Paper Review: Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Retrieval-augmented language models (RALMs) are enhanced by using external knowledge sources, but they face challenges such as retrieving irrelevant information and failing to use their inherent knowledge. They also struggle to determine when they have sufficient information for accurate answers, often not indicating when knowledge is lacking. To improve this, Chain-of-Noting (CON) has been introduced, which generates sequential reading notes for retrieved documents to evaluate their relevance and integrate this evaluation into the final answer. Developed using ChatGPT for training data and applied to an LLaMa-2 7B model, CON significantly improves RALMs’ performance on four open-domain QA benchmarks. It is particularly effective in handling noisy documents and questions outside the model’s pre-training knowledge, leading to higher accuracy and better rejection rates for unknown scenarios.
Method
Background
RALMs represent an advancement in language models by incorporating external knowledge sources. These models work by using an auxiliary variable representing retrieved documents to generate responses based on the input query and the content of these documents. However, due to the vast number of potential sources, they approximate the response generation process using the top-ranked documents.
Despite their advancements, RALMs have several limitations:
- Risk of Surface-Level Processing: RALMs might rely on superficial information missing nuances in complex or indirect questions.
- Difficulty in Handling Contradictory Information: They struggle when faced with contradictory information in documents, finding it challenging to resolve these contradictions or to determine which information is more credible.
- Reduced Transparency and Interpretability: The direct generation of answers by RALMs offers limited insight into the decision-making process, making it hard for users to understand how conclusions were reached.
- Overdependence on Retrieved Documents: RALMs may over-rely on the content of retrieved documents, potentially ignoring the model’s inherent knowledge. This can be problematic, especially when the documents are noisy or outdated.
The chain-of-note framework

The chain-of-note framework addresses the limitations of RALMs by enhancing their ability to critically assess retrieved documents. This is achieved through a structured note-taking process, where the model generates concise, relevant summaries for each document. This method allows for systematic evaluation of the information’s relevance and accuracy, improving response quality.
In practice, given an input question and retrieved documents, the model generates reading notes for each document before synthesizing a final response. The CON framework follows three key steps:
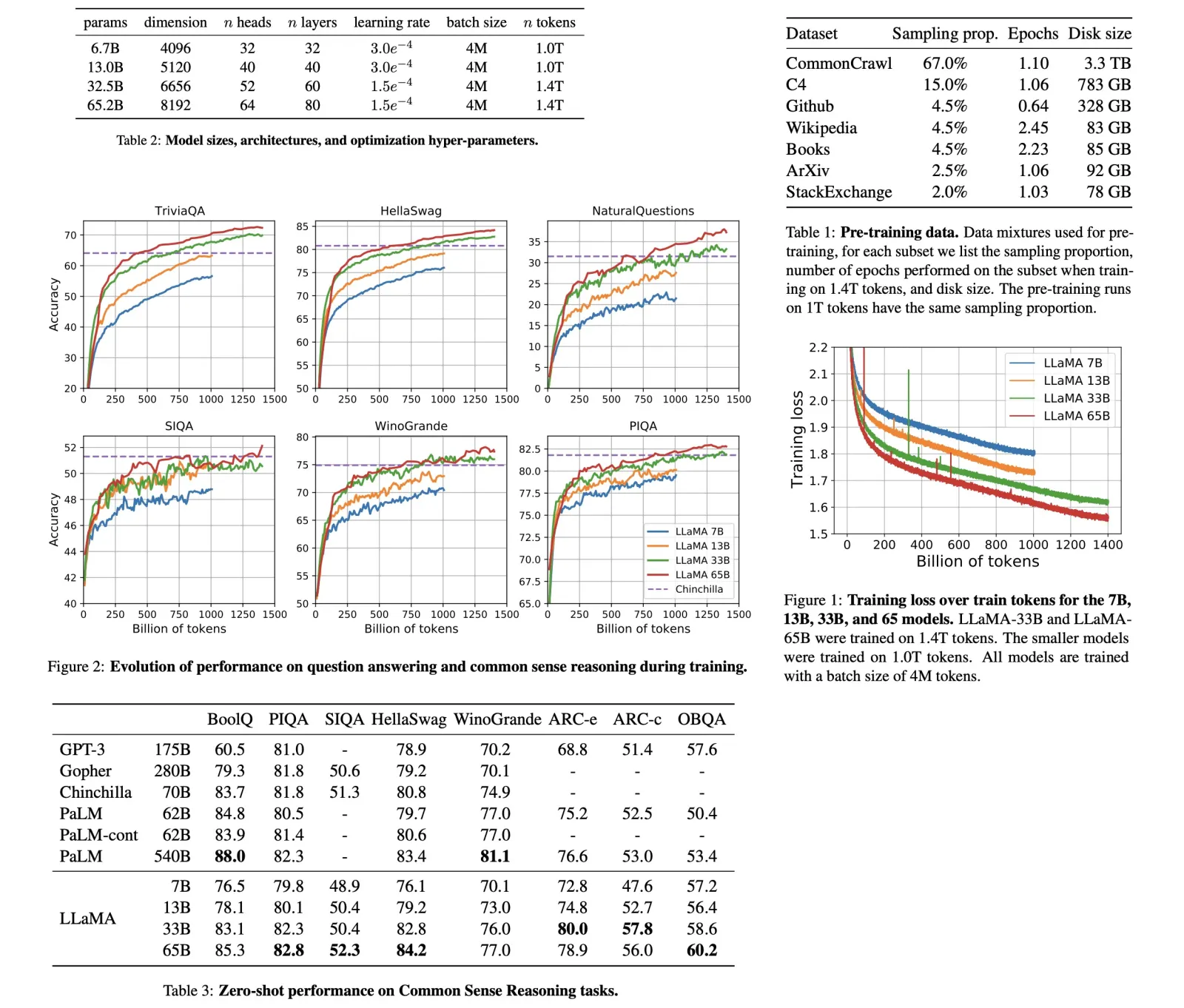
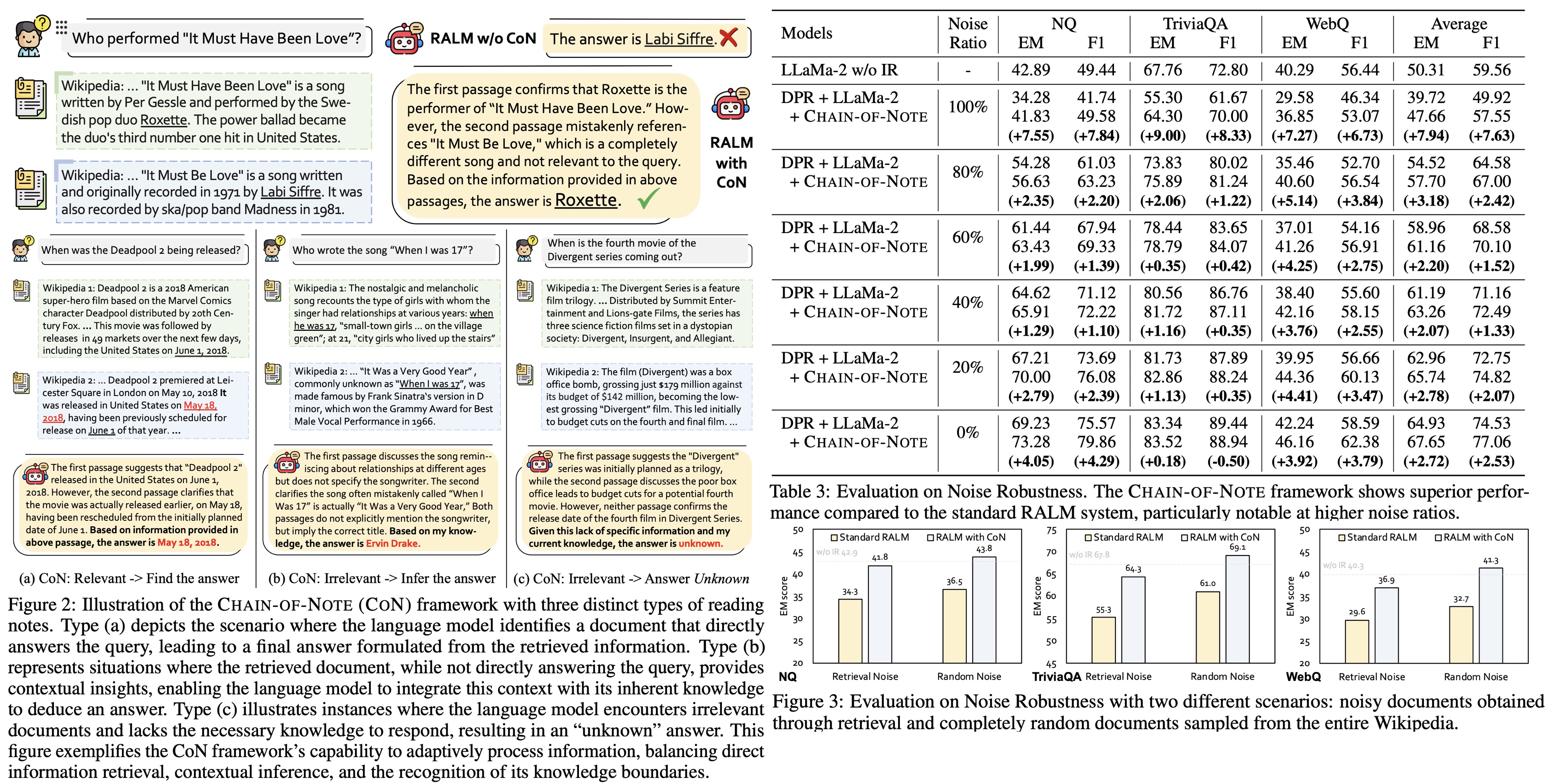
- Notes Design: CON constructs reading notes based on the relevance of the documents to the query. It directly answers from relevant documents, infers answers using context from partially relevant documents, and defaults to “unknown” if documents are irrelevant or insufficient for a response.
- Data Collection: Training data for these reading notes is generated using ChatGPT. This involves sampling 10k questions from the NQ dataset and prompting ChatGPT to create notes, which are then evaluated through human evaluation. The model’s adaptability is further tested on various open-domain datasets.
- Model Training: The model, based on the LLaMa-2 7B architecture, is trained with the collected data. It learns to generate reading notes corresponding to the relevance of each document to the input query. A weighted loss is used to balance the focus between reading notes and the final answer, ensuring the accuracy and reliability of responses.
Experiments
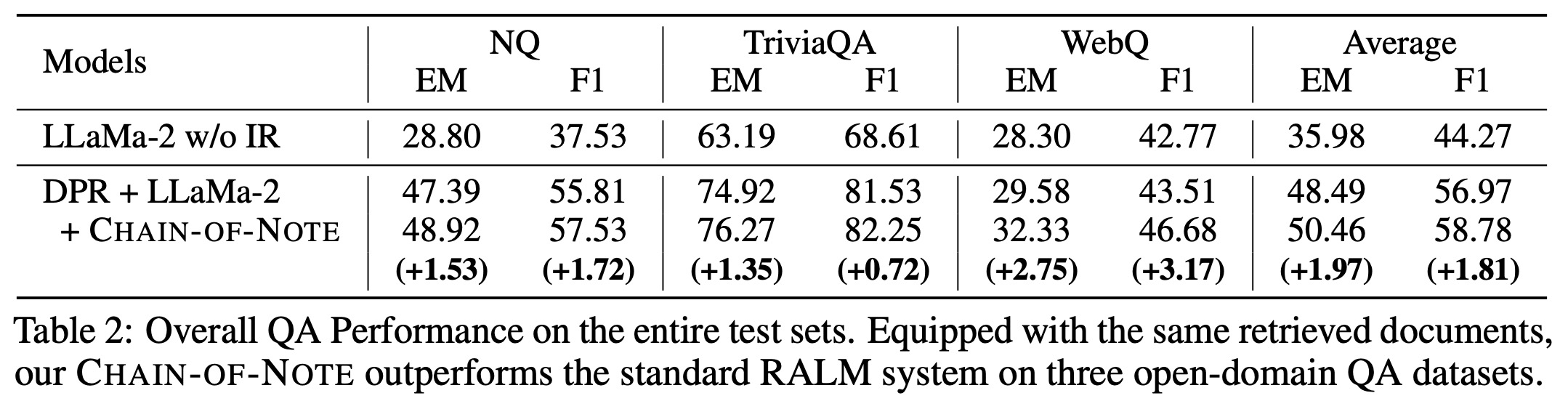
RALMs incorporating the Dense Passage Retrieval (DPR) method and the LLaMa-2 model with retrieval functionality consistently outperformed the LLaMa-2 model alone. This improvement is largely attributed to the effectiveness of the retrieval process. Notably, DPR showed better retrieval performance on the NQ and TriviaQA datasets compared to WebQ, indicating more pronounced benefits of retrieval on these datasets.
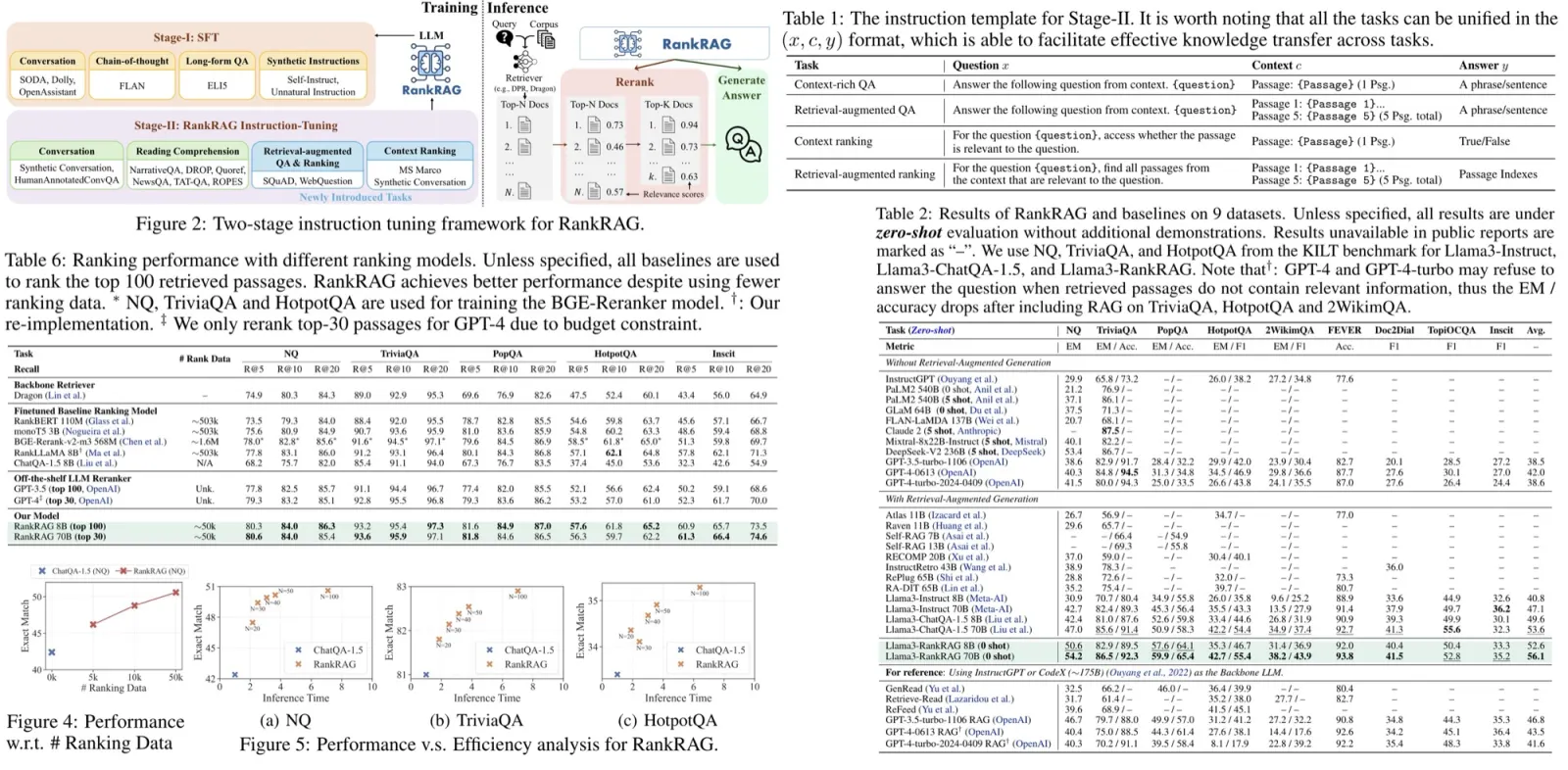
Further, enhanced RALM integrating CON outperformed standard RALMs. There was an average improvement of +1.97 in Exact Match scores across all datasets. CON particularly improves RALMs’ performance in scenarios where more noisy documents are retrieved initially.
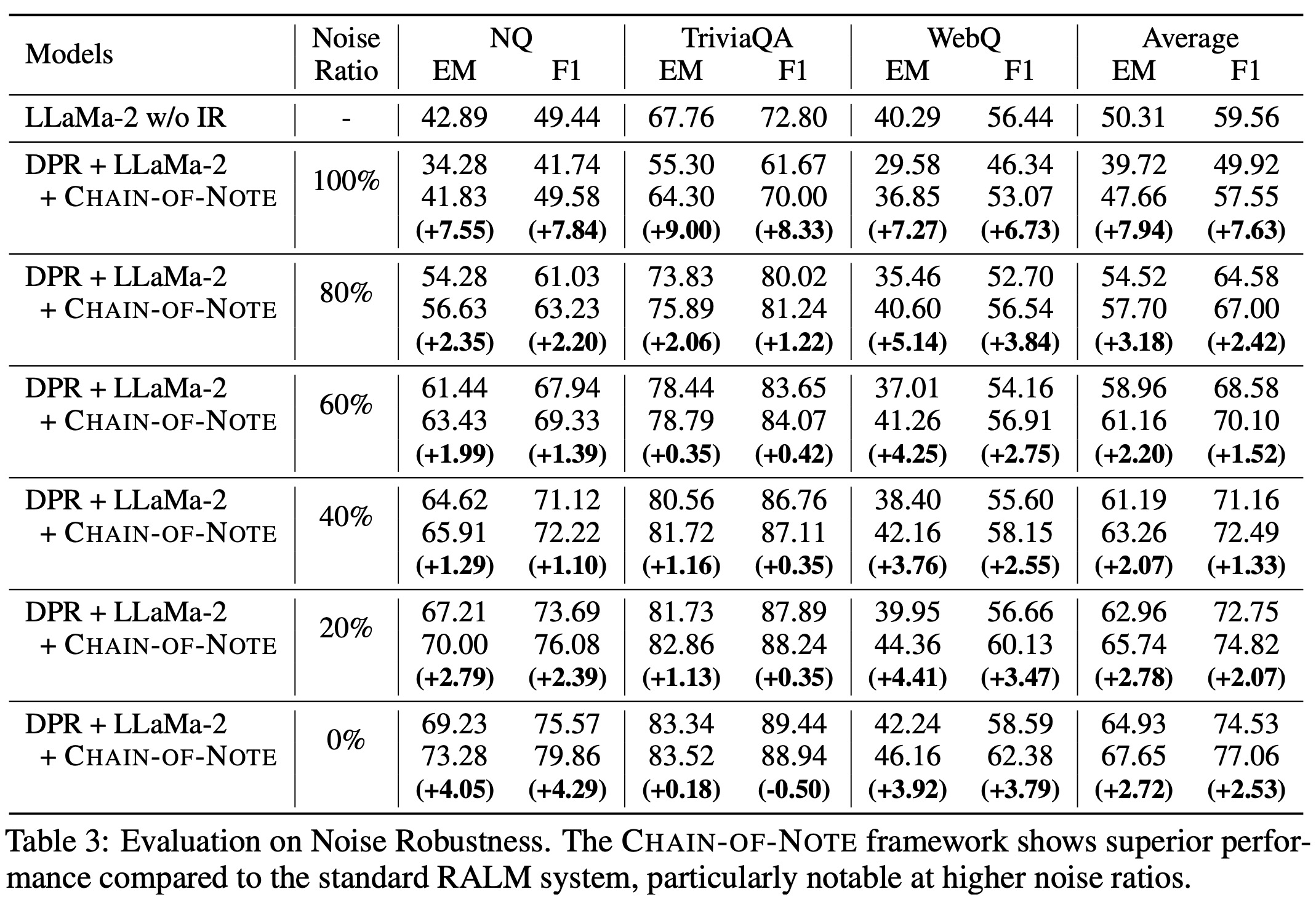
The evaluation of noise robustness in RALMs with CON was conducted under two scenarios: using top-ranked irrelevant documents retrieved from actual queries (representing semantic noise) and using completely random documents from Wikipedia (total noise). RALMs enhanced with CON consistently outperformed standard RALMs in scenarios with exclusively noisy documents, showing an average improvement of +7.9 in Exact Match scores across three open-domain QA datasets.
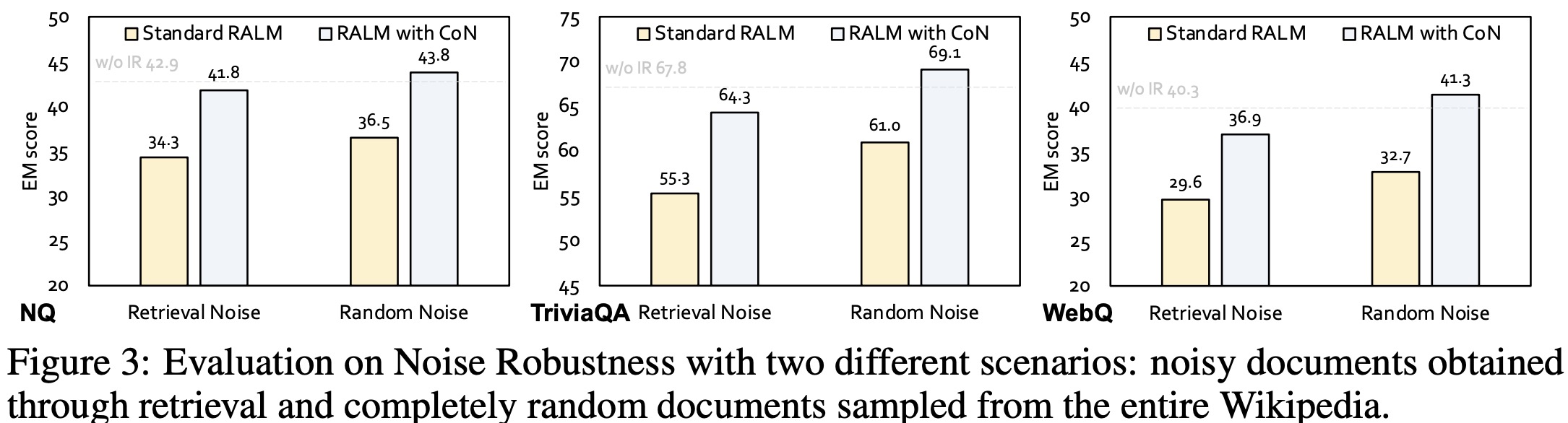
When dealing with entirely noisy documents, both standard RALMs and those enhanced with CON performed worse than the original LLaMa-2 model without information retrieval, indicating susceptibility to misleading information. However, the CON-enhanced model nearly matched the performance of LLaMa-2 without information retrieval, demonstrating its robustness and ability to disregard irrelevant data.
Additionally, the authors observed that both standard RALMs and those with CON performed better with random documents than with semantically noisy ones, suggesting that semantically relevant noise is more deceptive.

In case studies comparing standard RALMs with those enhanced by CON, distinct differences in information processing and interpretation were observed. In one case, the question was about the most recent Summer Olympics in the USA. The standard RALM incorrectly focused on a recent bid by Chicago for the 2016 Olympics, leading to an inaccurate answer. In contrast, the RALM with CON recognized that Chicago’s bid was unsuccessful, correctly concluding that the most recent Olympics in the USA were held in 1996.
In another case, concerning the language of the first Jnanpith Award recipient, the standard RALM identified the recipient but failed to link this to the language of his work. The RALM with CON, however, effectively synthesized information from multiple documents, correctly identifying Malayalam as the language. These cases highlight the superior capability of CON-enhanced RALMs in understanding and integrating information from various sources, avoiding surface-level details, and providing more nuanced and accurate conclusions.
paperreview deeplearning nlp llm rag