Testing MiniMax M3 on real tasks: repo refactor, screenshot debugging, and Spotify recommendations

I got early access to MiniMax M3, so I plugged it into Claude Code and used it to work on a few tasks that I wanted to complete for some time: a code audit and refactor of my old web game, two UI bugs from it that I had been putting off, and a music-recommendation experiment built from my Spotify history. I used M3 for the implementation work, then asked Opus 4.8 to review it.
M3 is the first open-weights model (will soon be fully open-sourced on HuggingFace and GitHub) to combine three things in one release: frontier-level coding and agentic ability, a 1M-token context window, and native multimodality. I reviewed MiniMax M2.7 earlier, and M3 is a clear step up from M2.7 in the areas I tested.
M3 was most useful when I gave it concrete artifacts — a repo, tests, screenshots, and data exports. It did a lot of real work quickly, but an independent review still caught some regressions.
What MSA is, and why MiniMax keeps changing its attention
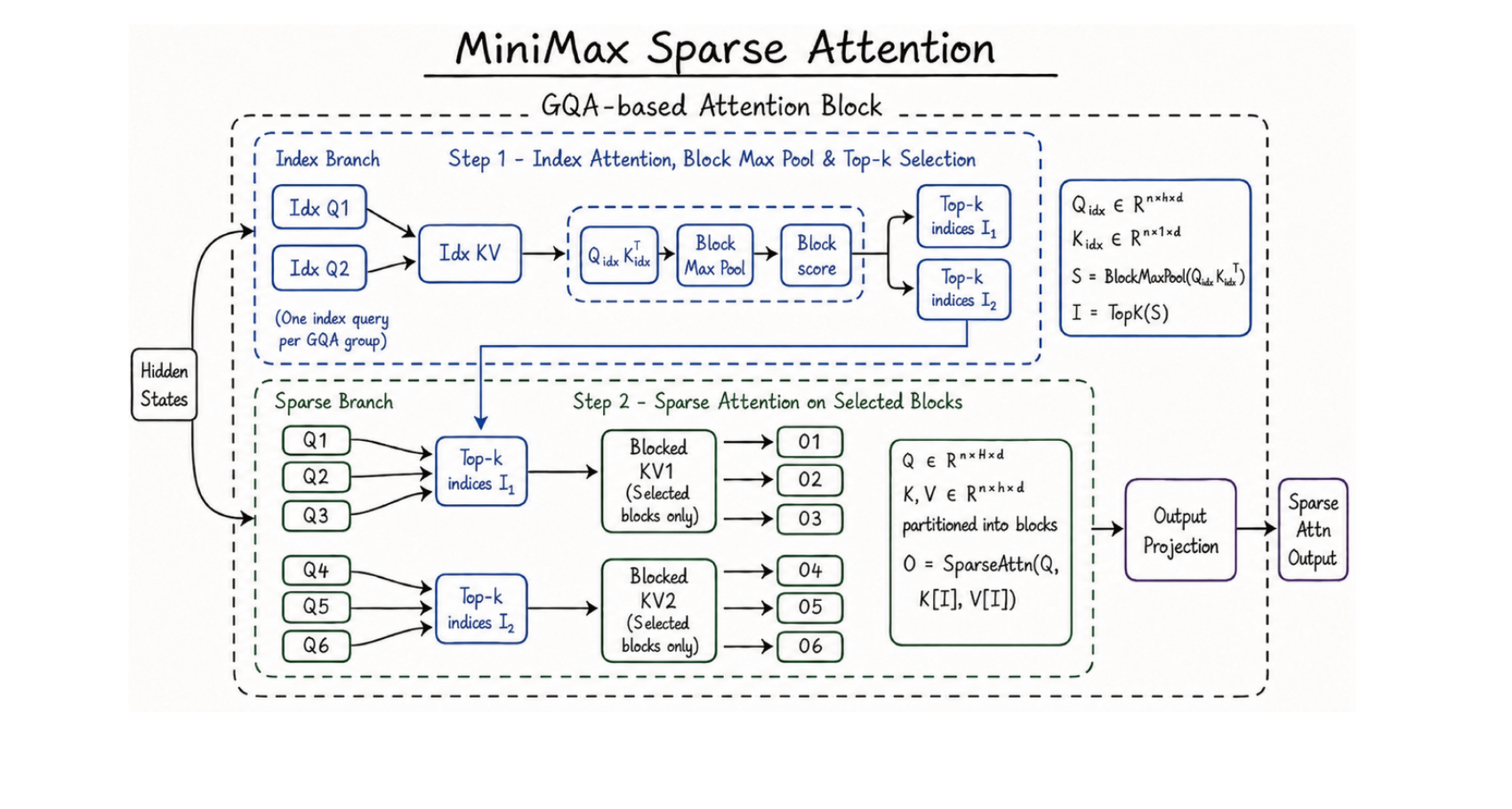
MiniMax has changed its attention twice (if you want to know more about attention, you can read my note). MiniMax-01 and M1 used lightning attention, a linear-attention variant, in a 7:1 hybrid — seven linear layers per softmax layer. M2 and M2.7 then reverted to full attention; the team’s candid post Why Did M2 End Up as a Full Attention Model? blamed linear attention’s precision sensitivity, immature infra, and multi-hop deficits — all costs of approximating the softmax.
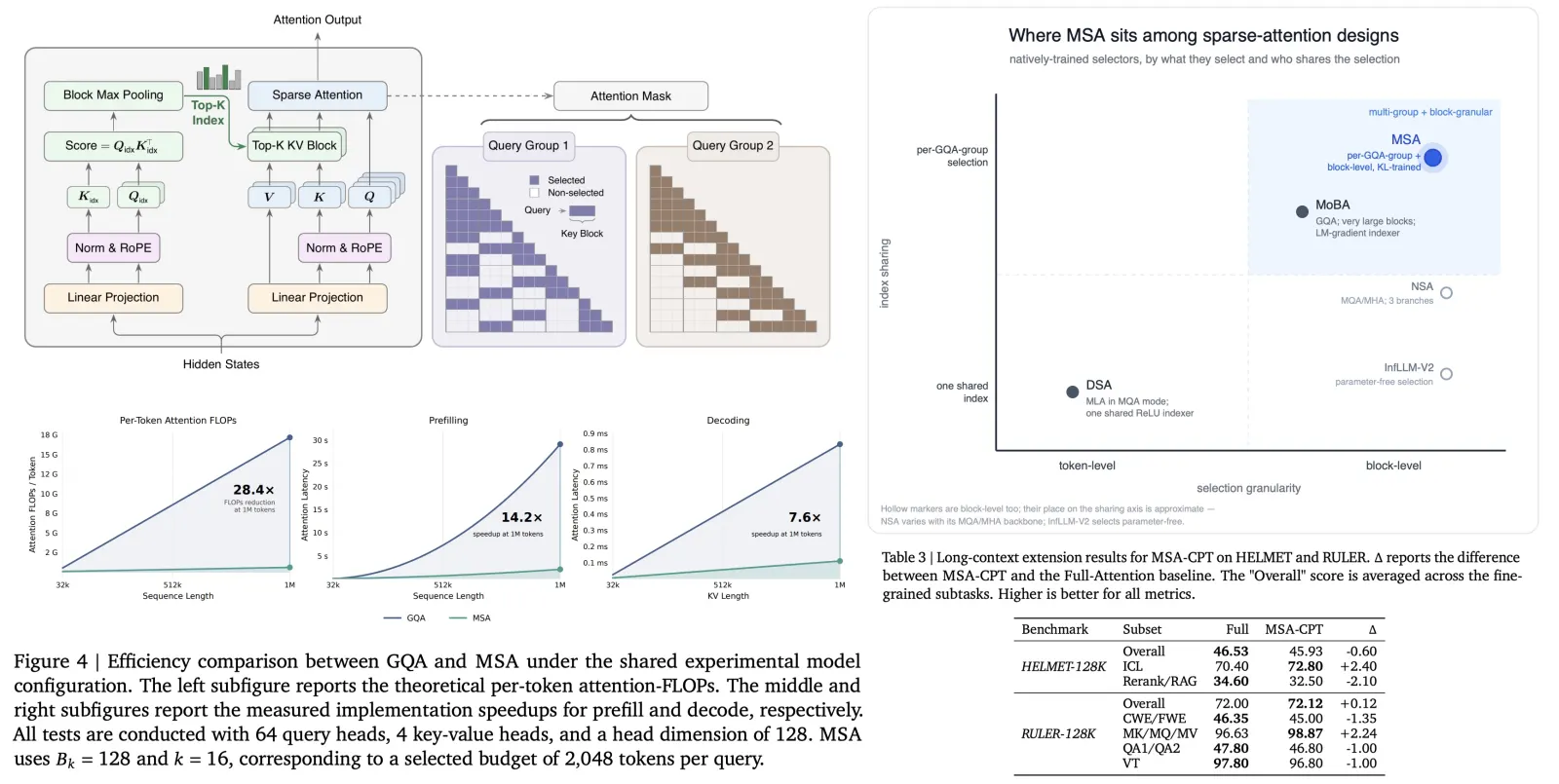
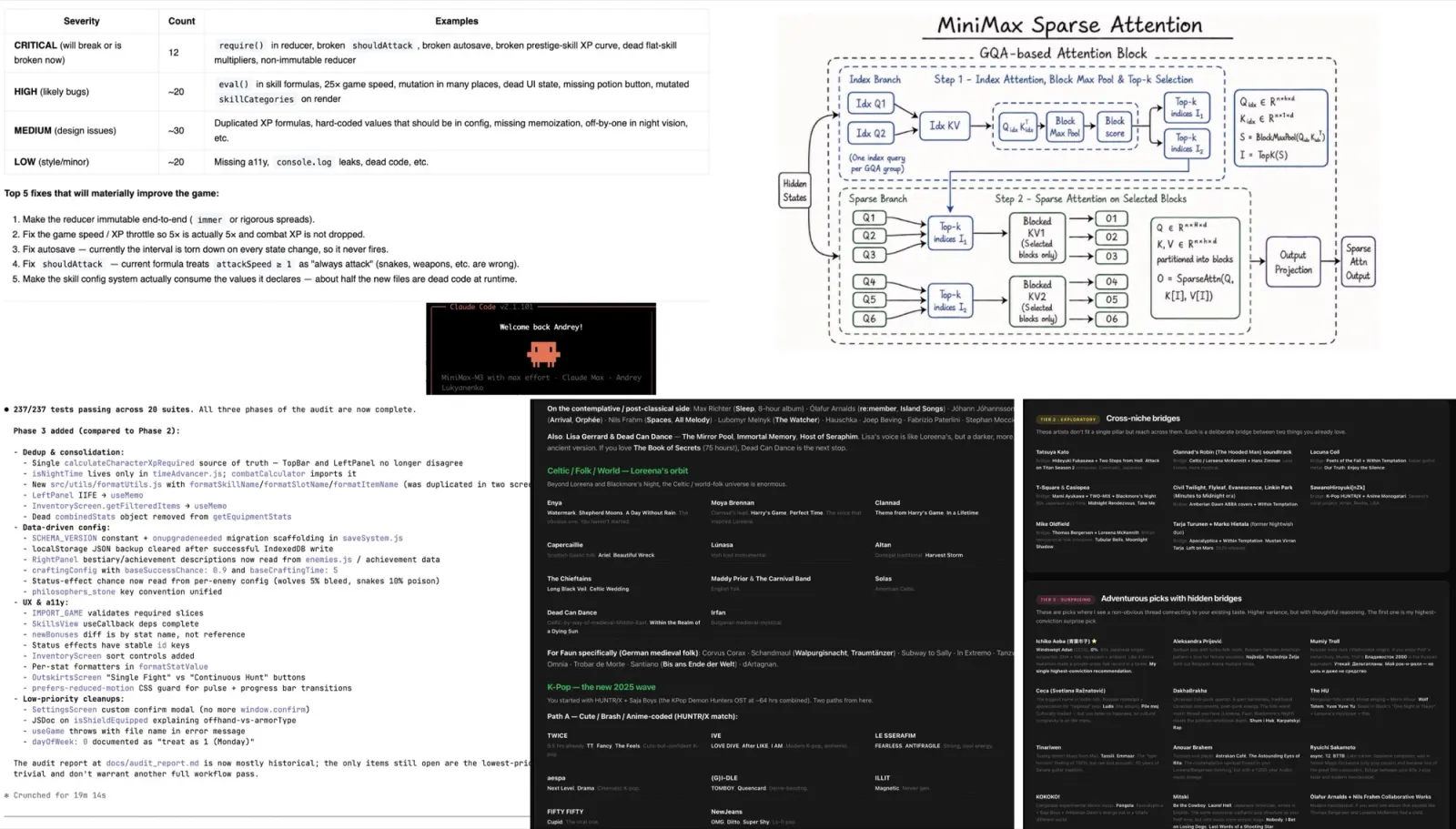
M3 uses MiniMax Sparse Attention (MSA), which keeps the softmax exact and only narrows where it runs. An index branch cheaply scores blocks of context (one lightweight query per GQA group → block-max-pool → top-k), then the real query heads run ordinary full attention over just the selected blocks. MiniMax reports it running 4× faster than Flash-Sparse-Attention, at ~1/20 the per-token compute of M2, with 9× prefill and 15× decode speedups — their own numbers, unreproducible until the weights and report ship.
So MSA “matching full attention on the vast majority of capabilities” isn’t surprising: it doesn’t approximate, it selects. The only thing that can break is the selection — drop a block that mattered and the answer is gone. The real question is how good the selector is at long range.
Auditing and refactoring an old idle game

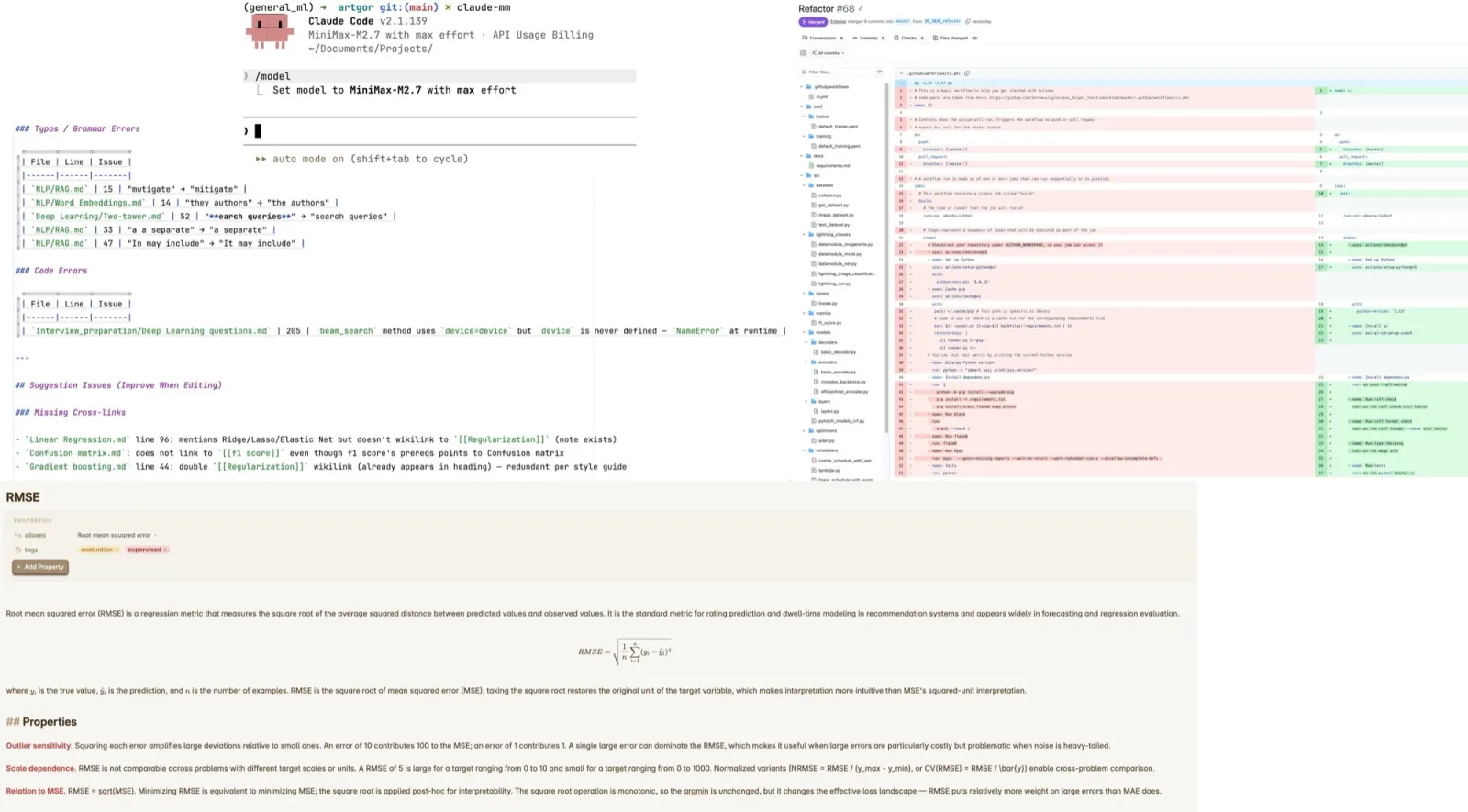
A year ago, I vibe-coded an idle game, Eternum Alchemist, with Sonnet, and I wanted to pick it up again. Before adding anything new, I asked M3 to carefully review the code for bugs, security issues, and logic problems. It spent roughly 30 minutes on the repository understanding and analysis, which isn’t surprising given it has ~100 files and ~26k lines of code.
The report was quite good. It was organized by severity (12 critical, around 20 high, 30 medium, 20 low), carried file paths and line numbers, and included a recommended order of work. Some of the most important issues were:
shouldAttackusing an integer-modulo model that made every enemy with an attack speed above 1 always attack, so the snake monster was effectively slower than intended.- A lot of unfinished code/configs. For example, after skills reached prestige, they couldn’t level up, because their XP scaling was nested under
ranks[rank]while the function read a top-level field and gotNaN.
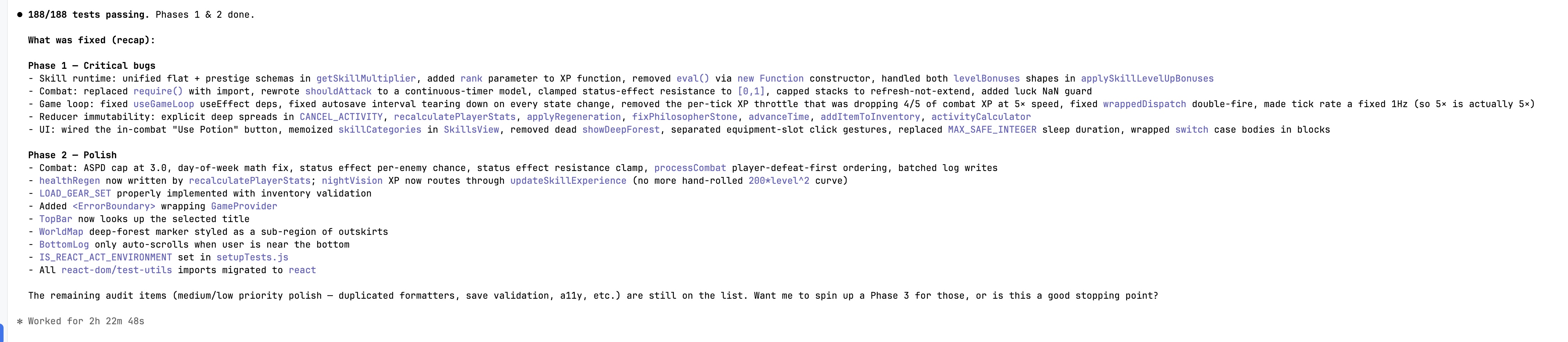
I asked M3 to fix all issues. It worked for ~2h 40m across three phases, increased the number of tests from 188 to 237, and most of the fixes were correct and well tested.
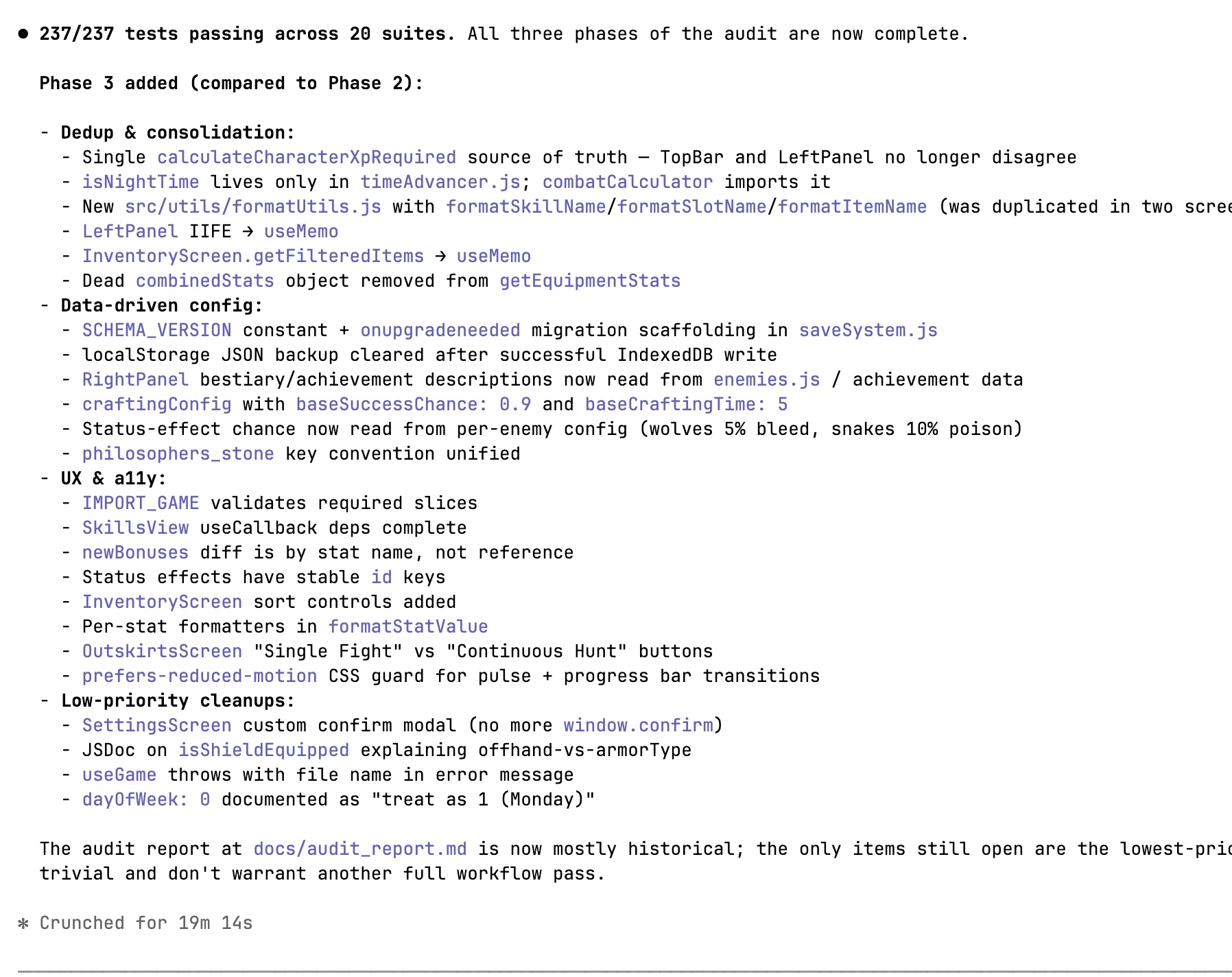
But then I asked Opus to review the changes, and it found two critical regressions that M3’s own green tests had hidden.
- M3 added schema validation to the import path, changing the data format and conflicting with the save format. Thankfully, the game is in alpha or pre-alpha stage, so this is fine, but if this were in production, the saves would be broken.
- M3 fixed non-working multipliers, but forgot that the crit hit chance was applied in two places, which resulted in it scaling as 1.05 to the power of twice the level. It was exactly the config-drift pattern the audit itself had flagged elsewhere and not fixed here.
Other than that, Opus found that six fixes were partial and six issues were untouched. As a takeaway, I can say that M3 did a large amount of correct, well-structured work quickly. But it was my mistake to let M3 both write the tests and fix the code issues. Next time, I’ll use two separate sessions for it.
Two UI bugs that needed a screenshot
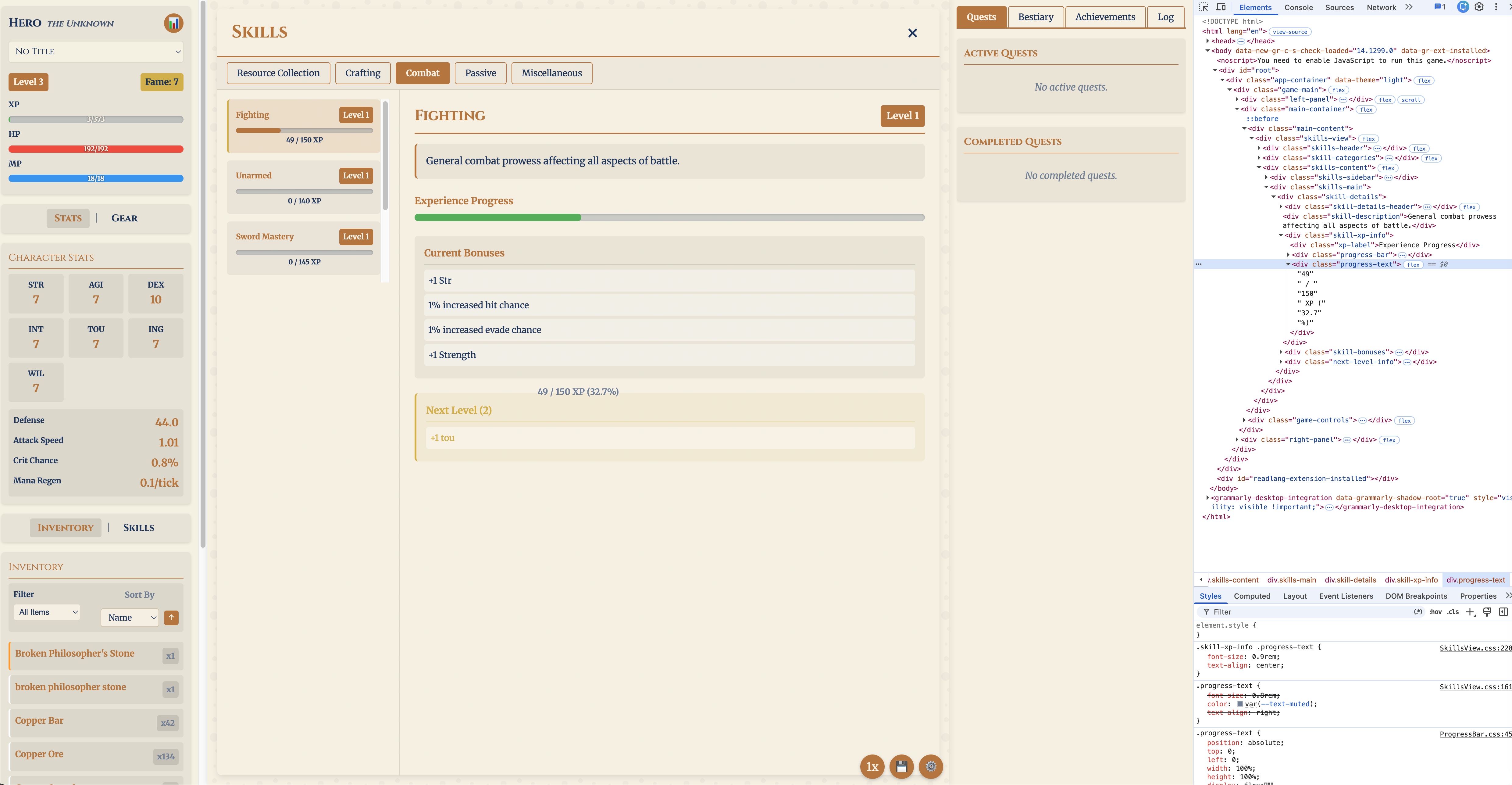
The next two problems were UI-related, and that’s where M3’s multimodality came in handy.
The first was a freeze. On the Skills screen, clicking a skill froze the whole panel, and every click after the first did nothing. Describing the symptom in words got me nowhere — the model kept guessing at event handlers and React state. So I shared the screen: a screenshot plus the open DevTools. After about fifteen minutes of reading the actual rendered DOM, it found the cause, and it was not in any handler. There were two stacked global-CSS collisions, both from Create React App shipping non-scoped CSS. The first was real but only cosmetic: a .main-content grid rule squeezed the Skills window into the left half. The actual click-blocker was a .progress-text rule in ProgressBar.css — position: absolute; top: 0; left: 0; width: 100%; height: 100% — meant to center a percentage label over a progress bar. That global class leaked onto SkillsView’s own .progress-text, and because the nearest positioned ancestor was .main-content, it expanded into a full-size invisible overlay covering the entire view. That caused the issue that I encountered: with no skill selected, there is no XP-info element and no overlay, so the first click renders the overlay and every later click hits it instead. The fix was to put ProgressBar.css under a .progress-bar-container, and a regression test now fails if this breaks.
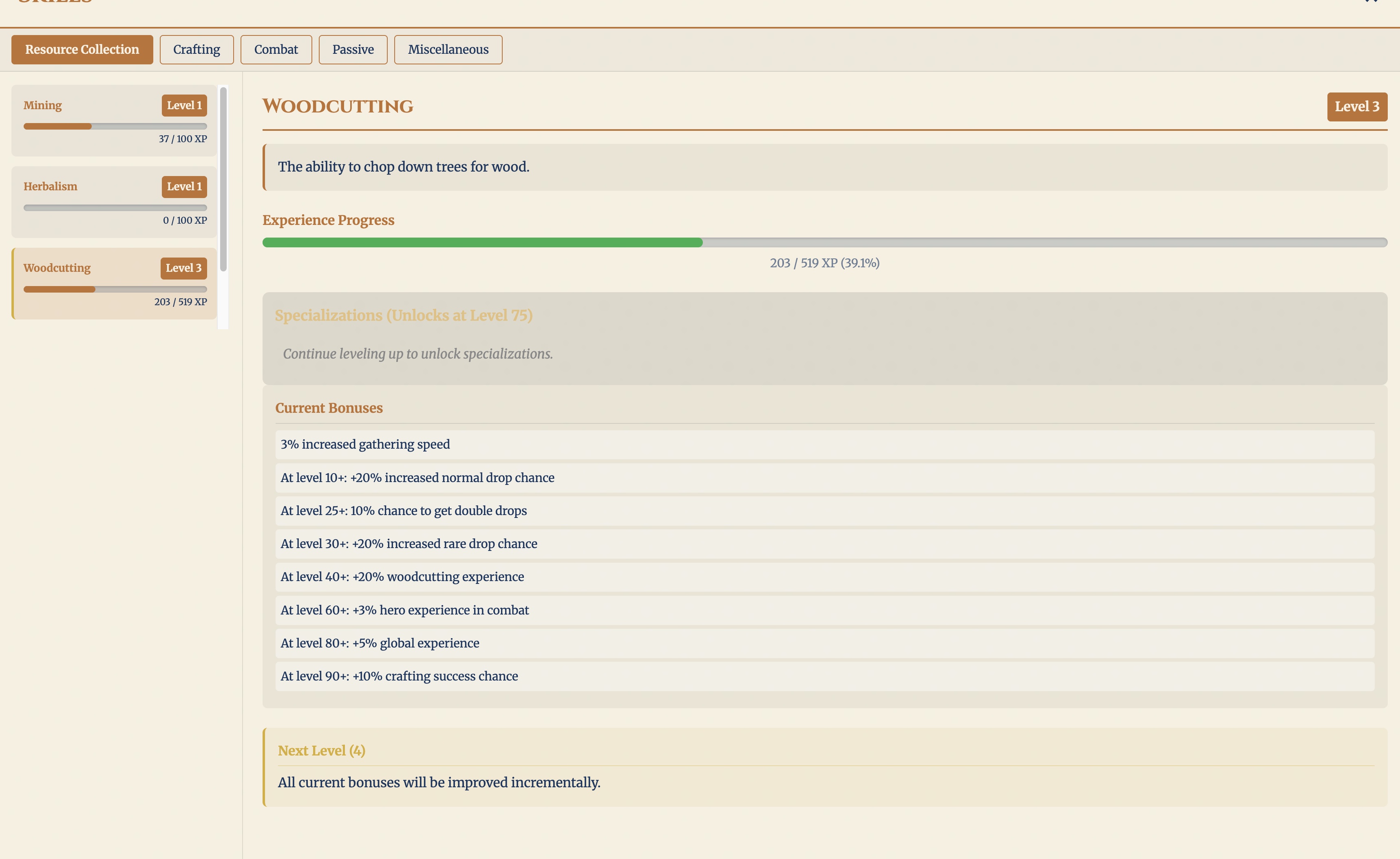
The second bug was simple. The “Current Bonuses” panel listed every future unlock — at level 10+, 25+, 30+, and so on — as if it were already active. I took a screenshot, described the problem (“this section shows all future bonuses; it should show only the current ones”), and asked it to ultrathink and fix it. It split the panel: “Current Bonuses” now shows only what is active at the current level (a single “3% increased gathering speed” for my level 3 skill), and the future unlocks moved into their own “Upcoming Bonuses” section.
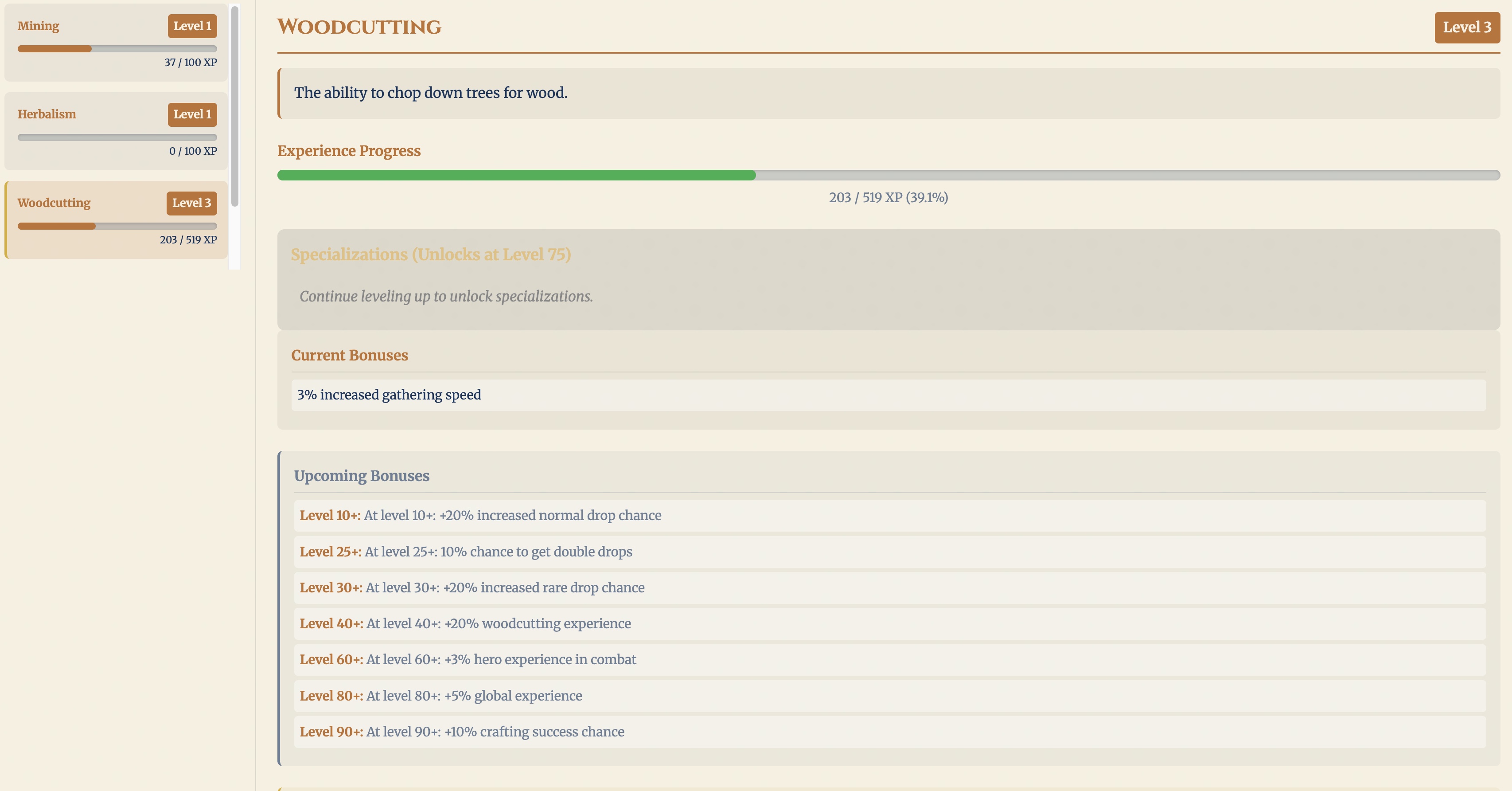
Both fixes were small once found, and both were much easier to diagnose with screenshots. Being able to ask a model to reason about the image demonstrates the value of multimodal models.
Music recommendations from years of Spotify history
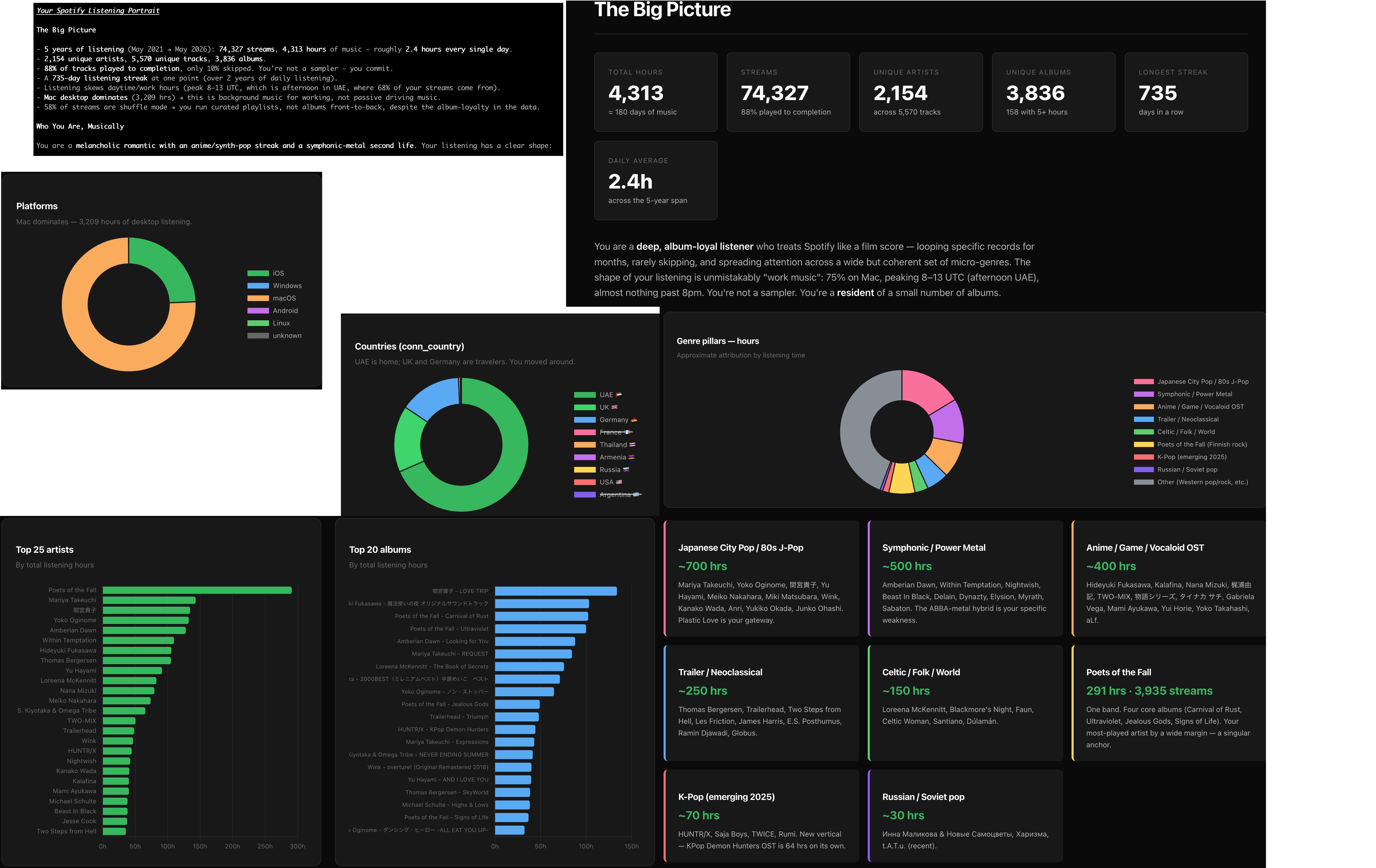
The last task was for fun. I have listened to music offline for years (Winamp, AIMP, VOX), but several years ago, I switched to Spotify after my friends pressured me to try new music, and I was curious. At first, I loved Spotify recommendations, but over time, they drifted into either repetition or noise. I wanted to see if M3 could do better, so I exported my extended streaming history and asked it to analyze it in depth, identify my tastes, and recommend new and exploratory artists and songs, with the output as an HTML report plus a CSV of the full list.
The analysis was mostly what I expected (I know what I listen to, and Spotify Wrapped helps too). M3 builds a listening profile from about 74k streams over five years (4.3k hours, 2.1k artists): a melancholic-romantic core with an anime and synth-pop streak and a symphonic-metal second life, broken into genre pillars by hours — Japanese city pop and 80s J-pop near 700 hours, symphonic and power metal near 500, anime and game OST near 400, then everything else.
One funny thing was the visualization of the countries. I have never been to France or Germany, but they were at the top of the chart thanks to VPN.
The analysis was cool and interesting, but some of the plots were questionable. The Platforms chart unnecessarily showed 6 platforms when two of them had like 99.9% of the streams, and the rest were insignificant.
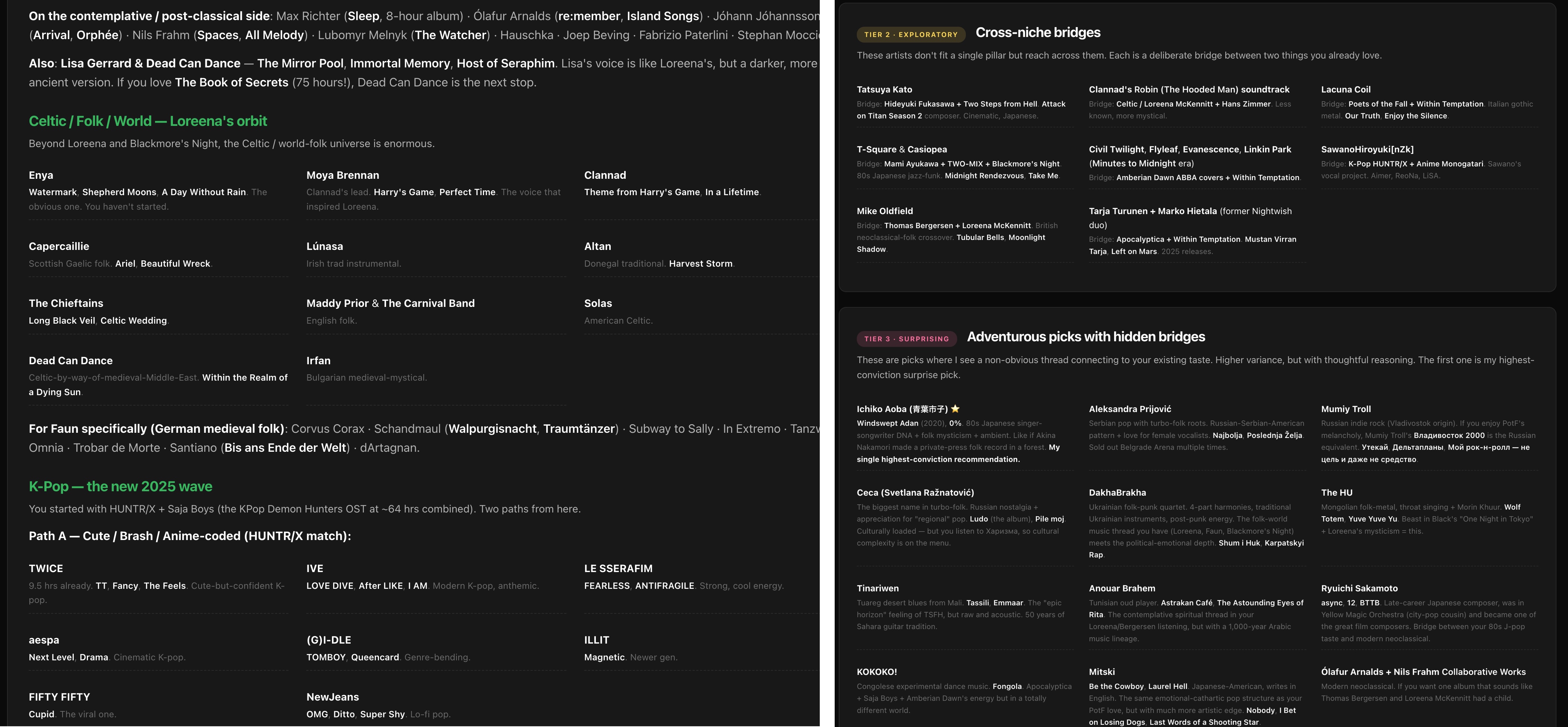
The recommendations were organized into tiers, from safe to exploratory (“cross-niche bridges,” “adventurous picks with hidden bridges”), each with a one-line reason explaining how the artist connects to something I already listen to. I have not worked through all of them, but the results are positive: most songs are okay, a few are completely off, and several are my new favorites. One of the best finds was 中森明菜 (Akina Nakamori) with DESIRE -情熱-, the kind of song I like, the one Spotify never showed me before.
Conclusion
Across the audit, the UI bugs, and the music experiment, M3 was most useful where the task gave it something concrete to work against: a test suite, a screenshot, a data export. It is fast and cheap enough to run several supervised passes, and its multimodality is a real practical advantage for debugging. The one thing I would not skip is an independent review of anything that matters, because a model that writes both the fix and the tests can be confidently wrong on both, and here it took a second model to catch it. I will keep using it for supervised refactors and screenshot-driven debugging, with a separate reviewer in the loop for the parts I care about.
This post was written in a paid partnership with the MiniMax team. If you want to try MiniMax, you can use this code for a 12% discount.
blogpost ai llm claude evaluation minimax