Beyond Positional Bias: How DroPE Unlocks Zero-Shot Long Context in LLMs
Modern LLMs struggle to generalize to sequences longer than their pretraining context, they typically require expensive long-context fine-tuning or architecture changes to extend usable context length. DroPE challenges this paradigm by removing positional embeddings after training and showing that while explicit positional biases aid convergence, they are not fundamentally needed at test time and, in fact, limit generalization to longer sequences.
The core insight is simple but counterintuitive: while positional embeddings (Rotary Positional Embeddings) accelerate early training by providing inductive structure, they become a bottleneck for generalizing to longer contexts. After a brief recalibration phase with positional embeddings dropped, pretrained LLMs exhibit zero-shot context extension far beyond their original sequence length without compromising performance on standard tasks. DroPE outperforms prior positional scaling methods and specialized architectures across different models and datasets at a fraction of the cost.
Explicit positional embeddings are beneficial for training
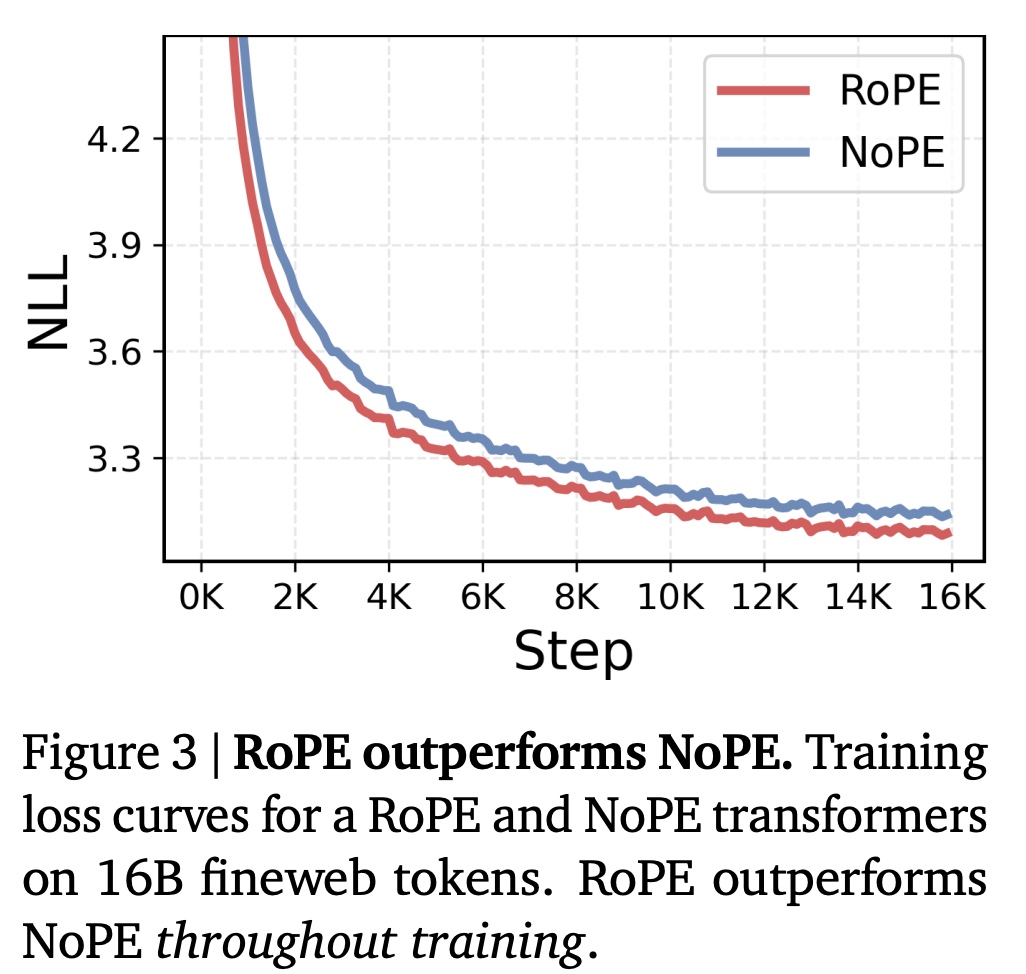
Although NoPE (No Positional Embedding) transformers are theoretically as expressive as RoPE models (they can reconstruct positional information using the causal mask), they consistently train worse in practice. Empirically, NoPE models show higher perplexity throughout training.
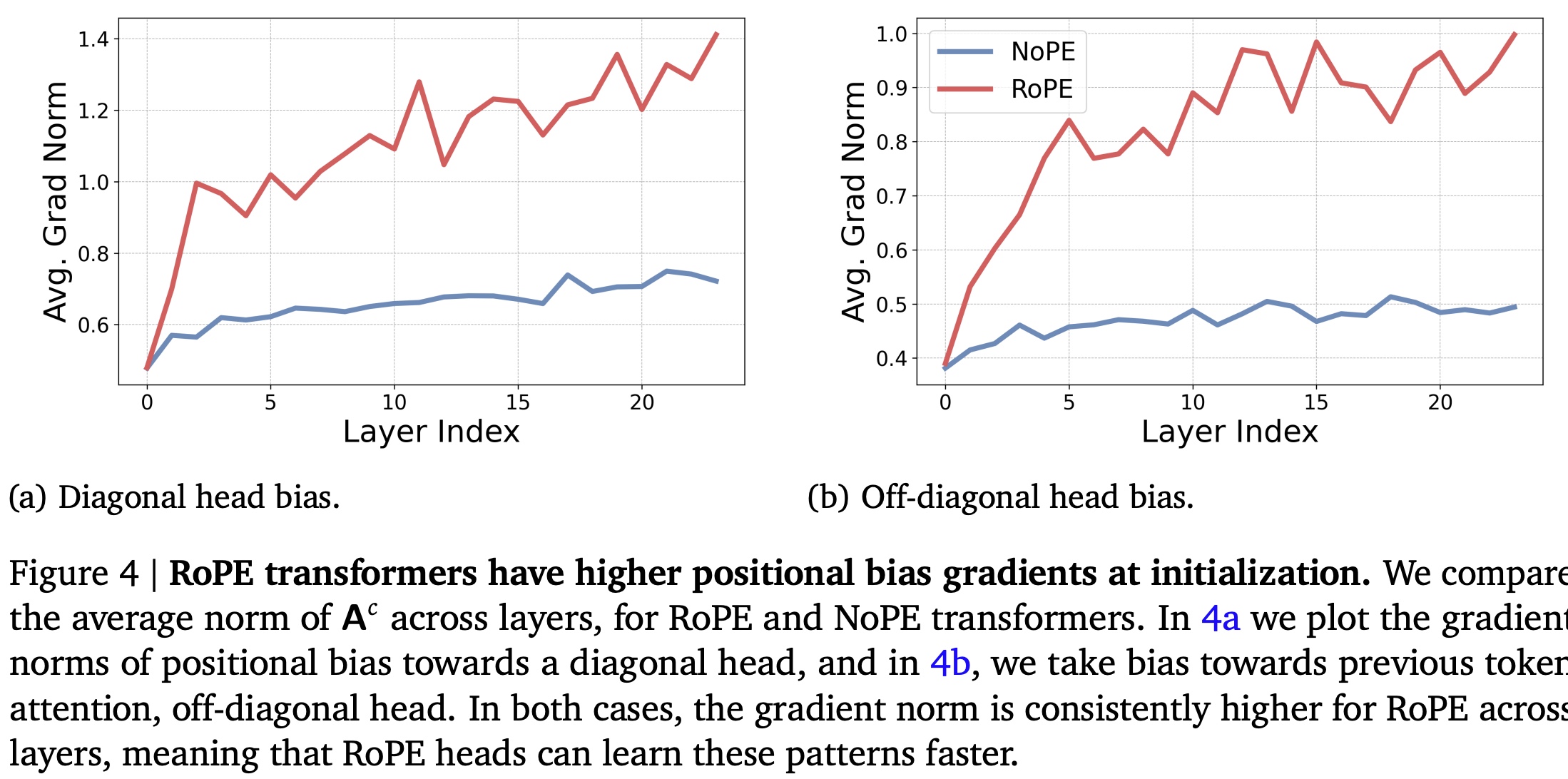
The authors argue that the difference is not about expressivity, but optimization dynamics. In NoPE transformers, positional information and attention non-uniformity (diagonal or near-diagonal attention patterns) develop only gradually because the gradients driving positional bias are bounded and small at initialization. Explicit positional embeddings like RoPE, however, inject strong positional bias from the start, enabling faster formation of useful attention patterns and more efficient training.
This means that NoPE can represent position, but learns it too slowly, while RoPE provides an inductive bias that accelerates training by immediately shaping attention toward position-sensitive structures.
RoPE prevents effective zero-shot context extension
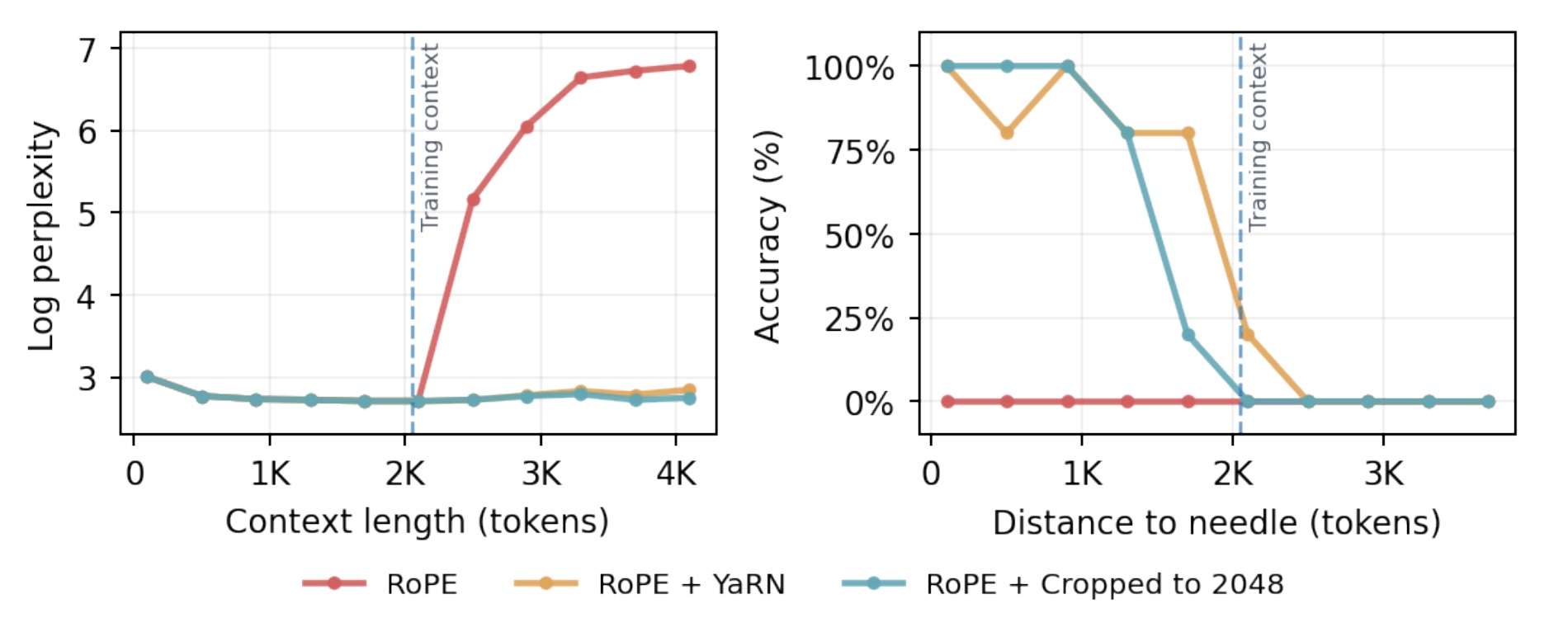
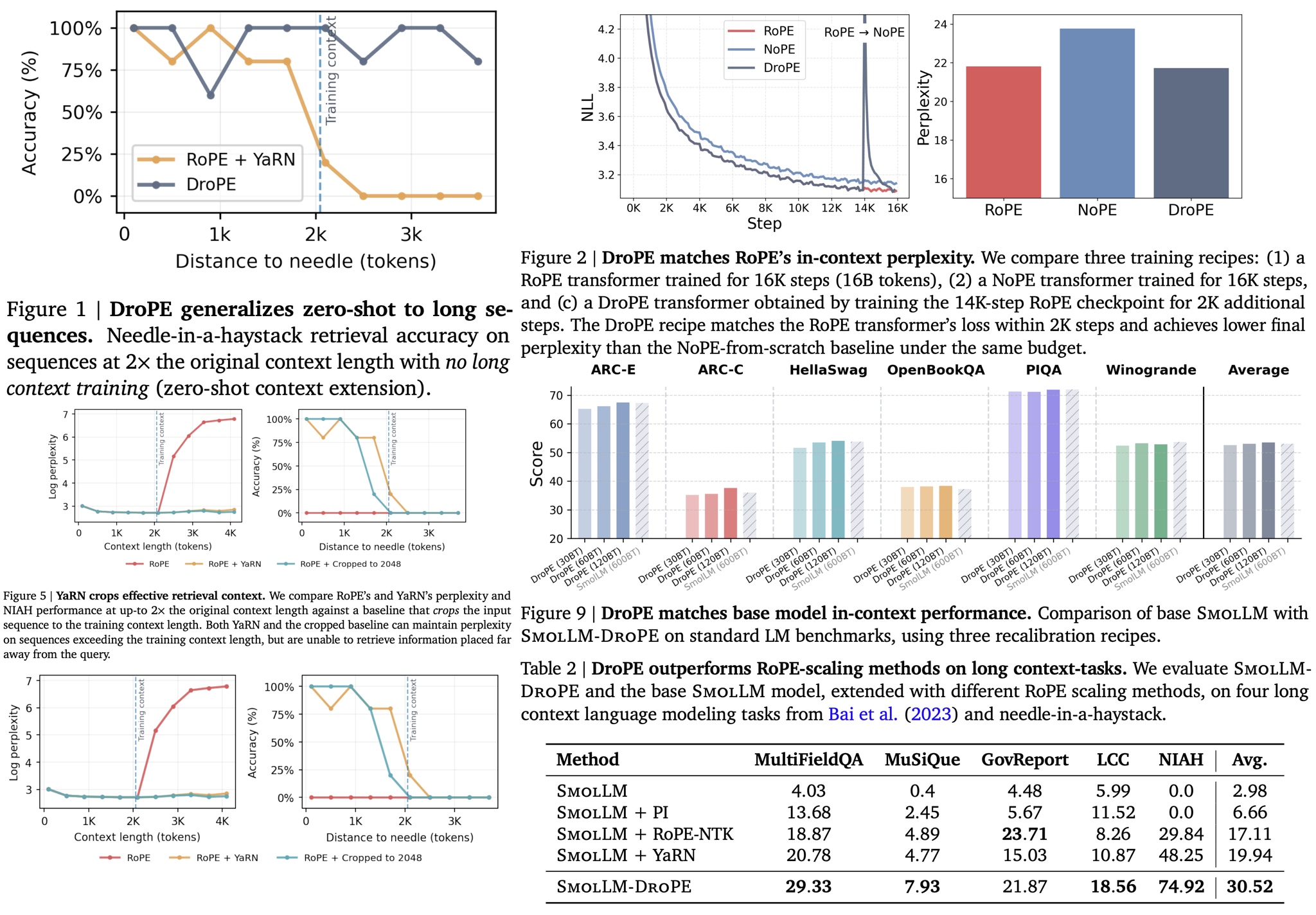
RoPE scaling methods such as YaRN can maintain stable perplexity on longer sequences, but they fail to truly generalize beyond the training context: on downstream tasks, they behave similarly to simply cropping inputs to the original context length, effectively ignoring information that appears far into the sequence. This failure is clearly visible in long-context retrieval tasks like needle-in-a-haystack, where important distant information is missed despite unchanged perplexity.
The reason is frequency compression, which is unavoidable in RoPE scaling. To keep positional phases within the training distribution, all post-hoc scaling methods must aggressively compress low frequencies. However, low frequencies are primarily used by semantic attention heads, not positional ones. As a result, scaling leaves positional (high-frequency) heads mostly intact but warps semantic attention at long distances, increasingly so as sequence length grows. This shifts attention away from the correct tokens in long-range settings, explaining why RoPE scaling cannot deliver true zero-shot context extension.
DroPE: Dropping positional embeddings after pretraining
The conclusion is that positional embeddings are crucial for efficient language model training, but they fundamentally limit long-context generalization. The key insight is that positional information is needed only during training, not at inference.
Based on this, the authors introduce DroPE, a simple procedure that removes all positional embeddings from a pretrained model and applies a short recalibration phase. After this, the model preserves its original in-context performance while gaining strong zero-shot generalization to much longer sequences, outperforming RoPE scaling methods and alternative long-context architectures.
In training-from-scratch experiments (0.5B models on 16B tokens), the authors train a RoPE model normally for 14B tokens, then remove positional embeddings and continue training for the final 2B tokens as a short recalibration phase. This DroPE model matches the original RoPE model’s in-context perplexity while clearly outperforming NoPE and other long-context architectures (ALiBi, RNoPE-SWA) on long-context retrieval tasks from the RULER benchmark. Compared to RoPE scaling methods (PI, NTK-RoPE, YaRN), DroPE consistently achieves higher success rates at 2× the training context length.
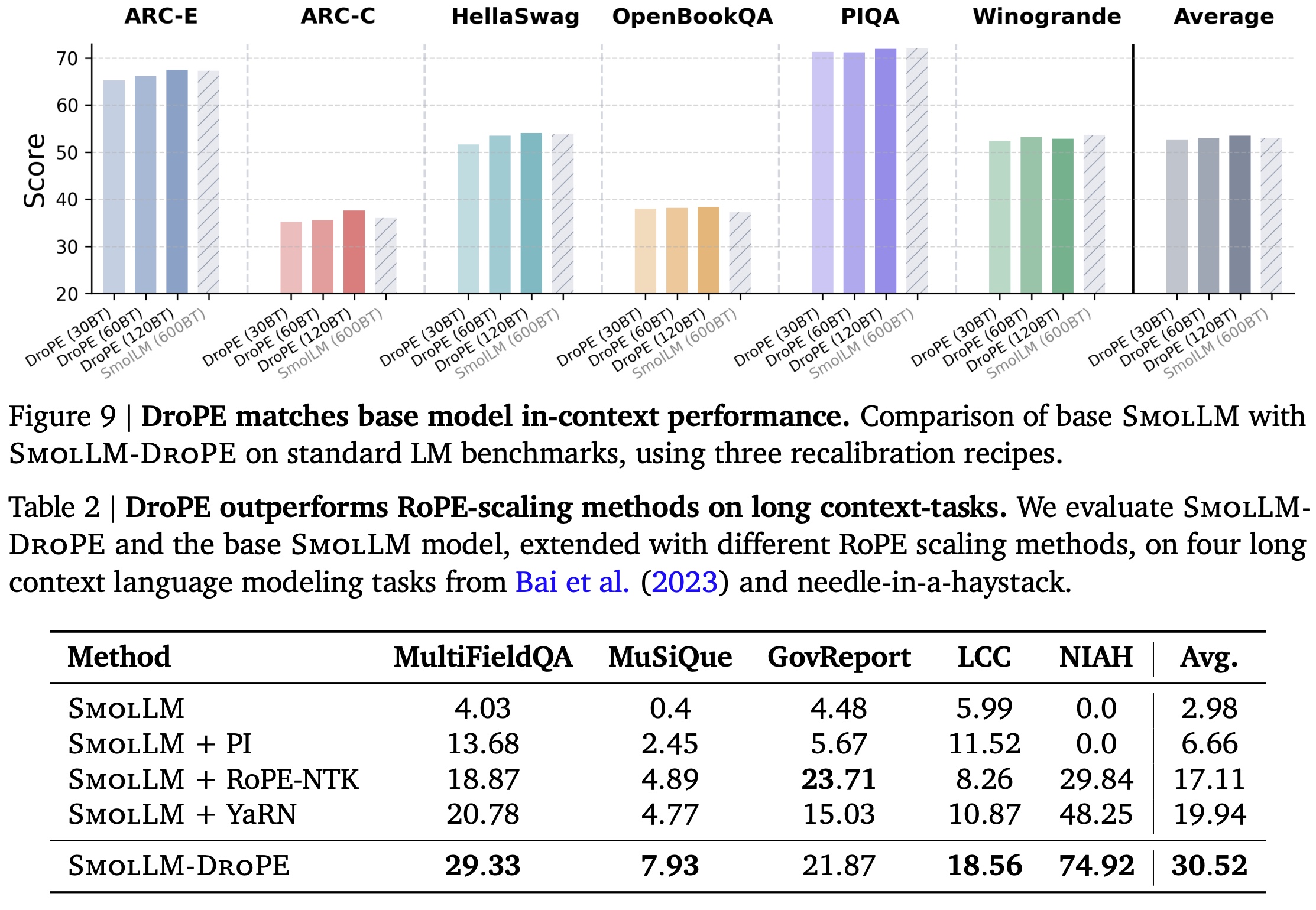
They also apply DroPE to an already-pretrained 360M SmolLM model trained on 600B tokens, demonstrating that it can extend context in “models in the wild”. With recalibration budgets of 30–120B tokens (and adding QKNorm to stabilize training), DroPE effectively adapts pretrained LMs for long-context generalization without architectural changes.
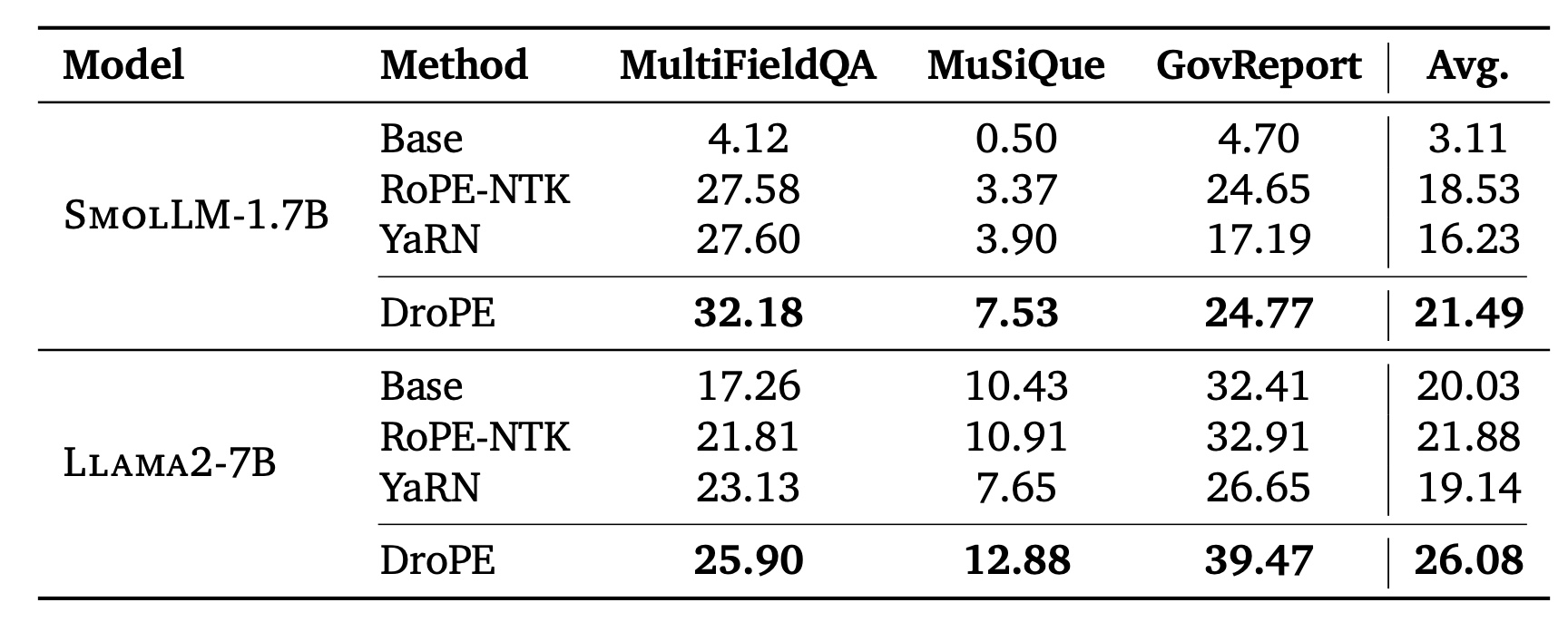
DroPE scales effectively to billion-parameter models. When applied to SmolLM-1.7B and Llama2-7B, DroPE requires only ~20B tokens of recalibration (2% and 0.5% of their original training budgets). Even with this minimal additional training, DroPE consistently outperforms state-of-the-art RoPE scaling methods on long-context question answering and summarization, demonstrating that the approach remains effective at large scale and can be applied immediately to existing models.
Conclusions
DroPE stands out among other long-context methods by decoupling the benefits of positional embeddings during training from their drawbacks at inference. Compared to scaling or adapting existing positional schemes (like RoPE scaling methods), which still rely on retained or rescaled position information and often require further fine-tuning, DroPE requires no additional long-context training while preserving original model capabilities.
I like that DroPE exhibits efficient pretrained convergence and scalable inference. More than that, it yields zero-shot extension with only a minimal recalibration phase without ever needing to train on long-sequence data. This makes it a very computationally elegant and cost-effective context extension strategy.
paperreview deeplearning llm attention transformer pretraining nlp scaling optimization efficiency fewshotlearning