Paper Review: A Recipe For Arbitrary Text Style Transfer with Large Language Models
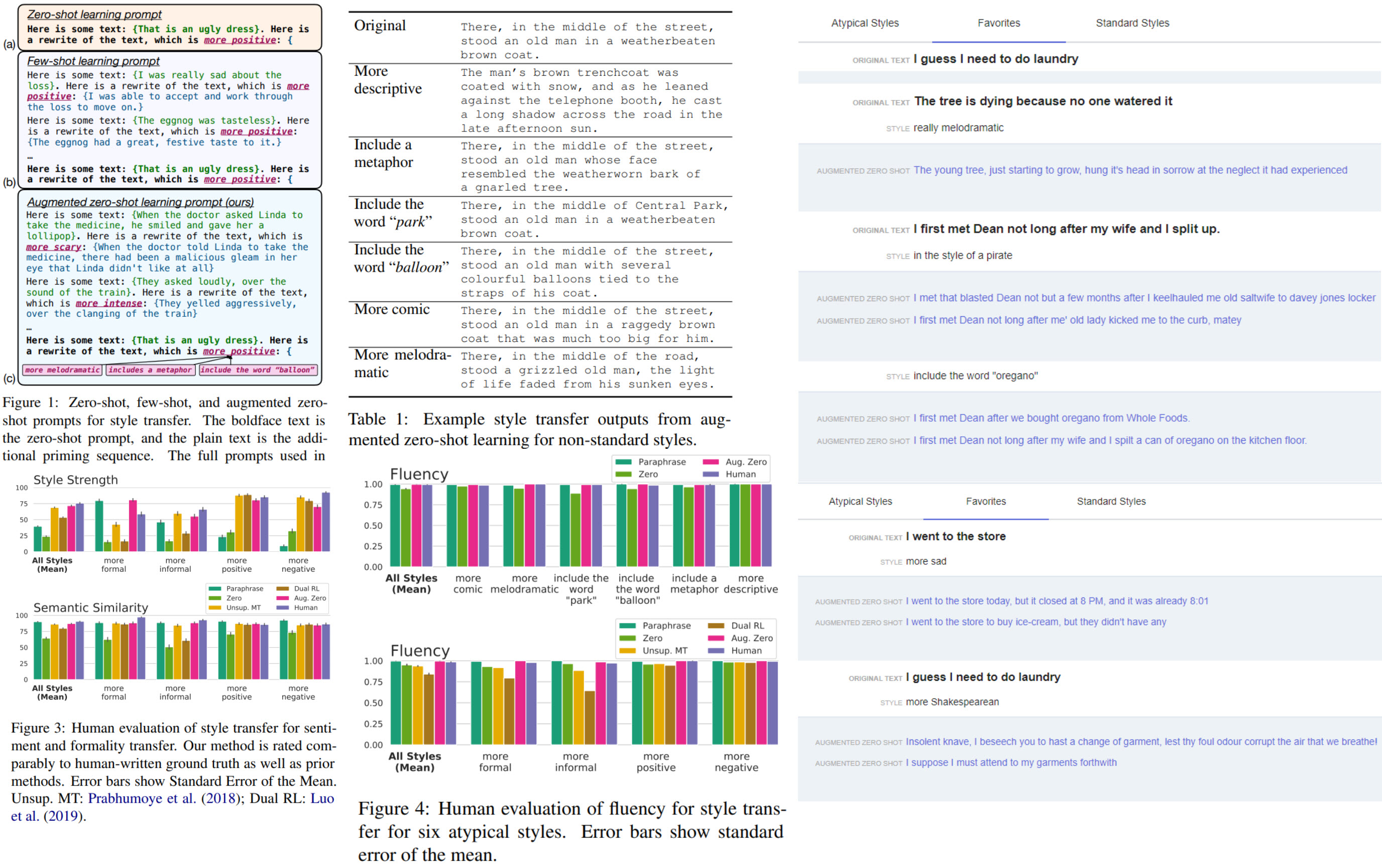
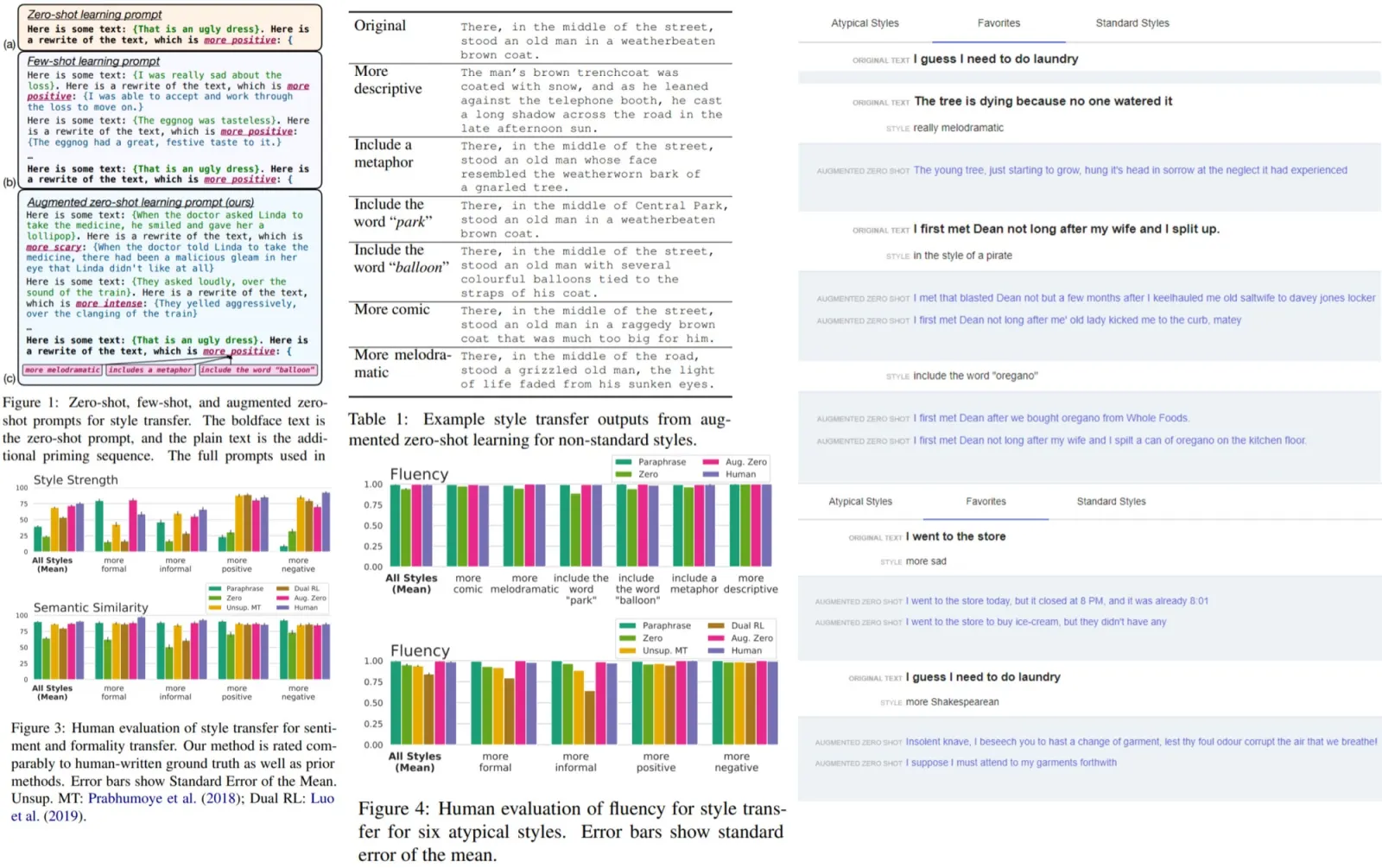
In this paper, the authors present a new approach prompting method called augmented zero-shot learning, which frames style transfer as a sentence rewriting task and requires only natural language instruction, without model finetuning or exemplars in the target style.
This approach is simple and works very well both on standard style transfer tasks and on arbitrary transformations such as “make this melodramatic” or “insert a metaphor.”
On using prompts
Large language models are trained only for continuation, but recently many approaches showed that it is possible to perform other NLP tasks by expressing them as prompts that encourage the model to output the desired answer as the continuation.
- Zero-shot prompting directly uses natural language to ask the large LM to perform a task, but it may fail: for example, by returning poorly formatted or illogical outputs;
- Few-shot prompting gives better results but requires exemplars for the exact task that we want the model to perform; thus, this approach is limited to a set of pre-defined styles;
- Augmented zero-shot learning prompts the model using related style transfer tasks in the same format. This preserves the flexibility of zero-shot prompting while pushing the model outputs to follow a specific template;
The approach
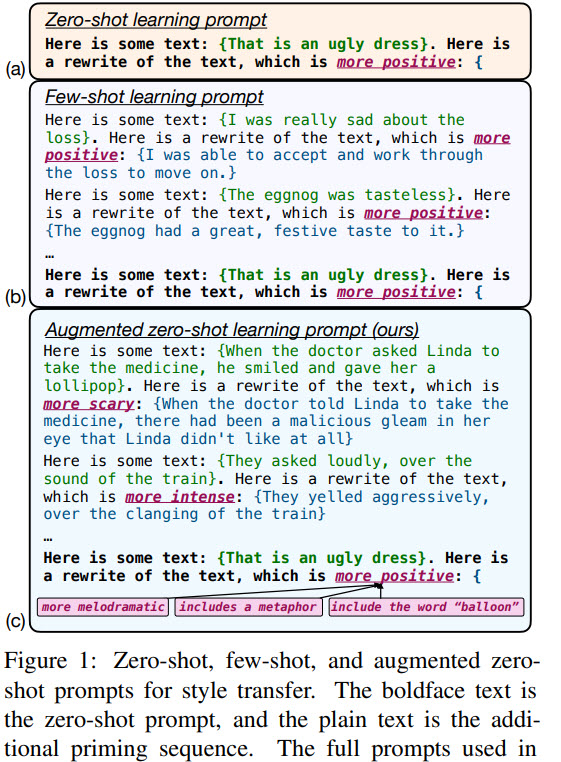
The authors use six non-standard style transfer tasks, that were among the most popular style adjustments in Google’s AI-assisted text editor. Demo link Paper link
The models are evaluated on the Reddit Writing Prompts validation set using human evaluation; they are also evaluated for sentiment and formality style transfer on the standard datasets.
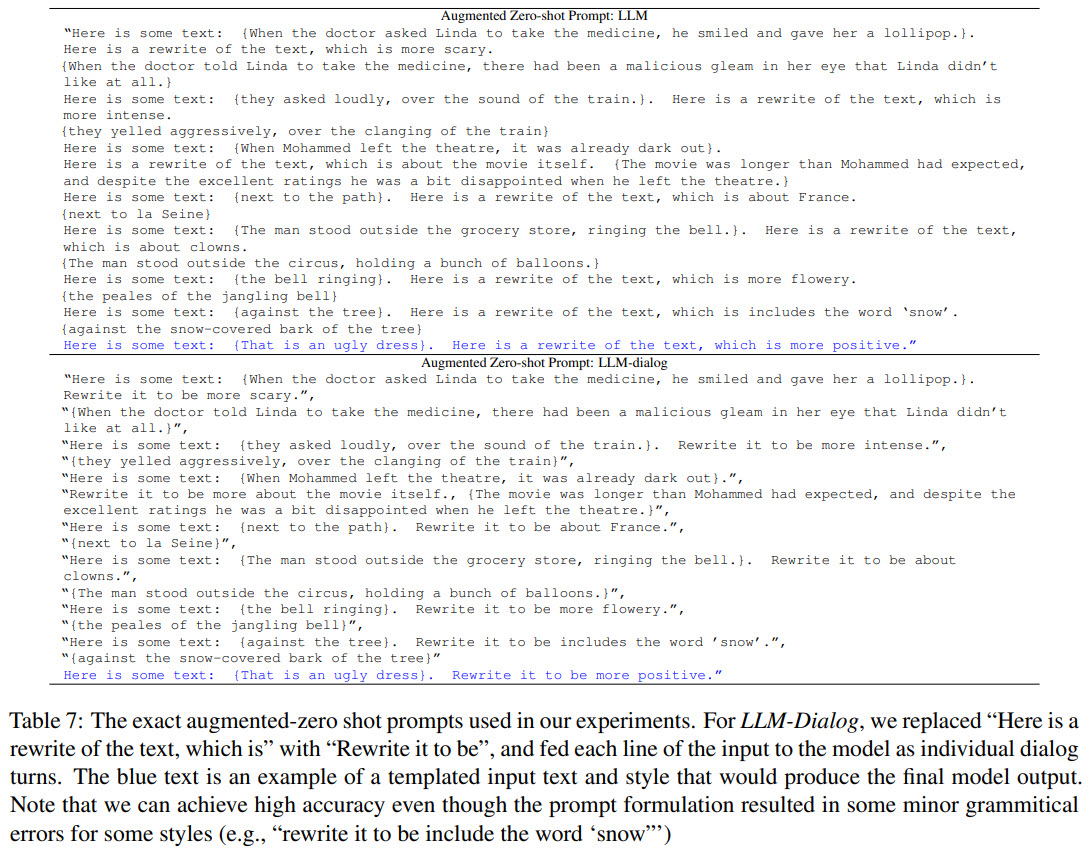
There are few details about the model itself. The authors use two models, both left-to-right decoder-only transformer language models with a non-embedding parameter count of 137B:
- The first one (LLM) was trained on public web documents;
- The second one (LLM-Dialog) finetunes LLM on a high-quality subset of data in a conversational format;
The authors also wanted to show that their approach can be used with other language models and performed an experiment with GPT-3.
For LLM-Dialog, the prompt is formulated as a conversation between one agent requesting rewrites and another performing the rewrites.
The results
The quality of the outputs of the model is on par with human-written ground truth.
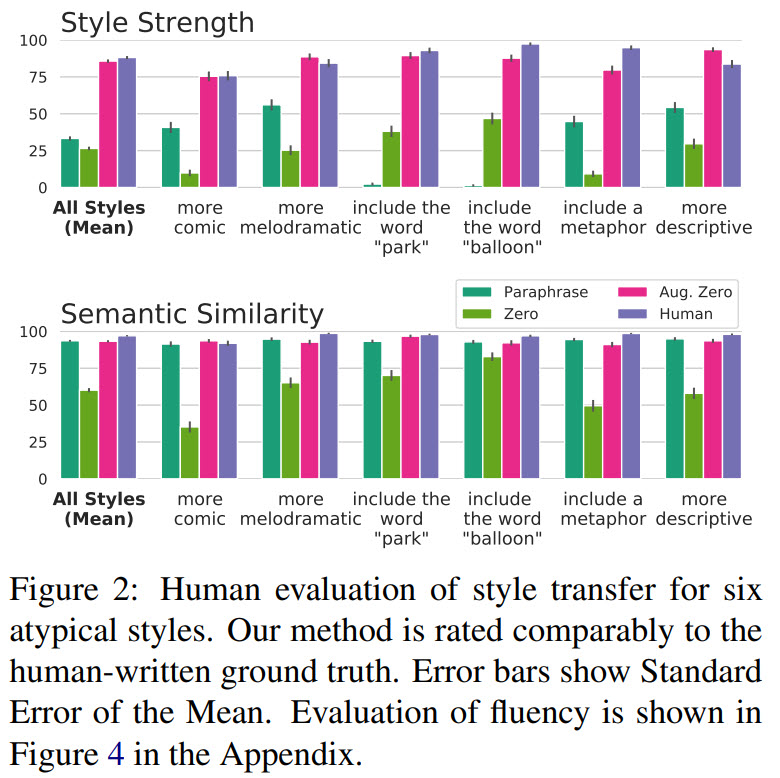
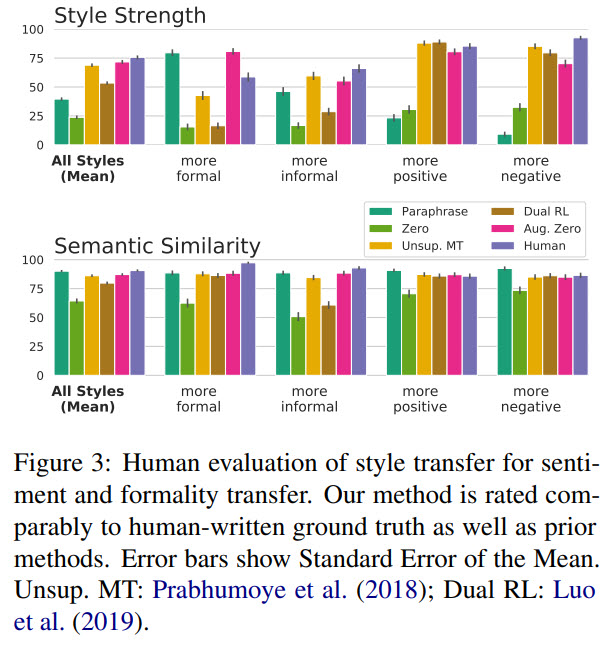
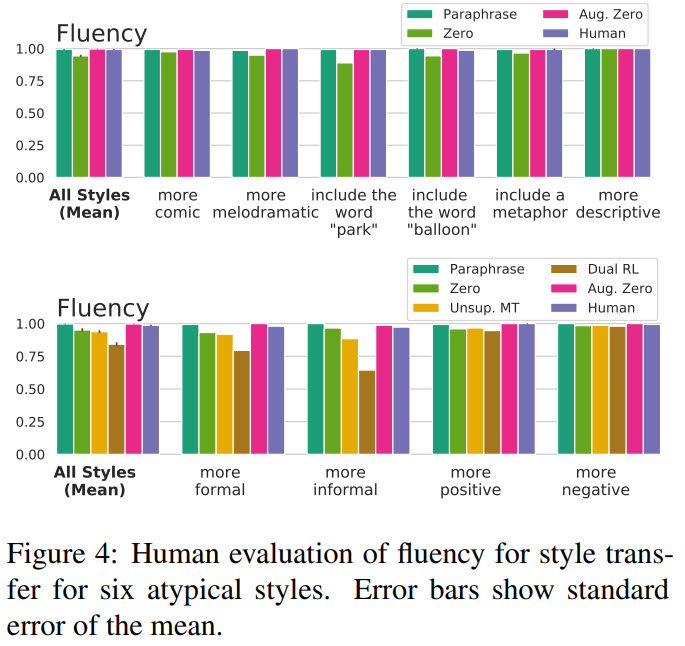
Limitations and Failure Modes
- Sometimes, the outputs of the model can’t be parsed into usable answers. For example, when given a prompt like “Here is some text: that is an ugly dress. Here is a rewrite of the text, which is more positive” LLM-Dialog might return something like “Sounds like you are a great writer!”. Another example of an unusable output could be “a good rewrite might be to say that the dress is pretty.”. Better datasets could solve this problem;
- The models can sometimes hallucinate text content;
- A model can have an inherent style - generating a text following a specific style by default;
- If a specific style transfer task has enough training data, it would be better to train a model on it;
- General large language model safety concerns;
I really like this paper! The idea of a completely arbitrary text style transfer is fantastic, and the outputs’ quality is quite good. And it was interesting to read about the model’s limitations, as often the authors simply praise their approach without discussing possible problems with it.
paperreview deeplearning nlp styletransfer