Paper Review: Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
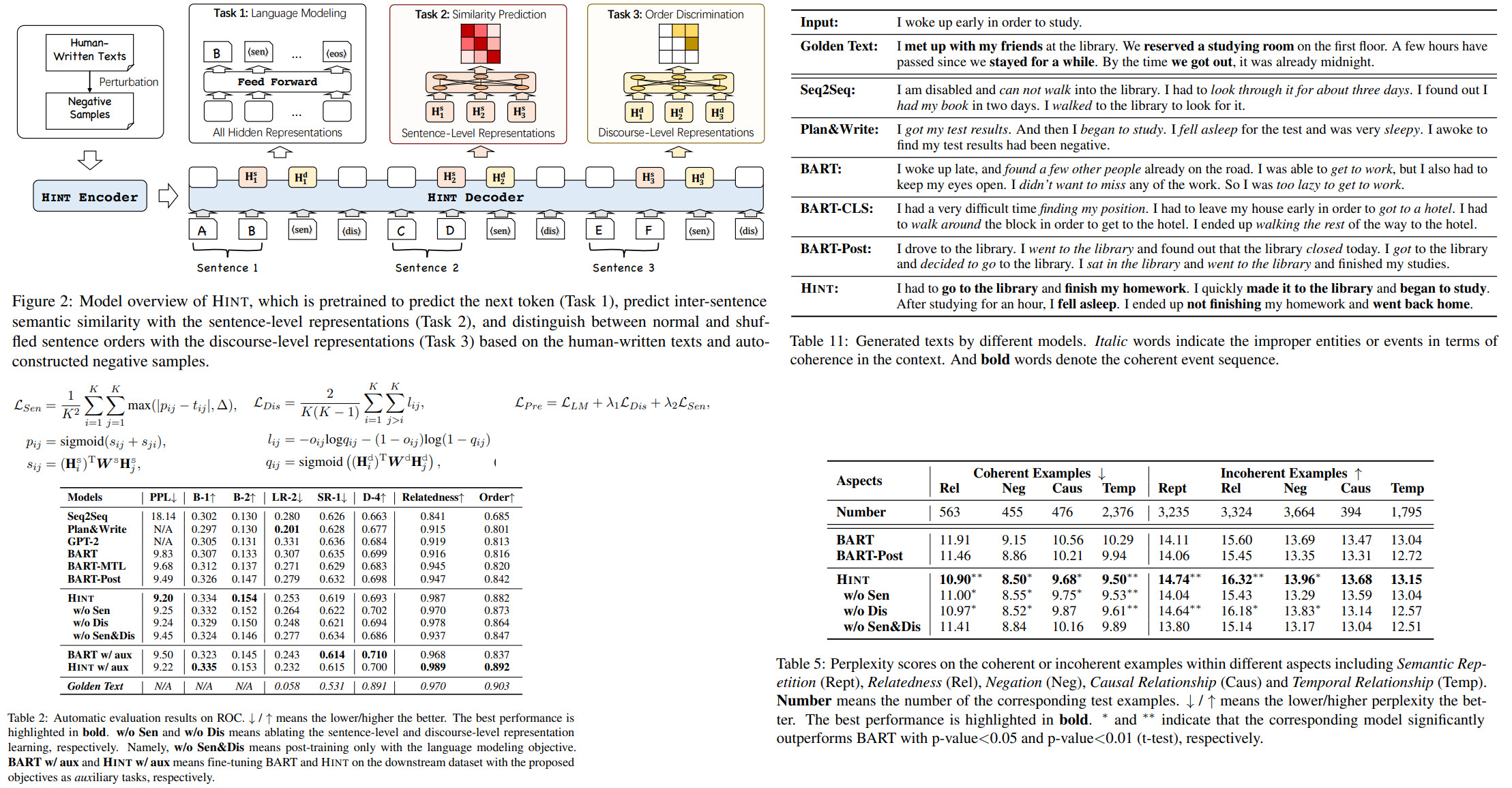
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than other approaches.

Here we see an example of text generation by BART. While the output is related to the content, it has a number of problems: repetitive plots, unrelated events, conflicting logic. The authors think that one of the causes is that NLG models are rarely trained beyond the token-level co-occurrence, but the semantics and discourse relations are critical in creating a coherent narrative. The authors try to solve this problem with a new architecture and pre-training objectives.
The model
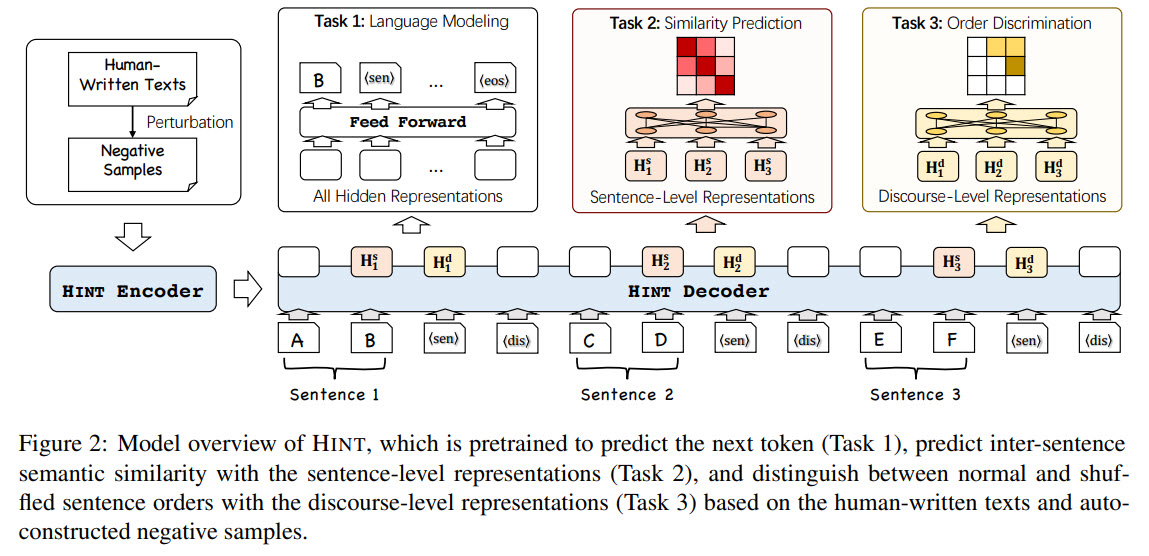
Usually, NLG models train a left-to-right decoder for next word prediction based on the attention to all prefix words. In this model, we insert special tokens at the end of each sentence (if text input has several sentences, we split it) to represent the prefix information at sentence and discourse levels. In fact, it is possible to change this and insert these tokens not after each sentence but after phrases or paragraphs.
Sentence-Level Representation
The idea is to take the decoder’s hidden states for two sentences and predict their similarity. The golden truth here is a similarity produced by SentenceBERT; the difference between similarities should be less than a given margin (so that hint doesn’t become too similar to SentenceBERT).
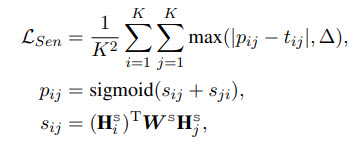
Discourse-Level Representation
They simply try to predict whether the order of two sentences is correct.
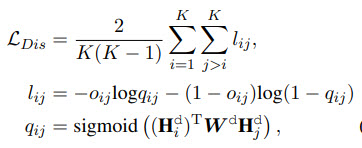
Pre-training and Fine-tuning
The authors augment the training data while pre-training with negative sampling:
- Randomly shuffling the sentences for the order discrimination task;
- Randomly repeat sentences or replaces them with other sentences for the similarity prediction task;
- During fine-tuning only the language modeling objective is used;
The experiments
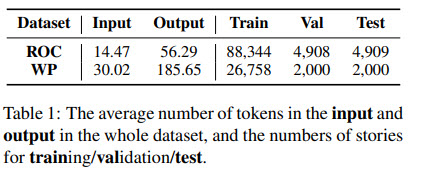
BookCorpus dataset is used for pre-training; evaluation is done on ROCStories (ROC) and WritingPrompts (WP).
The results
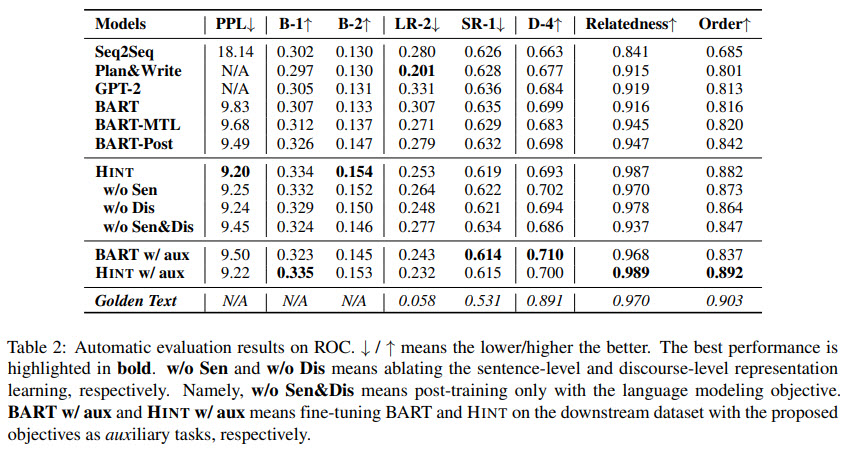
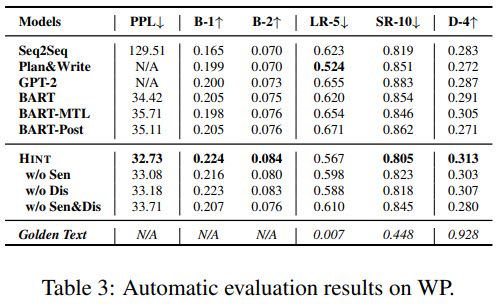
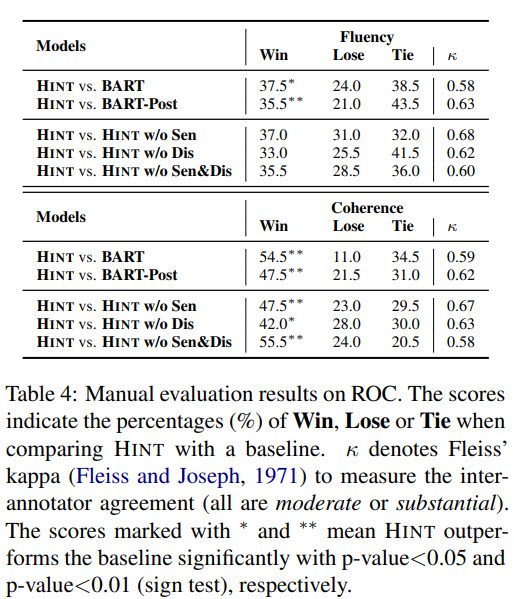
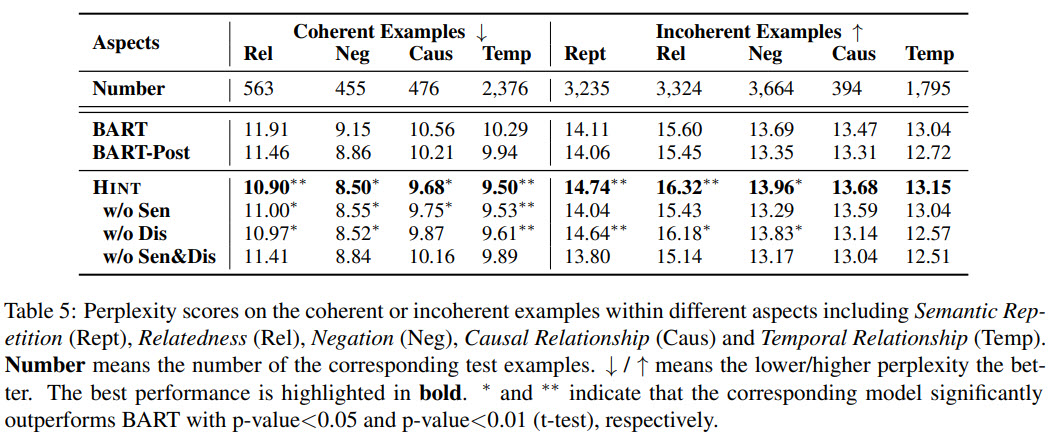
- HINT has the best perplexity, which proves that it can better model new texts;
- HINT also can generate more text overlap (BLEU);
- HINT also has good generation diversity while reducing repetition;
- Ablation texts show then two additional training objectives really help the model’s performance;
- Manual evaluation (Amazon Turk) also shows that HINT is better than BART;

Appendixes provide a lot of additional information on dataset generation, model training, and evaluation.
paperreview deeplearning nlp nlg pretraining