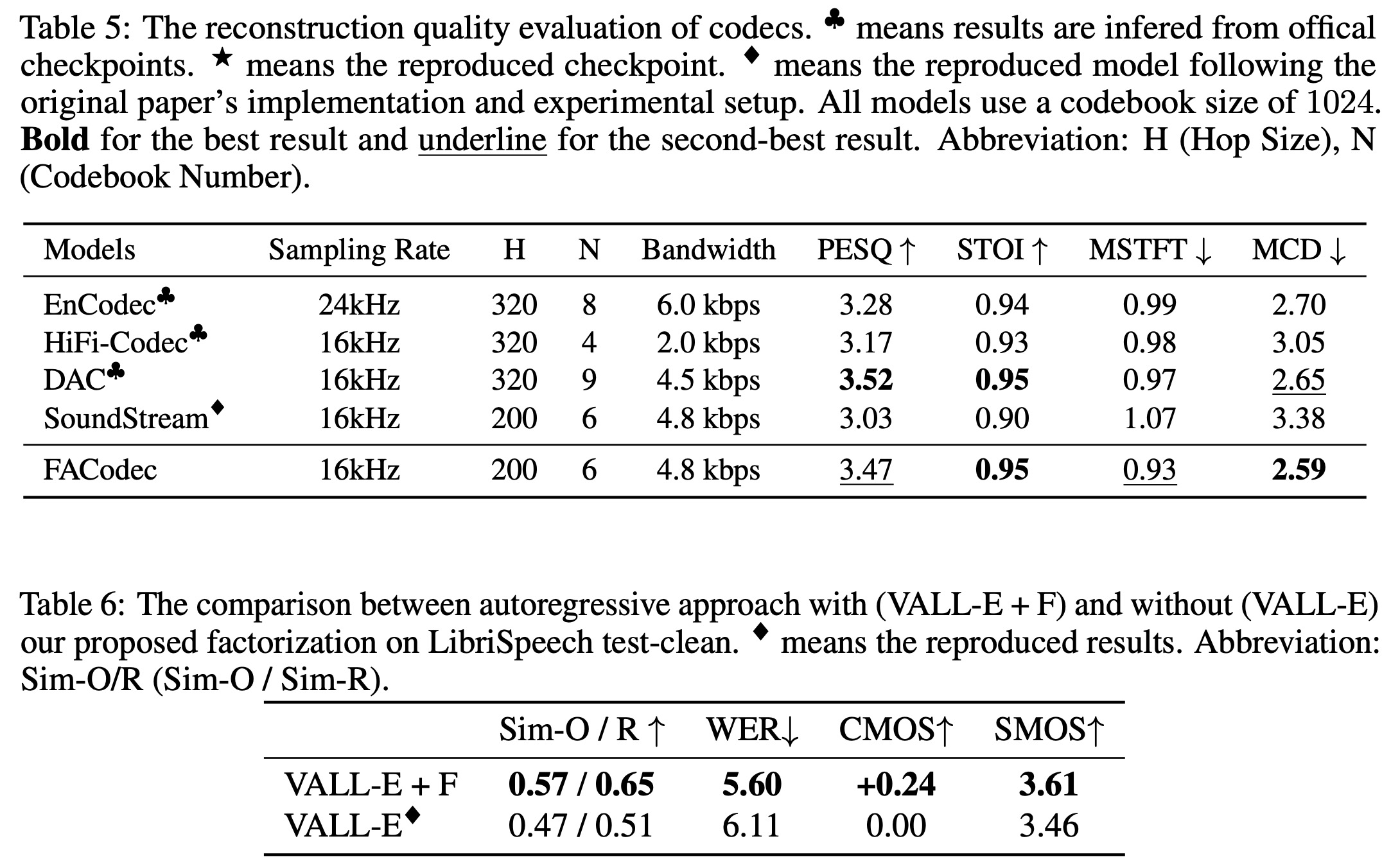
FACodec for Attribute Factorization
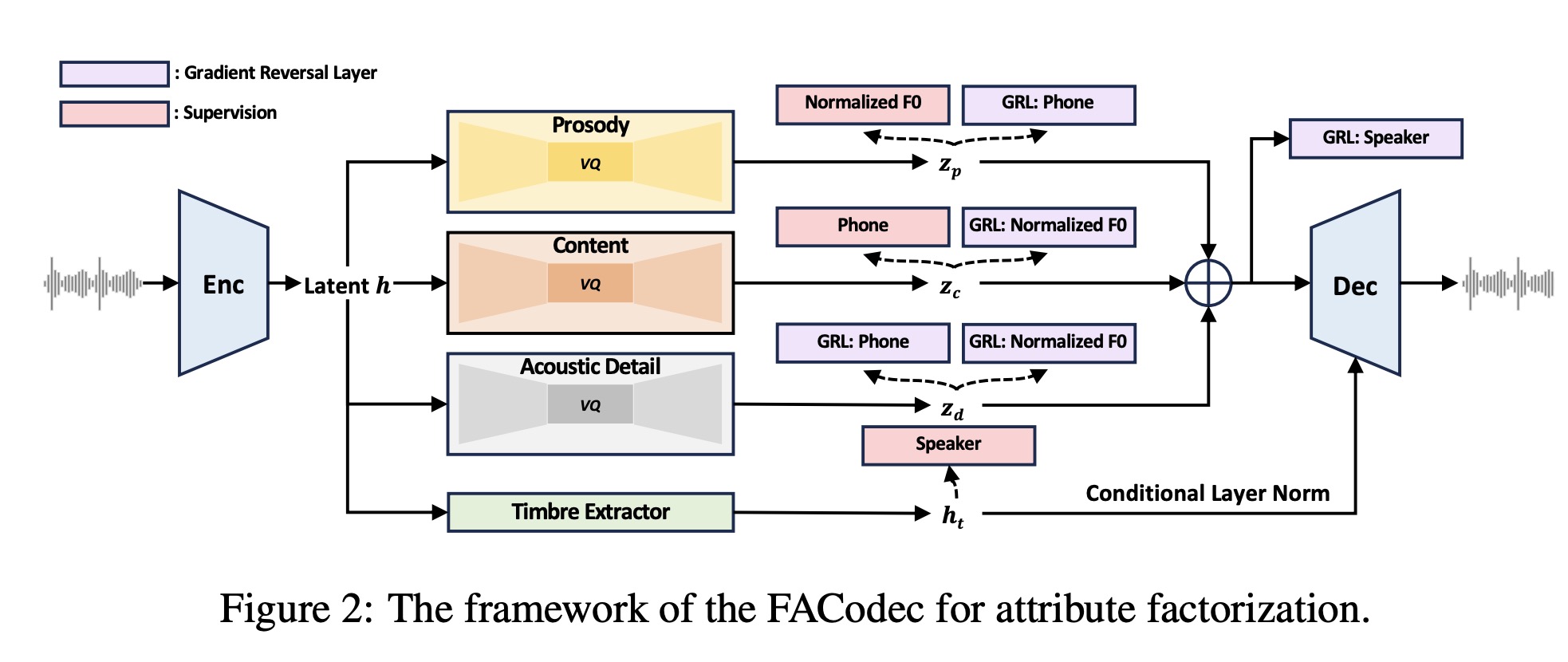
FACodec2 is designed to convert speech waveforms into distinct subspaces for content, prosody, timbre, and acoustic details, then reconstruct them into high-quality speech. It includes a speech encoder, a timbre extractor, three factorized vector quantizers for the different attributes, and a speech decoder. The encoder uses convolutional blocks to create a pre-quantization latent representation of the speech, which the timbre extractor, using a Transformer encoder, turns into a vector for timbre attributes. Other attributes are processed by factorized vector quantizer into discrete tokens. The decoder, larger than the encoder, combines these representations, incorporating timbre through conditional layer normalization, to reconstruct the speech waveform with high quality.
Techniques for better speech attribute disentanglement in a factorized neural speech codec include:
- an information bottleneck to remove unnecessary information
- supervision for high-quality disentanglement of attributes like prosody, content, and timbre;
- gradient reversal to prevent information leaks;
- detail dropout to balance disentanglement with reconstruction quality;
Factorized Diffusion Model
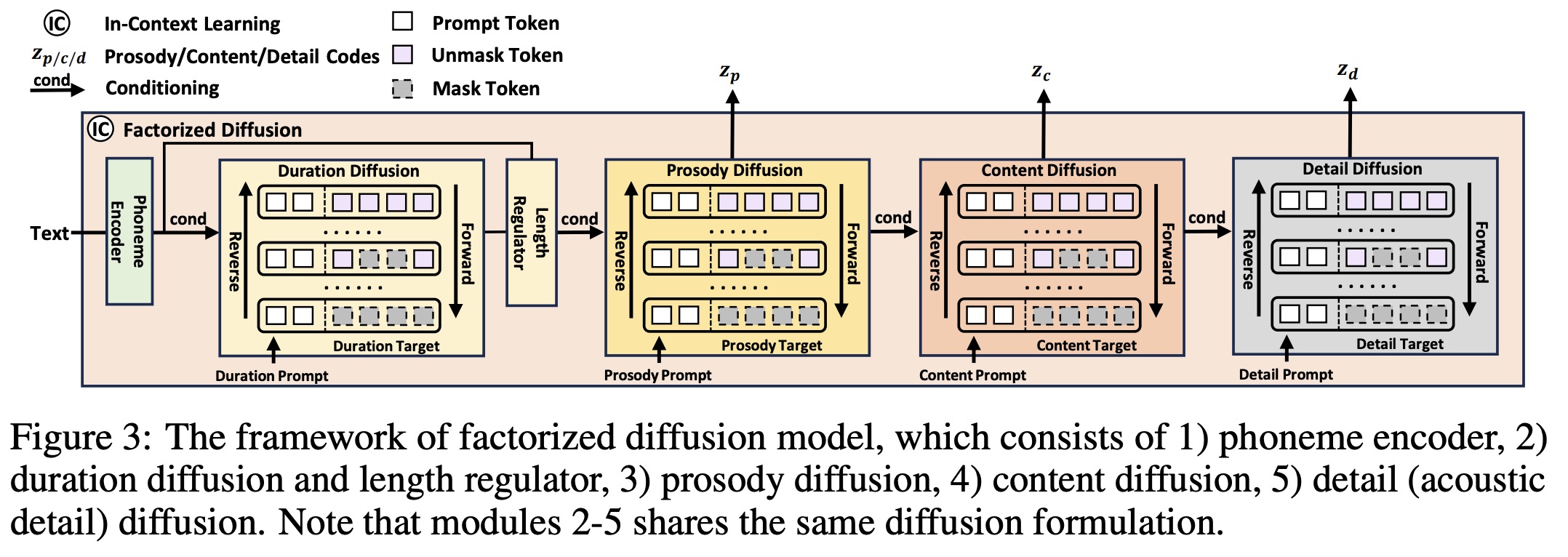
The model generates speech by discretely diffusing and sequentially generating speech attributes using a non-autoregressive model. Duration is generated first due to its design, and acoustic details last, following a logical sequence. The generative model receives attribute-specific prompts and applies discrete diffusion within each attribute’s subspace. Utilizing a codec to break down speech prompts into attribute prompts facilitates in-context learning. For example, for prosody generation, the authors concatenate the prosody prompt (without noise) and the target sequence (with noise) and then gradually remove noise from the target sequence with the prosody prompt.
The factorized diffusion model consists of a phoneme encoder and diffusion modules for each attribute, following the same discrete diffusion formulation but excluding explicit timbre generation, which is derived directly from prompts. Speech synthesis combines these attributes and decodes them via a codec decoder to produce the target speech.
Connections to the NaturalSpeech Series
NaturalSpeech 3 advances the NaturalSpeech TTS series by focusing on high-quality and diverse speech synthesis across single and multi-speaker, multi-style, and multi-lingual scenarios. It builds upon the foundational encoder/decoder and duration prediction components of its predecessors, distinguishing itself by introducing factorized diffusion models for generating discrete speech attributes. Unlike the flow-based models of NaturalSpeech and the latent diffusion models of NaturalSpeech 2, NaturalSpeech 3 uses the FACodec to disentangle speech into subspaces like prosody, content, acoustic details, and timbre, simplifying speech modeling and enhancing synthesis quality and diversity.
Experiments
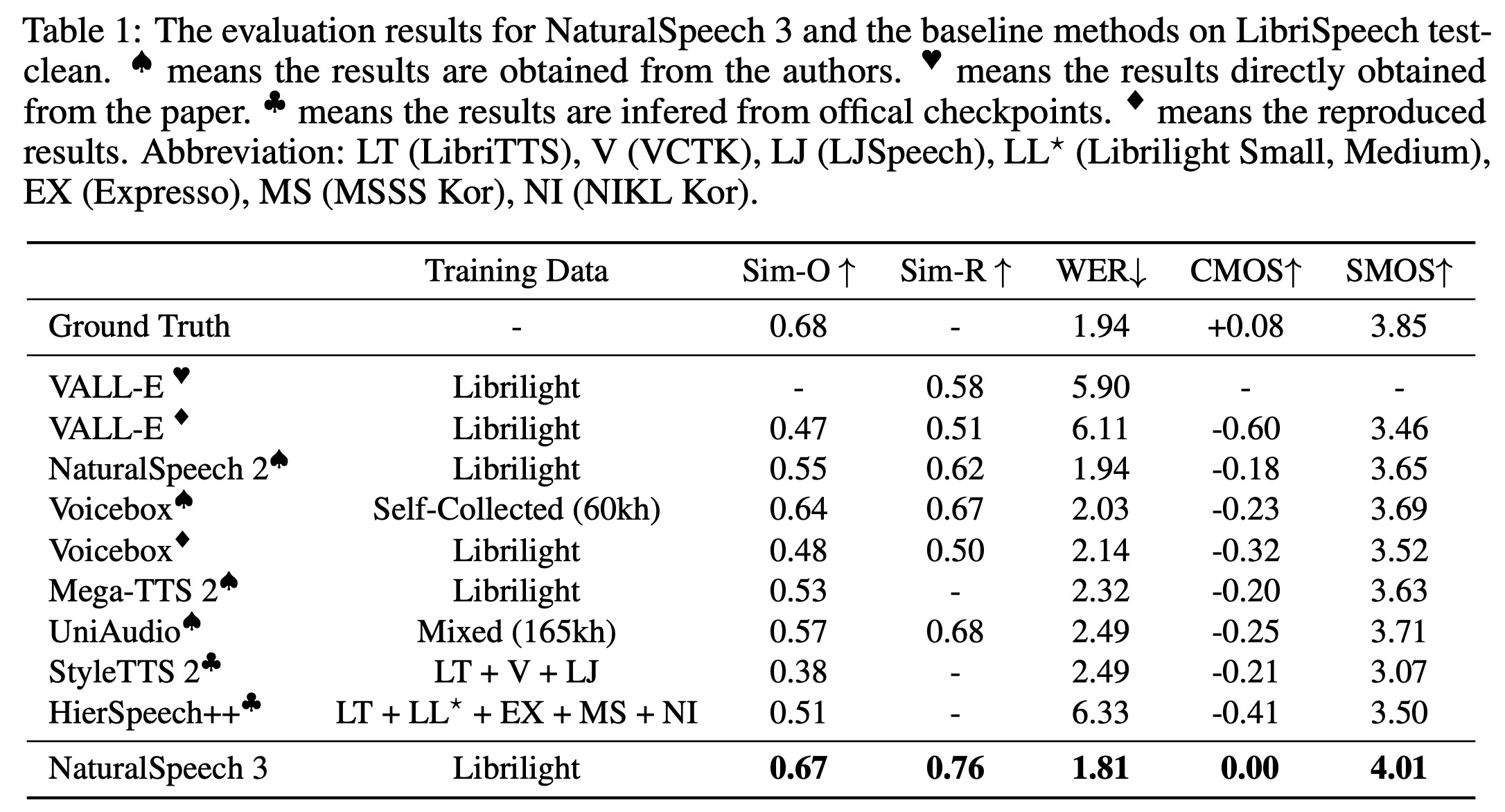
Evaluations of NaturalSpeech 3 show that it closely matches ground-truth recordings in quality and significantly surpasses baseline systems across various metrics. Speech quality assessed through CMOS tests shows NaturalSpeech 3 produces high-quality and natural speech. Speaker similarity evaluations, both objective and subjective, indicate it closely mimics speaker characteristics, outperforming other models. Prosody similarity assessments further demonstrate its superiority in capturing the nuances of speech prosody. Additionally, its robust zero-shot TTS capabilities are highlighted by lower word error rates compared to both ground truth and other baselines, indicating high intelligibility and superior performance.
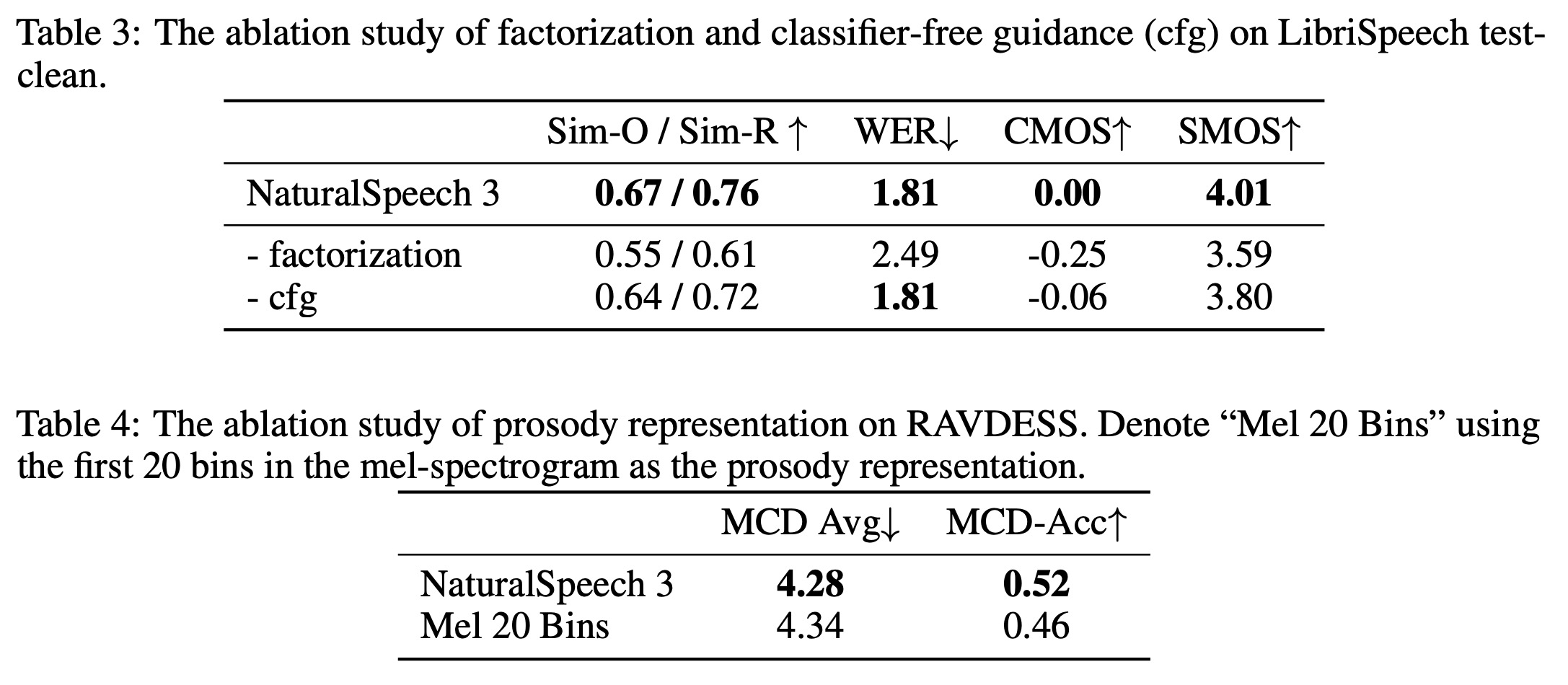
Ablation studies:
- Removing factorization from the codec and diffusion model leads to significant performance drops in speaker similarity metrics, word error rate, and subjective quality assessments;
- Omitting classifier-free guidance during inference results in noticeable declines in speaker similarity and quality metrics.
- Handcrafted features are less effective than learned prosody representations from the codec, underscoring the codec’s effectiveness in enhancing prosody similarity;
Effectiveness of Data and Model Scaling
Evaluations on the factorized diffusion model’s scaling effects show that both data and model scaling significantly enhance performance. With data scaling, even with just 1K hours of speech data, NaturalSpeech 3 shows effective speech generation, improving as data scales up to 200K hours, indicating clear benefits in speaker similarity and robustness. Model scaling, from 500M to 1B parameters, further boosts these metrics, suggesting larger models and more data contribute to better zero-shot TTS performance, with potential for even greater improvements with extended training and larger model sizes.
P. S. You can read my review of NaturalSpeech2 here.
paperreview deeplearning tts speech