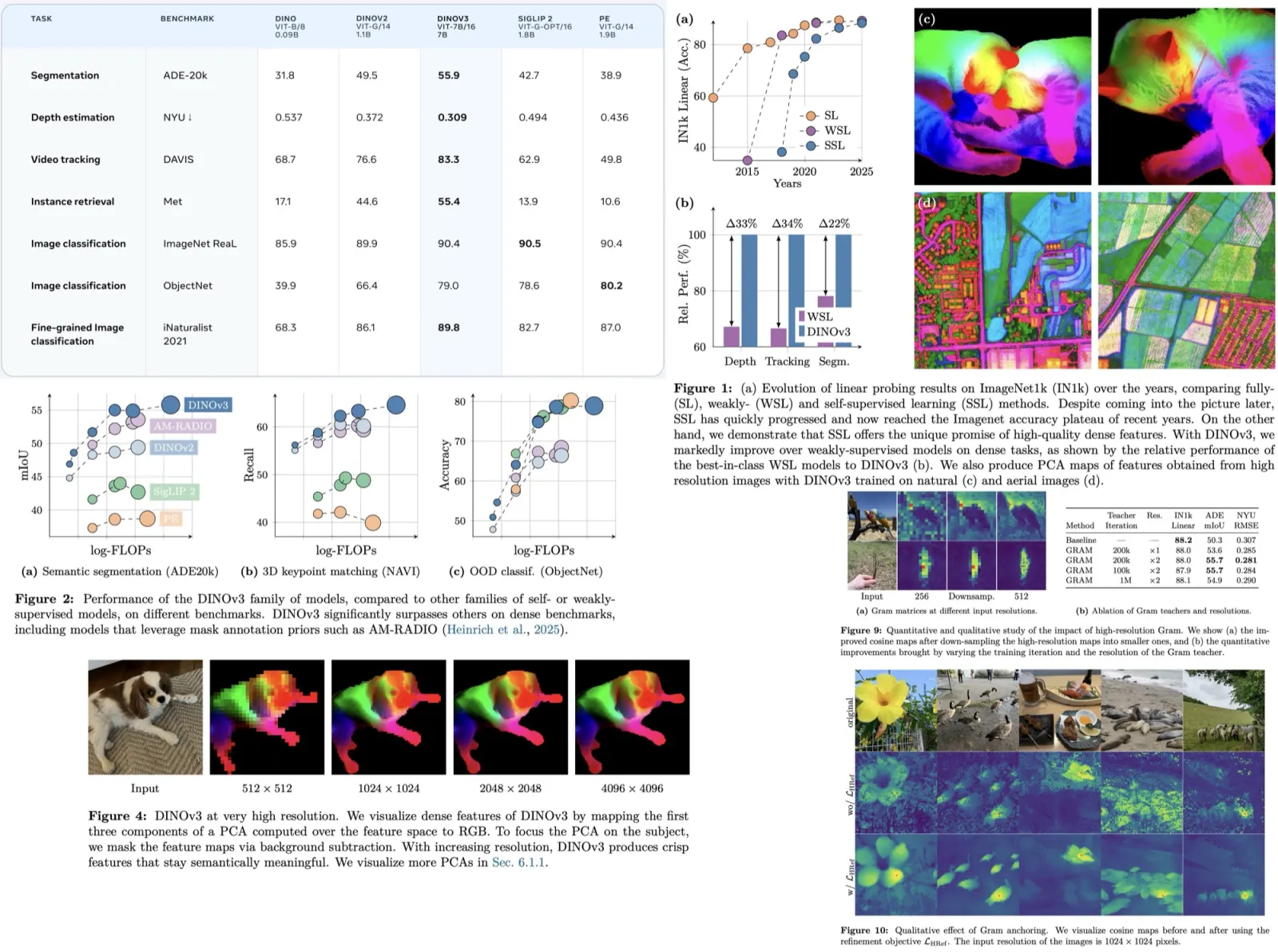
Paper Review: Domain-Aware Universal Style Transfer
Modern style transfer methods can successfully apply arbitrary styles to images in either an artistic or a photo-realistic way. However, due to their structural limitations, they can do it only within a specific domain: the degrees of content preservation and stylization depends on a predefined target domain.
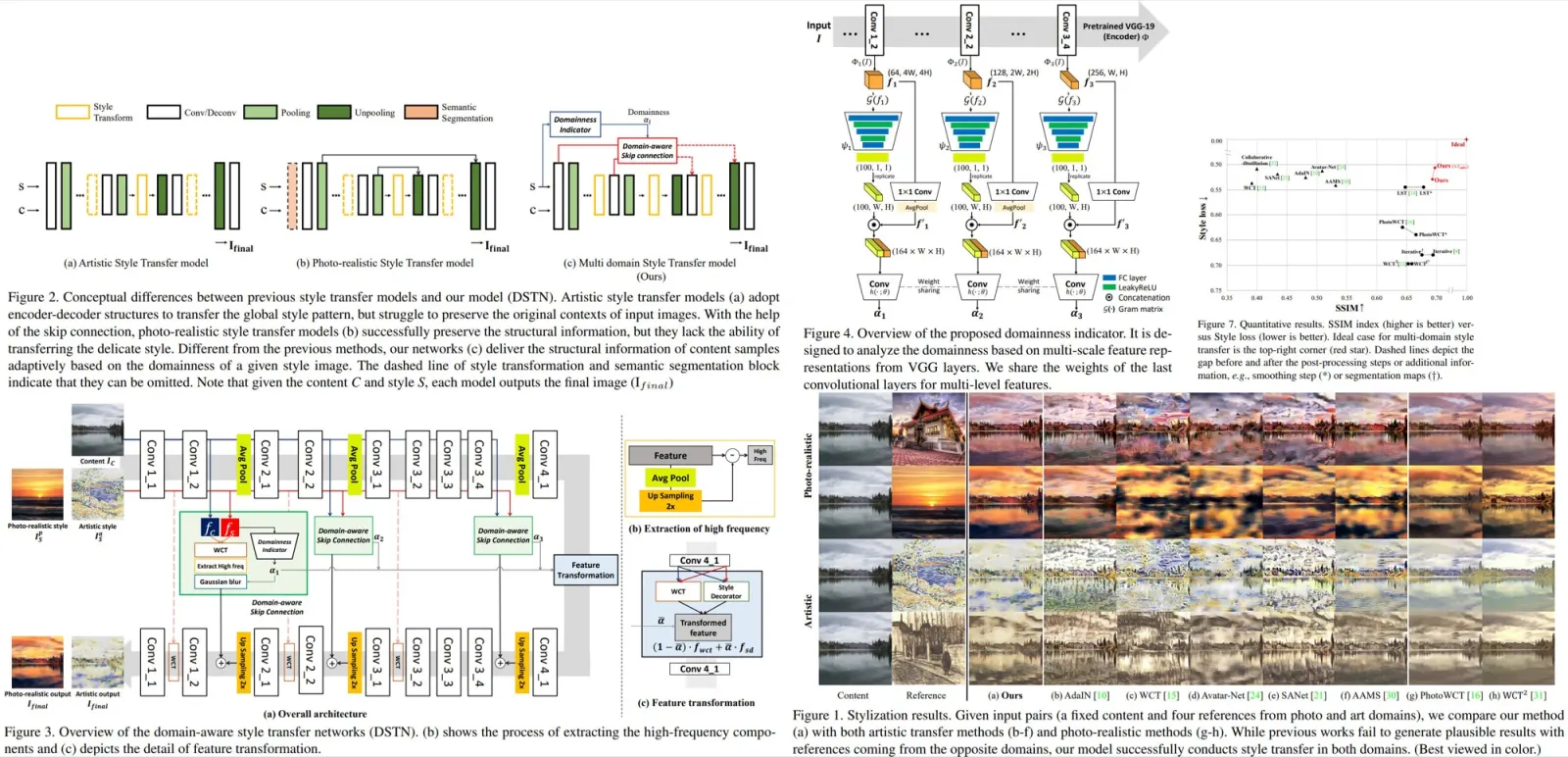
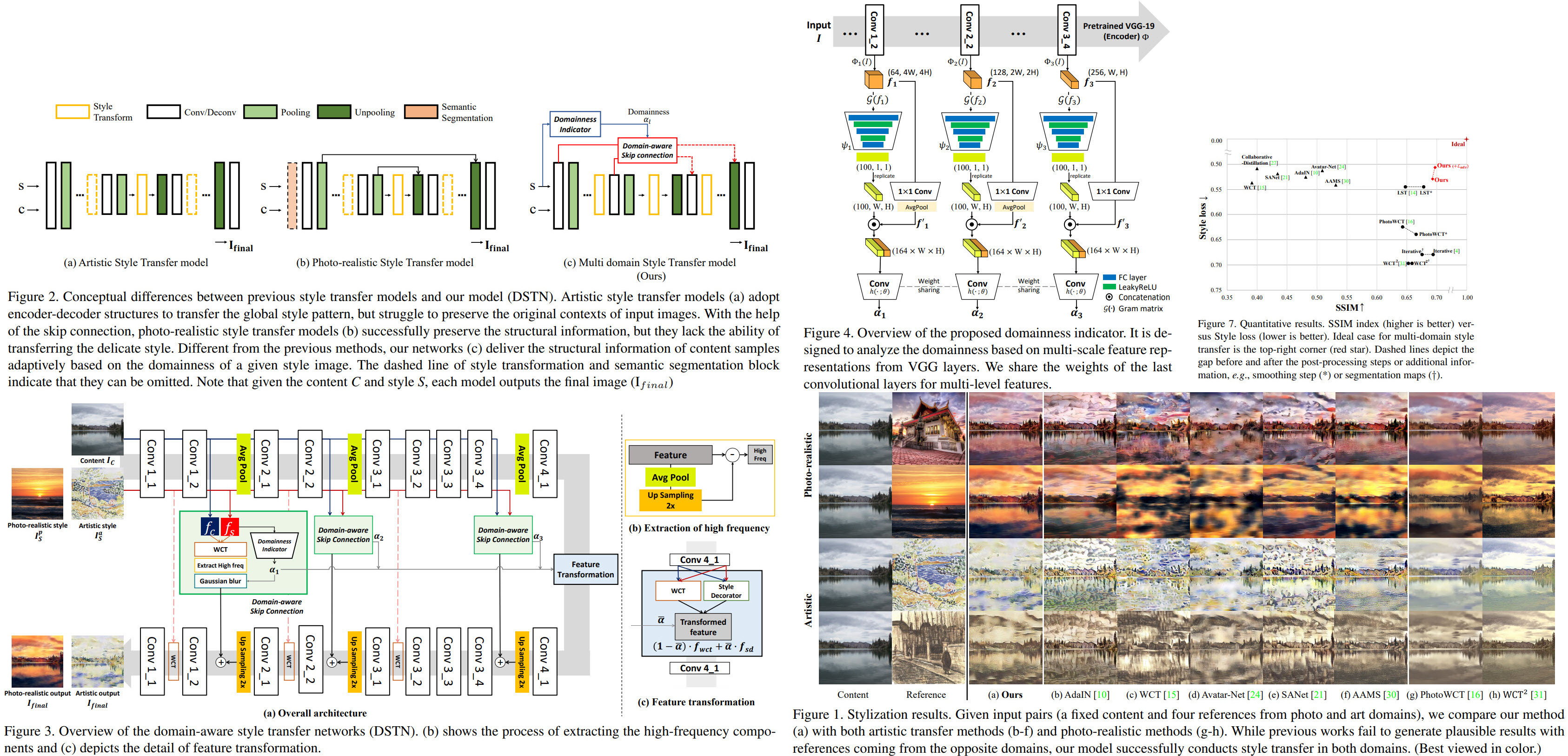
The authors propose Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. They design a domainess indicator (based on the texture and structural features) and introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator.
On styles and domains
There are numerous approaches for universal style transfer, and they work with images in two broad domains: artistic or photo-realistic.
In the first case, the models use second-order statistics of reference features to transform the features of content images. Some of them try to transfer the global style pattern from reference images. The downside of this approach is that these models struggle to maintain clear details in the decoder because there is no information in the content image. Thus, applying artistic style transfer to the photo-realistic reference images results in the content image’s structural distortions.
In the second case, the models focus on preserving original structures while transferring target styles. This approach uses skip-connections to constrain the transformation of input references. As a result, the models can’t produce the delicate patterns of artistic references.
The authors suggest a new approach focusing on capturing the domain characteristics from a given reference image and adjust the degree of the stylization and the structural preservation adaptively.
DSTN is a unified architecture: auto-encoder with domain-aware skip connections and the domainess indicator:
- domain-aware skip connections are used for balance between content preservation and texture stylization. They adjust the transmission clarity of the high-frequency component from the stylized feature maps according to the domain properties;
- the domainness indicator uses the texture and structural feature maps extracted from different levels of our encoder;

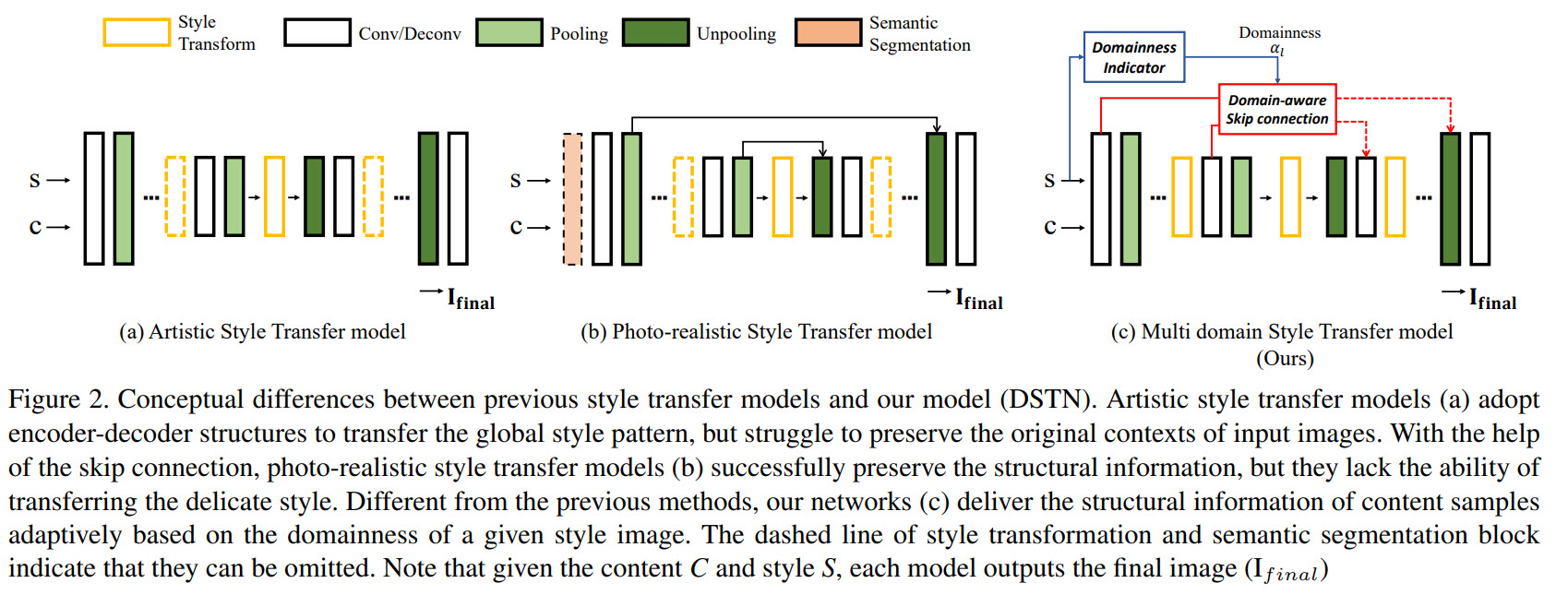
The approach
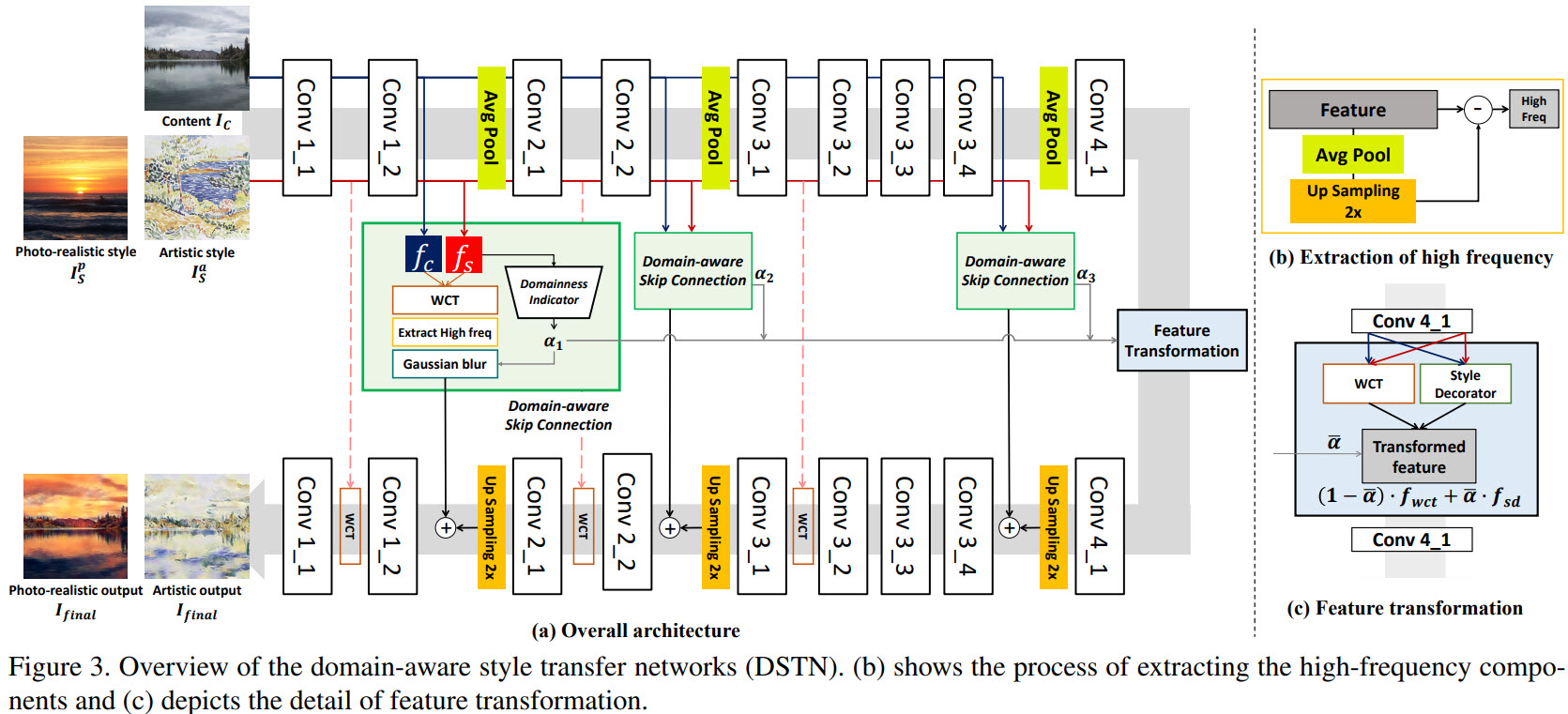
Domain-aware Skip Connection
- The domain-aware skip connection transforms the content feature with the given reference feature;
- After that, high-frequency components of a stylized feature are extracted;
- They are used as a key of reconstruction;
- the decoder reconstructs an image with structural information coming from skip connections and texture information from the feature transformation block;
Thanks to this design, it is possible to adjust the level of structural preservation according to the domain properties of reference images.
For example, for artistic references, we can blur the high-frequency components; as a result, the decoder has to rely on deep texture features instead of the structural details to reconstruct the image. And if we decrease the blur, the result will be photo-realistic.
Domainess indicator
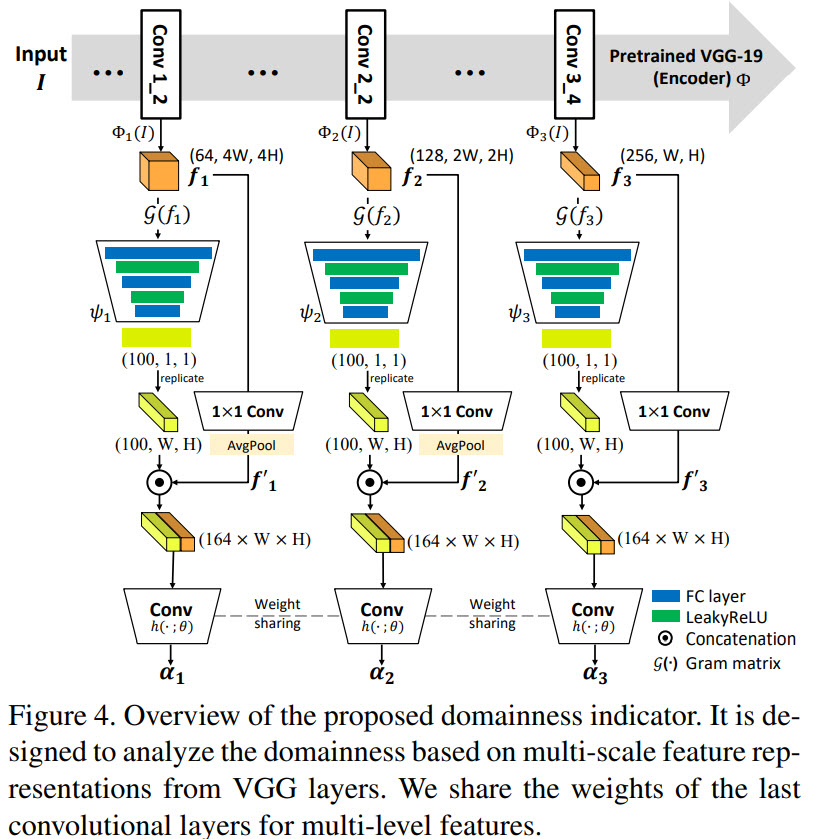
- We take feature maps from different layers of VGG and calculate a gram matrix;
- A channel-wise pooling is used to encode structural information;
- The texture and the structural information are concatenated and fed into convolutional layers with shared weights to obtain the domainess of each level;
- But two domains aren’t enough, so the authors use a domain adaptation method to utilize the intermediate space between photo-realistic and artistic - they create intermediate samples as mixes of artistic and photo-realistic;
- For two main domains they use a binary cross-entropy loss, for mixed samples the loss depends on the L1 distance between the features;
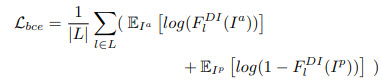
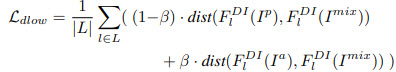
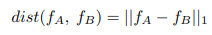
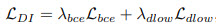
Training
- VGG-19 as an encoder with average pooling instead of max pooling;
- The decoder is similar, but pooling is replaced by up-sampling;
- The total loss is a sum of a loss for domainess indicator, adversarial loss, reconstruction loss, and total variation loss;
- DSTN is trained on MS-COCO and WikiART;
- Adam optimizer, batch size 6, 256x256 image size;
- The model is trained on a single 2080Ti;
The results
Qualitative results
DSTN shows good results on both domains


Quantitative results
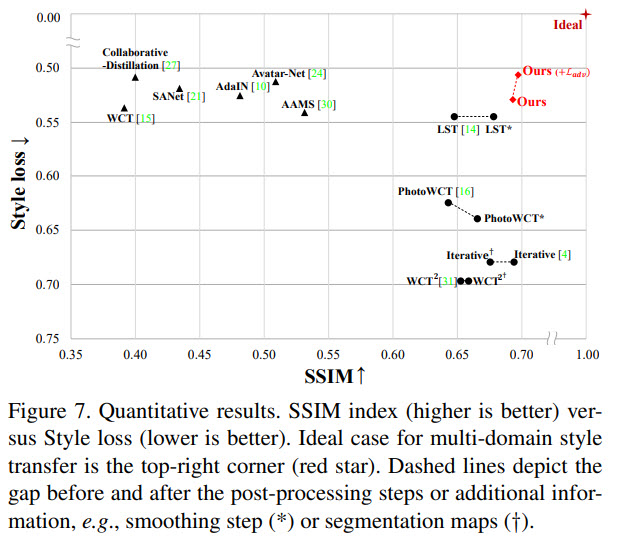
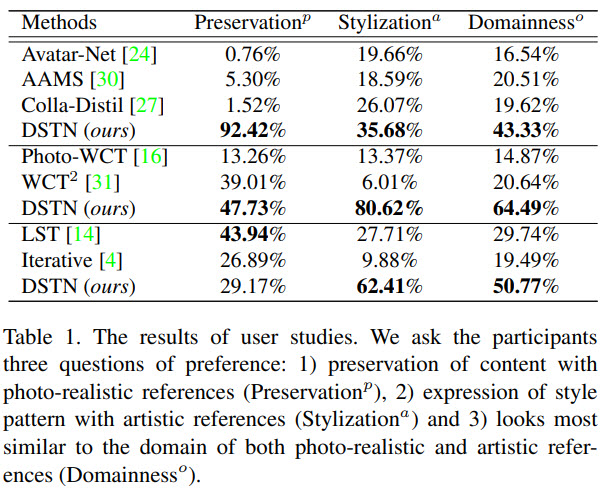
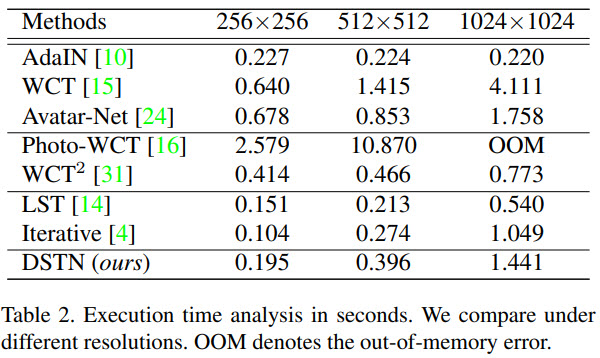
Ablation studies

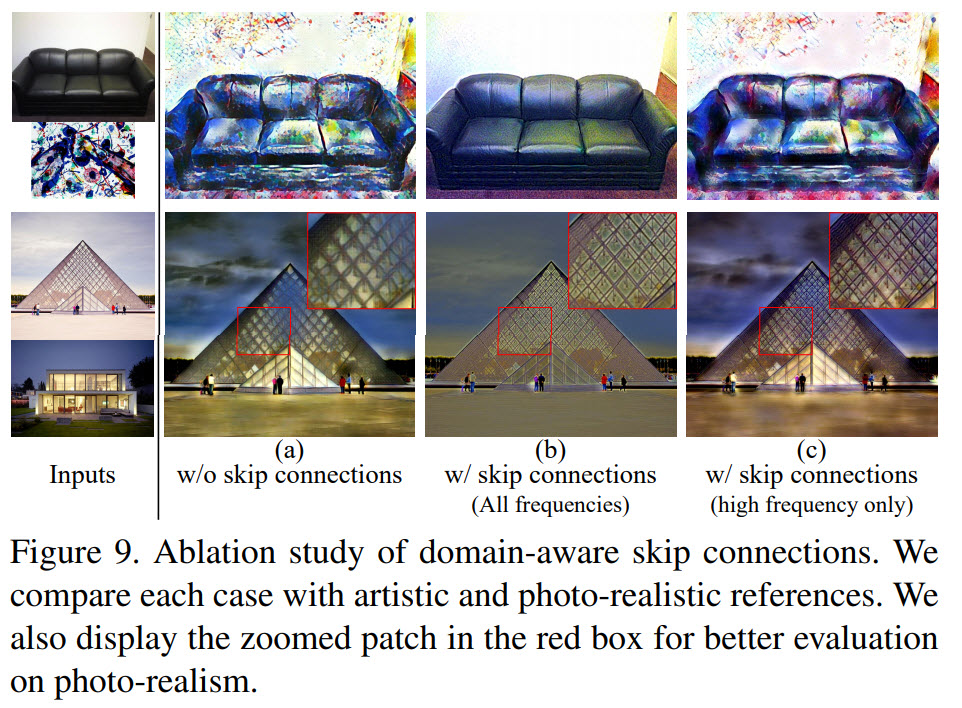
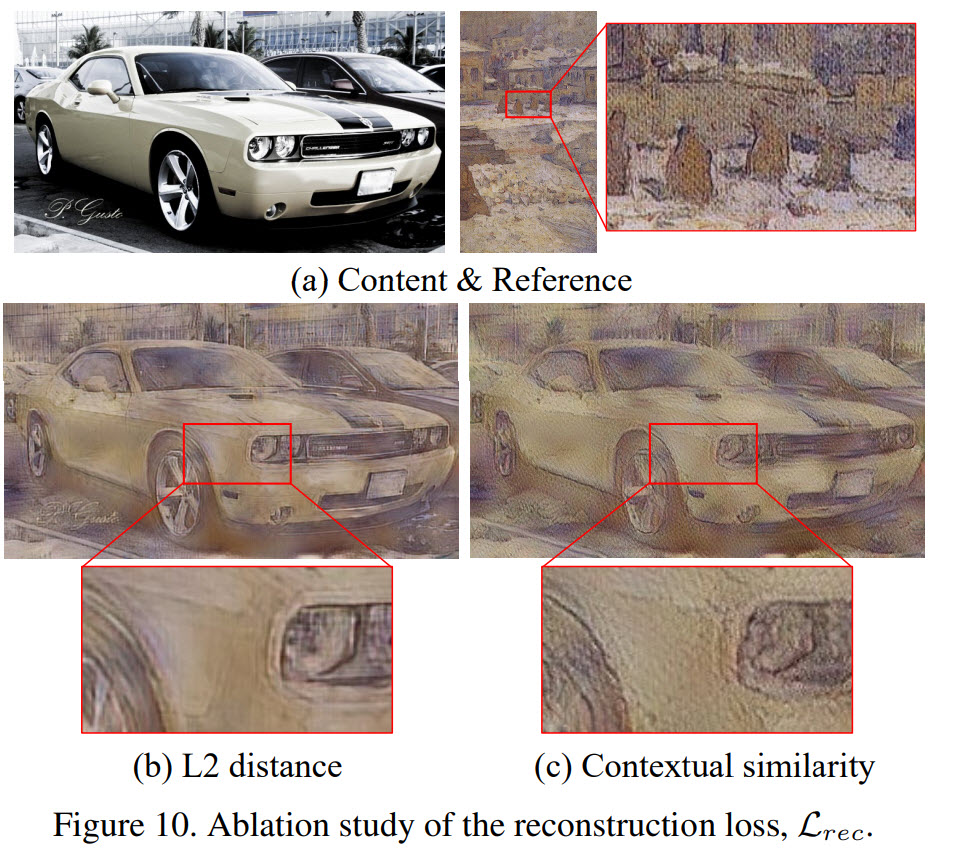
- The first figure shows the effect of changing the hyperparameters of the domainess indicator;
- Without the domain-aware skip connections, DSTN fails to preserve the structural features; applying them to all features causes the loss of the artistic effect; using only the high-frequency features leads to the best results;
- If we use L2 loss for reconstruction, the results are blurry and lack the detailed texture; contextual similarity loss is better;