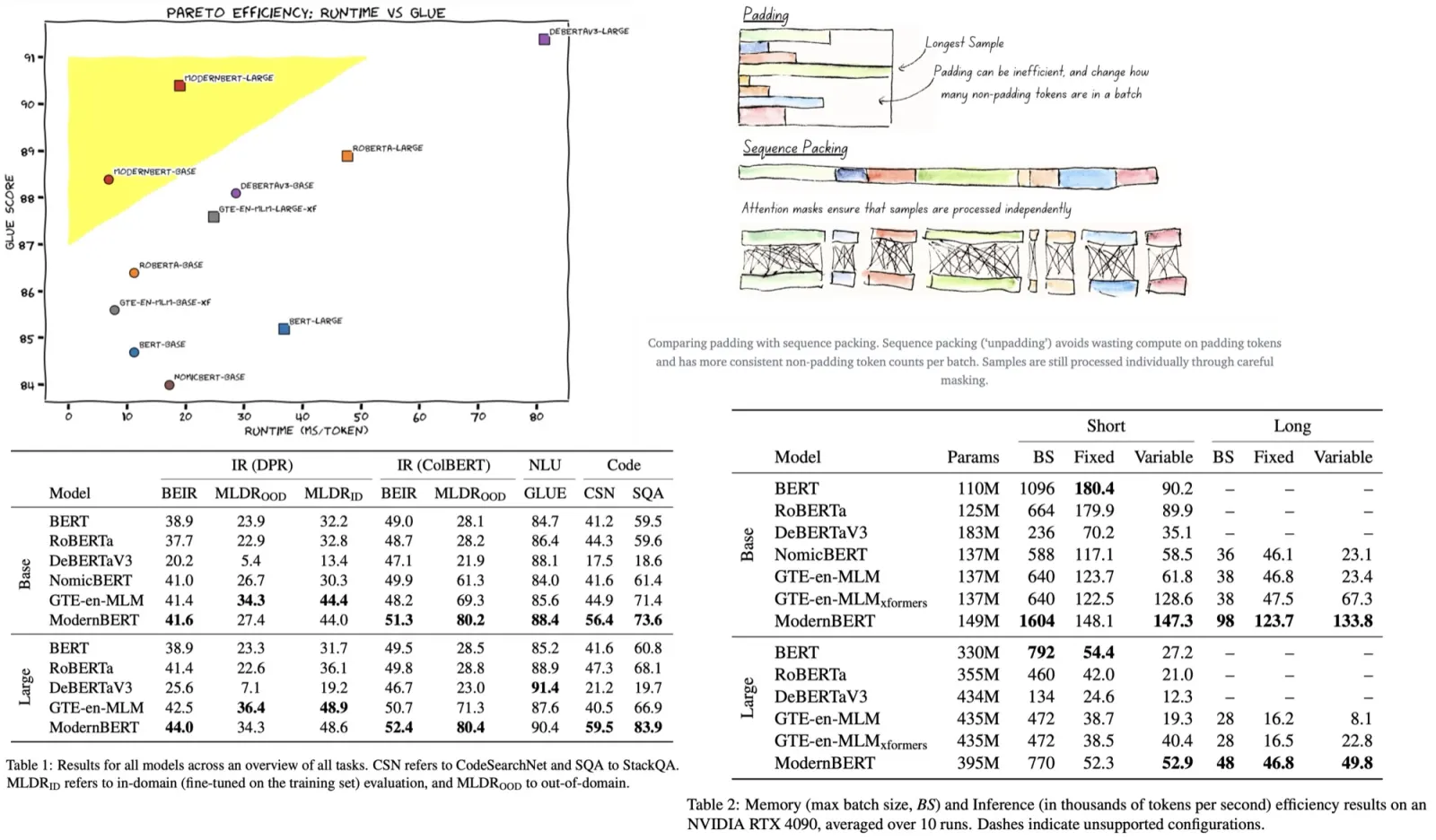
Paper Review: Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
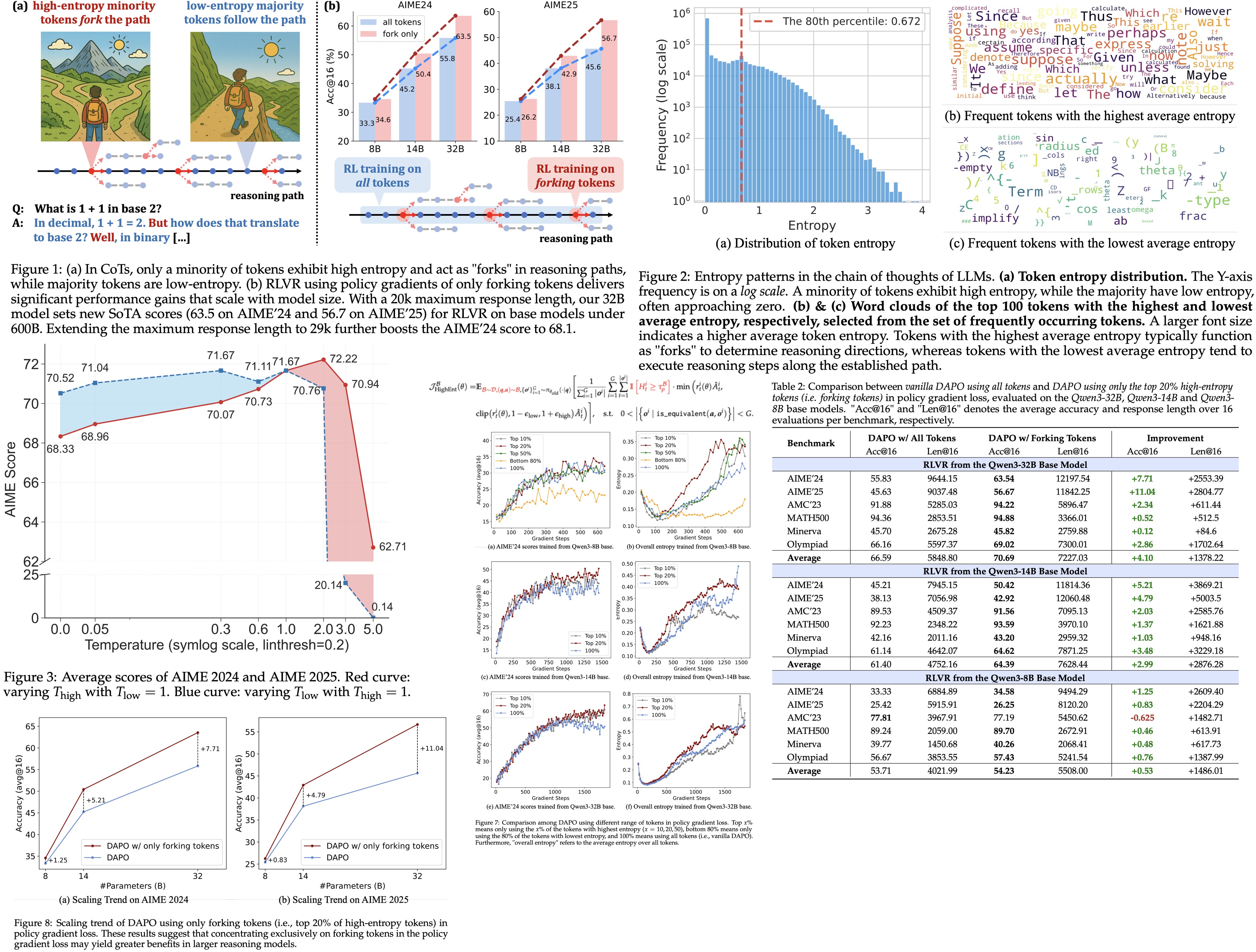
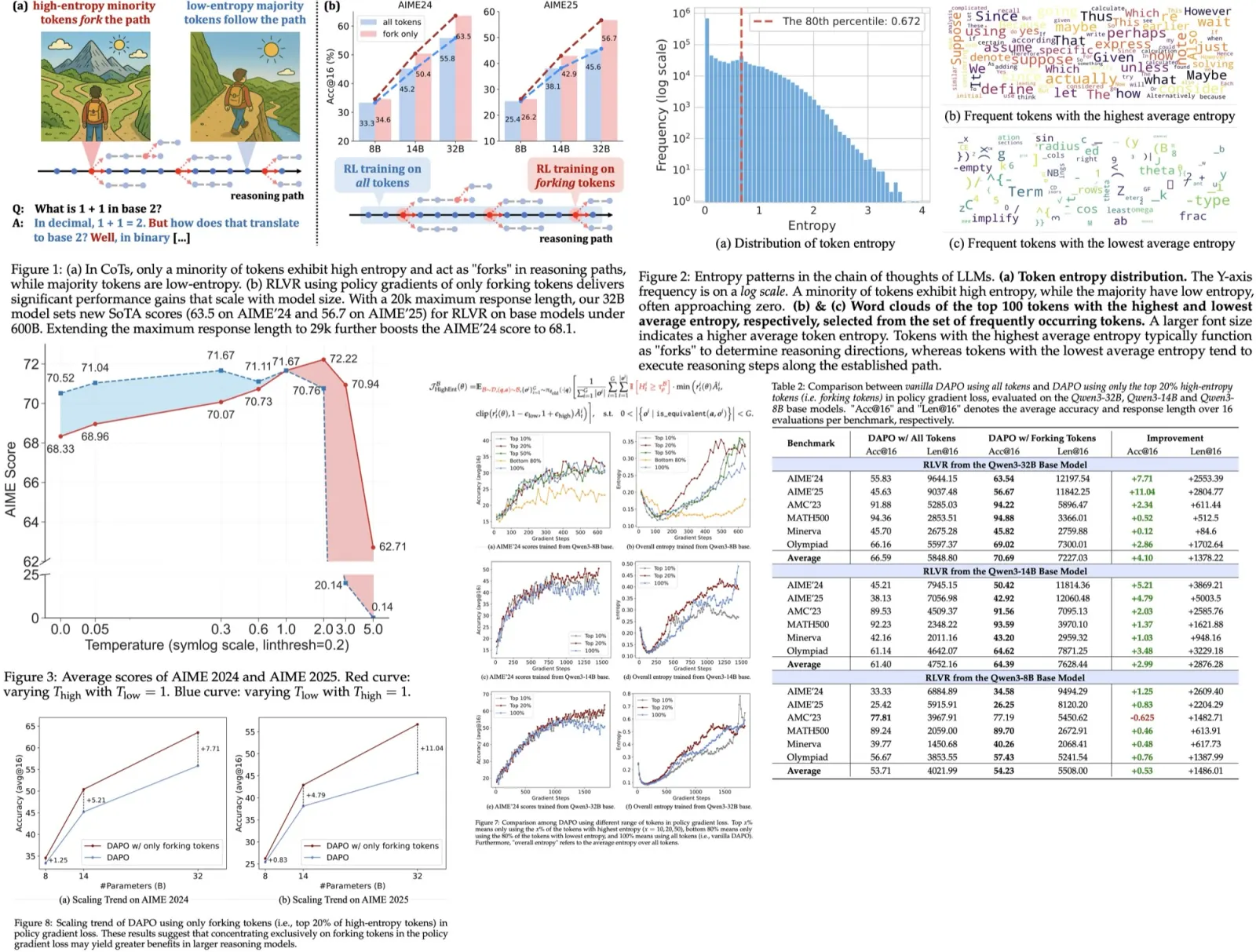
The authors observe that Reinforcement Learning with Verifiable Rewards (RLVR) improves LLM reasoning by selectively optimizing high-entropy tokens (critical points that steer reasoning paths). Most tokens have low entropy; only a small fraction (about 20%) act as forks guiding diverse reasoning. Restricting updates to these tokens maintains or enhances performance, especially at larger scales (Qwen3-32B, Qwen3-14B), while updating low-entropy tokens harms performance.
Preliminaries
Token entropy at position t measures the uncertainty of the model’s generation distribution at that step, defined as the entropy of the probability distribution over the vocabulary (after softmax). It reflects how uncertain the model is when selecting the next token, not a property of the token itself. The same token appearing in different positions can have different entropies. Even in off-policy training, entropy is computed from the current training policy’s distribution.
There are several policy optimization methods for RLVR:
- PPO: A standard method that stabilizes policy updates by clipping them to stay close to the old policy. It uses a value network to compute the advantage (how much better a given action is than expected).
- GRPO: An improved variant that removes the value network. Instead, it estimates the advantage by comparing each sampled response’s reward to the mean and standard deviation of rewards within a group of responses for the same query. It adds a KL penalty to keep the new policy close to the old one.
- DAPO (Dynamic sAmpling Policy Optimization): A further improvement over GRPO. It removes the KL penalty, introduces dynamic sampling, applies token-level policy gradients, shapes rewards for longer outputs, and uses a clip-higher mechanism. DAPO is considered a state-of-the-art method for RLVR without requiring a value network.
The authors use DAPO as the baseline RLVR algorithm.
Analyzing Token Entropy in Chain-of-Thought Reasoning
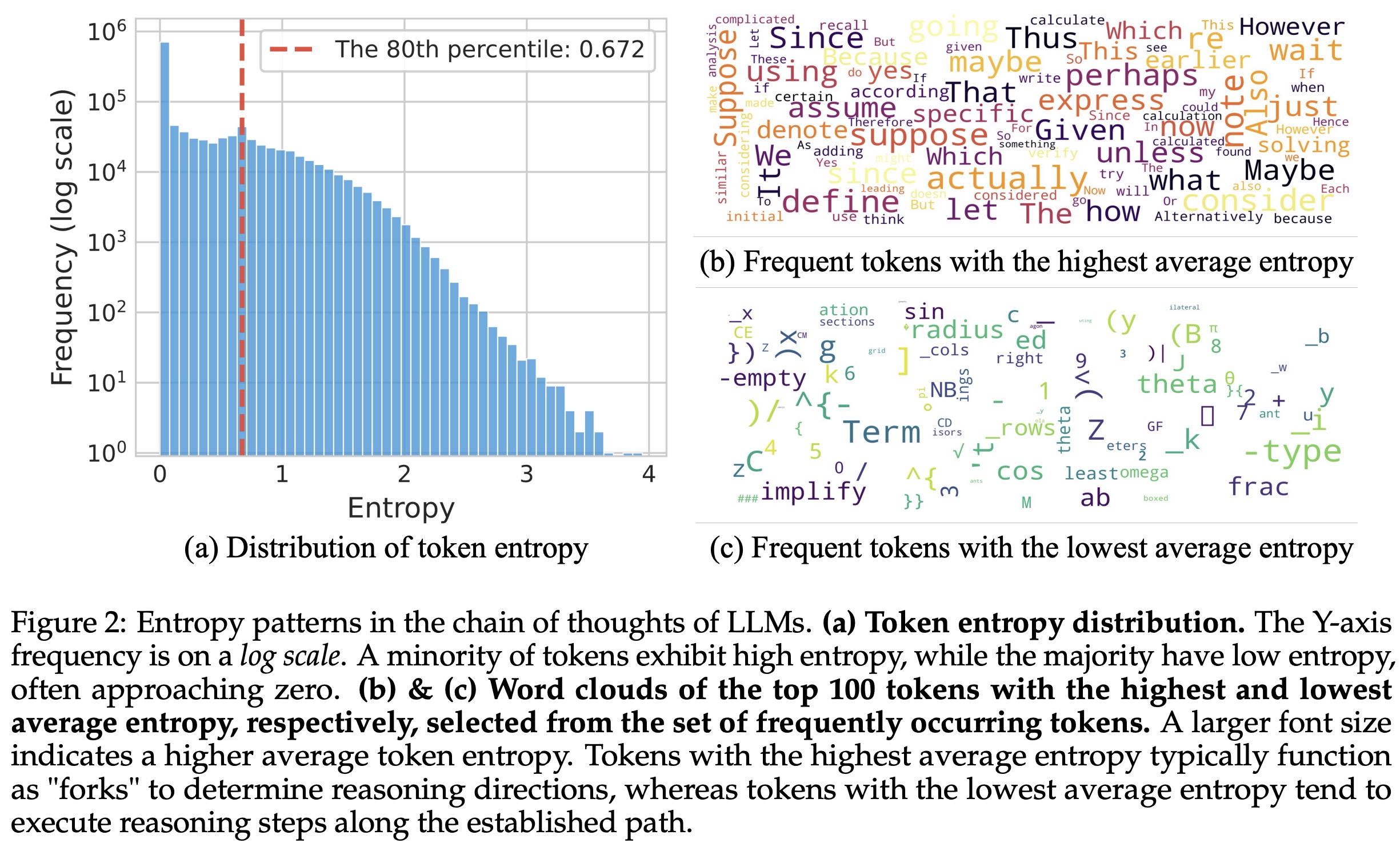
Token-level analysis of generation entropy in Chain-of-Thought reasoning shows two key patterns:
- Most tokens have low entropy, while a small minority (~20%) have high entropy.
- Forking tokens typically act as logical connectors (such as “however”, “because”, “thus”), guiding reasoning branches, while low-entropy tokens complete sentences or deterministic elements (suffixes, source code fragments, or mathematical expression components).
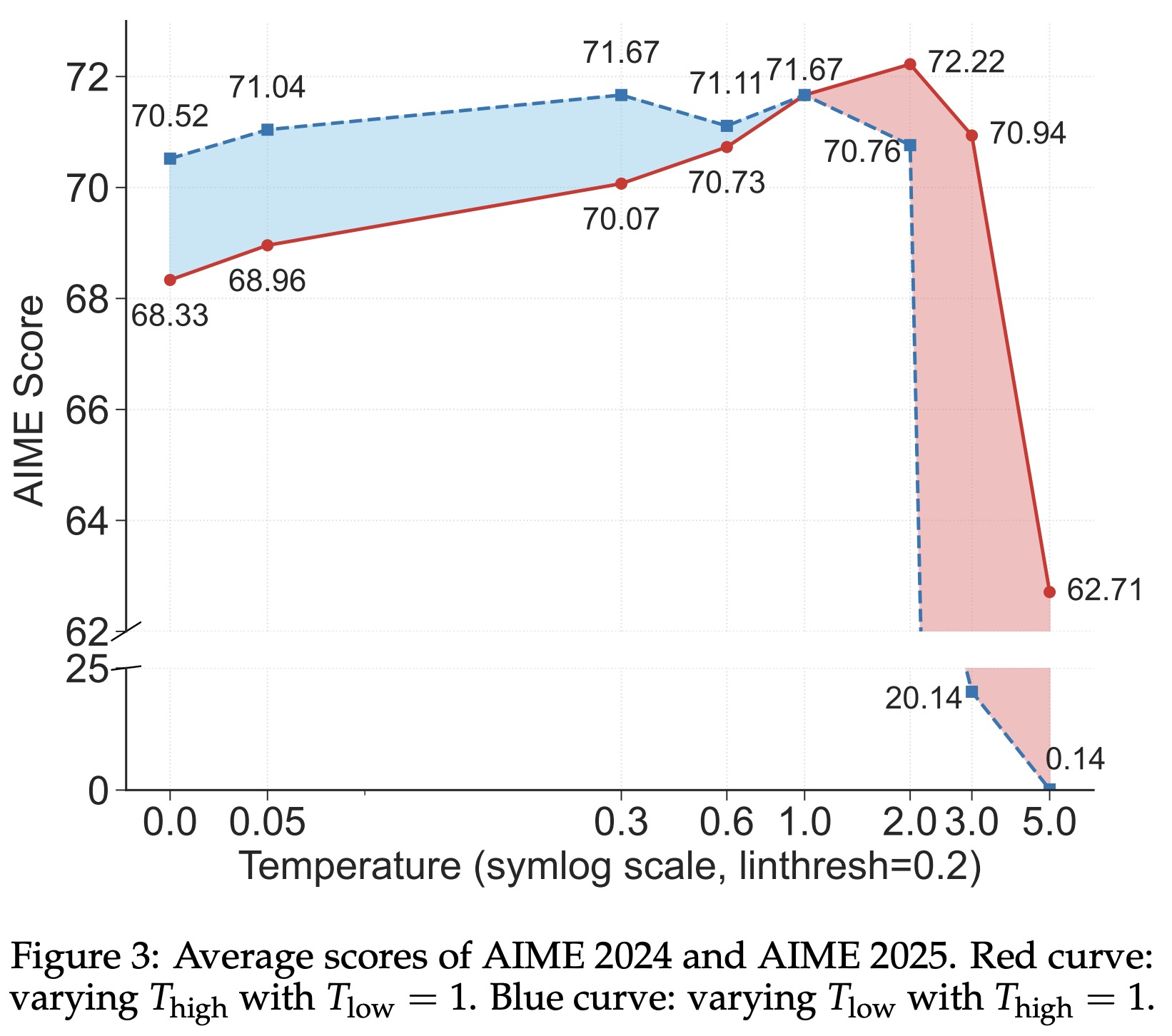
Experiments confirm that tuning decoding temperature for forking tokens affects performance: raising their temperature improves reasoning, while lowering it harms it. This supports the idea that forking tokens should retain high entropy to enable flexible reasoning paths.
RLVR Preserves and Reinforces Base Model Entropy Patterns
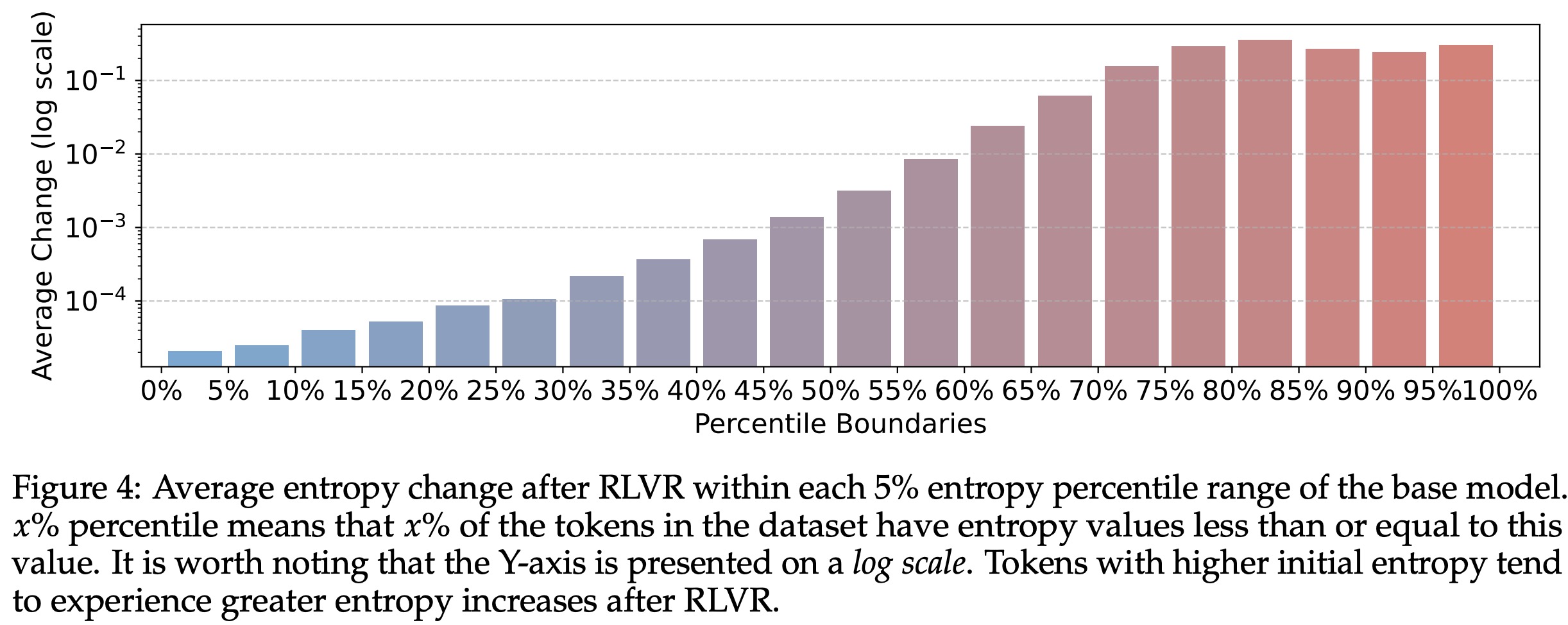
During RLVR training (using DAPO on Qwen3-14B), the model largely preserves the original entropy patterns of the base model. High-entropy tokens remain mostly consistent (over 86% overlap with the base model even at training convergence). RLVR mainly adjusts the entropy of these high-entropy tokens, increasing their entropy further, while low-entropy tokens remain stable with minimal change.
High-Entropy Minority Tokens Drive Effective RLVR
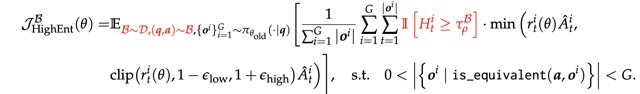
The authors modify DAPO by applying policy gradient updates only to high-entropy tokens. For each training batch, it selects the top-ρ fraction of tokens (by entropy) and discards gradients from low-entropy tokens. The objective remains the same as in DAPO, but only tokens meeting the high-entropy threshold contribute to the gradient calculation.
Both configurations, full-gradient RLVR (vanilla DAPO) and high-entropy-only RLVR, use the same techniques: clip-higher, dynamic sampling, token-level policy gradient loss, and overlong reward shaping. Importantly, the training excludes both KL divergence loss and entropy loss.
Results
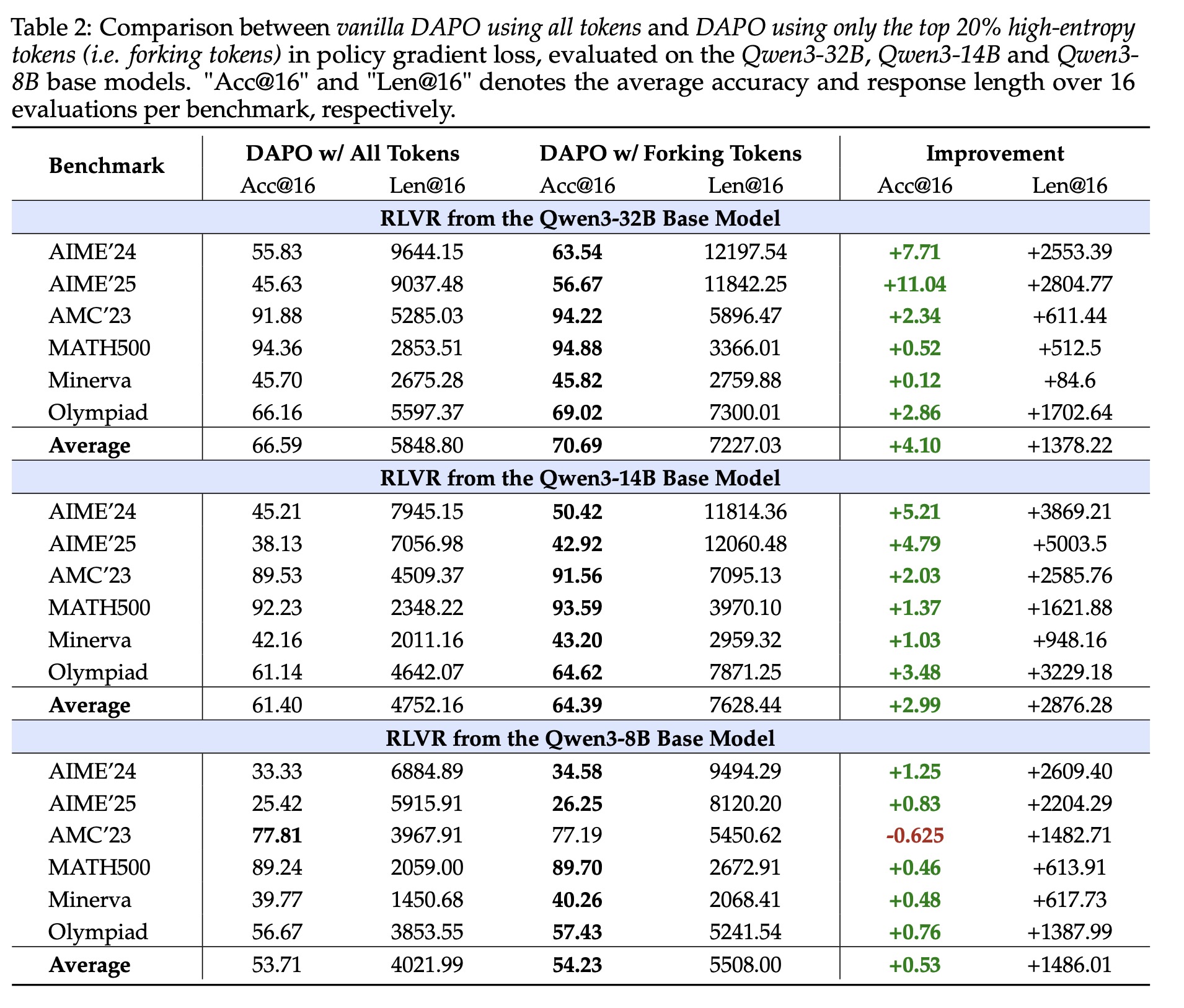
Focusing policy gradient updates on only the top 20% high-entropy tokens during RLVR improves or maintains reasoning performance, especially in larger models (Qwen3-14B, Qwen3-32B). Discarding the bottom 80% low-entropy tokens not only avoids harm but can even boost results, which suggests that low-entropy tokens contribute little or may hinder reasoning.
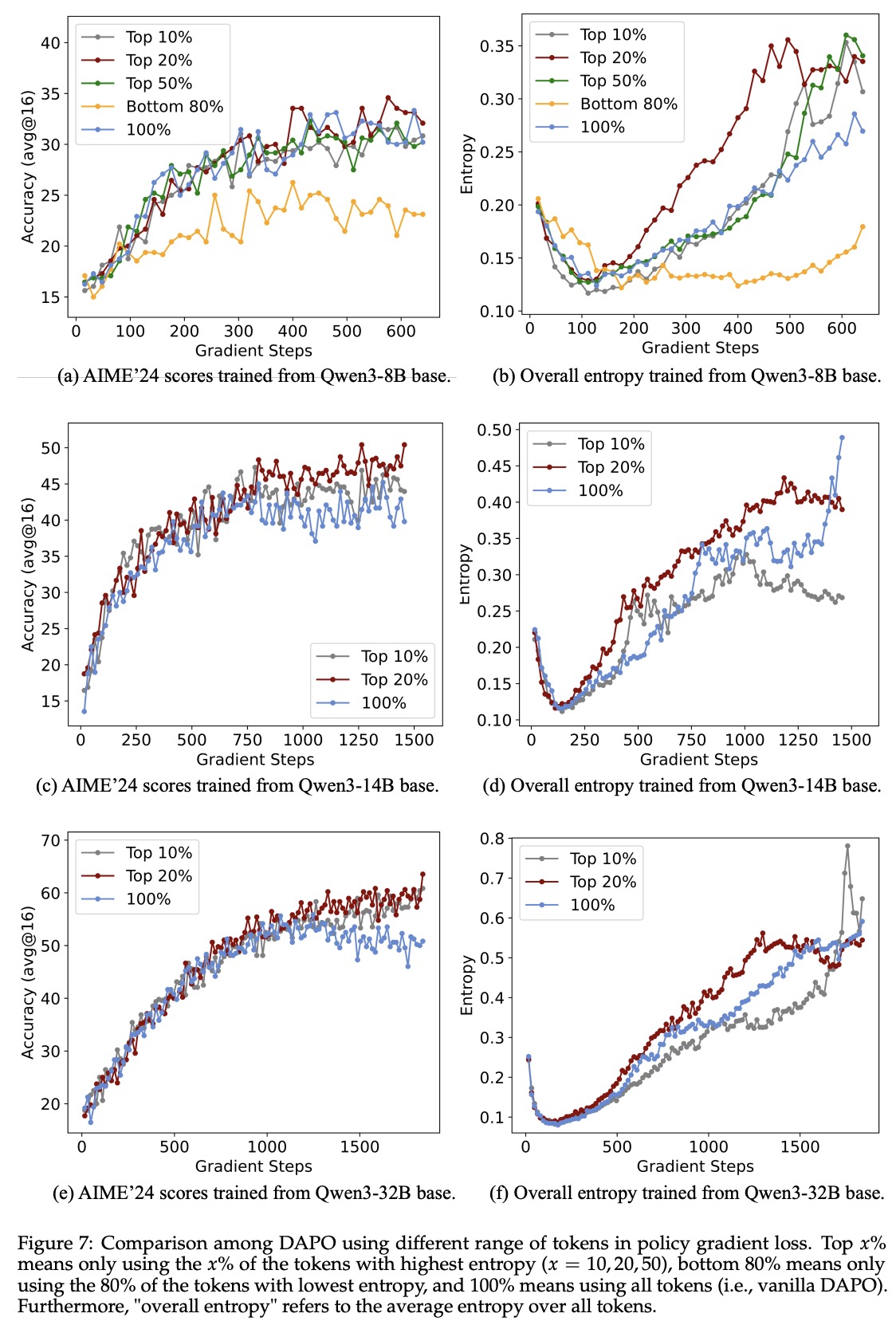
Varying the proportion of high-entropy tokens shows that performance is stable when using around 20%, but declines if too few or too many tokens are used. Retaining high-entropy tokens supports effective exploration during training, which appears key for improving reasoning, especially in larger models.
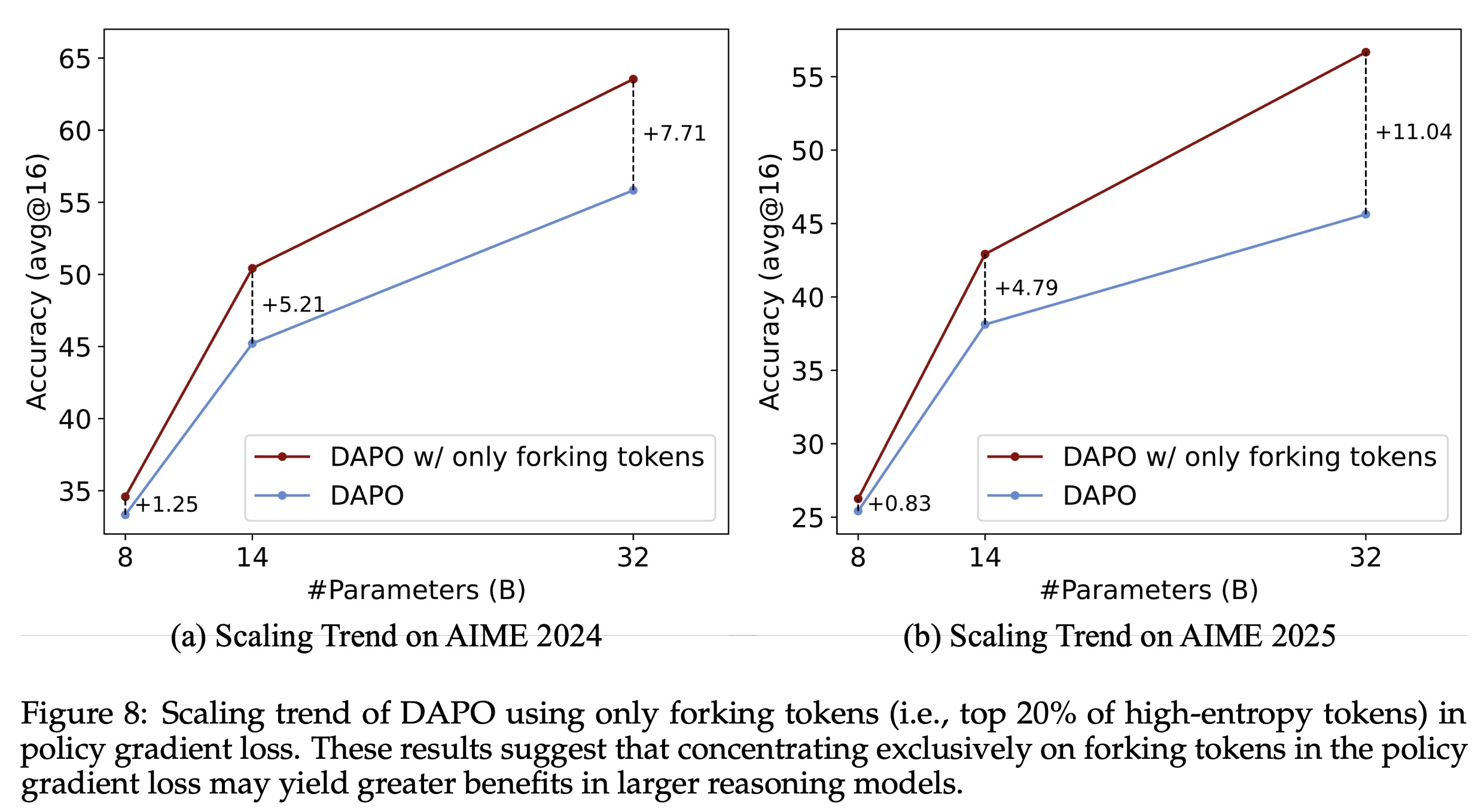
The benefits of this focused approach scale with model size - larger models show greater gains when training emphasizes high-entropy tokens. In smaller models like Qwen3-8B, the effect is weaker due to limited model capacity.
Discussions
- Why RL generalizes better than SFT: RL tends to preserve or increase the entropy of forking tokens, maintaining flexible reasoning paths, and enabling generalization to unseen tasks. In contrast, SFT reduces token entropy, leading to memorization and poor generalization.
- LLM reasoning vs traditional RL: LLM Chain-of-Thought outputs have a mixed entropy structure - mostly low-entropy tokens (for linguistic fluency) with a small fraction of high-entropy tokens driving reasoning exploration. In contrast, traditional RL typically uses uniform action entropy. This difference stems from LLM pretraining and the need to generate readable text.
- Entropy bonuses in RLVR: Uniformly applied entropy bonuses (common in RL) are suboptimal for LLM reasoning, as they disrupt low-entropy tokens critical for fluency. Clip-higher selectively promotes entropy in high-entropy tokens, enhancing reasoning performance without harming linguistic structure.