Paper Review: Cut and Learn for Unsupervised Object Detection and Instance Segmentation
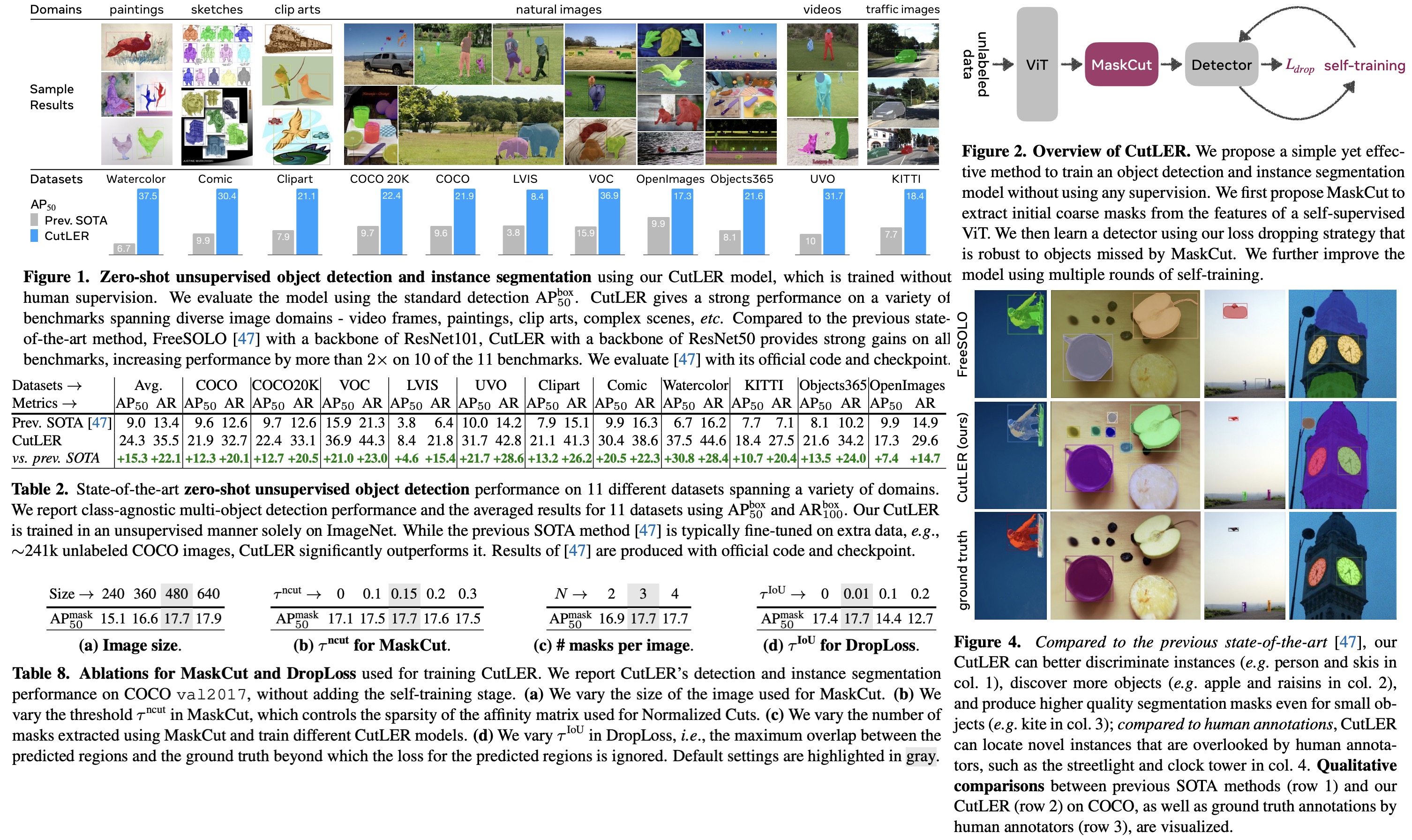
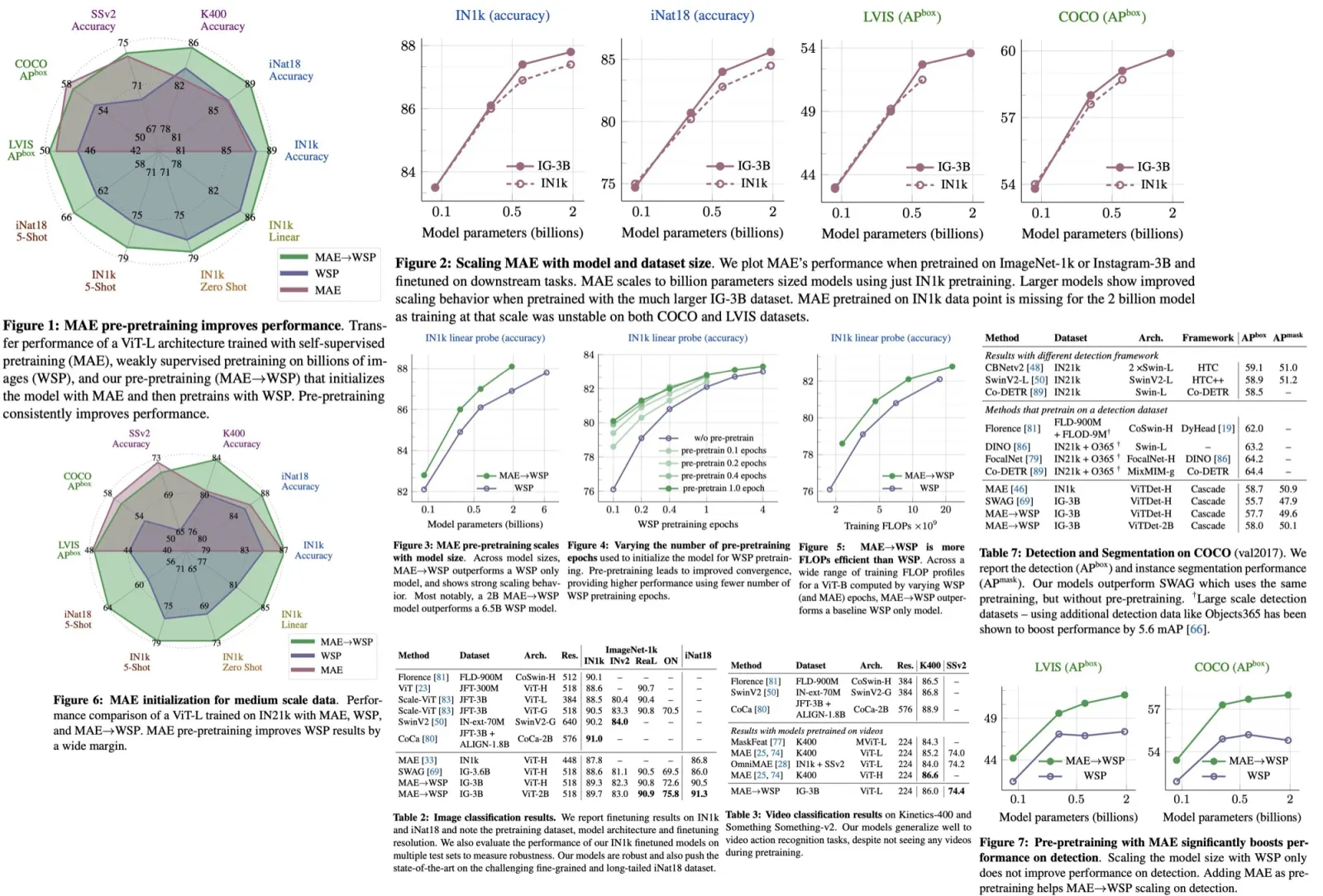
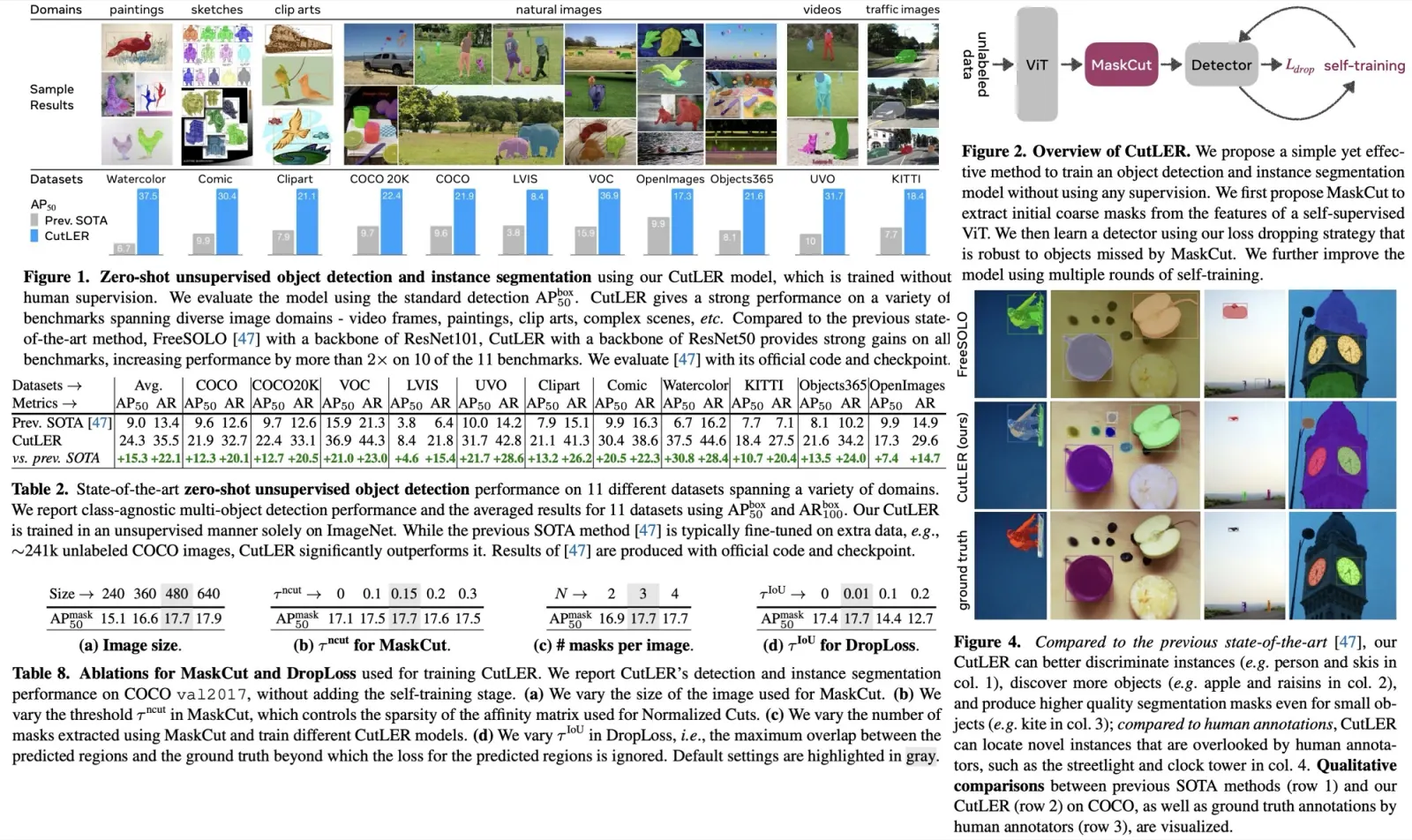
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
The approach
Preliminaries
Normalized Cuts (NCut) is a method for image segmentation that treats it as a graph partitioning problem. A graph is constructed by connecting nodes that represent image patches, with edges between nodes representing the similarity of the connected patches. NCut solves for the second smallest eigenvector of a generalized eigenvalue system to minimize the cost of partitioning the graph into two sub-graphs. DINO and TokenCut are previous works that leverage NCut, using the similarity of image patches in a feature space to compute the edge weights in NCut. However, a limitation of TokenCut is that it only computes one binary mask per image and only finds one object, reducing performance for multi-object discovery.

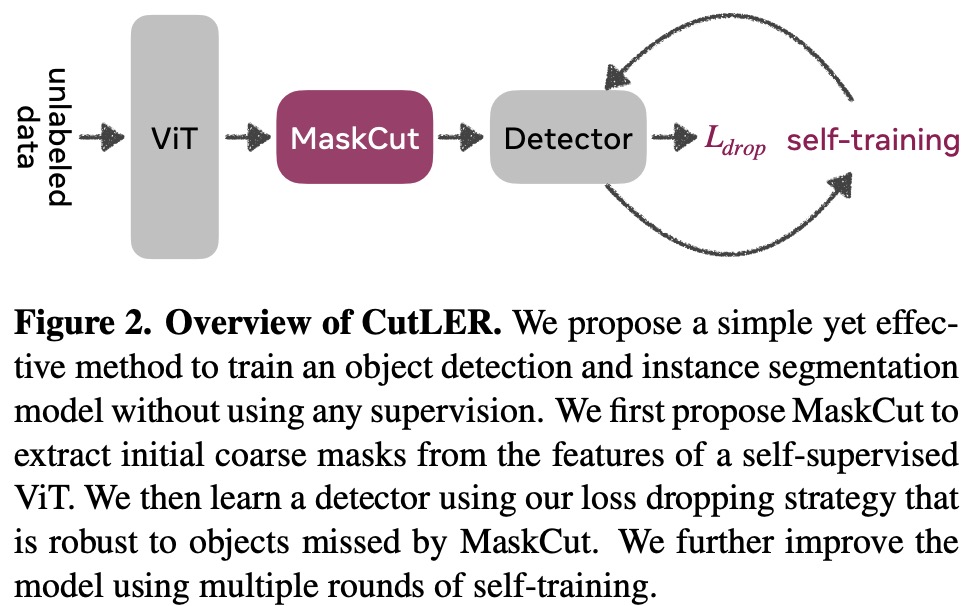
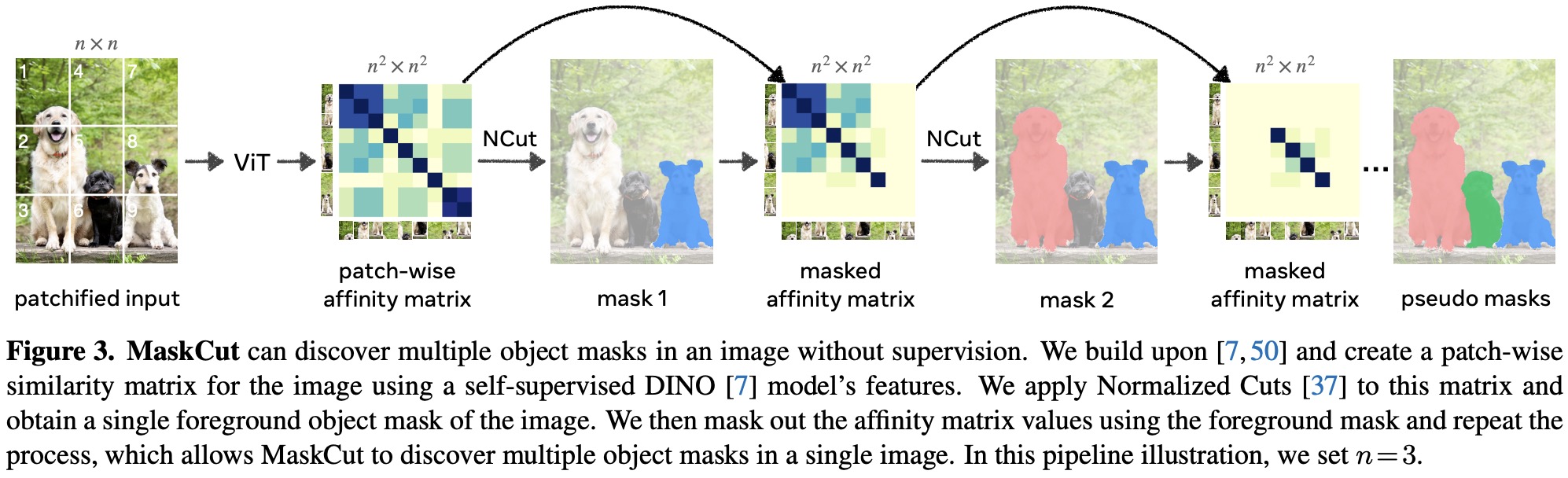
MaskCut
The authors propose “MaskCut” as an extension to the Normalized Cuts (NCut) method for image segmentation. MaskCut allows for the discovery of multiple objects per image by iteratively applying NCut to a masked similarity matrix. After getting the bipartition of the graph in each iteration, a binary mask is constructed using two criteria: the patches with higher values in the second smallest eigenvector should correspond to the foreground, and the foreground set should contain less than two of the four image corners. The node similarity is updated in each iteration by masking out the nodes corresponding to the foreground in previous stages, and this process is repeated until all objects have been discovered (three times by default).
DropLoss
The standard detection loss penalizes predicted regions that don’t overlap with the “ground-truth” masks, which may miss some instances (MaskCut generates them). To overcome this limitation, the authors propose to ignore the loss for predicted regions that have a low overlap with the “ground-truth” instances, with a threshold of 0.01. This encourages the exploration of different image regions and helps the detector discover objects not labeled in the “ground-truth”.
Multi-Round Self-Training
The authors employ a self-training strategy to improve the performance of a detection model. They use the predicted masks from each iteration of training, with a confidence score above a certain threshold, as additional pseudo annotations for the next round of self-training. They also filter out ground-truth masks that have a high IoU with the predicted masks to de-duplicate the predictions. The authors found that three rounds of self-training are sufficient to achieve good performance. Each round steadily increases the number of ground-truth samples used in training.
Implementation
The CutLER model uses images from the ImageNet dataset (1.3 million images) and does not use any annotations or pre-trained models. The MaskCut is used to generate masks (images are 480x480) with a three-stage process using the ViT-B/8 DINO model and CRF post-processing. The model is trained with either Mask R-CNN or Cascade Mask R-CNN on ImageNet for 160,000 iterations with a batch size of 16. The detector is initialized with the weights of a self-supervised DINO model and is optimized using SGD with a learning rate of 0.005, which decreases by 5 after 80,000 iterations. The authors use copy-paste augmentation and add mask downsampling. Self-training is done by initializing the detection model with the weights from the previous stage and optimizing for 80,000 iterations with a learning rate of 0.01. The model is not trained with the DropLoss during self-training.
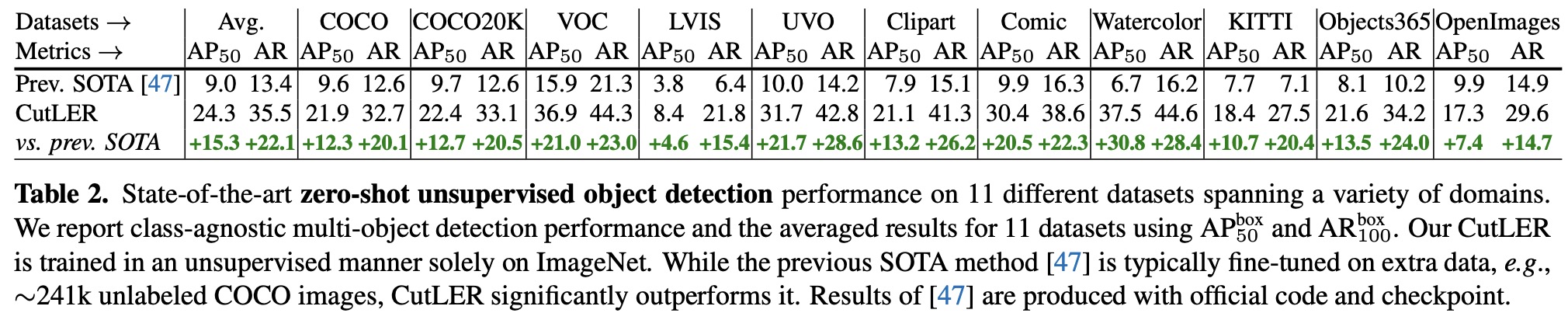
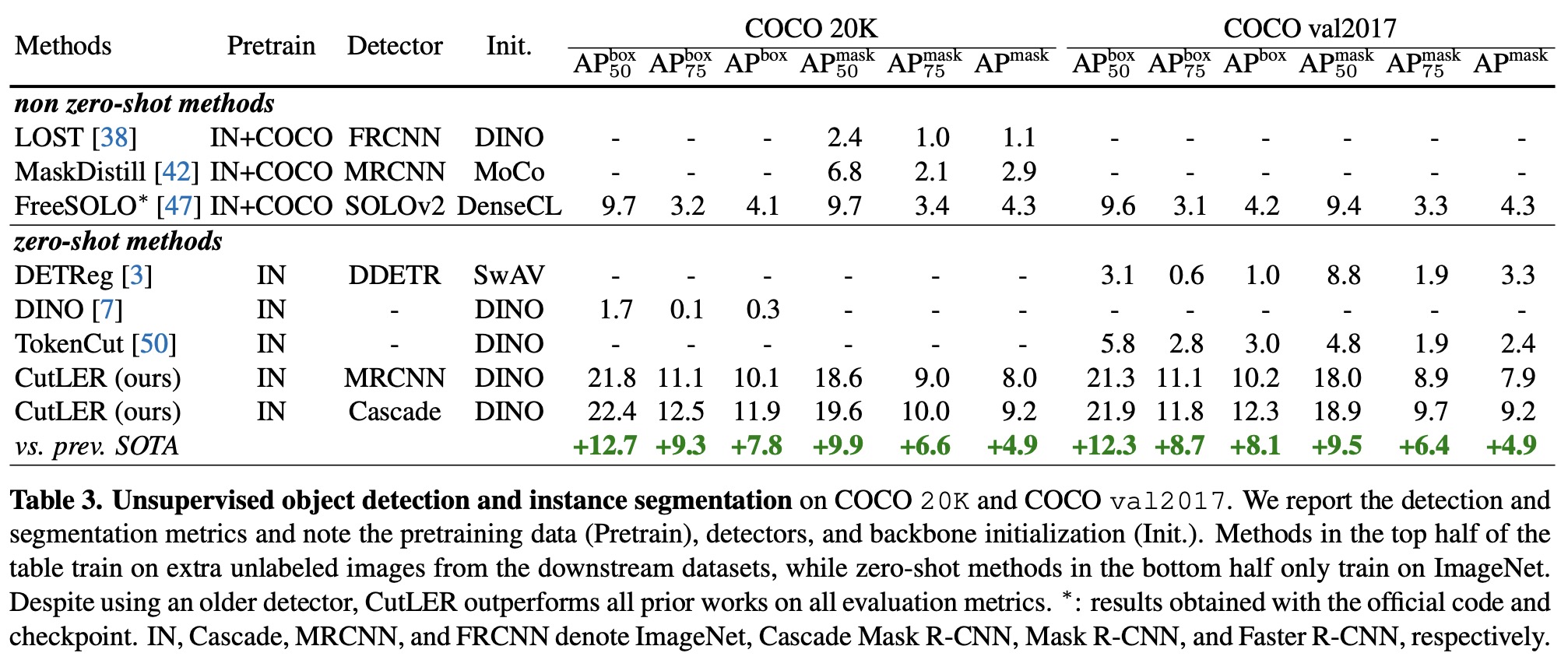
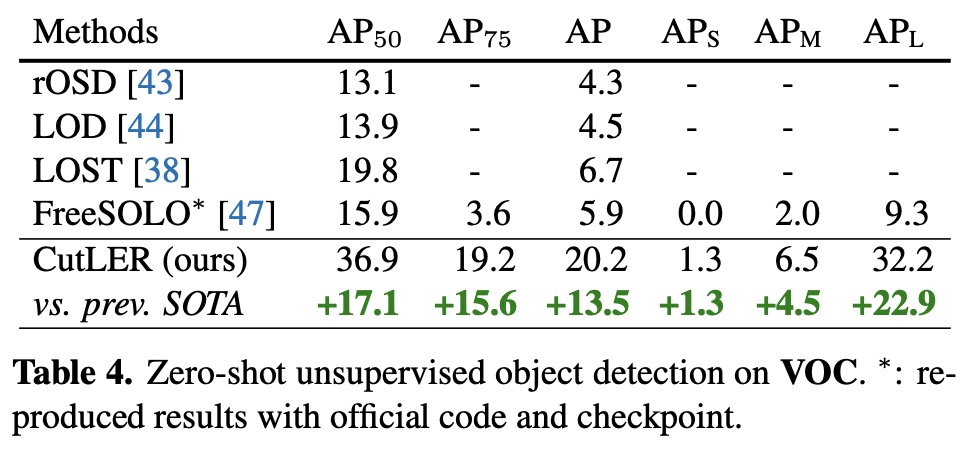
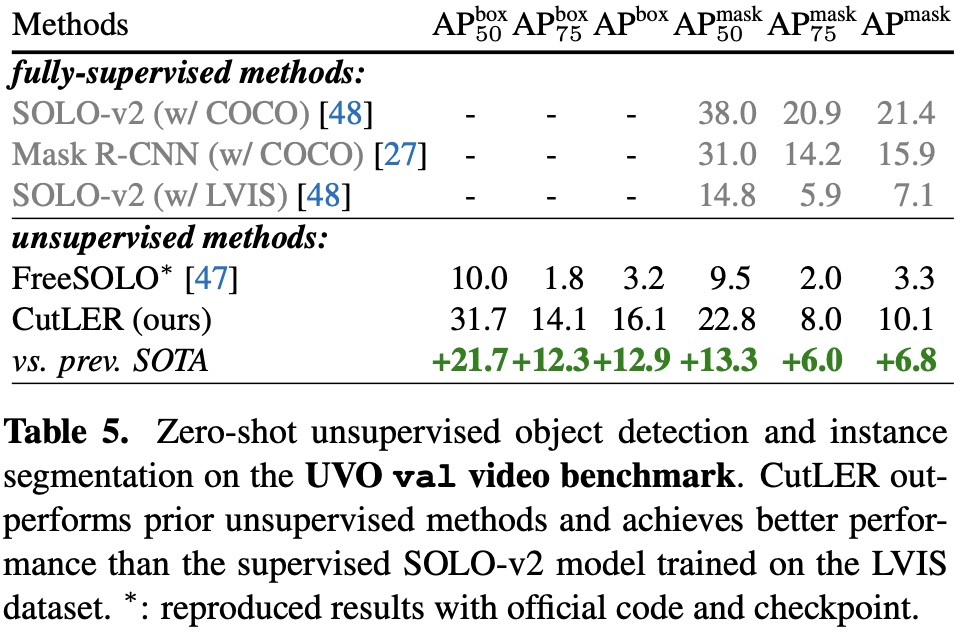
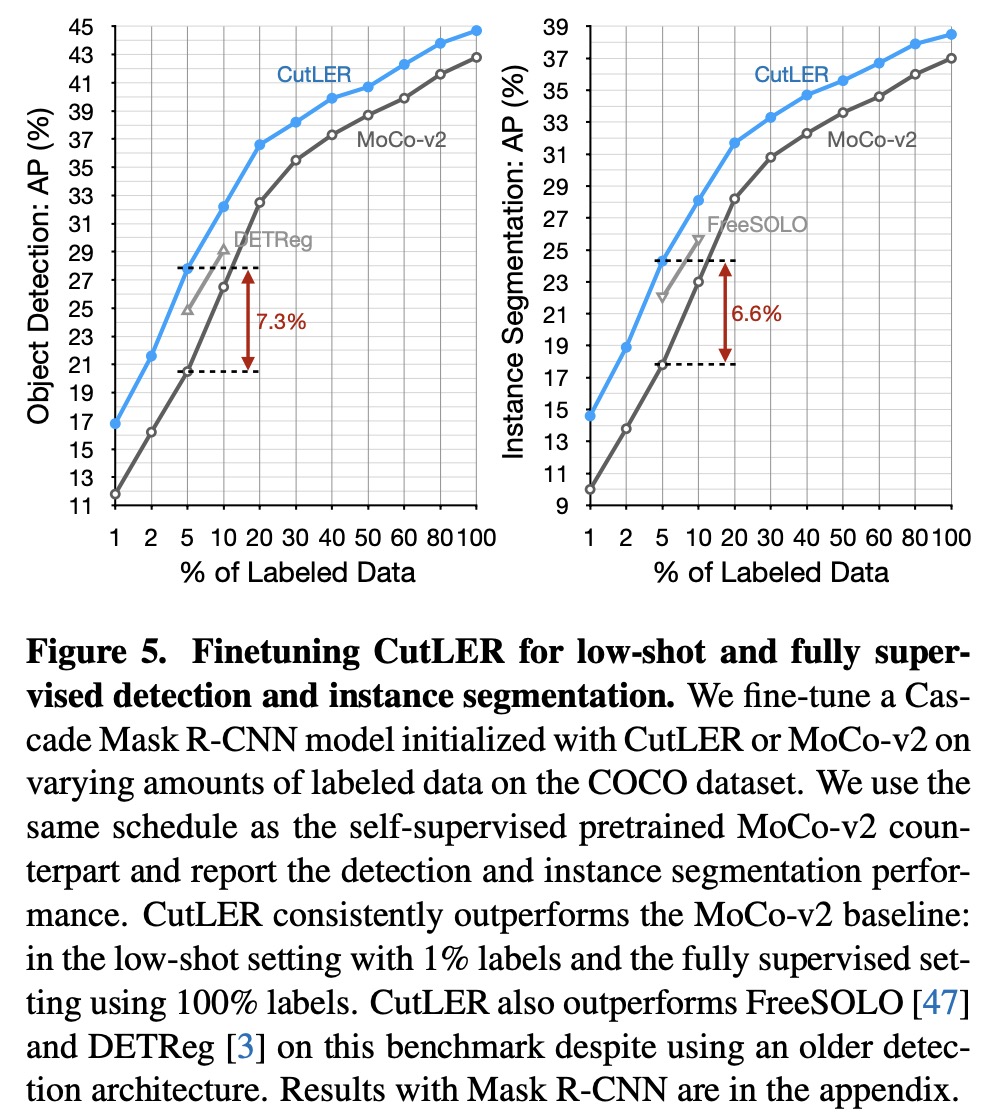
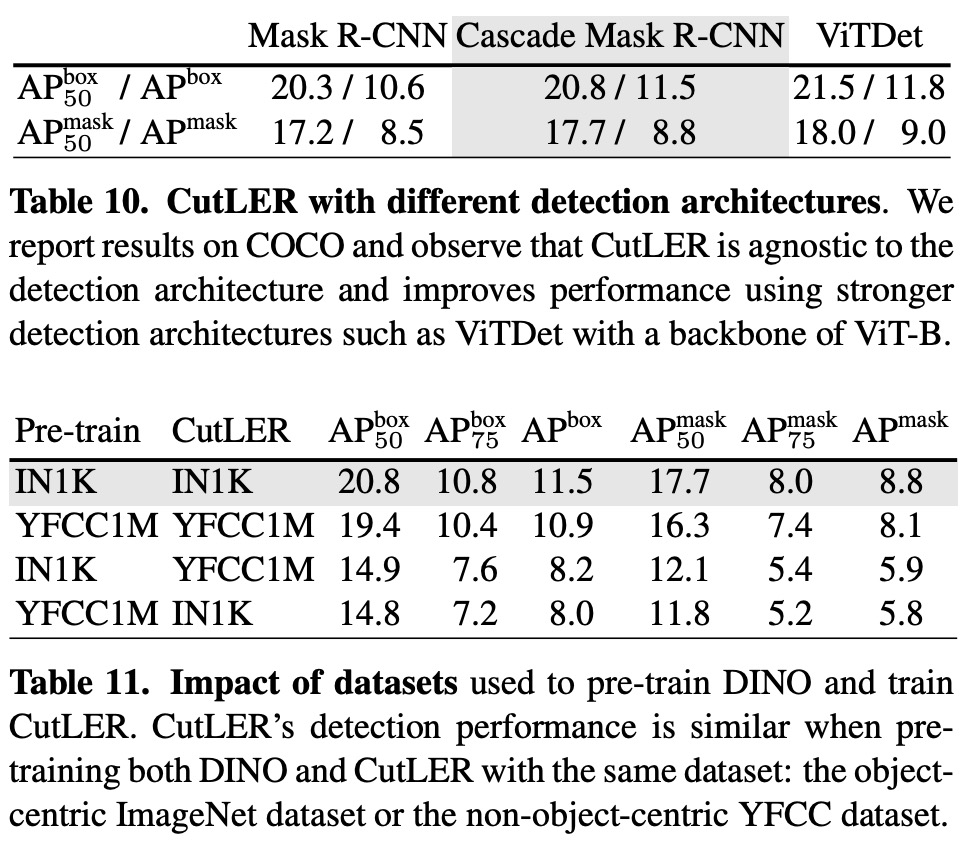
Results