Paper Review: DINOv3
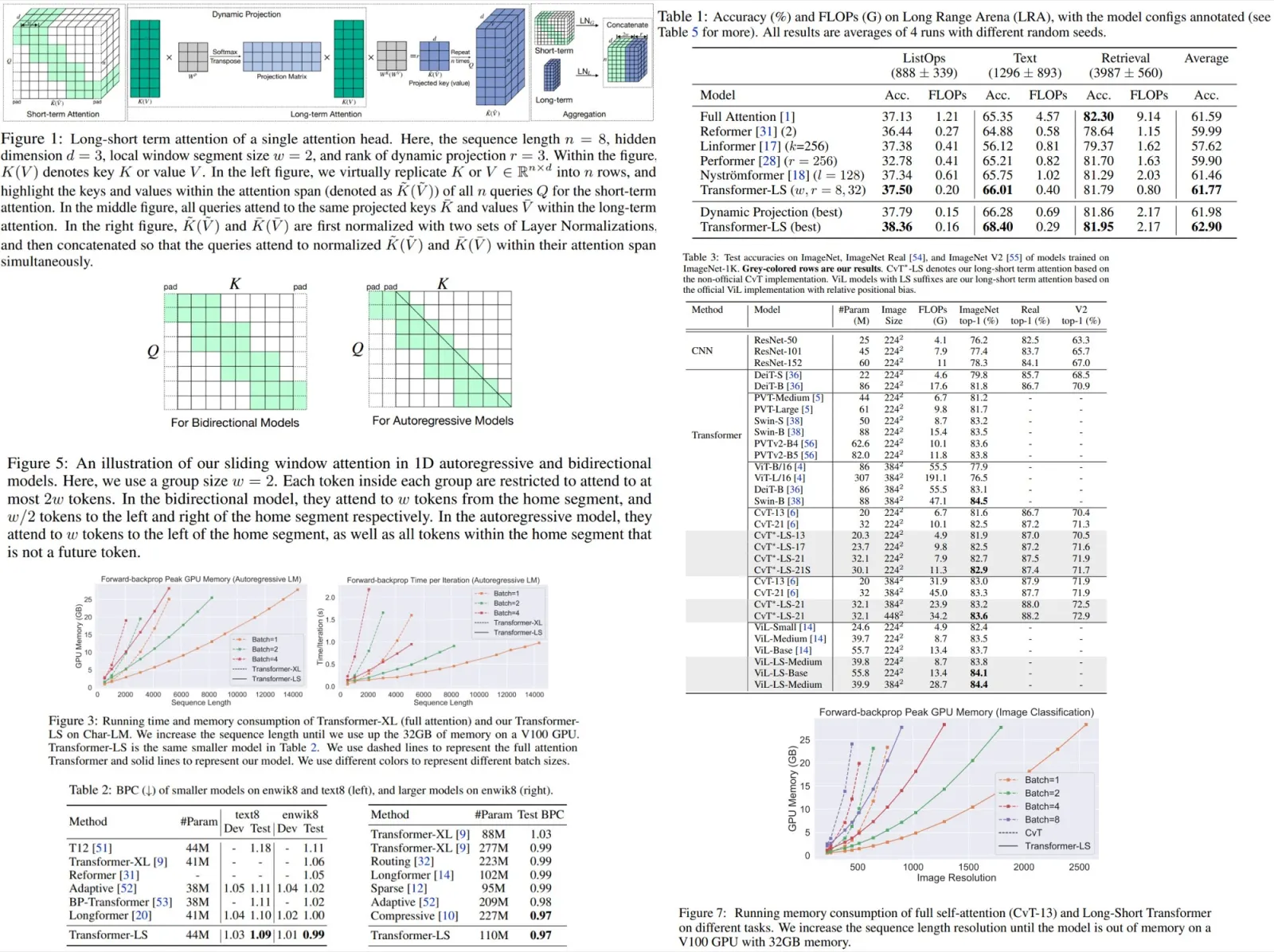
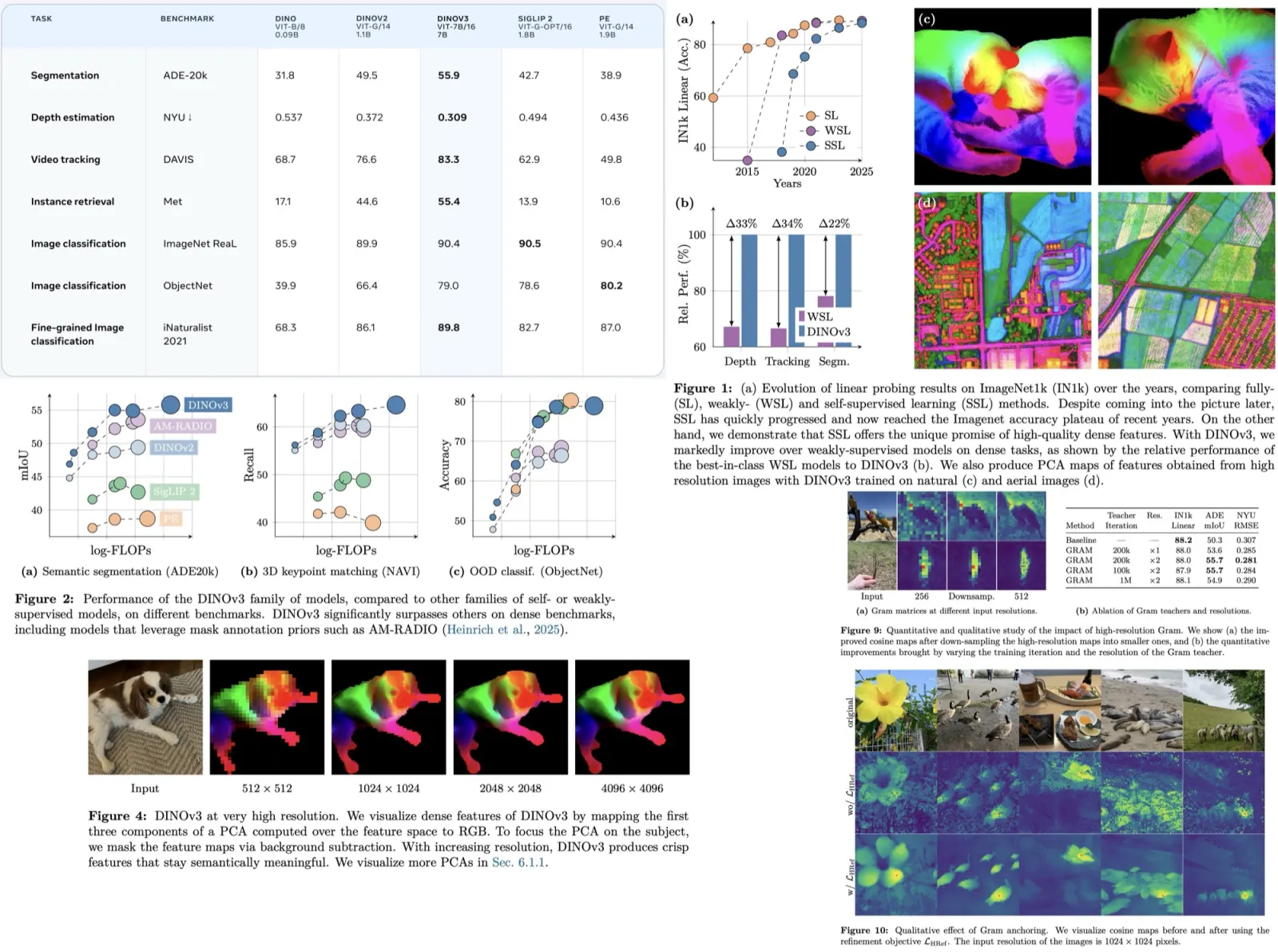
DINOv3 is a self-supervised vision model that scales effectively to large datasets and architectures, introduces Gram anchoring to prevent degradation of dense feature maps during long training, and applies post-hoc strategies for flexibility across resolutions, model sizes, and text alignment. It achieves superior performance on a wide range of vision tasks without fine-tuning and provides a suite of scalable models for diverse resource and deployment scenarios.
Training at Scale Without Supervision
Data Preparation
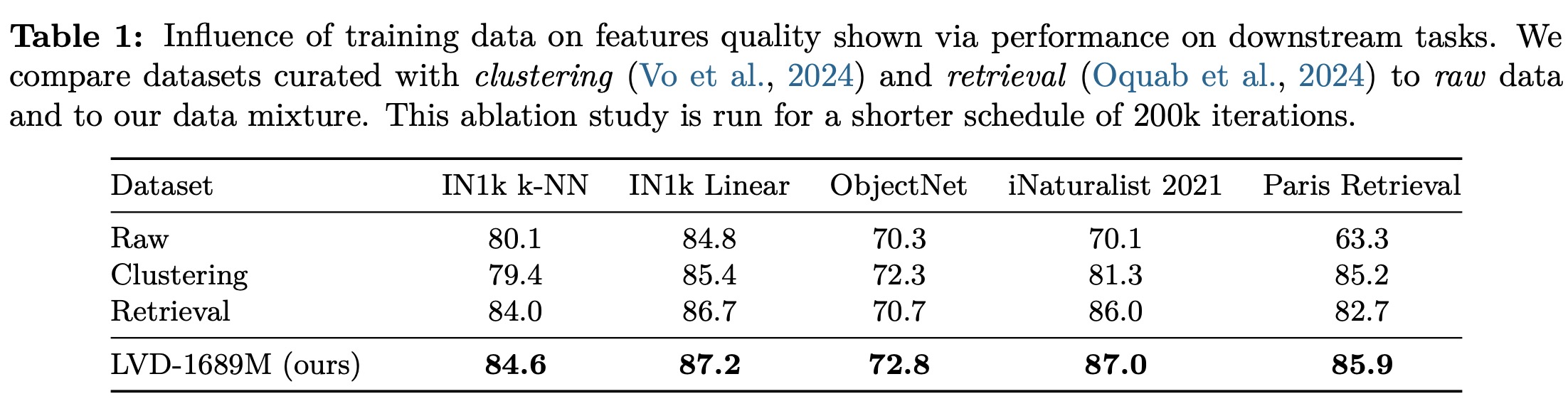
DINOv3 is trained on a large-scale dataset built from ~17 billion Instagram images, filtered through content moderation. To maximize both generalization and task relevance, the data is curated in three ways: hierarchical k-means clustering with balanced sampling to ensure broad visual diversity (yielding 1.7B images), retrieval-based selection to emphasize downstream-relevant concepts, and inclusion of standard vision datasets like ImageNet and Mapillary. During training, batches are sampled either homogeneously from ImageNet1k (10% of the time) or heterogeneously from all other sources. An ablation study shows that clustering, retrieval, or raw data alone do not consistently outperform each other, but combining all methods produces the best overall performance across benchmarks.
Large-Scale Training with Self-Supervision
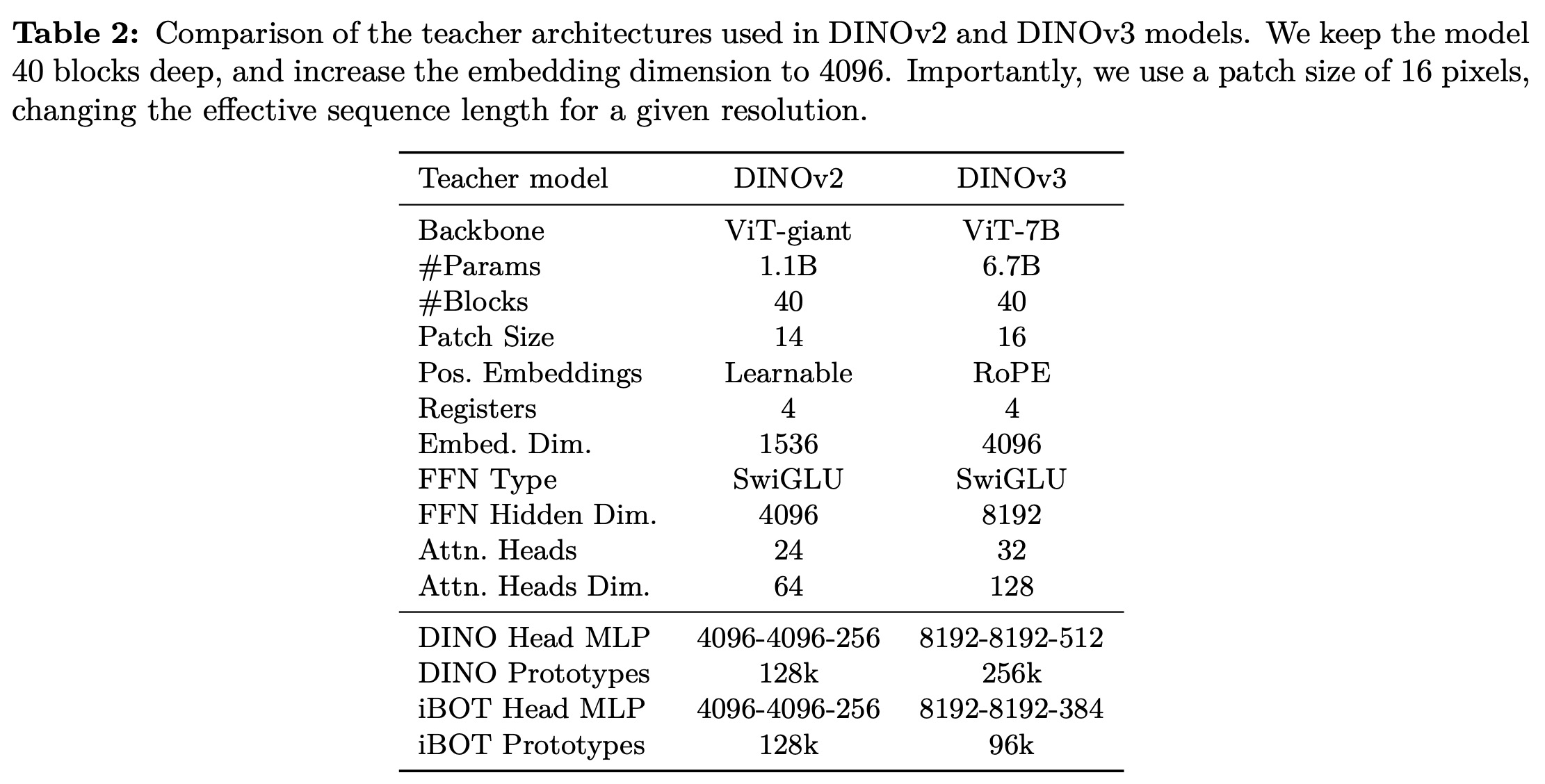
Most self-supervised learning methods struggle to scale to very large models due to instability or overly simple objectives, but DINOv2 showed strong results with 1.1B parameters. Building on this, DINOv3 scales to 7B parameters and combines multiple self-supervised objectives: an image-level loss (LDINO), a patch-level reconstruction loss (LiBOT), and a uniformity regularizer (LKoleo), with stability improvements: Sinkhorn-Knopp normalization and dedicated heads for global and local crops. The authors use a custom RoPE with box jittering to handle varying resolutions and aspect ratios. Optimization is simplified by removing parameter schedules, using constant learning rates and weight decay, and continuing training as long as downstream performance improves. Training uses AdamW, a batch size of 4096 across 256 GPUs, and a multi-crop strategy with 2 global and 8 local crops per image, enabling robust large-scale learning with improved global and local visual features.
Gram Anchoring: A Regularization for Dense Features
Loss of Patch-Level Consistency Over Training
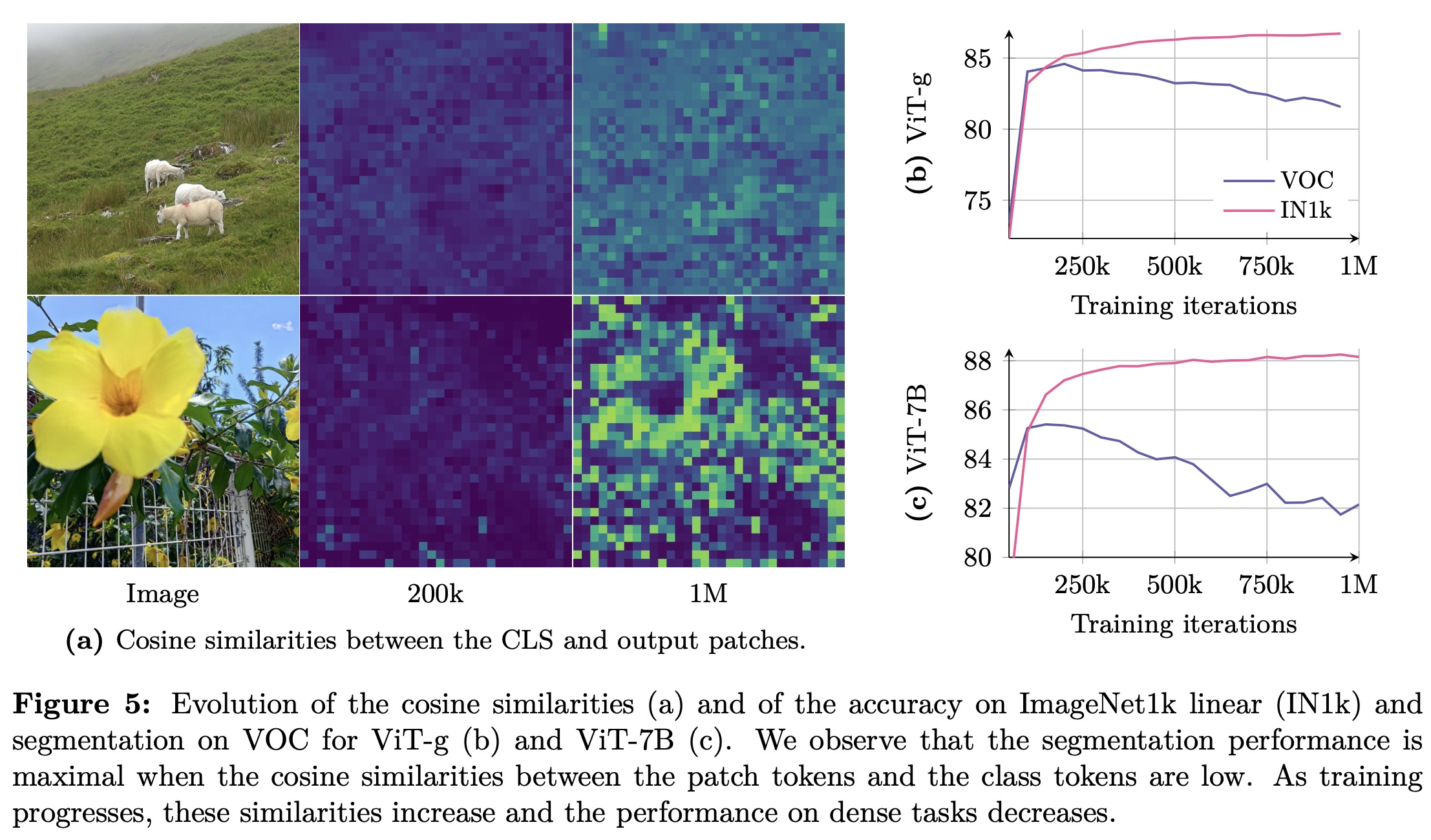
Extended training of DINOv3 improves global metrics (like image classification) but causes a decline in dense prediction tasks (like segmentation), with performance dropping after about 200k iterations. Analysis shows that patch-level features lose locality over time: similarity maps become noisy, and patch outputs increasingly align with the CLS token, reducing consistency. Unlike previously observed patch outliers, patch norms remain stable, but locality degrades. To address this, the authors introduce a new objective to regularize patch features, maintaining consistency for dense tasks while keeping strong global performance.
Gram Anchoring Objective
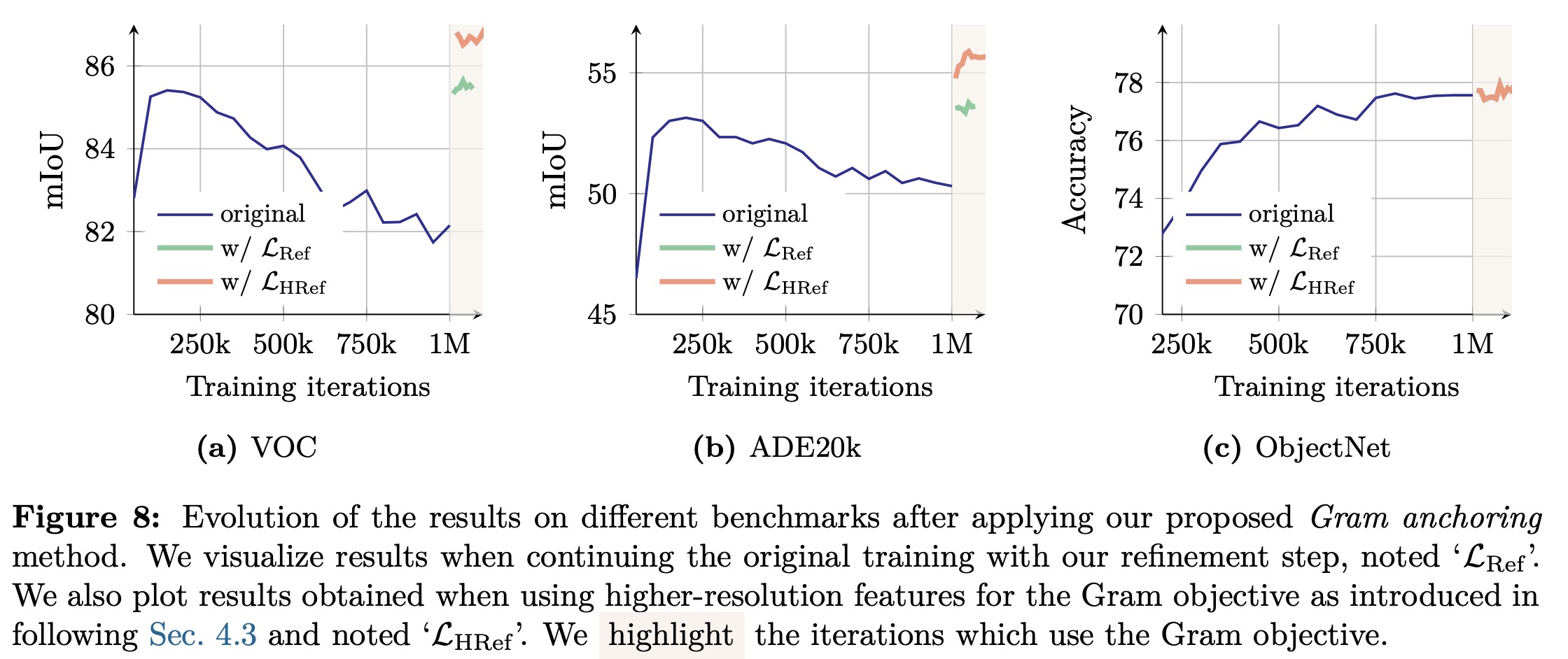
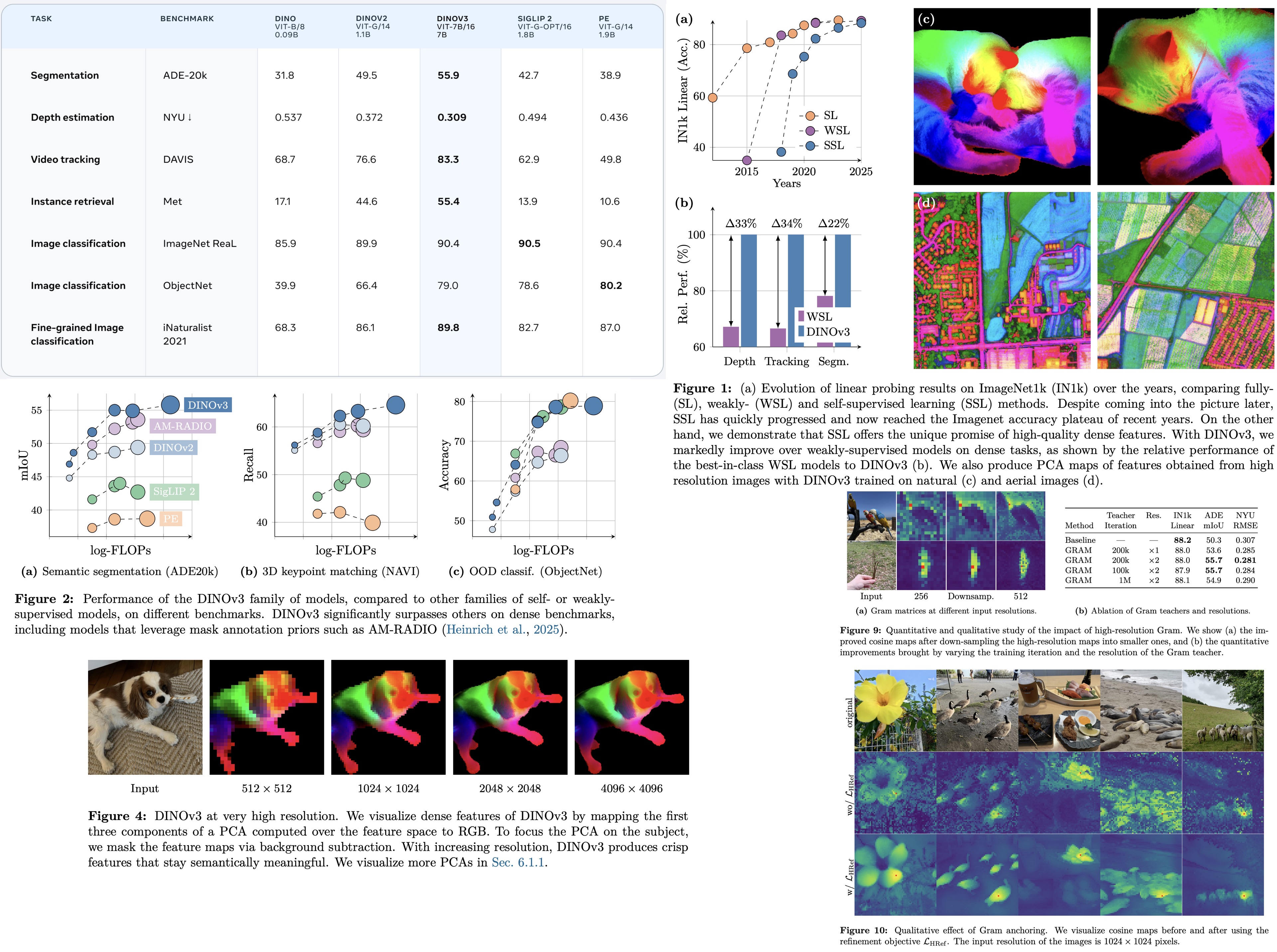
Experiments show that learning strong global representations and maintaining local consistency are relatively independent, with global performance dominating over time. Gram anchoring enforces patch-level consistency by aligning the Gram matrix of patch similarities between the student and an earlier “Gram teacher” model that preserves better dense properties. This loss is applied after 1M iterations and refined by periodically updating the Gram teacher. Gram anchoring quickly restores degraded local features, stabilizes the iBOT objective, and yields significant improvements on ADE20k segmentation, while having little negative impact on global benchmarks and even boosting some, such as ObjectNet.
Leveraging Higher-Resolution Features
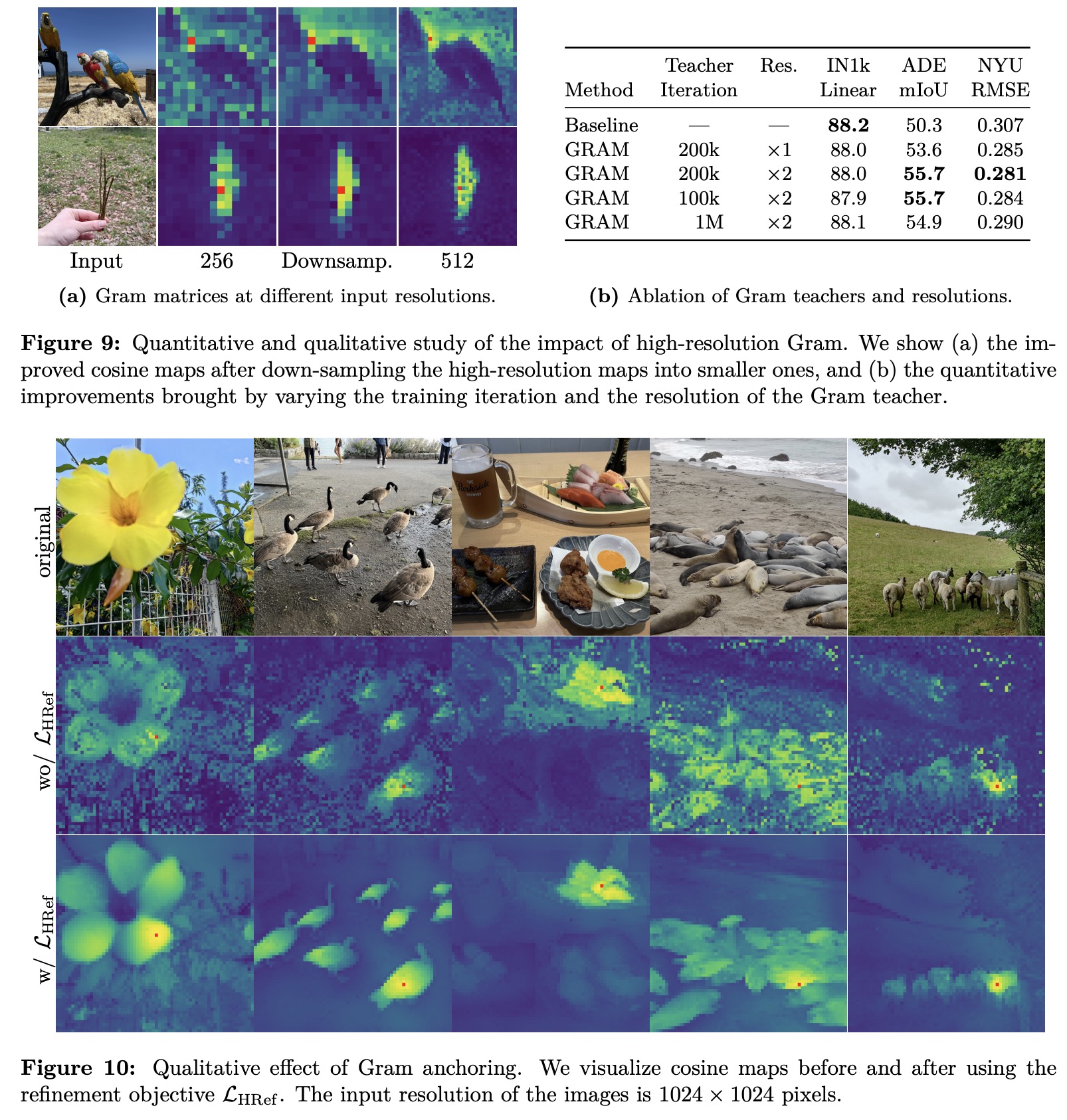
The authors use high-resolution refinement for the Gram teacher to improve patch-level consistency in dense tasks. Images are fed at double resolution, and the resulting feature maps are down-sampled to match the student’s output, preserving smoother and more coherent patch representations. These down-sampled features are used in the Gram objective, making a new loss LHRef. This approach distills the superior consistency of high-resolution features into the student model, yielding significant gains on dense benchmarks (+2 mIoU on ADE20k). Results show that early Gram teachers work best, while late ones degrade performance. Qualitative visualizations confirm that high-resolution Gram anchoring greatly enhances patch feature correlations.
Post-Training
Resolution Scaling
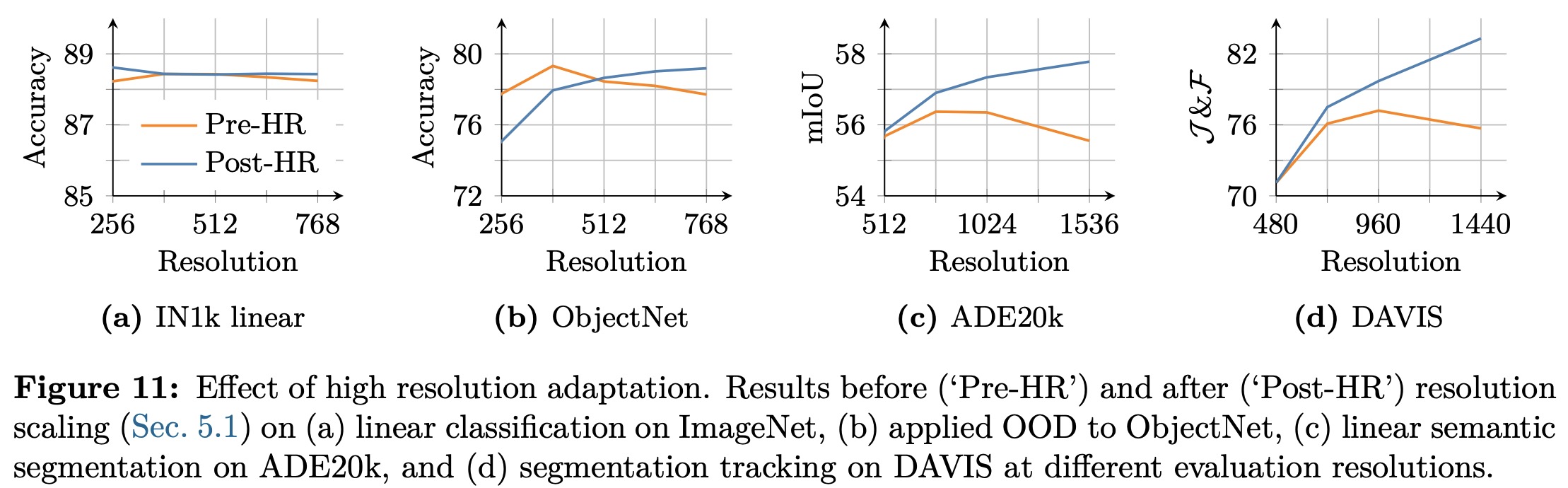
The model is trained at a resolution of 256 for efficiency, but many vision tasks require higher resolutions. To adapt, the authors add a high-resolution training step using mixed global (512, 768) and local (112, 168, 224, 336) crops for 10k iterations, with Gram anchoring from the 7B teacher to preserve patch consistency. This step improves generalization across resolutions: classification gains slightly, ObjectNet transfer balances between low and high resolutions, and dense tasks like segmentation and tracking see clear improvements. The adapted model maintains robust local features and remains stable even at resolutions far beyond training, up to 4k.
Model Distillation
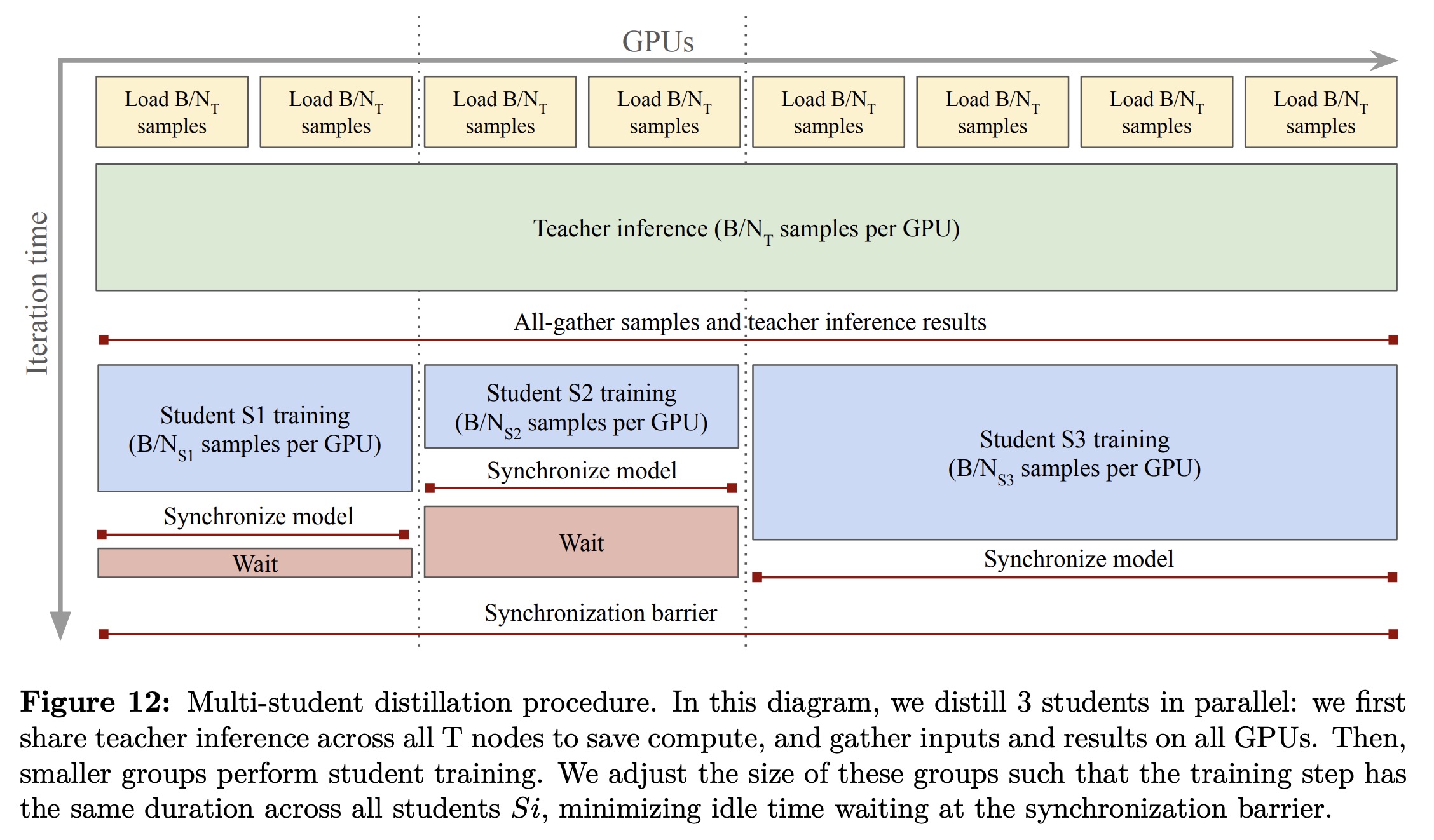
The 7B DINOv3 model is distilled into smaller Vision Transformer variants (ViT-S, B, L, custom S+, and H+), enabling efficient deployment while retaining much of the teacher’s representational power. Distillation uses the same objectives as the main training phase, with the fixed 7B model as the teacher and without Gram anchoring, since smaller students do not suffer patch-consistency issues. These distilled models achieve strong performance at a fraction of the compute cost. To scale efficiently, the teacher inference is shared across all GPUs and multiple students are trained in parallel. This reduces per-GPU cost, accelerates distillation, and allows training an entire family of models in one pass, providing practical options across different compute budgets.
Aligning DINOv3 with Text
Open-vocabulary image-text alignment often relied on CLIP, which captures only global correspondences, limiting fine-grained understanding. Recent work shows that self-supervised visual backbones can enable richer multimodal alignment. Building on this, DINOv3 is aligned with a text encoder using a LiT-style contrastive training strategy: the vision backbone is frozen, two transformer layers are added on top, and both CLS and mean-pooled patch embeddings are used to match text. This combines global and local features, improving dense task performance while keeping training efficient and consistent with prior data curation protocols.
Results
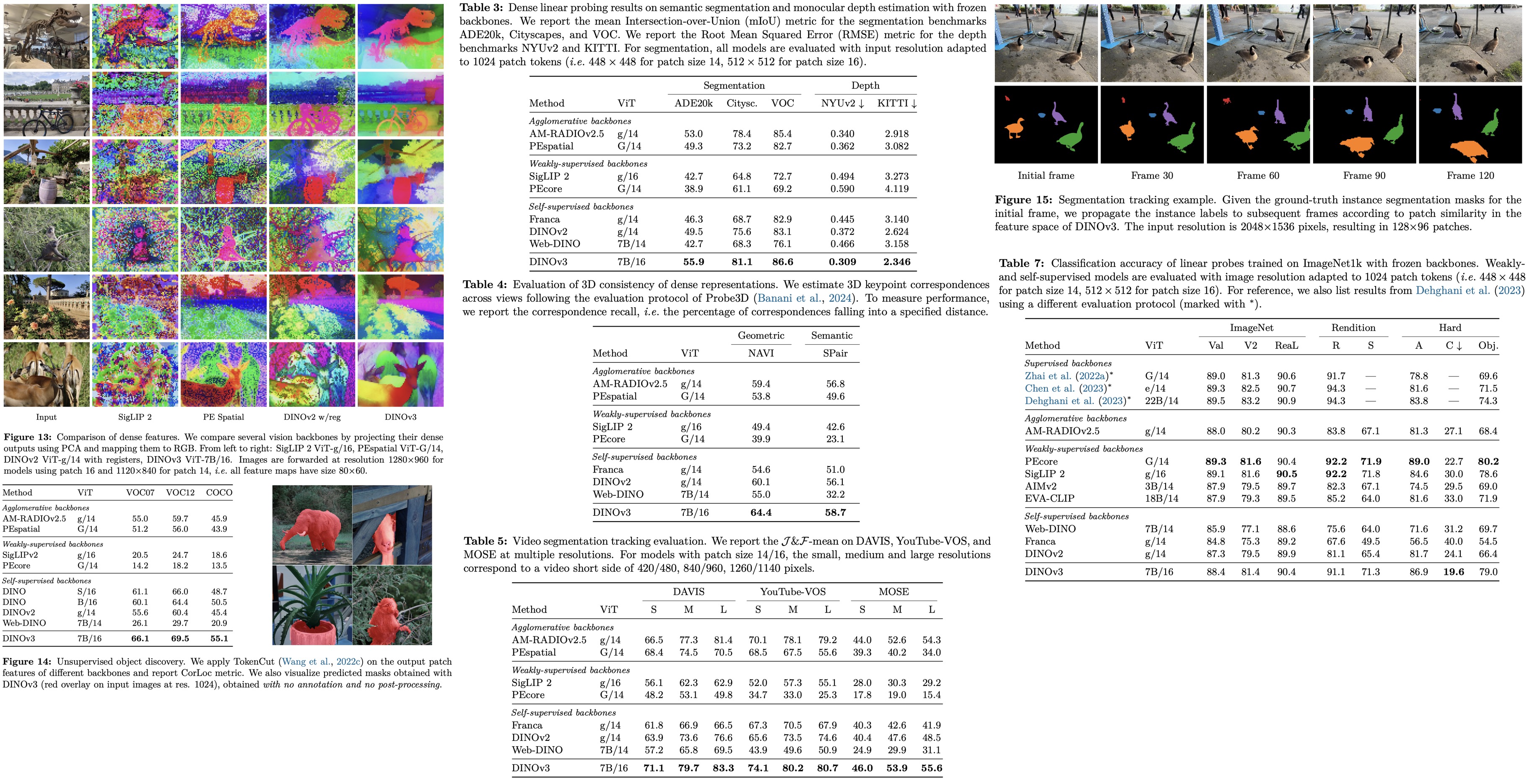
The authors evaluate DINOv3 7B across multiple vision tasks using frozen representations, showing that fine-tuning is unnecessary for strong performance. The model provides exceptional dense features and robust global representations, and serves as a foundation for building advanced systems that achieve competitive or state-of-the-art results in tasks such as object detection, semantic segmentation, 3D view estimation, and monocular depth estimation.
DINOv3 on Geospatial Data
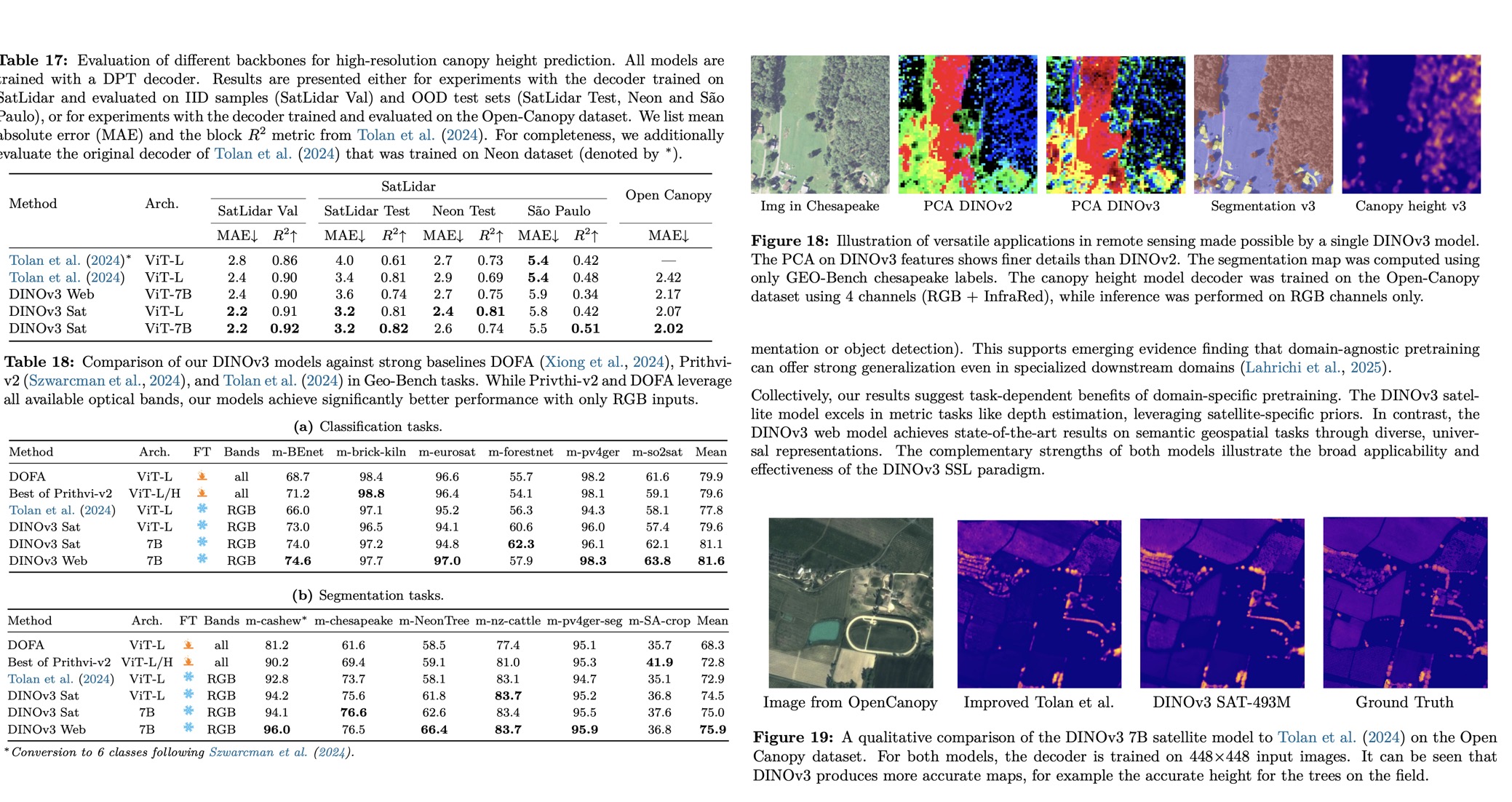
A DINOv3 7B satellite model is pre-trained on 493M high-resolution satellite images using the same training recipe as the web model, then distilled into smaller variants for efficiency. Evaluations show that the satellite model achieves new SOTA results in canopy height estimation, reducing MAE across SatLidar1M and Open-Canopy benchmarks, and performing strongly on semantic and detection tasks. The distilled ViT-L satellite model matches or even surpasses the 7B model in some cases, highlighting efficiency gains. Comparisons reveal that domain-specific pretraining benefits metric tasks like depth estimation, while the general web-trained DINOv3 achieves superior results in semantic segmentation and object detection. Together, the satellite and web models demonstrate complementary strengths, showing that DINOv3’s self-supervised paradigm generalizes effectively across both domain-specific and domain-agnostic geospatial tasks.
paperreview deeplearning cv pytorch imagesegmentation sota pretraining