Book Review: A Practical Guide to Reinforcement Learning from Human Feedback

I was offered to read A Practical Guide to Reinforcement Learning from Human Feedback by Sandip Kulkarni in exchange for an honest review. The book covers the full RLHF pipeline across 12 chapters: from classical reinforcement learning through reward modeling and PPO-based fine-tuning, and then into newer methods like DPO, RLAIF, and Constitutional AI. I liked this book and consider it to be a well-structured learning resource providing good theory basics and a lot of practical examples.
The overall structure

The book follows a deliberate three-stage progression:
- Explaining the core principles of reinforcement learning and policy optimization
- Building a complete RLHF pipeline for LLMs
- Exploring the evolution of alignment research
By the time you reach DPO in Chapter 10, you understand why it exists, because you have already built a reward model, dealt with PPO’s clipped objective, and seen the full canonical RLHF loop in action. That kind of understanding is hard to get from blog posts or paper summaries alone.
I also liked that the implementations use real libraries (TRL, PEFT, Hugging Face ecosystem) rather than building everything from scratch. In industry, we use existing tooling to avoid bugs and save time, and the book does the same. The memory optimization advice scattered through the middle chapters (gradient checkpointing, staged model loading, working within Colab constraints) is the kind of practical wisdom that many books skip entirely.
What I liked
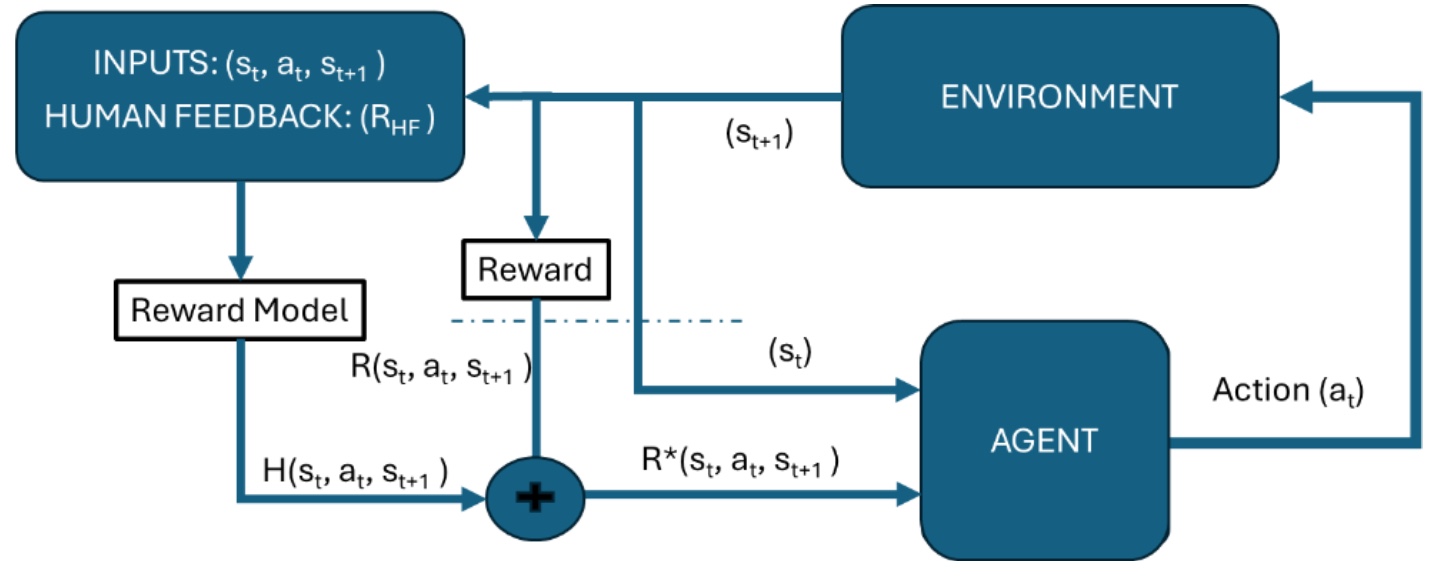
There were many things in this book that I liked, and I want to highlight several in particular:
- The discussions on annotator bias and labeling evaluation were especially interesting for me, as on one of my projects, we spend months on organizing data labeling
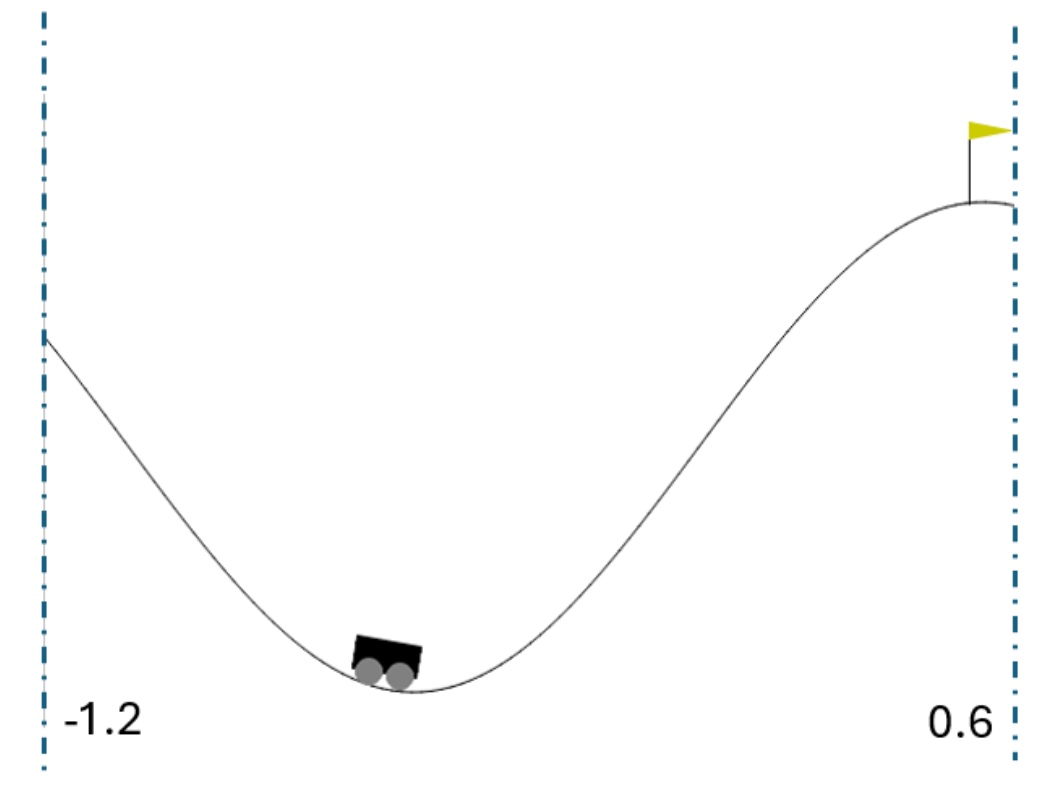
- Using human keyboard inputs for Mountain Car demonstrations was fun
- The code walkthroughs for configuring PEFT and LoRA were highly practical and well-written
- Using smaller models like Qwen2-0.5B-Instruct makes it easier to play with them when you don’t have good enough hardware for larger models
- The visualizations explaining the intuition behind the algorithms were great.
Chapters 9–12 are very interesting and useful; they cover modern approaches and offer many practical tips. The Constitutional AI section includes deployment architecture, transparency mechanisms, and governance considerations that feel like they were written by someone thinking about production systems, not just research experiments. The comparison between DPO and PPO trade-offs is well-argued and clearly presented. The evaluation chapter tackles genuinely hard problems (self-preference bias of LLM judges, mode collapse, the difficulty of proxy evaluations) without pretending there are clean answers.
What could have been better
There are some things that could have been handled differently or better:
- I’m not sure if it was necessary to explain self-attention and transformers in such detail.
- The TRL library versions are inconsistent across chapters, and since TRL’s API changed significantly between these versions, it would be great if all chapters used the latest version.
- I’d love to see some examples of UI/UX for data collection and user annotation.
But these are small nitpicks that are completely overshadowed by the good sides of the book.
Conclusion
This book is a good fit for ML practitioners seeking a single, structured resource that covers the RLHF landscape from foundations to modern methods. It is particularly useful for people transitioning into post-training roles, or for anyone who learns better from implementations than from papers. The code is reproducible, the tooling is up to date, and the pedagogical progression genuinely helps build intuition.
RLHF is moving fast, and any book on the topic will age quickly in its specifics. The value here is less in the details of any particular implementation and more in the mental scaffold: what reward models do, why evaluation is hard, how newer methods relate to older recipes, and why alignment is an engineering discipline rather than a collection of tricks. That scaffold holds up, even as the field continues to evolve.
blogpost books rl rlhf llm