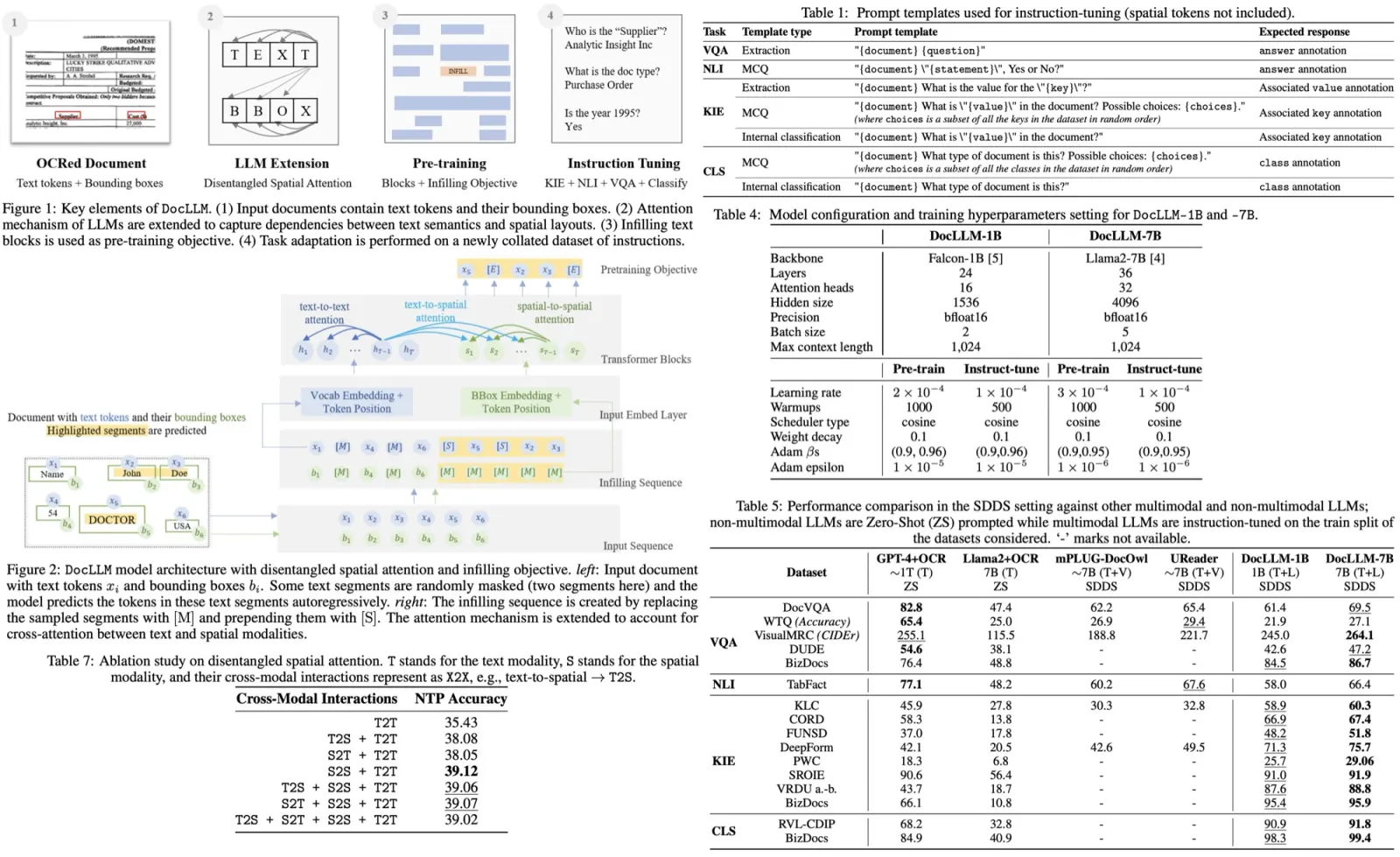
Paper Review: PaperBanana: Automating Academic Illustration for AI Scientists

PaperBanana is an agentic framework for automatically generating publication-ready academic illustrations. It coordinates specialized agents to retrieve references, plan content and style, render images, and iteratively refine results via self-critique using VLMs and image generation models. To evaluate the approach, the authors introduce PaperBananaBench, a benchmark of 292 methodology-diagram tasks curated from NeurIPS 2025 papers. Experiments show that PaperBanana outperforms strong baselines in faithfulness, conciseness, readability, and aesthetics, and the framework generalizes to high-quality statistical plot generation.
Task Formulation
The authors formulate automated academic illustration generation as the task of learning a function that maps a source context and communicative intent to a visual output. Given context and intent, the goal is to generate an image that faithfully represents the content while matching the intended focus. The formulation can be extended with optional reference examples, enabling few-shot guidance; without them, the task reduces to zero-shot generation. This paper focuses primarily on methodology diagrams, where the context is the textual method description and the intent is the figure caption that defines the illustration’s scope.
Methodology
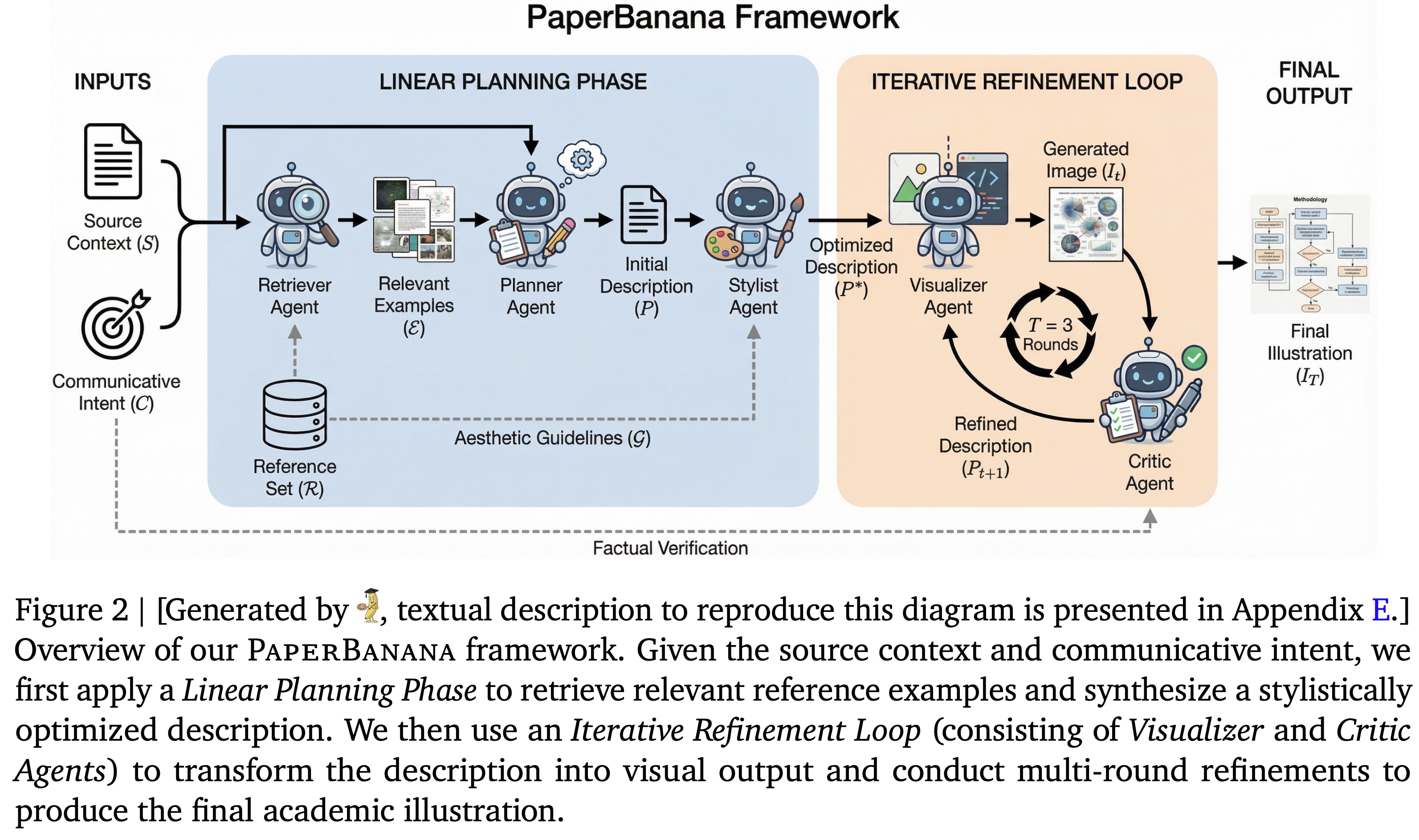
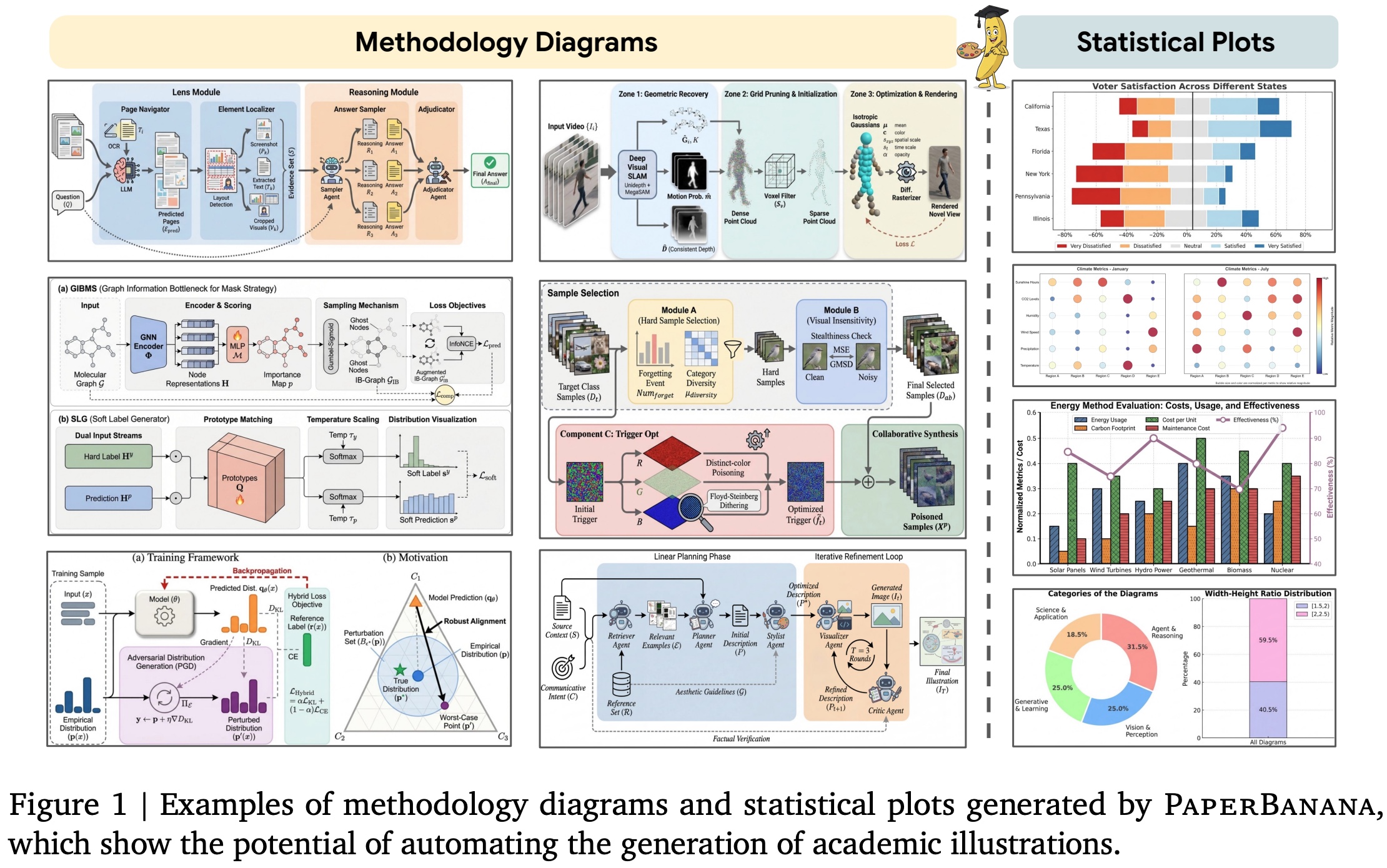
PaperBanana coordinates five specialized agents - Retriever, Planner, Stylist, Visualizer, and Critic - to transform scientific text into publication-quality diagrams and plots.
The Retriever selects relevant reference examples using VLM-based reasoning, prioritizing diagram structure and type over topical similarity. The Planner acts as the system’s cognitive core, converting the source context and communicative intent, guided by references, into a detailed textual plan of the target illustration. The Stylist enforces academic visual standards by synthesizing an aesthetic guideline from the reference corpus and refining the plan accordingly. The Visualizer generates images from the refined description using an image generation model, while the Critic evaluates each output against the original intent and context, providing feedback for iterative refinement. This Visualizer–Critic loop runs for three iterations to ensure accuracy, clarity, and visual quality.
The framework extends to statistical plot generation by having the Visualizer produce executable Matplotlib code instead of images, with the Critic iteratively correcting errors or inconsistencies.
Benchmark
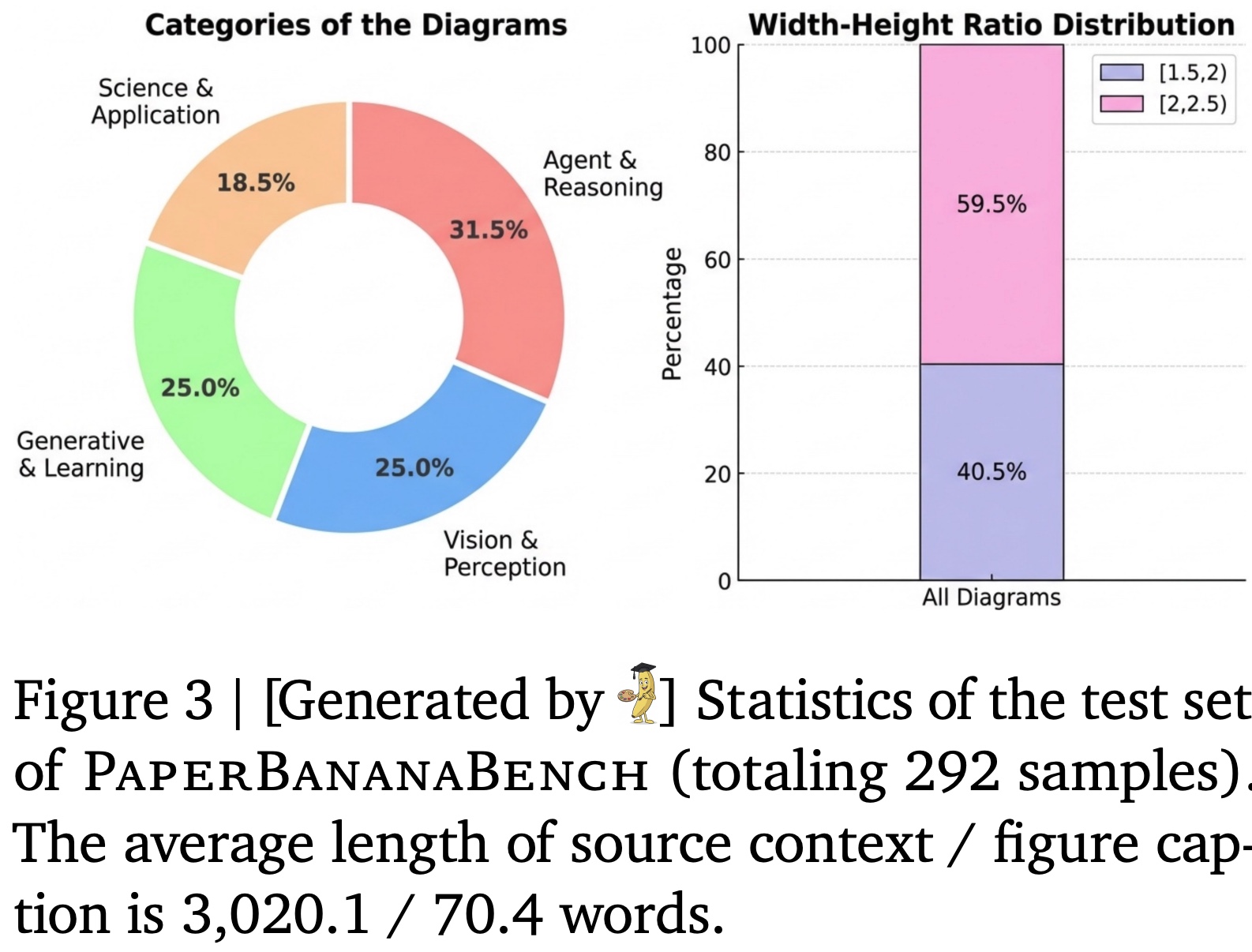
Data Curation
The authors sample 2k NeurIPS 2025 papers, parse PDFs with MinerU to extract methodology text, diagrams, and captions, and filter for quality. Papers without methodology diagrams are removed, and diagrams are further filtered by aspect ratio to ensure suitability for generation and fair evaluation, yielding 610 candidates. Diagrams are then categorized into four types: Agent & Reasoning, Vision & Perception, Generative & Learning, and Science & Applications. A final human curation step verifies text, captions, and categories and removes low-quality visuals, resulting in 584 high-quality samples, split evenly into a test set and a reference set.
Evaluation Protocol
The authors evaluate generated diagrams and plots using a VLM-as-a-Judge with a referenced comparison setup, where model outputs are directly compared against human-drawn figures. Evaluation covers two perspectives:
- Content: faithfulness to the source and communicative intent, and conciseness
- Presentation: readability and aesthetics
For each dimension, the judge assigns a win, loss, or tie relative to the human reference, mapped to scores of 100, 0, and 50. Overall scores are computed via a hierarchical aggregation that prioritizes faithfulness and readability over conciseness and aesthetics, ensuring that correctness and clarity dominate visual appeal.
Experiments
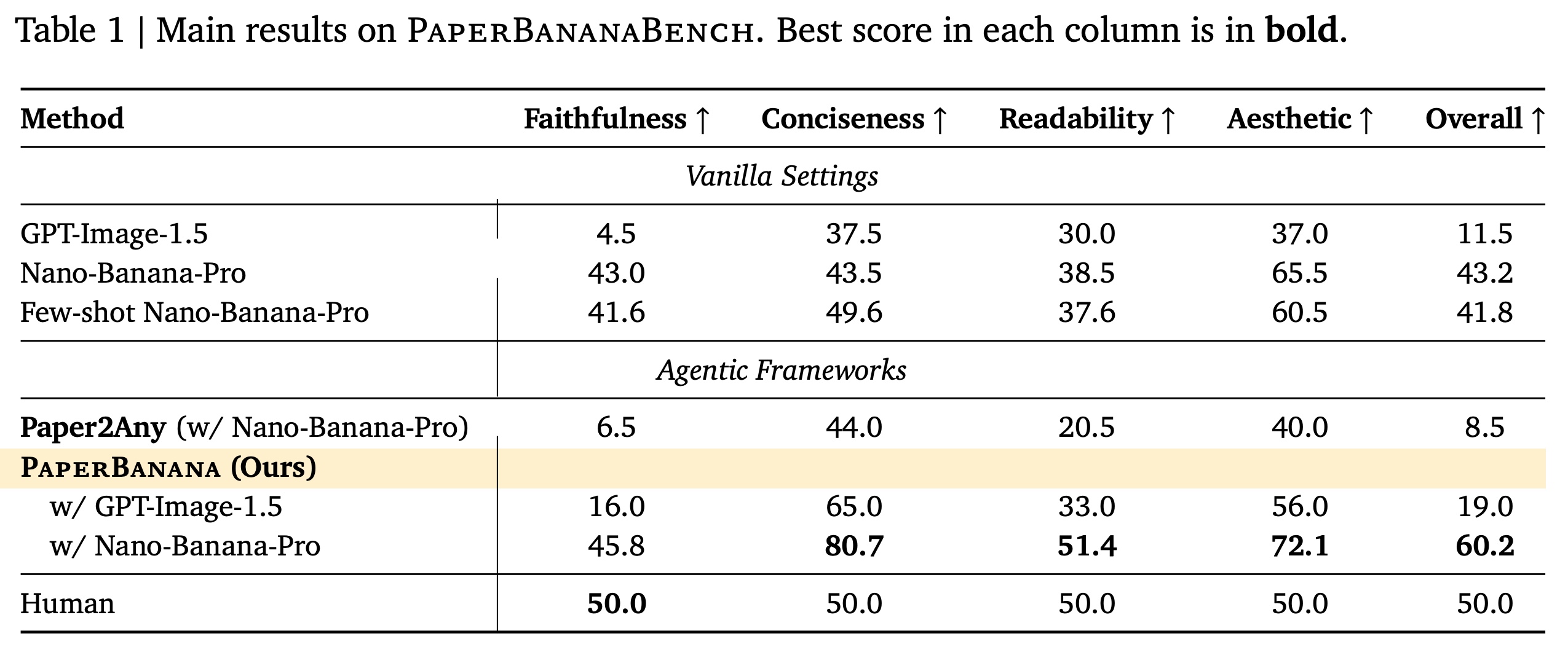
PaperBanana outperforms other models but underperforms the human reference in terms of faithfulness.
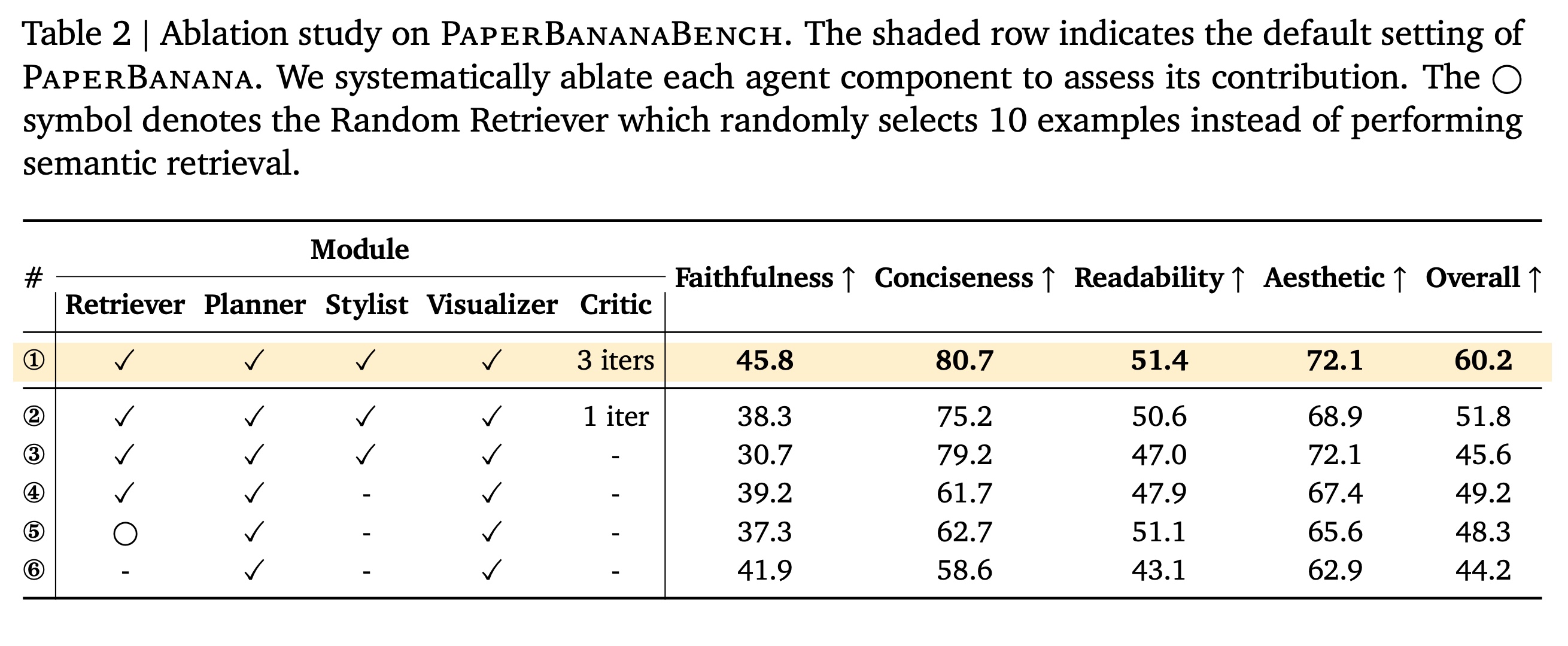
- Removing the Retriever results in substantial declines in conciseness, readability, and aesthetics, as the system produces verbose, visually unrefined diagrams. Surprisingly, using randomly selected references performs comparably to semantic retrieval, indicating that exposure to general structural and stylistic patterns matters more than precise content matching.
- The Stylist agent improves conciseness and aesthetics but slightly harms faithfulness by omitting technical details, while the Critic agent compensates for this loss by restoring faithfulness through iterative refinement. Additional refinement iterations further improve all metrics, balancing visual quality and technical accuracy.
Limitations and Future Directions
The authors discuss the limitations of PaperBanana and outline future directions.
- A key limitation is that the framework produces raster images, which are difficult to edit compared to vector graphics; potential solutions range from post-hoc image editing to reconstructing vector representations to agents that directly operate professional design software.
- Another challenge is the trade-off between standardized academic style and stylistic diversity, as a unified style guide constrains variation.
- While PaperBanana performs well visually, it still lags humans in fine-grained faithfulness, particularly in subtle structural details like arrow directions, reflecting limits of current VLM perception.
Possible extensions include test-time scaling to generate multiple stylistic variants for user or model selection, and applying the reference-driven paradigm to broader domains such as UI/UX design, patents, and industrial schematics.
paperreview deeplearning agent vlm visual multimodal