Paper Review: PaLI-3 Vision Language Models: Smaller, Faster, Stronger
PaLI-3 is an efficient vision language model with performance comparable to models 10 times its size. By comparing ViT models pretrained using classification and contrastive (SigLIP) methods, it was found that SigLIP-based PaLI excels in multimodal tasks, especially in localization and visually-situated text comprehension, despite slightly lagging in standard image classification. When the SigLIP image encoder is scaled up, it sets a new benchmark in multilingual cross-modal retrieval.
Model
Architecture
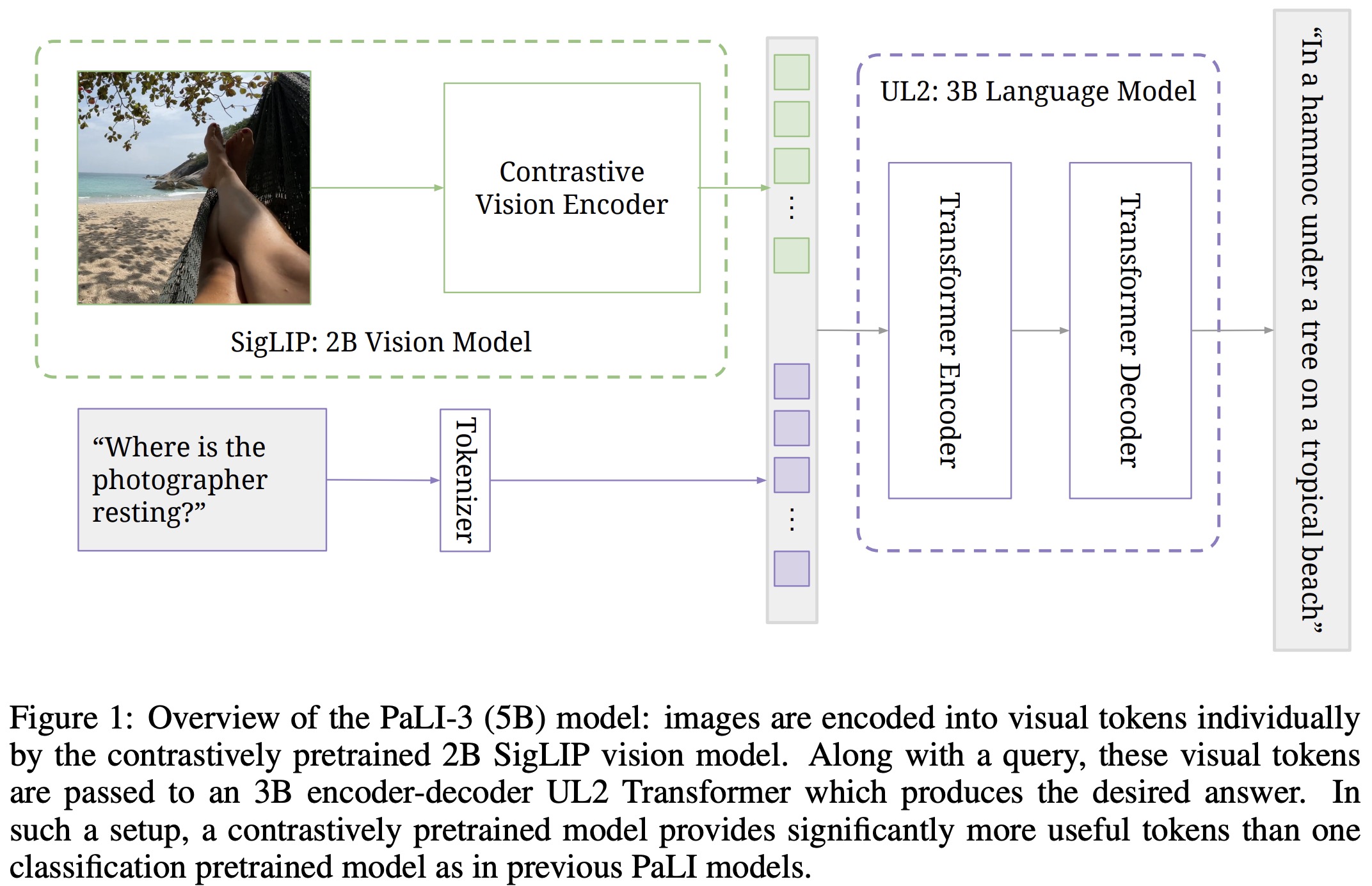
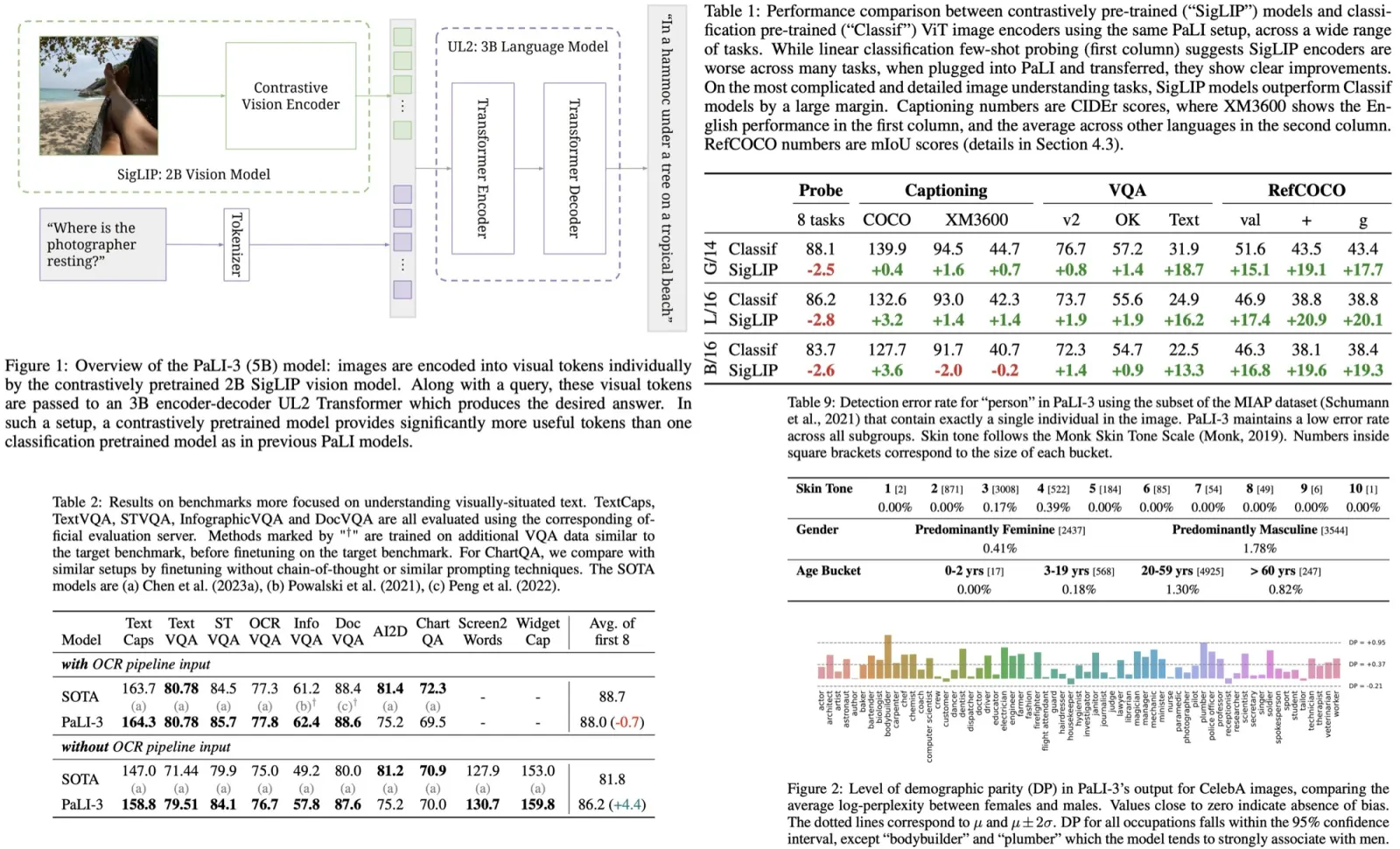
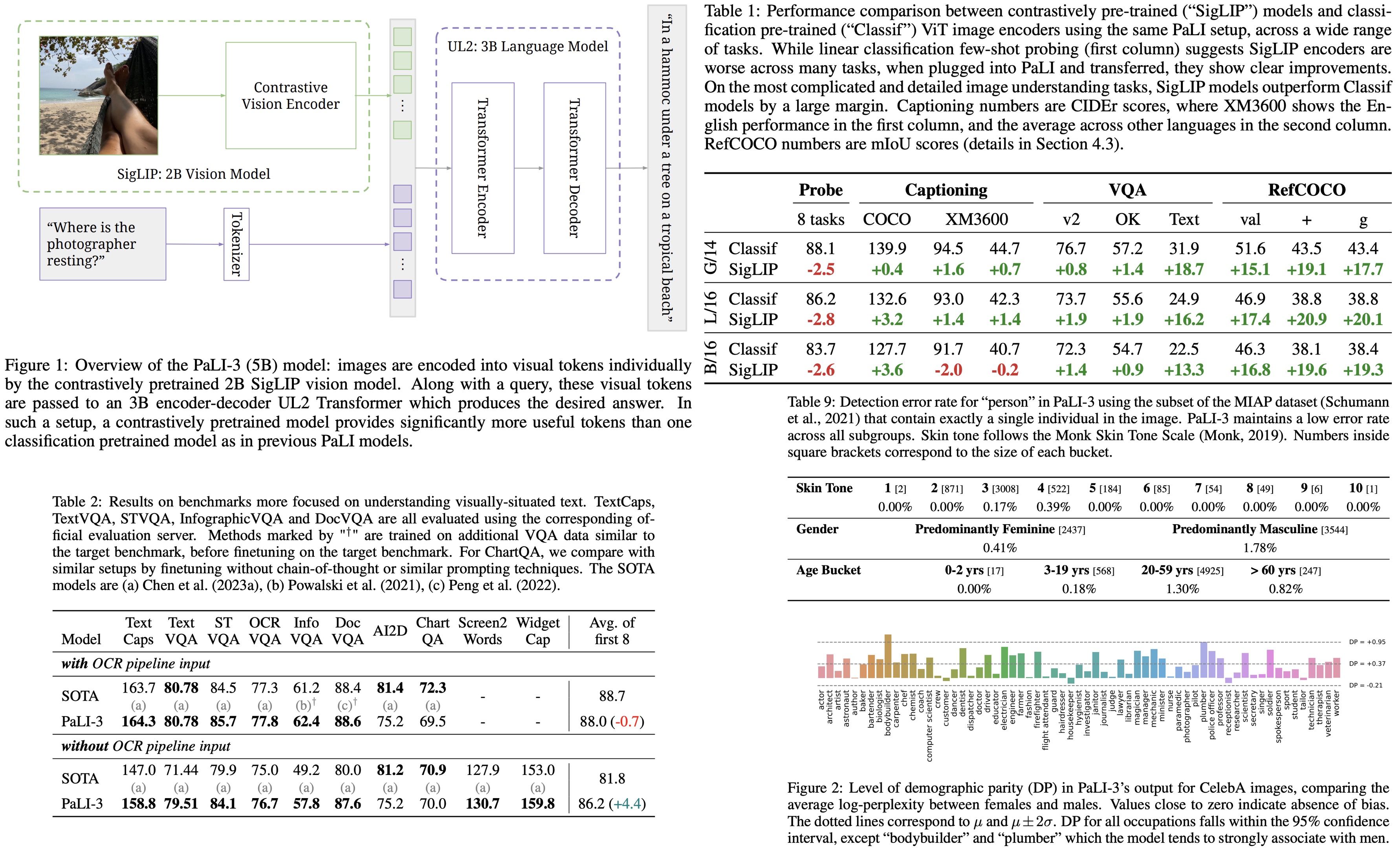
- The architecture of PaLI-3 is based on PaLI model, where ViT encodes images into tokens. These tokens, combined with text input, are processed by an encoder-decoder transformer to produce text output.
- The visual component of PaLI-3 uses a ViT-G/142 model with about 2B parameters, initialized from a contrastively pretrained method called SigLIP. This method trains image and text embedding transformers to determine if an image and text match. It’s similar to CLIP and ALIGN but is more efficient and robust. Only the ViT image embedding is retained for PaLI-3.
- In the full model, outputs from the ViT image encoder form visual tokens that are combined with text tokens and processed by a 3B parameter UL2 encoder-decoder language model to generate text output.
The text input to the model typically consists of a prompt that describes the type of task (e.g., Generate the alt_text in ⟨lang⟩ at ⟨pos⟩ for captioning tasks) and encode necessary textual input for the task (e.g., Answer in ⟨lang⟩: {question} for VQA tasks).
Stages of training
- Unimodal pretraining: The image encoder is pretrained using the SigLIP protocol on image-text pairs from the web, differing from PaLI and PaLI-X, which used a JFT classification encoder. About 40% of the pairs are retained through a model-based filtering approach. The image encoder is trained at a 224×224 resolution, the text encoder-decoder is a 3B UL2 model trained using a mixture of denoisers procedure.
- Multimodal training: The image encoder is merged with the text encoder-decoder and trained on a multimodal task and data mixture. The image encoder remains frozen and operates at its native 224×224 resolution. Training data is derived mainly from the WebLI dataset, with additional data sources like multilingual captioning on CC3M-35L, cross-lingual VQA and VQG, object-aware VQA, and object detection. Unlike PaLI-X, video data isn’t used, but PaLI-3 still performs well due to its robust image encoder. The dataset is also enriched with PDF documents and web-images in over 100 languages.
- Resolution increase: To enhance performance, the resolution of PaLI-3 is increased by fine-tuning the entire model. The model is trained with increasing resolutions, saving checkpoints at 812×812 and 1064×1064 resolutions.
- Task specialization (transfer): For each specific task, PaLI-3 is fine-tuned with the frozen ViT image encoder using the task’s training data. Most tasks use the 812×812 resolution checkpoint, but two tasks related to document understanding use the 1064×1064 resolution.
Experiments
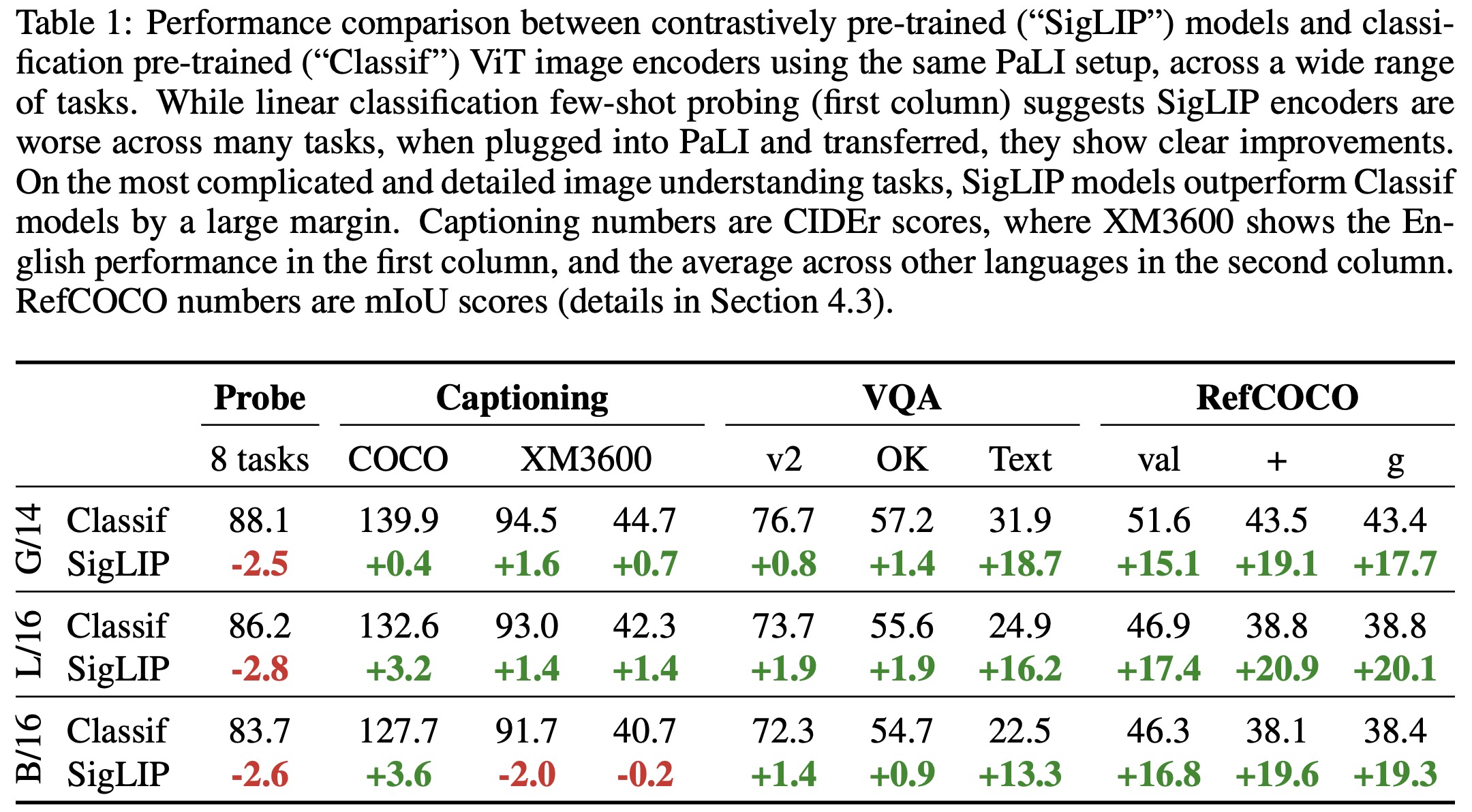
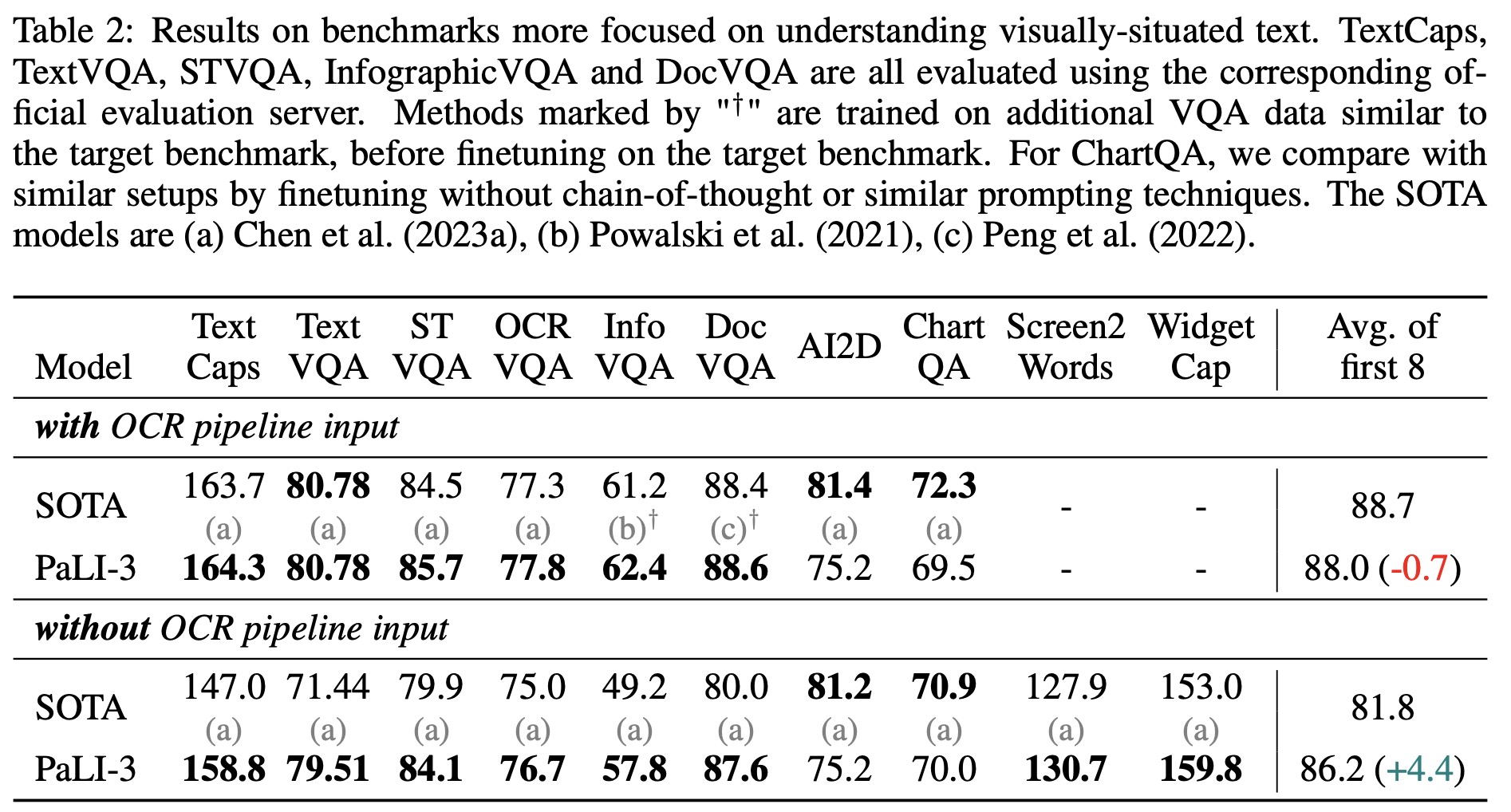
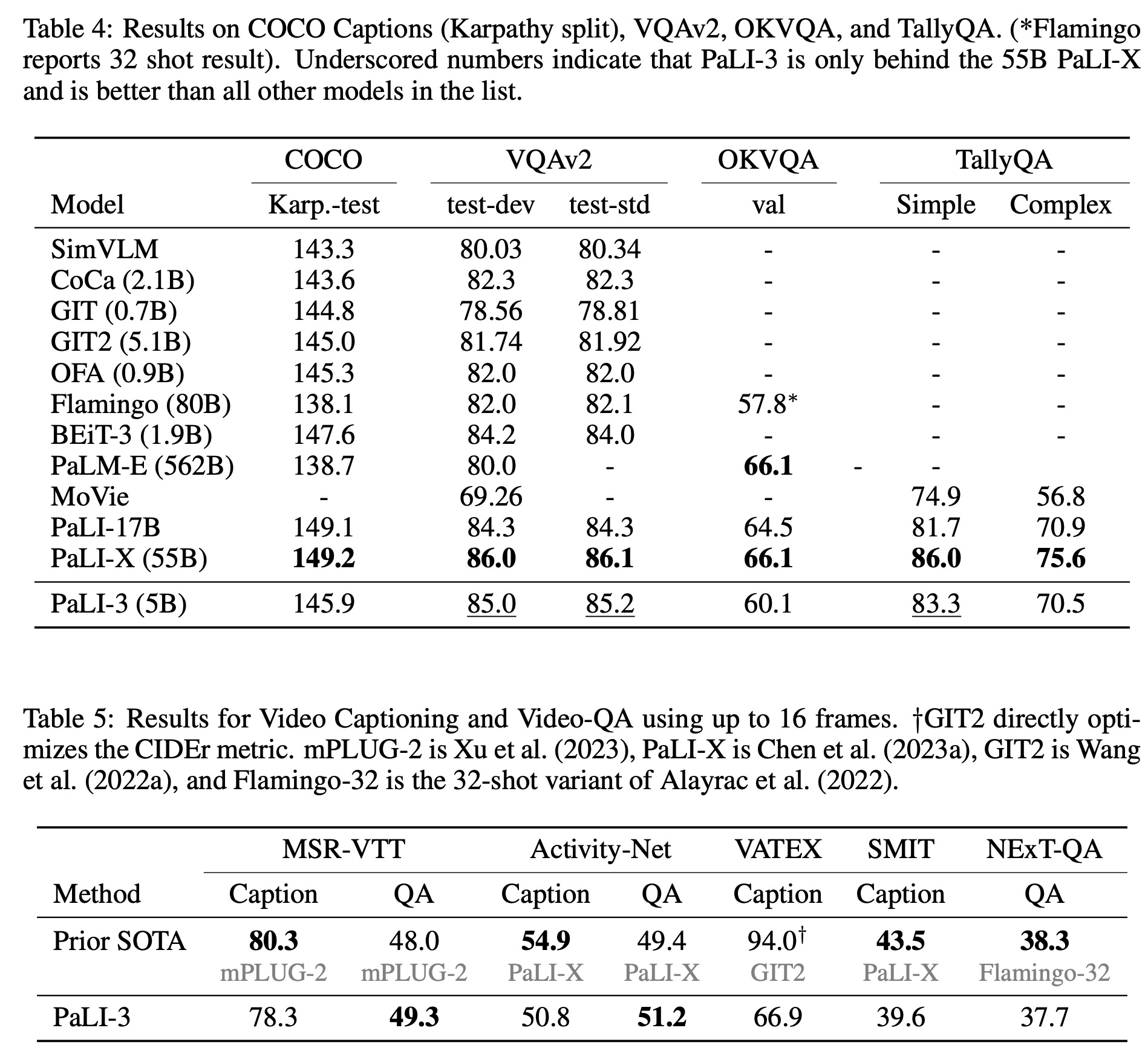
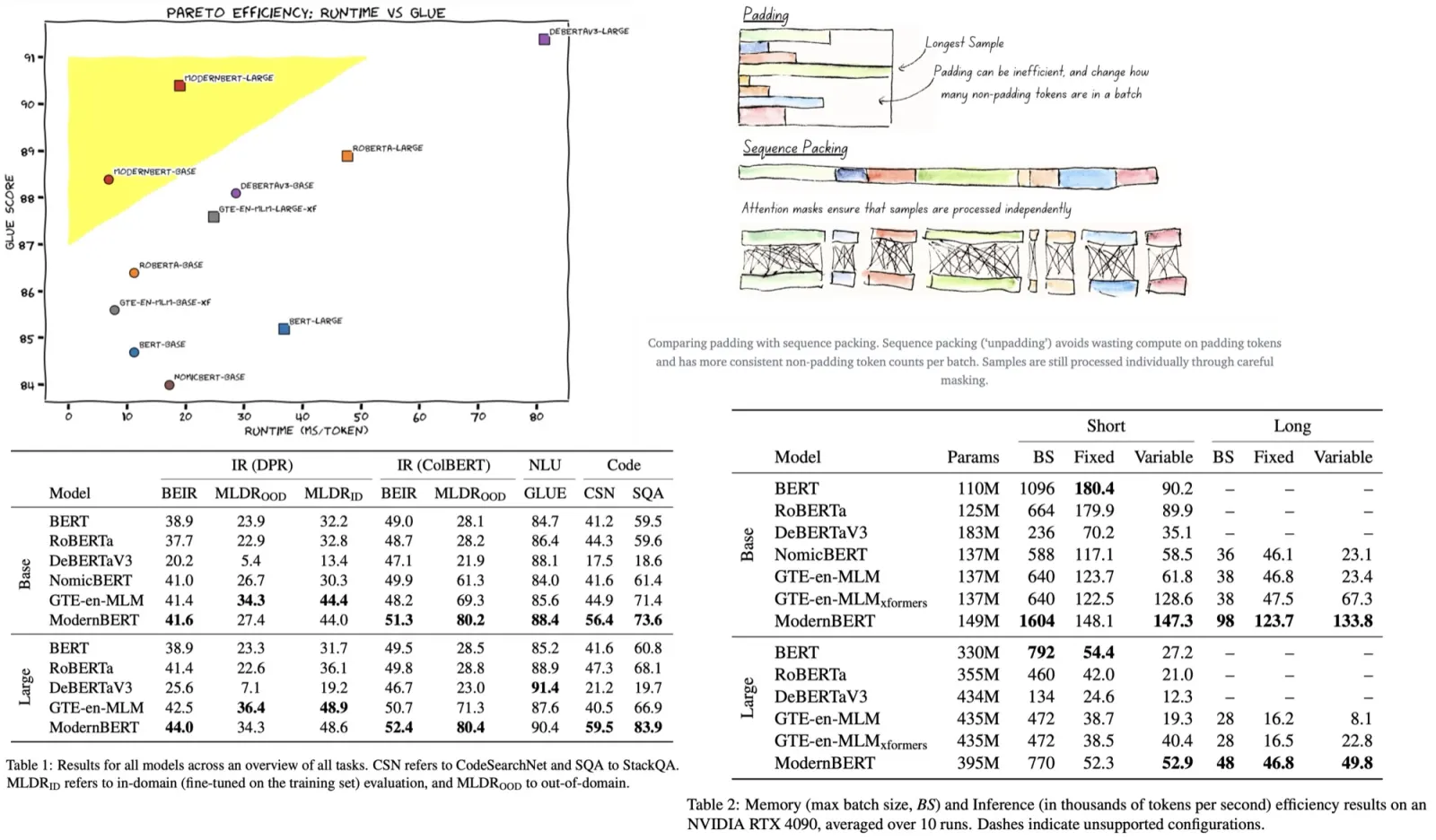
- Classification or contrastively pretrained ViT: Within the PaLI framework, two types of ViT models were compared: one pretrained for classification on the JFT dataset and the other contrastively pretrained on the WebLI dataset using the SigLIP protocol. Results showed that while SigLIP models lagged in few-shot linear classification, they excelled in PaLI-3 for tasks like captioning and more complex tasks like TextVQA and RefCOCO.
- Visually-situated text understanding: The model showed state-of-the-art performance on most benchmarks, with or without external OCR input. It particularly excelled in tasks without external OCR systems.
- Referring expression segmentation: PaLI-3 was enhanced to predict segmentation masks using the VQ-VAE method. The model was trained to predict a bounding box followed by mask tokens representing the mask inside the box. Results indicated that contrastive pretraining was more effective than classification pretraining for this type of task.
- Natural image understanding: The model showed strong performance, outperforming many larger models in most benchmarks.
- Video captioning and question answering: PaLI-3 was fine-tuned and evaluated on video captioning and video question-answering benchmarks. Despite not being pretrained with video data, PaLI-3 achieved excellent results (several SOTAs), highlighting the benefits of adopting contrastive ViTs.
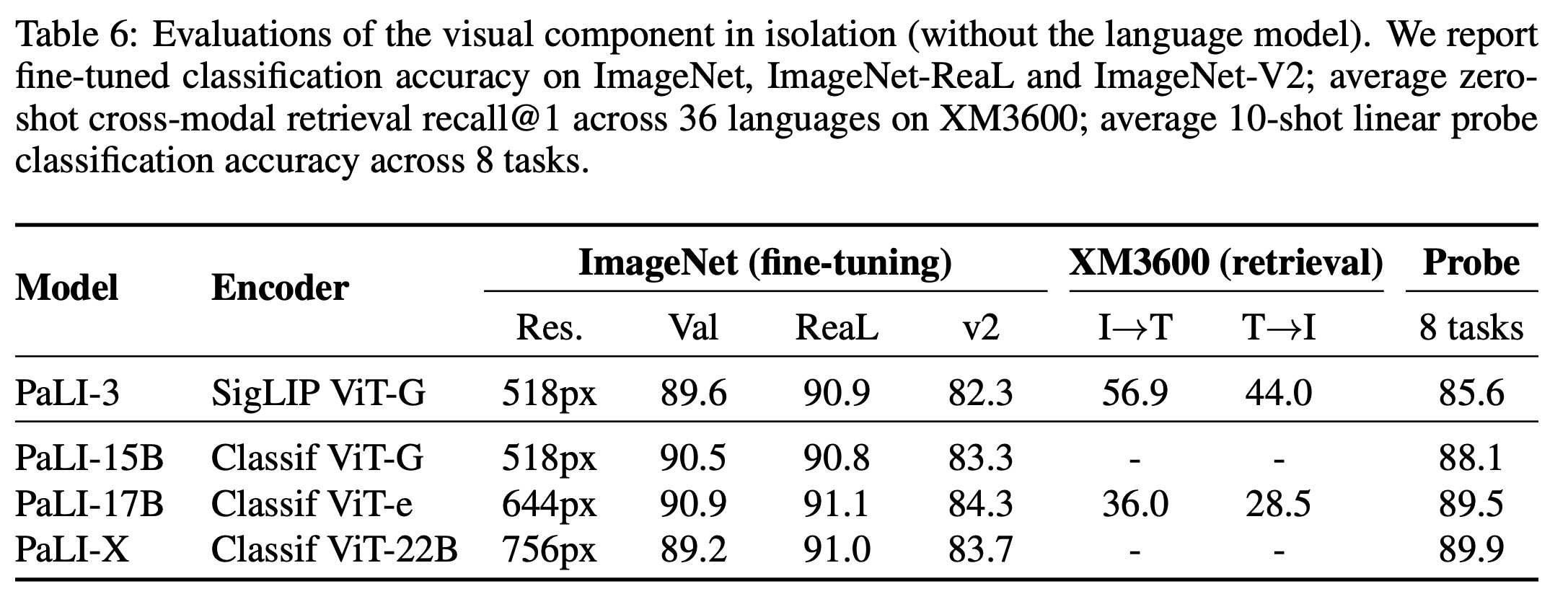
- Direct image encoder evaluation: In image classification tasks using ImageNet, the SigLIP model slightly lagged behind in top-1 and v2 accuracy but matched in ReaL accuracy (it avoids measuring “overfitting” to ImageNet peculiarities). For multilingual image-text retrieval on the Crossmodal-3600 benchmark, the SigLIP model outperformed the classification pretrained model. However, in linear probing tasks, SigLIP lagged behind.
Model fairness, biases, and other potential issues
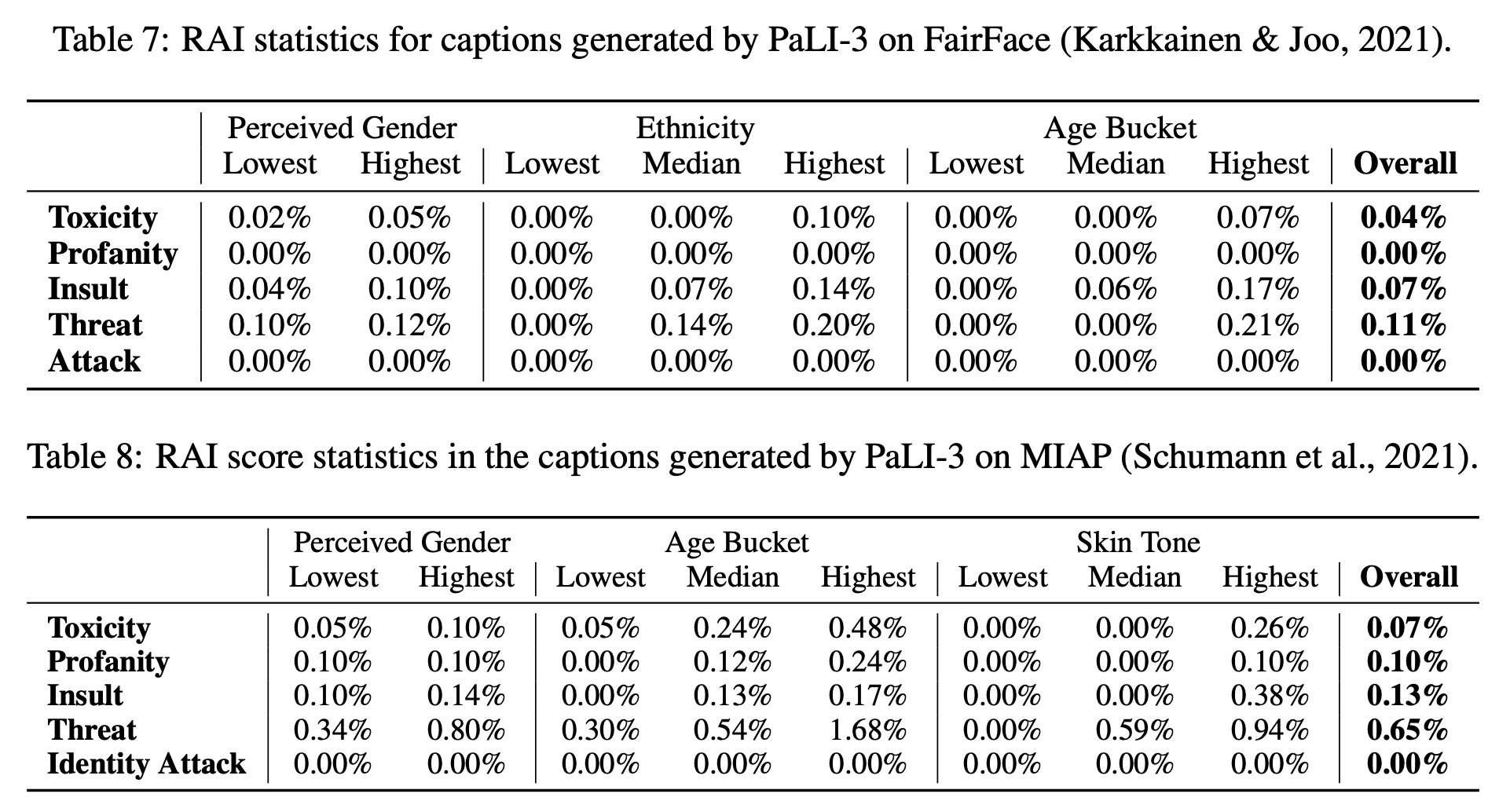
- Toxicity and Profanity Assessment: The MIAP and FairFace datasets were used to generate captions, and the Perspective API was employed to measure toxicity, profanity, and other potential issues. The results showed a low level of toxicity and profanity across all data slices, comparable to the PaLI-X model.
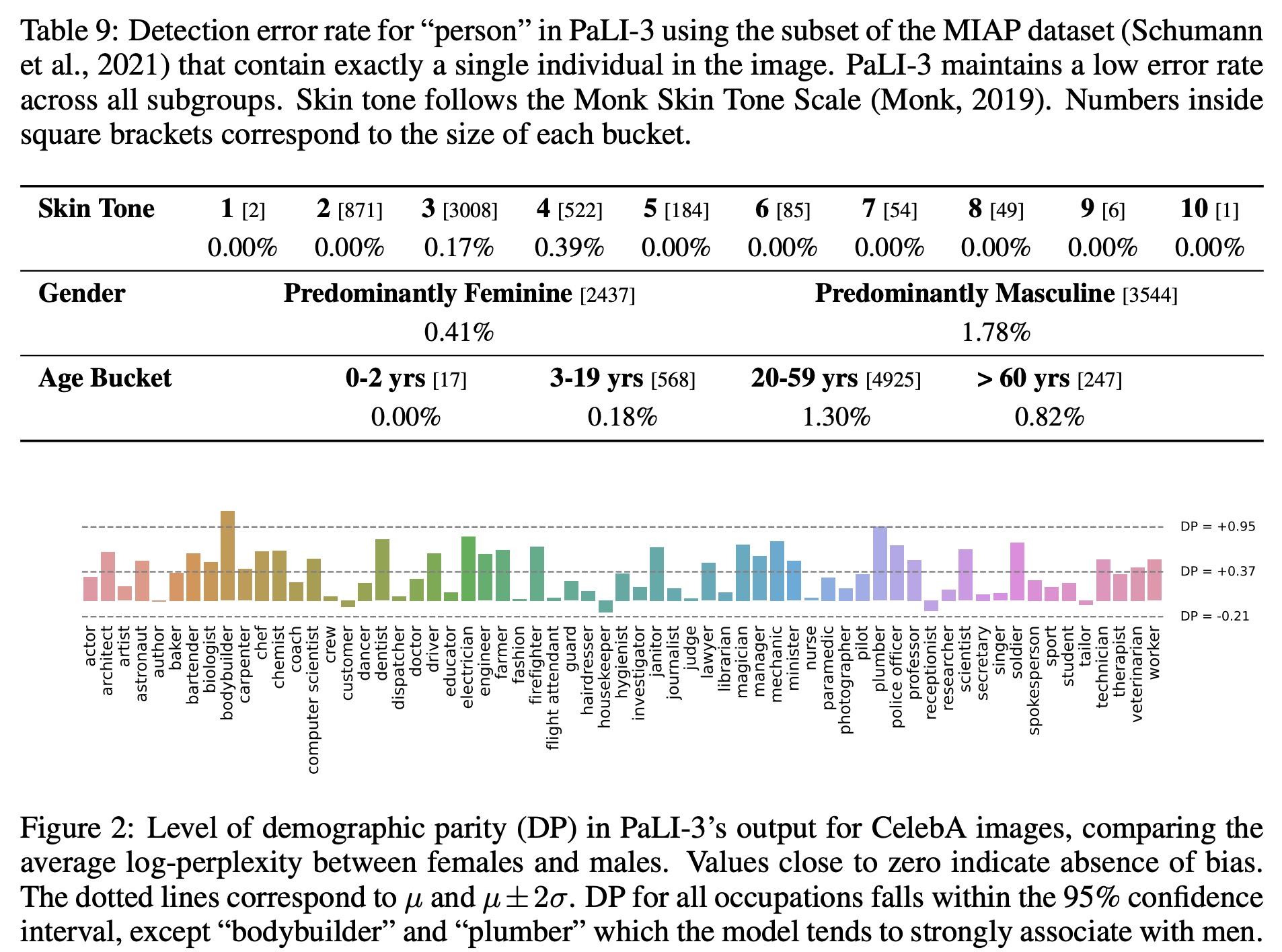
- Demographic Parity Examination: Using the CelebA dataset, the model’s response to images with occupation prefixes was analyzed. PaLI-3 showed a tendency to assign a higher log-perplexity score to women than men across most occupations.
- Performance Across Subgroups: On a detection task using the MIAP dataset, the model’s accuracy in identifying the presence of a person in images with a single individual was evaluated. The error rate was found to be very low across all subgroups.