Book Review: Unlocking Data with Generative AI and RAG, Second Edition

I was offered an opportunity to read Unlocking Data with Generative AI and RAG, Second Edition, by Keith Bourne, in exchange for an honest review. I reviewed the first edition back in 2024 and liked it, so I was curious to see how the second edition would handle the fact that RAG has since absorbed an entirely new layer of the stack — agents, graph retrieval, semantic caches, and memory systems. The book covers the modern RAG landscape across 20 chapters in three parts: classical RAG foundations, production-grade retrieval and evaluation, and an entirely new Part III on agentic RAG spanning LangGraph, ontology-driven graph RAG with Neo4j, semantic caching, and the CoALA memory framework. I liked this book, and its biggest strength is the continuous running example that carries you from a basic retriever in Chapter 2 all the way to a stateful, learning agent in Chapter 19 — a thread very few books manage to present.
The overall structure

The book is organized into three parts:
- Part I (Chapters 1–6) introduces RAG and its vocabulary, gets a complete pipeline running by Chapter 2, and then layers in practical applications, a security chapter with red and blue teaming, and a Gradio UI for demos.
- Part II (Chapters 7–11) goes deeper into the components: vectors and vector stores, similarity search, evaluation with Ragas, the LangChain retrievers and integrations, and the loaders, splitters, and output parsers that hold a real RAG system together.
- Part III (Chapters 12–19) is where the second edition contributes the most: agents and LangGraph, ontology engineering with Protégé, graph RAG on Neo4j, semantic caching, the CoALA memory framework, and a capstone investment-advisor agent that integrates all four CoALA memory types.
The implementations use real libraries rather than building everything from scratch, which mirrors how most teams actually work and saves the reader from the usual from-scratch boilerplate.
What I liked
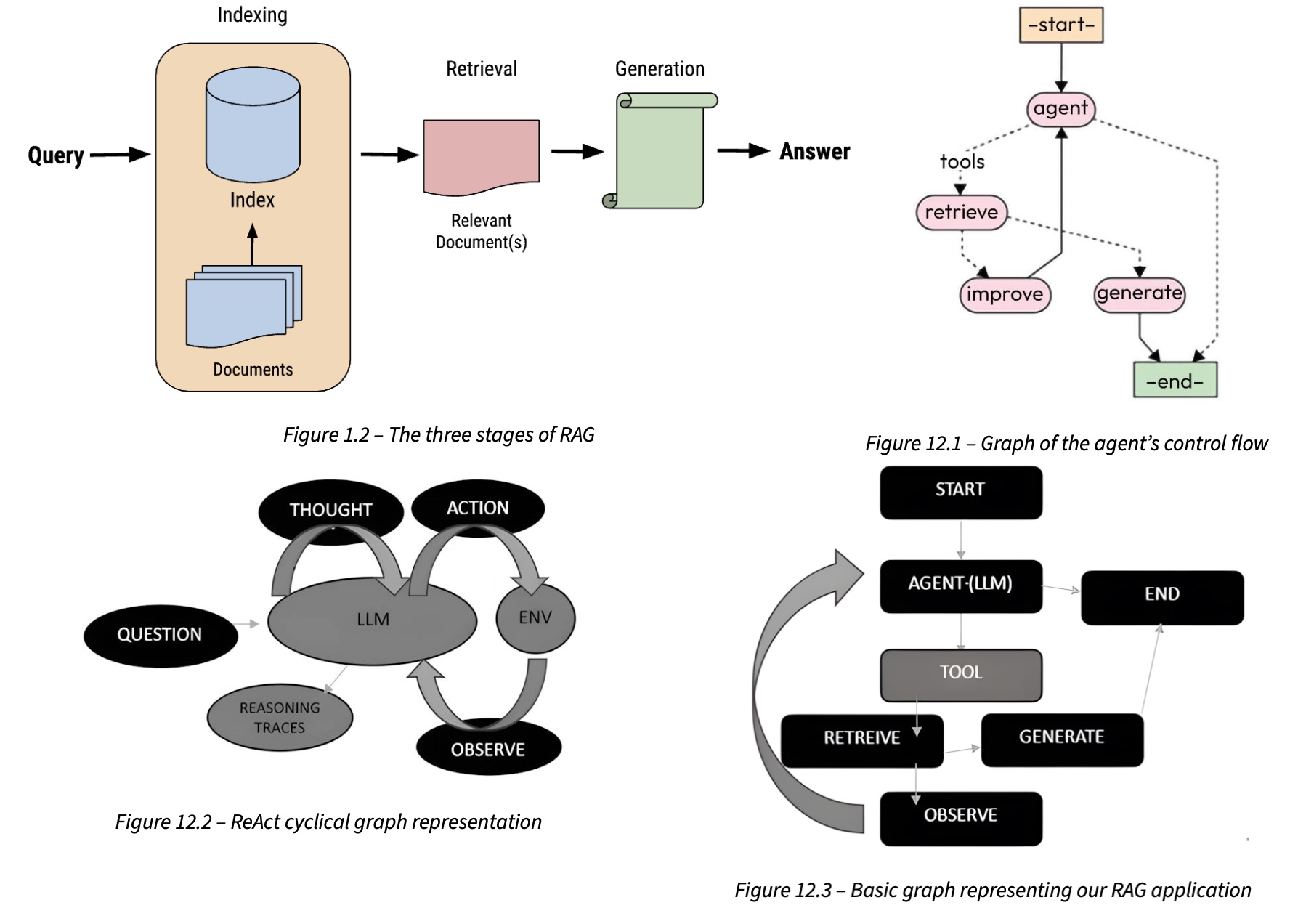
There were many things I liked in this book, and I want to highlight several in particular:
- The single running example is used throughout all 20 chapters. I’ve read enough ML books where each chapter is its own throwaway notebook, so I really appreciate it when one isn’t, and the continuity makes it easier for me to follow the ideas presented in the book.
- The small but important Chapter 3 detail of returning sources alongside answers. Until we have full trust in LLM, being able to answer the question “where did this answer come from?” is very important.
- Chapter 9’s evaluation is built around Ragas — faithfulness, answer relevancy, context precision, context recall, plus direct insights from a Ragas co-founder. A lot of evaluation work happens after deployment, which matches my experience on several real projects.
- Chapters 13–14 guide you from building a financial ontology in Protégé to loading it into Neo4j with hybrid embeddings that blend text and graph structure. Designing a clean ontology has the same slow, painful, valuable feel as the months we spent organizing data labeling on one of my past projects: it is the kind of upfront work that pays off everywhere downstream.
- The Chapter 5 red team / blue team prompt-injection lab. Security chapters in ML books usually read like policy documents, while this one actually has you attacking and defending your own RAG pipeline, which is a much better way to build practice.
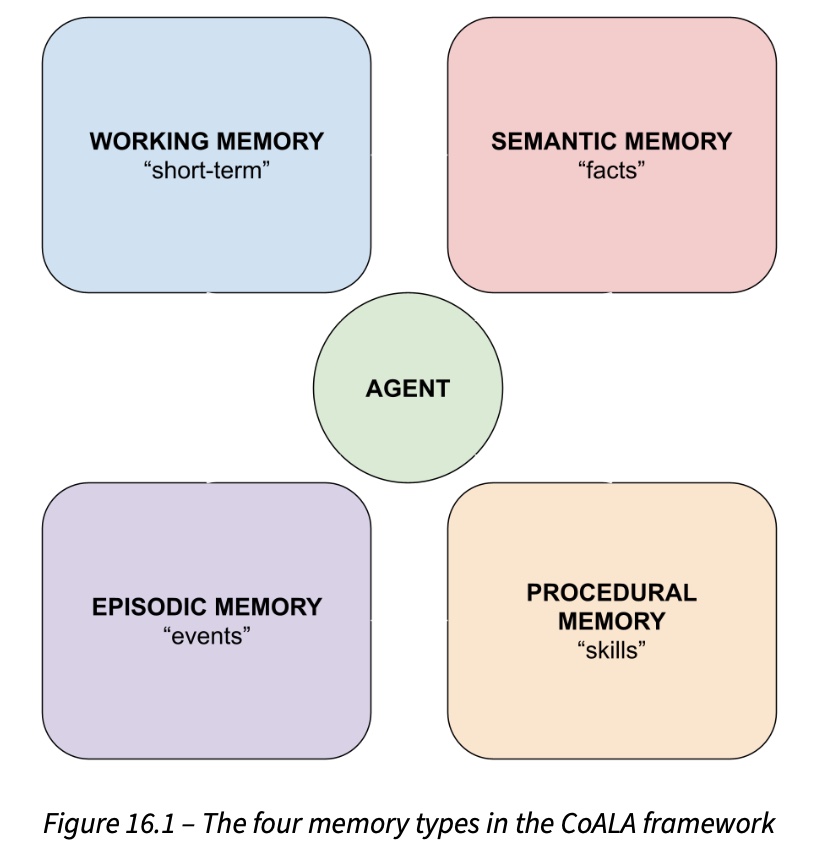
The standout production chapter for me was Chapter 15 on semantic caches. The long-tail framing of real-world queries, the cross-encoder verification step, the adaptive thresholds, and the eviction policy discussion are exactly the level of detail that separates a toy semantic cache from one that won’t embarrass you in production. Chapter 16 had a great comparison of three agentic memory frameworks: Mem0, LangMem, and Zep/Graphiti. And Chapter 19 brings everything together into a capstone investment-advisor agent that uses working, episodic, semantic, and procedural memory simultaneously.
What could have been better
There are a few small things that could have been handled differently:
- Failure modes are under-discussed. Almost every chapter sells the upside of its technique and skips what breaks. Agents make systems slower and harder to debug, cached answers can become stale, and memory stores can grow in ways that hurt retrieval. Such a comprehensive book could be more honest about the failure side, and I’d love a “what goes wrong” subsection in each Part III chapter in a future edition.
- A few places could use head-to-head numbers. When graph-based RAG is introduced, or when the memory-equipped agent is presented, I’d have liked even one quantitative comparison against a simpler baseline on the same questions — the architectures are convincing in concept, and a small numbers-on-a-table moment would make them convincing in practice too.
- The introduction chapter includes a table listing popular models and their context lengths for October 2025 – some of these models were already outdated at that time.
But these are small nitpicks that are completely overshadowed by the good sides of the book.
Conclusion
This book is a good fit for RAG practitioners past the hello-world stage — people who already know what an embedding is and what a retriever does, and who now want to go beyond basic vector search. It is particularly useful for engineers being asked to turn a working RAG prototype into something that handles evaluation, security, caching, and agentic workflows without falling apart in production. If you already own the first edition, the question is whether Part III is worth the upgrade, and the answer is yes — Chapters 12 through 19 are essentially a self-contained book on agentic RAG, and very few other resources cover this terrain end-to-end with working code.
RAG is moving fast, and any book on the topic will age quickly in its specifics — LangChain APIs will churn, new memory libraries will appear, and several embedding-model tables will look dated within a year. The value here is less in the details of any particular notebook and more in the mental scaffold: how retrieval quality connects to evaluation, how agents extend the RAG loop, why memory systems matter once an agent lives longer than a single turn, and where graph-based retrieval earns its weight. That scaffold holds up, even as the field continues to evolve.
blogpost books llm rag agents