Paper Review: TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes

Complex Visual Text Generation task focuses on generating detailed text across various image regions. The authors propose TextCrafter - a novel multi-visual method that progressively decomposes complex visual text, ensures robust alignment between text and its visual location, and incorporates a token focus enhancement to make visual text more prominent during generation. It addresses issues like text blurriness, omissions, and confusion. The authors publish CVTG-2K - a new benchmark dataset for evaluation. Experiments show TextCrafter outperforms the current state-of-the-art methods.
The approach
Overview
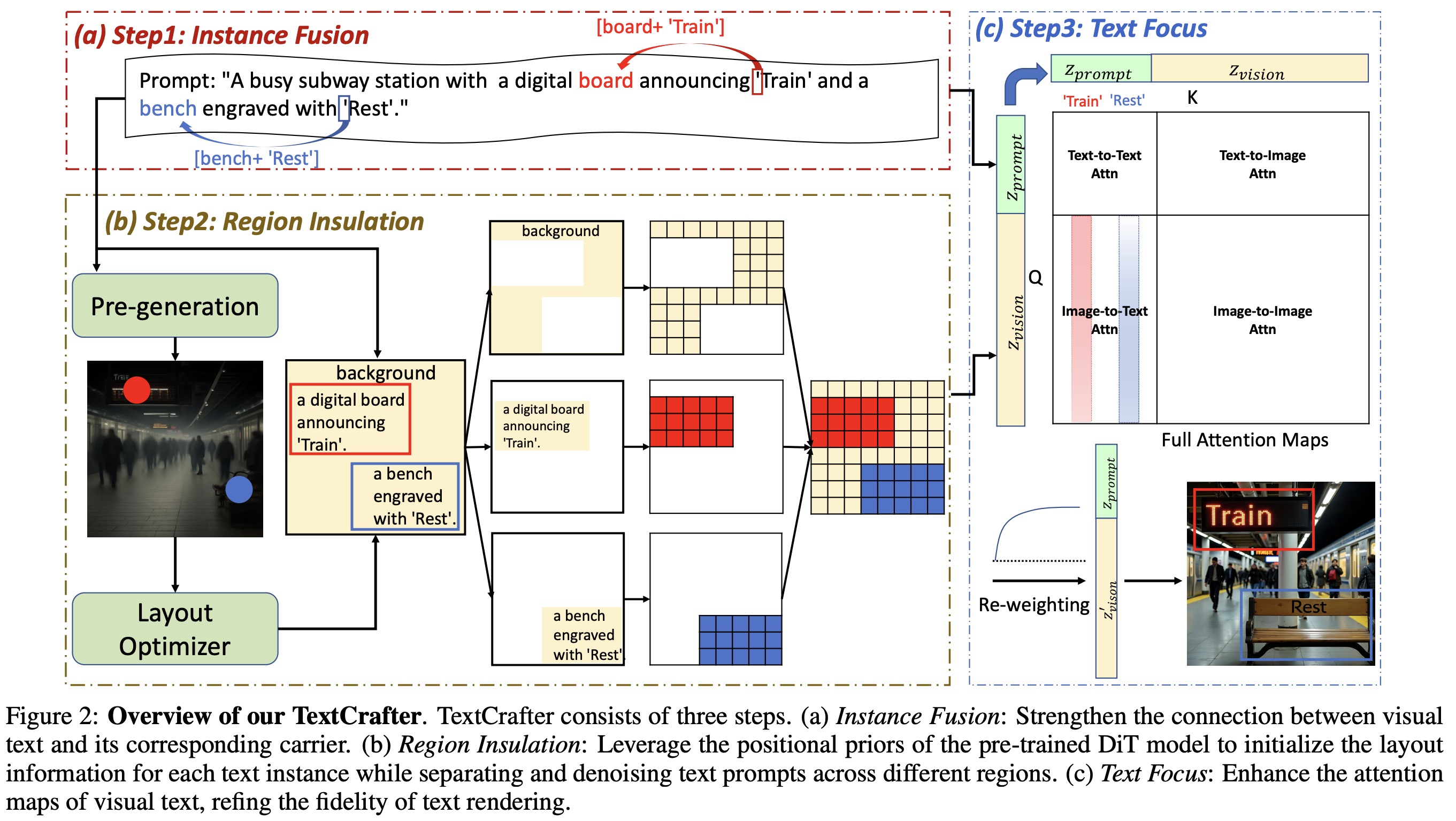
Complex Visual Text Generation (CVTG) is about generating an image from a prompt containing multiple visual text descriptions, each with its content, position, and attributes. The goal is to create an image accurately reflecting all specified visual texts and their descriptions.
Key challenges in CVTG for diffusion models are:
- Text confusion - overlapping or mixing of different text elements.
- Text omission - some texts are skipped or ignored.
- Text blurriness - some texts appear small or less prominent, making them unclear.
While current models handle single visual texts well, CVTG is more complex. The authors propose solving it by breaking it into smaller sub-tasks, solving them separately, and then combining the results. This coarse-to-fine approach enables precise and clear rendering, and it’s the foundation of TextCrafter.
Instance Fusion

To ensure that visual texts are correctly positioned within the generated image and not floating randomly, the authors propose an instance fusion strategy: instead of using the visual text’s own embedding, they use the embedding of the preceding quotation mark, which effectively captures both the content and spatial context of the text through attention. This quotation mark acts as a reference point, encapsulating the full information of the associated visual text. Following the idea of token additivity, its embedding is combined with the embedding of the text’s spatial carrier using a weighted fusion. The prompt is encoded using a T5 text encoder, and each token in the prompt is transformed into an embedding that contributes to the final image generation.
Region Insulation

To prevent interference between multiple texts, the authors decouple them into independent instances, assigning rectangular bounding boxes to define their layout, based on positional preferences learned by a pre-trained DiT model. This decoupling helps prevent interference between texts without requiring manual layout definitions or relying on large language models. During the early steps of the denoising process, attention maps are used to identify the most relevant points for each text, which are then used to guide layout initialization.
These initial bounding box layouts are then optimized using Mixed-Integer Linear Programming. The optimization aims to minimize the Manhattan distance between each box’s center and its corresponding maximum attention point.
The model then encodes the prompt and visual text descriptions, applies the instance fusion to refine embeddings, and begins the denoising process. During the first few denoising steps, each visual text instance is denoised separately using its own context, and then reinserted into the full image.
Text Focus

To maintain clear boundaries between different visual texts while ensuring overall visual harmony, the model merges all regions into a single latent variable during denoising. However, this can blur smaller text elements. To preserve their structure, the authors enhance the attention scores of visual texts and their preceding quotation marks, using a capped boost to avoid excessive amplification. The enhancement ratio is controlled by a tanh-based formula that adapts to the length of the text sequence, with smaller ratios for short texts.
Instead of UNet’s cross-attention, the MM-DiT model uses a full attention matrix with four interaction types: image-to-image, prompt-to-prompt, prompt-to-image, and image-to-prompt. The authors specifically re-weight the image-to-text section of this matrix to strengthen the model’s focus on visual text. During each denoising step, the attention values linked to visual text tokens are scaled by the enhancement ratio, ensuring they receive more attention without overwhelming the rest of the image.
Experiments
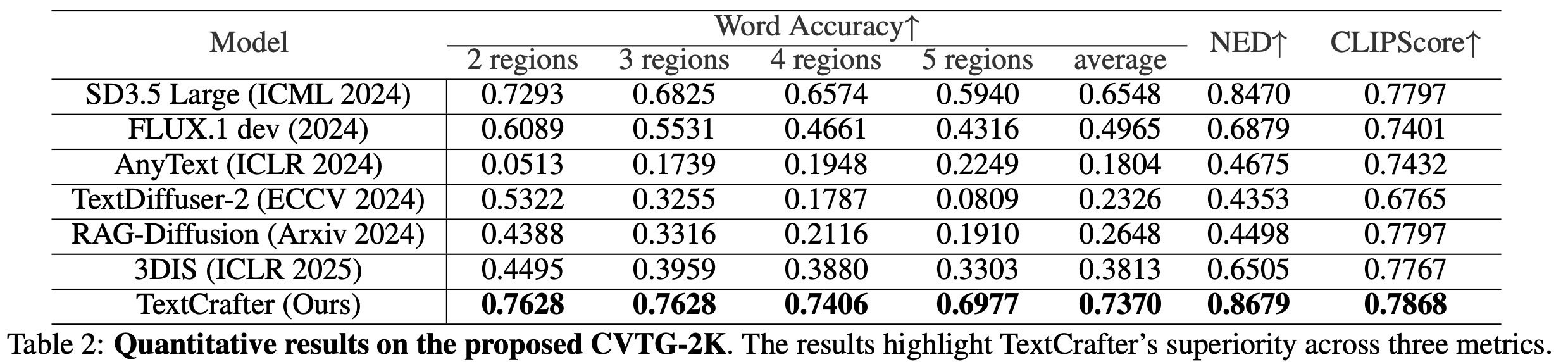
Quantitative experiments on the CVTG-2K benchmark show that TextCrafter outperforms competitors in OCR accuracy (Word Accuracy, NED) and prompt-following (CLIPScore), improving OCR accuracy by over 45% compared to FLUX. General models like Stable Diffusion 3.5 and FLUX struggle as text region complexity increases. Methods trained for single regions fail to generalize; multi-instance control methods also perform poorly on complex visual text generation.

Visual comparisons show that while models like SD3.5 and FLUX generate high-quality images, they suffer with text omissions and confusion as complexity rises. AnyText struggles with multi-word text, TextDiffuser loses background detail, RAG-Diffusion has merging problems, and 3DIS weakens text information. In contrast, TextCrafter successfully maintains image harmony while accurately rendering multiple visual texts according to the prompt, avoiding attribute confusion.

- Instance Fusion: Primarily ensures correct text placement and suppresses hallucinated text. Disabling it has a small impact on overall metrics but leads to text appearing in the wrong locations.
- Region Insulation: Improves all metrics significantly by decoupling texts, reducing complexity, and preventing interference. It achieves over 60% word accuracy alone and improves text clarity.
- Text Focus: Provides the most significant metric improvement, especially for small text clarity and accuracy. It performs best when combined with the other components for stability in complex scenarios.