Collaborative Reinforcement Learning: Why HACRL Trains Models in Teams Instead of Isolation
Modern reinforcement learning pipelines for large models are usually isolated: each model generates its own rollouts, evaluates them with a reward model, and updates its policy independently. This setup is inefficient because different models often explore different parts of the solution space, but their discoveries remain locked inside each training run.
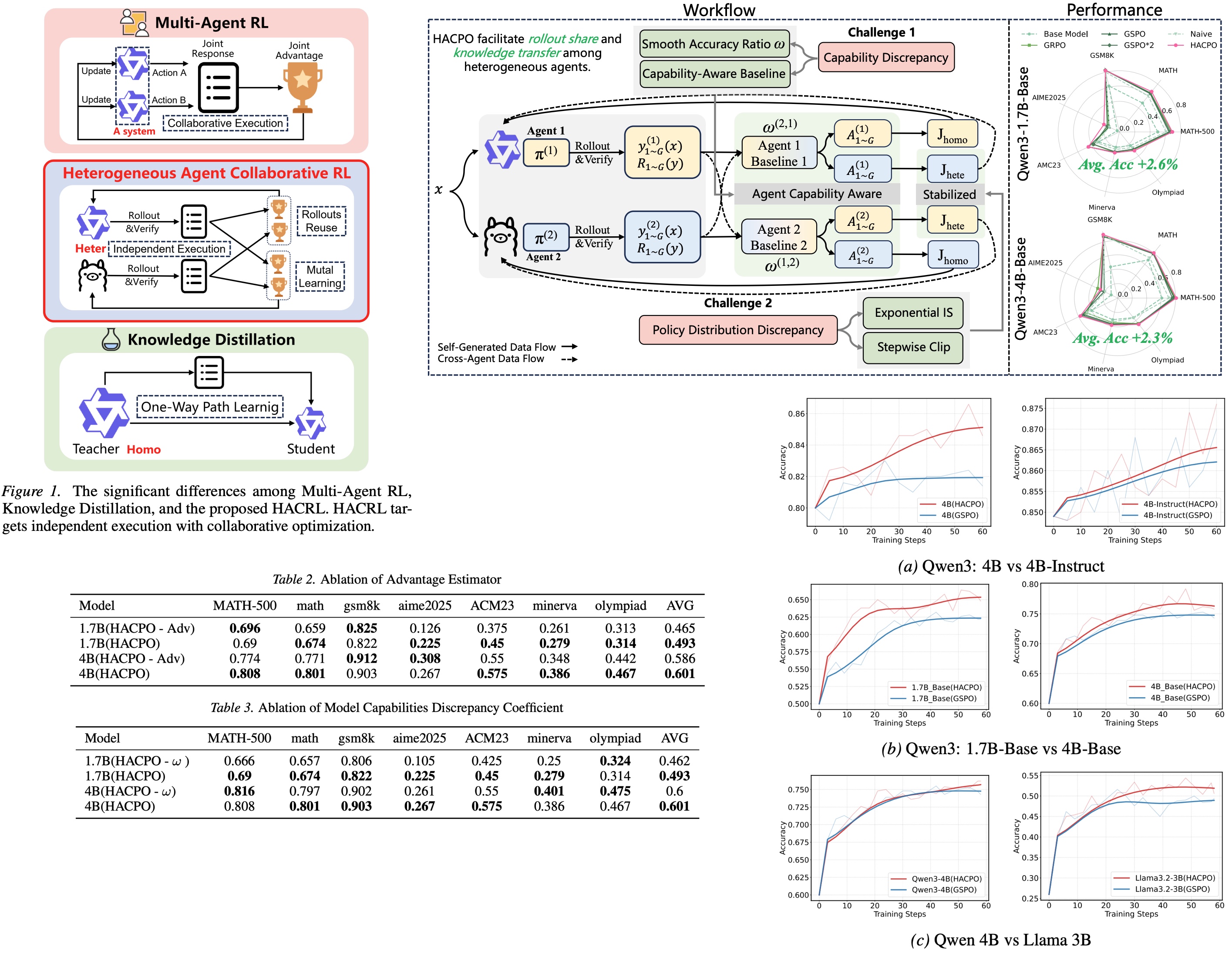
This paper explores a different idea: what if multiple heterogeneous models could learn from each other during training? HACRL (Heterogeneous Agent Collaborative Reinforcement Learning) enables multiple models to share successful trajectories while remaining independent during inference. The key algorithm, HACPO, enables this rollout sharing while correcting for policy mismatch between agents. In practice, this collaborative training improves reasoning performance and reduces rollout costs compared to standard RL approaches such as GSPO. The result is a simple yet powerful shift: instead of training models in isolation, HACRL lets them improve collectively through shared exploration.
Heterogeneous Agent Collaborative Reinforcement Learning
Most reinforcement learning pipelines train models separately; this means that even if multiple models are trained on the same task, their discoveries remain separate. One model might find a useful reasoning strategy, but other models never benefit from it.
HACRL proposes a different approach: multiple heterogeneous agents collaborate during training by sharing successful trajectories. The agents differ in architecture, size, or capability. When a model discovers a high-quality solution, the trajectory is shared with the others, allowing them to learn from that experience. The collaboration happens only during training - at inference time, each model still operates independently.
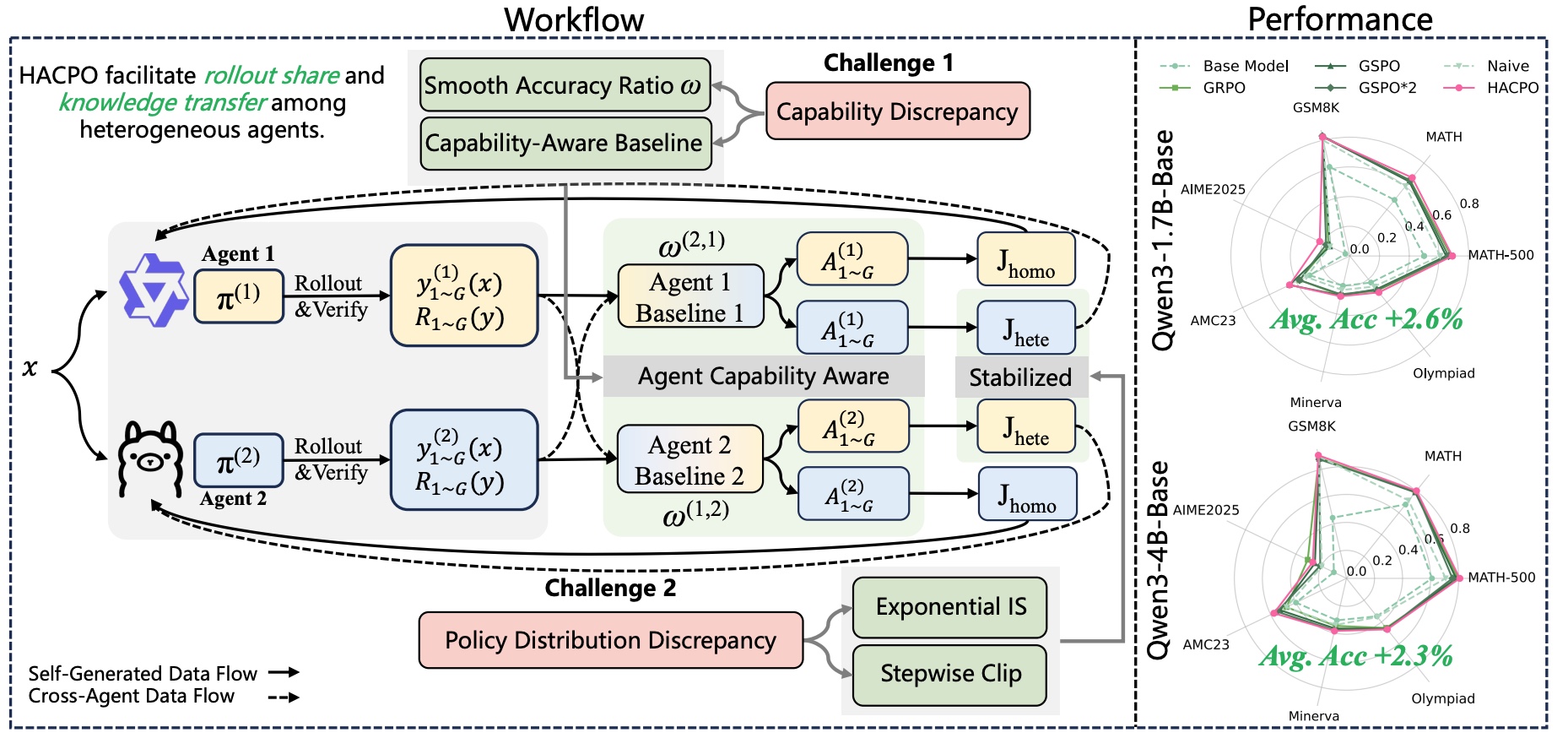
Having models of different capabilities means that using their trajectory naively by other models can introduce bias or destabilize learning. HACPO addresses this using two mechanisms:
- Exponential importance sampling adjusts the learning signal based on how compatible a shared trajectory is with the agent’s own policy: trajectories that look plausible receive stronger weight, while very unlikely ones have their influence reduced.
- Stepwise clipping further stabilizes training by limiting how large the policy ratio can become at each step of the sequence, preventing extremely unlikely tokens from producing large gradients.
The result is a collaborative training loop where agents both explore the problem space independently and learn from each other’s discoveries. Stronger models may uncover effective reasoning strategies, while weaker models contribute additional exploration diversity. Instead of repeating the same exploration across multiple training runs, HACRL turns training into a shared learning process, improving both performance and sample efficiency.
Experiments
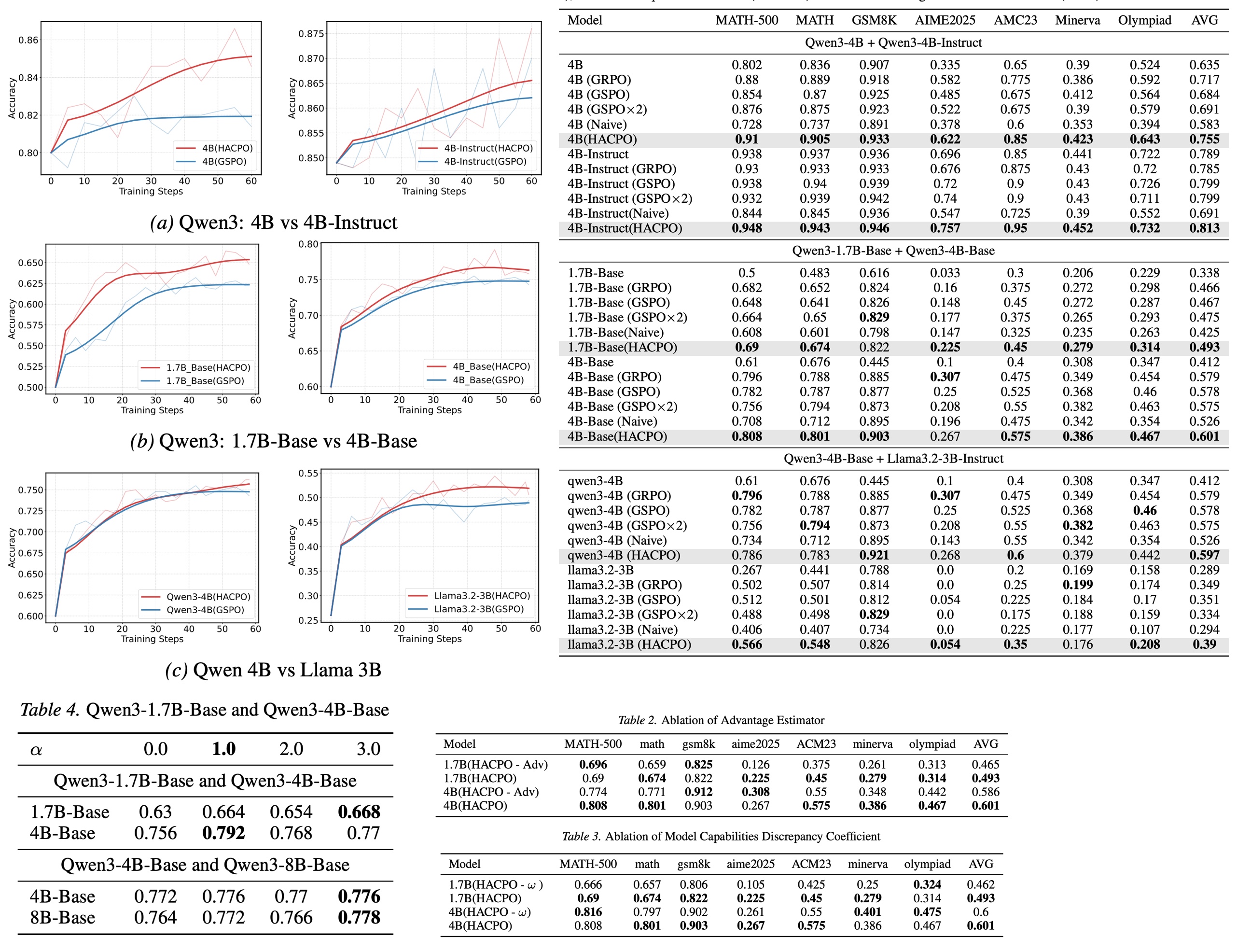
The experiments evaluate HACRL using multiple heterogeneous language models collaborating during reinforcement learning. The results show that collaborative training consistently improves reasoning performance compared to standard single-agent RL optimization.
In particular, HACRL outperforms strong baselines such as GSPO, while requiring significantly fewer rollout samples. The gains are especially noticeable when agents have complementary capabilities: stronger models help guide exploration, while weaker models contribute additional trajectory diversity. These results suggest that shared exploration across models can improve both performance and training efficiency, supporting the central idea behind collaborative reinforcement learning.
Conclusions
Traditional RL post-training methods such as PPO, GRPO, or GSPO optimize each model independently using its own rollouts. Knowledge distillation allows models to learn from others, but information typically flows in one direction—from teacher to student. Multi-agent reinforcement learning trains multiple agents together, but those systems usually require joint deployment or shared policies.
HACRL proposes a different design: collaboration during training, independence during inference. Models exchange useful experience without becoming dependent on each other. This makes the approach particularly attractive in modern AI ecosystems where many models coexist. Instead of competing for training data, models can collectively explore the solution space and accelerate learning.
paperreview deeplearning rl llm optimization agent finetuning