Paper Review: SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Paper link Code link (PyTorch)
The authors introduce an attention model for span-based joint entity and relation extraction. The key is using BERT: they use BERT embeddings, localized context, and strong negative sampling.
And in general, I like approaches where the neural net has more than one task. Also, I liked the ablation study and experiments in this paper.
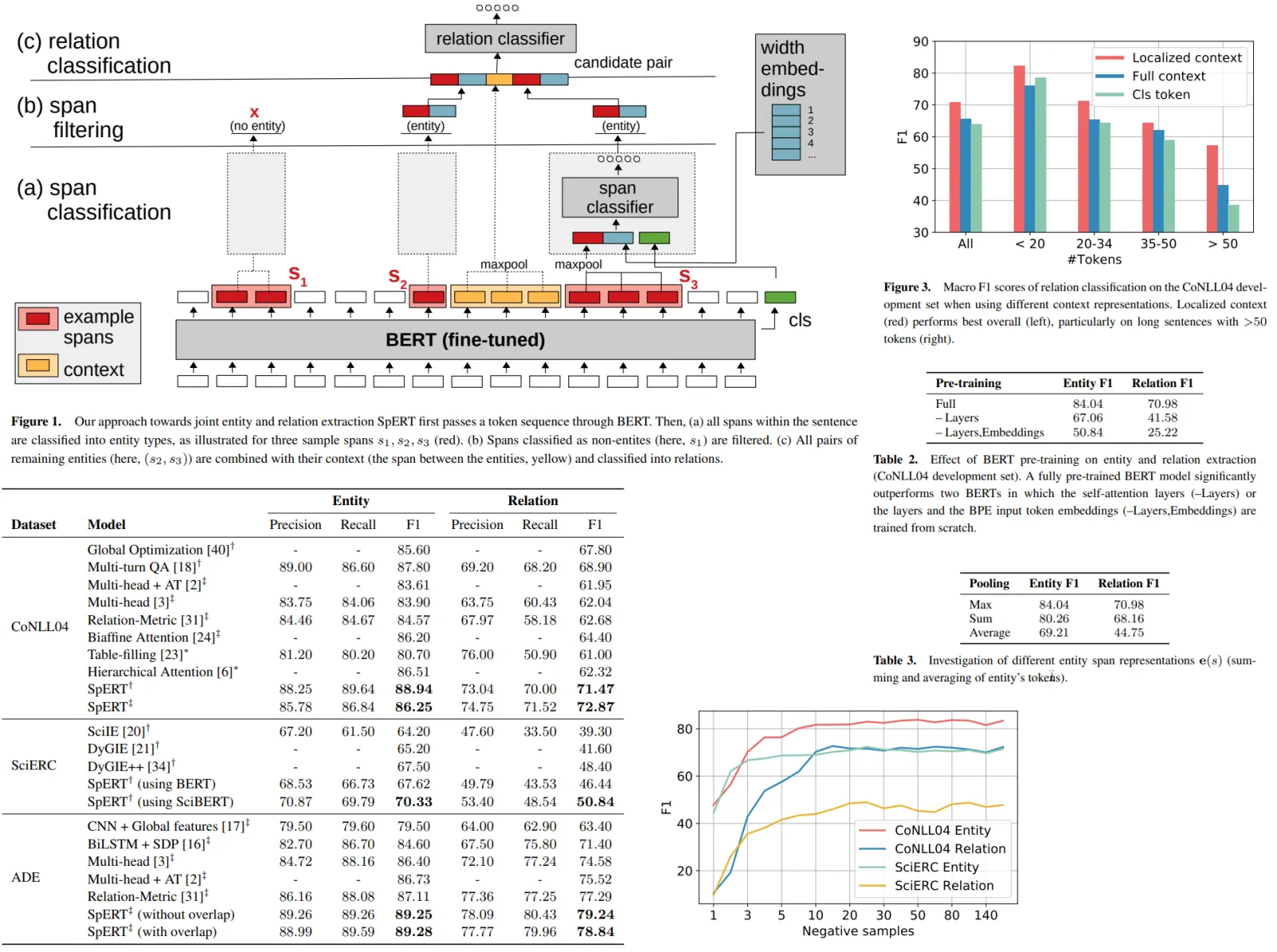
A span-based approach means that any token subsequence (= span) can be an entity, and a relation can be between any pair of spans. This approach also works for overlapping entities, like “codeine” inside of “codeine intoxication”. Note the difference with the usual NER, where each token has a single tag under the BIO scheme (or some other).
Bert is a big model, so while training, they run each sentence through BERT only once. And use some simple downstream processing with a basic entity/relation classifier.
The main contributions are the following:
- SpERT model. They report +2.1% F1 score over the current SOTA on the benchmark
- Ablation study showing that negative sampling within sentences is efficient, localized context is useful, and fine-tuning pre-trained model is better than training from scratch (who could have guessed)
The approach
The idea is the following:
- tokenize input sentence into BPE tokens. Get N tokens
- get embeddings using BERT. length of embedding sequence is N + 1 (the last token represents a special token, capturing the context of the whole sentence)
- classify each span (sequence of tokens, max length is 10) into entities
- filter non-entities
- classify remaining pairs into relations
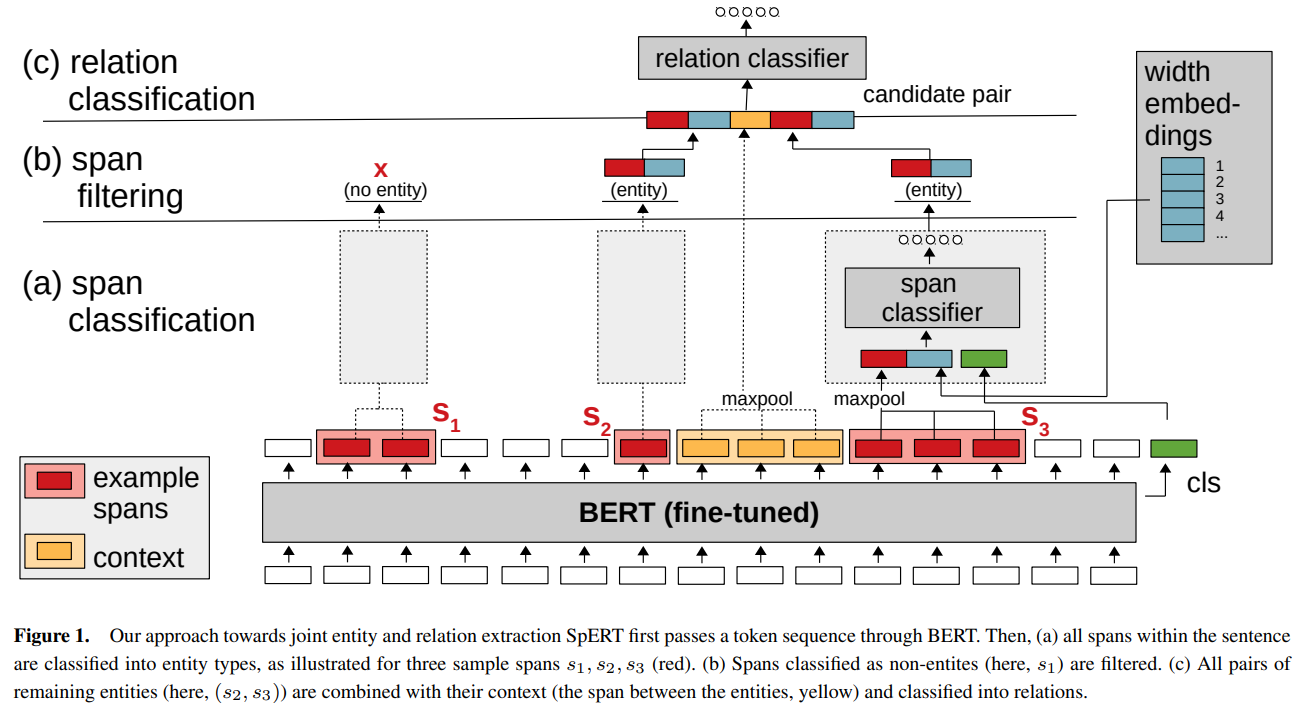
Span Classification
Bert embeddings of all words in spans are combines using fusion = maxpooling (but it is possible to use other approaches).
Width embeddings are concatenated to the span embedding. For each span length, there is a separate width embedding (like we have different width embeddings for spans with widths 1, 2, 3, and so on). And these embeddings are trainable.
And they also concatenate that additional token for sentence context.
After this, we have a softmax.
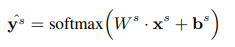
Span Filtering
Filter out spans that are predicted as non-entities.
Relation Classification
So we have R relation classes and SxS matrix with all pairs of spans.
The input of the classifier consists of two parts:
- fused embeddings of spans
- Using sentence context token doesn’t work. Instead, we take all the words between the entities and use maxpooling on their BERT embeddings. This is called localized context. If the entities are near each other, this representation is zero.
These two inputs are concatenated.
As relations are usually asymmetric, we classify (s1, s2) and (s2, s1) - relation in both ways. The activation function is sigmoid. The threshold for classification is α.
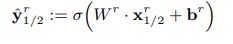
Training
Several processes are going on while training:
- learning size/width embeddings
- Ws, bs, Wr, br - parameters of classifiers
- BERT fine-tuning
Loss is a sum of:
- span classifier’s loss - cross-entropy over entities
- relation classifier’s loss - binary cross-entropy over relation classes
A training batch has B sentences, samples for classifiers are drawn in the following way:
- for span classifier, we take all labelled entities as positive samples and fixed number Ne of random non-entity spans as negatives
- for relation classifier, ground truth relations are used as positives, and negative pairs are entity pairs without any relation.
Note that these samples are created inside each sentence - not from multiple sentences in the batch. And there is a single pass of BERT. This is done for speed.
[So I suppose that we could train longer and generate negative samples across sentences to improve model performance.]
TheExperiments
CoNLL04. 4 entities, 5 relation types. 1153 train, 228 test.
SciERC. 6 entities, 7 relation types. 1861 train, 275 valid, 551 test.
ADE. 2 entities, 1 relation type. 10 cross-fold validation.
On the second dataset, the authors use SciBERT, on the other BERT base.
Adam, warmup, batch size 2, width embedding has size 25, 20 epochs. The number of negative entity and relation samples per sentence - 100.
The Results
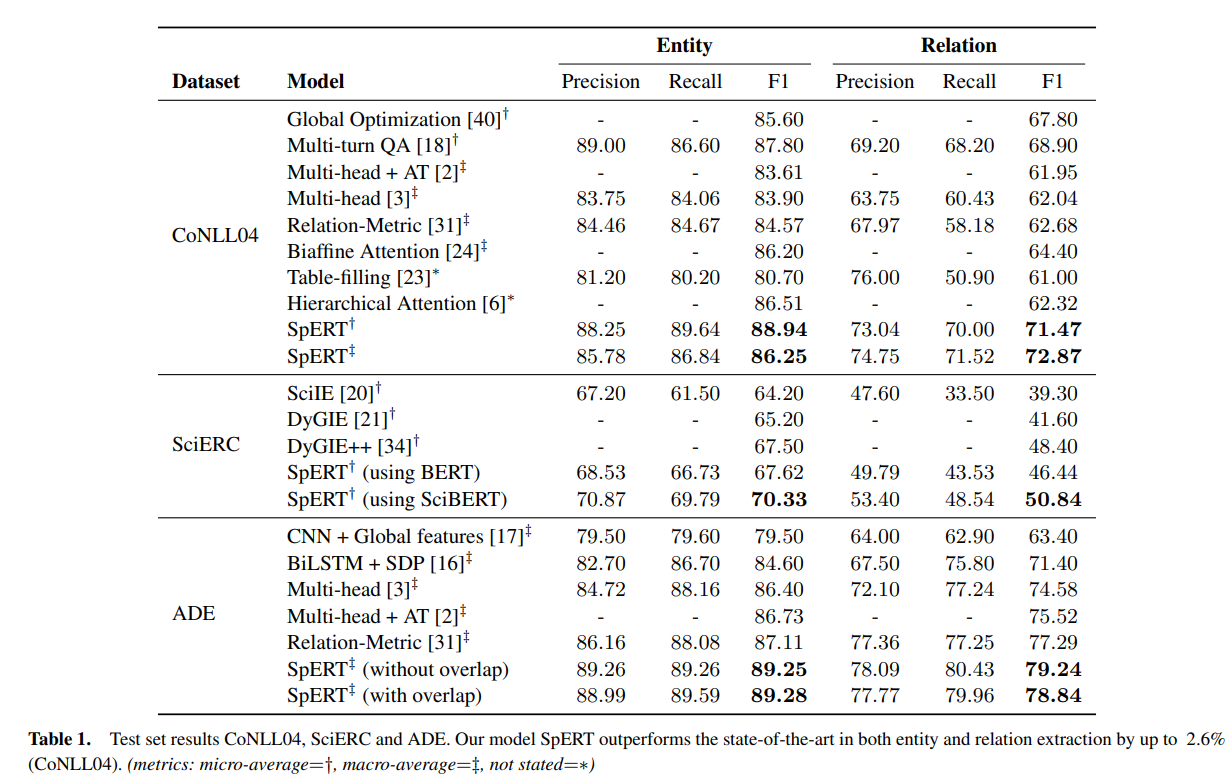
Candidate Selection and Negative Sampling
It seems that a higher number of negative samples really helps. At 20, scores stagnate, but authors say that increasing the number to 100 improves stability.
For relation classification, the authors tried using weak negative samples - generating pairs of spans before filtering and not after. Recall stayed high (84.4% on CoNLL04), but precision dropped to… 4.3% (Wow!). The main problem is that model starts predicting relations between subspans.
For example, in the sentence “[John Wilkes Booth] who assassinated [President Lincoln], was an actor” the model predicted such pairs as John + President or Wilkes + Lincoln.
And model also frequently predicted relations, where one of the spans was non-entity.
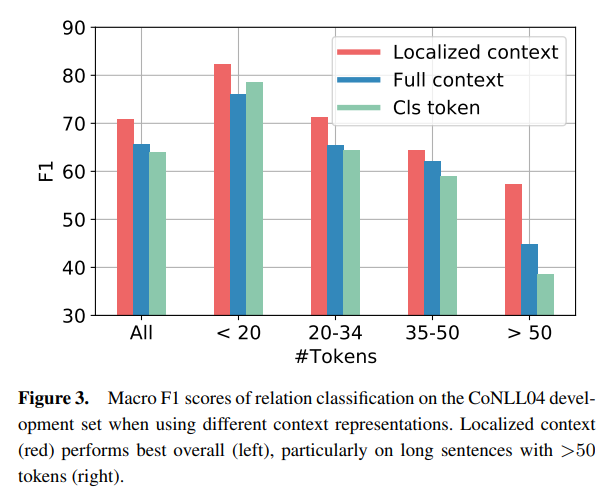
Localized Context
They compared Localized Context with Full context (max pooling over all tokens in a sentence) and that special token for sentence context.
Using full context results in many false positives.
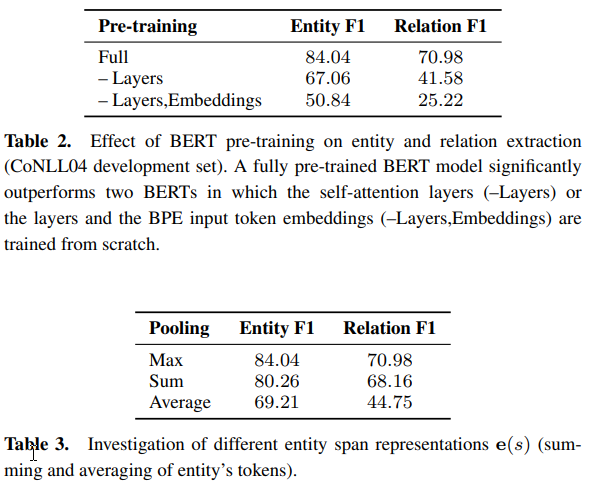
Pre-training and Entity Representation
Authors show that pre-training BERT gives a better score than training it from scratch or training its embeddings.
Also, they show that maxpooling of embeddings is much better than averaging or summing.
The Error Inspection
There are several common errors:
- Incorrect spans. Sometimes model adds one more word to span or misses one of the words
- Syntax. The model predicts relation between entities, which is possible, but in this sentence, these entities were unrelated
- Logical. Sometimes the relation isn’t explicitly stated, but it can be inferred from the context. Like names of employee and employer, but in the sentence there is no mentioning that one works for the other one.
- Classification. wrong relation type predicted
- Missing annotation. The model is correct; there was a missing annotation in the data.

At the end of the article, authors suggest possible improvements for localized context - additional syntactic features or learning the representation of the context.
paperreview nlp deeplearning transformer bert ner relationextraction

