Paper Review: AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
AgentA/B is a new system that uses LLM-based autonomous agents to simulate user interactions with real webpages for A/B testing, addressing traditional A/B testing limitations - the need for large live human traffic and long wait times. After interviewing industry practitioners and identifying workflow bottlenecks, the authors designed AgentA/B to deploy diverse LLM personas capable of performing complex multi-step actions (searching, clicking, purchasing). In a controlled experiment with 1,000 LLM agents, AgentA/B showed it could replicate human-like shopping behavior at scale, offering a promising alternative for faster, scalable A/B testing.
Formative study

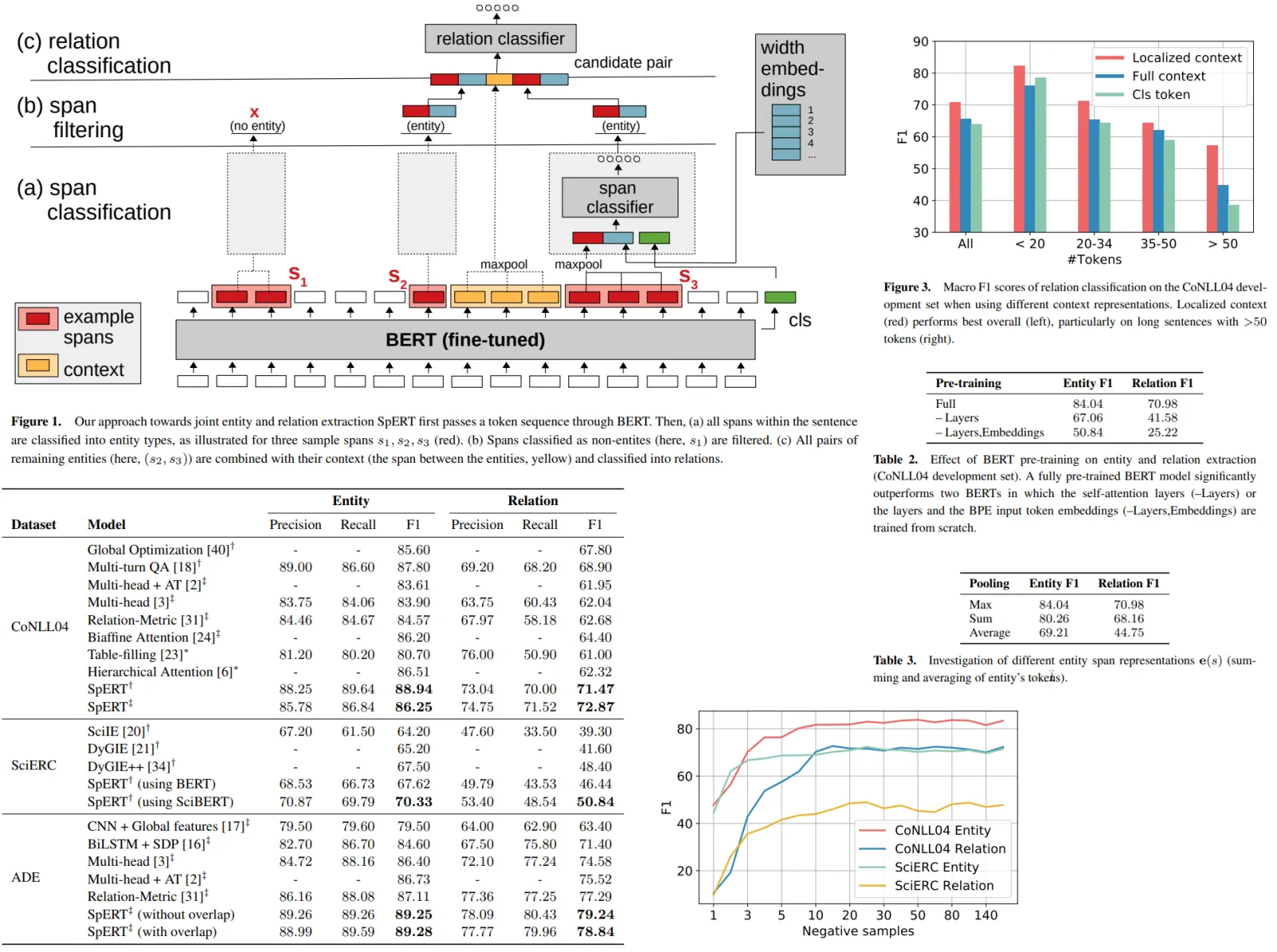
To guide the design of their LLM agent-based A/B testing system, the authors conducted semi-structured interviews with six experienced A/B testing professionals from the U.S. e-commerce industry. The researchers used grounded theory analysis, where two co-authors independently coded practices, tools, and challenges, developed a shared codebook, and organized findings into broader themes like A/B testing lifecycle and system bottlenecks, which shaped the system’s design.
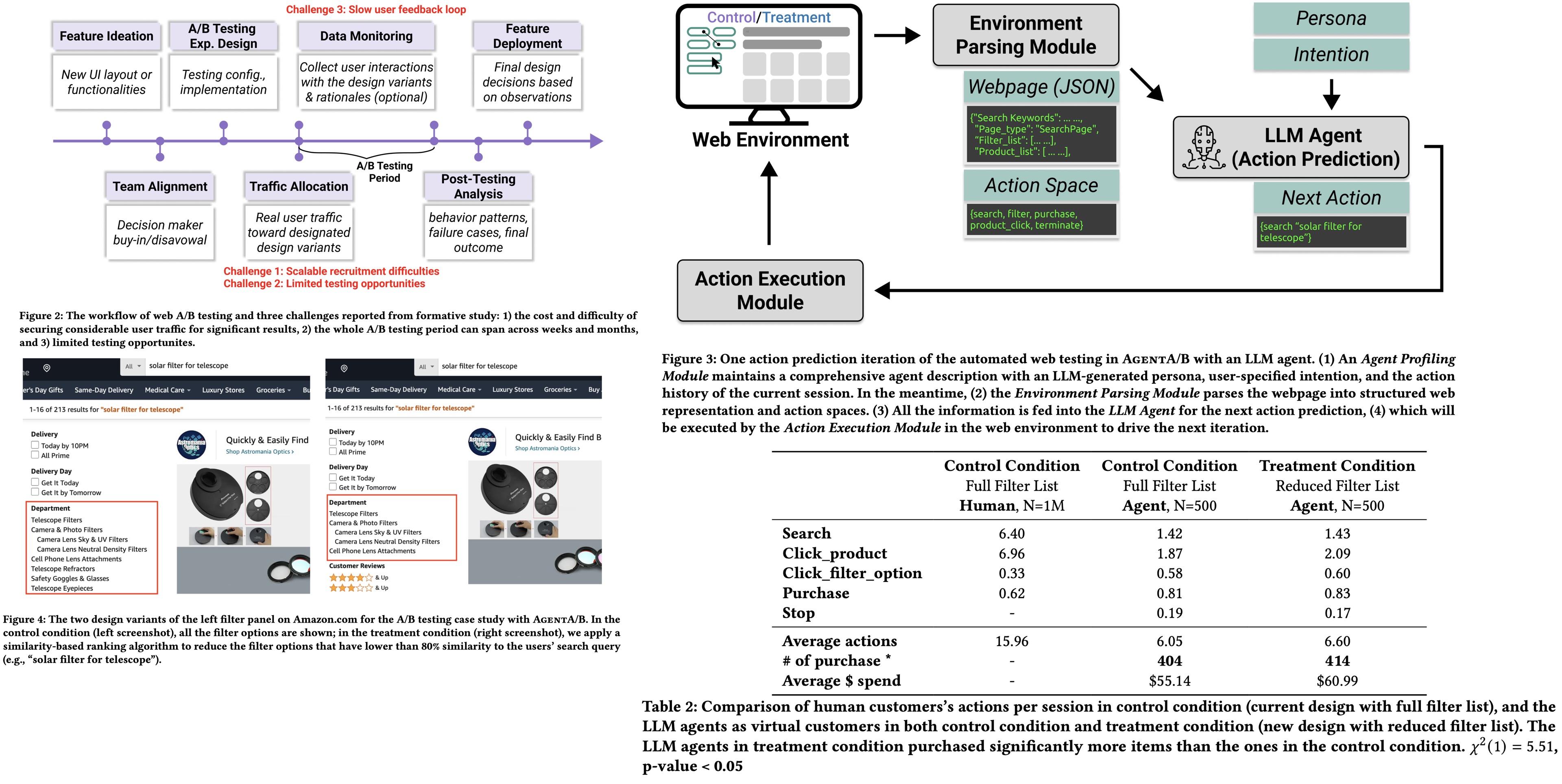
Interviews described that an A/B testing project typically follows seven stages:
- New feature ideation
- Team alignment and buy-in
- Experiment design
- Feature development and iteration
- A/B experiment launch
- Post-experiment analysis
- Feature decision
The full process often takes 3 months to a year, requiring cross-team collaboration.
The main challenges:
- High Development Cost: Building features for A/B testing is resource-intensive and time-consuming, with little early feedback.
- Lack of Early Feedback: Formal user feedback only arrives after launch, and internal alpha tests are often biased.
- Traffic Competition: Teams compete for user traffic, and lack automated tools to prioritize and manage test traffic, causing delays.
- High Failure Rates: About one-third of A/B tests fail to meet success criteria, leading to wasted effort.
The approach
System Overview and Pipeline
AgentA/B is an end-to-end simulation system for LLM agent-based A/B testing on live webpages. It mirrors traditional A/B testing but replaces human users with simulated agents.
The first step is defining agent specifications (demographics, behaviors, number of agents) and test configurations (goals, tracked metrics, features to test). The agent’s goal could be “find a discounted Bluetooth speaker under $30”.
Modules:
- LLM Agent Generation: creates diverse agents with specified personas and intentions.
- Testing Preparation: splits agents into control and treatment groups, ensures balanced distributions, and assigns agents to different web environments.
- Autonomous Simulation: agents interact with webpages via ChromeDriver and Selenium WebDriver, making decisions and recording all actions step-by-step.
- Post-Testing Analysis: aggregates and analyzes interaction data and provides comparative metrics and detailed behavior insights.
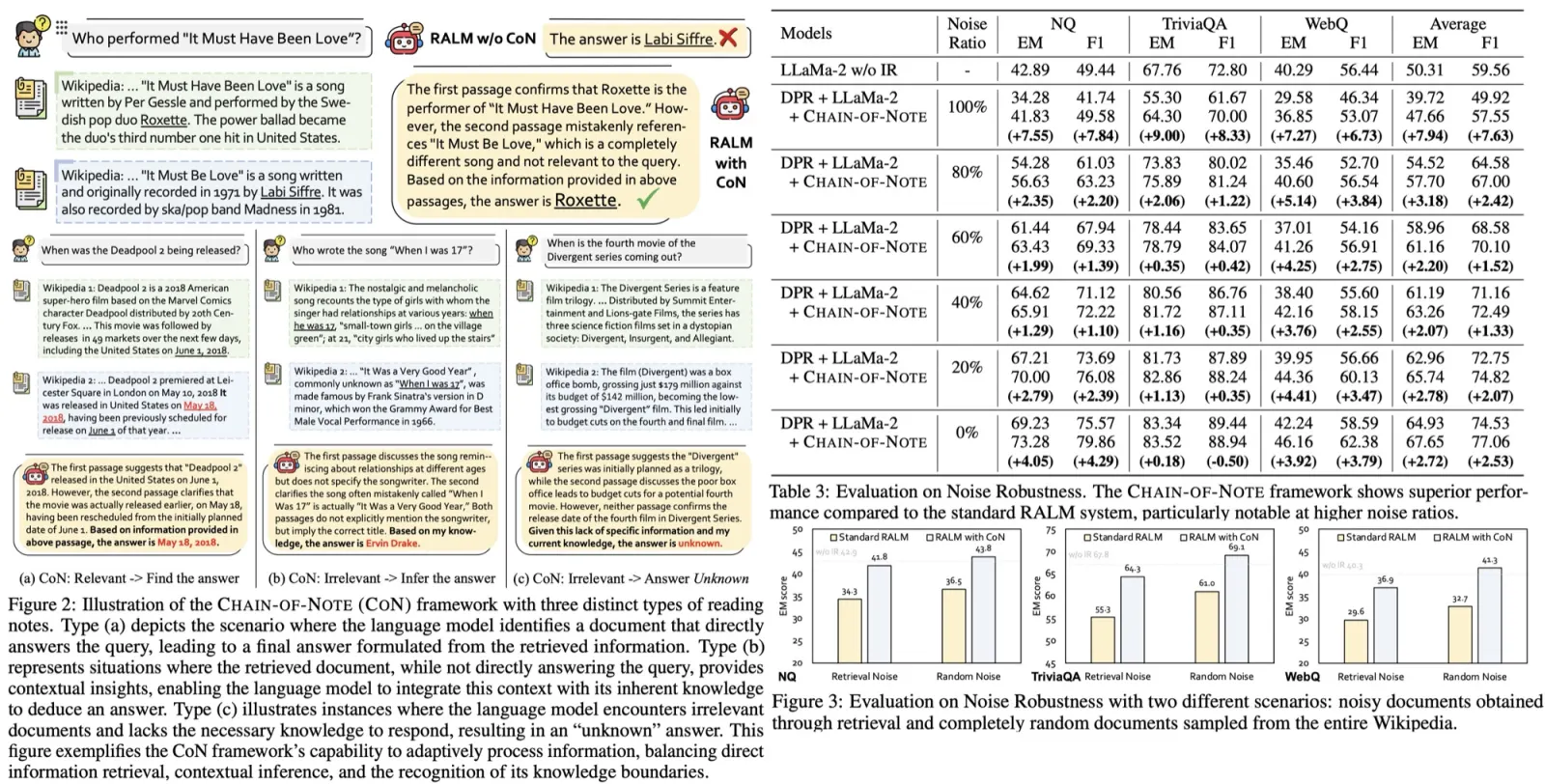
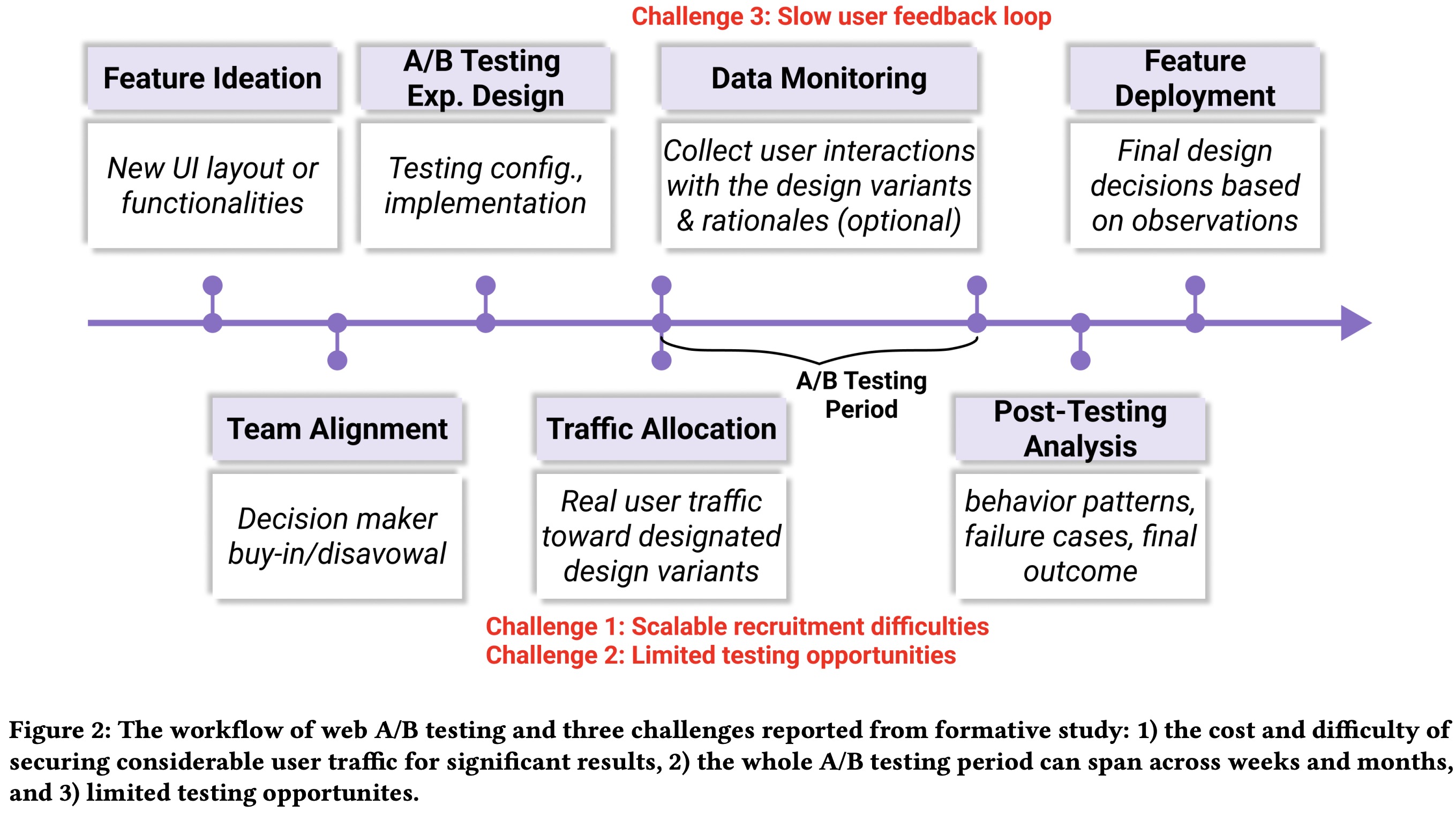
Agent-Environment Interaction Architecture
The core of AgentA/B is continuous interaction between LLM agents and live web environments, consisting of three components: the Environment Parsing Module, the LLM agent, and the Action Execution Module.
The Environment Parsing Module simplifies webpages into structured JSON observations by extracting only essential elements using ChromeDriver and JavaScript. It also defines the agent’s allowed actions: search, click product, click filter option, purchase, and stop. This structure enables realistic, efficient simulation of multi-step shopping behaviors in dynamic environments.
The LLM agent receives the structured webpage, action space, persona, and intention, and acts as a decision-making module that reasons about the current state and outputs the next action. It supports different LLM agent frameworks through a plug-and-play API.
The Action Execution Module translates predicted actions into real browser commands. The interaction loop continues until the agent completes its goal or hits failure or timeout conditions, and each session records the full trace of actions, rationales, page states, and outcomes.
Case study
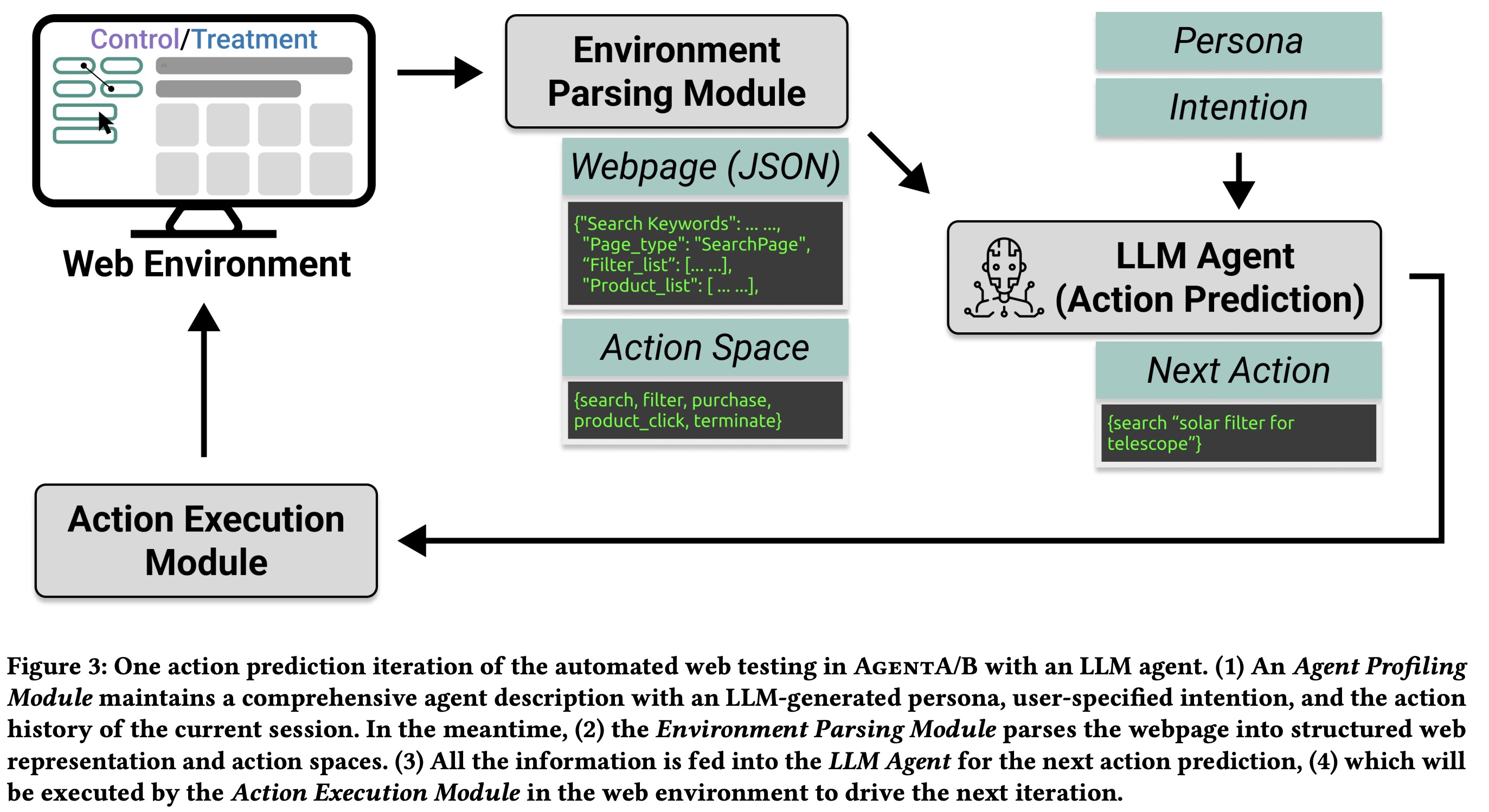
A/B Testing Scenario
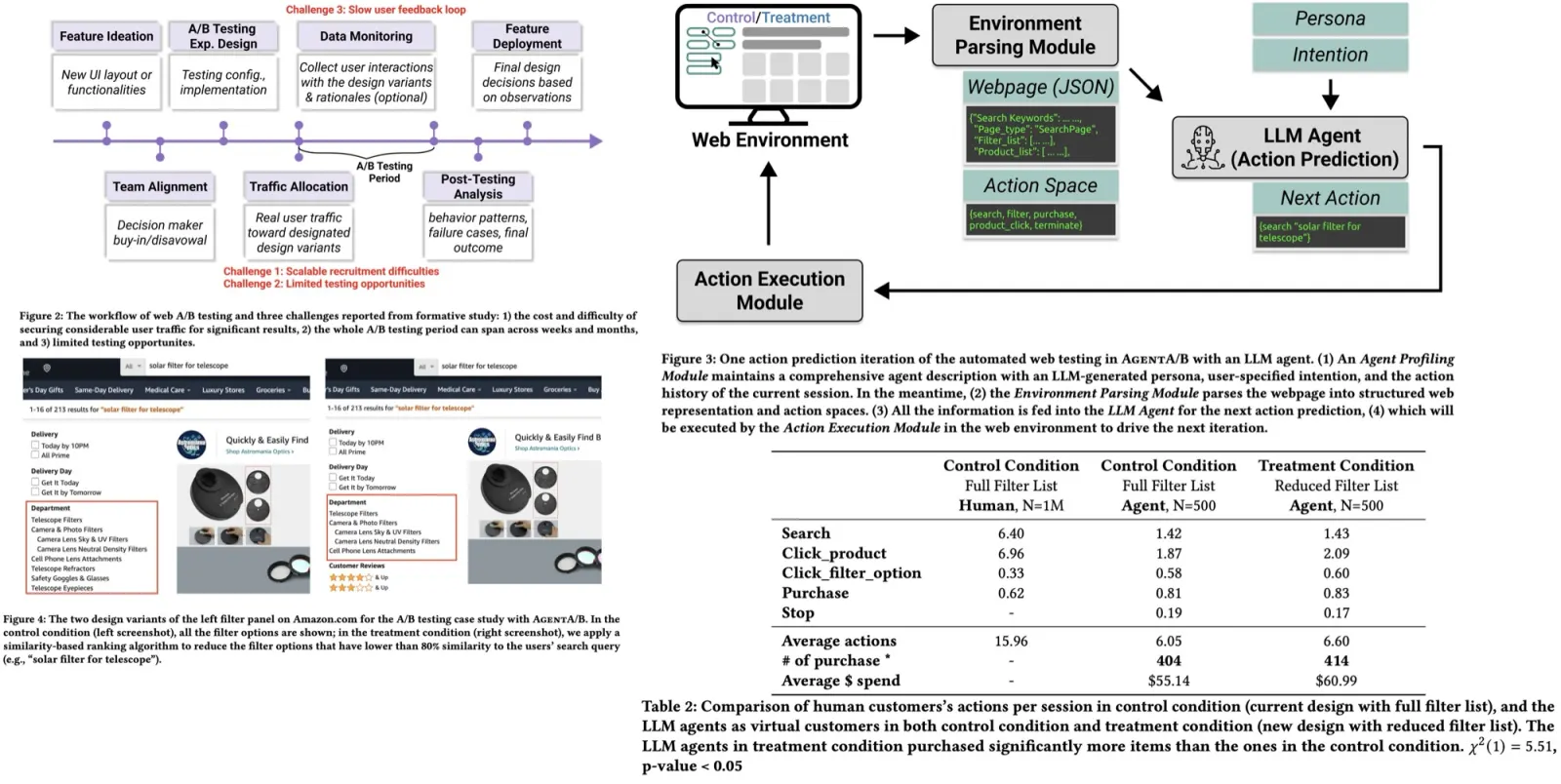
The authors simulated an A/B test on Amazon’s shopping interface to study how changes to the left-side filter panel affect user behavior. They compared the original design (showing all filters) with a new design that hides filters with less than 80% similarity to the search query. They used the AgentA/B system with Claude 3.5 Sonnet as the backend to generate 100k agent personas and sampled 1000 for the test. Each agent had a demographic profile and a shopping goal, and can use typical e-commerce actions. Simulation sessions were capped at 20 actions.
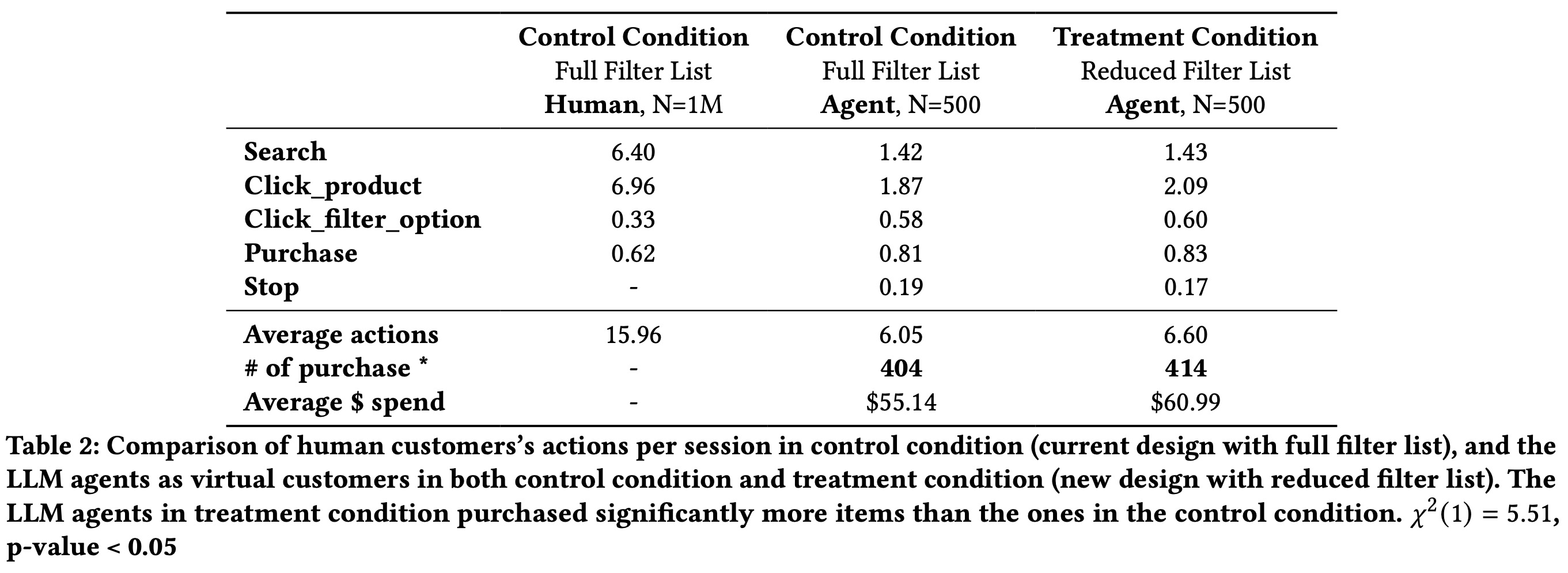
Finding: Alignment with Human Behavior
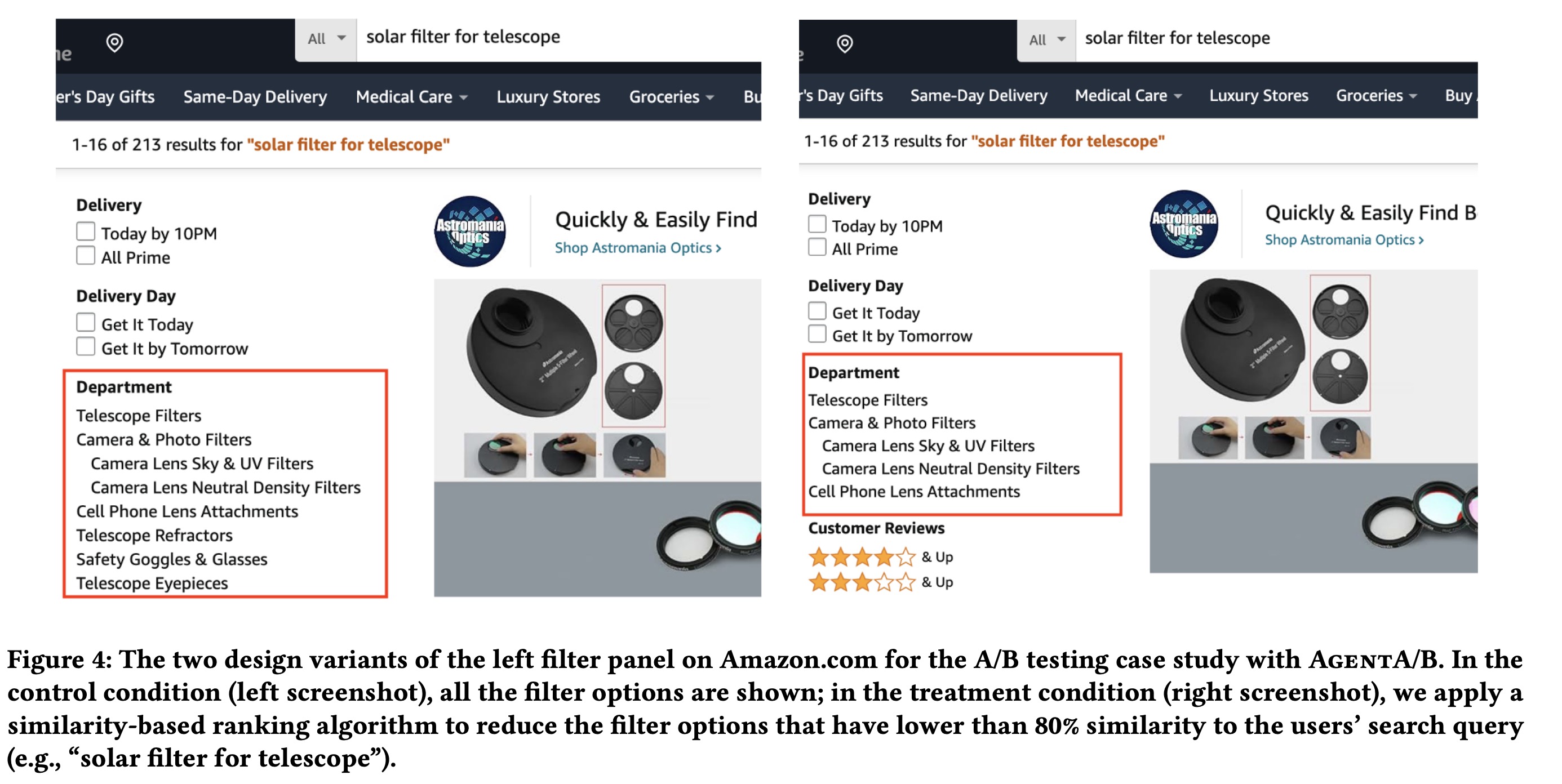
The authors compared AgentA/B’s simulated A/B testing results with real human A/B testing under identical conditions. Humans performed nearly twice as many actions per session and engaged in more exploratory behaviors (more clicks and searches), while LLM agents were more goal-directed and structured. Despite these differences, purchase rates and filter usage were similar between humans and agents, indicating that AgentA/B can reasonably approximate human decision-making for intention-driven tasks, making it useful for rapid UX evaluations without live deployment.
Findings: System Effectiveness Across Interface Variants
The authors used AgentA/B to test whether LLM agents could detect subtle UI design differences. Agents in the treatment condition (with improved filters) clicked more products, used filters slightly more, and made more purchases compared to the control group, though most differences were not statistically significant, except for the number of purchases. Agent behavior changes were consistent with trends seen in real human A/B tests.
paperreview deeplearning agent nlp llm