FIPO: Teaching LLMs Which Thoughts Actually Matter
Most reasoning models today rely on outcome-based RL: generate a solution, check if the answer is correct, and reinforce the whole trajectory. As reasoning becomes longer, the learning signal collapses - important steps and irrelevant tokens receive the same credit, and performance plateaus.
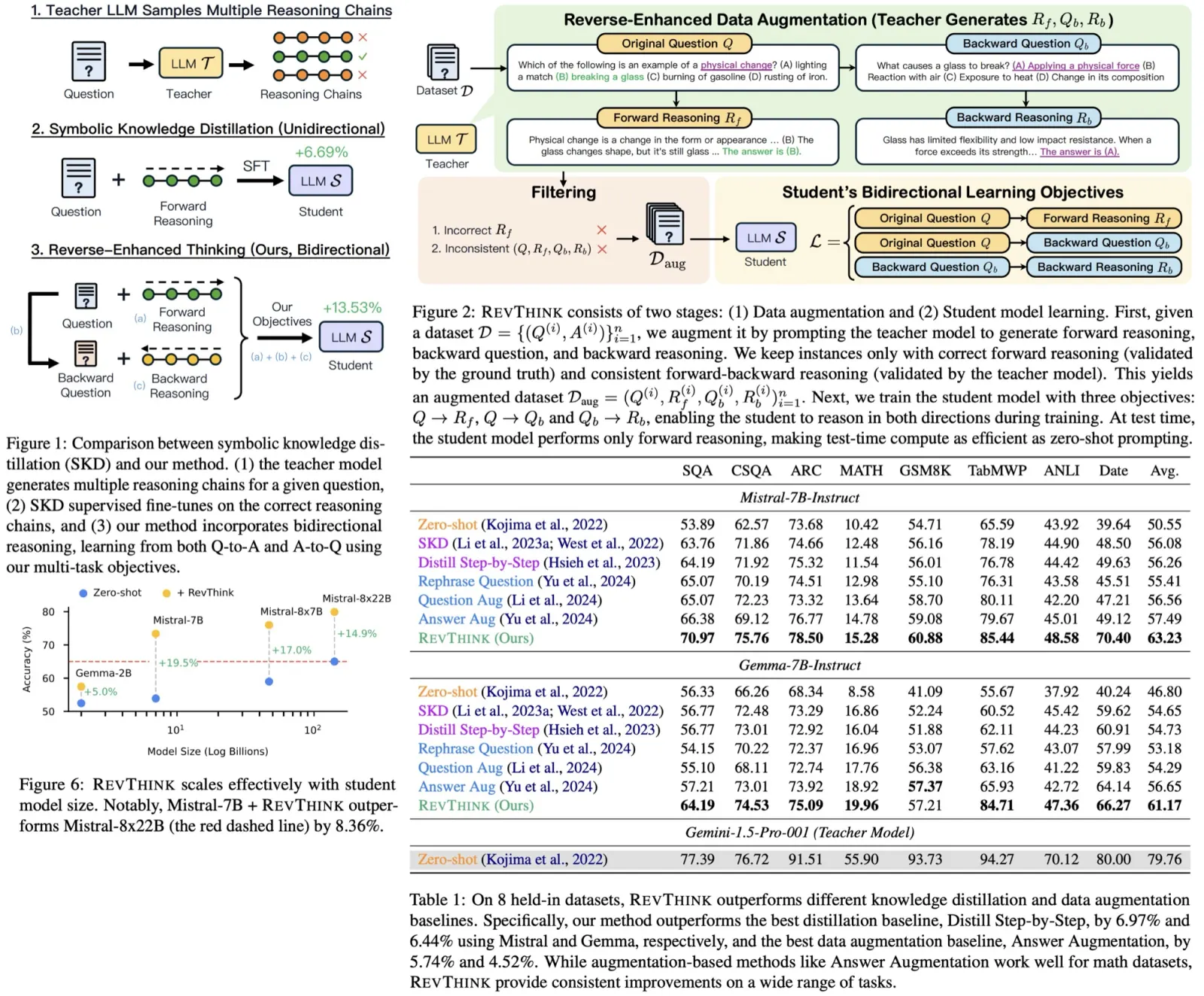
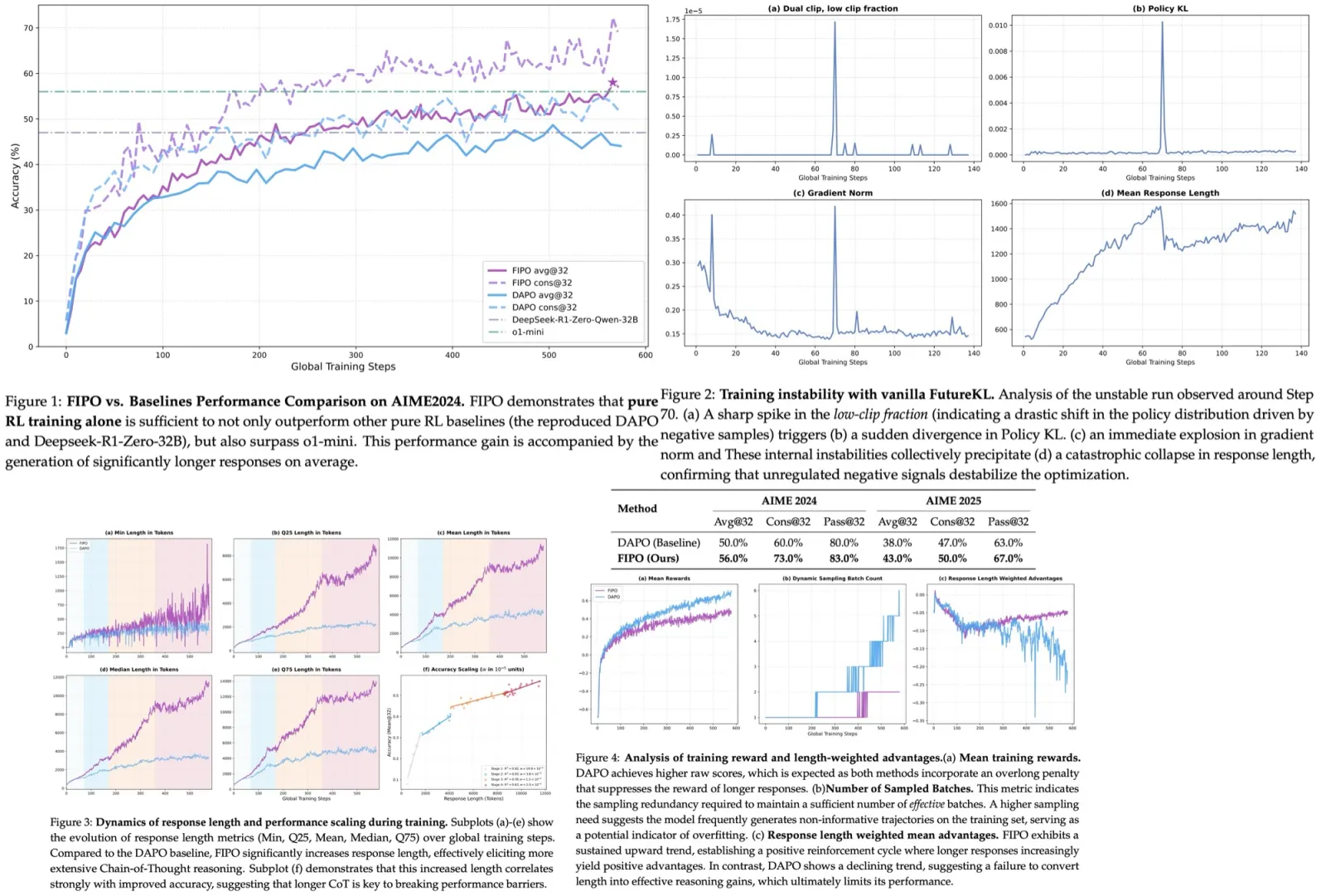
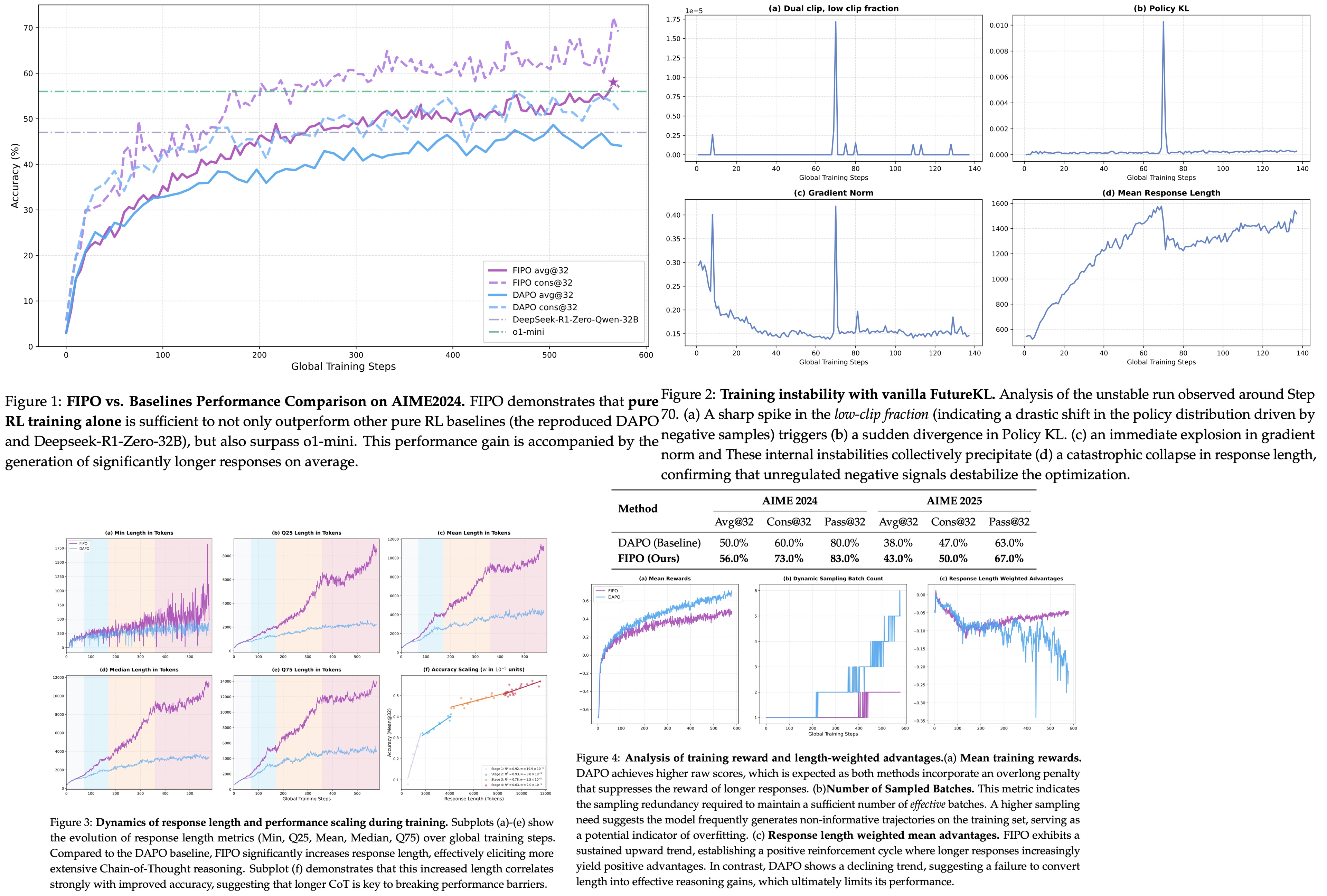
FIPO addresses this directly by introducing token-level credit assignment based on future impact. This turns a sparse, outcome-only signal into a dense, structured one. The authors train Qwen2.5-32B-Base on top of the DAPO recipe inside VeRL and evaluate on AIME 2024. They report Pass@1 going from 50.0% (DAPO) to a peak of 58.0%, converging around 56.0%. Response lengths roughly double during training, from around 4k tokens to more than 10k.
FIPO
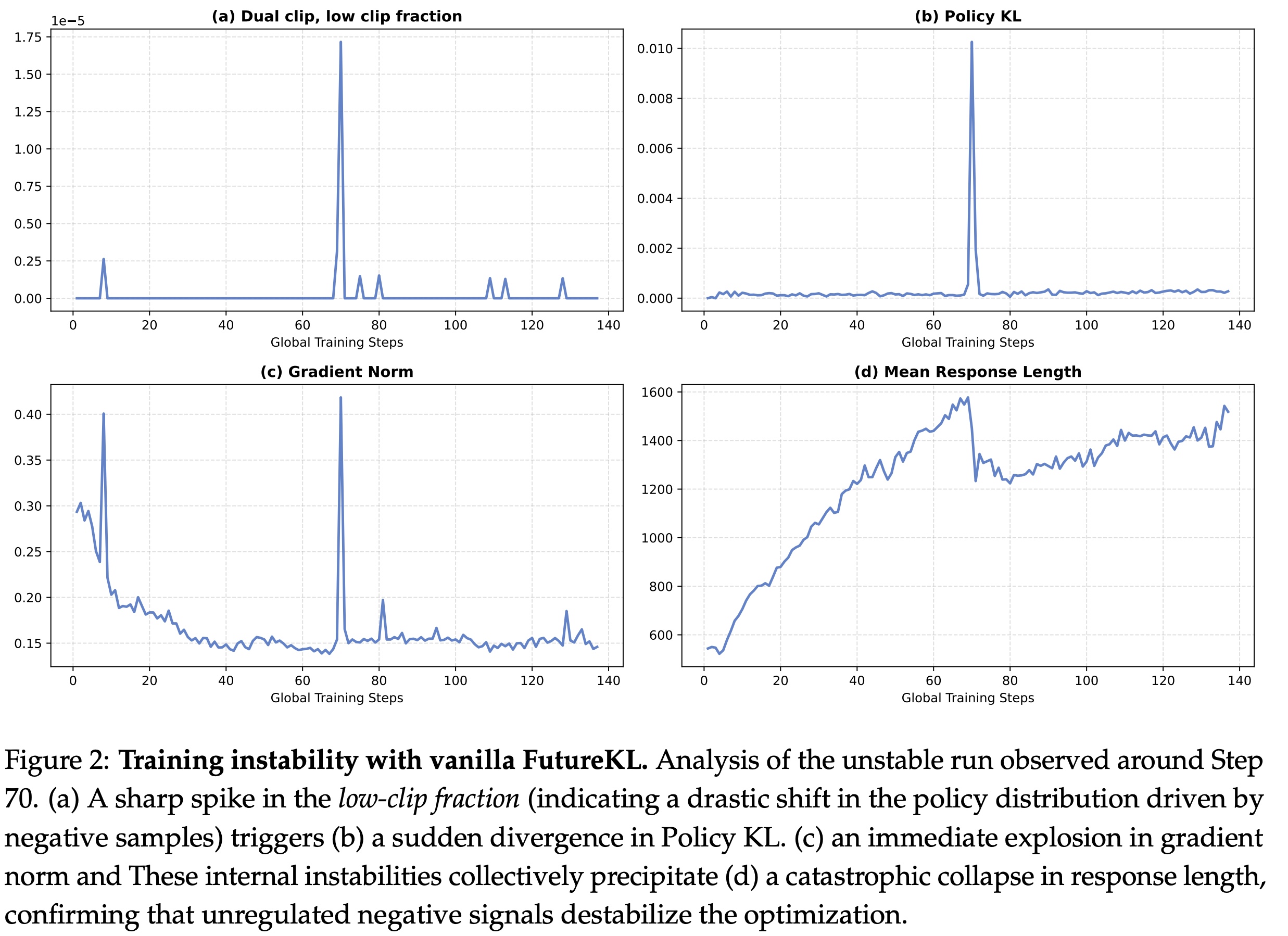
FIPO measures, for each token, how much the policy’s behaviour on the rest of the rollout has shifted since the last update. For each position in a response, the authors compute the log-ratio between the current and old policy at every subsequent position, then sum these shifts with a discount factor that decays with distance. This is the Future-KL: a per-token statistic that measures how much the policy’s behaviour on the tail of the rollout has moved since the last update. Closer future tokens matter more than far ones. The discount works as a soft half-life rather than a hard cutoff.
Future-KL can be unstable due to distributional shifts, so it needs some mechanisms to avoid destabilizing the training process. First, a dual-clip mask zeroes out tokens whose importance ratio exceeds a threshold around 10, so that extreme values don’t hurt the gradients. Second, the future-KL value is mapped through an exponential clip into a bounded influence weight. Tokens whose future trajectory shifted a lot after the update receive larger effective advantages; tokens that did not move the future of the rollout receive less weight.
Experiments
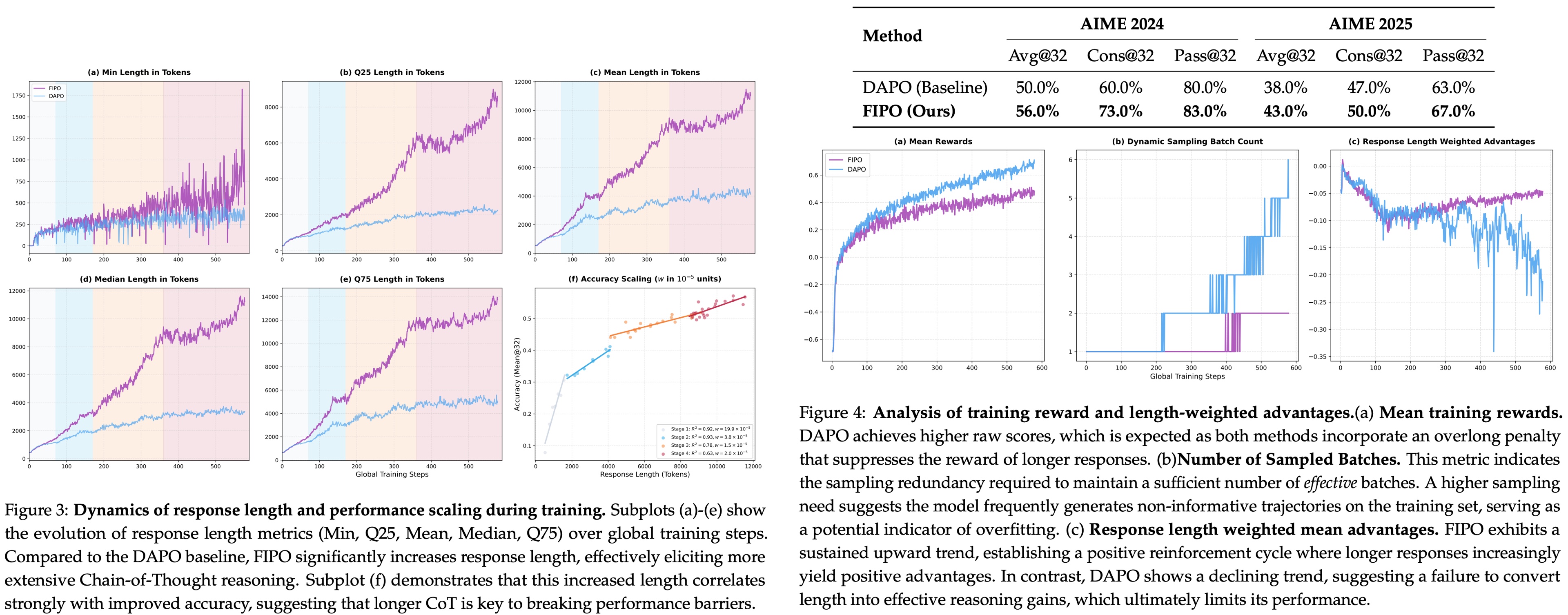
- FIPO: 58.0% peak, around 56.0% at convergence.
- DAPO baseline on Qwen2.5-32B-Base: 50.0% Pass@1. Reproduced DeepSeek-R1-Zero-32B: ~47%.
Both DAPO and FIPO show length growth, but the FIPO curves are longer at the same step count. That is consistent with denser credit letting the model commit to longer reasoning - useful tokens in the middle of a rollout can now be rewarded directly.
The main drivers of FIPO’s effectiveness are: the emergence of length-based scaling in reasoning chains, the positive learning signal, and the significantly improved stability of the optimization process.
Limitations
- Compute overhead from per-step future-KL accumulation and 10k-plus rollouts;
- Narrow task scope (math reasoning only);
- Fixed dataset (DAPO’s open math corpus, not scaled up);
- A base-model confound that makes it hard to isolate the contribution of the RL recipe from the underlying pretraining and SFT.
Conclusions
FIPO targets a different problem compared to methods like GRPO, DAPO, and recent reasoning systems (DeepSeek-R1, o-series). Most existing approaches improve reasoning by scaling models, improving sampling or refining reward signals. FIPO instead changes how the reward is distributed within a trajectory.
This makes it fundamentally different:
- Compared to GRPO/DAPO, it removes uniform credit assignment
- Compared to PPO-style RLHF, it avoids critics while still providing dense signals
- Compared to top reasoning models, it suggests gains can come from training signal design, not just scale
I am less sure how well the gains hold up outside AIME or under a compute-matched comparison. The short-horizon future-KL proxy probably rewards some variance that is not reasoning-relevant. For now, it looks like a promising direction for reasoning-specific training rather than a drop-in upgrade.
paperreview deeplearning llm rl reasoning optimization